spss练习题及简-答要点教学提纲
- 格式:doc
- 大小:549.50 KB
- 文档页数:24

《spss统计软件》练习题库及答案XXX《SPSS统计软件》练题库及答案(本科)一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:AInsert Variable;BInsert Case;CGo to Case;DWeight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:ASort Cases;BSelect Cases;CCompute;DCategorize Variables(C)3、Transpose菜单的功能是:A对数据进行分类汇总;B对数据进行加权处理;C对数据进行行列转置;D按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A.按照0.05显著性水平,拒绝H,说明三种城市的平均身高有差别;B.三种城市身高没有差别的可能性是0.043;C.三种城市身高有差别的可能性是0.043;D.申明城市不是身高的一个影响身分(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描绘和简单的统计揣度,在分析时能够产生二维或多维列联表,在统计揣度时能进行卡方检修的菜单是_Crosstabs__。
8、One-Samples T Test过程用于进行样本地点总体均数___与__已知总体均数_的比较。
3、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
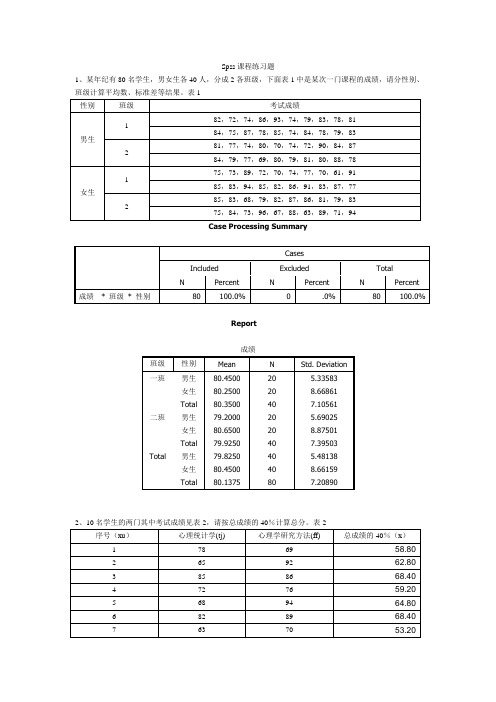
Spss课程练习题1、某年纪有80名学生,男女生各40人,分成2各班级,下面表1中是某次一门课程的成绩,请分性别、班级计算平均数、标准差等结果。
表1Case Processing SummaryReport成绩2、10名学生的两门其中考试成绩见表2,请按总成绩的40%计算总分。
表23、将表1中的数据合并,即不再分组,试整理成频数分布表,绘制出频数分布图,计算出常用的统计量。
Statistics成绩N Valid 80Missing 0Mean 80.1375Std. Error of Mean .80598Median 80.5000Mode 74.00(a)Std. Deviation 7.20890Minimum 61.00Maximum 96.00Sum 6411.00Percentiles 25 74.250050 80.500075 85.0000a Multiple modes exist. The smallest value is shown成绩F r e q u e n c y4、正常人的脉搏平均 数为72次/分。
现测得15名患者的脉搏:71,55,76,68,72,69,56,70,79,67,58,77,63,66,78 试问这15名患者的脉搏与正常人的脉搏是否有差异?One-Sample Test由结果可知,因为0.088>0.05,所以在p=0.05的显著性水平上差异不显著5、收集了20名学生的自信心值,见表3,试问该指标是否与性别有关?表3Independent Samples Test由数据可知,F检验的p=0.608>0.05,所以两组样本的方差差异不显著,所以t检验应该是Equal variances assumed一项进行判断。
双侧t检验的p=0.392>0.05,表示两个样本没有显著性差异4,试问两种训练方法的效果是否相同?表4注:x1、x2表示两组学生的跳高成绩,单位厘米(cm)配对样本T检验:Analyze -Compare Means -Paried-sample T TestPaired Samples CorrelationsPaired Samples Test由配对样本相关性检验可知,两样本相关性的p=0.00<0.05,因此两者存在相关性,由配对样本T检验的数据分析可得,两组数据的p=0.006<0.05所以两者之间在0.05的差异水平上差异显著7、为了探讨不同教法对英语教学效果的影响,将一个班级随机分成3组,接受3种不同的教法,英语成绩见表5,试问不同的教法之间是否存在着差异。

