杭电数据结构教案第八章
- 格式:ppt
- 大小:843.50 KB
- 文档页数:151

安徽大学本科教学课程教案
课程代码:ZJ36021
课程名称:数据结构
授课专业:计算机科学与技术
授课教师:邹海
职称/学位:副教授/ 博士
开课时间:二○一六至二○一七学年第二学期
第4次课程教学方案
第5次教学活动设计
第6次课程教学方案
第6次教学活动设计
第7次课程教学方案
算法也可以求得有向图G=(V,E)中每一对顶点间的最短路径。
方法是:每次以一个不同的顶点为源点重复Dijkstra算法便可求得每一对顶点间的最短路径,时间复杂度是
(Floyd)提出了另一个算法,其时间复杂度仍是O(n3) ,但算法形式更为简明,步骤更
第7次教学活动设计
课程教案审核情况。

数据结构第8章在数据结构的学习旅程中,第8 章往往会带来一些新的概念和挑战。
这一章通常会深入探讨一些复杂但实用的数据结构,为我们解决实际问题提供更多有力的工具。
让我们先来谈谈第 8 章可能会涉及到的一种重要数据结构——树。
树是一种分层的数据结构,它就像一棵倒立的树,有一个根节点,然后从根节点向下延伸出许多分支,每个分支又可以继续延伸出子分支。
树的结构使得数据的存储和检索变得更加高效。
比如二叉树,它的每个节点最多只有两个子节点,左子节点和右子节点。
通过合理的构建和遍历算法,我们可以快速地查找、插入和删除节点中的数据。
在实际应用中,树结构有着广泛的用途。
比如文件系统的目录结构就是一种树状结构。
从根目录开始,一级一级地向下展开,每个文件夹都可以看作是树的一个节点。
还有决策树,在机器学习和数据分析中经常被用到。
它通过一系列的条件判断,将数据逐步分类,帮助我们做出决策。
除了树,第 8 章可能还会讲到图。
图是一种更加复杂但强大的数据结构,它由顶点和边组成。
顶点表示对象,边表示顶点之间的关系。
图可以分为有向图和无向图。
有向图中的边是有方向的,而无向图中的边没有方向。
图的应用场景也非常丰富。
比如社交网络,每个人可以看作是一个顶点,人与人之间的关系就是边。
通过分析图的结构,我们可以了解社交网络中的信息传播、社区结构等。
在交通网络中,城市是顶点,道路是边,利用图算法可以找到最优的路径规划。
另外,第 8 章可能还会涉及到一些针对树和图的算法。
比如树的遍历算法,常见的有前序遍历、中序遍历和后序遍历。
这些遍历算法可以帮助我们按照特定的顺序访问树中的节点,从而实现对树中数据的处理。
对于图,最短路径算法是非常重要的,比如迪杰斯特拉算法和弗洛伊德算法,它们可以帮助我们在图中找到两个顶点之间的最短路径。
在学习第 8 章的过程中,可能会遇到一些困难。
因为这些数据结构和算法相对复杂,需要我们有较强的逻辑思维和抽象能力。
但是,只要我们坚持不懈,多做练习,通过实际的编程实现来加深对这些概念的理解,就一定能够掌握。


课程名称:数据结构授课教师:[教师姓名]授课班级:[班级名称]授课时间:[具体日期]学时安排:16学时教学目标:1. 理解数据结构的基本概念,掌握数据结构在计算机科学中的重要性。
2. 掌握常用数据结构的逻辑结构、存储结构及其操作实现。
3. 能够分析算法的时间复杂度和空间复杂度。
4. 能够运用所学知识解决实际问题,具备一定的编程能力。
