2004Development of Coded-Aperture Imaging with a Compact Gamma Camera
- 格式:pdf
- 大小:838.95 KB
- 文档页数:5

Fingerprint Verification Competition 2004(FVC2004)(指纹识别大赛2004)数据摘要:The Biometric Systems Lab (University of Bologna), the Pattern Recognition and Image Processing Laboratory (Michigan State University) and the Biometric Test Center (San Jose State University) are pleased to announce:FVC2004: the Third International Fingerprint Verification Competition .Continuous advances in the field of biometric systems and, in particular, in fingerprint-based systems (both in matching techniques and sensing devices) require that the performance evaluation of biometric systems be carried out at regular intervals..The aim of FVC2004 is to track recent advances in fingerprint verification, for both academia and industry, and to benchmark thestate-of-the-art in fingerprint technology.This competition should not be viewed as an 搊fficial?performance certification of biometric systems, since:the databases used in this contest have not been necessarily acquired in a real-world application environment and are not collected according to a formal protocol.only parts of the system software will be evaluated by using images fromsensors not native to each system.Nonetheless, the results of this competition will give a useful overview of the state-of-the-art in this field and will provide guidance to the participants for improving their algorithms.中文关键词:指纹传感器,指纹为基础的生物识别系统,指纹识别,电子指纹采集传感器,国际公开大赛,英文关键词:fingerprint sensing,fingerprint-based biometric systems,fingerprint recognition,electronic fingerprint acquisition sensors,international open competition,数据格式:IMAGE数据用途:fingerprint recognition数据详细介绍:Fingerprint Verification Competition 2004(FVC2004)The Biometric Systems Lab (University of Bologna), the Pattern Recognition and Image Processing Laboratory (Michigan State University) and the Biometric Test Center (San Jose State University) are pleased to announce:FVC2004: the Third International Fingerprint Verification Competition.HighlightsBackgroundThe first and second international competitions on fingerprint verification (FVC2000 and FVC2002) were organized in 2000 and 2002, respectively. These events received great attention both from academic and industrial biometric communities. They established a common benchmark allowingdevelopers to unambiguously compare their algorithms, and provided an overview of the state-of-the-art in fingerprint recognition. FVC2000 and FVC2002 were undoubtedly successful initiatives:The interest shown in FVC2000 and FVC2002 by the biometrics research community has prompted the organizers to schedule a new competition for 2004.AimContinuous advances in the field of biometric systems and, in particular, in fingerprint-based systems (both in matching techniques and sensing devices) require that the performance evaluation of biometric systems be carried out at regular intervals..The aim of FVC2004 is to track recent advances in fingerprint verification, for both academia and industry, and to benchmark the state-of-the-art in fingerprint technology.This competition should not be viewed as an 搊fficial?performance certification of biometric systems, since:the databases used in this contest have not been necessarily acquired in a real-world application environment and are not collected according toa formal protocol.only parts of the system software will be evaluated by using imagesfrom sensors not native to each system.Nonetheless, the results of this competition will give a useful overview of the state-of-the-art in this field and will provide guidance to the participants for improving their algorithms.ParticipantsParticipants can be from academia or industry.Anonymous participation will be accepted: participants will be allowed to decide whether or not to publish their names together with their system's performance. Participants will be confidentially informed about theperformance of their algorithm before they are required to make thisdecision. In case a participant decides to remain anonymous, the label "Anonymous organization" will be used, and the real identity will not be revealed.Organizers of FVC2004 will not participate in the contest.DatabasesFour different databases (DB1, DB2, DB3 and DB4) were collected by using the following sensors/technologies:DB1: optical sensor "V300" by CrossMatchDB2: optical sensor "U.are.U 4000" by Digital PersonaDB3: thermal sweeping sensor "FingerChip FCD4B14CB" by AtmelDB4: synthetic fingerprint generationNOTE: FVC2004 databases are markedly more difficult than FVC2002 and FVC2000 ones, due to the perturbations deliberately introduced (see below). Therefore one should neither compare error rates among different FVC competitions, nor conclude that the state-of-the art in fingerprint matching is not improving.Students (24 years old on the average) enrolled in the Computer Science degree program at the University of Bologna kindly agreed to act as volunteers for providing fingerprints:volunteers were randomly partitioned into three groups of 30 persons;each group was associated to a DB and therefore to a different fingerprint scanner (different subjects in each database, except for a small overlap of five volunteers present in two databases);each volunteer was invited to present him/herself at the collection place in three distinct sessions, with at least two weeks time separating each session;forefinger and middle finger of both the hands (four fingers total) of each volun-teer were acquired by interleaving the acquisition of the differentfingers to maxi-mize differences in finger placement;no efforts were made to control image quality and the sensor platens were not systematically cleaned;at each session, four impressions were acquired of each of the fourfingers of each volunteer;during the first sessions, individuals were asked to put the finger at a slightly different vertical position (in impressions 1 and 2) and to alternate low and high pressure against the sensor surface (impressions 3 and 4);during the second session, individuals were requested to exaggerate skin distortion (impressions 1 and 2) and rotation (3 and 4) of the finger;during the third session, fingers were dried (impressions 1 and 2) and moistened (3 and 4).At the end of the data collection, for each database a total of 120 fingers and 12 impressions per finger (1440 impressions) were gathered. As in previous editions, the size of each database to be used in the test was established as 110 fingers wide (w) and 8 impressions per finger deep (d) (880 fingerprints in all); collecting some additional data gave a margin in case of collection/labeling errors.Fingers from 101 to 110 (set B) have been made available to the participants to allow parameter tuning before the submission of the algorithms; the benchmark is then constituted by fingers numbered from 1 to 100 (set A).The following figure shows a sample image from each database:A minimal training of the volunteers has been performed before the first acquisition session and failure to acquire has been measured during the three sessions, counting the number of attempts required to acquire a valid sample (see following table).数据预览:点此下载完整数据集。


Single disperser design for coded aperture snapshotspectral imagingAshwin Wagadarikar,Renu John,Rebecca Willett,and David Brady* Department of Electrical and Computer Engineering,Duke University,Durham,North Carolina27708,USA*Corresponding author:dbrady@Received10September2007;accepted28November2007;posted13December2007(Doc.ID87303);published8February2008We present a single disperser spectral imager that exploits recent theoretical work in the area ofcompressed sensing to achieve snapshot spectral imaging.An experimental prototype is used to capturethe spatiospectral information of a scene that consists of two balls illuminated by different light sources.An iterative algorithm is used to reconstruct the data cube.The average spectral resolution is3.6nm perspectral channel.The accuracy of the instrument is demonstrated by comparison of the spectra acquiredwith the proposed system with the spectra acquired by a nonimaging reference spectrometer.©2008Optical Society of AmericaOCIS codes:300.6190,110.0110,120.6200.1.IntroductionSpectral imaging is a technique that generates a spa-tial map of spectral variation,making it a useful tool in many applications including environmental re-mote sensing[1],military target discrimination[2], astrophysics[3],and biomedical optics[4].When im-aging a scene,a spectral imager produces a two-dimensional spatial array of vectors that represents the spectrum at each pixel location.The resulting three-dimensional data set that contains two spatial dimensions and one spectral dimension is known as a data cube.Many different techniques for spectral imaging have been developed over the years.Whiskbroom[5], pushbroom[6],and tunablefilter[7]imagers are all conceptually simple spectral imager designs.These instruments capture a one-or two-dimensional sub-set of a data cube and thus require temporal scanning of the remaining dimension(s)to obtain a complete data cube.Furthermore,they have poor light collec-tion efficiency for incoherent sources,resulting in a poor signal-to-noise ratio(SNR).The light collection problem is addressed by multi-plex spectral imager designs based on Fourier and Hadamard transforms.Scanning Michelson Fourier transform spectral imagers[8]use a scanning interferometer,thus requiring significant mechanical stability[9].Multiplex pushbroom designs with Had-amard encoding use expensive spatial light modula-tors[10].Although they increase the light throughput, these designs still use some form of scanning,making it difficult to use them for spectral imaging of nonstatic scenes.Tomographic approaches have also produced major advances.Mooney et al.