SPSS软件课程考试题型:一、填空10分(每题1分,共10分)二、判断10分(每题1分,共10分)三、名词20分(每题2分,共20分)四、简答30分(每题5分,共6分,其中两个分析表格或图形)五、分析表格(每题15分,共30分)蓝色:为考点重要名词:1、5%修正均数剔除5%的最大与最小观测量后计算的均值。
2、四分位间距为了避免全距受两极端数值影响的缺点,按照一定顺序排列的一组数据中间部分50%的频数的差异作为反映数据的差异程度的指标,即四分位距,用QD表示。
3、三种T检验的分别得英文名称、One- Samples T Test Independent-Samples T Test Paired-Samples T Test4、交互作用当一个因素的主效应随另一个因素的变化而变化时,称两个因素间存在交互效应。
5、边际均值在多因素方差分析中,每种因素水平组合的因变量均值称为单元均值。
一个因素水平的因变量均值称为边际均值(Marginal Means)6、重复测量方差分析组内变异的主要的原因是实验对象之间的个体差异。
由于个体差异存在,即使实验对象受到相同的处理,他们的因变量值也可能相当不同。
重复测量设计的方差分析也是像协方差分析一样,是在研究中减少个体差异带来的误差方差的一种有效方法,而且由于对相同个体进行重复测量,在一定程度上降低了人力、物力、财力的消耗。
7、因素因素是影响因变量变化的客观条件8、处理、是影响因变量变化的人为条件。
也可通称为因素9、主效应因变量在一个因素各水平间的平均差异。
10、协方差分析利用线性回归方法消除混杂因素的影响过后进行的方差分析。
11、偏相关计算两个变量间在控制其他变量的影响下的相关系数。
12、距离相关对变量或观测量进行相似性或不相似性测度。
13、偏回归系数简称回归系数,表示其他自变量不变,xi每改变一个单位时,预测的y的平均变化量。
假设在其他所有自变量不变的情况下,某一个自变量变化引起因变量变化的比率。

1.用SPSS绘制饼图的时候为什么不能显示每一块所占的百分比呢?只有图形,看不到数字?答:双击输出的圆形图进入编辑状态,点击工具条上的条形状的工具。
圆形图中的数据或百分比就出现了,再利用编辑对话框的功能就可以改变文字或数字的大小、位置等。
2.spss多选项题变量如何设置?第一,多选项二分法;Q1 你经常使用的搜索引擎是哪几个?1 百度2 Google3 雅虎4 其他假设有5个被访者,分别选择了A 1B 1,2C 1,2,3D 2,3E 1,4一数据录入有两种录入法,分别是二分法和分类法。
1 二分法,数据结构如下二分法的特点是,题目有几个选项,SPSS数据文件中就有相应的几个变量以之对应。
选项选中为1,不选中为0(也可以自己定义)。
2 分类法,数据结构如下二多选题定义SPSS中处理多选题,其实有两个模块。
一个是在菜单Analyze -- Multiple Response –define sets中,这个地方定义的多选题是临时的,如果你关闭SPSS后再打开,多选题还得重新定义。
1 二分法:1)在菜单中打开定义多选题的对话框,然后把同一道题目的几个变量选中,点击向右的三角形将它们移动到"Variables in Set" 这个框中2)在Variable Coding里选中Dichotomies,即二分法3)在Category Label Source里选"Variable Labels"4)Set Name:填入多选题编号,Set Label:填入多选题的题干(或其他你觉得合适的标签)5)点击Add定义完后,可操作Analyze -- Multiple Response –frequencies,定义的多选变量只能频数统计(Analyze -- Multiple Response --frequencies)和交叉列表(Analyze -- Multiple Response - crosstabs)2.假设检验1. 单一样本t检验(One-sample t test),是用来比较一组数据的平均值和一个数值有无差异。

spss第二版习题及答案SPSS第二版习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学领域的数据分析和研究中。
对于学习SPSS的人来说,掌握习题并查看答案是提高技能的重要途径之一。
本文将为大家介绍一些SPSS第二版习题及其答案,希望能够帮助读者更好地理解和应用SPSS。
一、描述统计学习题1. 对于以下数据集,请计算平均数、中位数、众数、标准差和极差。
数据集:12,15,18,20,22,25,25,27,30,30答案:平均数:23.4,中位数:24,众数:25和30,标准差:6.89,极差:18 2. 对于以下数据集,请计算四分位数和箱线图。
数据集:10,12,15,18,20,22,25,25,27,30,30,32,35,40,45答案:第一四分位数(Q1):18.5,第二四分位数(Q2):25,第三四分位数(Q3):32.5,箱线图:参考附图1。
二、假设检验学习题1. 一个研究人员想要确定一种新的药物是否对治疗抑郁症有效。
他随机选择了100名患有抑郁症的患者,并将他们分为两组:实验组和对照组。
实验组接受新药物治疗,对照组接受安慰剂。
请使用SPSS进行假设检验,判断新药物是否显著改善了患者的抑郁症状。
答案:使用t检验进行假设检验。
设定零假设(H0):新药物对抑郁症状无显著改善;备择假设(H1):新药物对抑郁症状有显著改善。
根据样本数据计算得到t值和p值,如果p值小于设定的显著性水平(通常为0.05),则拒绝零假设,认为新药物对抑郁症状有显著改善。
三、相关性分析学习题1. 一个市场研究人员想要确定广告投入和销售额之间的相关性。
他收集了10个不同广告投入和销售额的数据。
请使用SPSS进行相关性分析,并解释结果。
答案:使用Pearson相关系数进行相关性分析。
根据样本数据计算得到相关系数r,r的取值范围为-1到1,如果r接近1,则表示广告投入和销售额之间存在正相关关系;如果r接近-1,则表示存在负相关关系;如果r接近0,则表示不存在线性相关关系。