教学内容:1. 绪论2. 线性表3. 栈和队列4. 串和数组5. 树与图6. 查找算法7. 排序算法教学大纲:一、绪论1. 数据结构的概念和作用2. 数据结构的分类3. 数据结构的学习方法和步骤二、线性表1. 线性表的定义和特点2. 线性表的顺序存储和链式存储3. 线性表的基本操作:插入、删除、查找、排序等三、栈和队列1. 栈的定义和特点2. 栈的顺序存储和链式存储3. 栈的基本操作:入栈、出栈、判空、清栈等4. 队列的定义和特点5. 队列的顺序存储和链式存储6. 队列的基本操作:入队、出队、判空、清队等四、串和数组1. 串的定义和特点2. 串的顺序存储和链式存储3. 串的基本操作:连接、查找、替换、提取等4. 数组的定义和特点5. 数组的顺序存储和链式存储6. 数组的基本操作:插入、删除、查找、排序等五、树与图1. 树的定义和特点2. 树的顺序存储和链式存储3. 树的基本操作:遍历、查找、插入、删除等4. 图的定义和特点5. 图的邻接矩阵存储和邻接表存储6. 图的基本操作:深度优先遍历、广度优先遍历、最短路径查找等六、查找算法1. 二分查找法2. 分块查找法3. 哈希查找法七、排序算法1. 冒泡排序2. 选择排序3. 插入排序4. 快速排序5. 归并排序6. 堆排序教学方法与手段:1. 讲授法:讲解数据结构的基本概念、原理和操作方法。
2. 案例分析法:通过实际案例讲解数据结构的应用。
3. 编程实践:让学生动手实现数据结构的相关操作。
4. 课堂讨论:鼓励学生积极思考,提出问题并共同探讨。

杭电数据结构课程设计一、课程目标知识目标:1. 学生能理解数据结构的基本概念,掌握线性表、栈、队列、树、图等常见数据结构的特点与应用。
2. 学生能描述各类数据结构的存储方式和操作方法,了解其时间复杂度和空间复杂度。
3. 学生能运用所学的数据结构知识解决实际问题,如排序、查找、最短路径等。
技能目标:1. 学生能运用编程语言(如C++、Java等)实现常见数据结构及其相关算法。
2. 学生能分析实际问题的数据特征,选择合适的数据结构进行问题求解。
3. 学生能通过课程项目实践,培养团队协作、沟通表达、问题解决等综合能力。
情感态度价值观目标:1. 学生对数据结构产生兴趣,认识到数据结构在计算机科学与软件开发中的重要性。
2. 学生在解决实际问题的过程中,培养积极探究、勇于创新的精神。
3. 学生通过团队协作,学会尊重他人、分享经验,提高沟通能力。
课程性质:本课程为计算机科学与技术专业的核心课程,旨在培养学生掌握数据结构的基本知识、技能和素养。
学生特点:学生具备一定的编程基础和数学素养,具有较强的逻辑思维能力,但对数据结构的应用和实际操作能力有待提高。
教学要求:结合课程性质和学生特点,注重理论与实践相结合,强调动手实践和实际应用,提高学生的数据结构知识水平和问题解决能力。
通过课程目标分解,将知识、技能和情感态度价值观目标融入教学过程,为后续教学设计和评估提供依据。
二、教学内容1. 线性表:介绍线性表的定义、特点、存储结构(顺序存储、链式存储),以及线性表的相关操作(插入、删除、查找等)。
教材章节:第2章 线性表2. 栈与队列:讲解栈和队列的基本概念、存储结构及操作方法,分析其应用场景。
教材章节:第3章 栈与队列3. 树与二叉树:阐述树的基本概念、存储结构、遍历方法,重点讲解二叉树的性质、存储结构、遍历算法(前序、中序、后序)及二叉树的应用。
教材章节:第4章 树与二叉树4. 图:介绍图的定义、存储结构(邻接矩阵、邻接表),图的遍历算法(深度优先搜索、广度优先搜索),以及最短路径、最小生成树等算法。

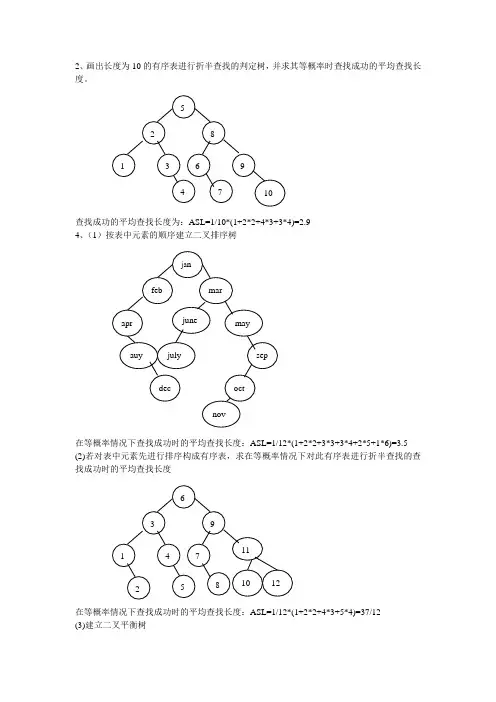
2、画出长度为10的有序表进行折半查找的判定树,并求其等概率时查找成功的平均查找长度。
