proc rank 语句
- 格式:docx
- 大小:16.25 KB
- 文档页数:3

第二十八课 Wilcoxon 秩和检验一、 两样本的Wilcoxon 秩和检验由Mann ,Whitney 和Wilcoxon 三人共同设计的一种检验,有时也称为Wilcoxon 秩和检验,用来决定两个独立样本是否来自相同的或相等的总体。
如果这两个独立样本来自正态分布和具有相同方差时,我们可以采用t 检验比较均值。
但当这两个条件都不能确定时,我们常替换t 检验法为Wilcoxon 秩和检验。
Wilcoxon 秩和检验是基于样本数据秩和。
先将两样本看成是单一样本(混合样本)然后由小到大排列观察值统一编秩。
如果原假设两个独立样本来自相同的总体为真,那么秩将大约均匀分布在两个样本中,即小的、中等的、大的秩值应该大约均匀被分在两个样本中。
如果备选假设两个独立样本来自不相同的总体为真,那么其中一个样本将会有更多的小秩值,这样就会得到一个较小的秩和;另一个样本将会有更多的大秩值,因此就会得到一个较大的秩和。
设两个独立样本为:第一个x 的样本容量为1n ,第二个y 样本容量为2n ,在容量为21n n n +=的混合样本(第一个和第二个)中,x 样本的秩和为x W ,y 样本的秩和为y W ,且有2)1(21+=+++=+n n n W W y x (28.1)我们定义2)1(111+-=n n W W x (28.2)2)1(222+-=n n W W y (28.3)以x 样本为例,若它们在混合样本中享有最小的1n 个秩,于是2)1(11+=n n W x ,也是x W 可能取的最小值;同样y W 可能取的最小值为2)1(22+n n 。
那么,x W 的最大取值等于混合样本的总秩和减去y W 的最小值,即2)1(2)1(22+-+n n n n ;同样,y W 的最大取值等于2)1(2)1(11+-+n n n n 。
所以,(28.2)和(28.3)式中的1W 和2W 均为取值在0与2122112)1(2)1(2)1(n n n n n n n n =+-+-+的变量。

附录A 习题答案习题1答案1.什么是观测值OBS?答:一份问卷、一个单一的整体、一个人、一个被测对象就是一个观测值,或称一个“个案”。
每个个案是由若干变量组成。
2. 什么是变量Variable?一份问卷一般有几个甚至几十个问答题,一个问答题就是一个变量。
如id、sex、age、location、income等。
3.下面的变量名哪些有效?哪些无效?sex、age、v1、location、_ab_、1age、1v、location1、@1、#1、%1、&2答:(1)有效的变量名是由1-8个有效字符组成且字母领头,后跟数字或有效的字母。
但字母@、#、$、%、^、&、*等是无效的字符。
比如:sex、age、v1、location、_ab_等变量名是正确的;(2)无效的变量名:1age、1v、location1、@1、#1、%1、&2等。
4.变量有哪些类型?答:变量有2种类型。
数字型:如INPUT id sex age;字符型:如“INPUT id sex $ age;”中的“sex $”表示性别是以m=男性,f=女性表示的。
5.给下面程序A.1a改错。
程序A.1a:DATA sj5; INPUT a b c @@; IF 4=<a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/ OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;解答:错在第3条语句上。
改错后的程序见程序A.1b。
程序A.1b:DATA sj5; INPUT a b c @@; IF a>=4 & a<15 THEN GOTO OK; a=3; COUNT+1; RETURN; /*RETURN(返回)到DATA步执行它下面的语句*/OK:SUMa+a; CARDS;3 6 9 10 22 15 12 10 14 ; PROC PRINT; RUN;习题2答案1.指出下列命令的作用。

20个SAS过程步
1、PROC
MEANS--数据描述:计算均数、标准差、最大值、最小值、变量有效数据个数、变量缺失个数
2、PROC UNIV ARIATE--正态性检验
3、PROC TTEST--两独立样本检验
4、PROC NPAR1WAR--秩和检验
5、PROC ANOV A--方差分析
6、PROC CORR--相关性分析
7、PROC REG--回归分析
8、PROC FREQ--计数资料描述;卡方检验;诊断试验
9、PROC LOGISTIC--结局是二分类的Logisitc回归分析
10、PROC PHREG--生存分析
11、PROC POWER--样本量及把握度计算
12、PROC PRINT--显示数据集
13、PROC GLM--回归分析或协方差分析
14、PROC RANK--给某变量排次或按序分组
15、PROC SORT--按某变量排序
16、PROC SURVEYSELECT--概率抽样
17、PORC IMPORT--导入数据集
18、PROC EXPORT--导出数据集
19、PROC CONTENTS--产生一个数据集的头文件,包含了多种该数据集的信息
20、PROC TABULATE--输出报表。

