基于CANOCO的生态学数据的多元统计分析
- 格式:pdf
- 大小:2.92 MB
- 文档页数:56

12 案例分析2:对群落构成特征以及所处环境相关性的探索——泉水草地的植被覆盖状况在这个案例中,我们将会展示多元分析中一种常见的应用:对一组包含环境参数的植被样本进行分析,寻找其中的规律。
这里的物种数据为喀尔巴阡山脉最西端山泉沼泽草地的典型植被样方(记录了所有的维管植物和苔藓植物,并用Braun–Blanquet等级估计法估测了植物的多度)。
数据已经用Braun–Blanquet等级估计进行转换,用1~7的数值*来表示r、+、1~5.样方中还包含了环境数据——泉水的化学性质、土壤有机碳含量和样点的坡度。
其中铁离子浓度数据使用摩尔浓度来表示的:这样一来,环境参数就都通过CANOCO标准化的处理,所以它们单位的选择没有对结果造成影响(不同的单位直接没有线性相关关系)†。
Michal Ha′jek无私地提供了这些数据,他们的研究分析已经发表,可以参考Ha′jek et al. (2002).这个案例分析的目标在于描述植被的基本特征以及与相关环境条件的联系,特别是泉水的化学性质之间的相关性。
这些数据都保存在文件meadow.xls中,一个工作表包含了物种数据,另一个工作表包含了环境参数(已在原数据基础上进行了简化)。
数据用WCanoImp程序转换为可导入CANOCO 的格式,最后生成meadows.spe和meadow.env两个文件。
我们注意到在Excel文件中,物种数据是颠倒的(物种名作为行,样方作为列)。
这在宏观尺度的调查中是常见的,因为在常规工作表中物种种类的数目常常要比样方的数目要多。
如果物种数量和洋房数量都超过了最大可容列数,你可以使用CanoMerge程序(见4.1章节),或者也可以用一些专门存储大型数据库的专业软件,最后生成CANOCO格式的文件(本文使用的数据是从TURBOVEG中的数据库提取出来的;Hennekens & Schaminee 2001)。
事实上,与近年来植被性状调查的数据量比较,我们分析的数据量(70个样本,285个物种)是相当少的。

基于CANOCO的生态学数据的多元统计分析著者:Jan Leps 捷克南波希米亚大学植物学系和捷克科学院昆虫研究所生态学教授Petr Smilauer 捷克南波希米亚大学多元统计分析讲师译者:赖江山中国科学院植物研究所生物多样性与生物安全研究组助理研究员这本书目的主要在于帮助生态学者分析野外观测数据和实验获得的数据。
本书对于学生或研究人员处理复杂的生态学问题非常有用,比如生物群落随环境条件的如何变化,或是生物群落在控制实验中的变化。
在简单介绍排序原理之后,本书的着重介绍约束排序方法(RDA 和CCA)和置换统计检验在多元数据中的应用。
同时介绍了如何利用分类的方法及现代回归技术(GLM,GAM,loess)来正确解读排序图。
最后,用CANOCO软件分析了7个难度不同的研究案例。
这些案例对于大家选择排序方法及分析排序结果很有帮助。
案例的数据均可以从网络本书的主页(http://regent.bf.jcu.cz/maed/)上获得。
原书前言群落的组成的多维数据,比如种群的属性,或是环境因子的属性,是生态学家研究生涯的面包与黄油。
这些数据被分析时候需要考虑它们的多维性。
用多元统计的方法来分析群落数据是比较适合的。
在这本书,我们尽量使用一套一致的方法来回答生态学家在研究中常遇到的问题。
然而,我们也经常用自己观点来表述一些内容,同时,我们也关注一些非参数的方法,比如非度量多维尺度分析(NMDS)的算法等等。
我们并不要是强调不同的方法对于分析多元数据的差异,而是想说明要解决一个问题,可以用很多方法。
在本书主要内容讲排序的方法,但并不意味着分类的方法没有用(译者注:排序与分类密不可分,分类分析群落的间断分布,排序分析群落的连续分布)。
同时,我们也对回归方做了一些总结,包括最新发展的内容比如广义可加模型(generalized additive models)。
在这本书的所描述的方法可以广泛被研究植物、动物和土壤的研究人员利用,当然也可以是水生生物方面的人员。

多元统计分析导论
多元统计分析是一种应用统计学方法研究多个变量之间相互关系的领域。
本文档将介绍多元统计分析的基本概念和主要技术。
1. 什么是多元统计分析?
多元统计分析是分析多个变量之间关系的统计学方法。
在多元统计分析中,我们可以同时考虑多个变量之间的相互作用,以更全面地理解数据集。
2. 多元统计分析的应用领域
多元统计分析广泛应用于各个领域,包括社会科学、自然科学和工程学。
它常被用于解释变量之间的关系、预测未知变量、探索数据集的特征等。
3. 多元统计分析的技术和方法
在多元统计分析中,常用的技术和方法包括多元方差分析(MANOVA)、主成分分析(PCA)、因子分析、聚类分析、判别分析等。
这些方法能够帮助研究者发现数据集中的模式和结构。
4. 多元统计分析的步骤
进行多元统计分析时,通常需要经历以下步骤:
- 数据预处理:清洗数据、处理缺失值等。
- 变量选择:选择适合分析的变量。
- 模型建立:选择合适的模型进行分析。
- 模型评估:评估模型的拟合程度和效果。
- 结果解释:解释结果并得出结论。
5. 总结
多元统计分析是一种强大的统计学工具,它能够在研究多个变量之间的关系时提供有价值的信息。
通过应用多元统计分析,研究者能够更深入地理解和解释数据集中的模式和结构。
以上是关于多元统计分析导论的简要介绍。
希望本文档能对您理解和应用多元统计分析提供帮助。