[11]developed a direct-view design that maximizes the light-gathering efficiency by not requiring any spatialfilter,such as a slit.With this design,the source is viewed through a rotating dispersive element.Measurements are taken at dif-ferent rotation angles.These measurements are pro-jective measurements through the data cube that can be tomographically reconstructed.Although the light-gathering efficiency of such an instrument is high,the geometry of the system limits the range of angles over which projections are made.As a result of the Fourier slice theorem,this results in an un-sampled region in Fourier space,a problem known as the missing cone problem because the unsampled re-gion is a conical volume in the Fourier domain rep-resentation of the data cube[13].The computed tomography imaging spectrometer(CTIS)[13]sys-tem is a static,snapshot instrument that captures multiple projections of the data cube at once.These capabilities make the CTIS ideal for spectral imaging0003-6935/08/1000B44-8$15.00/0©2008Optical Society of AmericaB44APPLIED OPTICS͞Vol.47,No.10͞1April2008of transient scenes.However,the instrument re-quires a large focal plane area and also suffers from the missing cone problem[14].An important characteristic shared by all the de-signs described above is that the total number of measurements they generate is greater than or equal to the total number of elements in the reconstructed data cube.In contrast,our group has introduced the idea of compressive spectral imaging,an approach to spectral imaging that intentionally generates fewer measurements than elements in the reconstructed data cube[12].Compressed sensing solves the under-determined data cube estimation problem by relying on a crucial property of natural scenes,namely,that they tend to be sparse on some multiscale basis.To achieve compressive spectral imaging,our group has developed a new class of imagers dubbed the coded aperture snapshot spectral imager(CASSI).The CASSI utilizes a coded aperture and one or more dispersive elements to modulate the opticalfield from a scene.A detector captures a two-dimensional,mul-tiplexed projection of the three-dimensional data cube representing the scene.The nature of the mul-tiplexing performed depends on the relative position of the coded aperture and the dispersive element(s) within the instruments.We recently reported on a dual disperser(DD) CASSI design[15],which consists of two sequentially dispersive arms arranged in opposition so that the dispersion in the second arm cancels the dispersion introduced by thefirst arm.A coded aperture is placed between the two arms.Recovery of the data cube from the detector measurement is performed by use of an expectation-maximization method designed for hyperspectral images.Such a design applies spa-tially varying,spectralfilter functions with narrow features.Through thesefilters,the detector mea-sures a projective measurement of the data cube in the spectral domain.In essence,the DD CASSI sac-rifices spatial information to gain spectral informa-tion about the data cube.Spectral information from each spatial location in the scene is multiplexed over a localized region of the detector.A useful property of the design is that the measurement resembles the scene,making it easy to focus the camera on objects in the scene.This also makes it possible to perform local block processing of the detector data to generate smaller data cubes of subsets of the entire scene. We report a new compressive CASSI instrument dubbed the single disperser(SD)CASSI.Like the DD CASSI,the SD CASSI does not directly measure each voxel in the desired three-dimensional data cube.It collects a small number(relative to the size of the data cube)of coded measurements and a sparse re-construction method is used to estimate the data cube from the noisy projections.The instrument disperses spectral information from each spatial location in the scene over a large area across the detector.Thus, spatial and spectral information from the scene is multiplexed on the detector,implying that the null space of the sensing operation of the SD CASSI dif-fers from that of the DD CASSI.Also,a raw measure-ment of a scene on the detector rarely reveals the spatial structure of the scene and makes block pro-cessing more challenging.Since the DD CASSI multiplexes only spectral in-formation in the data cube,it cannot reconstruct the spectrum of a point source object.On the other hand, the SD CASSI can reconstruct the spectrum of a point source,provided that the source spatially maps to an open element on the coded input aperture.This im-plies that,for reconstructions that demand high spa-tial resolution with less stringent demands on spectral resolution,the DD CASSI instrument should be the compressive spectral imager of choice.On the other hand,when spectral resolution is more critical than spatial resolution in the data cube,the SD CASSI instrument should be chosen.The SD CASSI has the additional benefit of requiring fewer optical elements,making optical alignment much easier. The SD CASSI also removes the CTIS constraints of measuring multiple projections of the data cube and using a large focal plane array.Essentially,just one spectrally dispersed projection of the data cube that is spatially modulated by the aperture code over all wavelengths is sufficient to reconstruct the entire spectral data cube.In Section2we detail our system model that math-ematically describes the sensing operation imple-mented by the SD CASSI.In Section3we describe the reconstruction technique used to generate a three-dimensional data cube from an underdeter-mined set of measurements collected by the detector of a SD CASSI.In Section4we describe the details of an experimental SD CASSI prototype constructed to experimentally verify the snapshot,compressive im-aging concept.Finally,in Section5we present the experimental results demonstrating the reconstruc-tion of a data cube of a scene.2.System ModelA schematic of the compressive,snapshot SD CASSI is shown in Fig.1.A standard imaging lens is used to form an image of a remote scene in the plane of the coded aperture.The coded aperture modulates the spatial information over all wavelengths in the spec-tral cube with the coded pattern.Imaging thecube Fig.1.Schematic of a SD CASSI.The imaging optics image thescene onto the coded aperture.The relay optics relay the image from the plane of the coded aperture to the detector through thedispersive element.1April2008͞Vol.47,No.10͞APPLIED OPTICS B45from this plane through the dispersive element re-sults in multiple images of the code-modulated scene at wavelength-dependent locations in the plane of the detector array.The spatial intensity pattern in this plane contains a coded mixture of spatial and spectral information about the scene.We note that this design essentially extends the architecture of our computa-tional static multimodal,multiplex spectrometers [10]to computational spectral imaging,with the ad-dition of an imaging lens placed in front of the input aperture code.Below we mathematically model the SD CASSI sensing process.The model assists us in developing the system operator matrix for the reconstruction algorithm.The model does not account for optical distortions introduced by the optical elements in the instrument such as blurring and smile distortion [16].However,it does help us to understand the basic operations implemented by the optical elements. The spectral density that enters the instrument and is relayed to the plane of the coded aperture can be represented as f0͑x,y;͒.If we represent the trans-mission function printed on the coded aperture as T͑x,y͒,the spectral density just after the coded ap-erture isf1͑x,y;͒ϭf0͑x,y;͒T͑x,y͒.(1)After propagation through the coded aperture,the relay optics and the dispersive element,the spectral density at the detector plane isf2͑x,y;͒ϭ͵͵␦͑xЈϪ͓xϩ␣͑Ϫc͔͒͒␦͑yЈϪy͒ϫf1͑xЈ,yЈ;͒dxЈdyЈϭ͵͵␦͑xЈϪ͓xϩ␣͑Ϫc͔͒͒␦͑yЈϪy͒ϫf0͑xЈ,yЈ;͒T͑xЈ,yЈ͒dxЈdyЈϭf0͑xϩ␣͑Ϫc͒,y;͒T͑xϩ␣͑Ϫc͒,y͒,(2)where the Dirac delta functions describe propagation through unity magnification imaging optics and a dispersive element with linear dispersion␣and cen-ter wavelengthc.The detector array is insensitive to wavelength and measures the intensity of incident light rather than the spectral density.Thus,the con-tinuous image on the detector array can be repre-sented asg͑x,y͒ϭ͵f0͑xϩ␣͑Ϫc͒,y;͒T͑xϩ␣͑Ϫc͒,y͒d.(3)This image is a sum over the wavelength dimension of a mask-modulated and later sheared data cube. Note that this is in contrast with the spatially regis-tered image formed on a DD CASSI detector as a result of summing over the wavelength dimension of a data cube that isfirst sheared,mask modulated, andfinally unsheared.Since the detector array is spatially pixelated with pixel size⌬,g͑x,y͒is sampled across both dimensions of the detector.In the presence of noise w,the mea-surements at position͑n,m͒on the detector can be represented asg nmϭ͵͵g͑x,y͒rectͩx⌬Ϫm,y⌬Ϫnͪdxdyϩw nm ϭ͵͵͵f0͑xϩ␣͑Ϫc͒,y;͒T͑xϩ␣͑Ϫc͒,y͒ϫrectͩx⌬Ϫm,y⌬Ϫnͪdxdydϩw nm.(4)Reconstruction of data cubes from the physical sys-tem benefits if the coded aperture feature size is an integer multiple q of the size of detector pixels⌬.This avoids the need for subpixel positioning accuracy of the coded aperture.The aperture pattern T͑x,y͒can be represented as a spatial array of square pinholes, with each pinhole having a side length of q⌬and t nЈ,mЈrepresenting an open or closed pinhole at position ͑nЈ,mЈ͒in the pinhole array:T͑x,y͒ϭ͚mЈ,nЈt nЈmЈrectͩxϪmЈ,yϪnЈͪ.(5)With this representation for the aperture pattern,the detector measurements as represented in Eq.(4)be-comeg nmϭ͚mЈ,nЈt nЈmЈ͵͵͵rectͩxϩ␣͑Ϫc͒ϪmЈ,yϪnЈͪϫrectͩx⌬Ϫm,y⌬Ϫnͪϫf0͑xϩ␣͑Ϫc͒,y;͒dxdydϩw nm.(6)Denoting the source spectral density f0͑x,y;͒in dis-crete form as f ijk and the aperture code pattern T͑x,y͒as t ij,the detector measurements in matrix form can be written asg nmϭ͚kf͑mϩk͒nk t͑mϩk͒nϩw nmϭ͑Hf͒nmϩw nm,(7)where H is a linear operator that represents the sys-tem forward model.3.Data Cube Reconstruction MethodThe SD CASSI measures a two-dimensional,spa-tiospectral multiplexed projection of the three-B46APPLIED OPTICS͞Vol.47,No.10͞1April2008dimensional data cube representing the scene.Reconstructing a data cube from this compressedmeasurement relies on the assumption that thesources in the scene have piecewise smooth spatialstructure,making the data cube highly compress-ible in the wavelet basis.Here we describe the re-construction method used to estimate the data cubefrom the detector measurements.The data cube canbe represented asfϭW,(8) whereis a vector composed of the two-dimensionalwavelet transform coefficients for each spectral bandconcatenated to form one vector,and W denotes theinverse two-dimensional wavelet transform appliedto each spectral band to form data cube f.The SDCASSI detector measurement can be represented asg nmϭ͑HW͒nmϩw nm,(9) where H is a representation of the system forwardmodel described in Section2and w nm is noise.If data cube f consists of͕pϫp͖spatial channelswith q spectral channels,it can be represented as acube of size͕pϫpϫq͖.The corresponding detectormeasurements g can be represented as a matrix ofsize͕pϫ͑pϩqϪ1͖͒.The number of columns in thismatrix reflects the fact that the detector measure-ment is a sum of coded images of the scene at eachspectral channel,with each spectral image displacedby a column of pixels from the adjacent image.If werepresent f and g as column vectors,the linear oper-ator matrix H can be represented as a matrix of size ͕͓p͑pϩqϪ1͔͒ϫ͑p2q͖͒.The vector of wavelet coef-ficients of data cubeis of size͕͓p2q͑3log2͑p͒ϩ1͔͒ϫ1͖.The size of this vector reflects the fact that the wavelet decomposition of the data cube is performedas a two-dimensional undecimated transform on eachof the q spectral channels.The undecimated trans-form is used to ensure that the resulting method istranslation invariant.An estimate fˆfor the data cube can be found bysolving the problemfˆϭW͓argminЈ͕gϪHWЈ22ϩЈ1͖͔.