Acrobat OCR识别文本功能提取图片文字
- 格式:doc
- 大小:37.50 KB
- 文档页数:2

从图片提取文字的方法
我们经常会需要从图片中提取文字,数量少的可以直接在键盘上敲写,数量大的就需要用到些省时省力的小技巧了,这样能够节省大量时间,这里主要介绍依托OCR光学字符识别技术实现文字提取目的。
方法1:提高图片质量
使用OCR技术需要尽量使图片看起来清晰并且方正,可使用ACDSee等软件,对原图片进行加工处理,使图片变得方方正正,不歪斜,字迹清晰可见,不模糊。
方法2:使用Microsoft Office办公软件
打开OneNote组件后,直接将照片拖入软件界面,加载图片完毕后,邮件点击复制图片中的文字选项,复制并粘贴到文档中,即可实现提取文字。
需要进行校对修正,有一定错误率,特别是模糊的字迹,需要提高图片质量。
该功能需在正常使用软件的情况下才可使用。
方法3:使用讯飞语音软件
打开软件后,点击图文识别按钮,即可打开文字提取功能,从软件中按照步骤打开图片,图片加载到软件中,并会自动提取文字,可以选择直接导出至Word文档或复制文字后粘贴到目标文档中。
需要进行校对修正,有一定错误率。
该软件功能需要付费。
方法4:使用手机扫描文档软件
目前,手机市场上推出很多OCR软件,通过扫描文档
获取图片,实现文字转换功能,比如“扫描全能王”。
只需打开软件,将摄像头对正文档纸张,即可扫描为图片,并可以提取图片中的文字,文字可以粘贴到文档中。

用OCR软件进行扫描识别文本的技巧扫描仪的一个重要功能就是通过OCR软件(即文字识别软件)将扫描后的文字图像转换成文本格式的文件,使文字处理软件能够调用处理。
这样可以大大提高文字录入速度,极大地提高工作效率。
目前,文字识别软件主要有《尚书OCR》、《汉王OCR》和《紫光OCR》等几种。
不过,我们在进行文字识别时经常会遇到识别率低的问题,其原因除了被识别稿件有问题外,主要还是我们没有掌握好扫描及OCR识别软件的使用技巧。
那么进行文字识别时有哪些技巧呢?一、根据识别稿的质量进行处理进行扫描识别时,在可能的情况下应尽量选择清晰度与洁净度都很高的识别稿,识别稿的清晰度与洁净度的不同会使扫描后的识别率有很大差距。
对一般的印刷稿、打印稿等质量较好的文稿进行识别,只要掌握好方法与技巧,其识别率一般可达到98%以上。
而对报纸、杂志等清晰度不佳的原稿进行识别,无论使用何种识别软件都难以达到很高的识别率。
1.对一些带有下划线、分隔线等符号的文本原稿,有些OCR软件是识别不出的,一般会出现乱码。
如果必须扫描带有这些符号的原稿,一是要确保使用的识别软件能够识别这些符号。
二是使用工具擦掉这些特殊符号,使识别软件能正确识别这些文字。
如果扫描后的文档中含有OCR软件不能识别的图像、图形和一些特殊符号,可以考虑使用“擦拭”工具将文档中的图像、图形和一些特殊符号擦除,同时将图像上一些杂点也一并去除。
使图像中除了文字没有多余的东西,这可以大大提高识别率并减少识别后的修改工作。
2.在扫描识别报纸或纸张较薄的文稿时,扫描时稿件背面的文字通常会透过纸张造成错字或乱码,使识别率大大降低。
在对这类原稿扫描时,我们可以在原稿的背面覆盖一张黑纸,在进行正式扫描时,适当增加扫描对比度或亮度,即可有效提高识别率。
3.对于一些图文混排的原稿,扫描成一幅图像进行全区识别会严重影响OCR软件的识别率。
我们可以根据实际情况将扫描后的版面切分成多个区域后再识别,切分区域的原则是:将图形、图像排除在区域之外(图1),尽量把文字字体、字号一致的划在一个区域内,不要嫌这个过程烦琐而选用自动切分区域,手动选取扫描区域会有更好识别效果,还应注意各识别区域不能有交叉情况。

要从多个图片中提取文字,可以使用光学字符识别(OCR)技术,这是一种通过扫描图像并识别其中的文字来将图像中的文字转换为可编辑文本的技术。
以下是几种常见的方法来实现这个目标:
1. OCR软件:有许多专门的OCR软件,如Adobe Acrobat、Abbyy FineReader、Tesseract等,它们可以帮助你将图像中的文字提取为文本。
你可以上传图片到这些软件中,然后进行文字识别处理,最终得到提取出的文字信息。
2. 在线OCR工具:有些网站提供免费的在线OCR工具,例如OnlineOCR、Google 文字识别等,你可以通过上传图片到这些网站,进行在线文字识别,最后将识别出的文字提取出来。
3. 手机APP:市面上有一些OCR识别的手机应用程序,比如百度OCR、Adobe Scan等,你可以通过手机拍摄图片,然后使用这些应用程序进行文字识别。
不过需要注意的是,OCR技术对于文字清晰度、语言、字体等都有一定的要求,所以在使用时需要确保图片质量良好,
文字清晰可见。
另外,对于一些特殊的字体或是手写文字,识别效果可能会有所不同。
综上所述,使用OCR软件、在线工具或手机应用是从多个图片中提取文字的常见方法,可以根据实际需求选择合适的工具来进行文字提取和识别。