proc sql语句摘要:1.Proc sql 语句简介2.Proc sql 语句的语法结构3.Proc sql 语句的应用示例4.Proc sql 语句的优缺点正文:【一、Proc sql 语句简介】Proc sql 语句是一种在计算机编程中使用的SQL(结构化查询语言)语句,主要用于对数据库进行操作,如查询、插入、更新和删除等。
它可以在程序中实现对数据库的自动化操作,简化了程序员对数据库的处理流程,提高了工作效率。
【二、Proc sql 语句的语法结构】Proc sql 语句的语法结构相对简单,通常由以下几个部分组成:1.创建proc sql 语句的声明:使用CREATE PROCEDURE 语句来定义一个proc sql 语句,例如:CREATE PROCEDURE my_proc()2.Proc sql 语句的执行:使用CALL 语句来执行proc sql 语句,例如:CALL my_proc()3.Proc sql 语句的参数:可以在创建proc sql 语句时定义参数,以便在执行时传递数据,例如:CREATE PROCEDURE my_proc(IN param1 INT, OUT param2 INT)4.Proc sql 语句的逻辑:主要包括SQL 语句,如SELECT、INSERT、UPDATE 和DELETE 等,以及相关的逻辑控制语句,如IF、ELSE、WHEN 等。
【三、Proc sql 语句的应用示例】以下是一个简单的Proc sql 语句应用示例,用于查询数据库中的数据并输出结果:```-- 创建proc sql 语句CREATE PROCEDURE query_data()BEGIN-- 执行SQL 语句查询数据SELECT * FROM my_table;END;-- 执行proc sql 语句CALL query_data();```【四、Proc sql 语句的优缺点】1.优点:(1)简化了程序员对数据库的操作,提高了工作效率;(2)有助于实现代码的模块化,便于维护和调试;(3)可以减少SQL 语句重复编写,提高代码复用性。

procrank工作原理procrank工作原理简介procrank是一款用于分析Android系统内存使用情况的工具。
它可以提供详细的进程和内存信息,帮助开发者识别和解决内存泄漏等问题。
本文将深入解释procrank的工作原理。
1. procrank的作用procrank主要用于以下方面:•分析内存使用情况•识别内存泄漏问题•监控进程的内存变化•帮助优化应用程序的内存管理2. procrank的工作原理procrank通过读取/proc目录下的文件,获取系统中的进程和内存信息。
具体来说,它使用了以下原理:/proc目录/proc目录是一个在Linux系统中特有的虚拟文件系统,它提供了访问系统内核和进程信息的接口。
procrank利用了/proc目录下的一些文件来获取系统中进程和内存的相关信息。
smaps文件smaps文件是/proc/[pid]/smaps路径下的文件,其中pid代表进程的ID。
smaps文件中包含了进程的内存映射信息,包括每个内存区域的起始地址、大小、权限等。
procrank会读取每个进程的smaps文件,分析内存映射信息,来获得进程在内存中的占用情况。
pagemap文件pagemap文件是/proc/[pid]/pagemap路径下的文件,其中pid代表进程的ID。
pagemap文件提供了进程使用的物理页面信息。
procrank会读取pagemap文件,与smaps文件中的内存映射信息相结合,计算出进程占用的物理内存大小。
分析进程信息通过读取/proc目录下的相关文件,并结合其他信息(如进程ID、名称等),procrank会分析每个进程的内存使用情况。
它可以计算出进程的虚拟内存大小、物理内存大小、共享内存大小等,并展示给开发者进行分析。
3. 使用procrank使用procrank主要有以下几个步骤:1.获取设备的root权限。
2.连接到设备的shell终端。
3.运行procrank命令,获取系统中的进程和内存信息。

选择题:SAS语言中,用于创建新数据集的关键字是:A. DATA(正确答案)B. SETC. PROCD. LIBRARY在SAS程序中,用于读取外部数据文件的关键字是:A. INPUTB. INFILE(正确答案)C. FILED. READSAS中,用于计算变量总和的函数是:A. SUM(正确答案)B. AVGC. TOTALD. ADD下列哪个语句用于在SAS中创建直方图?A. PROC PRINT;B. PROC UNIVARIATE; HISTOGRAM; (正确答案)C. PROC FREQ;D. PROC MEANS;在SAS中,用于对数据集进行排序的过程步骤是:A. PROC SORT; (正确答案)B. PROC RANK;C. PROC ORDER;D. PROC ARRANGE;SAS语言中,用于合并两个数据集的关键字是:A. MERGE(正确答案)B. COMBINEC. JOIND. CONCATENATE下列哪个选项不是SAS中的循环语句?A. %DO %END;(正确答案)B. DO UNTIL; END;C. DO WHILE; END;D. DO OVER; END;在SAS中,用于计算描述性统计量的过程步骤是:A. PROC UNIVARIATE;B. PROC MEANS;(正确答案)C. PROC FREQ;D. PROC SORT;SAS程序中,用于声明局部宏变量的关键字是:A. %LET;(正确答案)B. %GLOBALC. %LOCALD. %VAR。

