Towards robust multi-cue integration for visual tracking
- 格式:pdf
- 大小:250.33 KB
- 文档页数:14

机器学习与人工智能领域中常用的英语词汇1.General Concepts (基础概念)•Artificial Intelligence (AI) - 人工智能1)Artificial Intelligence (AI) - 人工智能2)Machine Learning (ML) - 机器学习3)Deep Learning (DL) - 深度学习4)Neural Network - 神经网络5)Natural Language Processing (NLP) - 自然语言处理6)Computer Vision - 计算机视觉7)Robotics - 机器人技术8)Speech Recognition - 语音识别9)Expert Systems - 专家系统10)Knowledge Representation - 知识表示11)Pattern Recognition - 模式识别12)Cognitive Computing - 认知计算13)Autonomous Systems - 自主系统14)Human-Machine Interaction - 人机交互15)Intelligent Agents - 智能代理16)Machine Translation - 机器翻译17)Swarm Intelligence - 群体智能18)Genetic Algorithms - 遗传算法19)Fuzzy Logic - 模糊逻辑20)Reinforcement Learning - 强化学习•Machine Learning (ML) - 机器学习1)Machine Learning (ML) - 机器学习2)Artificial Neural Network - 人工神经网络3)Deep Learning - 深度学习4)Supervised Learning - 有监督学习5)Unsupervised Learning - 无监督学习6)Reinforcement Learning - 强化学习7)Semi-Supervised Learning - 半监督学习8)Training Data - 训练数据9)Test Data - 测试数据10)Validation Data - 验证数据11)Feature - 特征12)Label - 标签13)Model - 模型14)Algorithm - 算法15)Regression - 回归16)Classification - 分类17)Clustering - 聚类18)Dimensionality Reduction - 降维19)Overfitting - 过拟合20)Underfitting - 欠拟合•Deep Learning (DL) - 深度学习1)Deep Learning - 深度学习2)Neural Network - 神经网络3)Artificial Neural Network (ANN) - 人工神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Autoencoder - 自编码器9)Generative Adversarial Network (GAN) - 生成对抗网络10)Transfer Learning - 迁移学习11)Pre-trained Model - 预训练模型12)Fine-tuning - 微调13)Feature Extraction - 特征提取14)Activation Function - 激活函数15)Loss Function - 损失函数16)Gradient Descent - 梯度下降17)Backpropagation - 反向传播18)Epoch - 训练周期19)Batch Size - 批量大小20)Dropout - 丢弃法•Neural Network - 神经网络1)Neural Network - 神经网络2)Artificial Neural Network (ANN) - 人工神经网络3)Deep Neural Network (DNN) - 深度神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Feedforward Neural Network - 前馈神经网络9)Multi-layer Perceptron (MLP) - 多层感知器10)Radial Basis Function Network (RBFN) - 径向基函数网络11)Hopfield Network - 霍普菲尔德网络12)Boltzmann Machine - 玻尔兹曼机13)Autoencoder - 自编码器14)Spiking Neural Network (SNN) - 脉冲神经网络15)Self-organizing Map (SOM) - 自组织映射16)Restricted Boltzmann Machine (RBM) - 受限玻尔兹曼机17)Hebbian Learning - 海比安学习18)Competitive Learning - 竞争学习19)Neuroevolutionary - 神经进化20)Neuron - 神经元•Algorithm - 算法1)Algorithm - 算法2)Supervised Learning Algorithm - 有监督学习算法3)Unsupervised Learning Algorithm - 无监督学习算法4)Reinforcement Learning Algorithm - 强化学习算法5)Classification Algorithm - 分类算法6)Regression Algorithm - 回归算法7)Clustering Algorithm - 聚类算法8)Dimensionality Reduction Algorithm - 降维算法9)Decision Tree Algorithm - 决策树算法10)Random Forest Algorithm - 随机森林算法11)Support Vector Machine (SVM) Algorithm - 支持向量机算法12)K-Nearest Neighbors (KNN) Algorithm - K近邻算法13)Naive Bayes Algorithm - 朴素贝叶斯算法14)Gradient Descent Algorithm - 梯度下降算法15)Genetic Algorithm - 遗传算法16)Neural Network Algorithm - 神经网络算法17)Deep Learning Algorithm - 深度学习算法18)Ensemble Learning Algorithm - 集成学习算法19)Reinforcement Learning Algorithm - 强化学习算法20)Metaheuristic Algorithm - 元启发式算法•Model - 模型1)Model - 模型2)Machine Learning Model - 机器学习模型3)Artificial Intelligence Model - 人工智能模型4)Predictive Model - 预测模型5)Classification Model - 分类模型6)Regression Model - 回归模型7)Generative Model - 生成模型8)Discriminative Model - 判别模型9)Probabilistic Model - 概率模型10)Statistical Model - 统计模型11)Neural Network Model - 神经网络模型12)Deep Learning Model - 深度学习模型13)Ensemble Model - 集成模型14)Reinforcement Learning Model - 强化学习模型15)Support Vector Machine (SVM) Model - 支持向量机模型16)Decision Tree Model - 决策树模型17)Random Forest Model - 随机森林模型18)Naive Bayes Model - 朴素贝叶斯模型19)Autoencoder Model - 自编码器模型20)Convolutional Neural Network (CNN) Model - 卷积神经网络模型•Dataset - 数据集1)Dataset - 数据集2)Training Dataset - 训练数据集3)Test Dataset - 测试数据集4)Validation Dataset - 验证数据集5)Balanced Dataset - 平衡数据集6)Imbalanced Dataset - 不平衡数据集7)Synthetic Dataset - 合成数据集8)Benchmark Dataset - 基准数据集9)Open Dataset - 开放数据集10)Labeled Dataset - 标记数据集11)Unlabeled Dataset - 未标记数据集12)Semi-Supervised Dataset - 半监督数据集13)Multiclass Dataset - 多分类数据集14)Feature Set - 特征集15)Data Augmentation - 数据增强16)Data Preprocessing - 数据预处理17)Missing Data - 缺失数据18)Outlier Detection - 异常值检测19)Data Imputation - 数据插补20)Metadata - 元数据•Training - 训练1)Training - 训练2)Training Data - 训练数据3)Training Phase - 训练阶段4)Training Set - 训练集5)Training Examples - 训练样本6)Training Instance - 训练实例7)Training Algorithm - 训练算法8)Training Model - 训练模型9)Training Process - 训练过程10)Training Loss - 训练损失11)Training Epoch - 训练周期12)Training Batch - 训练批次13)Online Training - 在线训练14)Offline Training - 离线训练15)Continuous Training - 连续训练16)Transfer Learning - 迁移学习17)Fine-Tuning - 微调18)Curriculum Learning - 课程学习19)Self-Supervised Learning - 自监督学习20)Active Learning - 主动学习•Testing - 测试1)Testing - 测试2)Test Data - 测试数据3)Test Set - 测试集4)Test Examples - 测试样本5)Test Instance - 测试实例6)Test Phase - 测试阶段7)Test Accuracy - 测试准确率8)Test Loss - 测试损失9)Test Error - 测试错误10)Test Metrics - 测试指标11)Test Suite - 测试套件12)Test Case - 测试用例13)Test Coverage - 测试覆盖率14)Cross-Validation - 交叉验证15)Holdout Validation - 留出验证16)K-Fold Cross-Validation - K折交叉验证17)Stratified Cross-Validation - 分层交叉验证18)Test Driven Development (TDD) - 测试驱动开发19)A/B Testing - A/B 测试20)Model Evaluation - 模型评估•Validation - 验证1)Validation - 验证2)Validation Data - 验证数据3)Validation Set - 验证集4)Validation Examples - 验证样本5)Validation Instance - 验证实例6)Validation Phase - 验证阶段7)Validation Accuracy - 验证准确率8)Validation Loss - 验证损失9)Validation Error - 验证错误10)Validation Metrics - 验证指标11)Cross-Validation - 交叉验证12)Holdout Validation - 留出验证13)K-Fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation - 留一法交叉验证16)Validation Curve - 验证曲线17)Hyperparameter Validation - 超参数验证18)Model Validation - 模型验证19)Early Stopping - 提前停止20)Validation Strategy - 验证策略•Supervised Learning - 有监督学习1)Supervised Learning - 有监督学习2)Label - 标签3)Feature - 特征4)Target - 目标5)Training Labels - 训练标签6)Training Features - 训练特征7)Training Targets - 训练目标8)Training Examples - 训练样本9)Training Instance - 训练实例10)Regression - 回归11)Classification - 分类12)Predictor - 预测器13)Regression Model - 回归模型14)Classifier - 分类器15)Decision Tree - 决策树16)Support Vector Machine (SVM) - 支持向量机17)Neural Network - 神经网络18)Feature Engineering - 特征工程19)Model Evaluation - 模型评估20)Overfitting - 过拟合21)Underfitting - 欠拟合22)Bias-Variance Tradeoff - 偏差-方差权衡•Unsupervised Learning - 无监督学习1)Unsupervised Learning - 无监督学习2)Clustering - 聚类3)Dimensionality Reduction - 降维4)Anomaly Detection - 异常检测5)Association Rule Learning - 关联规则学习6)Feature Extraction - 特征提取7)Feature Selection - 特征选择8)K-Means - K均值9)Hierarchical Clustering - 层次聚类10)Density-Based Clustering - 基于密度的聚类11)Principal Component Analysis (PCA) - 主成分分析12)Independent Component Analysis (ICA) - 独立成分分析13)T-distributed Stochastic Neighbor Embedding (t-SNE) - t分布随机邻居嵌入14)Gaussian Mixture Model (GMM) - 高斯混合模型15)Self-Organizing Maps (SOM) - 自组织映射16)Autoencoder - 自动编码器17)Latent Variable - 潜变量18)Data Preprocessing - 数据预处理19)Outlier Detection - 异常值检测20)Clustering Algorithm - 聚类算法•Reinforcement Learning - 强化学习1)Reinforcement Learning - 强化学习2)Agent - 代理3)Environment - 环境4)State - 状态5)Action - 动作6)Reward - 奖励7)Policy - 策略8)Value Function - 值函数9)Q-Learning - Q学习10)Deep Q-Network (DQN) - 深度Q网络11)Policy Gradient - 策略梯度12)Actor-Critic - 演员-评论家13)Exploration - 探索14)Exploitation - 开发15)Temporal Difference (TD) - 时间差分16)Markov Decision Process (MDP) - 马尔可夫决策过程17)State-Action-Reward-State-Action (SARSA) - 状态-动作-奖励-状态-动作18)Policy Iteration - 策略迭代19)Value Iteration - 值迭代20)Monte Carlo Methods - 蒙特卡洛方法•Semi-Supervised Learning - 半监督学习1)Semi-Supervised Learning - 半监督学习2)Labeled Data - 有标签数据3)Unlabeled Data - 无标签数据4)Label Propagation - 标签传播5)Self-Training - 自训练6)Co-Training - 协同训练7)Transudative Learning - 传导学习8)Inductive Learning - 归纳学习9)Manifold Regularization - 流形正则化10)Graph-based Methods - 基于图的方法11)Cluster Assumption - 聚类假设12)Low-Density Separation - 低密度分离13)Semi-Supervised Support Vector Machines (S3VM) - 半监督支持向量机14)Expectation-Maximization (EM) - 期望最大化15)Co-EM - 协同期望最大化16)Entropy-Regularized EM - 熵正则化EM17)Mean Teacher - 平均教师18)Virtual Adversarial Training - 虚拟对抗训练19)Tri-training - 三重训练20)Mix Match - 混合匹配•Feature - 特征1)Feature - 特征2)Feature Engineering - 特征工程3)Feature Extraction - 特征提取4)Feature Selection - 特征选择5)Input Features - 输入特征6)Output Features - 输出特征7)Feature Vector - 特征向量8)Feature Space - 特征空间9)Feature Representation - 特征表示10)Feature Transformation - 特征转换11)Feature Importance - 特征重要性12)Feature Scaling - 特征缩放13)Feature Normalization - 特征归一化14)Feature Encoding - 特征编码15)Feature Fusion - 特征融合16)Feature Dimensionality Reduction - 特征维度减少17)Continuous Feature - 连续特征18)Categorical Feature - 分类特征19)Nominal Feature - 名义特征20)Ordinal Feature - 有序特征•Label - 标签1)Label - 标签2)Labeling - 标注3)Ground Truth - 地面真值4)Class Label - 类别标签5)Target Variable - 目标变量6)Labeling Scheme - 标注方案7)Multi-class Labeling - 多类别标注8)Binary Labeling - 二分类标注9)Label Noise - 标签噪声10)Labeling Error - 标注错误11)Label Propagation - 标签传播12)Unlabeled Data - 无标签数据13)Labeled Data - 有标签数据14)Semi-supervised Learning - 半监督学习15)Active Learning - 主动学习16)Weakly Supervised Learning - 弱监督学习17)Noisy Label Learning - 噪声标签学习18)Self-training - 自训练19)Crowdsourcing Labeling - 众包标注20)Label Smoothing - 标签平滑化•Prediction - 预测1)Prediction - 预测2)Forecasting - 预测3)Regression - 回归4)Classification - 分类5)Time Series Prediction - 时间序列预测6)Forecast Accuracy - 预测准确性7)Predictive Modeling - 预测建模8)Predictive Analytics - 预测分析9)Forecasting Method - 预测方法10)Predictive Performance - 预测性能11)Predictive Power - 预测能力12)Prediction Error - 预测误差13)Prediction Interval - 预测区间14)Prediction Model - 预测模型15)Predictive Uncertainty - 预测不确定性16)Forecast Horizon - 预测时间跨度17)Predictive Maintenance - 预测性维护18)Predictive Policing - 预测式警务19)Predictive Healthcare - 预测性医疗20)Predictive Maintenance - 预测性维护•Classification - 分类1)Classification - 分类2)Classifier - 分类器3)Class - 类别4)Classify - 对数据进行分类5)Class Label - 类别标签6)Binary Classification - 二元分类7)Multiclass Classification - 多类分类8)Class Probability - 类别概率9)Decision Boundary - 决策边界10)Decision Tree - 决策树11)Support Vector Machine (SVM) - 支持向量机12)K-Nearest Neighbors (KNN) - K最近邻算法13)Naive Bayes - 朴素贝叶斯14)Logistic Regression - 逻辑回归15)Random Forest - 随机森林16)Neural Network - 神经网络17)SoftMax Function - SoftMax函数18)One-vs-All (One-vs-Rest) - 一对多(一对剩余)19)Ensemble Learning - 集成学习20)Confusion Matrix - 混淆矩阵•Regression - 回归1)Regression Analysis - 回归分析2)Linear Regression - 线性回归3)Multiple Regression - 多元回归4)Polynomial Regression - 多项式回归5)Logistic Regression - 逻辑回归6)Ridge Regression - 岭回归7)Lasso Regression - Lasso回归8)Elastic Net Regression - 弹性网络回归9)Regression Coefficients - 回归系数10)Residuals - 残差11)Ordinary Least Squares (OLS) - 普通最小二乘法12)Ridge Regression Coefficient - 岭回归系数13)Lasso Regression Coefficient - Lasso回归系数14)Elastic Net Regression Coefficient - 弹性网络回归系数15)Regression Line - 回归线16)Prediction Error - 预测误差17)Regression Model - 回归模型18)Nonlinear Regression - 非线性回归19)Generalized Linear Models (GLM) - 广义线性模型20)Coefficient of Determination (R-squared) - 决定系数21)F-test - F检验22)Homoscedasticity - 同方差性23)Heteroscedasticity - 异方差性24)Autocorrelation - 自相关25)Multicollinearity - 多重共线性26)Outliers - 异常值27)Cross-validation - 交叉验证28)Feature Selection - 特征选择29)Feature Engineering - 特征工程30)Regularization - 正则化2.Neural Networks and Deep Learning (神经网络与深度学习)•Convolutional Neural Network (CNN) - 卷积神经网络1)Convolutional Neural Network (CNN) - 卷积神经网络2)Convolution Layer - 卷积层3)Feature Map - 特征图4)Convolution Operation - 卷积操作5)Stride - 步幅6)Padding - 填充7)Pooling Layer - 池化层8)Max Pooling - 最大池化9)Average Pooling - 平均池化10)Fully Connected Layer - 全连接层11)Activation Function - 激活函数12)Rectified Linear Unit (ReLU) - 线性修正单元13)Dropout - 随机失活14)Batch Normalization - 批量归一化15)Transfer Learning - 迁移学习16)Fine-Tuning - 微调17)Image Classification - 图像分类18)Object Detection - 物体检测19)Semantic Segmentation - 语义分割20)Instance Segmentation - 实例分割21)Generative Adversarial Network (GAN) - 生成对抗网络22)Image Generation - 图像生成23)Style Transfer - 风格迁移24)Convolutional Autoencoder - 卷积自编码器25)Recurrent Neural Network (RNN) - 循环神经网络•Recurrent Neural Network (RNN) - 循环神经网络1)Recurrent Neural Network (RNN) - 循环神经网络2)Long Short-Term Memory (LSTM) - 长短期记忆网络3)Gated Recurrent Unit (GRU) - 门控循环单元4)Sequence Modeling - 序列建模5)Time Series Prediction - 时间序列预测6)Natural Language Processing (NLP) - 自然语言处理7)Text Generation - 文本生成8)Sentiment Analysis - 情感分析9)Named Entity Recognition (NER) - 命名实体识别10)Part-of-Speech Tagging (POS Tagging) - 词性标注11)Sequence-to-Sequence (Seq2Seq) - 序列到序列12)Attention Mechanism - 注意力机制13)Encoder-Decoder Architecture - 编码器-解码器架构14)Bidirectional RNN - 双向循环神经网络15)Teacher Forcing - 强制教师法16)Backpropagation Through Time (BPTT) - 通过时间的反向传播17)Vanishing Gradient Problem - 梯度消失问题18)Exploding Gradient Problem - 梯度爆炸问题19)Language Modeling - 语言建模20)Speech Recognition - 语音识别•Long Short-Term Memory (LSTM) - 长短期记忆网络1)Long Short-Term Memory (LSTM) - 长短期记忆网络2)Cell State - 细胞状态3)Hidden State - 隐藏状态4)Forget Gate - 遗忘门5)Input Gate - 输入门6)Output Gate - 输出门7)Peephole Connections - 窥视孔连接8)Gated Recurrent Unit (GRU) - 门控循环单元9)Vanishing Gradient Problem - 梯度消失问题10)Exploding Gradient Problem - 梯度爆炸问题11)Sequence Modeling - 序列建模12)Time Series Prediction - 时间序列预测13)Natural Language Processing (NLP) - 自然语言处理14)Text Generation - 文本生成15)Sentiment Analysis - 情感分析16)Named Entity Recognition (NER) - 命名实体识别17)Part-of-Speech Tagging (POS Tagging) - 词性标注18)Attention Mechanism - 注意力机制19)Encoder-Decoder Architecture - 编码器-解码器架构20)Bidirectional LSTM - 双向长短期记忆网络•Attention Mechanism - 注意力机制1)Attention Mechanism - 注意力机制2)Self-Attention - 自注意力3)Multi-Head Attention - 多头注意力4)Transformer - 变换器5)Query - 查询6)Key - 键7)Value - 值8)Query-Value Attention - 查询-值注意力9)Dot-Product Attention - 点积注意力10)Scaled Dot-Product Attention - 缩放点积注意力11)Additive Attention - 加性注意力12)Context Vector - 上下文向量13)Attention Score - 注意力分数14)SoftMax Function - SoftMax函数15)Attention Weight - 注意力权重16)Global Attention - 全局注意力17)Local Attention - 局部注意力18)Positional Encoding - 位置编码19)Encoder-Decoder Attention - 编码器-解码器注意力20)Cross-Modal Attention - 跨模态注意力•Generative Adversarial Network (GAN) - 生成对抗网络1)Generative Adversarial Network (GAN) - 生成对抗网络2)Generator - 生成器3)Discriminator - 判别器4)Adversarial Training - 对抗训练5)Minimax Game - 极小极大博弈6)Nash Equilibrium - 纳什均衡7)Mode Collapse - 模式崩溃8)Training Stability - 训练稳定性9)Loss Function - 损失函数10)Discriminative Loss - 判别损失11)Generative Loss - 生成损失12)Wasserstein GAN (WGAN) - Wasserstein GAN(WGAN)13)Deep Convolutional GAN (DCGAN) - 深度卷积生成对抗网络(DCGAN)14)Conditional GAN (c GAN) - 条件生成对抗网络(c GAN)15)Style GAN - 风格生成对抗网络16)Cycle GAN - 循环生成对抗网络17)Progressive Growing GAN (PGGAN) - 渐进式增长生成对抗网络(PGGAN)18)Self-Attention GAN (SAGAN) - 自注意力生成对抗网络(SAGAN)19)Big GAN - 大规模生成对抗网络20)Adversarial Examples - 对抗样本•Encoder-Decoder - 编码器-解码器1)Encoder-Decoder Architecture - 编码器-解码器架构2)Encoder - 编码器3)Decoder - 解码器4)Sequence-to-Sequence Model (Seq2Seq) - 序列到序列模型5)State Vector - 状态向量6)Context Vector - 上下文向量7)Hidden State - 隐藏状态8)Attention Mechanism - 注意力机制9)Teacher Forcing - 强制教师法10)Beam Search - 束搜索11)Recurrent Neural Network (RNN) - 循环神经网络12)Long Short-Term Memory (LSTM) - 长短期记忆网络13)Gated Recurrent Unit (GRU) - 门控循环单元14)Bidirectional Encoder - 双向编码器15)Greedy Decoding - 贪婪解码16)Masking - 遮盖17)Dropout - 随机失活18)Embedding Layer - 嵌入层19)Cross-Entropy Loss - 交叉熵损失20)Tokenization - 令牌化•Transfer Learning - 迁移学习1)Transfer Learning - 迁移学习2)Source Domain - 源领域3)Target Domain - 目标领域4)Fine-Tuning - 微调5)Domain Adaptation - 领域自适应6)Pre-Trained Model - 预训练模型7)Feature Extraction - 特征提取8)Knowledge Transfer - 知识迁移9)Unsupervised Domain Adaptation - 无监督领域自适应10)Semi-Supervised Domain Adaptation - 半监督领域自适应11)Multi-Task Learning - 多任务学习12)Data Augmentation - 数据增强13)Task Transfer - 任务迁移14)Model Agnostic Meta-Learning (MAML) - 与模型无关的元学习(MAML)15)One-Shot Learning - 单样本学习16)Zero-Shot Learning - 零样本学习17)Few-Shot Learning - 少样本学习18)Knowledge Distillation - 知识蒸馏19)Representation Learning - 表征学习20)Adversarial Transfer Learning - 对抗迁移学习•Pre-trained Models - 预训练模型1)Pre-trained Model - 预训练模型2)Transfer Learning - 迁移学习3)Fine-Tuning - 微调4)Knowledge Transfer - 知识迁移5)Domain Adaptation - 领域自适应6)Feature Extraction - 特征提取7)Representation Learning - 表征学习8)Language Model - 语言模型9)Bidirectional Encoder Representations from Transformers (BERT) - 双向编码器结构转换器10)Generative Pre-trained Transformer (GPT) - 生成式预训练转换器11)Transformer-based Models - 基于转换器的模型12)Masked Language Model (MLM) - 掩蔽语言模型13)Cloze Task - 填空任务14)Tokenization - 令牌化15)Word Embeddings - 词嵌入16)Sentence Embeddings - 句子嵌入17)Contextual Embeddings - 上下文嵌入18)Self-Supervised Learning - 自监督学习19)Large-Scale Pre-trained Models - 大规模预训练模型•Loss Function - 损失函数1)Loss Function - 损失函数2)Mean Squared Error (MSE) - 均方误差3)Mean Absolute Error (MAE) - 平均绝对误差4)Cross-Entropy Loss - 交叉熵损失5)Binary Cross-Entropy Loss - 二元交叉熵损失6)Categorical Cross-Entropy Loss - 分类交叉熵损失7)Hinge Loss - 合页损失8)Huber Loss - Huber损失9)Wasserstein Distance - Wasserstein距离10)Triplet Loss - 三元组损失11)Contrastive Loss - 对比损失12)Dice Loss - Dice损失13)Focal Loss - 焦点损失14)GAN Loss - GAN损失15)Adversarial Loss - 对抗损失16)L1 Loss - L1损失17)L2 Loss - L2损失18)Huber Loss - Huber损失19)Quantile Loss - 分位数损失•Activation Function - 激活函数1)Activation Function - 激活函数2)Sigmoid Function - Sigmoid函数3)Hyperbolic Tangent Function (Tanh) - 双曲正切函数4)Rectified Linear Unit (Re LU) - 矩形线性单元5)Parametric Re LU (P Re LU) - 参数化Re LU6)Exponential Linear Unit (ELU) - 指数线性单元7)Swish Function - Swish函数8)Softplus Function - Soft plus函数9)Softmax Function - SoftMax函数10)Hard Tanh Function - 硬双曲正切函数11)Softsign Function - Softsign函数12)GELU (Gaussian Error Linear Unit) - GELU(高斯误差线性单元)13)Mish Function - Mish函数14)CELU (Continuous Exponential Linear Unit) - CELU(连续指数线性单元)15)Bent Identity Function - 弯曲恒等函数16)Gaussian Error Linear Units (GELUs) - 高斯误差线性单元17)Adaptive Piecewise Linear (APL) - 自适应分段线性函数18)Radial Basis Function (RBF) - 径向基函数•Backpropagation - 反向传播1)Backpropagation - 反向传播2)Gradient Descent - 梯度下降3)Partial Derivative - 偏导数4)Chain Rule - 链式法则5)Forward Pass - 前向传播6)Backward Pass - 反向传播7)Computational Graph - 计算图8)Neural Network - 神经网络9)Loss Function - 损失函数10)Gradient Calculation - 梯度计算11)Weight Update - 权重更新12)Activation Function - 激活函数13)Optimizer - 优化器14)Learning Rate - 学习率15)Mini-Batch Gradient Descent - 小批量梯度下降16)Stochastic Gradient Descent (SGD) - 随机梯度下降17)Batch Gradient Descent - 批量梯度下降18)Momentum - 动量19)Adam Optimizer - Adam优化器20)Learning Rate Decay - 学习率衰减•Gradient Descent - 梯度下降1)Gradient Descent - 梯度下降2)Stochastic Gradient Descent (SGD) - 随机梯度下降3)Mini-Batch Gradient Descent - 小批量梯度下降4)Batch Gradient Descent - 批量梯度下降5)Learning Rate - 学习率6)Momentum - 动量7)Adaptive Moment Estimation (Adam) - 自适应矩估计8)RMSprop - 均方根传播9)Learning Rate Schedule - 学习率调度10)Convergence - 收敛11)Divergence - 发散12)Adagrad - 自适应学习速率方法13)Adadelta - 自适应增量学习率方法14)Adamax - 自适应矩估计的扩展版本15)Nadam - Nesterov Accelerated Adaptive Moment Estimation16)Learning Rate Decay - 学习率衰减17)Step Size - 步长18)Conjugate Gradient Descent - 共轭梯度下降19)Line Search - 线搜索20)Newton's Method - 牛顿法•Learning Rate - 学习率1)Learning Rate - 学习率2)Adaptive Learning Rate - 自适应学习率3)Learning Rate Decay - 学习率衰减4)Initial Learning Rate - 初始学习率5)Step Size - 步长6)Momentum - 动量7)Exponential Decay - 指数衰减8)Annealing - 退火9)Cyclical Learning Rate - 循环学习率10)Learning Rate Schedule - 学习率调度11)Warm-up - 预热12)Learning Rate Policy - 学习率策略13)Learning Rate Annealing - 学习率退火14)Cosine Annealing - 余弦退火15)Gradient Clipping - 梯度裁剪16)Adapting Learning Rate - 适应学习率17)Learning Rate Multiplier - 学习率倍增器18)Learning Rate Reduction - 学习率降低19)Learning Rate Update - 学习率更新20)Scheduled Learning Rate - 定期学习率•Batch Size - 批量大小1)Batch Size - 批量大小2)Mini-Batch - 小批量3)Batch Gradient Descent - 批量梯度下降4)Stochastic Gradient Descent (SGD) - 随机梯度下降5)Mini-Batch Gradient Descent - 小批量梯度下降6)Online Learning - 在线学习7)Full-Batch - 全批量8)Data Batch - 数据批次9)Training Batch - 训练批次10)Batch Normalization - 批量归一化11)Batch-wise Optimization - 批量优化12)Batch Processing - 批量处理13)Batch Sampling - 批量采样14)Adaptive Batch Size - 自适应批量大小15)Batch Splitting - 批量分割16)Dynamic Batch Size - 动态批量大小17)Fixed Batch Size - 固定批量大小18)Batch-wise Inference - 批量推理19)Batch-wise Training - 批量训练20)Batch Shuffling - 批量洗牌•Epoch - 训练周期1)Training Epoch - 训练周期2)Epoch Size - 周期大小3)Early Stopping - 提前停止4)Validation Set - 验证集5)Training Set - 训练集6)Test Set - 测试集7)Overfitting - 过拟合8)Underfitting - 欠拟合9)Model Evaluation - 模型评估10)Model Selection - 模型选择11)Hyperparameter Tuning - 超参数调优12)Cross-Validation - 交叉验证13)K-fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation (LOOCV) - 留一法交叉验证16)Grid Search - 网格搜索17)Random Search - 随机搜索18)Model Complexity - 模型复杂度19)Learning Curve - 学习曲线20)Convergence - 收敛3.Machine Learning Techniques and Algorithms (机器学习技术与算法)•Decision Tree - 决策树1)Decision Tree - 决策树2)Node - 节点3)Root Node - 根节点4)Leaf Node - 叶节点5)Internal Node - 内部节点6)Splitting Criterion - 分裂准则7)Gini Impurity - 基尼不纯度8)Entropy - 熵9)Information Gain - 信息增益10)Gain Ratio - 增益率11)Pruning - 剪枝12)Recursive Partitioning - 递归分割13)CART (Classification and Regression Trees) - 分类回归树14)ID3 (Iterative Dichotomiser 3) - 迭代二叉树315)C4.5 (successor of ID3) - C4.5(ID3的后继者)16)C5.0 (successor of C4.5) - C5.0(C4.5的后继者)17)Split Point - 分裂点18)Decision Boundary - 决策边界19)Pruned Tree - 剪枝后的树20)Decision Tree Ensemble - 决策树集成•Random Forest - 随机森林1)Random Forest - 随机森林2)Ensemble Learning - 集成学习3)Bootstrap Sampling - 自助采样4)Bagging (Bootstrap Aggregating) - 装袋法5)Out-of-Bag (OOB) Error - 袋外误差6)Feature Subset - 特征子集7)Decision Tree - 决策树8)Base Estimator - 基础估计器9)Tree Depth - 树深度10)Randomization - 随机化11)Majority Voting - 多数投票12)Feature Importance - 特征重要性13)OOB Score - 袋外得分14)Forest Size - 森林大小15)Max Features - 最大特征数16)Min Samples Split - 最小分裂样本数17)Min Samples Leaf - 最小叶节点样本数18)Gini Impurity - 基尼不纯度19)Entropy - 熵20)Variable Importance - 变量重要性•Support Vector Machine (SVM) - 支持向量机1)Support Vector Machine (SVM) - 支持向量机2)Hyperplane - 超平面3)Kernel Trick - 核技巧4)Kernel Function - 核函数5)Margin - 间隔6)Support Vectors - 支持向量7)Decision Boundary - 决策边界8)Maximum Margin Classifier - 最大间隔分类器9)Soft Margin Classifier - 