文字识别工具如何利用OCR技术提取扫描文档中的文字随着数字化时代的到来,越来越多的文档被电子化存储,但仍存在大量的纸质文档需要处理。
而这些纸质文档中的文字信息对于人们的查询、编辑和管理非常重要。
为了更好地实现纸质文档的数字化处理,文字识别(OCR)技术应运而生。
本文将介绍OCR技术是如何利用文字识别工具来提取扫描文档中的文字信息。
一、什么是OCR技术?OCR(Optical Character Recognition)即光学字符识别技术,是利用计算机对图像上的文字进行自动识别和转换为可编辑、可搜索的文字的一种技术。
OCR技术通过扫描纸质文档并对其进行图像处理、分析和文字识别,将扫描得到的图像转换为电子文本文件。
这一技术可以大大提高纸质文档的利用效率,并方便文档的存储和检索。
二、OCR技术的应用领域1. 文档数字化:OCR技术能够将纸质文档快速转换为电子文本,方便存储、管理和共享。
2. 归档与检索:OCR技术可以自动将扫描文档中的文字提取出来,实现文档分类、索引和检索。
3. 语音合成:OCR技术可用于将文字转化为语音,为用户提供更多的阅读方式。
4. 翻译与编辑:OCR技术可以将扫描文档中的文字转换为可编辑的文本,方便用户进行翻译、修改和编辑。
三、文字识别工具的特点及使用文字识别工具是一种软件或在线服务,通过OCR技术实现图像文字的自动识别和提取。
下面将介绍几种常用的文字识别工具及其特点:1. ABBYY FineReader:该软件具有强大的识别能力,能够处理多种语言文字,并支持多种输出格式,包括Word、Excel和PDF等。
其图像预处理功能能有效提升识别准确率。
2. Adobe Acrobat:Adobe Acrobat是一款专业的PDF编辑工具,内置OCR功能,可以直接将扫描文档中的文字提取出来,并将其转换为可编辑的PDF文件。
3. Google 文字识别:Google提供了一款免费的在线文字识别服务,用户可以直接上传图片或pdf文档,通过OCR技术将文字提取出来。

提取图片上的文字的方法方法一、安装OCR软件,给您提一点小技巧,在使用OCR软件识别前,可用用图片处理软件(例如:photoshop)处理一下,转换成黑白模式,并适当加大对比度,可以大大提高识别率。
方法二、用Microsoft Office自带的识别(Document Imaging)和扫描功能(Document scanning)。
1、Microsoft Office Document Imaging(office2003中内含)OFFICE中有一个组件document image,功能一样的强大。
不仅扫描的文字图片,连数码相机拍的墙上的宣传告示上的字都能提取出来。
(ocr识别工具(像眼睛)需要安装,需要office安装文件)第一步把要提取文字的图片格式转换成tif格式。
(转换方法有:1、用“画图”打开图片然后另存,格式选“tif”.2、打开图片用截屏保存为“tif”格式。
)第二步启动“Imaging”。
点“开始→程序→Microsoft Office→Microsoft Office 工具”,在“Microsoft Office 工具” 里点“ Microsoft Office Document Imaging”。
第三步用 Microsoft Office Document Imaging打开图片,用OCR工具(图中红色筐圈部分)选取你要提取的文字,然后点右键,选择-复制到word或者记事本。
2、、用摄像头作扫描仪输入文字:第一步,“开始→Microsoft office→Microsoft office工具→Microsoft office Document scanning”,如果该项未安装,系统则会自动安装。
第二步,安装完成,此时会弹出扫描新文件对话框,单击[扫描仪]按钮,在弹出的对话框中选中摄像头,并选中“在扫描前显示扫描仪驱动”复选框,再选中“黑白模式”,并选中“换页提示”和“扫描后查看文件”两项。