查找成功的平均查找长度为:ASL=1/10*(1+2*2+4*3+3*4)=2.94、(1)按表中元素的顺序建立二叉排序树在等概率情况下查找成功时的平均查找长度:ASL=1/12*(1+2*2+3*3+3*4+2*5+1*6)=3.5 (2)若对表中元素先进行排序构成有序表,求在等概率情况下对此有序表进行折半查找的查找成功时的平均查找长度在等概率情况下查找成功时的平均查找长度:ASL=1/12*(1+2*2+4*3+5*4)=37/12(3)建立二叉平衡树(虚线部分为不平衡部分)=LR 型==RL 型==RR 型=5、n=144b=n/s=144/12=12 (分成12块最好,每块的最佳长度为12)s=8 b=n/s=144/8=18若确定块的查找为顺序查找:ASL=(b+1)/2+(s+1)/2=14若确定块的查找为折半查找:ASL=1/18*(1+2*2+4*3+8*4+3*5)+(s+1)/2=32/9+9/2=8.061、 设散列表长度为9,哈系函数为H(x)=i div 3(i 为键值x 中第一个字母在字母表中的序号) H(Jan)=10 div 3=3 H(Feb)=6 div 3=2 H(Mar)=13 div 3=4 H(Apr)=1 div 3=0 H(May)=13 div 3=4 H(Jun)=10 div 3=3 H(Jul)=10 div 3=3 H(Aug)=1div 3=0 H(Sep)=19div 3=6 H(Oct)=15 div 3=5 H(Nov)=14 div 3=4 H(Dec)=4 div 3=10 1 2 3 4 5 6 7 8 12144===n s等概率时查找成功的平均查找长度:ASL=1/12*(1+2+1+1+1+2+3+1+2+3+1+1)=19/12 等概率时查找不成功的平均查找长度:ASL=1/9*(2+1+1+3+3+1+1+0+0)=4/36、哈希函数为H(k)=(3k)MOD 11用开放定址法处理冲突:d1=H(k) ; d i= (d i-1+(7k)MOD10+1) MOD11在0-10的散列地址空间中对关键字序列(22,41,53,46,30,13,01,67)构造哈希表0 1 2 3 4 5 6 7 8 9 10H(22)=(3*22)MOD 11=0H(41)=(3*41)MOD 11=2H(53)=(3*53)MOD 11=5H(46)=(3*46)MOD 11=6H(30)=(3*30)MOD 11=2 冲突H2=(2+d1)MOD 11=(2+2) MOD 11=4H(13)=(3*13)MOD 11=6 冲突H2=(6+d1)MOD 11=(6+6) MOD 11=1H(01)=(3*01)MOD 11=3H(67)=(3*67)MOD 11=3 冲突d1=3H2= (3+d1)MOD 11=(3+3) MOD 11=6冲突d2= (3+(7*67)MOD10+1) MOD11=2H3=(3+d2) MOD 11=(3+2) MOD11=5冲突d3= (2+(7*67)MOD10+1) MOD11=1H4=(3+d3) MOD 11=(3+1) MOD11=4 冲突d4= (1+(7*67)MOD10+1) MOD11=0H5=(3+d4) MOD 11=(3+0) MOD11=3 冲突d5= (0+(7*67)MOD10+1) MOD11=10H6=(3+d5) MOD 11=(3+10) MOD11=2 冲突d6= (10+(7*67)MOD10+1) MOD11=9H7=(3+d6) MOD 11=(3+9) MOD11=1 冲突d7= (9+(7*67)MOD10+1) MOD11=8H8=(3+d7) MOD 11=(3+8) MOD11=0 冲突d8= (8+(7*67)MOD10+1) MOD11=7H9=(3+d8) MOD 11=(3+7) MOD11=10等概率时查找成功的平均查找长度:ASL=1/8*(1*5+2*2+9)=9/4=2.25等概率时查找不成功的平均查找长度:ASL=11/3。