SPSS测试题及答案一、单项选择题(每题2分,共10题)1. 在SPSS中,数据视图和变量视图分别对应于哪种视图?A. 表格视图和属性视图B. 表格视图和字段视图C. 数据视图和属性视图D. 数据视图和字段视图答案:C2. SPSS中,哪个命令用于描述性统计分析?A. DESCRIPTIVESB. FREQUENCIESC. CROSSTABSD. MEANS答案:A3. 在SPSS中,如何将数据文件保存为Excel格式?A. 通过“文件”菜单选择“导出数据”B. 通过“文件”菜单选择“另存为”C. 通过“编辑”菜单选择“复制”D. 通过“视图”菜单选择“导出数据”答案:A4. SPSS中,哪个命令用于执行相关性分析?A. CORRELATIONSB. REGRESSIONC. T-TESTD. ANOVA答案:A5. 在SPSS中,如何对数据进行排序?A. 通过“数据”菜单选择“排序案例”B. 通过“分析”菜单选择“排序案例”C. 通过“转换”菜单选择“排序案例”D. 通过“文件”菜单选择“排序案例”答案:A6. SPSS中,哪个命令用于执行因子分析?A. FACTORB. CLUSTERC. DISCRIMINANTD. MANOVA答案:A7. 在SPSS中,如何创建一个新的变量?A. 通过“数据”菜单选择“计算变量”B. 通过“分析”菜单选择“计算变量”C. 通过“转换”菜单选择“计算变量”D. 通过“文件”菜单选择“计算变量”答案:C8. SPSS中,哪个命令用于执行聚类分析?A. CLUSTERB. FACTORC. DISCRIMINANTD. MANOVA答案:A9. 在SPSS中,如何对数据进行分组?A. 通过“数据”菜单选择“分组案例”B. 通过“分析”菜单选择“分组案例”C. 通过“转换”菜单选择“分组案例”D. 通过“文件”菜单选择“分组案例”答案:C10. SPSS中,哪个命令用于执行方差分析?A. ANOVAB. T-TESTC. CORRELATIONSD. REGRESSION答案:A结束语:以上是SPSS测试题及答案,希望能够帮助您更好地掌握SPSS 软件的使用方法和技巧。

spss练习题(打印版)SPSS练习题一、选择题1. 在SPSS中,数据视图(Data View)显示的是:- A. 变量标签- B. 变量名- C. 观察值- D. 变量类型2. 以下哪个命令可以用来计算描述性统计量?- A. `DESCRIPTIVES`- B. `FREQUENCIES`- C. `CORRELATIONS`- D. `T-TEST`3. 如果你想要在SPSS中查看数据集的变量信息,你应该使用:- A. `DATASET`- B. `VARIABLE`- C. `VIEW`- D. `INFO`二、填空题1. 在SPSS中,使用________命令可以进行变量的转换和计算。
2. 当你想要对数据进行分组分析时,可以使用SPSS的________功能。
3. 为了在SPSS中创建一个新的数据集,可以使用________命令。
三、简答题1. 描述如何在SPSS中进行单样本t检验,并解释其应用场景。
2. 解释在SPSS中使用交叉表(Crosstabs)的目的,并说明如何解读交叉表的结果。
四、操作题1. 假设你有一个包含学生成绩的数据集,变量包括:学生ID(ID),姓名(Name),数学成绩(Math),英语成绩(English)。
请写出在SPSS中计算数学和英语成绩平均值的步骤。
2. 如果你想要在SPSS中删除一个名为“Math”的变量,应该如何操作?参考答案一、选择题1. D2. A3. C二、填空题1. `COMPUTE`2. `SPLIT FILE`3. `SAVE AS`三、简答题1. 在SPSS中进行单样本t检验的步骤如下:- 首先,确保你的数据已经正确输入到SPSS的数据视图中。
- 选择“分析”菜单下的“比较均值”选项。
- 选择“单样本t检验...”。
- 将需要检验的变量移动到“检验变量”框中。
- 在“测试值”框中输入你想要比较的均值。
- 点击“确定”进行检验。
单样本t检验通常用于检验单个样本的均值是否显著不同于已知的总体均值。