WPS办公软件的OCR识别与文字提取随着科技的发展,办公软件越来越多样化,为我们的办公工作带来了很大的方便。
其中,WPS办公软件作为一款使用广泛的办公软件,具备了很多实用的功能,如文档编辑、表格制作和幻灯片设计等。
而在这些功能中,OCR识别与文字提取无疑是一项非常重要的特性。
本文将探讨WPS办公软件中的OCR识别与文字提取的功能与应用。
一、OCR识别的概念与作用OCR,全称为Optical Character Recognition,即光学字符识别技术,是一种将纸质文件、图片或扫描件中的文本信息转化为可编辑和搜索的电子文本的技术。
OCR识别在办公软件中的作用是将图像文件中的文字内容转化为可编辑的文字,并且可以通过搜索关键词快速定位到特定的文字内容。
这一技术极大地提高了文档处理的效率和便利性。
二、WPS办公软件中的OCR识别与文字提取功能WPS办公软件同样提供了OCR识别与文字提取的功能,让用户能够方便地将纸质文件、图片或扫描件中的文字识别出来并进行编辑。
使用WPS办公软件进行OCR识别与文字提取只需简单的几个步骤:1. 打开WPS办公软件并创建一个新的文档,在菜单栏中选择“插入”选项;2. 在下拉菜单中选择“图片”,然后选择要进行OCR识别的纸质文件、图片或扫描件,并点击“插入”按钮;3. 在图片被插入到文档中后,点击图片,出现的“识别文字”按钮将会高亮显示。
点击该按钮,WPS办公软件将自动开始对图片中的文字内容进行OCR识别与提取;4. 识别完成后,WPS办公软件会自动将文字内容添加到文档中,用户可以对其进行编辑、格式化或搜索。
通过以上简单的步骤,用户可以轻松地将纸质文件或图片中的文字内容提取出来,并在WPS办公软件中进行后续的编辑和处理。
三、OCR识别与文字提取的应用场景1. 文档数字化:通过将纸质文件或扫描件中的文字进行OCR识别与提取,可以将其转化为可编辑、可搜索的电子文档,大大提高了文档的存储和检索效率。
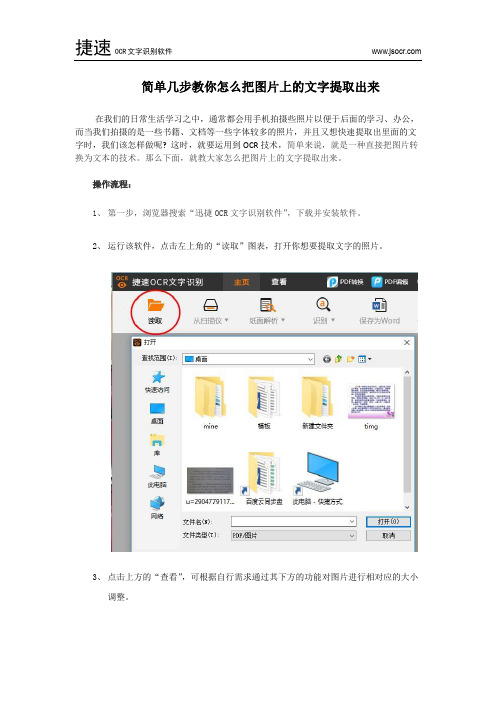
简单几步教你怎么把图片上的文字提取出来
在我们的日常生活学习之中,通常都会用手机拍摄些照片以便于后面的学习、办公,而当我们拍摄的是一些书籍、文档等一些字体较多的照片,并且又想快速提取出里面的文字时,我们该怎样做呢? 这时,就要运用到OCR技术,简单来说,就是一种直接把图片转换为文本的技术。
那么下面,就教大家怎么把图片上的文字提取出来。
操作流程:
1、第一步,浏览器搜索“迅捷OCR文字识别软件”,下载并安装软件。
2、运行该软件,点击左上角的“读取”图表,打开你想要提取文字的照片。
3、点击上方的“查看”,可根据自行需求通过其下方的功能对图片进行相对应的大小
调整。
4、接下来,依次点击“主页”—“纸面解析”,点击完后,图片上就会出现一个红色
边框,边框内的部分即需要识别的部分,拖动其四个角中的一个可对其进行范围的调整。
5、然后,移至软件的右下角有“文档属性”,根据需要,勾选或去除语种,符号。
6、设置完毕后,便可点击上方的“识别”按钮,对文字进行识别,下方右侧的区域
便是识别的结果。
若有误差,可自行在右下方区域进行编辑修正。
7、最后,点击上方的“保存为Word”,选择保存路径,点击“保存”就大功告成啦。
好啦,本期图片的文字提取教程就介绍到这里,是不是很简单呢?希望能对大家有所帮助。