8.9.10. A)ACFKDBG C)KCFAGDBB)GDBFKCA D)ABCDFKG欲得到二叉搜索树(BST)各结点值的递增序列,试问应该采用何种遍历方法(A)先序遍历C)后序遍历B)中序遍历D)层次遍历与数据元素本身的形式、内容、相对位置、个数无关的是数据的(A)存储结构C)逻辑结构B)存储形式D)运算实现有一棵非空的二叉树(第0层为根结点),其第i层上至多有(Ai1)个节点《软件技术基础》之数据结构习题)选择题1. 下面关于线性表的叙述中,正确的是(D )A)线性表的每个元素都有一个直接前驱和直接后继B)线性表中至少要有一个元素C)线性表中的元素必须按递增或递减的顺序排列D)除第一个元素和最后一个元素外,其余每个元素有且仅有一个直接前驱和直接后继2. 下面关于线性表的叙述中,错误的是(B )A)采用顺序存储的线性表必须占用一片连续的存储单元B)采用顺序存储的线性表便于进行插入和删除操作C)采用链接存储的线性表,不必占用一片连续的存储单元D)采用链接存储的线性表,便于进行插入和删除操作3. 设有栈S和队列Q,初始状态皆为空,元素a i、a?、a3、a4、a5、a6依次入栈,出栈的元素依次进入队列Q,若6个元素的出栈序列为:a2、a4、出、比、氏、a i,则栈的容量至少是(C )A) 6 C) 3B) 4 D) 24. 设在栈中,由顶向下已存放元素c、b、a,在第4个元素d入栈前,栈中元素可以出栈,试问d入栈后,不可能的出栈序列是( C )A) d c b a C) c a d bB) c b d a D) c d b a5. 在一棵二叉树的先序遍历、中序遍历、后序遍历序列中,所有叶节点的先后顺序(B)A)都不相同C)先序和中序相同,后序不同B)完全相同D)中序和后序相同,先序不同6. 设二叉树根结点的层次为0,—棵高度为h的满二叉树的结点个数是(C )A)2h C) 2h-1h-1 h+ 1 AB) 2 D) 2 -17. 已知一棵二叉树的前序序列为ABDGCFK,中序序列为DGBAFCK,则结点的后序序列为(B )11.双向链表结点结构如下:LLi nkData RL ink其中:LLink 是指向前趋结点的指针域,Data 是存放数据元素的数据域,RLink 是指向后继结点的指针域。

数据结构第八章在数据结构的世界里,每一章都像是一座知识的宝库,而第八章往往聚焦于一些特定且关键的数据结构和算法。
让我们首先来谈谈栈这种数据结构。
栈就像是一个只能从一端进出的“筒子”,遵循着后进先出的原则。
想象一下在食堂打饭,大家排队把餐盘叠放在一起,最后放上去的餐盘总是最先被拿走,这就是栈的基本运作方式。
在计算机程序中,栈有着广泛的应用。
比如函数调用时,系统会使用栈来保存函数的参数、局部变量等信息。
当一个函数执行完毕,它所占用的空间就会被释放,就像拿走最上面的餐盘一样。
队列则与栈相反,它是先进先出的。
就好比在银行排队办理业务,先来的人先得到服务。
队列在很多场景中都发挥着重要作用,比如操作系统中的任务调度、网络中的数据包传输等。
第八章可能还会涉及到树这种数据结构。
二叉树是其中非常重要的一种,它的每个节点最多有两个子节点。
二叉搜索树更是有着独特的性质,左子树的所有节点值都小于根节点的值,右子树的所有节点值都大于根节点的值。