软间隔分类器10) C Parameter - C参数11)Radial Basis Function (RBF) Kernel - 径向基函数核12)Polynomial Kernel - 多项式核13)Linear Kernel - 线性核14)Quadratic Kernel - 二次核15)Gaussian Kernel - 高斯核16)Regularization - 正则化17)Dual Problem - 对偶问题18)Primal Problem - 原始问题19)Kernelized SVM - 核化支持向量机20)Multiclass SVM - 多类支持向量机•K-Nearest Neighbors (KNN) - K-最近邻1)K-Nearest Neighbors (KNN) - K-最近邻2)Nearest Neighbor - 最近邻3)Distance Metric - 距离度量4)Euclidean Distance - 欧氏距离5)Manhattan Distance - 曼哈顿距离6)Minkowski Distance - 闵可夫斯基距离7)Cosine Similarity - 余弦相似度8)K Value - K值9)Majority Voting - 多数投票10)Weighted KNN - 加权KNN11)Radius Neighbors - 半径邻居12)Ball Tree - 球树13)KD Tree - KD树14)Locality-Sensitive Hashing (LSH) - 局部敏感哈希15)Curse of Dimensionality - 维度灾难16)Class Label - 类标签17)Training Set - 训练集18)Test Set - 测试集19)Validation Set - 验证集20)Cross-Validation - 交叉验证•Naive Bayes - 朴素贝叶斯1)Naive Bayes - 朴素贝叶斯2)Bayes' Theorem - 贝叶斯定理3)Prior Probability - 先验概率4)Posterior Probability - 后验概率5)Likelihood - 似然6)Class Conditional Probability - 类条件概率7)Feature Independence Assumption - 特征独立假设8)Multinomial Naive Bayes - 多项式朴素贝叶斯9)Gaussian Naive Bayes - 高斯朴素贝叶斯10)Bernoulli Naive Bayes - 伯努利朴素贝叶斯11)Laplace Smoothing - 拉普拉斯平滑12)Add-One Smoothing - 加一平滑13)Maximum A Posteriori (MAP) - 最大后验概率14)Maximum Likelihood Estimation (MLE) - 最大似然估计15)Classification - 分类16)Feature Vectors - 特征向量17)Training Set - 训练集18)Test Set - 测试集19)Class Label - 类标签20)Confusion Matrix - 混淆矩阵•Clustering - 聚类1)Clustering - 聚类2)Centroid - 质心3)Cluster Analysis - 聚类分析4)Partitioning Clustering - 划分式聚类5)Hierarchical Clustering - 层次聚类6)Density-Based Clustering - 基于密度的聚类7)K-Means Clustering - K均值聚类8)K-Medoids Clustering - K中心点聚类9)DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - 基于密度的空间聚类算法10)Agglomerative Clustering - 聚合式聚类11)Dendrogram - 系统树图12)Silhouette Score - 轮廓系数13)Elbow Method - 肘部法则14)Clustering Validation - 聚类验证15)Intra-cluster Distance - 类内距离16)Inter-cluster Distance - 类间距离17)Cluster Cohesion - 类内连贯性18)Cluster Separation - 类间分离度19)Cluster Assignment - 聚类分配20)Cluster Label - 聚类标签•K-Means - K-均值1)K-Means - K-均值2)Centroid - 质心3)Cluster - 聚类4)Cluster Center - 聚类中心5)Cluster Assignment - 聚类分配6)Cluster Analysis - 聚类分析7)K Value - K值8)Elbow Method - 肘部法则9)Inertia - 惯性10)Silhouette Score - 轮廓系数11)Convergence - 收敛12)Initialization - 初始化13)Euclidean Distance - 欧氏距离14)Manhattan Distance - 曼哈顿距离15)Distance Metric - 距离度量16)Cluster Radius - 聚类半径17)Within-Cluster Variation - 类内变异18)Cluster Quality - 聚类质量19)Clustering Algorithm - 聚类算法20)Clustering Validation - 聚类验证•Dimensionality Reduction - 降维1)Dimensionality Reduction - 降维2)Feature Extraction - 特征提取3)Feature Selection - 特征选择4)Principal Component Analysis (PCA) - 主成分分析5)Singular Value Decomposition (SVD) - 奇异值分解6)Linear Discriminant Analysis (LDA) - 线性判别分析7)t-Distributed Stochastic Neighbor Embedding (t-SNE) - t-分布随机邻域嵌入8)Autoencoder - 自编码器9)Manifold Learning - 流形学习10)Locally Linear Embedding (LLE) - 局部线性嵌入11)Isomap - 等度量映射12)Uniform Manifold Approximation and Projection (UMAP) - 均匀流形逼近与投影13)Kernel PCA - 核主成分分析14)Non-negative Matrix Factorization (NMF) - 非负矩阵分解15)Independent Component Analysis (ICA) - 独立成分分析16)Variational Autoencoder (VAE) - 变分自编码器17)Sparse Coding - 稀疏编码18)Random Projection - 随机投影19)Neighborhood Preserving Embedding (NPE) - 保持邻域结构的嵌入20)Curvilinear Component Analysis (CCA) - 曲线成分分析•Principal Component Analysis (PCA) - 主成分分析1)Principal Component Analysis (PCA) - 主成分分析2)Eigenvector - 特征向量3)Eigenvalue - 特征值4)Covariance Matrix - 协方差矩阵。
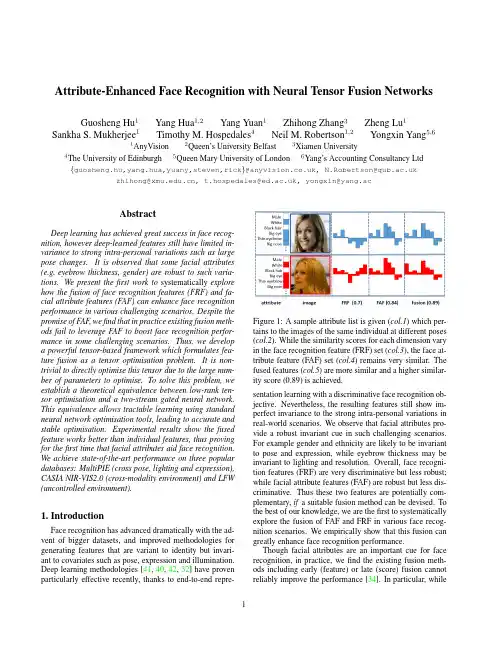
Attribute-Enhanced Face Recognition with Neural Tensor Fusion Networks Guosheng Hu1Yang Hua1,2Yang Yuan1Zhihong Zhang3Zheng Lu1 Sankha S.Mukherjee1Timothy M.Hospedales4Neil M.Robertson1,2Yongxin Yang5,61AnyVision2Queen’s University Belfast3Xiamen University 4The University of Edinburgh5Queen Mary University of London6Yang’s Accounting Consultancy Ltd {guosheng.hu,yang.hua,yuany,steven,rick}@,N.Robertson@ zhihong@,t.hospedales@,yongxin@yang.acAbstractDeep learning has achieved great success in face recog-nition,however deep-learned features still have limited in-variance to strong intra-personal variations such as large pose changes.It is observed that some facial attributes (e.g.eyebrow thickness,gender)are robust to such varia-tions.We present thefirst work to systematically explore how the fusion of face recognition features(FRF)and fa-cial attribute features(FAF)can enhance face recognition performance in various challenging scenarios.Despite the promise of FAF,wefind that in practice existing fusion meth-ods fail to leverage FAF to boost face recognition perfor-mance in some challenging scenarios.Thus,we develop a powerful tensor-based framework which formulates fea-ture fusion as a tensor optimisation problem.It is non-trivial to directly optimise this tensor due to the large num-ber of parameters to optimise.To solve this problem,we establish a theoretical equivalence between low-rank ten-sor optimisation and a two-stream gated neural network. This equivalence allows tractable learning using standard neural network optimisation tools,leading to accurate and stable optimisation.Experimental results show the fused feature works better than individual features,thus proving for thefirst time that facial attributes aid face recognition. We achieve state-of-the-art performance on three popular databases:MultiPIE(cross pose,lighting and expression), CASIA NIR-VIS2.0(cross-modality environment)and LFW (uncontrolled environment).1.IntroductionFace recognition has advanced dramatically with the ad-vent of bigger datasets,and improved methodologies for generating features that are variant to identity but invari-ant to covariates such as pose,expression and illumination. Deep learning methodologies[41,40,42,32]have proven particularly effective recently,thanks to end-to-endrepre-Figure1:A sample attribute list is given(col.1)which per-tains to the images of the same individual at different poses (col.2).While the similarity scores for each dimension vary in the face recognition feature(FRF)set(col.3),the face at-tribute feature(FAF)set(col.4)remains very similar.The fused features(col.5)are more similar and a higher similar-ity score(0.89)is achieved.sentation learning with a discriminative face recognition ob-jective.Nevertheless,the resulting features still show im-perfect invariance to the strong intra-personal variations in real-world scenarios.We observe that facial attributes pro-vide a robust invariant cue in such challenging scenarios.For example gender and ethnicity are likely to be invariant to pose and expression,while eyebrow thickness may be invariant to lighting and resolution.Overall,face recogni-tion features(FRF)are very discriminative but less robust;while facial attribute features(FAF)are robust but less dis-criminative.Thus these two features are potentially com-plementary,if a suitable fusion method can be devised.To the best of our knowledge,we are thefirst to systematically explore the fusion of FAF and FRF in various face recog-nition scenarios.We empirically show that this fusion can greatly enhance face recognition performance.Though facial attributes are an important cue for face recognition,in practice,wefind the existing fusion meth-ods including early(feature)or late(score)fusion cannot reliably improve the performance[34].In particular,while 1offering some robustness,FAF is generally less discrimina-tive than FRF.Existing methods cannot synergistically fuse such asymmetric features,and usually lead to worse perfor-mance than achieved by the stronger feature(FRF)only.In this work,we propose a novel tensor-based fusion frame-work that is uniquely capable of fusing the very asymmet-ric FAF and FRF.Our framework provides a more powerful and robust fusion approach than existing strategies by learn-ing from all interactions between the two feature views.To train the tensor in a tractable way given the large number of required parameters,we formulate the optimisation with an identity-supervised objective by constraining the tensor to have a low-rank form.We establish an equivalence be-tween this low-rank tensor and a two-stream gated neural network.Given this equivalence,the proposed tensor is eas-ily optimised with standard deep neural network toolboxes. Our technical contributions are:•It is thefirst work to systematically investigate and ver-ify that facial attributes are an important cue in various face recognition scenarios.In particular,we investi-gate face recognition with extreme pose variations,i.e.±90◦from frontal,showing that attributes are impor-tant for performance enhancement.•A rich tensor-based fusion framework is proposed.We show the low-rank Tucker-decomposition of this tensor-based fusion has an equivalent Gated Two-stream Neural Network(GTNN),allowing easy yet effective optimisation by neural network learning.In addition,we bring insights from neural networks into thefield of tensor optimisation.The code is available:https:///yanghuadr/ Neural-Tensor-Fusion-Network•We achieve state-of-the-art face recognition perfor-mance using the fusion of face(newly designed‘Lean-Face’deep learning feature)and attribute-based fea-tures on three popular databases:MultiPIE(controlled environment),CASIA NIR-VIS2.0(cross-modality environment)and LFW(uncontrolled environment).2.Related WorkFace Recognition.The face representation(feature)is the most important component in contemporary face recog-nition system.There are two types:hand-crafted and deep learning features.Widely used hand-crafted face descriptors include Local Binary Pattern(LBP)[26],Gaborfilters[23],-pared to pixel values,these features are variant to identity and relatively invariant to intra-personal variations,and thus they achieve promising performance in controlled environ-ments.However,they perform less well on face recognition in uncontrolled environments(FRUE).There are two main routes to improve FRUE performance with hand-crafted features,one is to use very high dimensional features(dense sampling features)[5]and the other is to enhance the fea-tures with downstream metric learning.Unlike hand-crafted features where(in)variances are en-gineered,deep learning features learn the(in)variances from data.Recently,convolutional neural networks(CNNs) achieved impressive results on FRUE.DeepFace[44],a carefully designed8-layer CNN,is an early landmark method.Another well-known line of work is DeepID[41] and its variants DeepID2[40],DeepID2+[42].The DeepID family uses an ensemble of many small CNNs trained in-dependently using different facial patches to improve the performance.In addition,some CNNs originally designed for object recognition,such as VGGNet[38]and Incep-tion[43],were also used for face recognition[29,32].Most recently,a center loss[47]is introduced to learn more dis-criminative features.Facial Attribute Recognition.Facial attribute recog-nition(FAR)is also well studied.A notable early study[21] extracted carefully designed hand-crafted features includ-ing aggregations of colour spaces and image gradients,be-fore training an independent SVM to detect each attribute. As for face recognition,deep learning features now outper-form hand-crafted features for FAR.In[24],face detection and attribute recognition CNNs are carefully designed,and the output of the face detection network is fed into the at-tribute network.An alternative to purpose designing CNNs for FAR is tofine-tune networks intended for object recog-nition[56,57].From a representation learning perspective, the features supporting different attribute detections may be shared,leading some studies to investigate multi-task learn-ing facial attributes[55,30].Since different facial attributes have different prevalence,the multi-label/multi-task learn-ing suffers from label-imbalance,which[30]addresses us-ing a mixed objective optimization network(MOON). Face Recognition using Facial Attributes.Detected facial attributes can be applied directly to authentication. Facial attributes have been applied to enhance face verifica-tion,primarily in the case of cross-modal matching,byfil-tering[19,54](requiring potential FRF matches to have the correct gender,for example),model switching[18],or ag-gregation with conventional features[27,17].[21]defines 65facial attributes and proposes binary attribute classifiers to predict their presence or absence.The vector of attribute classifier scores can be used for face recognition.There has been little work on attribute-enhanced face recognition in the context of deep learning.One of the few exploits CNN-based attribute features for authentication on mobile devices [31].Local facial patches are fed into carefully designed CNNs to predict different attributes.After CNN training, SVMs are trained for attribute recognition,and the vector of SVM scores provide the new feature for face verification.Fusion Methods.Existing fusion approaches can be classified into feature-level(early fusion)and score-level (late fusion).Score-level fusion is to fuse the similarity scores after computation based on each view either by sim-ple averaging[37]or stacking another classifier[48,37]. Feature-level fusion can be achieved by either simple fea-ture aggregation or subspace learning.For aggregation ap-proaches,fusion is usually performed by simply element wise averaging or product(the dimension of features have to be the same)or concatenation[28].For subspace learn-ing approaches,the features arefirst concatenated,then the concatenated feature is projected to a subspace,in which the features should better complement each other.These sub-space approaches can be unsupervised or supervised.Un-supervised fusion does not use the identity(label)informa-tion to learn the subspace,such as Canonical Correlational Analysis(CCA)[35]and Bilinear Models(BLM)[45].In comparison,supervised fusion uses the identity information such as Linear Discriminant Analysis(LDA)[3]and Local-ity Preserving Projections(LPP)[9].Neural Tensor Methods.Learning tensor-based compu-tations within neural networks has been studied for full[39] and decomposed[16,52,51]tensors.However,aside from differing applications and objectives,the key difference is that we establish a novel equivalence between a rich Tucker [46]decomposed low-rank fusion tensor,and a gated two-stream neural network.This allows us achieve expressive fusion,while maintaining tractable computation and a small number of parameters;and crucially permits easy optimisa-tion of the fusion tensor through standard toolboxes. Motivation.Facial attribute features(FAF)and face recognition features(FRF)are complementary.However in practice,wefind that existing fusion methods often can-not effectively combine these asymmetric features so as to improve performance.This motivates us to design a more powerful fusion method,as detailed in Section3.Based on our neural tensor fusion method,in Section5we system-atically explore the fusion of FAF and FRF in various face recognition environments,showing that FAF can greatly en-hance recognition performance.3.Fusing attribute and recognition featuresIn this section we present our strategy for fusing FAF and FRF.Our goal is to input FAF and FRF and output the fused discriminative feature.The proposed fusion method we present here performs significantly better than the exist-ing ones introduced in Section2.In this section,we detail our tensor-based fusion strategy.3.1.ModellingSingle Feature.We start from a standard multi-class clas-sification problem setting:assume we have M instances, and for each we extract a D-dimensional feature vector(the FRF)as{x(i)}M i=1.The label space contains C unique classes(person identities),so each instance is associated with a corresponding C-dimensional one-hot encoding la-bel vector{y(i)}M i=1.Assuming a linear model W the pre-dictionˆy(i)is produced by the dot-product of input x(i)and the model W,ˆy(i)=x(i)T W.(1) Multiple Feature.Suppose that apart from the D-dimensional FRF vector,we can also obtain an instance-wise B-dimensional facial attribute feature z(i).Then the input for the i th instance is a pair:{x(i),z(i)}.A simple ap-proach is to redefine x(i):=[x(i),z(i)],and directly apply Eq.(1),thus modelling weights for both FRF and FAF fea-tures.Here we propose instead a non-linear fusion method via the following formulationˆy(i)=W×1x(i)×3z(i)(2) where W is the fusion model parameters in the form of a third-order tensor of size D×C×B.Notation×is the tensor dot product(also known as tensor contraction)and the left-subscript of x and z indicates at which axis the ten-sor dot product operates.With Eq.(2),the optimisation problem is formulated as:minW1MMi=1W×1x(i)×3z(i),y(i)(3)where (·,·)is a loss function.This trains tensor W to fuse FRF and FAF features so that identity is correctly predicted.3.2.OptimisationThe proposed tensor W provides a rich fusion model. However,compared with W,W is B times larger(D×C vs D×C×B)because of the introduction of B-dimensional attribute vector.It is also almost B times larger than train-ing a matrix W on the concatenation[x(i),z(i)].It is there-fore problematic to directly optimise Eq.(3)because the large number of parameters of W makes training slow and leads to overfitting.To address this we propose a tensor de-composition technique and a neural network architecture to solve an equivalent optimisation problem in the following two subsections.3.2.1Tucker Decomposition for Feature FusionTo reduce the number of parameters of W,we place a struc-tural constraint on W.Motivated by the famous Tucker de-composition[46]for tensors,we assume that W is synthe-sised fromW=S×1U(D)×2U(C)×3U(B).(4) Here S is a third order tensor of size K D×K C×K B, U(D)is a matrix of size K D×D,U(C)is a matrix of sizeK C×C,and U(B)is a matrix of size K B×B.By restricting K D D,K C C,and K B B,we can effectively reduce the number of parameters from(D×C×B)to (K D×K C×K B+K D×D+K C×C+K B×B)if we learn{S,U(D),U(C),U(B)}instead of W.When W is needed for making the predictions,we can always synthesise it from those four small factors.In the context of tensor decomposition,(K D,K C,K B)is usually called the tensor’s rank,as an analogous concept to the rank of a matrix in matrix decomposition.Note that,despite of the existence of other tensor de-composition choices,Tucker decomposition offers a greater flexibility in terms of modelling because we have three hyper-parameters K D,K C,K B corresponding to the axes of the tensor.In contrast,the other famous decomposition, CP[10]has one hyper-parameter K for all axes of tensor.By substituting Eq.(4)into Eq.(2),we haveˆy(i)=W×1x(i)×3z(i)=S×1U(D)×2U(C)×3U(B)×1x(i)×3z(i)(5) Through some re-arrangement,Eq.(5)can be simplified as ˆy(i)=S×1(U(D)x(i))×2U(C)×3(U(B)z(i))(6) Furthermore,we can rewrite Eq.(6)as,ˆy(i)=((U(D)x(i))⊗(U(B)z(i)))S T(2)fused featureU(C)(7)where⊗is Kronecker product.Since U(D)x(i)and U(B)B(i)result in K D and K B dimensional vectors re-spectively,(U(D)x(i))⊗(U(B)z(i))produces a K D K B vector.S(2)is the mode-2unfolding of S which is aK C×K D K B matrix,and its transpose S T(2)is a matrix ofsize K D K B×K C.The Fused Feature.From Eq.(7),the explicit fused representation of face recognition(x(i))and facial at-tribute(z(i))features can be achieved.The fused feature ((U(D)x(i))⊗(U(B)z(i)))S T(2),is a vector of the dimen-sionality K C.And matrix U(C)has the role of“clas-sifier”given this fused feature.Given{x(i),z(i),y(i)}, the matrices{U(D),U(B),U(C)}and tensor S are com-puted(learned)during model optimisation(training).Dur-ing testing,the predictionˆy(i)is achieved with the learned {U(D),U(B),U(C),S}and two test features{x(i),z(i)} following Eq.(7).3.2.2Gated Two-stream Neural Network(GTNN)A key advantage of reformulating Eq.(5)into Eq.(7)is that we can nowfind a neural network architecture that does ex-actly the computation of Eq.(7),which would not be obvi-ous if we stopped at Eq.(5).Before presenting thisneural Figure2:Gated two-stream neural network to implement low-rank tensor-based fusion.The architecture computes Eq.(7),with the Tucker decomposition in Eq.(4).The network is identity-supervised at train time,and feature in the fusion layer used as representation for verification. network,we need to introduce a new deterministic layer(i.e. without any learnable parameters).Kronecker Product Layer takes two arbitrary-length in-put vectors{u,v}where u=[u1,u2,···,u P]and v=[v1,v2,···,v Q],then outputs a vector of length P Q as[u1v1,u1v2,···,u1v Q,u2v1,···,u P v Q].Using the introduced Kronecker layer,Fig.2shows the neural network that computes Eq.(7).That is,the neural network that performs recognition using tensor-based fu-sion of two features(such as FAF and FRF),based on the low-rank assumption in Eq.(4).We denote this architecture as a Gated Two-stream Neural Network(GTNN),because it takes two streams of inputs,and it performs gating[36] (multiplicative)operations on them.The GTNN is trained in a supervised fashion to predict identity.In this work,we use a multitask loss:softmax loss and center loss[47]for joint training.The fused feature in the viewpoint of GTNN is the output of penultimate layer, which is of dimensionality K c.So far,the advantage of using GTNN is obvious.Direct use of Eq.(5)or Eq.(7)requires manual derivation and im-plementation of an optimiser which is non-trivial even for decomposed matrices(2d-tensors)[20].In contrast,GTNN is easily implemented with modern deep learning packages where auto-differentiation and gradient-based optimisation is handled robustly and automatically.3.3.DiscussionCompared with the fusion methods introduced in Sec-tion2,we summarise the advantages of our tensor-based fusion method as follows:Figure3:LeanFace.