(10)The solution of this nonlinear optimization problem has received significant attention recently[17–19]. We use the gradient projection for sparse reconstruc-tion(GPSR)method developed by Figueiredo et al.[20].This approach is based on a variant of the Barzilai–Borwein gradient projection method[21] and has code available online[22].The reconstruc-tion method searches for a data cube estimate with a sparse representation in the wavelet basis;i.e.,athat contains mostly zeros and a relatively small number of large coefficients.Thefirst term in this optimization equation minimizes theᐉ2error be-tween the measurements modeled from the estimate and the true measurement.The second term is a penalty term that encourages sparsity of the recon-struction in the wavelet domain and controls the ex-tent to which piecewise smooth estimates are favored.In this formulation,is a tuning parameter for the penalty term and higher values ofyield sparser estimates of.4.Experimental SetupTo verify the SD CASSI spectral imaging concept experimentally,we constructed a proof-of-concept prototype as shown in Fig.2.The prototype consisted of(i)a coded aperture,lithographically patterned on a chrome-on-quartz mask,(ii)three lenses from Schneider Optics(Hauppauge,New York)with an f͞# of1.4and a focal length of22.5mm,(iii)an equilat-eral prism from Edmund Optics(Barrington,New Jersey)as a dispersive element,(iv)a monochrome charge-coupled device(CCD)detector from Photo-metrics(Tucson,Arizona)with1040ϫ1392pixels that are each4.65m square,and(v)a500–620nm bandpassfilter that was placed in front of the imag-ing lens to remove the impact of stray light on the experimental measurements.MATLAB routines were written to control and capture data on the CCD. The aperture code used in all the experiments was based on an order192S-matrix code[23],with fea-tures that were four CCD pixels wide and four CCD pixels tall,and two completely closed rows of CCD pixels added between the code rows.The columns of the original S-matrix code were shuffled in a random but repeatable way.The code was originally designed for a coded-aperture spectrometer and was not opti-mized for the spectral imaging application demon-strated in this paper.Although we have developed the theory for and conducted experimental studies of optimal aperture codes for coded aperture spectros-copy[9,24],it is not applicable to the spectral imaging application demonstrated here.Work on optimal ap-erture code(s)for the CASSI instruments will be re-ported in a futuremanuscript.Fig.2.(Color online)Experimental prototype of the SD CASSI.1April2008͞Vol.47,No.10͞APPLIED OPTICS B47An equilateral prism was used instead of a grating because the grating produces overlapping diffractive orders whereas the prism only refracts the wave-lengths into one order.Prisms also have large trans-mission efficiencies[25].Given the system geometry and the low dispersion of the equilateral prism,the number of CCD columns illuminated when white light was allowed to pass through the system was less than half of the width of the CCD array.Thus,the spectral range of the instrument was essentially lim-ited by the quantum efficiency of the CCD image sensor.5.Experimental Results and DiscussionWe note from the outset that given the proof-of-concept nature of the prototype system,it was simply put together with off-the-shelf parts and not opti-mized in optical ray tracing software.Consequently,the results presented in this section are limited to a display of the ability of the SD CASSI to reconstruct relatively simple spatiospectral scenes.We are in the process of constructing a second generation instru-ment that is sturdier and has much higher measure-ment quality.To generate an estimate of the data cube represent-ing the scene,the reconstruction algorithm requires two inputs:the aperture code used by the instrument to encode the data cube and the detector measure-ment of the data cube.Instead of using the code pat-tern printed on the aperture mask as the code pattern used for the reconstruction,the instrument was uni-formly illuminated with a single wavelength source in the form of a543nm laser.Figure3shows the detector measurement of the aperture code pattern after propagation through the optics.This is a more accurate representation of the spatial coding scheme applied to the data cube than the code printed on the aperture mask and thus produces a more accu-rate reconstruction of the data cube.We constructed a scene consisting of two Ping-Pong balls as shown in Fig.4.One Ping-Pong ball was illuminated by a543nm laser and a white light sourcefiltered by a green560nm narrowbandfilter. The other was a red Ping-Pong ball illuminated by a white light source.Figure5shows a CCD measure-ment of the scene obtained with the SD CASSI.Given the low linear dispersion of the prism,there is spa-tiospectral overlap of the aperture code-modulated images of each ball.The500–620nm bandpassfilter placed in front of the imaging lens ensures that only the subset of the data cube that corresponds to this band of wavelengths is measured by the instrument. Detector measurements of both the code pattern and the scene were digitally downsampled by a factor of2in the row and column dimensions prior to per-forming a reconstruction of the data cube.This down-sampling helped reduce the time needed by the reconstruction algorithm to generate an estimate of the data cube.The resulting͕128ϫ128ϫ28͖data cube spanned a spectral range from540to640nm. One hundred iterations of the reconstruction algo-rithm required approximately14min of run time on a desktop machine.The GPSR method was run with ϭ0.05.This value was determined by trial and error.Future work is needed to study how to choose the optimal value of.Figure6shows the spatial content of each of28 wavelength channels between540and640nm.Note Fig.3.(Color online)Aperture code pattern used by the recon-struction algorithm to generate an estimate of the datacube.Fig.4.(Color online)Scene consisting of a Ping-Pong ball illumi-nated by a543nm green laser and a white light sourcefiltered bya560nm narrowbandfilter(left),and a red Ping-Pong ball illu-minated by a white light source(right).Fig.5.(Color online)Detector measurement of the scene consist-ing of the two Ping-Pong balls.Given the low linear dispersion ofthe prism,there is spatiospectral overlap of the aperture code-modulated images of each ball.B48APPLIED OPTICS͞Vol.47,No.10͞1April2008that the mask modulation on the spatial structure visible in Fig.5has been removed in all the wave-length channels and that the two balls are spatially separated.To validate the ability of the SD CASSI to reconstruct the spectral signature of objects in the scene,we measured the spectral signatures of each Ping-Pong ball using an Ocean Optics (Dun-edin,Florida)spectrometer.Figure 7(a)shows the SD CASSI spectrum at a point on the green Ping-Pong ball,and Fig.7(b)shows the SD CASSI spec-trum at a point on the red Ping-Pong ball.The wavelength axis in the plots had to be calibrated because of the nonlinear dispersion of the prism across the detector.This calibration was performed by tracking the position of a point source while varying its wavelength.Figures 7(a)and 7(b)also show the Ocean Optics spectrum from each ball for comparison.The two reconstructed SD CASSI spec-tra closely match those generated by the Ocean Optics spectrometer.We note that the reconstruction algorithm used to generate the data cube assumed that the system re-sponse when the aperture code was fully illuminated with any wavelength was identical to the system re-sponse at 543nm.Thus,it did not account for an anamorphic horizontal stretch of the image that is wavelength dependent.The quality of the recon-structed data cube could be improved if the recon-struction algorithm were to utilize a system response that captures a fully illuminated aperture code pat-tern at all the wavelengths in the spectral range of the instrument.An important characteristic of any spectrometer or spectral imager is its spectral resolution.If we ignore the optical distortions such as the blurring and the smile distortion,the spectral resolution of the SD CASSI would then be determined by the width of the smallest code feature.Consider the case in which the smallest code feature maps to two detector pixels.Then imaging two adjacent,monochromaticpointFig.6.(Color online)Spatial content of the scene in each of 28spectral channels between 540and 640nm.The green ball can be seen in channels 3,4,5,6,7,and 8;the red ball can be seen in channels 23,24,and25.Fig.7.(Color online)(a)Spectral intensity through a point on the Ping-Pong ball illuminated by a 543nm green laser and a white light source filtered by a 560nm narrowband filter.