AdobeAcrobatPDF处理的基本操作和功能介绍Adobe Acrobat是一款功能强大的PDF处理工具,被广泛应用于文档管理和编辑领域。
本文将详细介绍Adobe Acrobat的基本操作和功能。
第一章:安装和启动Adobe AcrobatAdobe Acrobat可在官方网站下载安装包,根据操作系统选择相应的版本。
安装完成后,双击桌面图标启动Adobe Acrobat。
第二章:创建和编辑PDF文件Adobe Acrobat可以打开和编辑现有的PDF文件,也可以创建全新的PDF文件。
用户可以通过拖拽文件到Adobe Acrobat窗口的方式打开PDF文件,或者在菜单中选择“文件”-“打开”来导入文件。
编辑PDF文件时,用户可以添加、删除和移动文本、图片和表格等元素。
第三章:导出和转换PDF文件Adobe Acrobat可以将PDF文件导出为其他格式的文件,如Microsoft Word、Excel或PowerPoint等。
用户可以在菜单中选择“文件”-“导出为”-“其他格式”,然后选择需要导出的文件类型。
此外,Adobe Acrobat还支持批量转换多个PDF文件。
第四章:添加和编辑书签书签是PDF文件中的一种导航工具,方便用户快速定位到文件中的特定位置。
用户可以在Adobe Acrobat中使用“视图”-“导航面板”-“书签”来显示书签面板。
创建书签非常简单,只需选择需要添加书签的位置,然后在书签面板上点击“添加书签”按钮。
第五章:设置PDF文件安全Adobe Acrobat提供了多种安全功能,帮助用户保护PDF文件的机密性和完整性。
用户可以在菜单中选择“工具”-“保护”来设置文件密码、权限和数字签名等。
此外,Adobe Acrobat还支持将PDF文件设为只读,以防止其他人对其进行修改。
第六章:合并和拆分PDF文件有时,用户需要将多个PDF文件合并为一个文件或将一个大的PDF文件拆分为多个文件。

把图片中包含的文字提取出来识别为可编辑的文字/图片pdf文字识别2011-05-31 21:56用扫描仪扫描或用数码相机拍摄的包含文字的图片怎么才能变为可识别的文字呢。
步骤有二:1 图片转换为pdf文件。
2 Pdf文件识别出文字,打开word编辑文字。
注意:拍摄的时候,照片里面的文字和背景区别要明细,图片内容尽量保持整齐和完整,不要有皱褶,不然会影响后面的文字识别,另外,如果用数码相机拍取的话,最好打开闪光灯,保持纸质文档中文字区域的背景色一致。
第一步、图片转换为pdf:有五种方法方法一、用“JPG转PDF转换器”比较快,非常简单。
( /Software/design/zhuanhuantuxiang/1365.html)方法二、用“图片PDF转换精灵pictopdf2006.”也比较快,非常简单。
方法三、用TinyPDF虚拟PDF打印机转换:这里下载:(/softwares/TinyPDF.zip)。
安装完成后,会在系统里安装一台虚拟打印机。
然后选中图片—打印—照片打印—下一步—选中图片—下一步“打印选项”选。
TinyPDF—下一步另存为—pdf文件—完成。
方法四、用PDF_Factory_Pro_v3.52(/read.php?tid=694899)。
安装完成后,会在系统里安装一台虚拟打印机。
然后选中图片—打印—照片打印—下一步—选中图片—下一步“打印选项”选PDF_Factory_Pro—下一步—弹出PDF_Factory_Pro窗口--另存为—pdf文件—完成。
方法五:用Office 2003中自带的Microsoft Office Document Imaging工具。
安装以后实际上在office工具里有两个组件:“Microsoft Office Document Scanning”为扫描组件、“Microsoft Office Document Imaging”为图像组件。
(一般的office2003中都带。

快速提取文字的方法
提取文字的方法有很多种,这里列举几种常见的方法:
1. 使用OCR(光学字符识别)技术:通过扫描文档或拍摄照片,然后使用OCR软件将其转换为文本。
这种方法对于纸质文档非常有效,但可能需要一些校对和修正。
2. 使用截图工具:许多设备和操作系统都自带截图工具,可以截取屏幕上的任何区域,并将其保存为图片或PDF文件。
然后,可以使用OCR软件将截图转换为文本。
3. 使用手机相机拍摄:通过手机相机拍摄文档,然后使用手机上的OCR应用将其转换为文本。
这种方法需要确保拍摄清晰,并且文档背景单一。
4. 使用专业软件:有些专业软件,如Adobe Acrobat等,可以将PDF文件转换为文本,同时保留格式和布局。
5. 使用在线工具:许多在线工具提供免费或付费的OCR服务,如Google Cloud Vision API、Amazon Textract等。
6. 手动输入:如果文档数量不大,最简单的方法可能是手动输入每个字符。
请注意,不同的方法可能适用于不同的场景和需求,需要根据具体情况选择最适合的方法。