‘C’is a group of convolutional layers.Stage1:64@5×5(64feature maps are sliced to two groups of32ones, which are fed into maxout function.);Stage2:64@3×3,64@3×3,128@3×3,128@3×3;Stage3:196@3×3,196@3×3, 256@3×3,256@3×3,320@3×3,320@3×3;Stage4:512@3×3,512@3×3,512@3×3,512@3×3;Stage5:640@ 5×5,640@5×5.‘P’stands for2×2max pooling.The strides for the convolutional and pooling layers are1and2,respectively.‘FC’is a fully-connected layer of256D.High Order Non-Linearity.Unlike linear methods based on averaging,concatenation,linear subspace learning [8,27],or LDA[3],our fusion method is non-linear,which is more powerful to model complex problems.Further-more,comparing with otherfirst-order non-linear methods based on element-wise combinations only[28],our method is higher order:it accounts for all interactions between each pair of feature channels in both views.Thanks to the low-rank modelling,our method achieves such powerful non-linear fusion with few parameters and thus it is robust to overfitting.Scalability.Big datasets are required for state-of-the-art face representation learning.Because we establish the equivalence between tensor factorisation and gated neural network architecture,our method is scalable to big-data through efficient mini-batch SGD-based learning.In con-trast,kernel-based non-linear methods,such as Kernel LDA [34]and multi-kernel SVM[17],are restricted to small data due to their O(N2)computation cost.At runtime,our method only requires a simple feed-forward pass and hence it is also favourable compared to kernel methods. Supervised method.GTNN isflexibly supervised by any desired neural network loss function.For example,the fusion method can be trained with losses known to be ef-fective for face representation learning:identity-supervised softmax,and centre-loss[47].Alternative methods are ei-ther unsupervised[8,27],constrained in the types of super-vision they can exploit[3,17],or only stack scores rather than improving a learned representation[48,37].There-fore,they are relatively ineffective at learning how to com-bine the two-source information in a task-specific way. Extensibility.Our GTNN naturally can be extended to deeper architectures.For example,the pre-extracted fea-tures,i.e.,x and z in Fig.2,can be replaced by two full-sized CNNs without any modification.Therefore,poten-tially,our methods can be integrated into an end-to-end framework.4.Integration with CNNs:architectureIn this section,we introduce the CNN architectures used for face recognition(LeanFace)designed by ourselves and facial attribute recognition(AttNet)introduced by[50,30]. LeanFace.Unlike general object recognition,face recognition has to capture very subtle difference between people.Motivated by thefine-grain object recognition in [4],we also use a large number of convolutional layers at early stage to capture the subtle low level and mid-level in-formation.Our activation function is maxout,which shows better performance than its competitors[50].Joint supervi-sion of softmax loss and center loss[47]is used for training. The architecture is summarised in Fig.3.AttNet.To detect facial attributes,our AttNet uses the ar-chitecture of Lighten CNN[50]to represent a face.Specifi-cally,AttNet consists of5conv-activation-pooling units fol-lowed by a256D fully connected layer.The number of con-volutional kernels is explained in[50].The activation func-tion is Max-Feature-Map[50]which is a variant of maxout. We use the loss function MOON[30],which is a multi-task loss for(1)attribute classification and(2)domain adaptive data balance.In[24],an ontology of40facial attributes are defined.We remove attributes which do not characterise a specific person,e.g.,‘wear glasses’and‘smiling’,leaving 17attributes in total.Once each network is trained,the features extracted from the penultimate fully-connected layers of LeanFace(256D) and AttNet(256D)are extracted as x and z,and input to GTNN for fusion and then face recognition.5.ExperimentsWefirst introduce the implementation details of our GTNN method.In Section5.1,we conduct experiments on MultiPIE[7]to show that facial attributes by means of our GTNN method can play an important role on improv-Table1:Network training detailsImage size BatchsizeLR1DF2EpochTraintimeLeanFace128x1282560.0010.15491hAttNet0.050.8993h1Learning rate(LR)2Learning rate drop factor(DF).ing face recognition performance in the presence of pose, illumination and expression,respectively.Then,we com-pare our GTNN method with other fusion methods on CA-SIA NIR-VIS2.0database[22]in Section5.2and LFW database[12]in Section5.3,respectively. Implementation Details.In this study,three networks (LeanFace,AttNet and GTNN)are discussed.LeanFace and AttNet are implemented using MXNet[6]and GTNN uses TensorFlow[1].We use around6M training face thumbnails covering62K different identities to train Lean-Face,which has no overlapping with all the test databases. AttNet is trained using CelebA[24]database.The input of GTNN is two256D features from bottleneck layers(i.e., fully connected layers before prediction layers)of LeanFace and AttNet.The setting of main parameters are shown in Table1.Note that the learning rates drop when the loss stops decreasing.Specifically,the learning rates change4 and2times for LeanFace and AttNet respectively.Dur-ing test,LeanFace and AttNet take around2.9ms and3.2ms to extract feature from one input image and GTNN takes around2.1ms to fuse one pair of LeanFace and AttNet fea-ture using a GTX1080Graphics Card.5.1.Multi-PIE DatabaseMulti-PIE database[7]contains more than750,000im-ages of337people recorded in4sessions under diverse pose,illumination and expression variations.It is an ideal testbed to investigate if facial attribute features(FAF) complement face recognition features(FRF)including tra-ditional hand-crafted(LBP)and deeply learned features (LeanFace)to improve the face recognition performance–particularly across extreme pose variation.Settings.We conduct three experiments to investigate pose-,illumination-and expression-invariant face recogni-tion.Pose:Uses images across4sessions with pose vari-ations only(i.e.,neutral lighting and expression).It covers pose with yaw ranging from left90◦to right90◦.In com-parison,most of the existing works only evaluate perfor-mance on poses with yaw range(-45◦,+45◦).Illumination: Uses images with20different illumination conditions(i.e., frontal pose and neutral expression).Expression:Uses im-ages with7different expression variations(i.e.,frontal pose and neutral illumination).The training sets of all settings consist of the images from thefirst200subjects and the re-maining137subjects for testing.Following[59,14],in the test set,frontal images with neural illumination and expres-sion from the earliest session work as gallery,and the others are probes.Pose.Table2shows the pose-robust face recognition (PRFR)performance.Clearly,the fusion of FRF and FAF, namely GTNN(LBP,AttNet)and GTNN(LeanFace,At-tNet),works much better than using FRF only,showing the complementary power of facial features to face recognition features.Not surprisingly,the performance of both LBP and LeanFace features drop greatly under extreme poses,as pose variation is a major factor challenging face recognition performance.In contrast,with GTNN-based fusion,FAF can be used to improve both classic(LBP)and deep(Lean-Face)FRF features effectively under this circumstance,for example,LBP(1.3%)vs GTNN(LBP,AttNet)(16.3%), LeanFace(72.0%)vs GTNN(LeanFace,AttNet)(78.3%) under yaw angel−90◦.It is noteworthy that despite their highly asymmetric strength,GTNN is able to effectively fuse FAF and FRF.This is elaborately studied in more detail in Sections5.2-5.3.Compared with state-of-the-art methods[14,59,11,58, 15]in terms of(-45◦,+45◦),LeanFace achieves better per-formance due to its big training data and the strong gener-alisation capacity of deep learning.In Table2,2D meth-ods[14,59,15]trained models using the MultiPIE images, therefore,they are difficult to generalise to images under poses which do not appear in MultiPIE database.3D meth-ods[11,58]highly depend on accurate2D landmarks for 3D-2D modellingfitting.However,it is hard to accurately detect such landmarks under larger poses,limiting the ap-plications of3D methods.Illumination and expression.Illumination-and expression-robust face recognition(IRFR and ERFR)are also challenging research topics.LBP is the most widely used handcrafted features for IRFR[2]and ERFR[33].To investigate the helpfulness of facial attributes,experiments of IRFR and ERFR are conducted using LBP and Lean-Face features.In Table3,GTNN(LBP,AttNet)signifi-cantly outperforms LBP,80.3%vs57.5%(IRFR),77.5% vs71.7%(ERFR),showing the great value of combining fa-cial attributes with hand-crafted features.Attributes such as the shape of eyebrows are illumination invariant and others, e.g.,gender,are expression invariant.In contrast,LeanFace feature is already very discriminative,saturating the perfor-mance on the test set.So there is little room for fusion of AttrNet to provide benefit.5.2.CASIA NIR-VIS2.0DatabaseThe CASIA NIR-VIS2.0face database[22]is the largest public face database across near-infrared(NIR)images and visible RGB(VIS)images.It is a typical cross-modality or heterogeneous face recognition problem because the gallery and probe images are from two different spectra.The。

doi:10.19677/j.issn.1004-7964.2024.01.005基于改进YOLOv5的皮革抓取点识别及定位金光,任工昌*,桓源,洪杰(陕西科技大学机电工程学院,陕西西安710021)摘要:为实现机器人对皮革抓取点的精确定位,文章通过改进YOLOv5算法,引入coordinate attention 注意力机制到Backbone 层中,用Focal-EIOU Loss 对CIOU Loss 进行替换来设置不同梯度,从而实现了对皮革抓取点快速精准的识别和定位。
利用目标边界框回归公式获取皮革抓点的定位坐标,经过坐标系转换获得待抓取点的三维坐标,采用Intel RealSense D435i 深度相机对皮革抓取点进行定位实验。
实验结果表明:与Faster R-CNN 算法和原始YOLOv5算法对比,识别实验中改进YOLOv5算法的准确率分别提升了6.9%和2.63%,召回率分别提升了8.39%和2.63%,mAP 分别提升了8.13%和0.21%;定位实验中改进YOLOv5算法的误差平均值分别下降了0.033m 和0.007m,误差比平均值分别下降了2.233%和0.476%。
关键词:皮革;抓取点定位;机器视觉;YOLOv5;CA 注意力机制中图分类号:TP 391文献标志码:AGrab Point Identification and Localization of Leather based onImproved YOLOv5(College of Mechanical and Electrical Engineering,Shaanxi University of Science and Technology,Xi ’an 710021,China)Abstract:In order to achieve precise localization of leather grasping points by robots,this study proposed an improved approach based on the YOLOv5algorithm.The methodology involved the integration of the coordinate attention mechanism into the Backbone layer and the replacement of the CIOU Loss with the Focal-EIOU Loss to enable different gradients and enhance the rapid and accurate recognition and localization of leather grasping points.The positioning coordinates of the leather grasping points were obtained by using the target bounding box regression formula,followed by the coordinate system conversion to obtain the three-dimensional coordinates of the target grasping points.The experimental positioning of leather grasping points was conducted by using the Intel RealSense D435i depth camera.Experimental results demonstrate the significant improvements over the Faster R -CNN algorithm and the original YOLOv5algorithm.The improved YOLOv5algorithm exhibited an accuracy enhancement of 6.9%and 2.63%,a recall improvement of 8.39%and 2.63%,and an mAP improvement of 8.13%and 0.21%in recognition experiments,respectively.Similarly,in the positioning experiments,the improved YOLOv5algorithm demonstrated a decrease in average error values of 0.033m and 0.007m,and a decrease in error ratio average values of 2.233%and 0.476%.Key words:leather;grab point positioning;machine vision;YOLOv5;coordinate attention收稿日期:2023-06-09修回日期:2023-07-08接受日期:2023-07-12基金项目:陕西省重点研发计划资助项目(2022GY-250);西安市科技计划项目(23ZDCYJSGG0016-2022)第一作者简介:金光(1996-),男,硕士研究生,主要研究方向为机器视觉,深度学习。


第37卷第1期湖南理工学院学报(自然科学版)V ol. 37 No. 1 2024年3月 Journal of Hunan Institute of Science and Technology (Natural Sciences) Mar. 2024引入稳定学习的多中心脑磁共振影像统计分类方法研究杨勃, 钟志锴(湖南理工学院信息科学与工程学院, 湖南岳阳 414006)摘要:针对现有统计分析方法在多中心统计分类任务上缺乏稳定性的问题, 提出一种引入稳定学习的多中心脑磁共振影像的统计分类方法. 该方法使用多层3D卷积神经网络作为骨干结构, 并引入稳定学习旁路结构调节卷积网络习得特征的稳定性. 在稳定学习旁路中, 首先使用随机傅里叶变换获取卷积网络特征的多路随机序列, 然后通过学习和优化批次样本采样权重以获取卷积网络特征之间的独立性, 从而改善跨中心分类泛化性. 最后, 在公开数据库FCP中的3中心脑影像数据集上进行跨中心性别分类实验. 实验结果表明, 与基准卷积网络相比, 引入稳定学习的卷积网络具有更高的跨中心分类正确率, 有效提高了跨中心泛化性和多中心统计分类的稳定性.关键词:多中心脑磁共振影像分析; 卷积神经网络; 稳定学习; 跨中心泛化中图分类号: TP183 文章编号: 1672-5298(2024)01-0015-05 Research on a Classification Approach for Multi-site Brain Magnetic Resonance Imaging Analysis byIntroducing Stable LearningYANG Bo, ZHONG Zhikai(School of Information Science and Engineering, Hunan Institute of Science and Technology, Yueyang 414006, China) Abstract: Aiming at the lack of stability of existing statistical analysis methods suitable for single site tasks in a multi-site setting, a statistical classification approach integrating stable learning for multi-site brain magnetic resonance imaging(MRI) analysis tasks was proposed. In the proposed approach, a multi-layer 3-dimensional convolutional neural network(3D CNN) was used as the backbone structure, while a stable learning module used for improving the stability of features learning by CNN was integrated as bypassing structure. In the stable learning module, the random Fourier transform was firstly used to obtain the random sequences of CNN features, and then the independence between different sequences was obtained by optimizing sampling weights of every sample batch and improving the cross-site generalization. Finally, a cross-site gender classification experiment was conducted on the 3 brain MRI data site from the publicly available database FCP. The experimental results show that compared with the basic CNN, the CNN with stable learning has a higher accuracy in cross-site classification, and effectively improves the stability of cross-center generalization and multi-center statistical classification.Key words: multi-site brain MRI analysis; convolutional neural network; stable learning; cross-site generalization0 引言经典机器学习方法使用训练数据集来训练模型, 然后使用训练好的模型对新数据进行预测. 确保该训练—预测流程的有效性, 主要基于两点[1]: 一是理论上满足独立同分布假设, 即训练数据和新数据均独立采样自同一统计分布; 二是训练数据量要充分, 能够准确描述该统计分布.在大量实际应用中, 收集到的数据往往来自不同数据域, 不满足独立同分布假设, 导致经典机器学习方法在此场景下性能显著退化, 在某一个域中训练得到的模型完全无法迁移到其他域的数据上, 跨域泛化性差[2]. 磁共振影像(Magnetic Resonance Imaging, MRI)分析领域也同样存在此类问题. 为增大数据量以获得更优的训练效果, 单中心脑MRI分析已逐渐发展到多中心脑MRI分析. 虽然多中心影像数据量显著增收稿日期: 2023-06-19基金项目:湖南省研究生科研创新项目(CX20221231,YCX2023A50); 湖南省自然科学基金项目“面向小样本脑磁共振影像分析的数据生成技术与深度学习方法研究”(2024JJ7208)作者简介: 杨勃, 男, 博士, 教授. 主要研究方向: 机器学习、脑影像分析16 湖南理工学院学报(自然科学版) 第37卷长, 但由于存在机器参数、被试生理参数等诸多不同, 不同中心的数据无法满足独立同分布假设, 导致多中心统计分析表现出较差的稳定性[3,4].为提升多域分析的稳定性, 近年来机器学习理论研究从因果分析角度提出一系列基于线性无关特征采样的稳定预测方法[5,6], 并在低维数据上取得了一定效果, 初步展现出在多域分析上的巨大潜力. Zhang等[7]在此基础上提出稳定学习方法, 扩展了以前的线性框架, 以纳入深度模型. 由于在深度模型中获得的复杂非线性特征之间的依赖关系比线性情况下更难测量和消除[8,9], 因此稳定学习采用了一种基于随机傅里叶特征(Random Fourier Features, RFF)[10]的非线性特征去相关方法; 同时, 为了适应现代深度模型, 还专门设计了一种全局关联的保存和重新加载机制, 以减少训练大规模数据时的存储和计算成本. 相关实验表明, 稳定学习结合深度学习在高维图像识别任务上表现出较好的稳定性[7].本文尝试将稳定学习引入多中心脑MRI 的统计分类任务中, 将稳定学习与3D CNN 结合, 解决跨中心泛化性问题, 提高多中心分类稳定性. 首先介绍本研究设计的融合稳定学习的3D CNN 网络架构; 然后介绍稳定学习特征独立性最大化准则; 最后与基准3D CNN 分别在公开数据集FCP 中的3中心脑MRI 数据集上进行对比分类实验. 实验结果表明, 引入稳定学习的卷积网络具有更高的跨中心分类正确率, 有效提高了多中心脑MRI 统计分类的稳定性.1 融合稳定学习的3D CNN 架构设计融合稳定学习的3D CNN 总体架构设计如图1所示. 首先使用3D CNN 提取脑MRI 的3D 特征, 再将特征分别输出至稳定学习旁路和分类器主路进行训练. 稳定学习旁路使用随机傅里叶变换模块提取3D特征的多路RFF 特征, 然后使用样本加权解相关模块(Learning Sample Weighting for Decorrelation, LSWD)优化样本采样权重. 最后使用样本权重对分类器的预测损失进行加权, 以加权损失最小化为优化目标进行反向传播.图1 融合稳定学习的3D CNN 总体架构设计2 特征独立性最大化2.1 基于随机傅里叶变换的随机变量独立性判定设X 、Y 为两个随机变量, ()X f X 、()Y f Y 、(,)f X Y 分别表示X 的概率密度、Y 的概率密度以及X 和Y 的联合概率密度, 若满足(,)()()X Y f X Y f X f Y =,则称随机变量X 、Y 相互独立.当X 、Y 均服从高斯分布时, 统计独立性等价于统计不相关, 即Conv (,)((())(()))()()()0X Y E X E x Y E Y E XY E X E Y =--=-=,其中Conv (,)⋅⋅为两随机变量之间的协方差, ()E ⋅为随机变量的期望.第1期 杨 勃, 等: 引入稳定学习的多中心脑磁共振影像统计分类方法研究 17在本文深度神经网络中, 随机变量,X Y 就是脑MRI 的3D 特征变量. 设有n 个训练样本, 可将其视为对随机变量,X Y 分别进行了n 次采样, 获得了对应的随机序列12(,,,)n X x x x = 和12(,,,)nY y y y = . 可使用随机序列之间的协方差进行无偏估计:Conv 111()111,1n n n i j i j i j j X Y x x y y n n n ===⎛⎫⎛⎫=-- ⎪ ⎪-⎝⎭⎝⎭∑∑∑ . 需要指出的是, 若,X Y 不服从高斯分布, 则Conv0(),X Y = 不能作为变量独立性判定准则. 文[9]指出, 此情形下可将随机序列,X Y 转换为k 个随机傅里叶变换序列{RFF },){RFF }()(i i k i i kX Y ≤≤后再使用协方差进行判定.随机傅里叶变换公式为RFF ,)()(s i i i X X ωφ+ ~(0,1),i N ω~Uniform(0,2π),iφi <∞. 其中随机频率i ω从标准正态分布中采样得到, 随机相位i φ从0~2π之间的均匀分布中采样得到.通过随机傅里叶变换可获得如下两个随机矩阵RFF(),RFF()n k XY ⨯∈ : 1212RFF()(RFF ,RFF ,,RFF ),R .()())FF()(F ()RF ,RF ,()(F ,RFF ())k kX X X X Y Y Y Y == 计算这两个随机矩阵的协方差矩阵:Conv T111111(((RFF ),RF ()()()(F())RFF RFF RFF RFF 1)n n n i j i j i j j X Y X X Y Y n n n ===⎡⎤=--⎢⎣⎥-⎣⎦⎡⎤⎢⎥⎦∑∑∑ . 若||Conv 2(RFF(),RFF())||0,F X Y = 则可判定随机变量,X Y 相互独立. 本文参照文[6]建议, 固定5k =.2.2 基于样本加权的特征独立性最大化在融合稳定学习的深度神经网络中, 通过LSWD 模块优化样本权重并最大化特征之间的独立性, 优化准则如下:,1,j |arg min |()m i j i L =<=∑w Conv (RFF(w ⨀i Q ), RFF(w ⨀2))||j F Q , T s.t.,n >=0w w e .其中1n i ⨯∈ Q 为网络输出的第i 个特征序列, ⨀为Hamard 乘积运算, 1n ⨯∈ w 为n 个样本的权重, e 为全1向量. 上述优化准则, 可使得深度神经网络输出特征两两之间相互独立.3 实验结果与分析3.1 实验数据与预处理实验数据来自网上公共数据库1000功能连接组计划(1000 Functional Connectomes Project, FCP). 该公共数据库收集了35个中心合计1355名被试的脑MRI 数据. 本实验使用了FCP 中3个中心的数据集, 分别为:北京(Beijing)、剑桥(Cambridge)和国际医学会议(ICBM)[11], 主要任务是使用其中的3D 脑结构MRI 数据完成性别分类. 其中, Beijing 数据集包含被试样本140个(男性70个/女性70个), Cambridge 数据集包含被试样本198个(男性75个/女性123个), ICBM 数据集包含被试样本86个(男性41个/女性45个).在Matlab 2015中使用SPM8工具包对原始脑结构MRI 数据进行如下数据预处理:第1步 脑影像颅骨剥离;第2步 分割去颅骨脑影像为灰质、白质和脑脊液3部分(本实验仅使用灰质数据);第3步 标准化预处理, 将脑影像统一配准到MNI(Montreal Neurological Institute)模版空间;第4步 去噪与平滑预处理, 使用高斯平滑方法平滑标准化灰质影像.预处理后, 最终得到尺寸大小为121×145×121的3D 结构影像.18 湖南理工学院学报(自然科学版) 第37卷此外, 为减少后续计算量, 通过尺度缩放操作将预处理后的3D 结构影像尺寸进一步缩小至64×64×64.然后使用Z-Score 标准化方法对每个中心的数据分别进行中心偏差校正.3.2 分类器参数设置分别测试了基准3D CNN 和融合稳定学习的3D CNN 的多中心脑MRI 分类性能. 其中3D CNN 架构部分,两种分类器均采用同样的网络架构和参数, 具体如下.网络层数设计为5层, 每层包含2个3D 卷积操作(with padding), 2个ReLU 非线性映射操作和1个3D maxpooling 操作(每层窗宽均为2). 其中, 第1层卷积核尺寸为7×7×7, 第2~5层卷积核尺寸均为3×3×3, 1~5层输出通道大小分别为32、64、128、256、512.使用Pytorch 1.12.0平台搭建网络. 训练时, 初始学习率固定为0.001, 使用Adam 优化器进行训练,batchsize 固定为128(男女样本各64个).3.3 跨中心性别分类实验采用域泛化实验设置LOSO(Leave One Site Out)来测试不同分类器的跨中心脑MRI 分类的泛化能力, 即留一个中心数据作为测试数据, 其他中心数据作为训练数据. 在训练过程中, 确保用于测试的中心数据完全隔离. 实验重复三次, 使用不同的随机种子, 取平均值作为最终结果. 跨中心分类平均正确率见表1.表1 跨中心分类平均正确率(%)对比方法 测试中心 总体平均分类正确率(Cambridge, ICBM)-Beijing (Beijing, ICBM)-Cambridge (Cambridge, Beijing)-ICBMbase 75.76 73.91 72.48 74.05stable 78.11 75.59 75.97 76.56* base: 基准3D CNN; stable: 融合稳定学习的3D CNN.由表1可知, 融合稳定学习的3D CNN 在(Cambridge, ICBM)-Beijing 、(Beijing, ICBM)-Cambridge 、(Cambridge, Beijing)-ICBM 三个LOSO 分类测试中平均分类正确率分别提升2.35、1.68、3.49个百分点, 总体平均类正确率则提升2.51个百分点. 实验结果验证了引入稳定学习后, 跨中心泛化性得到明显提升.进一步绘制三个LOSO 分类任务的PR(Precision-Recall)曲线和ROC(Receiver Operating Characteristic)曲线, 并计算AUC(Area Under the Curve), 以评估分类方法的跨中心预测性能, 如图2~3所示.(a) (Cambridge, ICBM)-Beijing (b) (Beijing, ICBM)-Cambridge(c) (Cambridge, Beijing)-ICBM图2 跨中心分类ROC 曲线(a) (Cambridge, ICBM)-Beijing (b) (Beijing, ICBM)-Cambridge(c) (Cambridge, Beijing)-ICBM图3 跨中心分类PR 曲线 图2显示, 在三个LOSO 分类任务中融合稳定学习的3D CNN 的ROC 曲线明显优于基准3D CNN, 其AUC 值也分别提升了0.01, 0.05和0.05. 此外, 由每个LOSO 分类的三次随机实验统计得到的标准差相比基第1期 杨 勃, 等: 引入稳定学习的多中心脑磁共振影像统计分类方法研究 19 准3D CNN 显著下降了1个数量级, 也很好地证实了融合稳定学习的3D CNN 具有很好的多中心分类稳定性. 图3中, 除第1个LOSO 分类任务无法确定两种方法的优劣外, 在后两个LOSO 分类任务上, 融合稳定学习的3D CNN 表现明显优于基准3D CNN.最后绘制三个LOSO 分类任务训练过程中测试正确率变化曲线, 结果如图4所示.(a) (Cambridge, ICBM)-Beijing (b) (Beijing, ICBM)-Cambridge(c) (Cambridge, Beijing)-ICBM图4 跨中心分类训练过程中测试正确率变化情况 图4显示, 三个LOSO 分类任务在训练迭代到100代后, 融合稳定学习的3D CNN 的测试分类正确率稳定优于基准3D CNN, 进一步展示了引入稳定学习的多中心脑MRI 分类的有效性.4 结束语为解决多中心脑MRI 分类的稳定性问题, 本文提出引入稳定学习的统计分类方法, 设计融合稳定学习的3D CNN 架构, 通过学习样本权重提升特征之间的统计独立性, 从而提高对未知中心数据的跨中心预测能力. 通过3中心公共数据集性别分类实验, 最后验证了融合稳定学习的3D CNN 分类模型的有效性. 实验表明, 将稳定学习引入多中心脑MRI 统计分类任务中, 可以改善跨中心分类方法的泛化性能, 从而进一步提高多中心脑MRI 统计分类的稳定性.参考文献:[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.[2] GEIRHOS R, RUBISCH P, MICHAELIS C, et al. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy androbustness[EB/OL]. (2018-11-29)[2024-3-20]. https:///abs/1811.12231.[3] ZENG L L, WANG H, HU P, et al. Multi-site diagnostic classification of schizophrenia using discriminant deep learning with functional connectivityMRI[J]. EBioMedicine, 2018, 30: 74−85.[4] 李文彬, 许雁玲, 钟志楷, 等. 基于稳定学习的图神经网络模型[J]. 湖南理工学院学报(自然科学版), 2023, 36(4): 16−18.[5] KUANG K, XIONG R, CUI P, et al. Stable prediction with model misspecification and agnostic distribution shift[C]//Proceedings of the AAAI Conferenceon Artificial Intelligence, 2020, 34(4): 4485−4492.[6] KUANG K, CUI P, ATHEY S, et al. Stable prediction across unknown environments[C]//Proceedings of the 24th ACM SIGKDD International Conferenceon Knowledge Discovery & Data Mining, New York: Association for Computing Machinery, 2018: 1617–1626.[7] ZHANG X, CUI P, XU R, et al. Deep stable learning for out-of-distribution generalization[C]// Proceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition, IEEE Computer Society, 2021: 5368−5378.[8] LI H, PAN S J, WANG S, et al. Domain generalization with adversarial feature learning[C]//Proceedings of the IEEE/CVF Conference on Computer Visionand Pattern Recognition, IEEE Computer Society, 2018: 5400−5409.[9] GRUBINGER T, BIRLUTIU A, SCHONER H, et al. Domain generalization based on transfer component analysis[C]//Proceedings of the 13th InternationalWork-Conference on Artificial Neural Networks, Springer, 2015: 325−334.[10] RAHIMI A, RECHT B. Random features for large-scale kernel machines[C]//Proceedings of the 20th International Conference on Neural InformationProcessing Systems, 2007: 1177–1184.[11] JIANG R, ABBOTT C C, JIANG T, et al. SMRI biomarkers predict electroconvulsive treatment outcomes: accuracy with independent data sets[J].Neuropsychopharmacology, 2018, 43(5): 1078−1087.。

集成梯度特征归属方法-概述说明以及解释1.引言1.1 概述在概述部分,你可以从以下角度来描述集成梯度特征归属方法的背景和重要性:集成梯度特征归属方法是一种用于分析和解释机器学习模型预测结果的技术。
随着机器学习的快速发展和广泛应用,对于模型的解释性需求也越来越高。
传统的机器学习模型通常被认为是“黑盒子”,即无法解释模型做出预测的原因。
这限制了模型在一些关键应用领域的应用,如金融风险评估、医疗诊断和自动驾驶等。
为了解决这个问题,研究人员提出了各种机器学习模型的解释方法,其中集成梯度特征归属方法是一种非常受关注和有效的技术。
集成梯度特征归属方法能够为机器学习模型的预测结果提供可解释的解释,从而揭示模型对于不同特征的关注程度和影响力。
通过分析模型中每个特征的梯度值,可以确定该特征在预测中扮演的角色和贡献度,从而帮助用户理解模型的决策过程。
这对于模型的评估、优化和改进具有重要意义。
集成梯度特征归属方法的应用广泛,不仅适用于传统的机器学习模型,如决策树、支持向量机和逻辑回归等,也可以应用于深度学习模型,如神经网络和卷积神经网络等。
它能够为各种类型的特征,包括数值型特征和类别型特征,提供有益的信息和解释。
本文将对集成梯度特征归属方法的原理、应用优势和未来发展进行详细阐述,旨在为读者提供全面的了解和使用指南。
在接下来的章节中,我们将首先介绍集成梯度特征归属方法的基本原理和算法,然后探讨应用该方法的优势和实际应用场景。