多元统计分析在生态环境研究中的应用近年来,随着人们对生态环境保护问题的关注度不断提高,多元统计分析在生态环境研究中的应用也愈发重要。
多元统计分析是指通过对多个变量之间的关系进行统计建模和分析,揭示变量之间的潜在关系,进而为环境研究提供科学依据。
本文将探讨多元统计分析在生态环境研究中的应用,并阐述其重要性和局限性。
一、多元统计分析在生物多样性研究中的应用生物多样性是生态环境研究的一个重要指标,通过多元统计分析可以有效评估不同因素对生物多样性的影响,并找出影响因素之间的相互关系。
例如,可以利用主成分分析(PCA)对不同地点的生物群落数据进行降维处理,进而揭示不同地点之间的生物多样性差异;利用聚类分析可以将相似的生物群落样点归为一类,提供有针对性的保护策略。
二、多元统计分析在环境监测中的应用多元统计分析在环境监测中也具有重要意义。
通过对不同环境因子进行主成分分析,可以确定不同环境因子对环境变异的重要程度,从而指导环境保护工作。
此外,聚类分析和相关性分析也可以用于发现环境因子之间的关系,并为环境监测提供科学依据。
三、多元统计分析在生态系统恢复中的应用生态系统恢复是生态环境保护的一个重要方向。
多元统计分析在生态系统恢复中的应用主要有两个方面:首先,可以通过对不同恢复措施的效果进行多元统计分析,评估恢复效果的显著性,并为进一步改进恢复策略提供参考。
其次,可以利用多元回归分析探究不同环境因子对生态系统恢复的影响程度,为生态系统恢复工作提供指导。
四、多元统计分析的局限性虽然多元统计分析在生态环境研究中具有广泛应用,但也存在一定的局限性。
首先,多元统计分析需要大量的样本数据支撑,因此在实际应用中存在数据采集不足的问题。
其次,多元统计分析方法的选择和参数设定对结果具有较大影响,需要研究人员具备一定的统计分析知识和技能。
此外,多元统计分析结果仅仅是描述性的,无法提供因果关系的解释,需要与其他方法相结合来进一步分析。
综上所述,多元统计分析在生态环境研究中具有重要的应用价值。

多元统计分析在生态学研究中的应用生态学是关于生物与环境的相互作用的学科,旨在研究生物体与其周围环境之间的关系以及环境中各因素间的相互作用。
而多元统计分析作为一种科学的分析方法,可以在生态学研究中发挥重要的作用。
本文将介绍多元统计分析在生态学研究中的应用及其重要性。
1.生态学研究中的统计学方法传统的生态学研究中,通常采用单变量统计学方法进行数据分析,即采用一组数据进行分析,而忽略了不同变量(如温度、光照、湿度)之间的相互作用。
这种方法的局限性在于,它不能准确反映各种因素之间的复杂相互作用,影响生物体生长和分布的因素远不止一个单一因素。
2.多元统计学方法的优越性相比单变量分析,多元统计学方法能够在数据量较大时以更全面的视角进行数据分析,并提出数据之间的相互影响。
针对生态学问题,多元统计学方法能够分析多个变量对生态系统的复杂性,提高科学研究的深度与广度。
3.用多元统计方法分析物种组成与环境影响物种组成是生态系统的核心因素,也是研究各生态系统功能和生态过程的重要基础。
通过多元统计学方法,可以探究不同环境因素(如温度、光照、湿度等)对物种组成的影响。
例如,通过多元回归分析发现高山植被区内各种植物与物种多样性指数、平均高度和气候因子之间的关系,为后续高山植被区的生态保护提供了基础数据。
4.用多元统计方法分析种群变化物种的数量和分布是生态环境变化的反映,而种群数量的变化趋势直接反应了生物种群的稳定性和持久性。
用统计学方法分析物种种群数量变化,通过多元回归、多元方差分析等方法可以建立统计模型,探讨生态环境的变量对种群数量的影响。
例如,研究以刺鱼为代表的鱼类种群数量变化趋势,可以发现一个区域的温度、水深、盐度、底层形态以及其他环境变量是影响刺鱼数量变化的重要因素,从而为相关环境保护措施的制定提供基础数据。
5.多元统计方法在模拟生态系统中的应用生态系统通常是不完全可控的,因此科学家需要通过一些方法,探索生态系统中的各种变量之间的相互作用。

