数学建模实验四
- 格式:doc
- 大小:435.50 KB
- 文档页数:20

湖南城市学院数学与计算科学学院《数学建模》实验报告专业:学号:姓名:指导教师:成绩:年月日目录实验一 初等模型........................................................................ 错误!未定义书签。
实验二 优化模型........................................................................ 错误!未定义书签。
实验三 微分方程模型................................................................ 错误!未定义书签。
实验四 稳定性模型.................................................................... 错误!未定义书签。
实验五 差分方程模型................................................................ 错误!未定义书签。
实验六 离散模型........................................................................ 错误!未定义书签。
实验七 数据处理........................................................................ 错误!未定义书签。
实验八 回归分析模型................................................................ 错误!未定义书签。
实验一 初等模型实验目的:掌握数学建模的基本步骤,会用初等数学知识分析和解决实际问题。
实验内容:A 、B 两题选作一题,撰写实验报告,包括问题分析、模型假设、模型构建、模型求解和结果分析与解释五个步骤。

数学建模实验报告班级:姓名:学号:元件可靠性问题一、实验问题:给出3种不同情况的元件连接方式,分别求解他们的正常运行概率。
其中每个元件的正常运行概率均为p。
元件数为N,方式2与方式3用到了与A元件相同的N个B元件。
连接方式如图:方式1:方式2:方式3:二、问题分析:N个元件的连接方式,相当于电阻的串并联,所以可以用电阻串并联的关系去分析各无件之间的关系:对于方式一来说,相当于电阻的串联。
所以,他的正常运行的概率为p^n.对于方式二来说,相当于电阻先串联再并联。
所以,他的正常运行的概率为:1-(1-P^n)(1-P^n)=2P^n-P^2n.对于方式三来说,相当于电阻先并联再串联。
所以,他的正常运行的概率为:(1-(1-P^n)^2)^n=(2p-p^2)^n现在再比较三个系统正常工作概率大小P1- P2= p^n–(2p^n-p^2n )= p^2n–p^n 由于0<p<1,所以易知P^2n-P^n<0。
所以有P1< P2P2- P3=(2p^n- p^2n)- (2p-p^2)^n= p^n[(2- p^n)-(2-p)^n]因为p^n>0,所以只要比较[(2- p^n)-(2-p)^n]大小即可。
对此式求导有-n[p^(n-1)-(2-p)^n-1]可见此式恒大于零,所以函数单调递增。
当p=1时,[(2- p^n)-(2-p)^n]=0.所以P2- P3 <0,再由上求导可知所以P2<P3所以P3最大。
即其的可靠性最高。
理发店问题一、实验题目:某单人理发店有4反椅子接待顾客排队理发,当4把椅子都坐满人时,后来的顾客就不进店而离去。
顾客平均到达速率为4人/H,理发时间平均10min/人。
设到达过程为泊松流,服务时间服从负指数颁布。
求:(1)顾客一到达就能理发的概率;(2)系统中顾客数的期望值和排队等待顾客数的期望值;(3)顾客在理发店内逗留的全部时间的期望值;(4)在可能到达的顾客中因客满离开的概率。

第1篇一、实验目的本次实验旨在让学生掌握数学建模的基本步骤,学会运用数学知识分析和解决实际问题。
通过本次实验,培养学生主动探索、努力进取的学风,增强学生的应用意识和创新能力,为今后从事科研工作打下初步的基础。
二、实验内容本次实验选取了一道实际问题进行建模与分析,具体如下:题目:某公司想用全行业的销售额作为自变量来预测公司的销售量。
表中给出了1977—1981年公司的销售额和行业销售额的分季度数据(单位:百万元)。
1. 数据准备:将数据整理成表格形式,并输入到计算机中。
2. 数据分析:观察数据分布情况,初步判断是否适合使用线性回归模型进行拟合。
3. 模型建立:利用统计软件(如MATLAB、SPSS等)进行线性回归分析,建立公司销售额对全行业的回归模型。
4. 模型检验:对模型进行检验,包括残差分析、DW检验等,以判断模型的拟合效果。
5. 结果分析:分析模型的拟合效果,并对公司销售量的预测进行评估。
三、实验步骤1. 数据准备将数据整理成表格形式,包括年份、季度、公司销售额和行业销售额。
将数据输入到计算机中,为后续分析做准备。
2. 数据分析观察数据分布情况,绘制散点图,初步判断是否适合使用线性回归模型进行拟合。
3. 模型建立利用统计软件进行线性回归分析,建立公司销售额对全行业的回归模型。
具体步骤如下:(1)选择合适的统计软件,如MATLAB。
(2)输入数据,进行数据预处理。
(3)编写线性回归分析程序,计算回归系数。
(4)输出回归系数、截距等参数。
4. 模型检验对模型进行检验,包括残差分析、DW检验等。
(1)残差分析:计算残差,绘制残差图,观察残差的分布情况。
(2)DW检验:计算DW值,判断随机误差项是否存在自相关性。
5. 结果分析分析模型的拟合效果,并对公司销售量的预测进行评估。
四、实验结果与分析1. 数据分析通过绘制散点图,观察数据分布情况,初步判断数据适合使用线性回归模型进行拟合。
2. 模型建立利用MATLAB进行线性回归分析,得到回归模型如下:公司销售额 = 0.9656 行业销售额 + 0.01143. 模型检验(1)残差分析:绘制残差图,观察残差的分布情况,发现残差基本呈随机分布,说明模型拟合效果较好。