最后,我们将总结该方法的重要性,并展望未来该方法的发展前景。
1.2文章结构文章结构内容应包括以下内容:文章的结构部分主要是对整篇文章的框架进行概述,指导读者在阅读过程中能够清晰地了解文章的组织结构和内容安排。
第一部分是引言,介绍了整篇文章的背景和意义。
其中,1.1小节概述文章所要讨论的主题,简要介绍了集成梯度特征归属方法的基本概念和应用领域。
1.2小节重点在于介绍文章的结构,将列出本文各个部分的标题和内容概要,方便读者快速了解文章的大致内容。

基于边缘检测的抗遮挡相关滤波跟踪算法唐艺北方工业大学 北京 100144摘要:无人机跟踪目标因其便利性得到越来越多的关注。
基于相关滤波算法利用边缘检测优化样本质量,并在边缘检测打分环节加入平滑约束项,增加了候选框包含目标的准确度,达到降低计算复杂度、提高跟踪鲁棒性的效果。
利用自适应多特征融合增强特征表达能力,提高目标跟踪精准度。
引入遮挡判断机制和自适应更新学习率,减少遮挡对滤波模板的影响,提高目标跟踪成功率。
通过在OTB-2015和UAV123数据集上的实验进行定性定量的评估,论证了所研究算法相较于其他跟踪算法具有一定的优越性。
关键词:无人机 目标追踪 相关滤波 多特征融合 边缘检测中图分类号:TN713;TP391.41;TG441.7文献标识码:A 文章编号:1672-3791(2024)05-0057-04 The Anti-Occlusion Correlation Filtering Tracking AlgorithmBased on Edge DetectionTANG YiNorth China University of Technology, Beijing, 100144 ChinaAbstract: For its convenience, tracking targets with unmanned aerial vehicles is getting more and more attention. Based on the correlation filtering algorithm, the quality of samples is optimized by edge detection, and smoothing constraints are added to the edge detection scoring link, which increases the accuracy of targets included in candi⁃date boxes, and achieves the effects of reducing computational complexity and improving tracking robustness. Adap⁃tive multi-feature fusion is used to enhance the feature expression capability, which improves the accuracy of target tracking. The occlusion detection mechanism and the adaptive updating learning rate are introduced to reduce the impact of occlusion on filtering templates, which improves the success rate of target tracking. Qualitative evaluation and quantitative evaluation are conducted through experiments on OTB-2015 and UAV123 datasets, which dem⁃onstrates the superiority of the studied algorithm over other tracking algorithms.Key Words: Unmanned aerial vehicle; Target tracking; Correlation filtering; Multi-feature fusion; Edge detection近年来,无人机成为热点话题,具有不同用途的无人机频繁出现在大众视野。

AbstractCompressive sensing and sparse inversion methods have gained a significant amount of attention in recent years due to their capability to accurately reconstruct signals from measurements with significantly less data than previously possible. In this paper, a modified Gaussian frequency domain compressive sensing and sparse inversion method is proposed, which leverages the proven strengths of the traditional method to enhance its accuracy and performance. Simulation results demonstrate that the proposed method can achieve a higher signal-to- noise ratio and a better reconstruction quality than its traditional counterpart, while also reducing the computational complexity of the inversion procedure.IntroductionCompressive sensing (CS) is an emerging field that has garnered significant interest in recent years because it leverages the sparsity of signals to reduce the number of measurements required to accurately reconstruct the signal. This has many advantages over traditional signal processing methods, including faster data acquisition times, reduced power consumption, and lower data storage requirements. CS has been successfully applied to a wide range of fields, including medical imaging, wireless communications, and surveillance.One of the most commonly used methods in compressive sensing is the Gaussian frequency domain compressive sensing and sparse inversion (GFD-CS) method. In this method, compressive measurements are acquired by multiplying the original signal with a randomly generated sensing matrix. The measurements are then transformed into the frequency domain using the Fourier transform, and the sparse signal is reconstructed using a sparsity promoting algorithm.In recent years, researchers have made numerous improvementsto the GFD-CS method, with the goal of improving its reconstruction accuracy, reducing its computational complexity, and enhancing its robustness to noise. In this paper, we propose a modified GFD-CS method that combines several techniques to achieve these objectives.Proposed MethodThe proposed method builds upon the well-established GFD-CS method, with several key modifications. The first modification is the use of a hierarchical sparsity-promoting algorithm, which promotes sparsity at both the signal level and the transform level. This is achieved by applying the hierarchical thresholding technique to the coefficients corresponding to the higher frequency components of the transformed signal.The second modification is the use of a novel error feedback mechanism, which reduces the impact of measurement noise on the reconstructed signal. Specifically, the proposed method utilizes an iterative algorithm that updates the measurement error based on the difference between the reconstructed signal and the measured signal. This feedback mechanism effectively increases the signal-to-noise ratio of the reconstructed signal, improving its accuracy and robustness to noise.The third modification is the use of a low-rank approximation method, which reduces the computational complexity of the inversion algorithm while maintaining reconstruction accuracy. This is achieved by decomposing the sensing matrix into a product of two lower dimensional matrices, which can be subsequently inverted using a more efficient algorithm.Simulation ResultsTo evaluate the effectiveness of the proposed method, we conducted simulations using synthetic data sets. Three different signal types were considered: a sinusoidal signal, a pulse signal, and an image signal. The results of the simulations were compared to those obtained using the traditional GFD-CS method.The simulation results demonstrate that the proposed method outperforms the traditional GFD-CS method in terms of signal-to-noise ratio and reconstruction quality. Specifically, the proposed method achieves a higher signal-to-noise ratio and lower mean squared error for all three types of signals considered. Furthermore, the proposed method achieves these results with a reduced computational complexity compared to the traditional method.ConclusionThe results of our simulations demonstrate the effectiveness of the proposed method in enhancing the accuracy and performance of the GFD-CS method. The combination of sparsity promotion, error feedback, and low-rank approximation techniques significantly improves the signal-to-noise ratio and reconstruction quality, while reducing thecomputational complexity of the inversion procedure. Our proposed method has potential applications in a wide range of fields, including medical imaging, wireless communications, and surveillance.。

Secrets of Optical Flow Estimation and Their PrinciplesDeqing Sun Brown UniversityStefan RothTU DarmstadtMichael J.BlackBrown UniversityAbstractThe accuracy of opticalflow estimation algorithms has been improving steadily as evidenced by results on the Middlebury opticalflow benchmark.The typical formula-tion,however,has changed little since the work of Horn and Schunck.We attempt to uncover what has made re-cent advances possible through a thorough analysis of how the objective function,the optimization method,and mod-ern implementation practices influence accuracy.We dis-cover that“classical”flow formulations perform surpris-ingly well when combined with modern optimization and implementation techniques.Moreover,wefind that while medianfiltering of intermediateflowfields during optimiza-tion is a key to recent performance gains,it leads to higher energy solutions.To understand the principles behind this phenomenon,we derive a new objective that formalizes the medianfiltering heuristic.This objective includes a non-local term that robustly integratesflow estimates over large spatial neighborhoods.By modifying this new term to in-clude information aboutflow and image boundaries we de-velop a method that ranks at the top of the Middlebury benchmark.1.IntroductionThefield of opticalflow estimation is making steady progress as evidenced by the increasing accuracy of cur-rent methods on the Middlebury opticalflow benchmark [6].After nearly30years of research,these methods have obtained an impressive level of reliability and accuracy [33,34,35,40].But what has led to this progress?The majority of today’s methods strongly resemble the original formulation of Horn and Schunck(HS)[18].They combine a data term that assumes constancy of some image property with a spatial term that models how theflow is expected to vary across the image.An objective function combin-ing these two terms is then optimized.Given that this basic structure is unchanged since HS,what has enabled the per-formance gains of modern approaches?The paper has three parts.In thefirst,we perform an ex-tensive study of current opticalflow methods and models.The most accurate methods on the Middleburyflow dataset make different choices about how to model the objective function,how to approximate this model to make it com-putationally tractable,and how to optimize it.Since most published methods change all of these properties at once, it can be difficult to know which choices are most impor-tant.To address this,we define a baseline algorithm that is“classical”,in that it is a direct descendant of the original HS formulation,and then systematically vary the model and method using different techniques from the art.The results are surprising.Wefind that only a small number of key choices produce statistically significant improvements and that they can be combined into a very simple method that achieves accuracies near the state of the art.More impor-tantly,our analysis reveals what makes currentflow meth-ods work so well.Part two examines the principles behind this success.We find that one algorithmic choice produces the most signifi-cant improvements:applying a medianfilter to intermedi-ateflow values during incremental estimation and warping [33,34].While this heuristic improves the accuracy of the recoveredflowfields,it actually increases the energy of the objective function.This suggests that what is being opti-mized is actually a new and different ing ob-servations about medianfiltering and L1energy minimiza-tion from Li and Osher[23],we formulate a new non-local term that is added to the original,classical objective.This new term goes beyond standard local(pairwise)smoothness to robustly integrate information over large spatial neigh-borhoods.We show that minimizing this new energy ap-proximates the original optimization with the heuristic me-dianfiltering step.Note,however,that the new objective falls outside our definition of classical methods.Finally,once the medianfiltering heuristic is formulated as a non-local term in the objective,we immediately recog-nize how to modify and improve it.In part three we show how information about image structure andflow boundaries can be incorporated into a weighted version of the non-local term to prevent over-smoothing across boundaries.By in-corporating structure from the image,this weighted version does not suffer from some of the errors produced by median filtering.At the time of publication(March2010),the re-sulting approach is ranked1st in both angular and end-point errors in the Middlebury evaluation.In summary,the contributions of this paper are to(1)an-alyze currentflow models and methods to understand which design choices matter;(2)formulate and compare several classical objectives descended from HS using modern meth-ods;(3)formalize one of the key heuristics and derive a new objective function that includes a non-local term;(4)mod-ify this new objective to produce a state-of-the-art method. In doing this,we provide a“recipe”for others studying op-ticalflow that can guide their design choices.Finally,to en-able comparison and further innovation,we provide a public M ATLAB implementation[1].2.Previous WorkIt is important to separately analyze the contributions of the objective function that defines the problem(the model) and the optimization algorithm and implementation used to minimize it(the method).The HS formulation,for example, has long been thought to be highly inaccurate.Barron et al.[7]reported an average angular error(AAE)of~30degrees on the“Yosemite”sequence.This confounds the objective function with the particular optimization method proposed by Horn and Schunck1.When optimized with today’s meth-ods,the HS objective achieves surprisingly competitive re-sults despite the expected over-smoothing and sensitivity to outliers.Models:The global formulation of opticalflow intro-duced by Horn and Schunck[18]relies on both brightness constancy and spatial smoothness assumptions,but suffers from the fact that the quadratic formulation is not robust to outliers.Black and Anandan[10]addressed this by re-placing the quadratic error function with a robust formula-tion.Subsequently,many different robust functions have been explored[12,22,31]and it remains unclear which is best.We refer to all these spatially-discrete formulations derived from HS as“classical.”We systematically explore variations in the formulation and optimization of these ap-proaches.The surprise is that the classical model,appropri-ately implemented,remains very competitive.There are many formulations beyond the classical ones that we do not consider here.Significant ones use oriented smoothness[25,31,33,40],rigidity constraints[32,33], or image segmentation[9,21,41,37].While they deserve similar careful consideration,we expect many of our con-clusions to carry forward.Note that one can select among a set of models for a given sequence[4],instead offinding a “best”model for all the sequences.Methods:Many of the implementation details that are thought to be important date back to the early days of op-1They noted that the correct way to optimize their objective is by solv-ing a system of linear equations as is common today.This was impractical on the computers of the day so they used a heuristic method.ticalflow.Current best practices include coarse-to-fine es-timation to deal with large motions[8,13],texture decom-position[32,34]or high-orderfilter constancy[3,12,16, 22,40]to reduce the influence of lighting changes,bicubic interpolation-based warping[22,34],temporal averaging of image derivatives[17,34],graduated non-convexity[11]to minimize non-convex energies[10,31],and medianfilter-ing after each incremental estimation step to remove outliers [34].This medianfiltering heuristic is of particular interest as it makes non-robust methods more robust and improves the accuracy of all methods we tested.The effect on the objec-tive function and the underlying reason for its success have not previously been analyzed.Least median squares estima-tion can be used to robustly reject outliers inflow estimation [5],but previous work has focused on the data term.Related to medianfiltering,and our new non-local term, is the use of bilateralfiltering to prevent smoothing across motion boundaries[36].The approach separates a varia-tional method into twofiltering update stages,and replaces the original anisotropic diffusion process with multi-cue driven bilateralfiltering.As with medianfiltering,the bi-lateralfiltering step changes the original energy function.Models that are formulated with an L1robust penalty are often coupled with specialized total variation(TV)op-timization methods[39].Here we focus on generic opti-mization methods that can apply to any model andfind they perform as well as reported results for specialized methods.Despite recent algorithmic advances,there is a lack of publicly available,easy to use,and accurateflow estimation software.The GPU4Vision project[2]has made a substan-tial effort to change this and provides executablefiles for several accurate methods[32,33,34,35].The dependence on the GPU and the lack of source code are limitations.We hope that our public M ATLAB code will not only help in un-derstanding the“secrets”of opticalflow,but also let others exploit opticalflow as a useful tool in computer vision and relatedfields.3.Classical ModelsWe write the“classical”opticalflow objective function in its spatially discrete form asE(u,v)=∑i,j{ρD(I1(i,j)−I2(i+u i,j,j+v i,j))(1)+λ[ρS(u i,j−u i+1,j)+ρS(u i,j−u i,j+1)+ρS(v i,j−v i+1,j)+ρS(v i,j−v i,j+1)]}, where u and v are the horizontal and vertical components of the opticalflowfield to be estimated from images I1and I2,λis a regularization parameter,andρD andρS are the data and spatial penalty functions.We consider three different penalty functions:(1)the quadratic HS penaltyρ(x)=x2;(2)the Charbonnier penaltyρ(x)=√x2+ 2[13],a dif-ferentiable variant of the L1norm,the most robust convexfunction;and(3)the Lorentzianρ(x)=log(1+x22σ2),whichis a non-convex robust penalty used in[10].Note that this classical model is related to a standard pairwise Markov randomfield(MRF)based on a4-neighborhood.In the remainder of this section we define a baseline method using several techniques from the literature.This is not the“best”method,but includes modern techniques and will be used for comparison.We only briefly describe the main choices,which are explored in more detail in the following section and the cited references,especially[30].Quantitative results are presented throughout the remain-der of the text.In all cases we report the average end-point error(EPE)on the Middlebury training and test sets,de-pending on the experiment.Given the extensive nature of the evaluation,only average results are presented in the main body,while the details for each individual sequence are given in[30].3.1.Baseline methodsTo gain robustness against lighting changes,we follow [34]and apply the Rudin-Osher-Fatemi(ROF)structure texture decomposition method[28]to pre-process the in-put sequences and linearly combine the texture and struc-ture components(in the proportion20:1).The parameters are set according to[34].Optimization is performed using a standard incremental multi-resolution technique(e.g.[10,13])to estimateflow fields with large displacements.The opticalflow estimated at a coarse level is used to warp the second image toward thefirst at the nextfiner level,and aflow increment is cal-culated between thefirst image and the warped second im-age.The standard deviation of the Gaussian anti-aliasingfilter is set to be1√2d ,where d denotes the downsamplingfactor.Each level is recursively downsampled from its near-est lower level.In building the pyramid,the downsampling factor is not critical as pointed out in the next section and here we use the settings in[31],which uses a factor of0.8 in thefinal stages of the optimization.We adaptively de-termine the number of pyramid levels so that the top level has a width or height of around20to30pixels.At each pyramid level,we perform10warping steps to compute the flow increment.At each warping step,we linearize the data term,whichinvolves computing terms of the type∂∂x I2(i+u k i,j,j+v k i,j),where∂/∂x denotes the partial derivative in the horizon-tal direction,u k and v k denote the currentflow estimate at iteration k.As suggested in[34],we compute the deriva-tives of the second image using the5-point derivativefilter1 12[−180−81],and warp the second image and its deriva-tives toward thefirst using the currentflow estimate by bicu-bic interpolation.We then compute the spatial derivatives ofAvg.Rank Avg.EPEClassic-C14.90.408HS24.60.501Classic-L19.80.530HS[31]35.10.872BA(Classic-L)[31]30.90.746Adaptive[33]11.50.401Complementary OF[40]10.10.485Table1.Models.Average rank and end-point error(EPE)on the Middlebury test set using different penalty functions.Two current methods are included for comparison.thefirst image,average with the warped derivatives of the second image(c.f.[17]),and use this in place of∂I2∂x.For pixels moving out of the image boundaries,we set both their corresponding temporal and spatial derivatives to zero.Af-ter each warping step,we apply a5×5medianfilter to the newly computedflowfield to remove outliers[34].For the Charbonnier(Classic-C)and Lorentzian (Classic-L)penalty function,we use a graduated non-convexity(GNC)scheme[11]as described in[31]that lin-early combines a quadratic objective with a robust objective in varying proportions,from fully quadratic to fully robust. Unlike[31],a single regularization weightλis used for both the quadratic and the robust objective functions.3.2.Baseline resultsThe regularization parameterλis selected among a set of candidate values to achieve the best average end-point error (EPE)on the Middlebury training set.For the Charbonnier penalty function,the candidate set is[1,3,5,8,10]and 5is optimal.The Charbonnier penalty uses =0.001for both the data and the spatial term in Eq.