SPSS统计练习题及答案一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。

SPSS练习题1、现有两个SPSS数据文件,分别为“学生成绩一”和“学生成绩二”,请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
先排序data---sort cases再合并data---merge files2、有一份关于居民储蓄调查的数据存储在EXCEL中,请将该数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。
转换Data---transpose,输题目3、利用第2题的数据,将数据分成两份文件,其中第一份文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000-2000之间的调查数据,第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
选取数据data---select cases4、利用第2题数据,将其按常住地(升序)、收入水平(升序)存款金额(降序)进行多重排序。
排序data---sort cases一个一个选,加5、根据第1题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算transform---count按个输,把所有课程选取,define设区间,再排序6、根据第1题的完整数据,计算每个学生课程的平均分和标准差,同时计算男生和女生各科成绩的平均分。
描述性统计,先转换Data---transpose学号放下面,全部课程(poli到his)放上面,ok,analyze---descriptive statistics---descriptives,全选,options。
先拆分data---split file 按性别拆分,analyze---descriptive statistics---descriptives全选所有课程options---mean7、利用第2题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
数据分组Transform---recode---下面一个,输名字,change,old,range,new value---add 挨个输,从小加到大,等距8、在第2题的数据中,如果认为调查“今年的收入比去年增加”且“预计未来一两年收入仍会会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。

spss习题及其答案SPSS习题及其答案SPSS(Statistical Package for the Social Sciences)是一种广泛应用于社会科学研究领域的统计分析软件。
它提供了强大的数据处理和统计分析功能,使得研究人员能够更加准确地分析和解释数据。
在学习和使用SPSS的过程中,习题是一种非常有效的练习方式,能够帮助我们巩固所学知识并提高数据分析的能力。
下面将介绍几个常见的SPSS习题及其答案。
习题一:描述性统计分析某研究人员对一组学生的成绩进行了调查,并得到了以下数据:70、85、90、65、78、92、80、75、88、82。
请使用SPSS计算出这组数据的均值、标准差、最大值和最小值。
答案:打开SPSS软件,依次点击“数据”-“数据编辑器”,在变量视图中创建一个名为“成绩”的变量。
在数据视图中输入上述数据,然后点击“分析”-“描述性统计”-“描述性统计”。
将“成绩”变量移动到“变量”框中,点击“统计”按钮,在弹出的对话框中勾选“均值”、“标准差”、“最大值”和“最小值”,最后点击“确定”按钮。
SPSS将会输出这组数据的均值为80.7,标准差为8.77,最大值为92,最小值为65。
习题二:相关性分析某研究人员想要了解两个变量之间的相关性,他收集了一组学生的数学成绩和语文成绩数据。
请使用SPSS计算出这两个变量之间的相关系数。
答案:打开SPSS软件,依次点击“数据”-“数据编辑器”,在变量视图中创建两个变量分别为“数学成绩”和“语文成绩”。
在数据视图中输入相应的数据,然后点击“分析”-“相关”-“双变量”。
将“数学成绩”和“语文成绩”变量分别移动到“变量”框中,点击“确定”按钮。
SPSS将会输出这两个变量之间的相关系数,以及相关系数的显著性水平。
习题三:t检验某研究人员想要了解男性和女性在数学成绩上是否存在显著差异。
他收集了一组男性学生和一组女性学生的数学成绩数据。
请使用SPSS进行独立样本t检验。