OCR文字识别是什么?OCR文字识别就是对图片上的文字内容进行识别,然后输出可以编辑的文本。
当我们的文件都是图片格式且需要提取图片中文字内容,尤其是在需要处理纯图片格式的PDF文件时,就需要使用到OCR文字识别功能。
那么有什么软件具备OCR文字识别功能?该怎样操作才能完整提取出纯图片格式的PDF文件中的文字内容?我给大家分享两个方法。
第一个方法是使用PDF转换器。
嗨格式PDF转换器中就有OCR文字识别功能。
打开嗨格式PDF转换器后,我们点击“PDF转文件”。
然后可以选择“PDF转Word”或者“PDF转TXT”。
分别点击这两个转换功能,都可以看到它们的界面上的“OCR 文字识别”。
我以“PDF转Word为例”,给大家讲一下下面的操作。
进入PDF转Word界面后,我们就需要先将纯图片格式的PDF文件添加进界面的转换区域,点击一下中间会直接出现一个打开文件的对话框。
纯图片格式的PDF文件较多的话,在添加文件时全选进行高效的批量转换即可。
文件添加后,启用“OCR文字识别功能”。
转化模式也可以选择一下。
最后我们就只需要点击“开始转换”就好了。
PDF文件稍后会转换成Word 文档,纯图片格式PDF文件中的文字内容就这样简单的提取出来了。
想要提取纯图片格式PDF文件中的文字内容还有一个方法,我们可以使用图像文字识别工具。
首先需要打开PDF文件,然后找到电脑中的截图工具对PDF文件中的文字部分进行截图。
保存一下截好的图片,接着我们打开图像文字识别工具。
将图片上传到识别工具中,工具会自动识别图片中的文字。
识别出的文字会出现在下方的方框中,我们点击一下方框下的“复制内容”。
最后将文字内容粘贴到指定位置即可。
这个方法也可以实现纯图片格式PDF文件的文字提取,不过相对来说操作较为繁琐,多个PDF文件处理起来效率会很低。
提取出纯图片格式PDF文件中文字内容的方法就分享到这里了。
大家现在应该都了解OCR文字识别功能了吧,有兴趣的小伙伴可以动手操作一下哦~。

文字识别利用Word中的OCR功能提取文字在现代社会中,文字识别(Optical Character Recognition,OCR)技术的广泛应用使得大量的纸质文档得以数字化,进而方便我们进行编辑、储存和分享。
而在实际应用中,我们可以利用Microsoft Word软件中的OCR功能来提取文字内容,实现纸质文档的数字化转化。
本文将介绍如何使用Word中的OCR功能提取文字,并探讨其在实际应用中的价值和潜力。
一、什么是OCR技术OCR技术是一种将纸质文档或图片中的文字转化为可编辑和可搜索的电子文件的技术。
通过对图像进行分析与处理,OCR可以自动识别文字信息并进行文字转换,使得之前需要人工输入的繁琐工作得以自动化。
OCR技术目前已得到广泛应用,包括扫描文档转为可编辑文件、自动识别车牌号码、识别手写文字等。
二、Word中的OCR功能Microsoft Word软件是一款功能强大的文字处理工具,它不仅能够编辑和排版文字,还提供了OCR功能来处理纸质文档。
通过Word的OCR功能,我们可以将扫描或拍摄的纸质文档转化为可编辑的Word文档,从而方便我们进行后续的编辑和管理。
使用Word的OCR功能提取文字的步骤如下:1. 打开Word软件并创建一个新的文档。
2. 在菜单栏中选择“插入”选项,然后点击“图片”按钮。
3. 选择纸质文档的扫描件或照片,并确认插入。
4. 在插入的图片上右键点击,并选择“图片识别”选项。
5. 在弹出的对话框中,选择“从图片复制文本”。
6. Word将使用OCR技术对图片进行分析,并将文字内容自动提取并复制到文档中。
通过以上步骤,我们可以快速将纸质文档中的文字转化为可编辑的文本,实现数字化处理。
三、OCR技术的应用价值1. 文档数字化:OCR技术可以将纸质文档转化为电子文件,减少了纸张的使用和存储空间的占用,方便进行文档的传输、备份和管理。
2. 文字编辑与翻译:通过OCR提取出的文字内容,我们可以进行文字编辑、修改和翻译,极大地提高了工作效率和准确性。

光学字符识别技术OCR(Optical Character Recognition的简称),是自动识别技术研究和应用中的一个重要领域,我们识别图片中的文字,用的就是OCR技术。
目前有很多OCR识别软件,例如Office Document Imaging、汉王OCR,清华紫光OCR、尚书6号等等。
但需要注意,通常OCR软件只能够识别比较规范的印刷体,手写文本目前在识别上仍有困难。
下面简单介绍一下几款OCR识别软件及使用方法。
方法一、利用Office Document Imaging 提取文字Office在2003版中增加了Document Imaging工具,用它可以把文字给“抠”出来。
注意:Microsoft Office Document Imaging不是Office 2003默认的安装选项,初次启用时,如果该组件未安装,则需要插入Office的安装光盘进行安装。
使用方法1、在“文件”中打开图片,若是提取扫描仪中的印刷品文字,选择“扫描新文档”,即可将印刷品的文字扫描到电脑上。
2、工具-->使用OCR识别文本,OCR识别程序就会对图片进行识别,完成后选择:工具-->将文本发送到Word ,程序会自动打开Word文档,展现在你面前的就是从图片中“抠”出来的文字。
注意事项1、若图片中是英文,可在工具-->选项-->OCR-->OCR 语言,选择english,再进行识别。
2、Office Document Imaging只支持MDI、TIF等图片格式。
如需识别其他格式的图片,需要利用图片处理软件转换一下,或者利用Office Document Imaging 组件中的“Microsoft Office Document Imaging Writer”的虚拟打印机,将图片打印成一个MDI文件,然后再进行识别。
方法二、使用文字识别工具提取文字1、清华紫光OCR用法简介1)打开带有文字的图片,根据所要提取的文字进行裁剪(如果是电子书籍,可按下“Print Screerl”屏幕捕获键将其保存为图片)。