(1).The Lorentzian usesσ=1.5for the data term,andσ=0.03for the spa-tial term.These parameters arefixed throughout the exper-iments,except where mentioned.Table1summarizes the EPE results of the basic model with three different penalty functions on the Middlebury test set,along with the two top performers at the time of publication(considering only published papers).The clas-sic formulations with two non-quadratic penalty functions (Classic-C)and(Classic-L)achieve competitive results de-spite their simplicity.The baseline optimization of HS and BA(Classic-L)results in significantly better accuracy than previously reported for these models[31].Note that the analysis also holds for the training set(Table2).At the time of publication,Classic-C ranks13th in av-erage EPE and15th in AAE in the Middlebury benchmark despite its simplicity,and it serves as the baseline below.It is worth noting that the spatially discrete MRF formulation taken here is competitive with variational methods such as [33].Moreover,our baseline implementation of HS has a lower average EPE than many more sophisticated methods.Avg.EPE significance p-value Classic-C0.298——HS0.38410.0078Classic-L0.31910.0078Classic-C-brightness0.28800.9453HS-brightness0.38710.0078Classic-L-brightness0.32500.2969Gradient0.30500.4609Table2.Pre-Processing.Average end-point error(EPE)on the Middlebury training set for the baseline method(Classic-C)using different pre-processing techniques.Significance is always with respect to Classic-C.4.Secrets ExploredWe evaluate a range of variations from the baseline ap-proach that have appeared in the literature,in order to illu-minate which may be of importance.This analysis is per-formed on the Middlebury training set by changing only one property at a time.Statistical significance is determined using a Wilcoxon signed rank test between each modified method and the baseline Classic-C;a p value less than0.05 indicates a significant difference.Pre-Processing.For each method,we optimize the regu-larization parameterλfor the training sequences and report the results in Table2.The baseline uses a non-linear pre-filtering of the images to reduce the influence of illumina-tion changes[34].Table2shows the effect of removing this and using a standard brightness constancy model(*-brightness).Classic-C-brightness actually achieves lower EPE on the training set than Classic-C but significantly lower accuracy on the test set:Classic-C-brightness= 0.726,HS-brightness=0.759,and Classic-L-brightness =0.603–see Table1for comparison.This disparity sug-gests overfitting is more severe for the brightness constancy assumption.Gradient only imposes constancy of the gra-dient vector at each pixel as proposed in[12](i.e.it robustly penalizes Euclidean distance between image gradients)and has similar performance in both training and test sets(c.f. Table8).See[30]for results of more alternatives. Secrets:Some form of imagefiltering is useful but simple derivative constancy is nearly as good as the more sophisti-cated texture decomposition method.Coarse-to-fine estimation and GNC.We vary the number of warping steps per pyramid level andfind that3warping steps gives similar results as using10(Table3).For the GNC scheme,[31]uses a downsampling factor of0.8for non-convex optimization.A downsampling factor of0.5 (Down-0.5),however,has nearly identical performance Removing the GNC step for the Charbonnier penalty function(w/o GNC)results in higher EPE on most se-quences and higher energy on all sequences(Table4).This suggests that the GNC method is helpful even for the con-vex Charbonnier penalty function due to the nonlinearity ofAvg.EPE significance p-value Classic-C0.298——3warping steps0.30400.9688Down-0.50.2980 1.0000w/o GNC0.35400.1094Bilinear0.30200.1016w/o TA VG0.30600.1562Central derivativefilter0.30000.72667-point derivativefilter[13]0.30200.3125Bicubic-II0.29010.0391GC-0.45(λ=3)0.29210.0156GC-0.25(λ=0.7)0.2980 1.0000MF3×30.30500.1016MF7×70.30500.56252×MF0.3000 1.00005×MF0.30500.6875w/o MF0.35210.0078Classic++0.28510.0078 Table3.Model and Methods.Average end-point error(EPE)on the Middlebury training set for the baseline method(Classic-C) using different algorithm and modelingchoices.Figure1.Different penalty functions for the spatial terms:Char-bonnier( =0.001),generalized Charbonnier(a=0.45and a=0.25),and Lorentzian(σ=0.03).the data term.Secrets:The downsampling factor does not matter when using a convex penalty;a standard factor of0.5isfine. Some form of GNC is useful even for a convex robust penalty like Charbonnier because of the nonlinear data term. Interpolation method and derivatives.Wefind that bicu-bic interpolation is more accurate than bilinear(Table3, Bilinear),as already reported in previous work[34].Re-moving temporal averaging of the gradients(w/o TA VG), using Central differencefilters,or using a7-point deriva-tivefilter[13]all reduce accuracy compared to the base-line,but not significantly.The M ATLAB built-in function interp2is based on cubic convolution approximation[20]. The spline-based interpolation scheme[26]is consistently better(Bicubic-II).See[30]for more discussions. Secrets:Use spline-based bicubic interpolation with a5-pointfilter.Temporal averaging of the derivatives is proba-bly worthwhile for a small computational expense. Penalty functions.Wefind that the convex Charbonnier penalty performs better than the more robust,non-convex Lorentzian on both the training and test sets.One reason might be that non-convex functions are more difficult to op-timize,causing the optimization scheme tofind a poor local(a)With medianfiltering(b)Without medianfilteringFigure2.Estimatedflowfields on sequence“RubberWhale”using Classic-C with and without(w/o MF)the medianfiltering step. Color coding as in[6].(a)(w/MF)energy502,387and(b)(w/o MF)energy449,290.The medianfiltering step helps reach a so-lution free from outliers but with a higher energy.optimum.We investigate a generalized Charbonnier penalty functionρ(x)=(x2+ 2)a that is equal to the Charbon-nier penalty when a=0.5,and non-convex when a<0.5 (see Figure1).We optimize the regularization parameterλagain.Wefind a slightly non-convex penalty with a=0.45 (GC-0.45)performs consistently better than the Charbon-nier penalty,whereas more non-convex penalties(GC-0.25 with a=0.25)show no improvement.Secrets:The less-robust Charbonnier is preferable to the Lorentzian and a slightly non-convex penalty function(GC-0.45)is better still.Medianfiltering.The baseline5×5medianfilter(MF 5×5)is better than both MF3×3[34]and MF7×7but the difference is not significant(Table3).When we perform5×5medianfiltering twice(2×MF)orfive times(5×MF)per warping step,the results are worse.Finally,removing the medianfiltering step(w/o MF)makes the computedflow significantly less accurate with larger outliers as shown in Table3and Figure2.Secrets:Medianfiltering the intermediateflow results once after every warping iteration is the single most important secret;5×5is a goodfilter size.4.1.Best PracticesCombining the analysis above into a single approach means modifying the baseline to use the slightly non-convex generalized Charbonnier and the spline-based bicu-bic interpolation.This leads to a statistically significant improvement over the baseline(Table3,Classic++).This method is directly descended from HS and BA,yet updated with the current best optimization practices known to us. This simple method ranks9th in EPE and12th in AAE on the Middlebury test set.5.Models Underlying Median FilteringOur analysis reveals the practical importance of median filtering during optimization to denoise theflowfield.We ask whether there is a principle underlying this heuristic?One interesting observation is thatflowfields obtained with medianfiltering have substantially higher energy than those without(Table4and Figure2).If the medianfilter is helping to optimize the objective,it should lead to lower energies.Higher energies and more accurate estimates sug-gest that incorporating medianfiltering changes the objec-tive function being optimized.The insight that follows from this is that the medianfil-tering heuristic is related to the minimization of an objective function that differs from the classical one.In particular the optimization of Eq.(1),with interleaved medianfiltering, approximately minimizesE A(u,v,ˆu,ˆv)=(2)∑i,j{ρD(I1(i,j)−I2(i+u i,j,j+v i,j))+λ[ρS(u i,j−u i+1,j)+ρS(u i,j−u i,j+1)+ρS(v i,j−v i+1,j)+ρS(v i,j−v i,j+1)]}+λ2(||u−ˆu||2+||v−ˆv||2)+∑i,j∑(i ,j )∈N i,jλ3(|ˆu i,j−ˆu i ,j |+|ˆv i,j−ˆv i ,j |),whereˆu andˆv denote an auxiliaryflowfield,N i,j is the set of neighbors of pixel(i,j)in a possibly large area andλ2 andλ3are scalar weights.The term in braces is the same as theflow energy from Eq.(1),while the last term is new. This non-local term[14,15]imposes a particular smooth-ness assumption within a specified region of the auxiliary flowfieldˆu,ˆv2.Here we take this term to be a5×5rectan-gular region to match the size of the medianfilter in Classic-C.A third(coupling)term encouragesˆu,ˆv and u,v to be the same(c.f.[33,39]).The connection to medianfiltering(as a denoising method)derives from the fact that there is a direct relation-ship between the median and L1minimization.Consider a simplified version of Eq.(2)with just the coupling and non-local terms,where E(ˆu)=λ2||u−ˆu||2+∑i,j∑(i ,j )∈N i,jλ3|ˆu i,j−ˆu i ,j |.(3)While minimizing this is similar to medianfiltering u,there are two differences.First,the non-local term minimizes the L1distance between the central value and allflow values in its neighborhood except itself.Second,Eq.(3)incorpo-rates information about the data term through the coupling equation;medianfiltering theflow ignores the data term.The formal connection between Eq.(3)and medianfil-tering3is provided by Li and Osher[23]who show that min-2Bruhn et al.[13]also integrated information over a local region in a global method but did so for the data term.3Hsiao et al.[19]established the connection in a slightly different way.Classic-C 0.5890.7480.8660.502 1.816 2.317 1.126 1.424w/o GNC 0.5930.7500.8700.506 1.845 2.518 1.142 1.465w/o MF0.5170.7010.6680.449 1.418 1.830 1.066 1.395Table 4.Eq.(1)energy (×106)for the optical flow fields computed on the Middlebury training set .Note that Classic-C uses graduated non-convexity (GNC),which reduces the energy,and median filtering,which increases it.imizing Eq.(3)is related to a different median computationˆu (k +1)i,j=median (Neighbors (k )∪Data)(4)where Neighbors (k )={ˆu (k )i ,j }for (i ,j )∈N i,j and ˆu (0)=u as well as Data ={u i,j ,u i,j ±λ3λ2,u i,j±2λ3λ2···,u i,j ±|N i,j |λ32λ2},where |N i,j |denotes the (even)number of neighbors of (i,j ).Note that the set of “data”values is balanced with an equal number of elements on either side of the value u i,j and that information about the data term is included through u i,j .Repeated application of Eq.(4)converges rapidly [23].Observe that,as λ3/λ2increases,the weighted data val-ues on either side of u i,j move away from the values of Neighbors and cancel each other out.As this happens,Eq.(4)approximates the median at the first iterationˆu (1)i,j ≈median (Neighbors (0)∪{u i,j }).(5)Eq.(2)thus combines the original objective with an ap-proximation to the median,the influence of which is con-trolled by λ3/λ2.Note in practice the weight λ2on thecoupling term is usually small or is steadily increased from small values [34,39].We optimize the new objective (2)by alternately minimizingE O (u ,v )=∑i,jρD (I 1(i,j )−I 2(i +u i,j ,j +v i,j ))+λ[ρS (u i,j −u i +1,j )+ρS (u i,j −u i,j +1)+ρS (v i,j −v i +1,j )+ρS (v i,j −v i,j +1)]+λ2(||u −ˆu ||2+||v −ˆv ||2)(6)andE M (ˆu ,ˆv )=λ2(||u −ˆu ||2+||v −ˆv ||2)(7)+∑i,j ∑(i ,j )∈N i,jλ3(|ˆu i,j −ˆu i ,j |+|ˆv i,j −ˆv i ,j |).Note that an alternative formulation would drop the cou-pling term and impose the non-local term directly on u and v .We find that optimization of the coupled set of equations is superior in terms of EPE performance.The alternating optimization strategy first holds ˆu ,ˆv fixed and minimizes Eq.(6)w.r.t.u ,v .Then,with u ,v fixed,we minimize Eq.(7)w.r.t.ˆu ,ˆv .Note that Eqs.(3)andAvg.EPE significancep -value Classic-C0.298——Classic-C-A0.30500.8125Table 5.Average end-point error (EPE)on the Middlebury train-ing set is shown for the new model with alternating optimization (Classic-C-A ).(7)can be minimized by repeated application of Eq.(4);weuse this approach with 5iterations.We perform 10steps of alternating optimizations at every pyramid level and change λ2logarithmically from 10−4to 102.During the first and second GNC stages,we set u ,v to be ˆu ,ˆv after every warp-ing step (this step helps reach solutions with lower energy and EPE [30]).In the end,we take ˆu ,ˆv as the final flow field estimate.The other parameters are λ=5,λ3=1.Alternatingly optimizing this new objective function (Classic-C-A )leads to similar results as the baseline Classic-C (Table 5).We also compare the energy of these solutions using the new objective and find the alternat-ing optimization produces the lowest energy solutions,as shown in Table 6.To do so,we set both the flow field u ,v and the auxiliary flow field ˆu ,ˆv to be the same in Eq.(2).In summary,we show that the heuristic median filter-ing step in Classic-C can now be viewed as energy min-imization of a new objective with a non-local term.The explicit formulation emphasizes the value of robustly inte-grating information over large neighborhoods and enables the improved model described below.6.Improved ModelBy formalizing the median filtering heuristic as an ex-plicit objective function,we can find ways to improve it.While median filtering in a large neighborhood has advan-tages as we have seen,it also has problems.A neighborhood centered on a corner or thin structure is dominated by the surround and computing the median results in oversmooth-ing as illustrated in Figure 3(a).Examining the non-local term suggests a solution.For a given pixel,if we know which other pixels in the area be-long to the same surface,we can weight them more highly.The modification to the objective function is achieved by introducing a weight into the non-local term [14,15]:∑i,j ∑(i ,j )∈N i,jw i,j,i ,j (|ˆu i,j −ˆu i ,j |+|ˆv i,j −ˆv i ,j |),(8)where w i,j,i ,j represents how likely pixel i ,j is to belongto the same surface as i,j .。


目标跟踪的研究背景意义方法及现状目录• 1.课题背景与研究意义• 2.国内外研究现状• 3.存在的问题• 4.总结,发展与展望• 5.参考文献1课题背景与研究意义•运动目标的跟踪就是在视频图像的每一幅图像中确定出我们感兴趣的运动目标的位置,并把不同帧中同一目标对应起来。
•智能视频监控(IVS: Intelligent Video Surveillance)是计算机视觉领域近几年来发展较快,研究较多的一个应用方向。
它能够利用计算机视觉技术对采集到的视频信号进行处理、分析和理解,并以此为基础对视频监控系统进行控制,从而使视频监控系统具备更好的智能性和鲁棒性。
智能视频监控系统主要涉及到图像处理、计算机视觉、模式识别、人工智能等方面的科学知识,它的用途非常广泛,在民用和军事领域中都有着极大的应用前景。
2.国内外研究现状视频目标跟踪算法基于对比度分析基于匹配核方法运动检测其它方法特征匹配贝叶斯跟踪Meanshift方法光流法基于对比度分析的方法•算法思想:基于对比度分析的目标跟踪算法利用目标与背景在对比度上的差异来提取、识别和跟踪目标。
•分类:边缘跟踪,型心跟踪,质心跟踪。
•优缺点:不适合复杂背景中的目标跟踪,但在空中背景下的目标跟踪中非常有效。
基于特征匹配的目标跟踪算法•算法思想:基于匹配的目标跟踪算法需要提取目标的特征,并在每一帧中寻找该特征。
寻找的过程就是特征匹配过程。
•目标跟踪中用到的特征主要有几何形状、子空间特征、外形轮廓和特征点等。
其中,特征点是匹配算法中常用的特征。
特征点的提取算法很多,如Kanade Lucas Tomasi(KLT)算法、Harris 算法、SIFT 算法以及SURF 算法等。
•优缺点:特征点一般是稀疏的,携带的信息较少,可以通过集成前几帧的信息进行补偿。
目标在运动过程中,其特征(如姿态、几何形状、灰度或颜色分布等)也随之变化。
目标特征的变化具有随机性,这种随机变化可以采用统计数学的方法来描述。
CVPR2013总结前不久的结果出来了,⾸先恭喜我⼀个已经毕业⼯作的师弟中了⼀篇。
完整的⽂章列表已经在CVPR的主页上公布了(),今天把其中⼀些感兴趣的整理⼀下,虽然论⽂下载的链接⼤部分还都没出来,不过可以follow最新动态。
等下载链接出来的时候⼀⼀补上。
由于没有下载链接,所以只能通过题⽬和作者估计⼀下论⽂的内容。
难免有偏差,等看了论⽂以后再修正。
显著性Saliency Aggregation: A Data-driven Approach Long Mai, Yuzhen Niu, Feng Liu 现在还没有搜到相关的资料,应该是多线索的⾃适应融合来进⾏显著性检测的PISA: Pixelwise Image Saliency by Aggregating Complementary Appearance Contrast Measures with Spatial Priors Keyang Shi, Keze Wang, Jiangbo Lu, Liang Lin 这⾥的两个线索看起来都不新,应该是集成框架⽐较好。
⽽且像素级的,估计能达到分割或者matting的效果Looking Beyond the Image: Unsupervised Learning for Object Saliency and Detection Parthipan Siva, Chris Russell, Tao Xiang, 基于学习的的显著性检测Learning video saliency from human gaze using candidate selection , Dan Goldman, Eli Shechtman, Lihi Zelnik-Manor这是⼀个做视频显著性的,估计是选择显著的视频⽬标Hierarchical Saliency Detection Qiong Yan, Li Xu, Jianping Shi, Jiaya Jia的学⽣也开始做显著性了,多尺度的⽅法Saliency Detection via Graph-Based Manifold Ranking Chuan Yang, Lihe Zhang, Huchuan Lu, Ming-Hsuan Yang, Xiang Ruan这个应该是扩展了那个经典的 graph based saliency,应该是⽤到了显著性传播的技巧Salient object detection: a discriminative regional feature integration approach , Jingdong Wang, Zejian Yuan, , Nanning Zheng⼀个多特征⾃适应融合的显著性检测⽅法Submodular Salient Region Detection , Larry Davis⼜是⼤⽜下⾯的⽂章,提法也很新颖,⽤了submodular。
一种用于谱聚类图像分割的像素相似度计算方法
纳跃跃;于剑
【期刊名称】《南京大学学报:自然科学版》
【年(卷),期】2013()2
【摘要】图像分割是许多计算机视觉任务中的关键步骤,而谱聚类算法是目前图像分割的主要方法之一.为了使用谱聚类算法进行图像分割,首先需要计算用于反映像素间相似程度的相似矩阵,所采用的相似度计算方法是否能真实的反映出像素间的视觉相似度将显著影响算法的输出结果.针对普聚类图像分割算法的相似度计算问题,提出了一种新的像素间相似度计算方法.与传统方法相比,该方法不但考虑了像素自身的特征,而且考虑了其邻域内像素的视觉特征,以及两像素之间的边缘信息,使得计算所得的相似度更加符合人类的直观感受,且不易受到纹理的影响.另外,提出了一种针对该相似度计算方法的相似矩阵构造方法.在BSDS300图像库上的实验表明,使用该相似度能得到较好的图像分割结果.
【总页数】10页(P159-168)
【关键词】相似度;相似矩阵;谱聚类;图像分割
【作者】纳跃跃;于剑
【作者单位】北京交通大学计算机与信息技术学院
【正文语种】中文
【中图分类】TP391.41
【相关文献】
1.基于相似度矩阵的谱聚类集成图像分割 [J], 张琦;卢志茂;徐森;刘晨;隋毅
2.基于改进的相似度度量的谱聚类图像分割方法 [J], 邹旭华;叶晓东;谭治英;陆凯
3.谱聚类图像分割中相似度矩阵构造研究 [J], 李扬;陆璐;崔红霞
4.一种基于自适应超像素的改进谱聚类图像分割方法 [J], 覃正优;林一帆;陈瑜萍;林富强
5.一种新的基于超像素的谱聚类图像分割算法 [J], 高尚兵;周静波;严云洋
因版权原因,仅展示原文概要,查看原文内容请购买。
基于低秩约束的熵加权多视角模糊聚类算法张嘉旭 1王 骏 1, 2张春香 1林得富 1周 塔 3王士同1摘 要 如何有效挖掘多视角数据内部的一致性以及差异性是构建多视角模糊聚类算法的两个重要问题. 本文在Co-FKM 算法框架上, 提出了基于低秩约束的熵加权多视角模糊聚类算法(Entropy-weighting multi-view fuzzy C-means with low rank constraint, LR-MVEWFCM). 一方面, 从视角之间的一致性出发, 引入核范数对多个视角之间的模糊隶属度矩阵进行低秩约束; 另一方面, 基于香农熵理论引入视角权重自适应调整策略, 使算法根据各视角的重要程度来处理视角间的差异性. 本文使用交替方向乘子法(Alternating direction method of multipliers, ADMM)进行目标函数的优化. 最后, 人工模拟数据集和UCI (University of California Irvine)数据集上进行的实验结果验证了该方法的有效性.关键词 多视角模糊聚类, 香农熵, 低秩约束, 核范数, 交替方向乘子法引用格式 张嘉旭, 王骏, 张春香, 林得富, 周塔, 王士同. 基于低秩约束的熵加权多视角模糊聚类算法. 自动化学报, 2022,48(7): 1760−1770DOI 10.16383/j.aas.c190350Entropy-weighting Multi-view Fuzzy C-means With Low Rank ConstraintZHANG Jia-Xu 1 WANG Jun 1, 2 ZHANG Chun-Xiang 1 LIN De-Fu 1 ZHOU Ta 3 WANG Shi-Tong 1Abstract Effective mining both internal consistency and diversity of multi-view data is important to develop multi-view fuzzy clustering algorithms. In this paper, we propose a novel multi-view fuzzy clustering algorithm called en-tropy-weighting multi-view fuzzy c-means with low-rank constraint (LR-MVEWFCM). On the one hand, we intro-duce the nuclear norm as the low-rank constraint of the fuzzy membership matrix. On the other hand, the adaptive adjustment strategy of view weight is introduced to control the differences among views according to the import-ance of each view. The learning criterion can be optimized by the alternating direction method of multipliers (ADMM). Experimental results on both artificial and UCI (University of California Irvine) datasets show the effect-iveness of the proposed method.Key words Multi-view fuzzy clustering, Shannon entropy, low-rank constraint, nuclear norm, alternating direction method of multipliers (ADMM)Citation Zhang Jia-Xu, Wang Jun, Zhang Chun-Xiang, Lin De-Fu, Zhou Ta, Wang Shi-Tong. Entropy-weighting multi-view fuzzy C-means with low rank constraint. Acta Automatica Sinica , 2022, 48(7): 1760−1770随着多样化信息获取技术的发展, 人们可以从不同途径或不同角度来获取对象的特征数据, 即多视角数据. 多视角数据包含了同一对象不同角度的信息. 例如: 网页数据中既包含网页内容又包含网页链接信息; 视频内容中既包含视频信息又包含音频信息; 图像数据中既涉及颜色直方图特征、纹理特征等图像特征, 又涉及描述该图像内容的文本.多视角学习能有效地对多视角数据进行融合, 避免了单视角数据数据信息单一的问题[1−4].多视角模糊聚类是一种有效的无监督多视角学习方法[5−7]. 它通过在多视角聚类过程中引入各样本对不同类别的模糊隶属度来描述各视角下样本属于该类别的不确定性程度. 经典的工作有: 文献[8]以经典的单视角模糊C 均值(Fuzzy C-means, FCM)算法作为基础模型, 利用不同视角间的互补信息确定协同聚类的准则, 提出了Co-FC (Collaborative fuzzy clustering)算法; 文献[9]参考文献[8]的协同思想提出Co-FKM (Multiview fuzzy clustering algorithm collaborative fuzzy K-means)算法, 引入双视角隶属度惩罚项, 构造了一种新型的无监督多视角协同学习方法; 文献[10]借鉴了Co-FKM 和Co-FC 所使用的双视角约束思想, 通过引入视角权重, 并采用集成策略来融合多视角的模糊隶属收稿日期 2019-05-09 录用日期 2019-07-17Manuscript received May 9, 2019; accepted July 17, 2019国家自然科学基金(61772239), 江苏省自然科学基金(BK20181339)资助Supported by National Natural Science Foundation of China (61772239) and Natural Science Foundation of Jiangsu Province (BK20181339)本文责任编委 刘艳军Recommended by Associate Editor LIU Yan-Jun1. 江南大学数字媒体学院 无锡 2141222. 上海大学通信与信息工程学院 上海 2004443. 江苏科技大学电子信息学院 镇江2121001. School of Digital Media, Jiangnan University, Wuxi 2141222. School of Communication and Information Engineering,Shanghai University, Shanghai 2004443. School of Electronic Information, Jiangsu University of Science and Technology,Zhenjiang 212100第 48 卷 第 7 期自 动 化 学 报Vol. 48, No. 72022 年 7 月ACTA AUTOMATICA SINICAJuly, 2022度矩阵, 提出了WV-Co-FCM (Weighted view colla-borative fuzzy C-means) 算法; 文献[11]通过最小化双视角下样本与聚类中心的欧氏距离来减小不同视角间的差异性, 基于K-means 聚类框架提出了Co-K-means (Collaborative multi-view K-means clustering)算法; 在此基础上, 文献[12]提出了基于模糊划分的TW-Co-K-means (Two-level wei-ghted collaborative K-means for multi-view clus-tering)算法, 对Co-K-means 算法中的双视角欧氏距离加入一致性权重, 获得了比Co-K-means 更好的多视角聚类结果. 以上多视角聚类方法都基于成对视角来构造不同的正则化项来挖掘视角之间的一致性和差异性信息, 缺乏对多个视角的整体考虑.一致性和差异性是设计多视角聚类算法需要考虑的两个重要原则[10−14]. 一致性是指在多视角聚类过程中, 各视角的聚类结果应该尽可能保持一致.在设计多视角聚类算法时, 往往通过协同、集成等手段来构建全局划分矩阵, 从而得到最终的聚类结果[14−16]. 差异性是指多视角数据中的每个视角均反映了对象在不同方面的信息, 这些信息互为补充[10],在设计多视角聚类算法时需要对这些信息进行充分融合. 综合考虑这两方面的因素, 本文拟提出新型的低秩约束熵加权多视角模糊聚类算法(Entropy-weigh-ting multi-view fuzzy C-means with low rank con-straint, LR-MVEWFCM), 其主要创新点可以概括为以下3个方面:1)在模糊聚类框架下提出了面向视角一致性的低秩约束准则. 已有的多视角模糊聚类算法大多基于成对视角之间的两两关系来构造正则化项, 忽视了多个视角的整体一致性信息. 本文在模糊聚类框架下从视角全局一致性出发引入低秩约束正则化项, 从而得到新型的低秩约束多视角模糊聚类算法.2) 在模糊聚类框架下同时考虑多视角聚类的一致性和差异性, 在引入低秩约束的同时进一步使用面向视角差异性的多视角香农熵加权策略; 在迭代优化的过程中, 通过动态调节视角权重系数来突出具有更好分离性的视角的权重, 从而提高聚类性能.3)在模糊聚类框架下首次使用交替方向乘子法(Alternating direction method of multipliers,ADMM)[15]对LR-MVEWFCM 算法进行优化求解.N D K C m x j,k j k j =1,···,N k =1,···,K v i,k k i i =1,···,C U k =[µij,k ]k µij,k k j i 在本文中, 令 为样本总量, 为样本维度, 为视角数目, 为聚类数目, 为模糊指数. 设 表示多视角场景中第 个样本第 个视角的特征向量, , ; 表示第 个视角下, 第 个聚类中心, ; 表示第 个视角下的模糊隶属度矩阵, 其中 是第 个视角下第 个样本属于第 个聚类中心的模i =1,···,C j =1,···,N.糊隶属度, , 本文第1节在相关工作中回顾已有的经典模糊C 均值聚类算法FCM 模型[17]和多视角模糊聚类Co-FKM 模型[9]; 第2节将低秩理论与多视角香农熵理论相结合, 提出本文的新方法; 第3节基于模拟数据集和UCI (University of California Irvine)数据集验证本文算法的有效性, 并给出实验分析;第4节给出实验结论.1 相关工作1.1 模糊C 均值聚类算法FCMx 1,···,x N ∈R D U =[µi,j ]V =[v 1,v 2,···,v C ]设单视角环境下样本 , 是模糊划分矩阵, 是样本的聚类中心. FCM 算法的目标函数可表示为J FCM 可得到 取得局部极小值的必要条件为U 根据式(2)和式(3)进行迭代优化, 使目标函数收敛于局部极小点, 从而得到样本属于各聚类中心的模糊划分矩阵 .1.2 多视角模糊聚类Co-FKM 模型在经典FCM算法的基础上, 文献[9]通过引入视角协同约束正则项, 对视角间的一致性信息加以约束, 提出了多视角模糊聚类Co-FKM 模型.多视角模糊聚类Co-FKM 模型需要满足如下条件:J Co-FKM 多视角模糊聚类Co-FKM 模型的目标函数 定义为7 期张嘉旭等: 基于低秩约束的熵加权多视角模糊聚类算法1761η∆∆式(5)中, 表示协同划分参数; 表示视角一致项,由式(6)可知, 当各视角趋于一致时, 将趋于0.µij,k 迭代得到各视角的模糊隶属度 后, 为了最终得到一个具有全局性的模糊隶属度划分矩阵, Co-FKM 算法对各视角下的模糊隶属度采用几何平均的方法, 得到数据集的整体划分, 具体形式为ˆµij 其中, 为全局模糊划分结果.2 基于低秩约束的熵加权多视角模糊聚类算法针对当前多视角模糊聚类算法研究中存在的不足, 本文提出一种基于低秩约束的熵加权多视角模糊聚类新方法LR-MVEWFCM. 一方面通过向多视角模糊聚类算法的目标学习准则中引入低秩约束项, 在整体上控制聚类过程中各视角的一致性; 另一方面基于香农熵理论, 通过熵加权机制来控制各视角之间的差异性.同时使用交替方向乘子法对模型进行优化求解.U 1,···,U K U U U 设多视角隶属度 融合为一个整体的隶属度矩阵 , 将矩阵 的秩函数凸松弛为核范数, 通过对矩阵 进行低秩约束, 可以将多视角数据之间的一致性问题转化为核范数最小化问题进行求解, 具体定义为U =[U 1···U K ]T ∥·∥∗其中, 表示全局划分矩阵, 表示核范数. 式(8)的优化过程保证了全局划分矩阵的低秩约束. 低秩约束的引入, 可以弥补当前大多数多视角聚类算法仅能基于成对视角构建约束的缺陷, 从而更好地挖掘多视角数据中包含的全局一致性信息.目前已有的多视角的聚类算法在处理多视角数据时, 通常默认每个视角平等共享聚类结果[11], 但实际上某些视角的数据往往因空间分布重叠而导致可分性较差. 为避免此类视角的数据过多影响聚类效果,本文拟对各视角进行加权处理, 并构建香农熵正则项从而在聚类过程中有效地调节各视角之间的权重, 使得具有较好可分离性的视角的权重系数尽可能大, 以达到更好的聚类效果.