SPSS 上机练习题1、为了解某幼儿园学生身高情况,随机抽取幼儿20名,测得体重(Kg )分别为:16、14、12、13、11、17、15、10、19、17、10、12、10、12、13、11、11、15、14、14。
请用SPSS 算出算术平均数、标准差、中位数。
2、随机抽取8名高血压病人,试用一种新降血压药,在用药前后分别测得舒张压(mmHg )如下表,请用SPSS 分析并指出该药是否有降压作用?编号1 2 3 4 5 6 7 8 用药前94 95 98 100 94 98 95 100 用药后 80 90 108 95 96 80 85 95 配对T3、随机抽取某幼儿园男生10名和女生8名,测得身高值(Cm )分别如下表。
请用SPSS 分析并回答该幼儿园男生与女生身高是否有差异? 两独立样本T 检验男生 95 95 98 100 96 98 95 100 90 98 女生8090989596808595Equalvariances assumed表示假设两个组方差相等的情况,Equal variance not assumed 表示两个组方差不等的情况。
判断步骤:先看F值对应的sig值是否小于0.05,如果大于0.05,则通过第一行的t值对应的sig值来判断数据直接是否存在显著差异;如果小于0.05,则通过第二行的t值对应的sig值来判断数据直接是否存在显著差异。
4、随机抽取某幼儿园5岁女生10名,测得体重(Kg)分别为:10、12、10、12、13、11、11、15、14、14。
请用SPSS分析并指出该幼儿园5岁女生与全国平均水平(12Kg)是否有差异?8、随机抽取医院新生儿体重10名,测得体重(Kg)分别为:3.5、2.5、3.3、3.6、4、2.8、3、3.2、3.7、2.9。
请用SPSS分析并指出该医院新生儿体重与全国平均水平(3Kg)是否有差异?方法:One-simple T5、某医师用甲乙两种药物治疗哮喘,疗效情况如下表,请用SPSS分析并指出甲乙两种药物疗效是否有差异?药物治疗人数有效人数甲药60 48乙药55 26卡方检验:四格表注意数据的建立6、某医师对90例矽肺病人均用X线和病理两种方法进行诊断,结果如下表,请用SPSS分析并指出两种诊断方法结果是否有差异?X线诊断病理诊断+ -+ 12 50- 30 8配对卡方检验35487、某高校学生近视眼发病程度与四种血型的抽样调查数据如下表,请通过SPSS分析,说明该高校学生四种血型之间近视眼发病程度是否有差异?A B AB O近视程度轻度12 5 15 35重度10 9 8 15多个构成比较的卡方检验9、随机抽取某幼儿园1班10名、2班8名及3班9名同学,测得身高值(Cm)分别如下表。

spss练习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学研究和数据分析领域。
本文将提供一些SPSS练习题和对应的答案,以帮助读者提升SPSS使用和数据分析能力。
题目1:数据导入与基本操作问题描述:使用SPSS软件,将一组身高数据导入并进行基本操作。
解答:1. 打开SPSS软件并创建一个新的数据文件。
2. 在数据编辑栏中创建一个名为"Height"的变量,并设置其数据类型为数值型。
3. 逐行输入以下身高数据:165、170、180、155、168、175、185、162。
4. 在数据编辑栏中创建一个名为"Gender"的变量,并设置其数据类型为标签型(男性、女性)。
5. 逐行输入以下性别数据:男性、女性、女性、男性、男性、女性、男性、女性。
6. 完成数据输入后,保存文件并命名为"Height_Data.sav"。
题目2:数据清理与缺失值处理问题描述:使用SPSS软件,清理一组包含缺失值的数据并进行处理。
解答:1. 打开SPSS软件,并导入包含缺失值的数据文件。
2. 在数据编辑栏中,检查数据是否存在缺失值,采用统计分析方法得到具体的缺失值情况。
3. 处理缺失值的方法之一是删除带有缺失值的行。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"删除缺少变量值",点击确定。
4. 另一种处理缺失值的方法是用合适的数据填充缺失位置。
在数据编辑栏中选择"数据",然后点击"选择特定行",在弹出窗口中选择"选中缺少变量值的行",点击确定。
然后选择"数据",再点击"修改变量",选择合适的填充方法(如平均值、中位数等),点击确定。

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。

spss练习题及答案SPSS练习题及答案SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计的软件工具。
它提供了丰富的功能和强大的统计算法,帮助研究者和数据分析师快速、准确地处理和分析大量数据。
为了帮助大家更好地掌握SPSS的使用技巧,下面将给出一些SPSS练习题及答案,供大家参考。
练习题一:描述性统计分析某公司对员工的工资进行了调查,收集了100位员工的薪资数据,请根据以下数据,使用SPSS进行描述性统计分析。
薪资数据:5000,5500,6000,6500,7000,7500,8000,8500,9000,9500,10000,10500,11000,11500,12000,12500,13000,13500,14000,14500,15000,15500,16000,16500,17000,17500,18000,18500,19000,19500,20000,20500,21000,21500,22000,22500,23000,23500,24000,24500,25000,25500,26000,26500,27000,27500,28000,28500,29000,29500,30000答案:1. 打开SPSS软件,新建数据集,将薪资数据输入到数据集中。
2. 在菜单栏选择"分析",然后选择"描述统计",再选择"频数"。
3. 将薪资数据变量拖动到"变量"框中,点击"统计"按钮,在弹出的对话框中勾选"平均值"、"中位数"、"标准差"、"最小值"、"最大值"等选项,点击"确定"。
4. 点击"图表"按钮,选择"直方图",点击"确定"。