(b)Spectral intensity through a point on the red Ping-Pong ball illuminated by a white light source.Spectra from an Ocean Optics nonimaging reference spectrometer are shown for comparison.1April 2008͞Vol.47,No.10͞APPLIED OPTICSB49sources of close but distinct wavelengths to the small-est code feature can potentially result in spatiospec-tral mapping of both point sources to the same pixel on the detector.Thus,the spectral resolution for the SD CASSI,i.e.,the separation between the spectral channels,is determined by the amount of dispersion (in nanometers)across two detector pixels.Since the dispersion of a prism is nonlinear,the spectral reso-lution of this instrument varies with wavelength.Accordingly,an average spectral resolution can be computed for the SD CASSI experimental prototype.This was determined by removing the bandpass filter in front of the imaging lens and illuminating the instrument with a 543and 632nm laser.The sepa-ration between the aperture images resulting from these wavelengths was approximately 100pixels,cor-responding to an average dispersion of 0.9nm ͞pixel.Since the width of the smallest code feature was four detector pixels,the average spectral resolution of the instrument was 3.6nm ͞spectral channel.6.SummaryWe have developed a new class of spectral imagers known as the coded aperture snapshot spectral im-ager (CASSI).The dual disperser CASSI measures a two-dimensional coded spectral projection of the three-dimensional data cube.We have reported on the single disperser CASSI,which measures a two-dimensional coded spatiospectral projection of the three-dimensional data cube that represents the scene.The differences between these instruments are listed in table format in Fig.8.The GPSR method was used to estimate the data cube from the SD CASSI measurements by assuming spatial sparsity of the scene in the wavelet basis.A first generation prototype was used to provide exper-imental verification of the compressive spectral im-aging concept.The spatial resolution was enough to allow the identification of two distinct objects in the constructed scene.The spectral signatures of the scene as measured by the experimental prototype compared well with a reference nonimaging spec-trometer and the average spectral resolution was 3.6nm ͞spectral channel.Future work will focus on the development of a second generation SD CASSI with better image quality,improving the quality of reconstructed data cubes by utilizing the complete wavelength-dependent system response in the recon-struction process,and determining the optimal aper-ture code for the SD CASSI instrument.Finally,wenote that the DD CASSI and SD CASSI represent two extreme forms of compressive spectral imagers.Mod-ifying the second dispersive arm of the DD CASSI so that its dispersion does not completely cancel the dispersion caused by the first arm will result in a new CASSI instrument that will measure something be-tween a spatially well registered image and a spatio-spectral projection of the data cube.This research was supported by the Defense Ad-vanced Research Projects Agency’s Microsystems Technology Office through a collaborative project with Rice University (ONR grant N 00014-06-1-0610).References1.W.L.Smith,D.K.Zhou,F.W.Harrison,H.E.Revercomb,rar,H.L.Huang,and B.Huang,“Hyperspectral re-mote sensing of atmospheric profiles from satellites and air-craft,”Proc.SPIE 4151,94–102(2001).2.C.M.Stellman,F.M.Olchowski,and J.V.Michalowicz,“WAR HORSE (wide-area reconnaissance:hyperspectral overhead real-time surveillance experiment),”Proc.SPIE 4379,339–346(2001).3.R.P.Lin,B.R.Dennis,and A.O.Benz,eds.,The Reuven Ramaty High-Energy Solar Spectroscopic Imager (RHESSI)—Mission Description and Early Results (Kluwer Academic,2003).4.T.H.Pham,F.Bevilacqua,T.Spott,J.S.Dam,B.J.Tromberg,and S.Andersson-Engels,“Quantifying the absorption and re-duced scattering coefficients of tissuelike turbid media over a broad spectral range with noncontact Fourier-transform hy-perspectral imaging,”Appl.Opt.39,6487–6497(2000).5.R.O.Green,M.L.Eastwood,C.M.Sarture,T.G.Chrien,M.Aronsson,B.J.Chippendale,J.A.Faust,B.E.Pavri,C.J.Chovit,M.Solis,M.R.Olah,and O.Williams,“Imaging spec-troscopy and the Airborne Visible ͞Infrared Imaging Spectrom-eter (AVIRIS),”Remote Sens.Environ.65,227–248(1998).6.E.Herrala,J.T.Okkonen,T.S.Hyvarinen,M.Aikio,and mmasniemi,“Imaging spectrometer for process industry applications,”Proc.SPIE 2248,33–40(1994).7.H.Morris,C.Hoyt,and P.Treado,“Imaging spectrometers for fluorescence and Raman microscopy:acousto-optic and liquid crystal tunable filters,”Appl.Spectrosc.48,857–866(1994).8.C.L.Bennett,M.R.Carter,D.J.Fields,and J.A.M.Hernan-dez,“Imaging Fourier transform spectrometer,”Proc.SPIE 1937,191–200(1993).9.M.E.Gehm,S.T.McCain,N.P.Pitsianis,D.J.Brady,P.Potuluri,and M.E.Sullivan,“Static two-dimensional aperture coding for multimodal multiplex spectroscopy,”Appl.Opt.45,2965–2974(2006).10.Q.Hanley,P.Verveer,D.Arndt-Jovin,and T.Jovin,“Threedimensional spectral imaging by Hadamard transform spec-troscopy in a programmable array microscope,”J.Microsc.197,5–14(2000).11.J.M.Mooney,V.E.Vickers,M.An,and A.K.Brodzik,“High-throughput hyperspectral infrared camera,”J.Opt.Soc.Am.A 14,2951–2961(1997).12.D.J.Brady and M.E.Gehm,“Compressive imaging spectrom-eters using coded apertures,”Proc.SPIE 6246,62460A (2006).13.M.R.Descour,C.E.Volin,E.L.Dereniak,K.J.Thorne,A.B.Schumacher,D.W.Wilson,and P.D.Maker,“Demonstration of a high-speed nonscanning imaging spectrometer,”Opt.Lett.22,1271–1273(1997).14.W.R.Johnson, D.W.Wilson,and G.Bearman,“Spatial-spectral modulating snapshot hyperspectral imager,”Appl.Opt.45,1898–1908(2006).Fig.8.Description of the major differences between the DD CASSI and the SD CASSI instruments.B50APPLIED OPTICS ͞Vol.47,No.10͞1April 2008。

·专家论坛·高清数码相机联合HeadScan V04标化人体图像系统用于化妆品祛斑美白功效评价江文才 徐雅菲 杨静文 王建玟 谈益妹(上海市皮肤病医院皮肤与化妆品研究室上海 200443)摘要目的:利用高清数码相机联合HeadScan V04标化人体图像系统提取皮肤颜色,评估该系统在祛斑美白产品功效性评价应用中的可行性。
方法:本研究招募22例受试者,分别于祛斑美白化妆品使用前、使用后4周、8周应用Chromameter CR400和高清数码相机联合HeadScan V04标化人体图像系统测量试验区和对照区的皮肤颜色参数。
结果:高清数码相机联合HeadScan V04标化人体图像系统测量的皮肤颜色值与Chromameter CR400测量结果一致;两种方法测量的L*值、b*值和ITA°值具有较高的相关性。
结论:高清数码相机联合HeadScan V04标化人体图像系统非接触式皮肤颜色检测方法在身体用祛斑美白产品拍摄定位和功效评价中具有重要的价值和意义。
关键词 HeadScan标化人体图像系统L*a*b*色度系统祛斑美白功效评价中图分类号:TQ658.59 文献标志码:B 文章编号:1006-1533(2023)11-0021-04引用本文江文才, 徐雅菲, 杨静文, 等. 高清数码相机联合HeadScan V04标化人体图像系统用于化妆品祛斑美白功效评价[J]. 上海医药, 2023, 44(11): 21-24; 47.High-definition digital camera combined with HeadScan V04 standard photography platform for evaluating the efficacy of the whitening cosmeticsJIANG Wencai, XU Yafei, YANG Jingwen, WANG Jianmin, TAN Yimei(Department of Skin and Cosmetic Research, Shanghai Skin Disease Hospital, Shanghai 200443, China) ABSTRACT Objective: To extract skin color using high-definition digital camera combined with HeadScan V04 standard photography platform and study their feasibility in the evaluation of the effect of whitening cosmetics. Methods: Twenty-two volunteers were recruited in the study and the skin color parameters on the test and control area were measured by Chromameter CR400 and high-definition digital camera combined with HeadScan V04 standard photography platform before the application of whitening cosmetics and 4, 8 weeks after. Results: The measurement results by high-definition digital camera combined with HeadScan V04 standard photography platform were nearly consistent with those by the Chromameter CR400, and there isa strong correlation in L*, b* and ITA° between two methods. Conclusion: The high-definition digital camera combined withHeadScan V04 standard photography platform has good prospects in the efficacy evaluation of whitening cosmetics.KEY WORDS HeadScan standard photography platform; L*a*b* color system; whitening cosmetics; efficacy evaluation近年来随着经济的快速发展和人们对健康美丽要求的不断提升,特别是东方女性历来崇尚“肤如雪,凝如脂”之美,使得祛斑美白化妆品的销售与日俱增,并已成为主要的护肤产品之一。

3D FACE RECOGNITION FOR BIOMETRIC APPLICATIONSL.Akarun,B.G¨o kberk,A.A.SalahDepartment of Computer EngineeringBo˘g azic¸i University,Bebek,˙Istanbul,Turkeyphone:+(90)2123597183,fax:+(90)2122872461e-mail:{akarun,gokberk,salah}@.trABSTRACTFace recognition(FR)is the preferred mode of identity recognition by humans:It is natural,robust and unintrusive.However,auto-matic FR techniques have failed to match up to expectations:Vari-ations in pose,illumination and expression limit the performance of2D FR techniques.In recent years,3D FR has shown promise to overcome these challanges.With the availability of cheaper ac-quisition methods,3D face recognition can be a way out of these problems,both as a stand-alone method,or as a supplement to2D face recognition.We review the relevant work on3D face recogni-tion here,and discuss merits of different representations and recog-nition algorithms.1.INTRODUCTIONRecent developments in computer technology and the call for better security applications have brought biometrics into focus.A bio-metric is a physical property;it cannot be forgotten or mislaid like a password,and it has the potential to identify a person in very different settings:a criminal entering an airport,an unconscious patient without documents for identification,an authorized person accessing a highly-secured system.Be it for purposes of security or human–computer interaction,there is wide application to robust biometrics.Two different scenarios are of primary importance.In the veri-fication(authentication)scenario,the person claims to be someone, and this claim is verified by ensuring the provided biometric is suf-ficiently close to the data stored for that person.In the more diffi-cult recognition scenario,the person is searched in a database.The database can be small(e.g.criminals on the wanted list)or large (e.g.photos on registered ID cards).The unobtrusive search for a number of people is called screening.The signature and handwriting have been the oldest biometrics, used in the verification of authentication of documents.Face image and thefingerprint also have a long history,and are still kept by police departments all over the world.More recently,voice,gait, retina and iris scans,hand print,and3D face information are con-sidered for biometrics.Each of these have different merits,and applicability.When deploying a biometrics based system,we con-sider its accuracy,cost,ease of use,ease of development,whether it allows integration with other systems,and the ethical consequences of its use.Two other criteria are susceptibility to spoofing(faking an identity)in a verification setting,and susceptibility to evasion (hiding an identity)in a recognition setting.The purpose of the present study is to discuss the merits and drawbacks of3D face information as a biometric,and review the state of the art in3D face recognition.Two things make face recog-nition especially attractive for our consideration.The acquisition of the face information is easy and non-intrusive,as opposed to iris and retina scans.This is important if the system is going to be used frequently,and by a large number of users.The second point is the relatively low privacy of the information;we expose our faces constantly,and if the stored information is compromised,it does not lend itself to improper use like signatures andfingerprints would.The drawbacks of3D face recognition include high cost and decreased ease-of-use for