∑Kk =1w k =1w k ≥0令视角权重系数 且 , 则香农熵正则项表示为U w k U =[U 1···U K ]T w =[w 1,···,w k ,···,w K ]K 综上所述, 本文作如下改进: 首先, 用本文提出的低秩约束全局模糊隶属度矩阵 ; 其次, 计算损失函数时考虑视角权重 , 并加入视角权重系数的香农熵正则项. 设 ; 表示 个视角下的视角权重. 本文所构建LR-MVEWFCM 的目标函数为其中, 约束条件为m =2本文取模糊指数 .2.1 基于ADMM 的求解算法(11)在本节中, 我们将使用ADMM 方法, 通过交替方向迭代的策略来实现目标函数 的最小化.g (Z )=θ∥Z ∥∗(13)(10)最小化式 可改写为如下约束优化问题:其求解过程可分解为如下几个子问题:V w U V 1) -子问题. 固定 和 , 更新 为1762自 动 化 学 报48 卷(15)v i,k 通过最小化式 , 可得到 的闭合解为U w Q Z U 2) -子问题. 固定 , 和 , 更新 为(17)U (t +1)通过最小化式 , 可得到 的封闭解为w V U w 3) -子问题. 固定 和 , 更新 为Z Q U Z(20)通过引入软阈值算子, 可得式 的解为U (t+1)+Q (t )=A ΣB T U (t +1)+Q (t )S θ/ρ(Σ)=diag ({max (0,σi −θ/ρ)})(i =1,2,···,N )其中, 为矩阵 的奇异值分解, 核范数的近邻算子可由软阈值算子给出.Q Z U Q 5) -子问题. 固定 和 , 更新 为w =[w 1,···,w k ,···,w K ]U ˜U经过上述迭代过程, 目标函数收敛于局部极值,同时得到不同视角下的模糊隶属度矩阵. 本文借鉴文献[10]的集成策略, 使用视角权重系数 和模糊隶属度矩阵 来构建具有全局特性的模糊空间划分矩阵 :w k U k k 其中, , 分别表示第 个视角的视角权重系数和相应的模糊隶属度矩阵.LR-MVEWFCM 算法描述如下:K (1≤k ≤K )X k ={x 1,k ,···,x N,k }C ϵT 输入. 包含 个视角的多视角样本集, 其中任意一个视角对应样本集 , 聚类中心 , 迭代阈值 , 最大迭代次数 ;v (t )i,k ˜Uw k 输出. 各视角聚类中心 , 模糊空间划分矩阵和各视角权重 ;V (t )U (t )w (t )t =0步骤1. 随机初始化 , 归一化 及 ,;(21)v (t +1)i,k 步骤2. 根据式 更新 ;(23)U (t +1)步骤3. 根据式 更新 ;(24)w (t +1)k 步骤4. 根据式 更新 ;(26)Z (t +1)步骤5. 根据式 更新 ;(27)Q (t +1)步骤6. 根据式 更新 ;L (t +1)−L (t )<ϵt >T 步骤7. 如果 或者 , 则算法结束并跳出循环, 否则, 返回步骤2;w k U k (23)˜U步骤8. 根据步骤7所获取的各视角权重 及各视角下的模糊隶属度 , 使用式 计算 .2.2 讨论2.2.1 与低秩约束算法比较近年来, 基于低秩约束的机器学习模型得到了广泛的研究. 经典工作包括文献[16]中提出LRR (Low rank representation)模型, 将矩阵的秩函数凸松弛为核范数, 通过求解核范数最小化问题, 求得基于低秩表示的亲和矩阵; 文献[14]提出低秩张量多视角子空间聚类算法(Low-rank tensor con-strained multiview subspace clustering, LT-MSC),7 期张嘉旭等: 基于低秩约束的熵加权多视角模糊聚类算法1763在各视角间求出带有低秩约束的子空间表示矩阵;文献 [18] 则进一步将低秩约束引入多模型子空间聚类算法中, 使算法模型取得了较好的性能. 本文将低秩约束与多视角模糊聚类框架相结合, 提出了LR-MVEWFCM 算法, 用低秩约束来实现多视角数据间的一致性. 本文方法可作为低秩模型在多视角模糊聚类领域的重要拓展.2.2.2 与多视角Co-FKM 算法比较图1和图2分别给出了多视角Co-FKM 算法和本文LR-MVEWFCM 算法的工作流程.多视角数据Co-FKM视角 1 数据视角 2 数据视角 K 数据各视角间两两约束各视角模糊隶属度集成决策函数划分矩阵ÛU 1U 2U K图 1 Co-FKM 算法处理多视角聚类任务工作流程Fig. 1 Co-FKM algorithm for multi-view clustering task本文算法与经典的多视角Co-FKM 算法在多视角信息的一致性约束和多视角聚类结果的集成策略上均有所不同. 在多视角信息的一致性约束方面, 本文将Co-FKM 算法中的视角间两两约束进一步扩展到多视角全局一致性约束; 在多视角聚类结果的集成策略上, 本文不同于Co-FKM 算法对隶属度矩阵简单地求几何平均值的方式, 而是将各视角隶属度与视角权重相结合, 构建具有视角差异性的集成决策函数.3 实验与分析3.1 实验设置本文采用模拟数据集和UCI 中的真实数据集进行实验验证, 选取FCM [17]、CombKM [19]、Co-FKM [9]和Co-Clustering [20]这4个聚类算法作为对比算法, 参数设置如表1所示. 实验环境为: Intel Core i5-7400 CPU, 其主频为2.3 GHz, 内存为8 GB.编程环境为MATLAB 2015b.本文采用如下两个性能指标对各算法所得结果进行评估.1) 归一化互信息(Normalized mutual inform-ation, NMI)[10]N i,j i j N i i N j j N 其中, 表示第 类与第 类的契合程度, 表示第 类中所属样本量, 表示第 类中所属样本量, 而 表示数据的样本总量;2) 芮氏指标(Rand index, RI)[10]表 1 参数定义和设置Table 1 Parameter setting in the experiments算法算法说明参数设置FCM 经典的单视角模糊聚类算法m =min (N,D −1)min (N,D −1)−2N D 模糊指数 ,其中, 表示样本数, 表示样本维数CombKM K-means 组合 算法—Co-FKM 多视角协同划分的模糊聚类算法m =min (N,D −1)min (N,D −1)−2η∈K −1K K ρ=0.01模糊指数 , 协同学习系数 ,其中, 为视角数, 步长 Co-Clustering 基于样本与特征空间的协同聚类算法λ∈{10−3,10−2, (103)µ∈{10−3,10−2,···,103}正则化系数 ,正则化系数 LR-MVEWFCM 基于低秩约束的熵加权多视角模糊聚类算法λ∈{10−5,10−4, (105)θ∈{10−3,10−2, (103)m =2视角权重平衡因子 , 低秩约束正则项系数, 模糊指数 MVEWFCMθ=0LR-MVEWFCM 算法中低秩约束正则项系数 λ∈{10−5,10−4, (105)m =2视角权重平衡因子 , 模糊指数 多视角数据差异性集成决策函数各视角模糊隶属度U 1U 2U K各视角权重W 1W 2W kLR-MVEWFCM 视角 1 数据视角 2 数据视角 K 数据整体约束具有视角差异性的划分矩阵Û图 2 LR-MVEWFCM 算法处理多视角聚类任务工作流程Fig. 2 LR-MVEWFCM algorithm for multi-viewclustering task1764自 动 化 学 报48 卷f 00f 11N [0,1]其中, 表示具有不同类标签且属于不同类的数据配对点数目, 则表示具有相同类标签且属于同一类的数据配对点数目, 表示数据的样本总量. 以上两个指标的取值范围介于 之间, 数值越接近1, 说明算法的聚类性能越好. 为了验证算法的鲁棒性, 各表中统计的性能指标值均为算法10次运行结果的平均值.3.2 模拟数据集实验x,y,z A 1x,y,z A 2x,y,z A 3x,y,z 为了评估本文算法在多视角数据集上的聚类效果, 使用文献[10]的方法来构造具有三维特性的模拟数据集A ( ), 其具体生成过程为: 首先在MATLAB 环境下采用正态分布随机函数normrnd 构建数据子集 ( ), ( )和 ( ), 每组对应一个类簇, 数据均包含200个样本.x,y,z 其中第1组与第2组数据集在特征z 上数值较为接近, 第2组与第3组数据集在特征x 上较为接近;然后将3组数据合并得到集合A ( ), 共计600个样本; 最后对数据集内的样本进行归一化处理. 我们进一步将特征x , y , z 按表2的方式两两组合, 从而得到多视角数据.表 2 模拟数据集特征组成Table 2 Characteristic composition of simulated dataset视角包含特征视角 1x,y 视角 2y,z 视角 3x,z将各视角下的样本可视化, 如图3所示.通过观察图3可以发现, 视角1中的数据集在空间分布上具有良好的可分性, 而视角2和视角3的数据在空间分布上均存在着一定的重叠, 从而影Z YZZXYX(a) 模拟数据集 A (a) Dataset A(b) 视角 1 数据集(b) View 1(c) 视角 2 数据集(c) View 2(d) 视角 3 数据集(d) View 3图 3 模拟数据集及各视角数据集Fig. 3 Simulated data under multiple views7 期张嘉旭等: 基于低秩约束的熵加权多视角模糊聚类算法1765响了所在视角下的聚类性能. 通过组合不同视角生成若干新的数据集, 如表3所示, 并给出了LR-MVEWFCM重复运行10次后的平均结果和方差.表 3 模拟数据实验算法性能对比Table 3 Performance comparison of the proposedalgorithms on simulated dataset编号包含特征NMI RI1视角1 1.0000 ± 0.0000 1.0000 ± 0.0000 2视角20.7453 ± 0.00750.8796 ± 0.0081 3视角30.8750 ± 0.00810.9555 ± 0.0006 4视角1, 视角2 1.0000 ± 0.0000 1.0000 ± 0.0000 5视角1, 视角3 1.0000 ± 0.0000 1.0000 ± 0.0000 6视角2, 视角30.9104 ± 0.03960.9634 ± 0.0192 7视角2, 视角3 1.0000 ± 0.0000 1.0000 ± 0.0000对比LR-MVEWFCM在数据集1~3上的性能, 我们发现本文算法在视角1上取得了最为理想的效果, 在视角3上的性能要优于视角2, 这与图3中各视角数据的空间可分性是一致的. 此外, 将各视角数据两两组合构成新数据集4~6后, LR-MVEWFCM算法都得到了比单一视角更好的聚类效果, 这都说明了本文采用低秩约束来挖掘多视角数据中一致性的方法, 能够有效提高聚类性能.基于多视角数据集7, 我们进一步给出本文算法与其他经典聚类算法的比较结果.从表4中可以发现, 由于模拟数据集在某些特征空间下具有良好的空间可分性, 所以无论是本文的算法还是Co-Clustering算法、FCM算法等算法均取得了很好的聚类效果, 而CombKM算法的性能较之以上算法则略有不足, 分析其原因在于CombKM算法侧重于挖掘样本之间的信息, 却忽视了多视角之间的协作, 而本文算法通过使用低秩约束进一步挖掘了多视角之间的全局一致性, 因而得到了比CombKM算法更好的聚类效果.3.3 真实数据集实验本节采用5个UCI数据集: 1) Iris数据集; 2) Image Segmentation (IS) 数据集; 3) Balance数据集; 4) Ionosphere数据集; 5) Wine数据集来进行实验. 由于这几个数据集均包含了不同类型的特征,所以可以将这些特征进行重新分组从而构造相应的多视角数据集. 表5给出了分组后的相关信息.我们在多视角数据集上运行各多视角聚类算法; 同时在原数据集上运行FCM算法. 相关结果统计见表6和表7.NMI RI通过观察表6和表7中的和指标值可知, Co-FKM算法的聚类性能明显优于其他几种经典聚类算法, 而相比于Co-FKM算法, 由于LR-MVEWFCM采用了低秩正则项来挖掘多视角数据之间的一致性关系, 并引入多视角自适应熵加权策略, 从而有效控制各视角之间的差异性. 很明显, 这种聚类性能更为优异和稳定, 且收敛性的效果更好.表6和表7中的结果也展示了在IS、Balance、Iris、Ionosphere和Wine数据集上, 其NMI和RI指标均提升3 ~ 5个百分点, 这也说明了本文算法在多视角聚类过程中的有效性.为进一步说明本文低秩约束发挥的积极作用,将LR-MVEWFCM算法和MVEWFCM算法共同进行实验, 算法的性能对比如图4所示.从图4中不难发现, 无论在模拟数据集上还是UCI真实数据集上, 相比较MVEWFCM算法, LR-MVEWFCM算法均可以取得更好的聚类效果. 因此可见, LR-MVEWFCM目标学习准则中的低秩约束能够有效利用多视角数据的一致性来提高算法的聚类性能.为研究本文算法的收敛性, 同样选取8个数据集进行收敛性实验, 其目标函数变化如图5所示.从图5中可以看出, 本文算法在真实数据集上仅需迭代15次左右就可以趋于稳定, 这说明本文算法在速度要求较高的场景下具有较好的实用性.综合以上实验结果, 我们不难发现, 在具有多视角特性的数据集上进行模糊聚类分析时, 多视角模糊聚类算法通常比传统单视角模糊聚类算法能够得到更优的聚类效果; 在本文中, 通过在多视角模糊聚类学习中引入低秩约束来增强不同视角之间的一致性关系, 并引入香农熵调节视角权重关系, 控制不同视角之间的差异性, 从而得到了比其他多视角聚类算法更好的聚类效果.表 4 模拟数据集7上各算法的性能比较Table 4 Performance comparison of the proposed algorithms on simulated dataset 7数据集指标Co-Clustering CombKM FCM Co-FKM LR-MVEWFCMA NMI-mean 1.00000.9305 1.0000 1.0000 1.0000 NMI-std0.00000.14640.00000.00000.0000 RI-mean 1.00000.9445 1.0000 1.0000 1.0000 RI-std0.00000.11710.00000.00000.00001766自 动 化 学 报48 卷3.4 参数敏感性实验LR-MVEWFCM算法包含两个正则项系数,λθθθθλλ即视角权重平衡因子和低秩约束正则项系数, 图6以LR-MVEWFCM算法在模拟数据集7上的实验为例, 给出了系数从0到1000过程中, 算法性能的变化情况, 当低秩正则项系数= 0时, 即不添加此正则项, 算法的性能最差, 验证了本文加入的低秩正则项的有效性, 当值变化过程中, 算法的性能相对变化较小, 说明本文算法在此数据集上对于值变化不敏感, 具有一定的鲁棒性; 而当香农熵正则项系数= 0时, 同样算法性能较差, 也说明引入此正则项的合理性. 当值变大时, 发现算法的性能也呈现变好趋势, 说明在此数据集上, 此正则项相对效果比较明显.4 结束语本文从多视角聚类学习过程中的一致性和差异性两方面出发, 提出了基于低秩约束的熵加权多视角模糊聚类算法. 该算法采用低秩正则项来挖掘多视角数据之间的一致性关系, 并引入多视角自适应熵加权策略从而有效控制各视角之间的差异性,从而提高了算法的性能. 在模拟数据集和真实数据集上的实验均表明, 本文算法的聚类性能优于其他多视角聚类算法. 同时本文算法还具有迭代次数少、收敛速度快的优点, 具有良好的实用性. 由于本文采用经典的FCM框架, 使用欧氏距离来衡量数据对象之间的差异,这使得本文算法不适用于某些高维数据场景. 如何针对高维数据设计多视角聚类算法, 这也将是我们今后的研究重点.表 5 基于UCI数据集构造的多视角数据Table 5 Multi-view data constructdedbased on UCI dataset编号原数据集说明视角特征样本视角类别8IS Shape92 31027 RGB99Iris Sepal长度215023 Sepal宽度Petal长度2Petal宽度10Balance 天平左臂重量262523天平左臂长度天平右臂重量2天平右臂长度11Iris Sepal长度115043 Sepal宽度1Petal长度1Petal宽度112Balance 天平左臂重量162543天平左臂长度1天平右臂重量1天平右臂长度113Ionosphere 每个特征单独作为一个视角135134214Wine 每个特征单独作为一个视角1178133表 6 5种聚类方法的NMI值比较结果Table 6 Comparison of NMI performance of five clustering methods编号Co-Clustering CombKM FCM Co-FKM LR-MVEWFCM 均值P-value均值P-value均值P-value均值P-value均值80.5771 ±0.00230.00190.5259 ±0.05510.20560.5567 ±0.01840.00440.5881 ±0.01093.76×10−40.5828 ±0.004490.7582 ±7.4015 ×10−172.03×10−240.7251 ±0.06982.32×10−70.7578 ±0.06981.93×10−240.8317 ±0.00648.88×10−160.9029 ±0.0057100.2455 ±0.05590.01650.1562 ±0.07493.47×10−50.1813 ±0.11720.00610.2756 ±0.03090.10370.3030 ±0.0402110.7582 ±1.1703×10−162.28×10−160.7468 ±0.00795.12×10−160.7578 ±1.1703×10−165.04×10−160.8244 ±1.1102×10−162.16×10−160.8768 ±0.0097120.2603 ±0.06850.38250.1543 ±0.07634.61×10−40.2264 ±0.11270.15730.2283 ±0.02940.01460.2863 ±0.0611130.1385 ±0.00852.51×10−90.1349 ±2.9257×10−172.35×10−130.1299 ±0.09842.60×10−100.2097 ±0.03290.04830.2608 ±0.0251140.4288 ±1.1703×10−161.26×10−080.4215 ±0.00957.97×10−090.4334 ±5.8514×10−172.39×10−080.5295 ±0.03010.43760.5413 ±0.03647 期张嘉旭等: 基于低秩约束的熵加权多视角模糊聚类算法1767表 7 5种聚类方法的RI 值比较结果Table 7 Comparison of RI performance of five clustering methods编号Co-ClusteringCombKM FCMCo-FKM LR-MVEWFCM均值P-value 均值P-value 均值P-value 均值P-value 均值80.8392 ±0.0010 1.3475 ×10−140.8112 ±0.0369 1.95×10−70.8390 ±0.01150.00320.8571 ±0.00190.00480.8508 ±0.001390.8797 ±0.0014 1.72×10−260.8481 ±0.0667 2.56×10−50.8859 ±1.1703×10−16 6.49×10−260.9358 ±0.0037 3.29×10−140.9665 ±0.0026100.6515 ±0.0231 3.13×10−40.6059 ±0.0340 1.37×10−60.6186 ±0.06240.00160.6772 ±0.02270.07610.6958 ±0.0215110.8797 ±0.0014 1.25×10−180.8755 ±0.0029 5.99×10−120.8859 ±0.0243 2.33×10−180.9267 ±2.3406×10−16 5.19×10−180.9527 ±0.0041120.6511 ±0.02790.01560.6024 ±0.0322 2.24×10−50.6509 ±0.06520.11390.6511 ±0.01890.0080.6902 ±0.0370130.5877 ±0.0030 1.35×10−120.5888 ±0.0292 2.10×10−140.5818 ±1.1703×10−164.6351 ×10−130.6508 ±0.01470.03580.6855 ±0.0115140.7187 ±1.1703×10−163.82×10−60.7056 ±0.01681.69×10−60.7099 ±1.1703×10−168.45×10−70.7850 ±0.01620.59050.7917 ±0.0353R I数据集N M I数据集(a) RI 指标(a) RI(b) NMI 指标(b) NMI图 4 低秩约束对算法性能的影响(横坐标为数据集编号, 纵坐标为聚类性能指标)Fig. 4 The influence of low rank constraints on the performance of the algorithm (the X -coordinate isthe data set number and the Y -coordinate is the clustering performance index)目标函数值1 096.91 096.81 096.61 096.71 096.51 096.41 096.31 096.21 096.1目标函数值66.266.065.665.865.465.2迭代次数05101520目标函数值7.05.06.55.54.04.53.03.5迭代次数05101520迭代次数05101520目标函数值52.652.251.451.851.050.6迭代次数05101520×106(a) 数据集 7(a) Dataset 7(b) 数据集 8(b) Dataset 8(c) 数据集 9(c) Dataset 9(d) 数据集 10(d) Dataset 101768自 动 化 学 报48 卷ReferencesXu C, Tao D C, Xu C. Multi-view learning with incompleteviews. IEEE Transactions on Image Processing , 2015, 24(12):5812−58251Brefeld U. Multi-view learning with dependent views. In: Pro-ceedings of the 30th Annual ACM Symposium on Applied Com-puting, Salamanca, Spain: ACM, 2015. 865−8702Muslea I, Minton S, Knoblock C A. Active learning with mul-tiple views. Journal of Artificial Intelligence Research , 2006,27(1): 203−2333Zhang C Q, Adeli E, Wu Z W, Li G, Lin W L, Shen D G. In-fant brain development prediction with latent partial multi-view representation learning. IEEE Transactions on Medical Imaging ,2018, 38(4): 909−9184Bickel S, Scheffer T. Multi-view clustering. In: Proceedings of the 4th IEEE International Conference on Data Mining (ICDM '04), Brighton, UK: IEEE, 2004. 19−265Wang Y T, Chen L H. Multi-view fuzzy clustering with minim-ax optimization for effective clustering of data from multiple sources. Expert Systems with Applications , 2017, 72: 457−4666Wang Jun, Wang Shi-Tong, Deng Zhao-Hong. Survey on chal-lenges in clustering analysis research. Control and Decision ,2012, 27(3): 321−328(王骏, 王士同, 邓赵红. 聚类分析研究中的若干问题. 控制与决策,2012, 27(3): 321−328)7Pedrycz W. Collaborative fuzzy clustering. Pattern Recognition Letters , 2002, 23(14): 1675−16868Cleuziou G, Exbrayat M, Martin L, Sublemontier J H. CoFKM:A centralized method for multiple-view clustering. In: Proceed-ings of the 9th IEEE International Conference on Data Mining,Miami, FL, USA: IEEE, 2009. 752−7579Jiang Y Z, Chung F L, Wang S T, Deng Z H, Wang J, Qian P J. Collaborative fuzzy clustering from multiple weighted views.IEEE Transactions on Cybernetics , 2015, 45(4): 688−70110Bettoumi S, Jlassi C, Arous N. Collaborative multi-view K-means clustering. Soft Computing , 2019, 23(3): 937−94511Zhang G Y, Wang C D, Huang D, Zheng W S, Zhou Y R. TW-Co-K-means: Two-level weighted collaborative K-means for multi-view clustering. Knowledge-Based Systems , 2018, 150:127−13812Cao X C, Zhang C Q, Fu H Z, Liu S, Zhang H. Diversity-in-duced multi-view subspace clustering. In: Proceedings of the2015 IEEE Conference on Computer Vision and Pattern Recog-nition, Boston, MA, USA: IEEE, 2015. 586−59413Zhang C Q, Fu H Z, Liu S, Liu G C, Cao X C. Low-rank tensor constrained multiview subspace clustering. In: Proceedings of the 2015 IEEE International Conference on Computer Visio,Santiago, Chile: IEEE, 2015. 1582−159014Boyd S, Parikh N, Chu E, Peleato B, Eckstein J. Distributed optimization and statistical learning via the alternating direc-tion method of multipliers. Foundations and Trends in Machine Learning , 2011, 3(1): 1−12215Liu G C, Lin Z C, Yan S C, Sun J, Yu Y, Ma Y. Robust recov-ery of subspace structures by low-rank representation. IEEE1616.216.015.815.615.415.215.0目标函数值目标函数值目标函数值51015迭代次数迭代次数迭代次数 711.2011.1511.1011.0511.0010.9510.90800700600500400300200目标函数值38.638.238.438.037.837.637.437.251015205101520迭代次数 705101520(e) 数据集 11(e) Dataset 11(f) 数据集 12(f) Dataset 12(g) 数据集 13(g) Dataset 13(h) 数据集 14(h) Dataset 14图 5 LR-MVEWFCM 算法的收敛曲线Fig. 5 Convergence curve of LR-MVEWFCM algorithm图 6 模拟数据集7上参数敏感性分析Fig. 6 Sensitivity analysis of parameters on simulated dataset 77 期张嘉旭等: 基于低秩约束的熵加权多视角模糊聚类算法1769。
第41卷 第4期吉林大学学报(信息科学版)Vol.41 No.42023年7月Journal of Jilin University (Information Science Edition)July 2023文章编号:1671⁃5896(2023)04⁃0621⁃10特征更新的动态图卷积表面损伤点云分割方法收稿日期:2022⁃09⁃21基金项目:国家自然科学基金资助项目(61573185)作者简介:张闻锐(1998 ),男,江苏扬州人,南京航空航天大学硕士研究生,主要从事点云分割研究,(Tel)86⁃188****8397(E⁃mail)839357306@;王从庆(1960 ),男,南京人,南京航空航天大学教授,博士生导师,主要从事模式识别与智能系统研究,(Tel)86⁃130****6390(E⁃mail)cqwang@㊂张闻锐,王从庆(南京航空航天大学自动化学院,南京210016)摘要:针对金属部件表面损伤点云数据对分割网络局部特征分析能力要求高,局部特征分析能力较弱的传统算法对某些数据集无法达到理想的分割效果问题,选择采用相对损伤体积等特征进行损伤分类,将金属表面损伤分为6类,提出一种包含空间尺度区域信息的三维图注意力特征提取方法㊂将得到的空间尺度区域特征用于特征更新网络模块的设计,基于特征更新模块构建出了一种特征更新的动态图卷积网络(Feature Adaptive Shifting⁃Dynamic Graph Convolutional Neural Networks)用于点云语义分割㊂实验结果表明,该方法有助于更有效地进行点云分割,并提取点云局部特征㊂在金属表面损伤分割上,该方法的精度优于PointNet ++㊁DGCNN(Dynamic Graph Convolutional Neural Networks)等方法,提高了分割结果的精度与有效性㊂关键词:点云分割;动态图卷积;特征更新;损伤分类中图分类号:TP391.41文献标志码:A Cloud Segmentation Method of Surface Damage Point Based on Feature Adaptive Shifting⁃DGCNNZHANG Wenrui,WANG Congqing(School of Automation,Nanjing University of Aeronautics and Astronautics,Nanjing 210016,China)Abstract :The cloud data of metal part surface damage point requires high local feature analysis ability of the segmentation network,and the traditional algorithm with weak local feature analysis ability can not achieve the ideal segmentation effect for the data set.The relative damage volume and other features are selected to classify the metal surface damage,and the damage is divided into six categories.This paper proposes a method to extract the attention feature of 3D map containing spatial scale area information.The obtained spatial scale area feature is used in the design of feature update network module.Based on the feature update module,a feature updated dynamic graph convolution network is constructed for point cloud semantic segmentation.The experimental results show that the proposed method is helpful for more effective point cloud segmentation to extract the local features of point cloud.In metal surface damage segmentation,the accuracy of this method is better than pointnet++,DGCNN(Dynamic Graph Convolutional Neural Networks)and other methods,which improves the accuracy and effectiveness of segmentation results.Key words :point cloud segmentation;dynamic graph convolution;feature adaptive shifting;damage classification 0 引 言基于深度学习的图像分割技术在人脸㊁车牌识别和卫星图像分析领域已经趋近成熟,为获取物体更226吉林大学学报(信息科学版)第41卷完整的三维信息,就需要利用三维点云数据进一步完善语义分割㊂三维点云数据具有稀疏性和无序性,其独特的几何特征分布和三维属性使点云语义分割在许多领域的应用都遇到困难㊂如在机器人与计算机视觉领域使用三维点云进行目标检测与跟踪以及重建;在建筑学上使用点云提取与识别建筑物和土地三维几何信息;在自动驾驶方面提供路面交通对象㊁道路㊁地图的采集㊁检测和分割功能㊂2017年,Lawin等[1]将点云投影到多个视图上分割再返回点云,在原始点云上对投影分割结果进行分析,实现对点云的分割㊂最早的体素深度学习网络产生于2015年,由Maturana等[2]创建的VOXNET (Voxel Partition Network)网络结构,建立在三维点云的体素表示(Volumetric Representation)上,从三维体素形状中学习点的分布㊂结合Le等[3]提出的点云网格化表示,出现了类似PointGrid的新型深度网络,集成了点与网格的混合高效化网络,但体素化的点云面对大量点数的点云文件时表现不佳㊂在不规则的点云向规则的投影和体素等过渡态转换过程中,会出现很多空间信息损失㊂为将点云自身的数据特征发挥完善,直接输入点云的基础网络模型被逐渐提出㊂2017年,Qi等[4]利用点云文件的特性,开发了直接针对原始点云进行特征学习的PointNet网络㊂随后Qi等[5]又提出了PointNet++,针对PointNet在表示点与点直接的关联性上做出改进㊂Hu等[6]提出SENET(Squeeze⁃and⁃Excitation Networks)通过校准通道响应,为三维点云深度学习引入通道注意力网络㊂2018年,Li等[7]提出了PointCNN,设计了一种X⁃Conv模块,在不显著增加参数数量的情况下耦合较远距离信息㊂图卷积网络[8](Graph Convolutional Network)是依靠图之间的节点进行信息传递,获得图之间的信息关联的深度神经网络㊂图可以视为顶点和边的集合,使每个点都成为顶点,消耗的运算量是无法估量的,需要采用K临近点计算方式[9]产生的边缘卷积层(EdgeConv)㊂利用中心点与其邻域点作为边特征,提取边特征㊂图卷积网络作为一种点云深度学习的新框架弥补了Pointnet等网络的部分缺陷[10]㊂针对非规律的表面损伤这种特征缺失类点云分割,人们已经利用各种二维图像采集数据与卷积神经网络对风扇叶片㊁建筑和交通工具等进行损伤检测[11],损伤主要类别是裂痕㊁表面漆脱落等㊂但二维图像分割涉及的损伤种类不够充分,可能受物体表面污染㊁光线等因素影响,将凹陷㊁凸起等损伤忽视,或因光照不均匀判断为脱漆㊂笔者提出一种基于特征更新的动态图卷积网络,主要针对三维点云分割,设计了一种新型的特征更新模块㊂利用三维点云独特的空间结构特征,对传统K邻域内权重相近的邻域点采用空间尺度进行区分,并应用于对金属部件表面损伤分割的有用与无用信息混杂的问题研究㊂对邻域点进行空间尺度划分,将注意力权重分组,组内进行特征更新㊂在有效鉴别外邻域干扰特征造成的误差前提下,增大特征提取面以提高局部区域特征有用性㊂1 深度卷积网络计算方法1.1 包含空间尺度区域信息的三维图注意力特征提取方法由迭代最远点采集算法将整片点云分割为n个点集:{M1,M2,M3, ,M n},每个点集包含k个点:{P1, P2,P3, ,P k},根据点集内的空间尺度关系,将局部区域划分为不同的空间区域㊂在每个区域内,结合局部特征与空间尺度特征,进一步获得更有区分度的特征信息㊂根据注意力机制,为K邻域内的点分配不同的权重信息,特征信息包括空间区域内点的分布和区域特性㊂将这些特征信息加权计算,得到点集的卷积结果㊂使用空间尺度区域信息的三维图注意力特征提取方式,需要设定合适的K邻域参数K和空间划分层数R㊂如果K太小,则会导致弱分割,因不能完全利用局部特征而影响结果准确性;如果K太大,会增加计算时间与数据量㊂图1为缺损损伤在不同参数K下的分割结果图㊂由图1可知,在K=30或50时,分割结果效果较好,K=30时计算量较小㊂笔者选择K=30作为实验参数㊂在分析确定空间划分层数R之前,简要分析空间层数划分所应对的问题㊂三维点云所具有的稀疏性㊁无序性以及损伤点云自身噪声和边角点多的特性,导致了点云处理中可能出现的共同缺点,即将离群值点云选为邻域内采样点㊂由于损伤表面多为一个面,被分割出的损伤点云应在该面上分布,而噪声点则被分布在整个面的两侧,甚至有部分位于损伤内部㊂由于点云噪声这种立体分布的特征,导致了离群值被选入邻域内作为采样点存在㊂根据采用DGCNN(Dynamic Graph Convolutional Neural Networks)分割网络抽样实验结果,位于切面附近以及损伤内部的离群值点对点云分割结果造成的影响最大,被错误分割为特征点的几率最大,在后续预处理过程中需要对这种噪声点进行优先处理㊂图1 缺损损伤在不同参数K 下的分割结果图Fig.1 Segmentation results of defect damage under different parameters K 基于上述实验结果,在参数K =30情况下,选择空间划分层数R ㊂缺损损伤在不同参数R 下的分割结果如图2所示㊂图2b 的结果与测试集标签分割结果更为相似,更能体现损伤的特征,同时屏蔽了大部分噪声㊂因此,选择R =4作为实验参数㊂图2 缺损损伤在不同参数R 下的分割结果图Fig.2 Segmentation results of defect damage under different parameters R 在一个K 邻域内,邻域点与中心点的空间关系和特征差异最能表现邻域点的权重㊂空间特征系数表示邻域点对中心点所在点集的重要性㊂同时,为更好区分图内邻域点的权重,需要将整个邻域细分㊂以空间尺度进行细分是较为合适的分类方式㊂中心点的K 邻域可视为一个局部空间,将其划分为r 个不同的尺度区域㊂再运算空间注意力机制,为这r 个不同区域的权重系数赋值㊂按照空间尺度多层次划分,不仅没有损失核心的邻域点特征,还能有效抑制无意义的㊁有干扰性的特征㊂从而提高了深度学习网络对点云的局部空间特征的学习能力,降低相邻邻域之间的互相影响㊂空间注意力机制如图3所示,计算步骤如下㊂第1步,计算特征系数e mk ㊂该值表示每个中心点m 的第k 个邻域点对其中心点的权重㊂分别用Δp mk 和Δf mk 表示三维空间关系和局部特征差异,M 表示MLP(Multi⁃Layer Perceptrons)操作,C 表示concat 函数,其中Δp mk =p mk -p m ,Δf mk =M (f mk )-M (f m )㊂将两者合并后输入多层感知机进行计算,得到计算特征系数326第4期张闻锐,等:特征更新的动态图卷积表面损伤点云分割方法图3 空间尺度区域信息注意力特征提取方法示意图Fig.3 Schematic diagram of attention feature extraction method for spatial scale regional information e mk =M [C (Δp mk ‖Δf mk )]㊂(1) 第2步,计算图权重系数a mk ㊂该值表示每个中心点m 的第k 个邻域点对其中心点的权重包含比㊂其中k ∈{1,2,3, ,K },K 表示每个邻域所包含点数㊂需要对特征系数e mk 进行归一化,使用归一化指数函数S (Softmax)得到权重多分类的结果,即计算图权重系数a mk =S (e mk )=exp(e mk )/∑K g =1exp(e mg )㊂(2) 第3步,用空间尺度区域特征s mr 表示中心点m 的第r 个空间尺度区域的特征㊂其中k r ∈{1,2,3, ,K r },K r 表示第r 个空间尺度区域所包含的邻域点数,并在其中加入特征偏置项b r ,避免权重化计算的特征在动态图中累计单面误差指向,空间尺度区域特征s mr =∑K r k r =1[a mk r M (f mk r )]+b r ㊂(3) 在r 个空间尺度区域上进行计算,就可得到点m 在整个局部区域的全部空间尺度区域特征s m ={s m 1,s m 2,s m 3, ,s mr },其中r ∈{1,2,3, ,R }㊂1.2 基于特征更新的动态图卷积网络动态图卷积网络是一种能直接处理原始三维点云数据输入的深度学习网络㊂其特点是将PointNet 网络中的复合特征转换模块(Feature Transform),改进为由K 邻近点计算(K ⁃Near Neighbor)和多层感知机构成的边缘卷积层[12]㊂边缘卷积层功能强大,其提取的特征不仅包含全局特征,还拥有由中心点与邻域点的空间位置关系构成的局部特征㊂在动态图卷积网络中,每个邻域都视为一个点集㊂增强对其中心点的特征学习能力,就会增强网络整体的效果[13]㊂对一个邻域点集,对中心点贡献最小的有效局部特征的边缘点,可以视为异常噪声点或低权重点,可能会给整体分割带来边缘溢出㊂点云相比二维图像是一种信息稀疏并且噪声含量更大的载体㊂处理一个局域内的噪声点,将其直接剔除或简单采纳会降低特征提取效果,笔者对其进行低权重划分,并进行区域内特征更新,增强抗噪性能,也避免点云信息丢失㊂在空间尺度区域中,在区域T 内有s 个点x 被归为低权重系数组,该点集的空间信息集为P ∈R N s ×3㊂点集的局部特征集为F ∈R N s ×D f [14],其中D f 表示特征的维度空间,N s 表示s 个域内点的集合㊂设p i 以及f i 为点x i 的空间信息和特征信息㊂在点集内,对点x i 进行小范围内的N 邻域搜索,搜索其邻域点㊂则点x i 的邻域点{x i ,1,x i ,2, ,x i ,N }∈N (x i ),其特征集合为{f i ,1,f i ,2, ,f i ,N }∈F ㊂在利用空间尺度进行区域划分后,对空间尺度区域特征s mt 较低的区域进行区域内特征更新,通过聚合函数对权重最低的邻域点在图中的局部特征进行改写㊂已知中心点m ,点x i 的特征f mx i 和空间尺度区域特征s mt ,目的是求出f ′mx i ,即中心点m 的低权重邻域点x i 在进行邻域特征更新后得到的新特征㊂对区域T 内的点x i ,∀x i ,j ∈H (x i ),x i 与其邻域H 内的邻域点的特征相似性域为R (x i ,x i ,j )=S [C (f i ,j )T C (f i ,j )/D o ],(4)其中C 表示由输入至输出维度的一维卷积,D o 表示输出维度值,T 表示转置㊂从而获得更新后的x i 的426吉林大学学报(信息科学版)第41卷特征㊂对R (x i ,x i ,j )进行聚合,并将特征f mx i 维度变换为输出维度f ′mx i =∑[R (x i ,x i ,j )S (s mt f mx i )]㊂(5) 图4为特征更新网络模块示意图,展示了上述特征更新的计算过程㊂图5为特征更新的动态图卷积网络示意图㊂图4 特征更新网络模块示意图Fig.4 Schematic diagram of feature update network module 图5 特征更新的动态图卷积网络示意图Fig.5 Flow chart of dynamic graph convolution network with feature update 动态图卷积网络(DGCNN)利用自创的边缘卷积层模块,逐层进行边卷积[15]㊂其前一层的输出都会动态地产生新的特征空间和局部区域,新一层从前一层学习特征(见图5)㊂在每层的边卷积模块中,笔者在边卷积和池化后加入了空间尺度区域注意力特征,捕捉特定空间区域T 内的邻域点,用于特征更新㊂特征更新会降低局域异常值点对局部特征的污染㊂网络相比传统图卷积神经网络能获得更多的特征信息,并且在面对拥有较多噪声值的点云数据时,具有更好的抗干扰性[16],在对性质不稳定㊁不平滑并含有需采集分割的突出中心的点云数据时,会有更好的抗干扰效果㊂相比于传统预处理方式,其稳定性更强,不会发生将突出部分误分割或漏分割的现象[17]㊂2 实验结果与分析点云分割的精度评估指标主要由两组数据构成[18],即平均交并比和总体准确率㊂平均交并比U (MIoU:Mean Intersection over Union)代表真实值和预测值合集的交并化率的平均值,其计算式为526第4期张闻锐,等:特征更新的动态图卷积表面损伤点云分割方法U =1T +1∑Ta =0p aa ∑Tb =0p ab +∑T b =0p ba -p aa ,(6)其中T 表示类别,a 表示真实值,b 表示预测值,p ab 表示将a 预测为b ㊂总体准确率A (OA:Overall Accuracy)表示所有正确预测点p c 占点云模型总体数量p all 的比,其计算式为A =P c /P all ,(7)其中U 与A 数值越大,表明点云分割网络越精准,且有U ≤A ㊂2.1 实验准备与数据预处理实验使用Kinect V2,采用Depth Basics⁃WPF 模块拍摄金属部件损伤表面获得深度图,将获得的深度图进行SDK(Software Development Kit)转化,得到pcd 格式的点云数据㊂Kinect V2采集的深度图像分辨率固定为512×424像素,为获得更清晰的数据图像,需尽可能近地采集数据㊂选择0.6~1.2m 作为采集距离范围,从0.6m 开始每次增加0.2m,获得多组采量数据㊂点云中分布着噪声,如果不对点云数据进行过滤会对后续处理产生不利影响㊂根据统计原理对点云中每个点的邻域进行分析,再建立一个特别设立的标准差㊂然后将实际点云的分布与假设的高斯分布进行对比,实际点云中误差超出了标准差的点即被认为是噪声点[19]㊂由于点云数据量庞大,为提高效率,选择采用如下改进方法㊂计算点云中每个点与其首个邻域点的空间距离L 1和与其第k 个邻域点的空间距离L k ㊂比较每个点之间L 1与L k 的差,将其中差值最大的1/K 视为可能噪声点[20]㊂计算可能噪声点到其K 个邻域点的平均值,平均值高出标准差的被视为噪声点,将离群噪声点剔除后完成对点云的滤波㊂2.2 金属表面损伤点云关键信息提取分割方法对点云损伤分割,在制作点云数据训练集时,如果只是单一地将所有损伤进行统一标记,不仅不方便进行结果分析和应用,而且也会降低特征分割的效果㊂为方便分析和控制分割效果,需要使用ArcGIS 将点云模型转化为不规则三角网TIN(Triangulated Irregular Network)㊂为精确地分类损伤,利用图6 不规则三角网模型示意图Fig.6 Schematic diagram of triangulated irregular networkTIN 的表面轮廓性质,获得训练数据损伤点云的损伤内(外)体积,损伤表面轮廓面积等㊂如图6所示㊂选择损伤体积指标分为相对损伤体积V (RDV:Relative Damege Volume)和邻域内相对损伤体积比N (NRDVR:Neighborhood Relative Damege Volume Ratio)㊂计算相对平均深度平面与点云深度网格化平面之间的部分,得出相对损伤体积㊂利用TIN 邻域网格可获取某损伤在邻域内的相对深度占比,有效解决制作测试集时,将因弧度或是形状造成的相对深度判断为损伤的问题㊂两种指标如下:V =∑P d k =1h k /P d -∑P k =1h k /()P S d ,(8)N =P n ∑P d k =1h k S d /P d ∑P n k =1h k S ()n -()1×100%,(9)其中P 表示所有点云数,P d 表示所有被标记为损伤的点云数,P n 表示所有被认定为损伤邻域内的点云数;h k 表示点k 的深度值;S d 表示损伤平面面积,S n 表示损伤邻域平面面积㊂在获取TIN 标准包络网视图后,可以更加清晰地描绘损伤情况,同时有助于量化损伤严重程度㊂笔者将损伤分为6种类型,并利用计算得出的TIN 指标进行损伤分类㊂同时,根据损伤部分体积与非损伤部分体积的关系,制定指标损伤体积(SDV:Standard Damege Volume)区分损伤类别㊂随机抽选5个测试组共50张图作为样本㊂统计非穿透损伤的RDV 绝对值,其中最大的30%标记为凹陷或凸起,其余626吉林大学学报(信息科学版)第41卷标记为表面损伤,并将样本分类的标准分界值设为SDV㊂在设立以上标准后,对凹陷㊁凸起㊁穿孔㊁表面损伤㊁破损和缺损6种金属表面损伤进行分类,金属表面损伤示意图如图7所示㊂首先,根据损伤是否产生洞穿,将损伤分为两大类㊂非贯通伤包括凹陷㊁凸起和表面损伤,贯通伤包括穿孔㊁破损和缺损㊂在非贯通伤中,凹陷和凸起分别采用相反数的SDV 作为标准,在这之间的被分类为表面损伤㊂贯通伤中,以损伤部分平面面积作为参照,较小的分类为穿孔,较大的分类为破损,而在边缘处因腐蚀㊁碰撞等原因缺角㊁内损的分类为缺损㊂分类参照如表1所示㊂图7 金属表面损伤示意图Fig.7 Schematic diagram of metal surface damage表1 损伤类别分类Tab.1 Damage classification 损伤类别凹陷凸起穿孔表面损伤破损缺损是否形成洞穿××√×√√RDV 绝对值是否达到SDV √√\×\\S d 是否达到标准\\×\√\2.3 实验结果分析为验证改进的图卷积深度神经网络在点云语义分割上的有效性,笔者采用TensorFlow 神经网络框架进行模型测试㊂为验证深度网络对损伤分割的识别准确率,采集了带有损伤特征的金属部件损伤表面点云,对点云进行预处理㊂对若干金属部件上的多个样本金属面的点云数据进行筛选,删除损伤占比低于5%或高于60%的数据后,划分并装包制作为点云数据集㊂采用CloudCompare 软件对样本金属上的损伤部分进行分类标记,共分为6种如上所述损伤㊂部件损伤的数据集制作参考点云深度学习领域广泛应用的公开数据集ModelNet40part㊂分割数据集包含了多种类型的金属部件损伤数据,这些损伤数据显示在510张总点云图像数据中㊂点云图像种类丰富,由各种包含损伤的金属表面构成,例如金属门,金属蒙皮,机械构件外表面等㊂用ArcGIS 内相关工具将总图进行随机点拆分,根据数据集ModelNet40part 的规格,每个独立的点云数据组含有1024个点,将所有总图拆分为510×128个单元点云㊂将样本分为400个训练集与110个测试集,采用交叉验证方法以保证测试的充分性[20],对多种方法进行评估测试,实验结果由单元点云按原点位置重新组合而成,并带有拆分后对单元点云进行的分割标记㊂分割结果比较如图8所示㊂726第4期张闻锐,等:特征更新的动态图卷积表面损伤点云分割方法图8 分割结果比较图Fig.8 Comparison of segmentation results在部件损伤分割的实验中,将不同网络与笔者网络(FAS⁃DGCNN:Feature Adaptive Shifting⁃Dynamic Graph Convolutional Neural Networks)进行对比㊂除了采用不同的分割网络外,其余实验均采用与改进的图卷积深度神经网络方法相同的实验设置㊂实验结果由单一损伤交并比(IoU:Intersection over Union),平均损伤交并比(MIoU),单一损伤准确率(Accuracy)和总体损伤准确率(OA)进行评价,结果如表2~表4所示㊂将6种不同损伤类别的Accuracy 与IoU 进行对比分析,可得出结论:相比于基准实验网络Pointet++,笔者在OA 和MioU 方面分别在贯通伤和非贯通伤上有10%和20%左右的提升,在整体分割指标上,OA 能达到90.8%㊂对拥有更多点数支撑,含有较多点云特征的非贯通伤,几种点云分割网络整体性能均能达到90%左右的效果㊂而不具有局部特征识别能力的PointNet 在贯通伤上的表现较差,不具备有效的分辨能力,导致分割效果相对于其他损伤较差㊂表2 损伤部件分割准确率性能对比 Tab.2 Performance comparison of segmentation accuracy of damaged parts %实验方法准确率凹陷⁃1凸起⁃2穿孔⁃3表面损伤⁃4破损⁃5缺损⁃6Ponitnet 82.785.073.880.971.670.1Pointnet++88.786.982.783.486.382.9DGCNN 90.488.891.788.788.687.1FAS⁃DGCNN 92.588.892.191.490.188.6826吉林大学学报(信息科学版)第41卷表3 损伤部件分割交并比性能对比 Tab.3 Performance comparison of segmentation intersection ratio of damaged parts %IoU 准确率凹陷⁃1凸起⁃2穿孔⁃3表面损伤⁃4破损⁃5缺损⁃6PonitNet80.582.770.876.667.366.9PointNet++86.384.580.481.184.280.9DGCNN 88.786.589.986.486.284.7FAS⁃DGCNN89.986.590.388.187.385.7表4 损伤分割的整体性能对比分析 出,动态卷积图特征以及有效的邻域特征更新与多尺度注意力给分割网络带来了更优秀的局部邻域分割能力,更加适应表面损伤分割的任务要求㊂3 结 语笔者利用三维点云独特的空间结构特征,将传统K 邻域内权重相近的邻域点采用空间尺度进行区分,并将空间尺度划分运用于邻域内权重分配上,提出了一种能将邻域内噪声点降权筛除的特征更新模块㊂采用此模块的动态图卷积网络在分割上表现出色㊂利用特征更新的动态图卷积网络(FAS⁃DGCNN)能有效实现金属表面损伤的分割㊂与其他网络相比,笔者方法在点云语义分割方面表现出更高的可靠性,可见在包含空间尺度区域信息的注意力和局域点云特征更新下,笔者提出的基于特征更新的动态图卷积网络能发挥更优秀的作用,而且相比缺乏局部特征提取能力的分割网络,其对于点云稀疏㊁特征不明显的非贯通伤有更优的效果㊂参考文献:[1]LAWIN F J,DANELLJAN M,TOSTEBERG P,et al.Deep Projective 3D Semantic Segmentation [C]∥InternationalConference on Computer Analysis of Images and Patterns.Ystad,Sweden:Springer,2017:95⁃107.