江苏理工学院2017—2018学年第1学期《spss软件应用》上机操作题库1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果如下表。
问男女生在学业成绩上有无显著差异?中等以上中等以下男女性别* 学业成绩交叉制表计数学业成绩合计中等以上中等以下性别男23 17 40女38 22 60合计61 39 100根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。
2.为了研究两种教学方法的效果。
选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。
结果(测试分数)如下。
问:能否认为新教学方法优于原教学方法(采用非参数检验)?序号新教学方法原教学方法1 2 3 8369877865884 5 6 937859917259答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。
3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。
考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。
方法加盟时间分数方法加盟时间分数旧方法 1.5 9 新方法 2 12旧方法 2.5 10.5 新方法 4.5 14旧方法 5.5 13 新方法7 16旧方法 1 8 新方法0.5 9旧方法 4 11 新方法 4.5 12旧方法 5 9.5 新方法 4.5 10旧方法 3.5 10 新方法 2 10旧方法 4 12 新方法 5 14旧方法 4.5 12.5 新方法 6 16(1)分不同的培训方法计算加盟时间、评分增加量的平均数。
(2)分析两种培训方式的效果是否有差异?答:(1)所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556描述统计量所以旧方法的加盟时间平均数为3.5 分数增加量的平均数为10.6111(2)检验统计量b旧方法 - 新方法Z -2.530a渐近显著性(双侧) .011a. 基于正秩。

SPSS基础题训练及答案一.填空题1.SPSS软件有三种基本使用模式:全窗口菜单模式、程序操作模式和混合操作模式。
2.使用SPSS进行数据分析的基本步骤是建立SPSS数据文件,处理数据,进行统计分析,并解释分析结果。
3.spss数据编辑窗口中的一行成为一个case,一列成为一个variable。
4.spss中有3种基本的数据类型,分别为数值型,字符型,日期型。
bel表示变量名的标签。
6.values表示变量值的标签。
7.统计学根据数据的测量尺度将数据分为三类,即距离数据、类别数据和序列数据。
8.SPSS中变量名后的符号表示变量的数据类型为字符类型。
9.range(变量名,x1,x2)表示判断该变量是否在(x1,x2)之间。
10.任何(变量名x1,X2,?)指示是否判断变量在X1和x2中是否有任何值。
二.简答题1.简要说明数据分析过程中数据排序的目的答:1便于数据的浏览,有助于了解数据的取值状况,缺失值数量的多少,2.通过数据排序,可以快速找到数据的最大值和最小值,然后计算出数据的全距离,初步掌握和比较数据的分散程度。
3.通过数据排序能够快捷的发现数据的异常值,为了进一步明确他们是否会对分析产生重要影响进而提供帮助。
2.列出SPSS中计数间隔的几种描述形式答:单个变量值,系统缺失值,系统缺失值或用户缺失值,给定最大值和最小值区间,小于等于某个指定值的区间,大于等于某个指定值的区间3.列举spss提供的数据分组方法答:单变量分组,分组距离分组,分类号分组4.简述spss对数据进行统计分析刻画集中趋势的表述统计量以及刻画离散程度的描述统计量答:集中趋势的表达式统计:均值、中位数、模式、平均标准差、截断平均值、调和平均值和几何平均值。
离散程度的描述统计量:样本方差,样本标准差,全距,变异系数。
举例说明:算术均值=(x1+x2+x3+x4+………..+xn)/n5.简述条形图,饼图,直方图的特点及适用的情况答:条形图使用宽度相等的直条长度来表示数值,用于分类数据的图表显示。