《数学建模实验》实验报告学院名称数学与信息学院专业名称提交日期课程教师实验一:数学规划模型AMPL求解实验内容1. 用AMPL求解下列问题并作灵敏度分析:一奶制品加工厂用牛奶生产A1和A2两种奶制品,1桶牛奶可以在甲类设备上用12小时加工成3公斤A1或者在乙类设备上用8小时加工成4公斤A2,且都能全部售出,且每公斤A1获利24元,每公斤A2获利16元。
先加工厂每天能得到50桶牛奶的供应,每天工人总的劳动时间为480小时,并且甲类设备每天至多加工100公斤A1,乙类设备的加工能力没有限制,试为该厂制定一个计划,使每天的获利最大。
(1)建立模型文件:milk.modset Products ordered;param Time{i in Products }>0;param Quan{i in Products}>0;param Profit{i in Products}>0;var x{i in Products}>=0;maximize profit: sum{i in Products} Profit [i]* Quan [i]*x[i];subject to raw: sum{i in Products}x[i] <=50;subject to time:sum{i in Products}Time[i]*x[i]<=480;subject to capacity: Quan[first(Products)]*x[first(Products)]<=100;(2)建立数据文件milk.datset Products:=A1 A2;param Time:=A1 12 A2 8;param Quan:=A1 3 A2 4;param Profit:=A1 24 A2 16;(3) 建立批处理文件milk.runmodel milk.mod;data milk.dat;option solver cplex;solve;display x;(4)运行运行结果:CPLEX 11.0.0: optimal solution; objective 33602 dual simplex iterations (1 in phase I)x [*] :=A1 20A2 30;(5)灵敏度分析:model milk.mod;data milk.dat;option solver cplex;option cplex_options 'sensitivity';solve;display x;display x.rc, x.down, x.up;display raw, time, capacity;display raw.down, raw.up,raw.current, raw.slack;得到结果:【灵敏度分析】: x.rc x.down x.up:=A1 -3.55271e-15 64 96A2 0 48 72;raw = 48time = 2capacity = 0raw.down = 43.3333raw.up = 60raw.current = 50raw.slack = 0某公司有6个建筑工地,位置坐标为(a i, b i)(单位:公里),水泥日用量d i (单位:吨)1) 现有j j j吨,制定每天的供应计划,即从A, B两料场分别向各工地运送多少吨水泥,使总的吨公里数最小。

数学建模实验报告姓名:学院:专业班级:学号:数学建模实验报告(一)——用最小二乘法进行数据拟合一.实验目的:1.学会用最小二乘法进行数据拟合。
2.熟悉掌握matlab软件的文件操作和命令环境。
3.掌握数据可视化的基本操作步骤。
4.通过matlab绘制二维图形以及三维图形。
二.实验任务:来自课本64页习题:用最小二乘法求一形如y=a+b x2的多项式,使之与下列数据拟合:三.实验过程:1.实验方法:用最小二乘法解决实际问题包含两个基本环节:先根据所给出数据点的变化趋势与问题的实际背景确定函数类;然后按照最小二乘法原则求最小二乘解来确定系数。
即要求出二次多项式: y=a+b x2的系数。
2.程序:x=[19 25 31 38 44]y=[19.0 32.3 49.0 73.3 97.8]ab=y/[ones(size(x));x.^2];a=ab(1),b=ab(2)xx=19:44;plot(xx,a+b*xx.^2,x,y,'.')3.上机调试得到结果如下:x = 19 25 31 38 44y=19.0000 32.3000 49.0000 73.3000 97.8000a = 0.9726b = 0.0500图形:四.心得体会通过本次的数学模型的建立与处理,我们学习并掌握了用最小二乘法进行数据拟合,及多项式数据拟合的方法,进一步学会了使用matlab软件,加深了我们的数学知识,提高了我们解决实际问题的能力,为以后深入学习数学建模打下了坚实的基础。
数学建模实验报告(二)——用Newton法求方程的解一.实验目的1.掌握Newton法求方程的解的原理和方法。
2.利用Matlab进行编程求近似解。
二.实验任务来自课本109页习题4-2:用Newton法求f(x)=x-cosx=0的近似解三.实验过程1.实验原理:把f(x)在x0点附近展开成泰勒级数f(x) = f(x0)+(x-x0)f'(x0)+(x-x0)^2*f''(x0)/2! +… 取其线性部分,作为非线性方程f(x) = 0的近似方程,即泰勒展开的前两项,则有f(x0)+f'(x0)(x-x0)=0 设f'(x0)≠0则其解为x1=x0-f(x0)/f'(x0) 这样,得到牛顿法的一个迭代序列:x(n+1)=x(n)-f(x(n))/f'(x(n))。

内江师范学院中学数学建模实验报告册编制数学建模组审定牟廉明专业:班级:级班学号:姓名:数学与信息科学学院2016年3月说明1.学生在做实验之前必须要准备实验,主要包括预习与本次实验相关的理论知识,熟练与本次实验相关的软件操作,收集整理相关的实验参考资料,要求学生在做实验时能带上充足的参考资料;若准备不充分,则学生不得参加本次实验,不得书写实验报告;2.要求学生要认真做实验,主要是指不得迟到、早退和旷课,在做实验过程中要严格遵守实验室规章制度,认真完成实验内容,极积主动地向实验教师提问等;若学生无故旷课,则本次实验成绩不合格;3.学生要认真工整地书写实验报告,实验报告的内容要紧扣实验的要求和目的,不得抄袭他人的实验报告;4.实验成绩评定分为优秀、合格、不合格,实验只是对学生的动手能力进行考核,跟据所做的的情况酌情给分。