使用CANOCO进行CCA或RDA教程分析在生态学和环境科学研究中,多元统计分析是非常重要的手段之一。
通过分析数据之间的关系,我们可以更好地理解生态系统的结构和功能。
而Canonical Correspondence Analysis (CCA)和Redundancy Analysis (RDA)是几种常用的多元统计方法之一,用于研究环境因子与物种组成之间的关系。
CANOCO是一个非常流行的用于执行CCA和RDA的统计软件。
本教程将向您介绍如何使用CANOCO进行CCA或RDA分析,以帮助您更好地理解生态数据。
第一步:数据准备在进行CCA和RDA分析之前,首先需要准备好您的数据。
数据应该是一个表格矩阵,包括环境因子(如温度、湿度、土壤pH等)和物种组成数据。
确保数据格式正确,可以导入到CANOCO中进行进一步的分析。
第二步:导入数据打开CANOCO软件并导入您准备好的数据。
在菜单栏中选择“File” -> “Import data”,然后选择您的数据文件进行导入。
CANOCO支持多种数据格式,包括txt、csv等。
第三步:选择分析方法在导入数据后,您需要选择进行CCA还是RDA分析。
在CANOCO中,可以通过菜单栏中的“Analysis” -> “Cononical Correspondence Analysis”或“Redundancy Analysis”来选择相应的分析方法。
第四步:设置参数在选择了分析方法后,需要设置相应的参数。
首先要选择变量类型(环境因子或生物物种),然后可以选择如何对数据进行标准化等设置。
第五步:运行分析设置好参数后,点击“Run”按钮开始运行分析。
CANOCO会生成相应的结果,并提供图形展示和统计结果。
您可以根据生成的结果图表来更好地理解数据之间的关系。
第六步:结果解读最后,根据CANOCO生成的结果来解读环境因子和物种组成之间的关系。
通过对结果图表的分析,可以深入了解生态系统的结构和功能,为生态学研究提供更多有益信息。

![canocoaeparagraphaeoeoe_583[1]](https://img.taocdn.com/s1/m/af8ba20ef12d2af90242e673.png)
5 约束排序与置换检验(Constrained Ordination andPermutation tests)在这一章,我们将讨论约束排序及其相关的内容:环境因子的逐步筛选,蒙特卡罗置换检验和变量分解分析。
5.1 线性多元回归模型(Linear multiple regression model)首先,我们必须回顾一下传统的线性回归模型,因为这对于我们理解“直接梯度分析”(约束排序)相当重要。
图5-1展示的是最简单的线性回归模型,线性模型可以模拟响应变量Y依赖自变量X的程度。
图5-1中不仅有拟合回归线,也展示了模拟值和实测值之间的差别。
模拟值^Y i (回归线上的值)与实测值Y i之间的差值叫做回归残差(regression residual),用e表示。
所有的统计模型(statistical models,包括回归模型)有个重要的特征是它们都有两个主要的部分构成:系统组成部分(systematic component)表示响应变量中能被一个或更多的解释变量(模型)解释的部分,这部分用带参数的函数表示。
另外一部分就是随机部分(stochastic component),表示不能被目前解释变量(模型)所能解释的部分。
随机部分通常用概率和分布特性来定义。
我们通常通过响应变量有多少能够被系统组成部分解释来评估拟合模型的好坏。
也经常将能被解释和未被解释的部分进行比较。
目的在于,尽力去构建一个最简约的回归模型来解释最多的变化量,让所有的自变量对于响应变量的解释都有显著贡献。
我们可以通过逐步迭代(回归)(stepwise selection)的方式来选择解释变量(环境变量)的子集合,在排序术语中往往叫预选(forward selection)。
预选变量的过程是无响应变量的零和假设开始,零和假设是响应变量中没有可以被解释变量预测,而仅仅由随机变量解释。
当我们选择一个解释变量(环境变量)进入分析,可以导致回归模型能解释一部分响应变量。

使用CANOCO进行CCA或RDA教程分析CANOCO(Canonical Correspondence Analysis and Redundancy Analysis)是一种常用于生态学和环境科学领域的多元统计分析软件,用于研究物种与环境因子之间的相互关系。
本篇文章将介绍使用CANOCO进行CCA(Canonical Correspondence Analysis)或RDA (Redundancy Analysis)的教程分析方法。
一、简介CCA和RDA都是多元统计分析方法,用于探究物种组成与环境因子之间的关系。
它们同时考虑物种对环境的响应以及环境因子对物种组成的解释。
CCA适用于物种组成与连续型环境因子的分析,而RDA 适用于物种组成与定性和/或数量型环境因子的分析。
二、数据准备在进行CCA或RDA分析前,需要准备两个数据文件:物种数据和环境数据。
物种数据包括物种丰度或物种相对丰富度信息。
环境数据包括与物种组成相关的环境因子,如土壤pH、温度、湿度等。
在数据准备过程中,要确保数据的格式正确,数据项对应准确,并且缺失数据已经进行处理。
对于不同类型的环境因子,需要进行转换或标准化处理,以保证数据的可比性和准确性。
三、导入数据在CANOCO中,可以通过导入数据按钮或者使用数据向导来导入物种数据和环境数据。
在导入数据时,请注意选择正确的数据文件和数据格式,并按照软件的要求进行字段匹配。
四、选择分析方法在导入数据后,需要选择适合的分析方法:CCA或RDA。
如果环境因子为连续型变量,则选择CCA;如果环境因子包括分类变量或数量型变量,则选择RDA。
五、执行分析在选择完分析方法后,点击执行分析按钮,CANOCO将自动计算并生成相应的结果。
分析过程可能需要一定的时间,取决于数据集的大小和复杂程度。
六、解读结果分析完成后,可以查看生成的结果图表和统计数据。
结果图表通常包括轴排序图、环境响应图、环境相关性图等。