laser sensors,low accuracy for other acquisiton types,and the lack of sufficiently powerful algorithms. Figure.1presents a summary of different biometrics and their rela-tivestrengths.Figure1:Biometrics and their relative strengths.Although2D and 3D face recognition are not as accurate as iris scans,their ease of use and lower cost makes them a preferable choice for some scenarios.3D face recognition represents an improvement over2D face recognition in some respects.Recognition of faces from still im-ages is a difficult problem,because the illumination,pose and ex-pression changes in the images create great statistical differences and the identity of the face itself becomes shadowed by these fac-tors.Humans are very capable in this modality,precisely because they learn to deal with these variations.3D face recognition has the potential to overcome feature localization,pose and illumination problems,and it can be used in conjunction with2D systems.In the next section we review the current research on3D face recognition.We focus on different representations of3D informa-tion,and the fusion of different sources of information.We con-clude by a discussion of the future of3D face recognition.2.STATE OF THE ART IN3D FACE RECOGNITION 2.13D Acquisition and PreprocessingWe distinguish between a number of range data acquisition tech-niques.In the stereo acquisition technique,two or more cameras that are positioned and calibrated are employed to acquire simul-taneous snapshots of the subject.The depth information for each point can be computed from geometrical models and by solving a correspondence problem.This method has the lowest cost and high-est ease of use.The structural light technique involves a light pat-tern projected on the face,where the distortion of the pattern reveals depth information.This setup is relatively fast,cheap,and allows a single standard camera to produce3D and texture information.The last technique employs a laser sensor,which is typically more accu-rate,but also more expensive and slower to use.The acquisition of a single3D head scan can take more than30seconds,a restricting factor for the deployment of laser-based systems.3D information needs to be preprocessed after acquisition.De-pending on the type of sensor,there might be holes and spikes(ar-tifacts)in the range data.Eyes and hair will not reflect the light appropriately,and the structured light approaches will have trouble correctly registering those portions.Illumination still effects the3D acquisition,unless accurate laser scanners are employed[7].For patching the holes,missing points can befilled by inter-polation or by looking at the other side of the face[22,33].Gaus-sian smoothing and linear interpolation are used for both texture and range information[1,8,10,13,15,22,24,30].Clutter is usually re-moved manually[6,8,15,24,18,21,29,30]and sometimes parts of the data are completely omitted where the acquisition leads to noise levels that cannot be coped with algorithmically[10,21,35]. To help distance calculation,the mesh representations can be regu-larized[16,36],or a voxel discretization can be used[2].Most of the algorithms start by aligning the faces,either by their centres of mass[8,29],nose tip[15,18,19,22,26,30],the eyes[13,17],or byfitting a plane to the face and aligning it with that of the camera[2].Registration of the images is important for all local similarity metrics.The key idea in registration is to define the similarity metric and the set of possible transformations.The sim-ilarity is measured by point-to-point or point-to-surface distances, or cross correlation between more complex features.The rigid transformation of a3D object involves a3D rotation and translation,but the nonlinearity of the problem calls for iterative methods[11].The most frequently used([16,19,21,22,27,29]) registration technique is the Iterative Closest Point(ICP)algo-rithm[3].Warping and deforming the models(non–rigid regis-tration)for better alignment helps co-locating the landmarks.An important method is the Thin Plate Spline(TPS)algorithm,which establishes perfect correspondence[16,20].One should however keep in mind that the deformation may be detrimental to the recog-nition performance,as discriminatory information is lost propor-tional to the number of anchor points.Lu and Jain also distin-guish between inter-subject and intra-subject deformations,which is found useful for classification[20].Landmark locations used in registration are either found man-ually[6,10,17,19,21,25,33]or automatically[12,16,37].The correct localization of the landmarks is crucial to many algorithms, and it is usually not possible to judge the sensitivity of an algorithm to localization errors from its description.Nevertheless,the auto-matic landmark localization remains an unsolved problem.2.23D Recognition AlgorithmsWe summarize relevant work in3D face recognition.We have clas-sified each work according to the primary representation used in the recognition algorithm,much in the spirit of[7].Table3summarizes the recent work on3D and2D+3D face recognition.2.2.1Curvatures and Surface FeaturesIn one of the early3D face papers,Gordon proposed a curvature-based method for face recognition from3D data,kept in a cylin-drical coordinate system[13].Since the curvatures involve second derivatives,they are very sensitive to noise.An adaptive Gaussian smoothing is applied so as not to destroy curvature information. In[31]principal directions of curvatures are used.The advantage of these over surface normals is that they are applicable to free-form surfaces.Moreno et al.extracted a number of features from 3D data,and found that curvature and line features perform better than area features[24].In[14],the authors have compared differ-ent representations on the3D RMA dataset:point clouds,surface normals,shape-index values,depth images,and facial profile sets. Surface normals are reported to be more discriminative than others, and LDA is found very useful in extracting discriminative features.2.2.2Point Clouds and MeshesPoint cloud is the most primitive3D representation for faces,and it is difficult to work with.Achermann and Bunke employ Haus-dorff distance for matching the point clouds[2].They use a voxel discretization to speed up matching,but it causes some informa-tion o et al.discard matched points with large distances as noise[17].When the data are in point cloud representation,ICP is the most widely used registration technique.The similarity of two point sets that is calculated at each iteration of the ICP algorithm is fre-quently used in point cloud-based face recognizers.Medioni and Waupotitsch present an authentication system that acquires the3D image of the subject with two calibrated cameras[23]and ICP al-gorithm is used to define similarity between two face meshes.Lu et e a hybrid-ICP based registration using Besl’s method and Chen’s method successively[19].The base mesh is also used for alignment in[36],where features are extracted from around land-mark points,and nearest neighbour after PCA is used for recogni-tion.Lu and Jain also use ICP for rigid deformations,but they also propose to use TPS for intra-subject and inter-subject nonrigid de-formations,with the purpose of handling expression variations[20]. Deformation analysis and combination with appearance based clas-sifiers both increase the recognition accuracy.In a similar study,˙Irfano˘g lu et al.have used ICP to automat-ically locate facial landmarks in a coarse alignment step,and then warp faces using TPS algorithm to establish dense point-to-point correspondences[16].The use of an average face model signifi-cantly reduces the complexity of similarity calculation and point-cloud representation of registered faces are more suitable for recog-nition then depth image-based methods,point signatures,and im-plicit polynomial-based representation techniques.In a follow-up study,G¨o kberk et al.have analyzed the effect of registration meth-ods on the classification accuracy[14].To inspect side effects of warping on discrimination an ICP-based approximate dense regis-tration algorithm is designed that allows only rotation and transla-tion transformations.Experimental results confirmed that ICP with-out warping leads to better recognition accuracy1.Table.1sum-marizes the classification accuracies of different feature extractors for both TPS-based and ICP-based registration algorithms on the 3D RMA dataset.Improvement is visible for all feature extraction methods,except the shape-index.Table1:Average classification accuracies(and standard deviations) of different face recognizers for1)TPS warping-based and2)ICP-based face representation techniques.TPS ICPPoint Cloud92.95±1.0196.48±2.02Surface Normals97.72±0.4699.17±0.87Shape Index90.26±2.2188.91±1.07Depth PCA45.39±2.1550.78±1.10Depth LDA75.03±2.8796.27±0.93Central Profile60.48±3.7882.49±1.34Profile Set81.14±2.0994.30±1.552.2.3Depth MapDepth maps are usually used in conjunction with subspace meth-ods,although most of the existing2D techniques are suitable for processing the depth maps.The depth map construction consists of selecting a viewpoint,and smoothing the sampled depth values. In[15],PCA and ICA were compared on the depth maps.ICA was found to perform better,but PCA degraded more gracefully with declining numbers of training samples.In Srivastava et al. the set of all k-dimensional subspaces of the data space is searched with a MCMC simulated annealing algorithm for the optimal linear subspace[30].The optimal subspace method performs better than PCA,LDA or ICA.Achermann at pare an eigenface method with a5-state left-right HMM on a database of depth maps[1]. They show that the eigenface method outperforms the HMM,and 1In[32]texture was found to be more informative than depth;ourfind-ings point out to warping as a possible reason.the smoothing effects the eigenface method positively,while its ef-fect on the HMM is detrimental.The3D data are usually more suitable for alignment,and should be preferred if available.In Lee et al.the3D image is thresholded after alignment to obtain the depth map,and a number of small windows are sampled from around the nose[18].The statistical features extracted from these windows are used in recognition. 