根据实验准备、实验态度、实验报告的书写、实验报告的内容进行综合评定。
实验名称:数学规划模型(实验一)指导教师:实验时数: 4 实验设备:安装了VC++、mathematica、matlab的计算机实验日期:年月日实验地点:实验目的:掌握优化问题的建模思想和方法,熟悉优化问题的软件实现。
实验准备:1.在开始本实验之前,请回顾教科书的相关内容;2.需要一台准备安装Windows XP Professional操作系统和装有数学软件的计算机。
实验内容及要求原料钢管每根17米,客户需求4米50根,6米20根,8米15根,如何下料最节省?若客户增加需求:5米10根,由于采用不同切割模式太多,会增加生产和管理成本,规定切割模式不能超过3种,如何下料最节省?实验过程:摘要:生活中我们常常遇到对原材料进行加工、切割、裁剪的问题,将原材料加工成所需大小的过程,称为原料下料问题。
按工艺要求,确定下料方案,使用料最省,或利润最大是典型的优化问题。
以此次钢管下料问题我们采用数学中的线性规划模型.对模型进行了合理的理论证明和推导,然后借助于解决线性规划的专业软件Lingo 对题目所提供的数据进行计算从而得出最优解。


目录实训项目一线性规划问题及lingo软件求解 (1)实训项目二lingo中集合的应用…………………………………………。
7实训项目三lingo中派生集合的应用 (9)实训项目四微分方程的数值解法一 (13)实训项目五微分方程的数值解法二……………………………………。
.15实训项目六数据点的插值与拟合 (17)综合实训作品 (18)每次实训课必须带上此本子,以便教师检查预习情况和记录实验原始数据。
实验时必须遵守实验规则.用正确的理论指导实践袁必须人人亲自动手实验,但反对盲目乱动,更不能无故损坏仪器设备。
这是一份重要的不可多得的自我学习资料袁它将记录着你在大学生涯中的学习和学习成果.请你保留下来,若干年后再翻阅仍将感到十分新鲜,记忆犹新.它将推动你在人生奋斗的道路上永往直前!项目一:线性规划问题及lingo软件求解一、实训课程名称数学建模实训二、实训项目名称线性规划问题及lingo软件求解三、实验目的和要求了解线性规划的基本知识,熟悉应用LINGO解决线性规划问题的一般方法四:实验内容和原理内容一:某医院负责人每日至少需要下列数量的护士班次时间最少护士数1 6:00—10:00 602 10:00—14:00 703 14:00—18:00 604 18:00—22:00 505 22:00—02:00 206 02:00—06:00 30每班的护士在值班的开始时向病房报道,连续工作8个小时,医院领导为满足每班所需要的护士数,最少需要多少护士。
内容二:内容三五:主要仪器及耗材计算机与Windows2000/XP系统;LINGO软件六:操作办法与实训步骤内容一:考虑班次的时间安排,是从6时开始第一班,而第一班最少需要护士数为60,故x1>=60 ,又每班护士连续工作八个小时,以此类推,可以看出每个班次的护士可以为下一个班次工作四小时,据此可以建立如下线性规划模型:程序编程过程:min=x1+x2+x3+x4+x5+x6;x1〉=60;x1+x2〉=70;x2+x3>=60;x3+x4〉=50;x4+x5〉=20;x5+x6〉=30;编程结果:Global optimal solution found.Objective value:150.0000 Infeasibilities: 0。


一、实验目的1. 掌握数学建模的基本步骤,学会运用数学知识分析和解决实际问题。
2. 提高数学建模能力,培养创新思维和团队合作精神。
3. 熟练运用数学软件进行数据分析、建模和求解。
二、实验内容本次实验选取了以下三个题目进行建模:1. 题目一:某公司想用全行业的销售额作为自变量来预测公司的销售量,表中给出了1977—1981年公司的销售额和行业销售额的分季度数据(单位:百万元)。
2. 题目二:三个系学生共200名(甲系100,乙系60,丙系40),某公司计划招聘一批新员工,要求男女比例分别为1:1,甲系女生比例60%,乙系女生比例40%,丙系女生比例30%。
请为公司制定招聘计划。
3. 题目三:研究某市居民出行方式选择问题,收集了以下数据:居民年龄、收入、职业、出行距离、出行时间、出行频率等。
请建立模型分析居民出行方式选择的影响因素。
三、实验步骤1. 问题分析:对每个题目进行分析,明确问题背景、目标和所需求解的数学模型。
2. 模型假设:根据问题分析,对实际情况进行简化,提出合适的模型假设。
3. 模型构建:根据模型假设,选择合适的数学工具和方法,建立数学模型。
4. 模型求解:运用数学软件(如MATLAB、Python等)进行模型求解,得到结果。
5. 结果分析与解释:对求解结果进行分析,解释模型的有效性和局限性。
四、实验报告1. 题目一:线性回归模型(1)问题分析:利用线性回归模型预测公司销售量,分析行业销售额对销售量的影响。
(2)模型假设:假设公司销售量与行业销售额之间存在线性关系。
(3)模型构建:根据数据,建立线性回归模型y = β0 + β1x + ε,其中y为公司销售量,x为行业销售额,β0、β1为回归系数,ε为误差项。
(4)模型求解:运用MATLAB软件进行线性回归分析,得到回归系数β0、β1。
(5)结果分析与解释:根据模型结果,分析行业销售额对销售量的影响程度,并提出相应的建议。
2. 题目二:招聘计划模型(1)问题分析:根据男女比例要求,制定招聘计划,确保男女比例均衡。
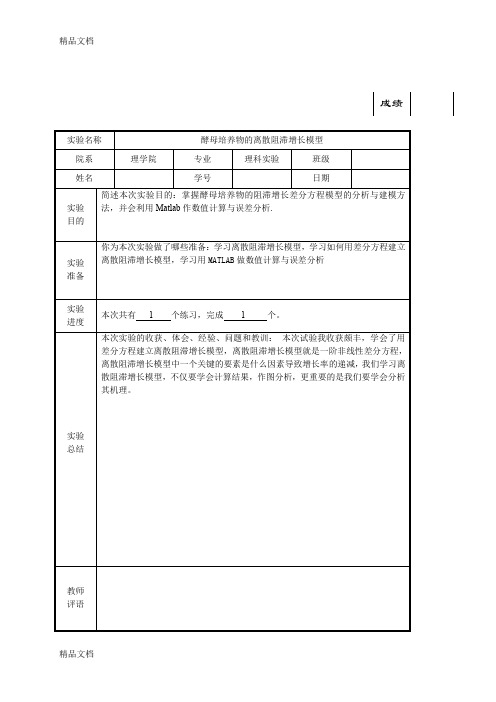