如何从图片中提取文字如何从图片中提取文字2011-05-19 13:30现在许多网站都有电子书下载,常见的格式有exe、chm、pdf等。
为了保护作者的权益,这些电子书可以看,但是其中的内容却不能进行复制,因为它就像一幅图片一样。
如果我们需要使用这些资料中的文本内容的话,是不是就一定要重新输入一遍呢?当然不用这么麻烦。
下面就为大家介绍将这些内容从资料中提取出来的方法。
用SnagIt工具进行文字提取。
SnagIt是一款功能强大的图片捕捉工具,但是很多朋友可能不知道,它还有文字捕捉的功能,能将文字从图片中提取出来。
SnagIt(屏幕捕捉程序)v8.1汉化绿色版:SnagIt当前版本为7.02,大小为8903KB,下载地址可以在找到,汉化补丁可以在找到。
启动SnagIt,选择菜单"输入/区域",选择菜单"工具/文字捕获",然后我们打开要捕捉的文件窗口,按下捕捉快捷键,选定捕捉区域即可捕捉到文字。
在左侧选中"窗口文字"(如图),在左侧选择输入位置(比如屏幕、区域、窗口等),输出位置(比如打印机、剪贴板、文件等)。
设置完成后,.回到要捕捉文字的文件窗口,按下"捕获"快捷键,即可将文字提取出来。
接着用相应工具重排文字。
此时我们发现提取的文字可能会有很多空格或段落错乱等现象,而且字号、字体等不合自己的心意。
这时我们可以用熟悉的WPS或Word软件进行重新编排。
我们以WPSOffice2003为例看看如何对付提取后文章的编排:用WPSOffice2003打开提取文章;然后选择"工具"菜单下的"文字"/"段落重排",这时你会看到提取文章重新进行排版;接下来选择"工具"菜单下的"文字"/"删除段首空格"命令,使得文章的每段参差不齐的行首空格被删除;再选择"工具"菜单下的"文字"/"增加段首空格",文章变为正常的书写格式;提取文章一般都留有空段,为删除这些空段,继续选择"工具"菜单下的"文字"/"删除空段"命令,这时文章完全变为我们所要的形式;用你熟悉的界面任意编辑文章吧。

ocr用户使用手册OCR(Optical Character Recognition)用户使用手册欢迎使用OCR技术,该技术可以将纸质文档上的文字转换为可编辑和可搜索的电子文本。
以下是OCR用户使用手册的步骤和说明:步骤1:安装OCR软件首先,您需要安装一款OCR软件。
常见的OCR软件包括Adobe Acrobat、ABBYY FineReader、Tesseract等。
根据您的需求和预算选择最适合的软件,并按照其安装向导进行安装。
步骤2:准备要识别的文档将待识别的纸质文档放在扫描仪或拍照设备上,确保图像清晰且文字易于辨认。
如果您已有电子文档,可以跳过此步骤。
步骤3:使用OCR软件进行识别打开OCR软件,并加载要进行文字识别的图像或文档。
根据软件界面的指引,选择OCR功能或选项,并开始识别过程。
识别的具体步骤可能因软件而异,通常包括预处理图像、选择识别语言、识别文字等操作。
步骤4:编辑识别的文本(如有必要)一旦OCR完成识别过程,您会得到一个可编辑的文本文件或电子文档。
检查并编辑识别的文本,纠正可能的错误或误识别。
OCR软件通常也提供文本编辑工具,使您能够直接在软件中进行修改。
步骤5:保存和导出结果完成编辑后,保存您的工作并选择适当的文件格式以导出结果。
常见的文件格式包括PDF、DOC、TXT等。
您还可以选择将导出结果保存到云存储或其他位置以进行备份和共享。
注意事项:- 确保图像清晰:使用高质量的扫描仪或拍照设备捕捉图像,并确保图像清晰可辨认。
- 选择正确的语言:在进行OCR识别之前,确保选择了正确的语言设置。
某些OCR软件还支持多种语言的同时识别。
- 编辑识别的文本:请注意检查和编辑识别的文本,因为OCR 软件可能存在误识别的情况。
尤其是对于手写文本、模糊图像或低质量的扫描件,可能需要更多的编辑工作。
希望本OCR用户使用手册能够帮助您顺利进行文字识别和转换工作。
如有其他问题,请及时咨询OCR软件的用户手册或其官方网站的支持页面。