[2]MATURANA D,SCHERER S.VoxNet:A 3D Convolutional Neural Network for Real⁃Time Object Recognition [C]∥Proceedings of IEEE /RSJ International Conference on Intelligent Robots and Systems.Hamburg,Germany:IEEE,2015:922⁃928.[3]LE T,DUAN Y.PointGrid:A Deep Network for 3D Shape Understanding [C]∥2018IEEE /CVF Conference on ComputerVision and Pattern Recognition (CVPR).Salt Lake City,USA:IEEE,2018:9204⁃9214.[4]QI C R,SU H,MO K,et al.PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation [C]∥IEEEConference on Computer Vision and Pattern Recognition (CVPR).Hawaii,USA:IEEE,2017:652⁃660.[5]QI C R,SU H,MO K,et al,PointNet ++:Deep Hierarchical Feature Learning on Point Sets in a Metric Space [C]∥Advances in Neural Information Processing Systems.California,USA:SpringerLink,2017:5099⁃5108.[6]HU J,SHEN L,SUN G,Squeeze⁃and⁃Excitation Networks [C ]∥IEEE Conference on Computer Vision and PatternRecognition.Vancouver,Canada:IEEE,2018:7132⁃7141.[7]LI Y,BU R,SUN M,et al.PointCNN:Convolution on X⁃Transformed Points [C]∥Advances in Neural InformationProcessing Systems.Montreal,Canada:NeurIPS,2018:820⁃830.[8]ANH VIET PHAN,MINH LE NGUYEN,YEN LAM HOANG NGUYEN,et al.DGCNN:A Convolutional Neural Networkover Large⁃Scale Labeled Graphs [J].Neural Networks,2018,108(10):533⁃543.[9]任伟建,高梦宇,高铭泽,等.基于混合算法的点云配准方法研究[J].吉林大学学报(信息科学版),2019,37(4):408⁃416.926第4期张闻锐,等:特征更新的动态图卷积表面损伤点云分割方法036吉林大学学报(信息科学版)第41卷REN W J,GAO M Y,GAO M Z,et al.Research on Point Cloud Registration Method Based on Hybrid Algorithm[J]. Journal of Jilin University(Information Science Edition),2019,37(4):408⁃416.[10]ZHANG K,HAO M,WANG J,et al.Linked Dynamic Graph CNN:Learning on Point Cloud via Linking Hierarchical Features[EB/OL].[2022⁃03⁃15].https:∥/stamp/stamp.jsp?tp=&arnumber=9665104. [11]林少丹,冯晨,陈志德,等.一种高效的车体表面损伤检测分割算法[J].数据采集与处理,2021,36(2):260⁃269. LIN S D,FENG C,CHEN Z D,et al.An Efficient Segmentation Algorithm for Vehicle Body Surface Damage Detection[J]. Journal of Data Acquisition and Processing,2021,36(2):260⁃269.[12]ZHANG L P,ZHANG Y,CHEN Z Z,et al.Splitting and Merging Based Multi⁃Model Fitting for Point Cloud Segmentation [J].Journal of Geodesy and Geoinformation Science,2019,2(2):78⁃79.[13]XING Z Z,ZHAO S F,GUO W,et al.Processing Laser Point Cloud in Fully Mechanized Mining Face Based on DGCNN[J]. ISPRS International Journal of Geo⁃Information,2021,10(7):482⁃482.[14]杨军,党吉圣.基于上下文注意力CNN的三维点云语义分割[J].通信学报,2020,41(7):195⁃203. YANG J,DANG J S.Semantic Segmentation of3D Point Cloud Based on Contextual Attention CNN[J].Journal on Communications,2020,41(7):195⁃203.[15]陈玲,王浩云,肖海鸿,等.利用FL⁃DGCNN模型估测绿萝叶片外部表型参数[J].农业工程学报,2021,37(13): 172⁃179.CHEN L,WANG H Y,XIAO H H,et al.Estimation of External Phenotypic Parameters of Bunting Leaves Using FL⁃DGCNN Model[J].Transactions of the Chinese Society of Agricultural Engineering,2021,37(13):172⁃179.[16]柴玉晶,马杰,刘红.用于点云语义分割的深度图注意力卷积网络[J].激光与光电子学进展,2021,58(12):35⁃60. CHAI Y J,MA J,LIU H.Deep Graph Attention Convolution Network for Point Cloud Semantic Segmentation[J].Laser and Optoelectronics Progress,2021,58(12):35⁃60.[17]张学典,方慧.BTDGCNN:面向三维点云拓扑结构的BallTree动态图卷积神经网络[J].小型微型计算机系统,2021, 42(11):32⁃40.ZHANG X D,FANG H.BTDGCNN:BallTree Dynamic Graph Convolution Neural Network for3D Point Cloud Topology[J]. Journal of Chinese Computer Systems,2021,42(11):32⁃40.[18]张佳颖,赵晓丽,陈正.基于深度学习的点云语义分割综述[J].激光与光电子学,2020,57(4):28⁃46. ZHANG J Y,ZHAO X L,CHEN Z.A Survey of Point Cloud Semantic Segmentation Based on Deep Learning[J].Lasers and Photonics,2020,57(4):28⁃46.[19]SUN Y,ZHANG S H,WANG T Q,et al.An Improved Spatial Point Cloud Simplification Algorithm[J].Neural Computing and Applications,2021,34(15):12345⁃12359.[20]高福顺,张鼎林,梁学章.由点云数据生成三角网络曲面的区域增长算法[J].吉林大学学报(理学版),2008,46 (3):413⁃417.GAO F S,ZHANG D L,LIANG X Z.A Region Growing Algorithm for Triangular Network Surface Generation from Point Cloud Data[J].Journal of Jilin University(Science Edition),2008,46(3):413⁃417.(责任编辑:刘俏亮)。
目标跟踪相关资源(含模型,CVPR2017论文,代码,牛人等)Visual TrackersECO: Martin Danelljan, Goutam Bhat, Fahad Shahbaz Khan, Michael Felsberg. "ECO: Efficient Convolution Operators for Tracking." CVPR (2017). [paper] [project] [github]CFNet: Jack Valmadre, Luca Bertinetto, Jo?o F. Henriques, Andrea Vedaldi, Philip H. S. Torr. "End-to-end representation learning for Correlation Filter based tracking." CVPR (2017). [paper] [project] [github]CACF: Matthias Mueller, Neil Smith, Bernard Ghanem. "Context-Aware Correlation Filter Tracking." CVPR (2017 oral). [paper] [project] [code]RaF: Le Zhang, Jagannadan Varadarajan, Ponnuthurai Nagaratnam Suganthan, Narendra Ahuja and Pierre Moulin "Robust Visual Tracking Using Oblique Random Forests." CVPR (2017). [paper] [project] [code]MCPF: Tianzhu Zhang, Changsheng Xu, Ming-Hsuan Yang. "Multi-task Correlation Particle Filter for Robust Visual Tracking ." CVPR (2017). [paper] [project] [code]ACFN: Jongwon Choi, Hyung Jin Chang, Sangdoo Yun, Tobias Fischer, Yiannis Demiris, and Jin Young Choi. "Attentional Correlation Filter Network for Adaptive Visual Tracking." CVPR (2017) [paper] [project] [test code)][training code]LMCF: Mengmeng Wang, Yong Liu, Zeyi Huang. "Large Margin Object Tracking with Circulant Feature Maps." CVPR (2017). [paper] [zhihu]ADNet: Sangdoo Yun, Jongwon Choi, Youngjoon Yoo, Kimin Yun, Jin Young Choi. "Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning ." CVPR (2017). [paper] [project]CSR-DCF: Alan Luke?i?, Tomá? Vojí?, Luka ?ehovin, Ji?í Matas, Matej Kristan. "Discriminative Correlation Filter with Channel and Spatial Reliability." CVPR (2017). [paper][code]BACF: Hamed Kiani Galoogahi, Ashton Fagg, Simon Lucey. "Learning Background-Aware Correlation Filters for Visual Tracking." CVPR (2017). [paper]Bohyung Han, Jack Sim, Hartwig Adam "BranchOut: Regularization for Online Ensemble Tracking with Convolutional Neural Networks." CVPR (2017).SANet: Heng Fan, Haibin Ling. "SANet: Structure-Aware Network for Visual Tracking." CVPRW (2017). [paper] [project] [code]DNT: Zhizhen Chi, Hongyang Li, Huchuan Lu, Ming-Hsuan Yang. "Dual Deep Network for Visual Tracking." TIP (2017). [paper]DRT: Junyu Gao, Tianzhu Zhang, Xiaoshan Yang, Changsheng Xu. "Deep Relative Tracking." TIP (2017). [paper]BIT: Bolun Cai, Xiangmin Xu, Xiaofen Xing, Kui Jia, Jie Miao, Dacheng Tao. "BIT: Biologically Inspired Tracker." TIP (2016). [paper] [project][github]SiameseFC: Luca Bertinetto, Jack Valmadre, Jo?o F. Henriques, Andrea Vedaldi, Philip H.S. Torr. "Fully-Convolutional Siamese Networks for Object Tracking." ECCV workshop (2016). [paper] [project] [github]GOTURN: David Held, Sebastian Thrun, Silvio Savarese. "Learning to Track at 100 FPS with Deep Regression Networks." ECCV (2016). [paper] [project] [github]C-COT: Martin Danelljan, Andreas Robinson, Fahad Khan, Michael Felsberg. "Beyond Correlation Filters: Learning Continuous Convolution Operators for Visual Tracking." ECCV (2016). [paper] [project] [github]CF+AT: Adel Bibi, Matthias Mueller, and Bernard Ghanem. "Target Response Adaptation for Correlation Filter Tracking." ECCV (2016). [paper] [project]MDNet: Nam, Hyeonseob, and Bohyung Han. "Learning Multi-Domain Convolutional Neural Networks for Visual Tracking." CVPR (2016). [paper] [VOT_presentation] [project] [github]SINT: Ran Tao, Efstratios Gavves, Arnold W.M. Smeulders. "Siamese Instance Search for Tracking." CVPR (2016). [paper] [project]SCT: Jongwon Choi, Hyung Jin Chang, Jiyeoup Jeong, Yiannis Demiris, and Jin Young Choi. "Visual Tracking Using Attention-Modulated Disintegration and Integration." CVPR (2016). [paper] [project]STCT: Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "STCT: Sequentially TrainingConvolutional Networks for Visual Tracking." CVPR (2016). [paper] [github]SRDCFdecon: Martin Danelljan, Gustav H?ger, Fahad Khan, Michael Felsberg. "Adaptive Decontamination of the Training Set: A Unified Formulation for Discriminative Visual Tracking." CVPR (2016). [paper] [project]HDT: Yuankai Qi, Shengping Zhang, Lei Qin, Hongxun Yao, Qingming Huang, Jongwoo Lim, Ming-Hsuan Yang. "Hedged Deep Tracking." CVPR (2016). [paper] [project]Staple: Luca Bertinetto, Jack Valmadre, Stuart Golodetz, Ondrej Miksik, Philip H.S. Torr. "Staple: Complementary Learners for Real-Time Tracking." CVPR (2016). [paper] [project] [github]DLSSVM: Jifeng Ning, Jimei Yang, Shaojie Jiang, Lei Zhang and Ming-Hsuan Yang. "Object Tracking via Dual Linear Structured SVM and Explicit Feature Map." CVPR (2016). [paper] [code] [project]CNT: Kaihua Zhang, Qingshan Liu, Yi Wu, Minghsuan Yang. "Robust Visual Tracking via Convolutional Networks Without Training." TIP (2016). [paper] [code]DeepSRDCF: Martin Danelljan, Gustav H?ger, Fahad Khan, Michael Felsberg. "Convolutional Features for Correlation Filter Based Visual Tracking." ICCV workshop (2015). [paper] [project]SRDCF: Martin Danelljan, Gustav H?ger, Fahad Khan, Michael Felsberg. "Learning Spatially Regularized Correlation Filters for Visual Tracking." ICCV (2015). [paper][project]CNN-SVM: Seunghoon Hong, Tackgeun You, Suha Kwak and Bohyung Han. "Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network ." ICML (2015) [paper] [project]CF2: Chao Ma, Jia-Bin Huang, Xiaokang Yang and Ming-Hsuan Yang. "Hierarchical Convolutional Features for Visual Tracking." ICCV (2015) [paper] [project] [github]FCNT: Lijun Wang, Wanli Ouyang, Xiaogang Wang, and Huchuan Lu. "Visual Tracking with Fully Convolutional Networks." ICCV (2015). [paper] [project] [github]LCT: Chao Ma, Xiaokang Yang, Chongyang Zhang, Ming-Hsuan Yang. "Long-term Correlation Tracking." CVPR (2015). [paper] [project] [github]RPT: Yang Li, Jianke Zhu and Steven C.H. Hoi. "Reliable Patch Trackers: Robust Visual Tracking by Exploiting Reliable Patches." CVPR (2015). [paper] [github]CLRST: Tianzhu Zhang, Si Liu, Narendra Ahuja, Ming-Hsuan Yang, Bernard Ghanem."Robust Visual Tracking Via Consistent Low-Rank Sparse Learning." IJCV (2015). [paper] [project] [code]DSST: Martin Danelljan, Gustav H?ger, Fahad Shahbaz Khan and Michael Felsberg. "Accurate Scale Estimation for Robust Visual Tracking." BMVC (2014). [paper] [PAMI] [project]MEEM: Jianming Zhang, Shugao Ma, and Stan Sclaroff. "MEEM: Robust Tracking via Multiple Experts using Entropy Minimization." ECCV (2014). [paper] [project]TGPR: Jin Gao,Haibin Ling, Weiming Hu, Junliang Xing. "Transfer Learning Based Visual Tracking with Gaussian Process Regression." ECCV (2014). [paper] [project]STC: Kaihua Zhang, Lei Zhang, Ming-Hsuan Yang, David Zhang. "Fast Tracking via Spatio-Temporal Context Learning." ECCV (2014). [paper] [project]SAMF: Yang Li, Jianke Zhu. "A Scale Adaptive Kernel Correlation Filter Tracker with Feature Integration." ECCV workshop (2014). [paper] [github]KCF: Jo?o F. Henriques, Rui Caseiro, Pedro Martins, Jorge Batista. "High-Speed Tracking with Kernelized Correlation Filters." TPAMI (2015). [paper] [project]OthersRe3: Daniel Gordon, Ali Farhadi, Dieter Fox. "Re3 : Real-Time Recurrent Regression Networks for Object Tracking." arXiv (2017). [paper] [code]DCFNet: Qiang Wang, Jin Gao, Junliang Xing, Mengdan Zhang, Weiming Hu. "Modeling and Propagating CNNs in a Tree Structure for Visual Tracking." arXiv (2017). [paper] [code]TCNN: Hyeonseob Nam, Mooyeol Baek, Bohyung Han. "Modeling and Propagating CNNs in a Tree Structure for Visual Tracking." arXiv (2016). [paper] [code]RDT: Janghoon Choi, Junseok Kwon, Kyoung Mu Lee. "Visual Tracking by Reinforced Decision Making." arXiv (2017). [paper]MSDAT: Xinyu Wang, Hanxi Li, Yi Li, Fumin Shen, Fatih Porikli . "Robust and Real-time Deep Tracking Via Multi-Scale DomainAdaptation." arXiv (2017). [paper]RLT: Da Zhang, Hamid Maei, Xin Wang, Yuan-Fang Wang. "Deep Reinforcement Learning for Visual Object Tracking in Videos." arXiv (2017). [paper]SCF: Wangmeng Zuo, Xiaohe Wu, Liang Lin, Lei Zhang, Ming-Hsuan Yang. "Learning Support Correlation Filters for Visual Tracking." arXiv (2016). [paper] [project]DMSRDCF: Susanna Gladh, Martin Danelljan, Fahad Shahbaz Khan, Michael Felsberg. "Deep Motion Features for Visual Tracking." ICPR Best Paper (2016). [paper]CRT: Kai Chen, Wenbing Tao. "Convolutional Regression for Visual Tracking." arXiv (2016). [paper]BMR: Kaihua Zhang, Qingshan Liu, and Ming-Hsuan Yang. "Visual Tracking via Boolean Map Representations." arXiv (2016). [paper]YCNN: Kai Chen, Wenbing Tao. "Once for All: a Two-flow Convolutional Neural Network for Visual Tracking." arXiv (2016). [paper]Learnet: Luca Bertinetto, Jo?o F. Henriques, Jack Valmadre, Philip H. S. Torr, Andrea Vedaldi. "Learning feed-forward one-shot learners." NIPS (2016). [paper]ROLO: Guanghan Ning, Zhi Zhang, Chen Huang, Zhihai He, Xiaobo Ren, Haohong Wang. "Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking." arXiv (2016). [paper] [project] [github]Yao Sui, Ziming Zhang, Guanghui Wang, Yafei Tang, Li Zhang. "Real-Time Visual Tracking: Promoting the Robustness ofCorrelation Filter Learning." ECCV (2016). [paper] [project]Yao Sui, Guanghui Wang, Yafei Tang, Li Zhang. "Tracking Completion." ECCV (2016). [paper] [project]EBT: Gao Zhu, Fatih Porikli, and Hongdong Li. "Beyond Local Search: Tracking Objects Everywhere with Instance-Specific Proposals." CVPR (2016). [paper] [exe]RATM: Samira Ebrahimi Kahou, Vincent Michalski, Roland Memisevic. "RATM: Recurrent Attentive Tracking Model." arXiv (2015). [paper] [github]DAT: Horst Possegger, Thomas Mauthner, and Horst Bischof. "In Defense of Color-based Model-free Tracking." CVPR (2015). [paper] [project] [code]RAJSSC: Mengdan Zhang, Junliang Xing, Jin Gao, Xinchu Shi, Qiang Wang, Weiming Hu. "Joint Scale-Spatial Correlation Tracking with Adaptive Rotation Estimation." ICCV workshop (2015). [paper] [poster]SO-DLT: Naiyan Wang, Siyi Li, Abhinav Gupta, Dit-Yan Yeung. "Transferring Rich Feature Hierarchies for Robust Visual Tracking." arXiv (2015). [paper] [code]DLT: Naiyan Wang and Dit-Yan Yeung. "Learning A Deep Compact Image Representation for Visual Tracking." NIPS (2013). [paper] [project] [code]Naiyan Wang, Jianping Shi, Dit-Yan Yeung and Jiaya Jia. "Understanding and Diagnosing Visual Tracking Systems." ICCV (2015). [paper] [project] [code]Dataset-MoBe2016:Luka ?ehovin, Alan Luke?i?, Ale? Leonardis, Matej Kristan. "Beyond standard benchmarks: Parameterizing performance evaluation in visual object tracking." arXiv (2016). [paper]Dataset-UAV123: Matthias Mueller, Neil Smith and Bernard Ghanem. "A Benchmark and Simulator for UAV Tracking." ECCV (2016) [paper] [project] [dataset]Dataset-TColor-128: Pengpeng Liang, Erik Blasch, Haibin Ling. "Encoding color information for visual tracking: Algorithms and benchmark." TIP (2015) [paper] [project] [dataset]Dataset-NUS-PRO: Annan Li, Min Lin, Yi Wu, Ming-Hsuan Yang, and Shuicheng Yan. "NUS-PRO: A New Visual Tracking Challenge." PAMI (2015) [paper] [project] [Data_360(code:bf28)]?[Data_baidu]][View_360(code:515a)]?[View_baidu]]Dataset-PTB: Shuran Song and Jianxiong Xiao. "Tracking Revisited using RGBD Camera: Unified Benchmark and Baselines." ICCV (2013) [paper] [project] [5 validation] [95 evaluation]Dataset-ALOV300+: Arnold W. M. Smeulders, Dung M. Chu, Rita Cucchiara, Simone Calderara, Afshin Dehghan, Mubarak Shah. "Visual Tracking: An Experimental Survey." PAMI (2014) [paper] [project]?Mirror Link:ALOV300++ Dataset?Mirror Link:ALOV300++ GroundtruthDataset-DTB70: Siyi Li, Dit-Yan Yeung. "Visual Object Tracking for Unmanned Aerial Vehicles: A Benchmark andNew Motion Models." AAAI (2017) [paper] [project] [dataset]Dataset-VOT: [project][VOT13_paper_ICCV]The Visual Object Tracking VOT2013 challenge results[VOT14_paper_ECCV]The Visual Object Tracking VOT2014 challenge results[VOT15_paper_ICCV]The Visual Object Tracking VOT2015 challenge results[VOT16_paper_ECCV]The Visual Object Tracking VOT2016 challenge results深度学习方法(Deep Learning Method)由于其独有的优越性成为当前研究的热点,各种框架和算法层出不穷,这在前文的目标检测部分都有较为详细的介绍。
ISSN 1674-8484 CN 11-5904/U汽车安全与节能学报, 2015年, 第6卷第1期J Automotive Safety and Energy, 2015, Vol. 6 No. 1Vehicle Sideslip Angle Estimation based on Fusion of Kinematics-Dynamics MethodsGAO Bolin 1,2, XIE Shugang 2, GONG Jinfeng 2(1. School of Mechanical Engineering, Tianjin University, Tianjin 300072, China;2. China Automotive Technology & Research Center, Tianjin 300300, China)Abstract: A novel method of vehicle sideslip angle estimation was proposed based on a fusion of kinematics and dynamics methods to improve the estimation accuracy. A sideslip angle fusion observer (SAFO) was constructed with three local filters to estimate lateral velocities sending preliminary output to a master filter. The master filter fuses the outputs from all local filters to calculate a global sideslip angle estimation result according to driving information and fusion rules. The results show that the SAFO has good estimation accuracy and stability in a long time running with good robust for sensor signal bias. Therefore, the vehicle test data verifies the SAFO performances.Keywords: vehicle safety; sideslip angle estimation; kinematics method; dynamics method; fusion observer;pseudo-integration基于运动学—动力学方法融合的汽车质心侧偏角估计(英文)高博麟1,2,谢书港2,龚进峰2(1. 天津大学机械工程学院,天津 300072,中国;2. 中国汽车技术研究中心,天津 300300,中国)摘 要: 为了提高汽车质心侧偏角估计的准确性,提出了一种新的、基于运动学—动力学方法的融合估计方法。