这使得在二叉搜索树中查找、插入和删除节点的操作都能高效进行。
此外,图也是一个重要的内容。
图可以用来表示各种关系,比如城市之间的道路连接、人际关系网络等。
图的遍历算法,如深度优先遍历和广度优先遍历,是理解和处理图数据的基础。
在算法方面,第八章或许会介绍一些排序算法的优化和应用。
比如快速排序的改进版本,或者归并排序在处理大规模数据时的技巧。
另外,哈希表也是常见的内容之一。
哈希表通过哈希函数将键映射到特定的位置,从而实现快速的查找和插入操作。
但哈希冲突的处理是哈希表需要重点关注的问题。
在实际应用中,理解和掌握这些数据结构和算法是至关重要的。
比如在开发一个电商网站的购物车功能时,可能会用到栈来记录用户添加和删除商品的操作顺序;在实现一个消息队列系统时,队列就是核心的数据结构。
对于学习数据结构的我们来说,第八章的知识不仅是理论上的积累,更是实践中的工具。
通过不断地练习和应用,我们才能真正掌握这些知识,并且能够在面对实际问题时,灵活地选择和运用合适的数据结构和算法来解决问题。

![杭电-[数据结构(c语言版)]](https://uimg.taocdn.com/5ed46a25f01dc281e53af087.webp)
杭电-[数据结构(c语言版)](附:期末复习题及期末样卷)第一章绪论一.基本概念和术语数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科。
术语:数据、数据元素、数据对象、数据结构、抽象数据类型、算法。
数据结构的形式定义(二元组)数据的逻辑结构:线性结构非线性结构数据的存储结构(物理结构):主要有顺序存储结构链式存储结构抽象数据类型(三元组)算法(5个重要特性)二.算法的时间复杂度和空间复杂度算法的评价:正确性、可读性、健壮性、高效率、低存储量第二章线性表一.线性表的定义线性结构的特点二.线性表的存储结构1.顺序存储结构(顺序表)插入/删除元素时,需移动元素2.链式存储结构(链表,分为单向链表、双向链表)带头结点的链表和不带头结点的链表;循环链表;链表空与非空的情况。
3.两种存储结构的优缺点比较,各适合那些场合。
三.线性表操作的实现(算法描述)插入元素、删除元素、查找、判表是否满足某种特性例:判断题:1. 线性表的逻辑顺序与存储顺序总是一致的。
F2. 线性结构的基本特征是:每个结点有且仅有一个直接前驱和一个直接后继。
F3. 线性表的链式存储结构优于顺序存储结构。
F选择题:线性表L在( B )情况下适于使用链表结构实现。
A. 不需修改L的结构B. 需不断对L进行删除、插入C. 需经常修改L中结点值D. L中含有大量结点填空题:1. 对于顺序表中,在第i个元素前插入一个元素需移动n-i+1 个元素,要删除第i个元素,需移动n-i 个元素。
2. 在双向循环链表中某结点(由指针p指示)之后插入s指针所指结点的操作是:;;;;。
第三章栈和队列一.栈1.栈的定义2.栈的存储结构:顺序存储结构链式存储结构3.栈的应用:二叉树的先序、中序、后序遍历算法图的深度优先遍历算法(将递归算法改写为非递归算法可借助栈来完成;递归算法的执行需用栈来实现)二.队列1.队列的定义2.队列的存储结构:顺序存储结构(循环队列),链式存储结构3.队列的应用:二叉树层序遍历图的广度优先遍历算法4.循环队列:·队空、队满的判断条件·求队列的长度·循环队列通常用front和rear来指示队头和队尾的位置来表示一个队列;如果用front指示队头,用length表示队列的长度,也可以表示一个队列。