一.实验题目:已知从测量酵母培养物增长的实验收集的数据如表:时刻/h 0 1 2 3 4 5 6 7 8 9 生物量/g 513.3 559.7 594.8 629.4 640.8 651.1 655.9 659.6 661.8二.实验要求1、作图分析酵母培养物的增长数据、增长率、与相对增长率.2、建立酵母培养物的增长模型.3、利用线性拟合估计模型参数,并进行模型检验,展示模型拟合与预测效果图.4、利用非线性拟合估计模型参数,并进行模型检验,展示模型拟合与预测效果图.5、请分析两个模型的区别,作出模型的评价.三.实验内容(1)对于此问,可直接根据数据作图先求相对增长率随时间的变化,程序如下:k=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18];x=[9.6,18.3,29.0,47.2,71.1,119.1,174.6,257.3,350.7,441.0,513.3,559.7,594.8,629.4,640.8,651. 1,655.9,659.6,661.8];n=1;for n=1:18dx(n)=x(n+1)-x(n);endr=dx./x(1:18);plot(0:17,r,'kv')xlabel('时间k(小时)'),ylabel('增长率(%)')title('增长率与时间')模拟效果图如下:时间 k(小时)增长率 (%)增长率与时间再求增长量随时间的变化,程序如下:k=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18];x=[9.6,18.3,29.0,47.2,71.1,119.1,174.6,257.3,350.7,441.0,513.3,559.7,594.8,629.4,640.8,651.1,655.9,659.6,661.8]; n=1;for n=1:18dx(n)=x(n+1)-x(n); endplot(0:17,dx,'ko')xlabel('时间k (小时) '),ylabel('增长量 (克)')title('增长量与时间')模拟效果图如下:24681012141618时间 k(小时)增长量 (克)增长量与时间(2)建立酵母培养物的模型k---时刻(小时);x(k)---酵母培养物在第k 小时的生物量(克);r(k)---用前差公式计算的生物量在第k 小时的增长率; r---生物量的固有增长率;N---生物量的最大容量。

数学建模实验项⽬数学建模实验指导书数学建模实验项⽬⼀养⽼基⾦问题⼀、实验⽬的与意义:1、练习初等问题的建模过程;2、练习Matlab基本编程命令;⼆、实验要求:3、较能熟练应⽤Matlab基本命令和函数;4、注重问题分析与模型建⽴,了解建模⼩论⽂的写作过程;5、提⾼Matlab的编程应⽤技能。
三、实验学时数:2学时四、实验类别:综合性五、实验内容与步骤:(1.必做,2、3选⼀)1.某⼤学青年教师从31岁开始建⽴⾃⼰的养⽼基⾦,他把已有的积蓄10000元也⼀次性地存⼊,已知⽉利率为0.001(以复利计),每⽉存⼊700元,试问当他60岁退休时,他的退休基⾦有多少?⼜若,他退休后每⽉要从银⾏提取1000元,试问多少年后他的基⾦将⽤完?2.贷款助学问题。
3贷款购房问题。
⾃⼰调查设计具体情况数学建模实验项⽬⼆梯⼦问题⼀、实验⽬的与意义:1、进⼀步熟悉数学建模步骤;2、练习Matlab优化⼯具箱函数;3、进⼀步熟悉最优化模型的求解过程。
⼆、实验要求:1、较能熟练应⽤Matlab⼯具箱去求解常规的最优化模型;2、注重问题分析与模型建⽴,熟悉建模⼩论⽂的写作过程;3、提⾼Matlab的编程应⽤技能。
三、实验学时数:2学时四、实验类别:综合性五、实验内容与步骤:⼀幢楼房的后⾯是⼀个很⼤的花园。
在花园中紧靠着楼房建有⼀个温室,温室⾼10英尺,延伸进花园7英尺。
清洁⼯要打扫温室上⽅的楼房的窗户。
他只有借助于梯⼦,⼀头放在花园中,⼀头靠在楼房的墙上,攀援上去进⾏⼯作。
他只有⼀架20⽶长的梯⼦,你认为他能否成功?能满⾜要求的梯⼦的最⼩长度是多少?步骤:1.先进⾏问题分析,明确问题;2.建⽴模型,并运⽤Matlab函数求解;3.对结果进⾏分析说明;4.设计程序画出图形,对问题进⾏直观的分析和了解(主要⽤画线函数plot,line)5.写⼀篇建模⼩论⽂。
数学建模实验项⽬三确定肥猪的最佳销售时机⼀、实验⽬的与意义:1、认识微分法的建模过程;2、认识微分⽅程的数值解法。

数学实验报告实验序号:实验一日期:实验序号:实验二日期:实验序号: 实验三 日期:班级 姓名 学号实验 名称架设电缆的总费用问题背景描述:一条河宽1km ,两岸各有一个城镇A 与B ,A 与B 的直线距离为4km ,今需铺设一条电缆连接A 于B ,已知地下电缆的铺设费用是2万元/km ,水下电缆的修建费用是4万元/km 。
实验目的:通过建立适当的模型,算出如何铺设电缆可以使总花费最少。
数学模型:如图中所示,A-C-D-B 为铺设的电缆路线,我们就讨论a=30度,AE (A 到河岸的距离)=0.5km ,则图中:DG=4-AC cos b -1/tan c ; BG=0.5km AC=AE/sin bCD=EF/sin c=1/sin c BD=BG D 22G则有总的花费为:W=2*(AC+BD )+4*CD ;我们所要做的就是求最优解。
实验所用软件及版本:Matlab 7.10.0实验序号: 实验四 日期:班级 姓名 学号实验 名称慢跑者与狗问题背景描述:一个慢跑者在平面上沿曲线25y x 22=+以恒定的速度v 从(5,0)起逆时钟方向跑步,一直狗从原点一恒定的速度w ,跑向慢跑者,在运动的过程中狗的运动方向始终指向慢跑者。
实验目的:用matlab 编程讨论不同的v 和w 是的追逐过程。
数学模型:人的坐标为(manx,many ),狗的坐标为(dogx,dogy ),则时间t 时刻的人的坐标可以表示为manx=R*cos(v*t/R); many=R*sin(v*t/R);sin θ=| (many-dogy)/sqrt((manx-dogx)^2+(many-dogy)^2)|;cos θ=| (manx-dogx)/sqrt((manx-dogx)^2+(many-dogy)^2)|;则可知在t+dt 时刻狗的坐标可以表示为:dogx=dogx(+/-)w* cos θ*dt; dogy=dogy(+/-)w* sin θ*dt; (如果manx-dogx>0则为正号,反之则为负号)实验所用软件及版本:Matlab 7.10.0实验序号:实验五日期:班级姓名学号两圆的相对滚动实验名称问题背景描述:有一个小圆在大圆内沿着大圆的圆周无滑动的滚动。