2.2.4ProfileThe most important problem for the profile-based schemes is the extraction of the profile.In an early paper Cartoux et e an iterative scheme tofind the symmetry plane that cuts the face into two similar parts[9].The nose tip and a second point are used to extract the profiles.Nagamine et e various heuristics tofind feature points and align the faces by looking at the symmetry[25]. Then the faces are intersected with different kinds of planes(verti-cal,horizontal or cylindrical around the nose tip),and the intersec-tion curve is used in recognition.Vertical planes around±20mm.of the central region and selecting a cylinder with20−30mm.radius around the nose(crossing the inner corners of the eyes)produced the best results.In[4],Beumier and Acheroy detail the acquisition of the popular3D RMA dataset with structural light and report pro-file based recognition results.In addition to the central profile,they use the average of two lateral profiles in recognition.Once the profiles are obtained,there are several ways of match-ing them.In[9],corresponding points of two profiles are selected to maximize a matching coefficient that uses the curvature on the profile curve.Then a correlation coefficient and the mean quadratic distance is calculated between the coordinates of the aligned profile curves,as two alternative measures.In[4],the area between the profile curves is used.In[14]distances calculated with L1norm, L2norm,and generalized Hausdorff distance were compared for aligned profiles,and the L1norm is found to perform better.2.2.5Analysis by SynthesisIn[6]the analysis-by-synthesis approach that uses morphable mod-els is detailed.A morphable model is defined as a convex combi-nation of shape and texture vectors of a number of samples that are placed in dense correspondence.A single3D model face is used to render an image similar to the test image,which leads to the es-timation of viewpoint parameters(pose angles,3D translation,fo-cal length of the camera),illumination parameters(ambient and di-rected light intensities,direction angles of the light,colour contrast, gains and offsets of the colour channels),and deformation parame-ters(shape and texture).In[22]a system is proposed to work with 2D colour images and corresponding3D depth maps.The idea is to synthesize a pose and illumination corrected image pair for recog-nition.The depth images performed significantly better(by4-7per cent)than colour images,and the combination increased the accu-racy as well(by1-2per cent).Pose correction is found to be more important than illumination correction.2.2.6Combinations of RepresentationsMost of the work that uses3D face data use a combination of rep-resentations.The enriched variety of features,when combined with classifiers with different statistical properties,produce more accu-rate and more robust results.In Tsutsumi et al.surface normals and intensities are concatenated to form a single feature vector,and the dimensionality is reduced with PCA[34].In[35],the3D data are described by point signatures,and the2D data by Gabor wavelet responses,respectively.3D intensities and texture were combined to form the4D representation in[29].Bronstein et al.point out to the non-rigid nature of the face,and to the necessity of using a suit-able similarity metric that takes this deformability into account[8]. For this purpose,they use multi-dimensional scaling projection al-gorithm for both shape and texture information.Apart from techniques that fuse the representations at the fea-ture level,there are a number of systems that employ combination at the decision level.Chang et al.propose in[10]to use Maha-lanobis distance-based nearest-neighbor classifiers on the2D inten-sity and3D range images separately,and fuse the decisions with a rank-based approach at the decision level.In[32]the depth map and colour maps(one for each YUV channel)are projected via PCA and the distances in four subspaces are combined by multiplication. In[33]the depth map and the intensity image are processed with embedded HMMs separately,and weighted score summation is pro-posed for the combination.In[21],Lu and Jain combine texture (LDA)and surface(point-to-plane distance)with weighted voting, but only the difficult samples are classified via the combined sys-tem.Profiles are also used in conjunction with other features.In[5], 3D central and lateral profiles,gray level central and lateral profiles were evaluated separately,and then fused with Fisher’s method. In[26]a surface-based recognizer and a profile-based recognizer are combined at the decision level.Surface-matcher’s similarity is based on a point cloud distance approach,and profile similarity is calculated using Hausdorff distance.In[27],a number of methods are tested on the depth map(Eigenface,Fisherface,and kernel Fish-erface),and the depth map expert is fused with three profile experts with Max,Min,Sum,Product,Median and Majority V ote rules,out of which the Sum rule was selected.G¨o kberk et al.have proposed two combination schemes that use3D facial shape information[14].In thefirst scheme,called parallel fusion,different pattern classifiers are trained using differ-ent features such as point clouds,surface normals,facial profiles, and PCA/LDA of depth images.The outputs of these pattern classi-fiers are merged using a rank-based decision level fusion algorithm. As combination rules,consensus voting,a non-linear variation of a rank-sum method,and a highest rank majority method are used.Ta-ble.2shows the recognition accuracies of individual pattern recog-nizers together with the accuracies of the parallel ensemble methods for the3D RMA dataset.It is seen that while the best individual pat-tern classifier(Depth-LDA)can accurately classify96.27per cent of the test examples,a non-linear rank-sum fusion of Depth-LDA, surface normals,and point cloud classifiers improves the accuracy to99.07per cent.Paired t-test results indicate that all of the ac-curacies of the parallel fusion schemes are statistically better than individual classifier’s performances.The second scheme is called serial fusion where the class outputs of afilteringfirst classifier is passed to a second more complex classifier.The ranked output lists of these classifiers are fused.Thefirst classifier in the pipeline should be fast and accurate.Therefore a point cloud-based pattern classifier was selected.As the second classifier,Depth-LDA was chosen because of its discriminatory power.This system has98.14 per cent recognition accuracy,significantly better than the single best classifier.Table2:Classification accuracies of single face classifiers(top part),and the combined classifiers(bottom part).Performances of Pattern ClassifiersDimensionality Acc.Point Cloud3,389×395.96Surface Normals3,389×395.54Depth PCA30050.78Depth LDA3096.27Profile Set1,55794.30Performances of Combined ClassifiersPattern Classifiers Acc.Consensus V oting LDA,PC,SN98.76Nonlinear Rank-Sum Profile,LDA,SN99.07Highest Rank Majority Profile,LDA,SN,PC98.13Serial Fusion PC,LDA98.143.CONCLUSIONSThere are a number of questions3D face recognition research needs to address.In acquisition,the accuracy of cheaper and less intru-sive systems needs to be improved,temporal sequences should be considered.For registration,automatic landmark localization,arti-fact removal,scaling,and elimination of errors due to occlusions, glasses,beard,etc.need to be worked out.Ways of deforming the face without losing discriminative information might be beneficial.It is obvious that information fusion is the future of3D face recognition.There are many ways of representing and combining texture and shape information.We also distinguish between local and configural processing,where the ideal face recognizer makes use of both.For realistic systems,single training instance cases should be considered,which is a great hurdle to some of the more successful discriminative algorithms.Publicly available3D datasets are necessary to encourage further research on these topics.REFERENCES[1]Achermann,B.,X.Jiang,H.Bunke,“Face recognition usingrange images,”in Proc.Int.Conf.on Virtual Systems and Mul-tiMedia,pp.129-136,1997.[2]Achermann,B.,H.Bunke,“Classifying range images of hu-man faces with Hausdorff distance,”in Proc.ICPR,pp.809-813,2000.[3]Besl,P.,N.McKay,“A Method for Registration of3-DShapes,”IEEE Trans.PAMI,vol.14,no.2,pp.239-256,1992.[4]Beumier,C.,M.Acheroy,“Automatic3D face authentication,”Image and Vision Computing,vol.18,no.4,pp.315-321,2000.[5]Beumier,C.,M.Acheroy,“Face verification from3D andgrey level cues,”Pattern Recognition Letters,vol.22,pp.1321-1329,2001.[6]Blanz,V.,T.Vetter,“Face Recognition Based on Fitting a3DMorphable Model,”IEEE Trans.PAMI,vol.25,no.9,pp.1063-1074,2003.[7]Bowyer,K.,Chang K.,P.Flynn,“A survey of multi-modal2D+3D face recognition,”Technical Report,Notre Dame De-partment of Computer Science and Engineering,2004. [8]Bronstein,A.M.,M.M.Bronstein,R.Kimmel,“Expression-invariant3D face recognition,”in J.Kittler,M.S.Nixon(eds.) Audio-and Video-Based Person Authentication,pp.62-70, 2003.[9]Cartoux,J.Y.,Preste,M.Richetin,“Face authentica-tion or recognition by profile extraction from range images,”in Proc.of the Workshop on Interpretation of3D Scenes,pp.194-199,1989.[10]Chang,K.,K.Bowyer,P.Flynn,“Multi-modal2D and3Dbiometrics for face recognition,”in Proc.IEEE Int.Workshop on Analysis and Modeling of Faces and Gestures,2003. [11]Chen,Y.,G.Medioni,“Object Modeling by Registrationof Multiple Range Images,”Image and Vision Computing, vol.10,no.3,pp.145-155,1992.[12]Colbry,D.,X.Lu,A.Jain,G.Stockman,“3D face feature ex-traction for recognition,”Technical Report MSU-CSE-04-39, Computer Science and Engineering,Michigan State Univer-sity,2004.[13]Gordon,G.“Face recognition based on depth and curvaturefeatures,”in SPIE Proc.:Geometric Methods in Computer Vi-sion,vol.1570,pp.234-247,1991.[14]G¨o kberk,B.,A.A.Salah,L.Akarun,“Rank-based DecisionFusion for3D Shape-based Face Recognition,”submitted for publication.[15]Hesher, C., A.Srivastava,G.Erlebacher,“A novel tech-nique for face recognition using range imaging,”in Proc.7th Int.Symposium on Signal Processing and Its Applications, pp.201-204,2003.[16]˙Irfano˘g lu,M.O.,B.G¨o kberk,L.Akarun,“3D Shape-BasedFace Recognition Using Automatically Registered Facial Sur-faces,”in Proc.ICPR,vol.4,pp.183-186,2004.[17]Lao,S.,Y.Sumi,M.Kawade,F.Tomita,“3D template match-ing for pose invariant face recognition using3D facial model built with iso-luminance line based stereo vision,”in Proc.ICPR,vol.2,pp.911-916,2000.[18]Lee,Y.,K.Park,J.Shim,T.Yi,“3D face recognition usingstatistical multiple features for the local depth information,”in Proc.ICVI,2003.