spss练习题及解答第2题-----会做:请把下面的频数表资料录入到SPSS 数据库中,并划出直方图,同时计算均数和标准差。
112~114~116~118~ 15120~ 18122~ 1124~ 14126~ 10128~130~132~134~13 1解答:1、输入中位数:111,113,115,117,....135;和频数1,3,. (1)2、对频数进行加权:DATA━Weigh Cases━Weigh Cases by━频数━OK3、Analyze━Descriptive Statistics━Frequences━将组中值加入Variable框━点击Statistics按钮━选中Mean和Std.devision━Continue━点击Charts按钮━选中HIstograms━Continue━OK第3题—会做:某医生收集了81例30-49岁健康男子血清中的总胆固醇值测定结果如下,试编制频数分布表,并计算这81名男性血清胆固醇含量的样本均数。
219.184.0 130.037.0 152.137.163.166.181.7176.0 168.208.043.101.078.214.0 131.201.0199.922.184.197.200.197.0 181.183.1 135.2169.0 188.641.205.133.178.139.131.171.0155.225.137.129.157.188.104.191.109.7199.1 196.226.185.006.163.166.184.045.6188.214.97.175.129.188.0 160.925.199.2174.168.166.176.220.252.183.177.160.8117.159.251.181.1 164.0 153.246.196.155.4 解答:1、输入数据:单列,81行。
2、A nalyze━Descriptive Statistics━Frequences━将变量值加入Variable框━点击Statistics按钮━选中Mean━Continue━点击OK实习二定量资料的统计分析第1题--会做:从某单位1999年的职工体检资料中获得101名正常成年女子的血清总胆固醇的测量结果如下,试对其进行正态性检验。
SPSS练习题1、现有两个SPSS数据文件,分别为“学生成绩一”和“学生成绩二”,请将这两份数据文件以学号为关键变量进行横向合并,形成一个完整的数据文件。
先排序data---sort cases再合并data---merge files2、有一份关于居民储蓄调查的数据存储在EXCEL中,请将该数据转换成SPSS数据文件,并在SPSS中指定其变量名标签和变量值标签。
转换Data---transpose,输题目3、利用第2题的数据,将数据分成两份文件,其中第一份文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000-2000之间的调查数据,第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
选取数据data---select cases4、利用第2题数据,将其按常住地(升序)、收入水平(升序)存款金额(降序)进行多重排序。
排序data---sort cases一个一个选,加5、根据第1题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算transform---count按个输,把所有课程选取,define设区间,再排序6、根据第1题的完整数据,计算每个学生课程的平均分和标准差,同时计算男生和女生各科成绩的平均分。
描述性统计,先转换Data---transpose学号放下面,全部课程(poli到his)放上面,ok,analyze---descriptive statistics---descriptives,全选,options。
先拆分data---split file 按性别拆分,analyze---descriptive statistics---descriptives全选所有课程options---mean7、利用第2题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
数据分组Transform---recode---下面一个,输名字,change,old,range,new value---add 挨个输,从小加到大,等距8、在第2题的数据中,如果认为调查“今年的收入比去年增加”且“预计未来一两年收入仍会会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。
(计算transform---count或)选取data---select cases9、利用第2题数据,采用频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
Analyze--- descriptive statistics---frequencies10、利用第2题数据,从数据的集中趋势、离散程度和分布形状等角度,分析被调查者本次存款金额的基本特征,并与标准分布曲线进行对比,进一步,对不同常住地住房存款金额的基本特征进行对比分析。
An DS d Analyze---Descriptive Statistics---Descriptives,选择存款金额到Variable(s)中。
按Option,然后选择Mean,std.deviation,Minlmum,Variance,Maximum,Range,Kutosis,Skewness,Variablelist.然后按continue,ok11、将第1题的数据看作来自总体的样本,试分析男生和女生的课程平均分是否存在显著差异;试分析哪些课程的平均差异不显著。
Transform compute课程平均分=mean() analyze->compare means->independent-samples T;选择若干变量作为检验变量到test variables框(课程平均分);选择代表不同总体的变量(sex)作为分组变量到grouping variable框;.定义分组变量的分组情况Define Groups...:(填1,2)。
1.两总体方差是否相等F检验:F的统计量的观察值为0.257,对应的P值为0.614,;如果显著性水平为0.05,由于概率P值大于0.05,两种方式的方差无显著差异.看eaual variances assumend。
2.两总体均值的检验:.T统计量的观测值为-0.573,对应的双尾概率为0.569,T的P值>显著水平0.05,故不能推翻原假设,所以女生男生的课程平均分无显著差异。