《数学建模实验报告》Lingo软件的上机实践应用简单的线性规划与灵敏度分析学号:班级:姓名:日期:2010—7—21数学与计算科学学院一、实验目的:通过对数学建模课的学习,熟悉了matlab和lingo等数学软件的简单应用,了解了用lingo软件解线性规划的算法及灵敏性分析。
此次lingo上机实验又使我更好地理解了lingo程序的输入格式及其使用,增加了操作连贯性,初步掌握了lingo软件的基本用法,会使用lingo计算线性规划题,掌握类似题目的程序设计及数据分析。
二、实验题目(P55课后习题5):某工厂生产A、2A两种型号的产品都必须经过零件装配和检验两道工序,1如果每天可用于零件装配的工时只有100h,可用于检验的工时只有120h,各型号产品每件需占用各工序时数和可获得的利润如下表所示:(1)试写出此问题的数学模型,并求出最优化生产方案.(2)对产品A的利润进行灵敏度分析1(3)对装配工序的工时进行灵敏度分析(4)如果工厂试制了A型产品,每件3A产品需装配工时4h,检验工时2h,可获3利润5元,那么该产品是否应投入生产?三、题目分析:总体分析:要解答此题,就要运用已知条件编写出一个线性规划的Lingo 程序,对运行结果进行分析得到所要数据;当然第四问也可另编程序解答.四、 实验过程:(1)符号说明设生产1x 件1A 产品,生产2x 件2A 产品.(2)建立模型目标函数:maxz=61x +42x 约束条件:1) 装配时间:21x +32x <=100 2) 检验时间:41x +22x <=120 3) 非负约束:1x ,2x >=0所以模型为: maxz=61x +42xs.t 。
⎪⎩⎪⎨⎧>=<=+<=+0,1202410032212121x x x x x x(3)模型求解:1)程序model:title 零件生产计划; max=6*x1+4*x2; 2*x1+3*x2<=100; 4*x1+2*x2<=120; end附程序图1:2)计算结果Global optimal solution found。

实验四:Matlab 神经网络以及应用于汽油辛烷值预测专业年级: 2014级信息与计算科学1班姓名: 黄志锐 学号:201430120110一、实验目的1. 掌握MATLAB 创建BP 神经网络并应用于拟合非线性函数2. 掌握MATLAB 创建REF 神经网络并应用于拟合非线性函数3. 掌握MATLAB 创建BP 神经网络和REF 神经网络解决实际问题4. 了解MATLAB 神经网络并行运算二、实验内容1. 建立BP 神经网络拟合非线性函数2212y x x =+第一步 数据选择和归一化根据非线性函数方程随机得到该函数的2000组数据,将数据存贮在data.mat 文件中(下载后拷贝到Matlab 当前目录),其中input 是函数输入数据,output 是函数输出数据。
从输入输出数据中随机选取1900中数据作为网络训练数据,100组作为网络测试数据,并对数据进行归一化处理。
第二步 建立和训练BP 神经网络构建BP 神经网络,用训练数据训练,使网络对非线性函数输出具有预测能力。
第三步 BP 神经网络预测用训练好的BP 神经网络预测非线性函数输出。
第四步 结果分析通过BP 神经网络预测输出和期望输出分析BP 神经网络的拟合能力。
详细MATLAB代码如下:27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54disp(['神经网络的训练时间为', num2str(t1), '秒']);%% BP网络预测% 预测数据归一化inputn_test = mapminmax('apply', input_test, inputps); % 网络预测输出an = sim(net, inputn_test);% 网络输出反归一化BPoutput = mapminmax('reverse', an, outputps);%% 结果分析figure(1);plot(BPoutput, ':og');hold on;plot(output_test, '-*');legend('预测输出', '期望输出');title('BP网络预测输出', 'fontsize', 12);ylabel('函数输出', 'fontsize', 12);xlabel('样本', 'fontsize', 12);% 预测误差error = BPoutput-output_test;figure(2);plot(error, '-*');title('BP神经网络预测误差', 'fontsize', 12);ylabel('误差', 'fontsize', 12);xlabel('样本', 'fontsize', 12);figure(3);plot((output_test-BPoutput)./BPoutput, '-*');title('BP神经网络预测误差百分比');errorsum = sum(abs(error));MATLAB代码运行结果截图如下所示:MATLAB代码运行结果如下所示:图1 BP神经网络预测输出图示图2 BP神经网络预测误差图示图3 BP 神经网络预测误差百分比图示2. 建立RBF 神经网络拟合非线性函数22112220+10cos(2)10cos(2)y x x x x ππ=-+-第一步 建立exact RBF 神经网络拟合, 观察拟合效果详细MATLAB 代码如下:MATLAB代码运行结果如下所示:图4 RBF神经网络拟合效果图第二步建立approximate RBF神经网络拟合详细MATLAB代码如下:13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41F = 20+x1.^2-10*cos(2*pi*x1)+x2.^2-10*cos(2*pi*x2); %% 建立RBF神经网络% 采用approximate RBF神经网络。
实验四 混合整数规划一、问题重述某开放式基金现有总额为15亿元的资金可用于投资,目前共有8个项目可供投资者选择,每个项目可重复投资。
根据专家经验,对每个项目投资总额不能太高,应有上限。