基于CANOCO的生态学数据的多元统计分析著者:Jan Leps 捷克南波希米亚大学植物学系和捷克科学院昆虫研究所生态学教授Petr Smilauer 捷克南波希米亚大学多元统计分析讲师译者:赖江山中国科学院植物研究所生物多样性与生物安全研究组助理研究员这本书目的主要在于帮助生态学者分析野外观测数据和实验获得的数据。
本书对于学生或研究人员处理复杂的生态学问题非常有用,比如生物群落随环境条件的如何变化,或是生物群落在控制实验中的变化。
在简单介绍排序原理之后,本书的着重介绍约束排序方法(RDA 和CCA)和置换统计检验在多元数据中的应用。
同时介绍了如何利用分类的方法及现代回归技术(GLM,GAM,loess)来正确解读排序图。
最后,用CANOCO软件分析了7个难度不同的研究案例。
这些案例对于大家选择排序方法及分析排序结果很有帮助。
案例的数据均可以从网络本书的主页(http://regent.bf.jcu.cz/maed/)上获得。
原书前言群落的组成的多维数据,比如种群的属性,或是环境因子的属性,是生态学家研究生涯的面包与黄油。
这些数据被分析时候需要考虑它们的多维性。
用多元统计的方法来分析群落数据是比较适合的。
在这本书,我们尽量使用一套一致的方法来回答生态学家在研究中常遇到的问题。
然而,我们也经常用自己观点来表述一些内容,同时,我们也关注一些非参数的方法,比如非度量多维尺度分析(NMDS)的算法等等。
我们并不要是强调不同的方法对于分析多元数据的差异,而是想说明要解决一个问题,可以用很多方法。
在本书主要内容讲排序的方法,但并不意味着分类的方法没有用(译者注:排序与分类密不可分,分类分析群落的间断分布,排序分析群落的连续分布)。
同时,我们也对回归方做了一些总结,包括最新发展的内容比如广义可加模型(generalized additive models)。
在这本书的所描述的方法可以广泛被研究植物、动物和土壤的研究人员利用,当然也可以是水生生物方面的人员。

生物多样性 2013, 21 (6): 765–768 Doi: 10.3724/SP.J.1003.2013.04133 Biodiversity Science http: //—————————————————— 收稿日期: 2013-05-31; 接受日期: 2013-08-22 基金项目: 国家自然科学基金(31200403) ∗通讯作者 Author for correspondence. E-mail: lai@生态学多元数据排序分析软件Canoco 5介绍赖江山*(中国科学院植物研究所植被与环境变化国家重点实验室, 北京 100093)摘要: 基于样方单元的生物群落调查多元数据是生物多样性研究中最基本的数据类型之一。
排序(ordination)作为多元统计最常用的方法之一, 目的是在可视化的低维空间展示多维数据的结构。
Canoco 是数据排序分析最流行的软件之一。
Canoco 4.5自从2002年发布以来, 凭借简单的操作界面和功能齐全的绘图工具, 得到广泛的应用。
但随着计算机技术的不断发展和新的排序方法不断出现, Canoco 4.5已经无法满足生态学研究人员对于多元数据深入分析的需求。
作为Canoco 4.5的升级版本, Canoco 5于2012年10月发布。
Canoco 5在Canoco 4.5基础上做了很多改进,主要体现在简化数据输入、提供更完善的帮助系统和绘图工具、简化方差分解和显著性检验的步骤, 并增加了一些新的分析方法(例如PCNM 、NMDS 、功能性状关联分析等)。
本文概述了Canoco 5所做的这些改进, 并对有些重要操作步骤进行提示, 供同行参考。
关键词: 方差分解, 邻体矩阵主坐标分析, 非度量多维尺度分析, 谱系, 功能属性Canoco 5: a new version of an ecological multivariate data ordination programJiangshan Lai *State Key Laboratory of Vegetation and Environmental Change, Institute of Botany, Chinese Academy of Sciences, Bei-jing 100093Abstract: Ordination of multidimensional data on community composition is one of the most important mul-tivariate statistical methods used in biodiversity research. The aim of ordination is to visualize multidimen-sional data structure at a low-dimensional ordination space. Canoco is one of the most popular programs for ordination analysis and Canoco 4.5 was widely used for such analysis after its release in 2002, because of its simple user interface and powerful graphic tools. A new version of Cannoco, Canoco 5 was released in Oc-tober 2012. This new version simplifies data entry, provides a better help system and graphics tools, simpli-fies steps of variation partitioning and significance tests, adds some new methods (e.g. PCNM, NMDS, asso-ciation analysis of functional traits, etc.). This paper provides an overview of the major improvements to Canoco 5, and addresses important steps required for particular analyses.Key words: variation partitioning, PCNM, NMDS, functional traits, phylogenetic基于样方单元的生物群落调查数据是生物多样性研究中最基本的数据类型之一。
基于Canoco的CCA数据处理过程解析一、数据处理1、数据格式要求在Excel表格里面,你必须将数据做成矩形形式。
默认的方式(也是常用的方式)是一行代表一个样方,一列代表一个变量。
表格左顶格最好是空着。
最好第一列和第一行分别有样方编号和变量的名称。
必须注意的是名称不能超过8个字符,如果超过8个字符,CANOCO会自动截取前8个字符作为名称。
变量名称最好是英文字母、数字、圆点或是连字符,空格也可以。
除了第一行和第一列,表格内剩下的填充内容必须是数字或是空着,绝对不能使用字符型数据。
定性变量(因子)必须转换为哑变量(0‐1数据)方可进入CANOCO分析。
当数据在Excel表格里按要求整理好后,将包含数据的矩形方阵选定,然后选择“复制”按钮,此时数据便复制到剪贴板中。
WCanoImp 便可以从剪贴板中读取数据。
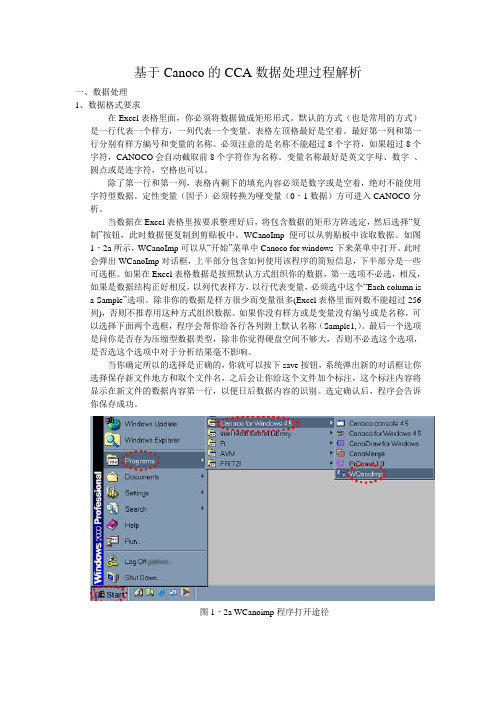
如图1‐2a所示,WCanoImp可以从“开始”菜单中Canoco for windows下来菜单中打开。
此时会弹出WCanoImp对话框,上半部分包含如何使用该程序的简短信息,下半部分是一些可选框。
如果在Excel表格数据是按照默认方式组织你的数据,第一选项不必选,相反,如果是数据结构正好相反,以列代表样方,以行代表变量,必须选中这个“Each column isa Sample”选项。
除非你的数据是样方很少而变量很多(Excel表格里面列数不能超过256列),否则不推荐用这种方式组织数据。
如果你没有样方或是变量没有编号或是名称,可以选择下面两个选框,程序会帮你给各行各列附上默认名称(Sample1,)。
最后一个选项是问你是否存为压缩型数据类型,除非你觉得硬盘空间不够大,否则不必选这个选项,是否选这个选项中对于分析结果毫不影响。
当你确定所以的选择是正确的,你就可以按下save按钮,系统弹出新的对话框让你选择保存新文件地方和取个文件名,之后会让你给这个文件加个标注,这个标注内容将显示在新文件的数据内容第一行,以便日后数据内容的识别。