Towards Robust Multi-Cue Integration for VisualTrackingMartin Spengler and Bernt SchielePerceptual Computing and Computer Vision GroupComputer Science DepartmentETH Zurich,Switzlerandspengler,schiele@inf.ethz.chAbstract.Even though many of today’s vision algorithms are very successful,they lack robustness since they are typically limited to a particular situation.Inthis paper we argue that the principles of sensor and model integration can in-crease the robustness of today’s computer vision systems substantially.As anexample multi-cue tracking of faces is discussed.The approach is based on theprinciples of self-organization of the integration mechanism and self-adaptationof the cue models during tracking.Experiments show that the robustness of sim-ple models is leveraged significantly by sensor and model integration.1IntroductionIn the literature several algorithms are reported for precise object tracking in real-time. However,since most approaches to tracking are based on a single cue they are most often restricted to particular environmental conditions which are static,controlled or known a priori.Since no single visual cue will be robust and general enough to deal with a wide variety of environmental conditions their combination promises to increase robustness and generality.In this paper we argue that in order to obtain robust tracking in dynamically changing environments any approach should aim to use and integrate different plementary cues allow tracking under a wider range of different conditions than any single cue alone.Redundant cues on the other hand allow to eval-uate the current tracking result and therefore allow to adapt the integration mechanism and the visual cues themselves in order to allow optimal integration.In our belief,optimal context-dependent combination of information will be key to the long-term goal of robust object tracking.In order to enable robustness over time it is essential to use multiple cues simultaneously.Most approaches–based on multiple cues–only use one cue at a time therefore optimizing performance rather than ing multiple cues simultaneously allows not only to use complementary and redundant information at all times but also allows to detect failures more robustly and thus enabling recovery.This paper introduces a general system framework for the integration of multi-ple cues.The ultimate goal of the framework is to increase and enable robust object tracking in dynamically changing environments.The general framework exploits two methodologies for the adaptation to different conditions:firstly the integration schemecan be changed and secondly the visual cues themselves can be adapted.Adapting the visual cues allows to adapt to different environmental changes directly.Changing the integration scheme reflects the underlying assumption that different cues are suitable for different conditions.Based on this general framework two different approaches are introduced and experimentally analyzed.This paper discusses the development of a system which aims at robust tracking through self-adaptive multi-cue integration.Democratic Integration introduced by Tri-esch and Malsburg[15]may be seen as an example of such a system.Section4in-troduces and discusses a modified version of Democratic Integration.The approach is evaluated experimentally and several shortcomings are identified.In particular,the orig-inal approach is limited to the tracking of a single target which leads to the proposition of a second system(Sect.5).In this system multi-hypotheses tracking and multi-cue integration is realized by means of C ONDENSATION,a conditional density propagation algorithm proposed by Isard and Blake[2].Expectation maximization(EM)is used to obtain more reliable probability densities of the single-cue observations.Again,exper-imental results are reported and discussed.2Related WorkAlthough it is well known that the integration of multiple cues is a key prerequisite for robust biological and machine vision,most of today’s tracking approaches are based on single cues.Even approaches which are called multi-cue in the literature often do not use their cues in parallel or treat them as equivalent channels.On the contrary, many approaches try to select the“optimal”cue for the actually perceived context. Also common is to use a single,predominant cue supported by other,often less reliable cues.The layered hierarchy of vision based tracking algorithms proposed by Toyama and Hager[13,12]is a good example for the cue selection approach.Their declared goal is to enable robust,adaptive tracking in real-time.Different tracking algorithms are selected with respect to the actual conditions:Whenever conditions are good,an accurate and precise tracking algorithm is employed.When conditions deteriorate more robust but less accurate algorithms are chosen.Crowley and Berard[5]have proposed to use three different tracking algorithms in a similar way as proposed by Toyama and Hager.Isard and Blake proposed the now popular C ONDENSATION algorithm[8].The orig-inal algorithm–well suited for simultaneous multi-hypotheses tracking–has been ex-tended[9]by a second supportive cue(color in their case)which allows to recover from tracking failures.C ONDENSATION and its derivative I CONDENSATION possess two important properties:C ONDENSATION is able to track multiple target hypotheses simultaneously which is important in the presence of multiple targets but also for re-covery from tracking failure.In addition,C ONDENSATION is well suited for concurrent integration of multiple visual cues even though not explicitly proposed by Isard and Blake.Democratic Integration,an approach proposed by Triesch and Malsburg[15]im-plements concurrent cue integration:All visual cues contribute simultaneously to theoverall result and none of the cues has an outstanding relevance compared to the others. Again,robustness and generality is a major motivation for the proposal.Triesch et al [14]convincingly argue for the need for adaptive multi-cue integration and support their claims with psychophysical experiments.Adaptivity is a key point in which democratic integration contrasts with other integration mechanisms.Following the classification scheme of Clark and Yuille[4],democratic integration implements weakly coupled cue integration.That is,the used cues are independent in a probabilistic sense1.Democratic integration and similar weakly coupled data fusion methods are also closely related to voting[11].The weighted sum approach of democratic integration may be seen as weighted plurality voting as proposed in[10].A more thorough analysis of the relations between sensor fusion and voting can be found in[3].In the following section we propose a general system framework.We strongly be-lieve that a robust and reliable tracking system has to have at least three key proberties: Multi-cue integration,context-sensitive adaptivity and the ability to simultaneously pur-sue multiple target hypotheses.Due to its interesting and favorable properties we have chosen democratic integration as an exemplary implementation of the general approach. In order to track multiple target hypotheses simultaneously,we integrated C ONDENSA-TION into our system as well.The combination of these two promising approaches leads to a tracking system which has all three above mentioned key properties.3General System FrameworkThis section describes the general system framework based on the integration of multi-ple cues.The ultimate goal of the framework is to enable robust tracking in dynamically changing environments.Visual cues should be complementary as well as redundant as motivated above.An important aspect of the general framework is that it is adaptable depending on the actual context.In order to adapt the system optimally the actual track-ing results are evaluated and fed back to the integration mechanism as well as to the visual cues themselves.This allows to adapt the integration and the visual cues opti-mally to the current situation.The general system framework is depicted in Fig.1.Based on a series of images (called sensor data in the following)visual cues are implemented. Each visual cue estimates the target’s state vector individually.These estimations are then fused by the multi-cue integration unit into a single probability density.Based on this probability density the multi-cue state estimator estimates potential target po-sitions.These estimated target positions as well as the probability density are then fed back to the multi-cue integration unit and the visual cues in order to adapt their internal states aiming to improve the overall performance.The pro-posed formulation is general andflexible with respect to different visual cues as well as different integration mechanisms.Also any feedback mechanism may be used enabling for example to use high level knowledge about the particular object or environment. Following Fig.1we introduce notations for the different stages of the framework:(3) Feedback The set of estimated target state vectors as well as the probability distribution are fed back to the multi-cue integration unit and the single-cue observation units in order to adapt their parameterizations and.4Democratic IntegrationDemocratic Integration,thefirst implementation of our general system framework,was originally proposed by Triesch at.al.[15].Five visual cues agree upon a common po-sition estimation.The individual cues are then evaluated on this estimation in order to determine their weights for the following time step.Additionally,every single cue adapts its internal model to increase the system’s overall performance.At every moment two fundamental assumptions must be fulfilled:First,consensus between the individual cues must be predominant.Second,environmental changes must only affect a minority of the visual cues.4.1System DescriptionSensor&Single-cue Observation Democratic Integration currently works on two-dimensional color images.The system’s sensor module(see Fig.1middle column) captures a sequence of color images and dispatches them to the attached single-cue observation units.These map the images to two-dimensional saliency maps expressing the observation’s probability for every position.Democratic Integration implements the following single-cue observations:The intensity change cue detects motion in a gray-level image relative to its predecessor.Motion is thus pixel-wise defined as the difference of inten-sity between two subsequent images.Skin color detection calculates for every pixel the probability of skin color.More specifically human skin color is modeled as a specific subspace of the HSI2color space.Depending only on the system’s target po-sition estimations,the motion prediction cue predicts the target’s future motion to maintain motion continuity.In contrast to the original paper[15]we imple-mented a motion prediction unit using Kalmanfiltering.In order to determine potential head positions,the shape template matching cue correlates the gray-level in-put image and a head template for every position in the input image.The contrast cue extracts contrast pixel-wise from the input image.Contrast,defined over the pixel’s neighborhood,is compared to a adaptive model of contrast in order to detect pixels with salient contrast.All visual cues except the intensity change cue can be adapted.Multi-cue Integration&Multi-cue State Estimation Democratic Integration imple-ments context-dependent multi-cue integration by means of a weighted sum of the cues’probability densities:(4) Adapting the weights dynamically with respect to the cues’former performance opens the possibility to react on alternating situations.Conforming with the general system framework introduced in Sect.3,Democratic Integration provides a multi-cue state estimation scheme:(5) That is,the estimated target position is defined as the maximal response of the com-bined probability distribution.This choice of a multi-cue state estimation isreasonable when the probability distribution has a single non-ambiguous max-ima.However,the target state estimation scheme fails as soon as multiple hypotheses with similar probability emerge.Feedback Once the system is initialized,Democratic Integration provides means to adjust its parameters with respect to the current situation.As outlined in Sect.3,unsu-pervised self-adaptation occurs in two different levels:1.Self-organized Multi-cue Integration Adapting the integration mechanism itselfmakes it possible to select those visual cues which are reliable in the current context and to suppress the other ones.In Democratic Integration,this selection mechanism is implemented by the following dynamics:(6)where is a normalized quality measurement of cue relative to the estima-tion and is a constant determining how fast the weights are adapted.Quality measurement is defined as the normalized distance between response and average response.2.Auto-adaptive Single-cue Observation In analogy to the feedback loop for themulti-cue integration,the models of the single-cue observations are adapted by the following dynamics:(7)where extracts a suitable feature vector from image at position.Again,time constant controls the speed for adapting the model/parameters.As is,the feedback mechanism relies on the decision for a single target position estimate.The system is therefore limited to single target tracking and incapable of tracking multiple targets or even multiple target hypotheses.This is a major shortcom-ing of Democratic Integration as we will see in the experiments.4.2Analysis of Democratic IntegrationColor-change Sequence The color change sequence(Fig.2)challenges the two most important visual cues for Democratic Integration,intensity change and skin color de-tection.Both of them start with initial reliabilities whereas the remaining cues have initial weights.This setup expresses the a priori knowledgeone has about the task:Tracking skin colored regions which are in motion.After an initial period of convergence toward balanced weights,the ambient illumi-nation changes abruptly from white to green(see Fig.2,frame24).Hence skin color detection fails completely and intensity change’s reliability is also decreased for sev-eral frames.However,motion prediction is able to compensate.As soon as the lighting regains constancy(frame30),intensity change becomes reliable again and its weight is increased.Skin color detection fails until the skin color model has adapted to the new conditions(frame40).Afterward its weight increases too,converging toward for-mer equilibrium.When the subject leaves the scene(frame50),tracking is lost and the weights are re-adapted toward their default values.Shape template matching and contrast have only supporting character in this sequence.Soccer Sequence The soccer sequence depicted in Fig.3challenges Democratic In-tegration since it is captured in an uncontrolled environment.Furthermore,different potential targets appear and disappear over time.Similar to the color-change sequence discussed above,the weights converge toward an equilibrium in an initial period.When the tracked subject leaves the scene in frame38,tracking is lost and re-adaptation to-ward default weights begins.After re-entrance(frame53),the system continues to track the target.Failure of skin color detection between frame60and frame80is compen-sated by the remaining cues,namely motion prediction and contrast.After the skin color cue has recovered,a period of convergence lasts until the target’s occlusion in frame123causes reorganization.Finally,tracking is lost when the target disappears and the weights are re-adapted toward their default values.Two Person Sequence Looking at the problem of simultaneous tracking of multiple potential targets,this sequence shows more than one subject simultaneously.Also,the two subject cross,occluding one another.Due to the delay between arrival of subject one and subject two,the system is able to lock on subject one.The initial period of stable equilibrium lasts until the two subjects begin to shake hands in frame40.At this point they do not move anymore and therefore the intensity change cue looses weight. Tracking continues although subject one is occluded by subject two when they cross. After a second period of equilibrium,the weights converge toward their default values after both targets have left the scene.Throughout the entire sequence,subject one is tracked successfully.Since the system can track only one target at any time it is rather unpredictable which subject is tracked after they met.This exemplifies that the system is inherently limited to single target tracking.Discussion In the experiments,Democratic Integration proved the concept of dynamic context-dependent multi-cue integration as a promising technique to achieve reliable tracking under uncontrolled conditions.Under steady conditions,the system convergestoward an equilibrium whereas sudden changes in the environment provoke re-organization of the system.As expected,failure of a visual cue is compensated by other cues in or-der to maintain continuous tracking.Several cues are able to recover after a failure by adapting their internal states to the changed situation.Nevertheless,Democratic Integration has several major shortcomings:The most obvious one is the system’s inherent limitation to single target tracking.That is,Demo-cratic Integration is not able to track multiple(potential)targets simultaneously.Fur-thermore,self-organizing systems like Democratic Integration are likely to fail in cases where they start tracking false positives.In such cases the system may adapt to the wrong target resulting in reinforced false positive tracking.A third problem is that the different initial parameters are set based on personal experience only.In the future we plan to employ machine learning techniques.5Integration with C ONDENSATIONIn this section we propose a second implementation of the general system framework.It aims to improve the integration scheme to overcome shortcomings identified in the previous section.In particular integration by means of C ONDENSATION[2]is used allowing to track multiple hypotheses simultaneously.This enables to track multiple subjects as shown in the experiments with the two person sequence.Also multiple hy-potheses tracking is less affected by false positives since no decision is made about the “true”target positions.5.1System DescriptionSensor&Single-cue Observation In order to conform with the general system frame-work(Sect.3),integration with C ONDENSATION replaces multi-cue integration,multi-cue state estimation and feedback of Democratic Integration.Sensor and single-cue observation basically remain the same.Only intensity change and skin color detection are used in the following.Template matching and contrast cue have been removed with-out substitution because they had no major impact in the previous experiments.Motion prediction is no longer maintained as separate visual cue but is now part of the multi-cue integration.As a novelty,probability densities and are approximated by mix-tures of Gaussians in order to cluster the saliency maps.(8)where denotes the number of Gaussians in the mixture.Factor weights Gaus-sian.Clustering is performed by means of expectation maximization(EM),an iterative algorithm adjusting means,variances and weights of the mixture’s Gaussians in order to maximize the log-likelihood of randomly drawn samples ,.(9) In order to minimize,EM requires iteratively applied update rules for,,and .For the special case of a mixture of Gaussians closed forms of these rules exist [1].They can be obtained by maximizing relative to means,standard deviation ,and weight,i.e.by solving the following equations:,robustness of tracking.Democratic Integration,thefirst implementation of the frame-work,shows convergence toward an equilibrium under steady conditions.Distractions of visual cues are compensated by the less affected cues.Democratic Integration how-ever is limited to track a single target even though several might be present.This limi-tation is primarily induced by the self-organization mechanisms which depends on the estimation of a single target position.Another shortcoming of Democratic Integration is false positive tracking:when the system locks on a wrong target it adapts itself to-ward this false positive.Reinforced by its self-adaptation mechanism the system will most often not recover from this failure and continue to track the wrong target.The second implementation of the general system framework is based on C ON-DENSATION which enables simultaneous tracking of multiple hypotheses.This primar-ily tackles the single-target limitation but also the false positive tracking problem of Democratic Integration.Experiments show that this scheme reliably detects and tracks multiple hypotheses even under challenging conditions.Maintaining multiple hypothe-ses over time explicitly avoids locking on a particular target and therefore prevents wrong adaptation caused by false positive tracking.Future work will address localized adaptation of the visual cues as well as of multi-cue integration.Although C ONDENSATION implicitly uses self-organization,superpo-sition of complementary visual cues will be adaptive again in order to increase the system’s robustness.For the same reason adaptivity is introduced for the visual cues again.Furthermore,the system will be enhanced by new complementary cues,taking advantage of the system’s modularity.References[1]Christopher M.Bishop.Neural Networks for Pattern Recognition.Oxford University Press,1999.[2]Andrew Blake and Michael Isard.Active Contours:The Application of Techniques fromGraphics,Vision,Control Theory and Statistics to Visual Tracking of Shapes in Motion.Springer,1998.[3] C.G.Br¨a utigam.A Model-Free Voting Approach to Cue Integration.PhD thesis,Dept.ofNumerical Analysis and Computing Science,KTH(Royal Institute of Technology),August 1998.[4]J.Clark and A.Yuille.Data fusion for sensory information processing.Kluwer AcademicPublishers,Boston,Ma.–USA,1994.[5]J.L.Crowley and F.Berard.Multi-modal tracking of faces for video communications.InIEEE Conference on Computer Vision and Pattern Recognition,1997.[6]Rafael C.Gonzalez and Richard E.Woods.Digital Image Processing.Addison-WesleyPublishing Company,1993.[7]Ulf Grenander,Y.Chow,and Daniel M.Keenan.HANDS:A Pattern Theoretic Study ofBiological Shapes.Springer,1991.[8]M.Isard and A.Blake.Condensation–conditional density propagation for visual tracking.International Journal of Computer Vision,29(1):5–28,1998.[9]M.Isard and A.Blake.Icondensation:Unifying low-level and high-level tracking in astochastic framework.In ECCV’98Fifth European Conference on Computer Vision,Vol-ume I,pages893–908,1998.[10] D.Kragi´c and H.I.Christensen.Integration of visual cues for active tracking of an end-effector.In IROS’99,volume1,pages362–368,October1999.[11] B.Parhami.V oting algorithms.IEEE Transactions on Reliability,43(3):617–629,1994.[12]K.Toyama and G.Hager.Incremental focus of attention for robust vision-based tracking.International Journal of Computer Vision,1999.[13]K.Toyama and G.Hager.Incremental focus of attention for robust visual tracking.In IEEEConference on Computer Vision and Pattern Recognition,1996.[14]J.Triesch,D.H.Ballard,and R.A.Jacobs.Fast temproal dynamics of visual cue integration.Technical report,University of Rochester,Computer Science Department,September2000.[15]Jochen Triesch and Christoph von der Malsburg.Self-organized integration of adaptivevisual cues for face tracking.In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition,2000.。