Adobe Acrobat高效PDF编辑与转换技巧PDF是现代电子文档的重要形式,但有时候我们需要编辑或转换PDF文件。
Adobe Acrobat是一个功能强大的工具,为用户提供了广泛的PDF编辑和转换功能。
在本文中,我们将介绍一些高效的Adobe Acrobat技巧,帮助您编辑和转换PDF文件。
1. 编辑文本在Adobe Acrobat中,您可以轻松地编辑PDF文件中的文本。
只需选择“工具”->“编辑PDF”->“编辑文本”,然后单击要编辑的文本。
您可以修改文本的内容、大小和字体,以及调整文本的对齐方式和颜色。
此外,您还可以将文本设置为静态和可编辑状态。
2. 合并PDF文件在Adobe Acrobat中,您可以将多个PDF文件合并为一个文件。
只需选择“文件”->“创建”->“合并PDF文件”,然后单击要合并的文件,即可创建一个新的合并文件。
您还可以对新文件进行排序,以确保它们按您想要的方式出现。
3. 从PDF文件中提取页面您可以从PDF文件中提取一个或多个页面,然后将其另存为新文件。
选择“工具”->“页面”->“提取”,然后选择要提取的页面。
在“选项”中,您可以设置要提取的页面范围,并为新文件指定名称和保存位置。
4. 裁剪页面如果PDF文件中的页面过大,您可以使用Adobe Acrobat裁剪页面。
只需选择“工具”->“页面”->“裁剪页面”,然后选择要裁剪的页面。
您可以手动调整边框,也可以使用预设设置来裁剪页面。
5. 将PDF文件转换为其他格式在Adobe Acrobat中,您可以轻松地将PDF文件转换为其他格式,例如Word、Excel或HTML。
选择“文件”->“创建”->“PDF转换”,然后选择要转换的文件,并选择要转换为的格式。
在“选项”中,您可以选择转换的页面范围和转换后文件的设置。
6. OCR扫描PDF文件如果您有一个扫描的PDF文件,但其中的文本不能被编辑或搜索,您可以使用Optical Character Recognition(OCR)功能来自动识别文本并将其转换为可编辑的格式。

ocr的使用方法一、OCR是啥玩意儿1.1 OCR啊,就是光学字符识别(Optical Character Recognition)的缩写。
简单来说呢,这东西就像是一个超级智能的小助手,能够把图片或者扫描件里的文字给识别出来,变成咱们可以编辑的文字内容。
比如说你看到一张特别好看的手写便签的照片,想把上面的文字保存下来,OCR就能派上大用场啦。
1.2 这就好比是给计算机装上了一双能够认字的眼睛。
以前啊,计算机只能识别那些已经输入好的电子文字,对于图片里的文字那是两眼一抹黑。
现在有了OCR,就像是打开了一扇新的大门,让计算机能够“看”懂图片里的文字内容了。
二、OCR咋用呢2.1 首先得找个合适的OCR工具。
现在市面上有不少这样的工具呢,有些是专门的软件,有些是手机APP。
就像“条条大路通罗马”,不管是哪种形式,只要能满足你的需求就成。
比如说“ABBYY FineReader”,这可是OCR界的老大哥了,功能很强大。
还有一些在线的OCR工具,像Smallpdf,用起来也挺方便的。
2.2 有了工具之后呢,就开始操作啦。
如果是软件或者APP,一般就是先把要识别的图片或者扫描件给导进去。
这就跟把食材放进锅里一样,是第一步。
要是在线的OCR工具,那就按照它的提示,把文件上传上去。
然后呢,就等着它识别。
这个过程就像是等待面包出炉一样,有点小期待。
2.3 识别完了之后,可别以为就万事大吉了。
有时候啊,这识别出来的文字可能会有点小错误,毕竟这OCR也不是神仙嘛。
所以得检查检查,就像咱们做完数学题得检查对错一样。
如果有错误,就手动改一改,把那些识别错的字给纠正过来。
三、OCR使用的小窍门3.1 图片的质量很关键。
如果图片模糊不清,就像雾里看花一样,那OCR识别起来就会很费劲,甚至可能识别错误。
所以啊,尽量保证图片清晰,光线均匀。
这就好比是给OCR创造一个良好的工作环境,它才能更好地发挥作用。
3.2 不同的OCR工具可能对不同类型的文字有不同的识别效果。