canoco5使用实例Canoco5是一款用于多元统计分析的软件,主要用于生态学、环境科学、农业科学等领域的数据分析。
下面将介绍Canoco5的使用实例。
一、数据准备在使用Canoco5进行数据分析之前,需要先准备好数据。
数据应该是一个表格,其中每一行代表一个样本,每一列代表一个变量。
变量可以是连续型或分类型的,但是需要将分类型变量转化为虚拟变量。
二、导入数据在Canoco5中,可以通过“File”菜单中的“Import Data”命令将数据导入到软件中。
在导入数据时,需要指定数据文件的格式和数据类型。
Canoco5支持多种数据格式,包括Excel、CSV、TXT等。
在导入数据时,还需要指定哪些变量是响应变量,哪些变量是解释变量。
三、选择分析方法Canoco5支持多种分析方法,包括PCA、RDA、CCA、DCA等。
在选择分析方法时,需要根据数据类型和研究目的来选择合适的方法。
例如,如果数据是连续型的,可以选择PCA方法进行主成分分析;如果数据是分类型的,可以选择DCA方法进行对应分析。
四、运行分析在选择分析方法后,可以通过“Analyze”菜单中的“Run Analysis”命令来运行分析。
在运行分析时,需要指定哪些变量是响应变量,哪些变量是解释变量,以及分析方法的参数。
Canoco5会自动计算出各个变量的权重和贡献率,并生成相应的图表和报告。
五、结果解释在分析完成后,可以通过Canoco5生成的图表和报告来解释结果。
例如,可以通过PCA图来观察样本之间的相似性和差异性;可以通过RDA图来观察响应变量和解释变量之间的关系。
此外,还可以通过Canoco5生成的报告来查看各个变量的权重和贡献率,以及分析方法的统计显著性。
总之,Canoco5是一款功能强大的多元统计分析软件,可以帮助研究人员快速、准确地分析数据。
在使用Canoco5进行数据分析时,需要注意数据的准备和导入、分析方法的选择和参数设置、以及结果的解释和报告生成。