这些项目所需要的投资额已知,一般情况下投资一年后各项目所得利润也可估算出来,如表1所示。
请帮该公司解决以下问题:(1) 就表1提供的数据,应该投资哪些项目,使得第一年所得利润最高?(2) 在具体投资这些项目时,实际还会出现项目之间互相影响的情况。
公司咨询有关专家后,得到以下可靠信息:同时投资项目A 1,A 3,它们的年利润分别是1005万元,1018.5万元;同时投资项目A 4,A 5,它们的年利润分别是1045万元,1276万元;同时投资项目A 2,A 6,A 7,A 8,它们的年利润分别是1353万元,840万元,1610万元,1350万元,该基金应如何投资? 其中M 为你的学号后3位乘以10。
(3) 如果考虑投资风险,则应如何投资,使收益尽可能大,而风险尽可能小。
投资项目总体风险可用投资项目中最大的一个风险来衡量。
专家预测出各项目的风险率,如表2所示。
二、符号说明i A ::投资额;i b :i A 个项目所获得的年利润;i C :第i A 个项目投资所获得的利润; 'i C :第i A 个项目同时投资所获得的利润;i m :投资i A 的上限; i y :表示0—1变量;i p :投资第i A 个项目的投资风险;三、模型的建立 对于问题一目标函数:81max i i i c x ==∑s.t. 150000i i i i i ib x b x m ⎧≤⎪⎨⎪≤⎩∑对于问题二 设定0—1变量131130...,1...,A A y A A ⎧⎨⎩项目不同时投资项目同时投资 452450...,1...,A A y A A ⎧⎨⎩项目不同时投资项目同时投资 2678326780...,,1...,,A A A A y A A A A ⎧⎨⎩,项目不同时投资,项目同时投资 目标函数:''''11133111332445524455''''322667788322667788max ()(1)()()(1)()()(1)()y x c x c y x c x c y x c x c y x c x c y x c x c x c x c y x c x c x c x c =++-++++-++++++-+++s.t. 11313124545232678267831500001000i i i i i ib x k y x xx x y ky x x x x y k y x x x x x x x x y kb x m ⎧≤⎪⎪=⎪⎪≤⎪⎪≥⎪⎪≤⎨⎪⎪≥⎪⎪≤⎪⎪≥⎪⎪≤⎩∑对于问题三:目标函数:max min max()i iii i i c x b x p =∑s.t. 150000i i i i i ib x b x m ⎧≤⎪⎨⎪≤⎩∑对于问题三模型的简化固定投资风险,优化收益,设a 为固定的最大风险。

数学建模实验报告数据的统计分析一、引言数学建模是一种多学科交叉领域,广泛应用于自然科学、工程技术、经济管理等领域。
在数学建模的过程中,对实验数据的统计分析是非常重要的一步。
本文将针对数学建模实验报告中的数据,进行统计分析,以探索数据特征和相关关系。
二、方法在本次实验中,我们采集了相关数据,包括自变量和因变量。
为了对数据进行统计分析,我们首先使用了统计软件进行数据清洗和预处理,包括去除异常值、缺失值处理等。
然后,我们利用统计学的方法对数据进行描述性统计和推断性统计,以获取数据的各种特征和潜在规律。
三、描述性统计分析描述性统计分析是对数据的基本特征进行描述和总结的方法。
我们首先计算了数据的平均值、中位数、方差和标准差,以揭示数据的集中趋势和离散程度。
接着,我们绘制了数据的频率分布图和直方图,以展现数据的分布情况和形态特征。
此外,我们还计算了数据的偏度和峰度,用以描述数据分布的非对称性和尖峭程度。
四、推断性统计分析推断性统计分析是利用样本数据对总体进行推断的方法。
在本次实验中,我们使用了参数估计和假设检验两种常见的推断性统计方法。
首先,我们使用最大似然估计法对数据的参数进行估计,包括均值、方差等。
然后,我们进行了假设检验,以验证研究假设是否成立。
在假设检验中,我们使用了t检验、F检验等常见的统计检验方法,对样本数据和假设进行比较,判断其差异的显著性。
五、结果与讨论通过描述性统计和推断性统计分析,我们得出了以下结论:1. 数据的平均值为X,标准差为X,表明数据整体上呈现X特征。
2. 数据的分布图显示,数据大致呈正态分布/偏态分布/离散分布等。
实验4实验报告2013326601054 夏海浜13信科1班完成教材(2013高教版)实验;P136 T2程序:clearP1=binopdf(45,100,0.5)p=binopdf(44,100,0.5);P2=P1-px=0:100;P3=binocdf(x,100,0.5);P4=binopdf(x,100,0.5);subplot(2,1,1)plot(x,P4,'*')title('概率累积')subplot(2,1,2)plot(x,P4,'+')title('概率密度')图:运行结果:P1 =0.0485P2 =0.0095P140 T1程序:例1:clear;clc;x=[0.236,0.257,0.258;0.238,0.253,0.264;0.248,0.255,0.259;0.245,0.254,0.267;0.243,0.261,0.262]; group=[1,1,1,1,1];p=anova1(x)图:p =1.3431e-05例2:clear;clc;x=[58.2,56.2,65.3;52.6,41.2,60.8;49.1,54.1,51.6;42.8,50.5,48.4;60.1,70.9,39.2;58.3,73.2,40.7;75.8,58.2,48.7;71.5,51.0,41.4];p=anova2(x,2)p =0.0035 0.0260 0.0001P145 T1程序:x1=[3.5 5.3 5.1 4.2 6.0 6.8 5.5 3.1 7.2 4.5 8.0 6.5 6.5 3.7 6.2 7.0 4.5 5.9 5.6 4.8 3.9];x2=[9 20 18 31 13 25 30 5 47 25 23 35 39 21 7 40 23 33 27 