[19]Lu,X.,D.Colbry,A.K.Jain,“Three-Dimensional ModelBased Face Recognition,”in Proc.ICPR,2004.[20]Lu,X.A.K.Jain,“Deformation Analysis for3D Face Match-ing,”to appear in Proc.IEEE WACV,2005.[21]Lu,X.A.K.Jain,“Integrating Range and Texture Informationfor3D Face Recognition,”to appear in Proc.IEEE WACV, 2005.[22]Malassiotis,S.,M.G.Strintzis,“Pose And Illumination Com-pensation For3D Face Recognition,”in Proc.ICIP,2004. [23]Medioni,G.,R.Waupotitsch,“Face recognition and model-ing in3D,”IEEE Int.Workshop on Analysis and Modeling of Faces and Gestures,pp.232-233,2003.[24]Moreno, A.B.,´A.S´a nchez,J.F.V´e lez, F.J.D´ıaz,“Facerecognition using3D surface-extracted descriptors,”in Proc.IMVIPC,2003.[25]Nagamine,T.,T.Uemura,I.Masuda,“3D facial image anal-ysis for human identification,”in Proc.ICPR,pp.324-327, 1992.[26]Pan,G.,Y.Wu,Z.Wu,W.Liu,“3D Face recognition by pro-file and surface matching,”in Proc.IJCNN,vol.3,pp.2169-2174,2003.[27]Pan,G.,Z.Wu,“3D Face Recognition From Range Data,”submitted to Int.Journal of Image and Graphics,2004. [28]Pankanti,S.,R.M.Bolle,A.Jain“Biometrics:The Future ofIdentification,”IEEE Computer,pp.46–49,2000.[29]Papatheodorou,T.,D.Rueckert,“Evaluation of automatic4Dface recognition using surface and texture registration,”in Proc.AFGR,pp.321-326,2004.[30]Srivastava,A.,X.Liu,C.Hesher,“Face Recognition UsingOptimal Linear Components of Range Images,”submitted for publication,2003.[31]Tanaka,H.,M.Ikeda,H.Chiaki,“Curvature-based face sur-face recognition using spherical correlation,”in Proc.ICFG, pp.372-377,1998.[32]Tsalakanidou,F.,D.Tzovaras,M.Strinzis,“Use of depth andcolour eigenfaces for face recognition,”Pattern Recognition Letters,vol.24,pp.1427-1435,2003.[33]Tsalakanidou,F.,S.Malassiotis,M.Strinzis,“Integration of2D and3D images for enhanced face authentication,”in Proc.AFGR,pp.266-271,2004.[34]Tsutsumi,S.,S.Kikuchi,M.Nakajima,“Face identificationusing a3D gray-scale image-a method for lessening restric-tions on facial directions,”in Proc.AFGR,pp.306-311,1998.[35]Wang,Y.,C.Chua,Y.Ho,“Facial feature detection and facerecognition from2D and3D images,”Pattern Recognition Letters,vol.23,pp.1191-1202,2002.[36]Xu,C.,Y.Wang,T.Tan,L.Quan,“Automatic3D face recog-nition combining global geometric features with local shape variation information,”in Proc.AFGR,pp.308-313,2004. [37]Yacoob,Y.,L.S.Davis,“Labeling of human face componentsfrom range data,”CVGIP:Image Understanding,vol.60,no.2, pp.168-178,1994.Table3:Overview of3D face recognition systemsGroup Representation Database Algorithm NotesGordon[13]curvatures26training Euclidean Curvatures can be used for feature detection24test nearest neighbour but they are sensitive to smoothing.Tanaka et al.[31]curvature NRCC Fisher’s spherical Use principal curvatures instead of surface based EGI correlation normals for non-polyhedral objects.Moreno et al.[24]Curvature,line,7img.×Euclidean Angle,distance and curvature featuresregion features60persons nearest neighbour work better than area based features. Achermann and point cloud120training Hausdorff Hausdorff distance can be speeded upBunke[2]120test nearest neighbour by voxel discretization.Lao et al.[17]curve segments36img.×Euclidean Points with bad correspondence are10persons nearest neighbour not used in distance calculation.Medioni and mesh7img.×normalized After alignment,a distance map is found. Waupotitsch[23]100persons cross-correlation Statistics of the map are used in similarity.˙Irfano˘g lu et al.[16]point cloud3D RMA Point set ICP used to align point clouds with a basedifference(PSD)mesh.PSD outperforms PCA on depth map.Lu et al.[19]mesh90training hybrid ICP and ICP distances and shape index based113test cross-correlation correlation can be usefully combined.Xu et al.[36]regular mesh3D RMA Feature extraction,Feature derivation+PCA around landmarksPCA and NN worked better than aligned mesh distances.Lu and Jain[20]deformation500training ICP+TPS,Distinguishing between inter-subject and points196test nearest neighbour intra-subject deformations helps recognition. Achermann depth map120training eigenface Eigenface outperforms HMM.Smoothinget al.[1]120test vs.HMM is good for eigenface,bad for HMM.Hesher et al.[15]mesh FSU ICA or PCA+ICA outperforms PCA,PCA degrades morenearest neighbour gracefully as training samples are decreased. Lee et al.[18]depth map2img.×feature extraction+Mean and variance of depth from windows35persons nearest neighbour around the nose are used as features. Srivastava et al.[30]depth map6img.×subspace projection Optimal subspace found with MCMC simulated67persons+SVM annealing outperforms PCA,ICA and LDA. Cartoux et al.[9]profile3/4img.×curvature based High quality images needed for principal5persons nearest neigbour curvatures.Nagamine et al.[25]vertical,horiz.,10img.×Euclidean Central vertical profile and circular sections circular profiles16persons nearest neigbour touching eye corners are most informative. Beumier and vertical profiles3D RMA area based Central profile and mean lateral profiles Acheroy[4]nearest neigbour are fused by averaging.Blanz and Vetter[6]2D+viewpoint CMU-PIE,analysis Using a generic3D model,2D viewpoint parameters FERET by synthesis parameters are found.Malassiotis and texture+110img.×embedded HMM Depth is better than colour,fusion is best.Pose Strinzis[22]depth map20persons+fusion correction is better than illumination correction. Tsutsumi et al.[34]texture+35img.×concatenated Adding perturbed versions of training images depth map24persons features+PCA reduces sensitivity of PCA.Beumier and2D and3D3D RMA nearest neighbour Combination of2D and3D helps.Temporal Acheroy[5]vertical profiles+fusion fusion(snapshots taken in time)helps too. Wang et al.[35]point signature6img.×concatenation Omit3D info from the eyes,eyebrows(missing Gabor features50persons after PCA+SVM elements)and mouth(expression sensitivity) Bronstein et al.[8]texture+157concatenation after Bending-invariant canonical representation is depth map persons PCA+near.neigh.robust to facial expressions.Chang et al.[10]texture+278training Mahalanobis based Pose correction through3D is not better than depth map166test near.neigh.+fusion rotation-corrected2D.Pan et al.[26]profile+3D RMA ICP+Hausdorff Surface and profile combined usefully.Discard point cloud+fusion worst points(10per cent)during registration. Tsalakanidou texture+XM2VTS nearest neighbour Fusion of frontal colour and depth images with et al.[32]depth map+fusion colour faces from profile.Tsalakanidou texture+60img.×embedded HMM Appropriately processed texture is moreet al.[33]depth map50persons+fusion informative than warped depth maps.Pan and Wu[27]depth map6img.×(kernel)Fisherface Sum rule is preferred to max,min,product, +profile120persons+Eigenface+fusion median and majority vote for fusion. Papatheodorou dense mesh12img.×nearest neighbour3D helps2D especially for profile views.and R¨u ckert[29]+texture62persons+fusion Texture has small relative weight.Lu and Jain[21]mesh598test ICP(3D),LDA(2D)Difficult samples are evaluated by the+texture scans+fusion combined scheme.G¨o kberk et al.[14]surface normals,3D RMA PCA,LDA,Best single classifier is depth-LDA.profiles,depth nearest neighbour,Combining it with surface normals and profilesmap,point cloud rank based fusion with nonlinear rank sum increases accuracy.。

专利名称:Aperture for coded-aperture imaging发明人:Cattin-Liebl, Roger申请号:EP03405493.2申请日:20030702公开号:EP1494047A1公开日:20050105专利内容由知识产权出版社提供专利附图:摘要:An aperture for coded-aperture imaging comprises a sequence of transparent(2) and opaque (3) circles, wherein the transparent (2) and opaque (3) circles represent a one-dimensional sequence known for the construction of coded aperture masks. This achieves a coded aperture (1) which is invariant to rotation. The aperture according to theinvention can readily be used in coded-aperture imaging optical transmission of data between a screen, e.g. a computer screen, displaying the intermediate image, and a smart-card, wherein the user of such a smart-card is not supposed to align the camera comprising the decoding aperture (1), i.e. the smard-card, with the coding mask used to prepare the intermediate image.申请人:Berner Fachhochschule Hochsschule für Technik und Architektur Biel-Bienne 地址:Abteilung Automobiltechnik, Quellgasse 21 2501 Biel-Bienne CH国籍:CH代理机构:Liebetanz, Michael, Dipl.-Phys.更多信息请下载全文后查看。

专利名称:Coded aperture imaging method and device发明人:Cruickshank, Garth,Hennion,Claude,Dickinson, Joe,Naylor, David B.申请号:EP02291900.5申请日:20020726公开号:EP1385124A1公开日:20040128专利内容由知识产权出版社提供专利附图:摘要:Imaging process for generating a 3-dimension representation of a 3-dimension observation field, including the following steps: (a) detecting radiations emitted by a plurality of voxels in the observation field, through a collimator (5) having radiationtransmitting areas (16) which are unevenly distributed, thus determining a detected 2-dimension distribution H(I,J) of the radiations detected through the collimator,(b) and determining an estimated 3-dimension distribution of the radiation emissions hes(i,j,k) of the voxels in the observation field, which corresponds to the detected 2-dimension distribution H(I,J).申请人:Cruickshank, Garth,Hennion, Claude,Dickinson, Joe,Naylor, David B.地址:47 Woodbridge Road, Moseley Birmingham B13 9DZ GB,12, rue de la Glacière 75013 Paris FR,The Podge, 4, Janvrin Road, St. Helier Jersey, Channel Islands GB,51 Cornwall Road Cheam, Surrey SM2 6DU GB国籍:GB,FR,GB,GB代理机构:Burbaud, Eric更多信息请下载全文后查看。

专利名称:Coded aperture imaging system发明人:スリンガー,クリストフアー・ウイリアム,ルーイス,キース・ローダー申请号:JP2008512909申请日:20060523公开号:JP2008542863A公开日:20081127专利内容由知识产权出版社提供专利附图:摘要: The present invention relates to coded aperture imaging methods and coded aperture imaging device. In one embodiment, the coded aperture imaging systemincludes a coded aperture mask means reconfigurable detector and at least one array.You can view different coded aperture mask, without the necessary optical components or large moving parts of any reconfigurable coded aperture mask means is imaging at various resolutions and / or across various field It can be performed. It is possible toperform imaging of a large area without having to arrange seamlessly using the detector array with more than one, which represents a separate embodiment of the presentinvention. The invention also relates to the use of a coded aperture imaging methods inthe wavelength range of the visible infrared, or ultraviolet. it is possible to automatically remove any aberrations introduced by the element image decoding is curved, the use of coded aperture imaging method for imaging the optical element curved is taught.申请人:キネテイツク・リミテツド地址:イギリス国、ロンドン・エス・ダブリユ・1・6・テイ・デイ、バツキンガム・ゲート・85国籍:GB代理人:川口 義雄,小野 誠,渡邉 千尋,金山 賢教,大崎 勝真,坪倉 道明更多信息请下载全文后查看。