canoco方差分解Canoco方差分解是一种用于分析多元数据的统计方法,它可以帮助研究者理解不同因素之间的关系以及它们对数据变异的贡献。
本文将介绍Canoco方差分解的基本原理、应用范围、数据处理流程以及优缺点等方面。
一、基本原理Canoco方差分解是基于多元线性回归模型的一种统计方法,它可以将数据的总变异分解为不同因素的贡献,从而揭示它们对数据变异的影响程度。
具体来说,Canoco方差分解可以将数据的总变异分解为两个部分:一是由因素之间的相互作用所引起的变异,称为交互作用(Interaction);二是由每个因素单独作用所引起的变异,称为主效应(Main effect)。
通过对交互作用和主效应的分解,我们可以了解不同因素之间的关系以及它们对数据变异的贡献。
二、应用范围Canoco方差分解主要应用于生态学、环境科学、农业科学等领域的数据分析。
它可以用于研究不同环境因素对生物群落结构、物种多样性、生产力等方面的影响,也可以用于研究不同农艺措施对作物生长、产量等方面的影响。
此外,Canoco方差分解还可以用于研究不同因素之间的交互作用,比如气候变化和土地利用变化对生态系统的影响等。
三、数据处理流程Canoco方差分解的数据处理流程主要包括数据准备、模型拟合、方差分解和结果解释等步骤。
具体来说,数据准备包括数据清洗、变量选择、数据标准化等;模型拟合包括选择适当的回归模型、拟合模型、检验拟合效果等;方差分解包括计算交互作用和主效应的贡献、绘制方差分解图等;结果解释包括解释主要因素对数据变异的贡献、解释不同因素之间的关系等。
四、优缺点Canoco方差分解的优点在于它可以揭示不同因素之间的关系以及它们对数据变异的贡献,从而帮助研究者深入理解数据。
此外,Canoco方差分解还可以用于研究不同因素之间的交互作用,这对于揭示复杂的生态系统或农业生产系统的动态变化非常有帮助。
然而,Canoco方差分解也存在一些缺点,比如对数据的要求较高、模型拟合需要较长的时间等。

生态统计学方法与应用生态统计学是一门应用数学领域的学科,它研究的是生物群落、生态系统和生态过程中所涉及的数据的收集、分析和解释方法。
生态统计学旨在帮助生态学家和环境科学家了解和预测生物多样性、物种分布、生态过程以及环境变化对生态系统的影响。
本文将探讨生态统计学方法的基本原理和常用的应用领域。
一、生态统计学方法的基本原理生态统计学方法基于数理统计学的基本原理,但又结合了特定的生态学问题和数据类型的特点。
下面介绍一些常用的生态统计学方法:1. 生物多样性测度:生态学家通常关注物种的多样性程度。
在生态统计学中,我们可以使用物种丰富度、物种均匀度和生物多样性指数等测度来评估不同生物群落的多样性水平。
2. 物种分布建模:通过收集物种分布数据和环境变量数据,我们可以使用生态统计学方法来建立物种分布模型。
这种模型能够帮助我们预测物种在不同环境条件下的分布情况。
3. 群落结构分析:群落结构是指生物群落中不同物种的相对丰度和重叠程度。
通过使用聚类分析、多元回归分析和其他多元统计方法,我们可以研究和描述不同群落的结构特征,从而了解各个物种之间的相互作用和生态过程。
4. 时间序列分析:生态学研究通常需要对不同时间点的数据进行比较和分析。
生态统计学方法可以帮助我们对时间序列数据进行建模和预测,并揭示生态系统随时间的变化趋势。
二、生态统计学在应用中的作用生态统计学方法在各个生态学研究领域都有广泛的应用,下面介绍几个主要的应用领域:1. 物种保护与管理:生态统计学方法可以帮助我们评估和监测濒危物种的种群数量,了解其栖息地的质量和连通性,并为物种保护和管理制定科学依据。
2. 生态系统健康评估:通过使用生态统计学方法,我们可以对生态系统的结构和功能进行评估,了解不同干扰和压力对生态系统的影响,并提供生态恢复和保护的建议。
3. 环境监测:生态统计学方法可用于分析环境监测数据,帮助我们了解环境变量与物种分布、多样性和群落结构之间的关系,从而推测环境变化对生态系统的影响。

基于CANOCO的生态学数据的多元统计分析著者:Jan Leps 捷克南波希米亚大学植物学系和捷克科学院昆虫研究所生态学教授Petr Smilauer 捷克南波希米亚大学多元统计分析讲师译者:赖江山中国科学院植物研究所生物多样性与生物安全研究组助理研究员这本书目的主要在于帮助生态学者分析野外观测数据和实验获得的数据。
本书对于学生或研究人员处理复杂的生态学问题非常有用,比如生物群落随环境条件的如何变化,或是生物群落在控制实验中的变化。
在简单介绍排序原理之后,本书的着重介绍约束排序方法(RDA 和CCA)和置换统计检验在多元数据中的应用。
同时介绍了如何利用分类的方法及现代回归技术(GLM,GAM,loess)来正确解读排序图。
最后,用CANOCO软件分析了7个难度不同的研究案例。
这些案例对于大家选择排序方法及分析排序结果很有帮助。
案例的数据均可以从网络本书的主页(http://regent.bf.jcu.cz/maed/)上获得。
原书前言群落的组成的多维数据,比如种群的属性,或是环境因子的属性,是生态学家研究生涯的面包与黄油。
这些数据被分析时候需要考虑它们的多维性。
用多元统计的方法来分析群落数据是比较适合的。
在这本书,我们尽量使用一套一致的方法来回答生态学家在研究中常遇到的问题。
然而,我们也经常用自己观点来表述一些内容,同时,我们也关注一些非参数的方法,比如非度量多维尺度分析(NMDS)的算法等等。
我们并不要是强调不同的方法对于分析多元数据的差异,而是想说明要解决一个问题,可以用很多方法。
在本书主要内容讲排序的方法,但并不意味着分类的方法没有用(译者注:排序与分类密不可分,分类分析群落的间断分布,排序分析群落的连续分布)。
同时,我们也对回归方做了一些总结,包括最新发展的内容比如广义可加模型(generalized additive models)。
在这本书的所描述的方法可以广泛被研究植物、动物和土壤的研究人员利用,当然也可以是水生生物方面的人员。