34 15];x3=[6.1 6.4 7.4 7.5 5.9 6.0 4.0 5.8 8.3 5.0 7.6 7.0 5.0 4.0 5.5 7.0 3.5 4.9 4.3 8.0 5.8];Y=[11.1 13.4 12.9 13.8 12.5 13.0 13.6 10.0 17.6 12.7 14.4 14.7 14.2 11.2 11.4 16.0 12.0 13.5 12.3 15.1 11.7]';subplot(1,3,1),plot(x1,Y,'*'),title('Y与x1的散点图')subplot(1,3,2),plot(x2,Y,'+'),title('Y与x2的散点图')subplot(1,3,3),plot(x3,Y,'o'),title('Y与x3的散点图')散点图:b =6.29140.29540.10720.4450bint =5.2994 7.2833 0.1237 0.4671 0.0872 0.1271 0.3002 0.5899r =0.09530.5511-0.1205-0.39250.4171-0.64990.6883-0.32430.45040.1746-0.1020-0.3781-0.4168-0.21530.07920.23830.3565-0.2519-0.45320.18620.0676rint =-0.6858 0.8765 -0.2443 1.3466 -0.9294 0.6884 -1.1196 0.3345 -0.3511 1.1853 -1.3958 0.0961 -0.0162 1.3929 -1.0566 0.4081 -0.2333 1.1340 -0.6539 1.0030 -0.8039 0.5998 -1.1820 0.4257 -1.1745 0.3410 -0.9924 0.5617-0.6452 0.8035-0.5556 1.0321-0.3988 1.1118-1.0618 0.5579-1.2317 0.3253-0.5599 0.9322-0.7530 0.8882stats =0.9564 124.4453 0.0000 0.1624从两种残差图都可以看到残差的大部分分布在零的附近,因此还是比较好的,去掉4,12,19这三个样本点后残差更加接近原点,重新拟合得到回归模型为3210.4450x 0.1072x 0.2954x 6.2914y +++=且回归系数的置信区间更小,均不包括原点,统计变量stats 包含的三个检验统计量:相关系数的平方R 方,假设检验统计量F ,概率P 分别为0.9564,124.4453,0.000 0,比较可知R ,F 均增加,说明模型得到改进。
P149 T2程序:A=[3.5,5.3,5.1,5.8,4.2,6.0,6.8,5.5,3.1,7.2,4.5,4.9,8.0,6.5,6.5,3.7,6.2,7.0,4.0,4.5,5.9,5.6,4.8,3.9;9,20,18,33,31,13,25,30,5,47,25,11,23,35,39,21,7,40,35,23,33,27,34,15;6.1,6.4,7.4,6.7,7.5,5.9,6.0,4.0,5.8,8.3,5.0,6.4,7.6,7.0,5.0,4.0,5.5,7.0,6.0,3.5,4.9,4.3,8.0,5.8]';Y=[11.1 13.4 12.9 15.6 13.8 12.5 13.0 13.6 10.0 17.6 12.7 10.6 14.4 14.7 14.2 11.2 11.4 16.0 12.7 12.0 13.5 12.3 15.1 11.7]';x1=A(:,1);x2=A(:,2);x3=A(:,3);x4=x1.*x2;x5=x1.*x3;x6=x2.*x3;X=[A,x4,x5,x6];stepwise(X,Y)图:T3程序:x1=[1.376,1.375,1.387,1.401,1.412,1.428,1.445,1.477]'x2=[0.450,0.475,0.485,0.500,0.535,0.545,0.550,0.575]'x3=[2.170,2.554,2.676,2.713,2.823,3.088,3.122,3.262]'x4=[0.8922,1.1610,0.5346,0.9589,1.0239,1.0499,1.1065,1.1387]' x=[x1,x2,x3,x4]R=corrcoef(x)[V,D]=eig(R)运行结果:x1 =1.37601.37501.38701.40101.4120 1.4280 1.4450 1.4770x2 =0.4500 0.4750 0.4850 0.5000 0.5350 0.5450 0.5500 0.5750x3 =2.1700 2.5540 2.6760 2.71302.82303.0880 3.1220 3.2620x4 =0.89221.1610 0.53460.95891.0239 1.0499 1.1065 1.1387x =1.3760 0.45002.1700 0.8922 1.3750 0.4750 2.5540 1.1610 1.3870 0.4850 2.6760 0.5346 1.4010 0.5000 2.7130 0.9589 1.4120 0.5350 2.8230 1.0239 1.4280 0.54503.0880 1.0499 1.4450 0.5500 3.1220 1.1065 1.4770 0.5750 3.2620 1.1387R =1.0000 0.9483 0.9119 0.4613 0.9483 1.0000 0.9683 0.4747 0.9119 0.9683 1.0000 0.4036 0.4613 0.4747 0.4036 1.0000V =0.5407 0.1634 -0.7854 0.2531 0.5519 0.1660 0.1560 -0.8022 0.5380 0.2534 0.5968 0.5387 0.3369 -0.9389 0.0519 0.0477D =3.1626 0 0 00 0.7269 0 00 0 0.0882 00 0 0 0.0223P152 T1程序:x=[1 