专利名称:The computer program and the methodwhere the image processing device, theimaging system, and object inside thepicture it expands reduces发明人:レイモンド イェー エー ハベッツ,ルテゥガー ネイルンシング申请号:JP2007514280申请日:20050525公开号:JP2008501179A公开日:20080117专利内容由知识产权出版社提供专利附图:摘要:As for this invention, in regard to the image processing device which it expands reduces object inside the picture, as for this image processing device, in order to expand to reduce the aforementioned object on the basis of the calibration factor which isguided from relationship between actual dimension of the marker and size at the pixel unit, inside the picture of the said marker being something which has the calibrator which is formed, in order to form the plural calibration factors which can this calibratorfurthermore, making use of the marker of the direction where the plural which is identified inside the aforementioned picture differs, it constitutes. Picture 1 faces the direction which differs spatially and arrangement differs vis-a-vis anatomy structure 2, plural objects 3,8,9 are included. Object 3, as length of this object 3 is measured at the pixel unit, in order to calculate actual length of object 3, making use of the calibration factor which was requested from the marker A which takes the arrangement which spatially is similar to object 3, is linked to the measurement tool which is formed. Picture 1 includes furthermore, in order actual length of object 8,9, at the pixel unit of these objects to calculate on the basis of the calibration factor which was requested making use of length, and marker B, the object 8,9 which is linked to the measurement tool which is formed. As for the object which corresponds to the marker which differs in order to form the proofreading group, grouping, it is ideal for actual dimension of all objects inside the same proofreading group that to try is renewed automatically, by the renewal of calibration factor. Convenience for the user, as for the identification of each proofreading group it is ideal to change. This invention furthermore regards also the imaging system and computer program and the method of making the enlargement reduction of object inside the picture possible.申请人:コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ地址:オランダ国 5621 ベーアー アインドーフェン フルーネヴァウツウェッハ 1国籍:NL代理人:伊東 忠彦更多信息请下载全文后查看。

专利名称:PROCESS, DEVICE AND USE FOREVALUATING CODED IMAGES发明人:BORDES, Philippe,GUILLOTEL, Philippe 申请号:EP2000001688申请日:20000229公开号:WO00/054220P1公开日:20000914专利内容由知识产权出版社提供摘要:The present invention relates to a process for evaluating the quality of coded images, characterized in that it comprises: a) a step of processing the signal representative of the image so as to obtain a processed signal, b) a step of constructing on the basis of the signal representative of the coded image, a signal representative of the field of motion image on the basis of the source sequence, c) a step of building a signal representative of the segmenting of the field of motion and of storing the image pixels representative of each region having a different field of motion at an address defined with respect to the velocity vectors estimated in the step of constructing the field of motion making it possible to determine the pixels having different velocity vectors, d) a step of determining or of calculating a psychovisual human filter to be applied as a function of the estimated velocity of the region, e) a step of filtering the processed signal, and f) a step of constructing the map of disparities between the signals representative of the image which are obtained after the filtering step and the signals representative of the decoded image which are obtained after the filtering step.申请人:BORDES, Philippe,GUILLOTEL, Philippe地址:46, quai Alphonse Le Gallo F-92100 Boulogne Billancourt FR,ThomsonMultimedia 46, quai Alphonse Le Gallo F-92648 Boulogne Cedex FR,Thomson Multimedia 46, quai Alphonse Le Gallo F-92648 Boulogne Cedex FR国籍:FR,FR,FR代理机构:RUELLAN LEMONNIER, Brigitte,KERBER Thierry更多信息请下载全文后查看。
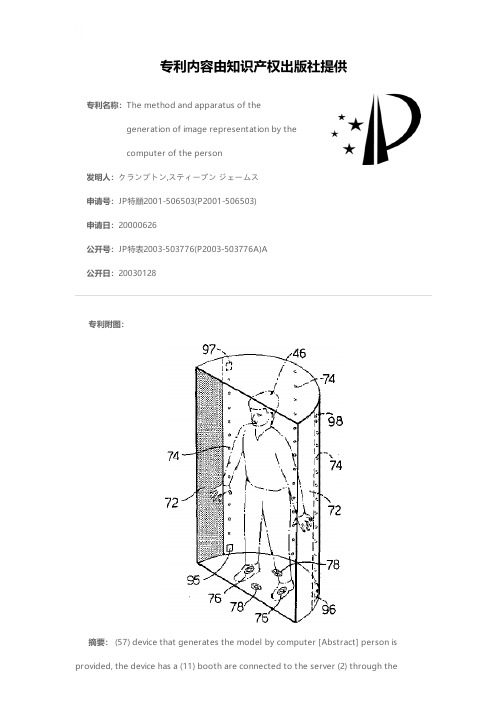
专利名称:The method and apparatus of thegeneration of image representation by thecomputer of the person发明人:クランプトン,スティーブン ジェームス申请号:JP特願2001-506503(P2001-506503)申请日:20000626公开号:JP特表2003-503776(P2003-503776A)A公开日:20030128专利内容由知识产权出版社提供专利附图:摘要: (57) device that generates the model by computer [Abstract] person isprovided, the device has a (11) booth are connected to the server (2) through theInternet (3). Model by computer corresponding to the person by comparing a general model image data of the person is obtained using the (1) Booth, then stored the image was acquired is created. Is then stored in the server data representing a model which can then be transmitted to the server (2). Then the stored data is retrieved via the Internet using a personal computer with a software application stored. Then the application software of the personal computer (4) on, can be utilized as the data is created in one image representation of any pose several persons.申请人:クランプトン,スティーブン ジェームス地址:イギリス国,ハートフォードシャー イーエヌ7 5ジェーユー,ウォルサム クロス,ゴッフスオーク,ブロードフィールズ 9国籍:GB代理人:石田 敬 (外4名)更多信息请下载全文后查看。

第44卷第6期航天返回与遥感2023年12月SPACECRAFT RECOVERY & REMOTE SENSING119基于非局部深度先验的编码孔径快照光谱成像重构算法王乙任1徐彭梅1,*王立志2苏云1崔博伦1朱军3(1 北京空间机电研究所,北京100094)(2 北京理工大学,北京100081)(3 航天东方红卫星有限公司,北京100094)摘要在编码孔径快照光谱成像(CASSI)重构领域,重构质量的提升受到图像先验正则化和优化方法的双重影响。
针对传统正则项设计复杂、调参效率低下及现有深度先验正则项感受野局限、难以捕捉长距离依赖等问题,以及基于模型的优化方法重建精度不足、端到端优化方法缺乏解释性的挑战,文章提出了一种创新的基于非局部深度先验的CASSI重构算法。
该算法通过构建非局部深度先验网络,在先验正则化方面实现高光谱图像空间与光谱维度的全局信息和长程依赖的深入捕捉;在优化方法上,引入了深度展开网络的多阶段架构,加快了收敛速度,并显著提高了重建质量。
仿真结果显示,新算法重建图像的峰值信噪比(PSNR)较传统方法提高了13.12 dB,较最新的深度学习方法提升了1.06 dB;同时,计算复杂度降低了43.4%,参数量减少了53.2%,有效保证了深度学习方法的计算效率。
试验验证结果显示新算法能够还原更多细节、恢复更多的结构和纹理,视觉效果较好,进一步验证了该算法的有效性。
这一研究可为深度学习在计算光谱成像重构领域的应用提供一定参考。
关键词计算光谱成像编码孔径快照光谱成像深度学习压缩感知中图分类号: TP391.9文献标志码: A 文章编号: 1009-8518(2023)06-0119-11DOI: 10.3969/j.issn.1009-8518.2023.06.011Reconstruction Algorithm Based on Non-Local Deep Prior for Coded Aperture Snapshot Spectral ImagersWANG Yiren1XU Pengmei1,*WANG Lizhi2SU Yun1CUI Bolun1ZHU Jun3(1 Beijing Institute of Space Mechanics & Electricity, Beijing 100094, China)(2 Beijing Institute of Technology, Beijing 100081, China)(3 DFH Satellite Co., Ltd., Beijing 100094, China)Abstract In the field of compressive aperture snapshot spectral imaging (CASSI) reconstruction, the enhancement of reconstruction quality is dually influenced by image prior regularization and optimization methods. Addressing the complexities and inefficiencies in tuning traditional regularizers, as well as the limited收稿日期:2023-06-20基金项目:民用航天项目(D010206)引用格式:王乙任, 徐彭梅, 王立志, 等. 基于非局部深度先验的编码孔径快照光谱成像重构算法[J]. 航天返回与遥感, 2023, 44(6): 119-129.WANG Yiren, XU Pengmei, WANG Lizhi, et al. Reconstruction Algorithm Based on Non-Local Deep Prior forCoded Aperture Snapshot Spectral Imagers[J]. Spacecraft Recovery & Remote Sensing, 2023, 44(6): 119-129. (inChinese)120航天返回与遥感2023年第44卷receptive fields and difficulties in capturing long-range dependencies of existing deep prior regularizers, and the challenges of insufficient reconstruction accuracy in model-based optimization methods and lack of interpretability in end-to-end optimization approaches, this paper proposes an innovative CASSI reconstruction algorithm based on non-local deep prior. This algorithm, through the construction of a non-local deep prior network, achieves comprehensive capture of global information and long-range dependencies in both spatial and spectral dimensions for hyperspectral images in the aspect of prior regularization. In terms of optimization method, the introduction of multi-stage architecture in the deep unfolding network accelerates convergence and significantly enhances the reconstruction quality. Simulation results demonstrate that the proposed algorithm achieves a peak signal-to-noise Ratio (PSNR) improvement of 13.12 dB over traditional methods and 1.06 dB over the latest deep learning approaches. Concurrently, it reduces computational complexity by 43.4% and the number of parameters by 53.2%, effectively ensuring the computational efficiency of the deep learning method. Experimental validation results indicate that the new algorithm can restore more details, recover more structures and textures, and provide better visual effects, further verifying its effectiveness. The above research offers valuable references for the application of deep learning in computational spectral imaging reconstruction.Keywords computational spectral imaging; snapshots spectral imaging; deep learning; compressive sensing0 引言高光谱成像技术能够获取图谱合一的三维数据立方体。

发表在2004年11月期微机发展Imagine流处理器王湘新1文梅伍楠李海燕李礼张春元摘要Imagine流处理器以其在媒体处理上的优势和良好的扩展性,已经成为研究热点。
本文着重从不同角度详细分析了介绍Imagine芯片的特点。
关键词流处理器,流,带宽层次,ImagineImagine Stream ProcessorWang xiangxin, Wen Mei, Wu Nan, Li Haiyan, Li Li, Zhang ChunyuanAbstract With high performance in media processing and good scalability, the Imagine stream processor became hotspot in research. This paper analyzes characters of the Imagine stream processor from different angles.key words Stream processor ,Stream, Bandwidth hierarchy, Imagine0 介绍传统的微处理器如Iiantium,其运算单元只占芯片面积的6.5%,大部分芯片面积被用于实现cache、支持分支预测、乱序执行、通讯调度等。
关于这一点图形处理器和DSP做得比较好,一个现代的高端图形加速芯片拥有超过64个浮点ALU和1000个整数ALU,运算密度将近是传统微处理器的100倍。
在面对密集型运算任务时,运算单元的低占有率带来了运算速度上的巨大差别。
(1GOPS CPU vs. 1TOPS Graphics chip)因此我们面临的问题是如何发展新的体系结构有效利用这些丰富而廉价的资源,为芯片提供更大规模计算的能力。
而如何有效利用芯片集成能力的提高,换言之就是如何充分利用技术发展带来的丰富而廉价的运算资源,有效利用芯片面积来计算,是新型微体系结构研究的重要课题。

SPIHT算法及其在基于二维条码的防伪证件中的应用韩大炜;梁华庆;耿敏【摘要】针对基于PDF417二维条码的防伪证件中的照片压缩问题,将小波变换和SPIHT算法相结合,实现了一种图像压缩方法.该算法首先将证件照片进行小波分解,然后根据人眼视觉特性,把小波分解系数进行SPIHT量化编码,可将证件照片压缩到PDF417条码存储空间限制的1 108个字节以内.实验表明本算法具有较好的图像压缩效果和图像重建质量.【期刊名称】《科学技术与工程》【年(卷),期】2010(010)013【总页数】5页(P3096-3100)【关键词】证件防伪;PDF417;图像压缩;小波变换;SPIHT算法【作者】韩大炜;梁华庆;耿敏【作者单位】中国石油大学,北京,机电工程学院电子信息工程系,北京,102249;中国石油大学,北京,机电工程学院电子信息工程系,北京,102249;中国石油大学,北京,机电工程学院电子信息工程系,北京,102249【正文语种】中文【中图分类】TN911.73由于 PDF417二维条码具有信息容量大、可靠性高、纠错能力强、制作容易、成本低且不依赖数据库等优点,应用范围十分广泛,证件防伪就是其一个重要应用领域。
基于二维条码的防伪证件的基本原理是:将证件持有人的数字照片通过数据压缩算法转化成0—1比特流;再将 0—1比特流加密置乱后编成PDF417码,然后和证件持有人的数字照片一起打印输出,制成防伪证件。
证件鉴别时,用 PDF417扫描器对条码进行扫描,将解码后恢复出的数字照片与证件上的照片进行比对,判别真伪。
上述证件防伪方案,其核心技术是照片的压缩算法。
由于受到 PDF417二维条形码存储空间的限制(存储空间为1108个字节),对照片的压缩要求非常高。
既要在指定字节数的情况下压缩图像,又要保证较高质量的压缩效果和重建效果。
此外,为保证实用性,算法要尽可能简单。
现有的静态图片压缩技术大多不能同时满足这些要求。