配对差异:analyze->compare means->paired-samples T…paired variables框中每科与不同科目配对很麻烦略12、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75,现从雇员中随机随出11人参加考试,得分如下:80、81、72、60、78、65、56、79、77、87、76,请问该经理的宣称是否可信?步骤:采用单样本T检验(原假设H0:u=u0,总体均值与检验值之间不存在显著差异.);菜单选项:Analyze->compare means->one-samples T test;指定检验值:在test后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean)为73.7,标准差(std.deviation)为9.55,均值标准误差(std error mean)为2.87.t 统计量观测值为-4.22,t统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14),由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值(sig.(2-tailed))为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14),所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
13、利用促销方式数据,试分析这三种推销方式是否存在显著差异,绘制各组均值的对比图,并利用LSD方法进行多重比较检验。
单因素方差分析对比图为options中的descriptivesLSD为post…中的P值大于a接受所以无关14、已知240例心肌梗塞患者治疗后24小时内的死亡情况如表1所示,问两组病死亡率相差是否显著?(example1.sav)(显著性水平为5%)表1:急性心肌梗塞患者治疗后24小时生死情况·提出假设:H0:是否接受治疗的急性心肌梗塞患者的病死率相差不显著H1:是否接受治疗的急性心肌梗塞患者的病死率相差显著·操作步骤:1、打开数据文件:file-open-data-example1.sav2、对count变量进行weight cases处理:data-weight cases选中weight cases by;在Frequencies variable中加入变量count。
3、对数据进行交叉汇总,如得出的下列频次交叉表,如图表3-1:用descriptive-cross tab过程,column填status, row填group。
在cell选项中,选中percentages,以计算频数百分比。
·统计表格及分析:表3-1 是否接受治疗与生存状况的相关性检验成果表(Chi-Square Tests)表3-1是相关性卡方检验成果表。
表中依次列出了Pearson卡方系数、线性相关的值(Value)、自由度(df)和双尾检验的显著水平(Asymp. Sig. (2-sided))。
表3-2显示了根据是否使用单参注射液对急性心肌梗塞患者进行分组后,患者的生存和死亡状况频数和所占总数的百分比。
表3-2 急性心肌梗塞患者是否治疗与生死情况的列联表状况(status) 总数生存死亡分组(group)) 用单参注射液Count 185 10 195% within 分组(group) 94.9% 5.1% 100.0% 未用单参注射液Count 38 7 45% within ·分组(group) 84.4% 15.6% 100.0%总数Count 223 17 240% within ·分组(group) 92.9% 7.1% 100.0% ·结论:根据表3-1可以看出,双侧检验的显著性概论为0.014,小于显著性水平0.05;因此否定原假设,接受备择假设,即两组患者的完全缓解率之间差别显著。
15、已知数据如表2所示,比较单用甘磷酰芥(单纯化疗组)与复合使用光霉素、环磷酰胺等药(复合化疗组)对淋巴系统肿瘤的疗效,问两组患者的完全缓解率之间有无差别?(example2.sav)(显著性水平为5%)表2:两化疗组的缓解率比较同上小于拒绝显著16、已知数据如表3所示,问我国南北方鼻咽癌患者(按籍贯分)的病理组织学分类的构成比有无差别?(example3.sav)(显著性水平为5%)同上小于拒绝显著表3:我国南北方鼻咽癌患者病理组织学分类构成17、已知97名被调查儿童体检数据文件为child.sav,请分别计算男性、女性与两性合计的儿童的平均身高与体重、中位身高与体重以及身高与体重的标准差。
1、打开数据文件:file-open-data-child.sav2、均值比较与检验:Analyze-Compare means-means3、在independent Var. 中选性别,dependent Var. 中选体重和身高4、在option子框中选择median/mean/Std. Deviation1、男性儿童的平均身高为109.962厘米;平均体重为18.202千克;中位身高为109.10厘米;中位体重为17.50千克;身高的标准差为6.084厘米;体重的标准差为2.786千克。
2、女性儿童的平均身高为109.896厘米;平均体重为18.389千克;中位身高为109.450厘米;中位体重为17.750千克;身高的标准差为5.770厘米;体重的标准差为3.235千克。
3、两性儿童的平均身高为109.930厘米;平均体重为18.292千克;中位身高为109.250厘米;中位体重为17.605千克;身高的标准差为5.905厘米;体重的标准差为2.995千克。
18、已知97名被调查儿童体检数据文件为child.sav,请问儿童的身高与体重是否分别受到性别与年龄的影响?(显著性水平为5%)·提出假设:1、H0:身高与体重受到年龄的影响不显著H1:身高与体重受到年龄的影响显著2、H0:身高与体重受到性别的影响不显著H1:身高与体重受到性别的影响显著·操作步骤:1、打开数据文件:file-open-data-child.sav2、均值比较与检验:analysis-compare means-means3、在independent Var. 中选性别和年龄,dependent Var. 中选体重和身高4、在option子框中选择median/mean/ Std. Deviation在statistic for first layer 区域内勾上ANOVA table and eta复选框·统计表格及分析:表7-1 体重、身高与年龄的方差分析表在表7-1中,分别列出了平方和(Sum of Squares)、自由度(df)、均方差(Mean Square)、F值以及F值的显著性水平(Sig.)。