mac ocr翻译Mac OCR翻译是指在Mac操作系统上使用OCR(Optical Character Recognition,光学字符识别)技术进行文字识别和翻译的过程。
OCR技术可以将图像中的文字转换成可编辑的文本,然后利用翻译软件将文本翻译成其他语言。
在Mac上,有多种方法可以实现OCR翻译:1. 使用内置的预览应用程序,Mac的预览应用程序具有OCR功能。
打开预览应用程序,然后选择“文件”菜单中的“导入”选项,选择要进行OCR的图像文件。
接下来,选择“工具”菜单中的“文字”选项,预览将自动识别图像中的文字。
然后,你可以将识别出的文字复制到翻译软件或在线翻译网站进行翻译。
2. 使用第三方OCR软件,在Mac上有许多第三方OCR软件可供选择,例如ABBYY FineReader、Adobe Acrobat等。
这些软件通常具有更高的识别准确性和更多的功能。
你可以安装并使用这些软件来进行OCR翻译。
3. 使用在线OCR服务,还有一些在线OCR服务可以在Mac上使用,例如Google OCR、百度OCR等。
你只需将图像上传到这些服务的网站,它们会自动识别图像中的文字,并提供文本输出。
然后,你可以将输出的文本复制到翻译软件或在线翻译网站进行翻译。
当你获得了OCR识别的文本后,可以使用各种翻译软件或在线翻译网站将文本翻译成其他语言。
常用的在线翻译网站包括Google 翻译、百度翻译、有道翻译等。
此外,还有一些翻译软件可以在Mac上安装和使用,例如Microsoft Translator、DeepL等。
总结来说,Mac OCR翻译可以通过预览应用程序、第三方OCR 软件或在线OCR服务来实现文字识别,然后利用翻译软件或在线翻译网站进行翻译。
这样可以帮助你将图像中的文字快速准确地翻译成其他语言。
Acrobat OCR识别文本功能提取图片文字
来源:发布时间:12-04-11编辑:李静
Acrobat自带的OCR识别文本功能,可以将图片格式的PDF文件(扫描件或者图片制作)转换成文本文件,从而提取图片中的文字。
您可使用Acrobat识别以前已转换成PDF 扫描文档的文本。
光学字符识别(OCR)软件允许您搜索、更正和复制扫描的PDF中的文本。
要将OCR应用于PDF,必须已经将原始扫描仪分辨率设置为72dpi或更高。
首先确保电脑已安装AdobeAcrobat。
OCR识别文本功能的设置
1、识别单个文档中的文本
打开扫描的PDF。
选择“文档”>“OCR文本识别”>“使用OCR识别文本”。
在“识别文本”对话框中,选择“页面”下的一个选项。
(可选)单击“编辑”打开“识别文本-设置”对话框,然后按需要指定选项。
2、识别多个文档中的文本
在Acrobat中,选择“文档”>“OCR文本识别”>“使用OCR识别多个文件中的文本”。
在“页面捕捉多个文件”对话框中,单击“添加文件”,选择“添加文件”,“添加文件夹”或“添加打开的文件”。
然后选择相应的文件或文件夹。
在“输出选项”对话框中,指定输出文件的目标文件夹、文件名首选项以及输出格式。
在“识别文本-设置”对话框中,指定选项,然后单击“确定”。
3、识别PDF包中组件PDF中的文本
在PDF包中选择一个或多个扫描的PDF。
选择“文档”>“OCR文本识别”>“使用OCR识别文本”。
在“识别文本-设置”对话框中指定选项。
OCR识别文本功能的使用
1.捕获扫描页面
通过Acrobat的“使用OCR识别文本”功能可以将扫描页面由图像转换成可搜索的PDF 文档。
Acrobat允许以3种格式捕获扫描页面:格式化的文本和图形PDF、可搜索的图像PDF (精确)以及可搜索的图像PDF(紧凑)。
可搜索的图像PDF在PDF文档中将扫描图像放在前景中,而将捕获的文本放在不可见的背景层中。
捕获扫描页面的具体步骤如下所述:
(1)选择“文档>使用OCR识别文本>开始”命令,弹出“识别文本”对话框。
(2)选择要捕获的页面。
(3)单击“编辑”按钮,弹出“识别文本-设置”对话框,选择“OCR识别的主要语言”和“PDF输出样式”选项,然后单击“确定”按钮。
(4)单击“确定”按钮开始OCR识别文本过程。
使用OCR识别文本不仅可将扫描页面中的文字内容转换成可搜索文本,另外还可以校正由于在扫描过程中导致的页面歪斜。
2.修正转化文本
Acrobat在识别扫描页面是,可能由于字迹模糊等原因不能正确识别文本,Acrobat将对存在疑点处标记为“捕获疑点”。
被标记为“捕获疑点”之处以文字捕获前的位图显示,而该文字的替换字符则在一个不可见的底层上。
选择“文档>使用OCR识别文本>查找所有的OCR可疑物”命令,所有标记为“捕获疑
点”之处以红色线框显示。
选择“文档>使用OCR识别文本>查找第一个OCR可疑物”命令,弹出“查找元素”对话框。
单击“查找下一个”按钮,疑点处的位图依次显示在该对话框中,同时当前工具切换到“TouchUp文本工具”,并选中替换的文本,如果替换文本没有错误,可以单击“接受和查找”按钮,疑点处的位图将被接受的文本替换显示,如果替换文本不正确,可以使用“TouchUp文本工具”先进行修正,然后再单击“接受和查找”按钮进行确认。