2 4 2;2 43 3;3 34 4;4 5 5 5]geom=geomean(x)harm=harmmean(x)meanX=mean(x)medianm=median(x)rangem=range(x)var1x=var(x,1)stdX=std(x)covX=cov(x)moment1=moment(x,1)moment2=moment(x,2)moment3=moment(x,3)moment4=moment(x,4)R=corrcoef(x)运行结果:x =1 2 4 22 43 33 34 44 5 5 5geom =2.21343.3098 3.9360 3.3098harm =1.9200 3.1169 3.8710 3.1169meanX =2.50003.50004.0000 3.5000medianm =2.50003.50004.0000 3.5000 rangem =3 3 2 3var1x =1.2500 1.2500 0.5000 1.2500 stdX =1.2910 1.2910 0.8165 1.2910 covX =1.6667 1.3333 0.6667 1.66671.3333 1.6667 0.3333 1.33330.6667 0.3333 0.6667 0.66671.6667 1.3333 0.6667 1.6667 moment1 =0 0 0 0moment2 =1.2500 1.2500 0.5000 1.2500 moment3 =0 0 0 0moment4 =2.5625 2.5625 0.5000 2.5625R =1.0000 0.8000 0.6325 1.00000.8000 1.0000 0.3162 0.80000.6325 0.3162 1.0000 0.63251.0000 0.8000 0.6325 1.0000T2X=[1 2 3 4 5 6 7 8 9 10]'*[10 9 8 7 6 5 4 3 2 1]geom=geomean(x)harm=harmmean(x)meanX=mean(x)medianm=median(x)rangem=range(x)var1x=var(x,1)stdX=std(x)covX=cov(x)moment1=moment(x,1)moment2=moment(x,2)moment3=moment(x,3)moment4=moment(x,4)R=corrcoef(x)X =10 9 8 7 6 5 4 3 2 120 18 16 14 12 10 8 6 4 230 27 24 21 18 15 12 9 6 340 36 32 28 24 20 16 12 8 450 45 40 35 30 25 20 15 10 560 54 48 42 36 30 24 18 12 670 63 56 49 42 35 28 21 14 780 72 64 56 48 40 32 24 16 890 81 72 63 54 45 36 27 18 9100 90 80 70 60 50 40 30 20 10 geom =2.21343.3098 3.9360 3.3098harm =1.9200 3.1169 3.8710 3.1169meanX =2.50003.50004.0000 3.5000medianm =2.50003.50004.0000 3.5000rangem =3 3 2 3var1x =1.2500 1.2500 0.5000 1.2500stdX =1.2910 1.2910 0.8165 1.2910covX =1.6667 1.3333 0.6667 1.66671.3333 1.6667 0.3333 1.33330.6667 0.3333 0.6667 0.66671.6667 1.3333 0.6667 1.6667moment1 =0 0 0 0moment2 =1.2500 1.2500 0.5000 1.2500moment3 =0 0 0 0moment4 =2.5625 2.5625 0.5000 2.5625R =1.0000 0.8000 0.6325 1.00000.8000 1.0000 0.3162 0.80000.6325 0.3162 1.0000 0.63251.0000 0.8000 0.6325 1.0000P153 T3m=magic(5)m([1 7 13 19 25])=[NaN NaN NaN NaN NaN] nan=nansum(m)min=nansum(m)max=nanmax(m)median=nanmedian(m)std=nanstd(m)运行结果:m =17 24 1 8 1523 5 7 14 164 6 13 20 2210 12 19 21 311 18 25 2 9m =NaN 24 1 8 1523 NaN 7 14 164 6 NaN 20 2210 12 19 NaN 311 18 25 2 NaNnan =48 60 52 44 56min =48 60 52 44 56max =23 24 25 20 22median =10.5000 15.0000 13.0000 11.0000 15.5000std =7.9582 7.7460 10.9545 7.7460 7.9582P179 T1 and T2先建立俩个函数于.m文件中:function y=xbar(x)n=length(x);y=sum(x);y=y./n;function y=sigma2(x)Y=x-xbar(x);Y2=Y.*Y;n=length(x);y=sum(Y2);y=y./n;T1>> x=[2.3,4.0,5.4,3.4,4.3,3.4,2.8,4.5,4.3,4.2,3.8,3.7,3.2,3.6,3.5,3.4];>> mu=xbar(x)运行结果:mu =3.7375T2>> x=[3.2,3.3,3.4,3.6,3.7,3.8,4.1,4.0,4.2,3.9,3.1,3.0,3.3,3.2,3.2];>> mu=xbar(x)mu =3.5333运行结果:>> sig=sigma2(x)sig =0.1436。