基于CANOCO的生态学数据的多元统计分析著者:Jan Leps 捷克南波希米亚大学植物学系和捷克科学院昆虫研究所生态学教授Petr Smilauer 捷克南波希米亚大学多元统计分析讲师译者:赖江山中国科学院植物研究所生物多样性与生物安全研究组助理研究员这本书目的主要在于帮助生态学者分析野外观测数据和实验获得的数据。
本书对于学生或研究人员处理复杂的生态学问题非常有用,比如生物群落随环境条件的如何变化,或是生物群落在控制实验中的变化。
在简单介绍排序原理之后,本书的着重介绍约束排序方法(RDA 和CCA)和置换统计检验在多元数据中的应用。
同时介绍了如何利用分类的方法及现代回归技术(GLM,GAM,loess)来正确解读排序图。
最后,用CANOCO软件分析了7个难度不同的研究案例。
这些案例对于大家选择排序方法及分析排序结果很有帮助。
案例的数据均可以从网络本书的主页(http://regent.bf.jcu.cz/maed/)上获得。
原书前言群落的组成的多维数据,比如种群的属性,或是环境因子的属性,是生态学家研究生涯的面包与黄油。
这些数据被分析时候需要考虑它们的多维性。
用多元统计的方法来分析群落数据是比较适合的。
在这本书,我们尽量使用一套一致的方法来回答生态学家在研究中常遇到的问题。
然而,我们也经常用自己观点来表述一些内容,同时,我们也关注一些非参数的方法,比如非度量多维尺度分析(NMDS)的算法等等。
我们并不要是强调不同的方法对于分析多元数据的差异,而是想说明要解决一个问题,可以用很多方法。
在本书主要内容讲排序的方法,但并不意味着分类的方法没有用(译者注:排序与分类密不可分,分类分析群落的间断分布,排序分析群落的连续分布)。
同时,我们也对回归方做了一些总结,包括最新发展的内容比如广义可加模型(generalized additive models)。
在这本书的所描述的方法可以广泛被研究植物、动物和土壤的研究人员利用,当然也可以是水生生物方面的人员。
由于本书的两位作者的背景,本书的内容偏向植物生态学。
这本手册的材料原先是作为“生态数据多元分析”的课件。
我们也希望这本书能用于其它相关类似的课程,也期望每个学生能够从这本书提高他们的分析数据的能力。
我们希望这本书可以作为Canoco 4.5 使用手册的简明的补充材料。
Jan Lep 和Petr Smilauer译者前言四年前,我开始接触CANOCO软件时候,也是菜鸟一个,自己并不是学统计出身,学习的过程也非常缓慢。
当时也不会想到四年后今天,我居然还能为大家翻译这样一本有关CANOCO的书。
这个过程,不得不承认普兰塔()的作用,正是为了回答塔友有关排序和CANOCO相关的问题,我不断翻文献、看软件说明书和自己摸索,积累了一点关于多元统计方法和CANOCO软件的一些知识。
我相信很多的塔友的排序知识比我丰富,CANOCO软件用得比我熟练,但至今不愿“出山”写本中文的参考书,哪怕是翻译一本也行。
没办法,只能由我这个半桶水的家伙来承担此任务。
《士兵突击》的许三多有口头禅:“俺就是想做有意义的事情”。
我一直觉得,翻译这本书就是非常有意义的事情,尽管现在的评价考核体系根本不会考虑我翻译了这本书,但我还是很乐意做这个事情。
如果有很多CANOCO的初学者将从中受益,我也深感欣慰。
当然,我发现每天早上上班和晚上下班前翻译一两段这本书还是一件很惬意的事情,而在翻译的过程,我也学到很多的东西。
由于本人非统计科班出身,而且时间比较仓促,翻译过程中可能有不少错误。
有些统计学术语内容也可能斟酌不够,把握不准。
因此,希望各个兄弟姐妹发现错误后给直接在博客里面回复,我会尽快修改。
赖江山2009/6/251.导论和数据处理(Introduction and data manipulation)1.1为什么排序?(Why ordination?)当考察植物或动物群落沿着一系列环境条件下的变化情况,我们经常发现在不同条件的群落不仅物种组成变化很大,而且这些变化往往具有连续性(consistency)和可预测性(predictability)。
例如,我们为了要考察景观尺度上的草地群落的变化,可以通过观测样方内物种组成变化来描述,我们可以在一、两个或是三个虚拟坐标轴上将这些样方一个一个进行排列。
当我们的目光在虚拟的排序轴上从一个样方移动到下一个相邻的样方,我们就会发现群落内物种组成变化通常很小。
群落中物种组成渐变跟每个物种对环境条件有着需求不同但又有重叠的生物学性质息息相关,这些环境因子如土壤平均湿度及随季节的波动变化、物种间竞争养分和光照能力等等。
如果我们原来排列样方的虚拟轴走向恰好能反映某种环境因子的变化规律(比如土壤湿度或是土壤养分丰富度),这些排序轴便可以被称为土壤湿度梯度、养分梯度等等。
这些环境梯度偶尔恰好又能跟实际的景观联系起来,例如土壤湿度梯度与河岸坡面,经常是沿着坡面从下到上,土壤湿度逐渐降低。
但大部分情况下,我们并不能发现这些轴具体反映什么环境因子,或是反映什么空间变化,因此我们只能称这些轴为群落组成变化梯度。
生物群落的变化可以用很多统计方法来描述,但我们如果着重考察群落变化的连续性,所谓的“排序方法”是很好的选择。
自从上个世纪五十年代开始,生态学家就开始用排序的方法分析生态学数据,经过半个世纪的发展,现在已经创制出种类繁多排序技术。
我们利用刚才那个草地群落的例子来说明一下最简单的排序使用。
当我们通过样方调查法来描述群落物种变化规律的时候,把样方数据总结在一个表格里面形成一个物种-样方矩阵,矩阵的列代表物种,行代表样方。
如果用排序的方法分析数据矩阵并在排序图上表示出来(图1-1),我们可以获得对于这个草地群落相当直观的认识。
排序图的解读规则将在随后的第10章进行讨论。
但即使现在不知道这些规则,只要脑子里有群落连续性分布的思想和相似相近的原则(Proximity implies similarity),我们也能从这个图解读出一些信息。
在图1-1中灰色的圆圈代表样方,我们可以相信如果两个样方在排序图上挨得越近,它们的物种组成和种间数量比例应该越相似。
在图1-1中用三角型代表物种。
或许这些物种的生态学特征能够帮我们解读排序轴所表示的生态学梯度。
有几个偏好丰富养分的土壤的物种(如Urtica dioica, Aegopodium podagraria, or Filipendula ulmaria)排在图的右边,另外一些偏好养分匮乏的土壤的物种排在左边(如(Viola palustris, Carex echinata, or Nardus stricta)。
因此,排序图中的水平轴(第一轴)可以解读为表示土壤养分的梯度,从左到右,养分越丰富。
同样的道理,排序图下面几个物种(如Galium palustre, Scirpus sylvaticus, or Ranunculus repens)比排在上面的一些物种(如Achillea millefolium, Trisetum flavescens, or Veronica chamaedrys)更喜欢湿生环境。
因此,纵轴(第二轴)可以解读为表示土壤的湿度梯度。
同样,或许大家都可以猜到,在排序图上,如果某一物种的越靠近某一个样方,表示该物种在此样方内个体数量越多。
同样,两个物种离一个样方的距离也可以代表它们在该样方所占比例的差异,离得越近该物种相对数量越多。
上面的例子已经展示了排序方法对于群落分析的最基本的用途。
通过排序分析,我们可以认识群落格局,也可以将排序轴跟我们已知的环境条件联系起来,看是否代表某一环境梯度。
当然,也许我们必须用统计手段来检验排序轴到底是否真能代表环境因子的梯度,比如,上面这个例子,我们可以这样问个问题:群落物种组成分布真的是随土壤湿度的变化,还是仅仅是一个巧合呢?通过约束排序法(constrained ordination methods)可以帮我们回答这样的问题。
这些内容通通将要在本书的后半部分介绍。
然而,这本书并没有止步于仅仅用排序的方法来探讨上述这些简单的确定性的分析。
这本书还介绍了各种类型的回归和方差分析,包括了固定样点重复观察的数据分析,空间结构数据分析和各种等级的方差分析。
这些方法能够让生态学家探讨更复杂、更现实的科学问题。
另外,这本书不仅是告诉如何分析问题,还手把手教大家怎么做。
图1.1 草地植被物种组成的CA排序图1.2专业术语(Terminology)多元统计分析的专业术语非常复杂。
本书内至少有两套不同的术语,一套是很多学科领域共同使用的、纯粹统计学术语,本书中我们将这部分术语斜体并放在括号里面;另外一套是群落生态学惯用的多元统计学术语。
本书也大部分统计术语基于群落生态学,偶尔用纯粹统计学术语来表达一些常用的统计学理论。
本书中的术语跟CANOCO软件中的术语是一致的。
在群落学分析中,大部分情况是下是基于样方单元(sampling units)观测的原始数据。
每个样方内包含很多物种的数量信息,或是其他属性的信息。
原始数据常用矩阵来表示,一般是一行代表一个样方,一列代表一个属性特征(如物种,水分或土壤的物理化学特征等等)生态学原始数据一般由两个部分构成,一组是响应变量(response variable),另外一组是解释变量(explanatory variables)。
在群落学分析里面,响应变量经常是物种的组成数据,而解释变量通常是环境因子,比如土壤或水的特征属性等。
在一个模型里,我们要利用解释变量来预测响应变量(群落的组成)。
在排序分析中,解释变量又经常可以分为两组:一类主环境变量,我们主要关心它们与群落内物种分布的关系;另外一组叫协环境变量(在一般统计方法里面也叫协同变量covariates)。
协环境变量与主环境变量同时对响应应变起作用,因此我们要分析主环境变量效应之前,应先将协环境变量的效应剔除出来,以便更准确考察主环境变量与物种分布的关系。
举个例子,我们要分析一个特定区域土壤的属性特征和管理模式(刈割或放牧)对草地群落物种组成的影响。
当我们感兴趣的土壤的属性的影响,不关心管理模型的影响时,物种组成数据作为响应变量,土壤的属性数据作为解释变量,得出的结论可以看出每个物种分布与土壤梯度的关系。
同样,我们考察管理模式对物种分布的影响,不关心土壤的属性的影响时,只用管理模型数据作为解释变量即可。
然而,假设管理模式可能改变土壤的属性,这样就能通过影响土壤属性改变来间接影响物种分布。
现在我们只要分析管理模式单独对群落内物种组成的影响,需要排除掉通过影响土壤间接影响物种分布的这部分效应。
此时,就应该把管理模式作为主环境变量,而土壤属性数据作为协环境变量。