bugreport1.概述:bugreport记录android启动过程的log,以及启动后的系统状态,包括进程列表,内存信息,VM信息等等到。
2.结构:(1)dumpstateMEMORY INFO获取该log:读取文件/proc/meminfo系统内存使用状态CPU INFO获取该log:执行/system/bin/top -n 1 -d 1 -m 30 -t系统CPU使用状态PROCRANK获取该log:执行/system/bin/procrank执行/system/xbin/procrank后输出的结果,查看一些内存使用状态VIRTUAL MEMORY STATS获取该log:读取文件/proc/vmstat虚拟内存分配情况vmalloc申请的内存则位于vmalloc_start~vmalloc_end之间,与物理地址没有简单的转换关系,虽然在逻辑上它们也是连续的,但是在物理上它们不要求连续。
VMALLOC INFO获取该log:读取文件/proc/vmallocinfo虚拟内存分配情况SLAB INFO获取该log:读取文件/proc/slabinfoSLAB是一种内存分配器.这里输出该分配器的一些信息ZONEINFO获取该log:读取文件/proc/zoneinfozone infoSYSTEM LOG(需要着重分析)获取该log:执行/system/bin/logcat -v time -d *:v会输出在程序中输出的Log,用于分析系统的当前状态VM TRACES获取该log:读取文件/data/anr/traces.txt因为每个程序都是在各自的VM中运行的,这个Log是现实各自VM的一些tracesEVENT LOG TAGS获取该log:读取文件/etc/event-log-tagsEVENT LOG获取该log:执行/system/bin/logcat -b events -v time -d *:v输出一些Event的logRADIO LOG获取该log:执行/system/bin/logcat -b radio -v time -d *:v显示一些无线设备的链接状态,如GSM,PHONE,STK(Satellite Tool Kit)...NETWORK STATE获取该log:执行/system/bin/netcfg (得到网络链接状态)获取该log:读取文件/proc/net/route (得到路由状态)显示网络链接和路由SYSTEM PROPERTIES获取该log:参考代码实现显示一些系统属性,如Version,Services,network...KERNEL LOG获取该log:执行/system/bin/dmesg显示Android内核输出的LogKERNEL WAKELOCKS获取该log:读取文件/proc/wakelocks内核对一些程式和服务唤醒和休眠的一些记录KERNEL CPUFREQ(Linux kernel CPUfreq subsystem) Clock scaling allows you to change the clock speed of the CPUs on the fly.This is a nice method to save battery power, because the lower the clock speed is, the less power the CPU consumes.PROCESSES获取该log:执行ps -P显示当前进程PROCESSES AND THREADS获取该log:执行ps -t -p -P显示当前进程和线程LIBRANK获取该log:执行/system/xbin/librank剔除不必要的libraryBINDER FAILED TRANSACTION LOG获取该log:读取文件/proc/binder/failed_transaction_logBINDER TRANSACTION LOG获取该log:读取文件/proc/binder/transaction_logBINDER TRANSACTIONS获取该log:读取文件/proc/binder/transactionsBINDER STATS获取该log:读取文件/proc/binder/statsBINDER PROCESS STATE获取该log:读取文件/proc/binder/proc/*bind相关的一些状态FILESYSTEMS获取该log:执行/system/bin/df主要文件的一些容量使用状态(cache,sqlite,dev...)PACKAGE SETTINGS获取该log:读取文件/data/system/packages.xml系统中package的一些状态(访问权限,路径...),类似Windows里面的一些lnk文件吧. PACKAGE UID ERRORS获取该log:读取文件/data/system/uiderrors.txt错误信息KERNEL LAST KMSG LOG最新kernel message logLAST RADIO LOG最新radio logKERNEL PANIC CONSOLE LOGKERNEL PANIC THREADS LOG控制台/线程的一些错误信息logBACKLIGHTS获取该log:获取LCD brightness读/sys/class/leds/lcd-backlight/brightness获取该log:获取Button brightness读/sys/class/leds/button-backlight/brightness获取该log:获取Keyboard brightness读/sys/class/leds/keyboard-backlight/brightness获取该log:获取ALS mode读/sys/class/leds/lcd-backlight/als获取该log:获取LCD driver registers读/sys/class/leds/lcd-backlight/registers获取相关亮度的一些信息(2)build.propVERSION INFO输出下列信息当前时间当前内核版本:可以读取文件(/proc/version)获得显示当前命令:可以读取文件夹(/proc/cmdline)获得显示系统build的一些属性:可以读取文件(/system/build.prop)获得输出系统一些属性gsm.version.ril-implgsm.version.basebandgsm.imeigsm.sim.operator.numericgsm.operator.alpha(3)dumpsys执行/system/bin/dumpsys后可以获得这个log.经常会发现该log输出不完整,因为代码里面要求该工具最多只执行60ms,可能会导致log无法完全输出来.可以通过修改时间参数来保证log完全输出.信息:Currently running servicesDUMP OF SERVICE services-name(running)。


1.内存占用对于智能手机而言,内存大小是固定的;因此,如果单个app的内存占用越小,手机上可以安装运行的app就越多;或者说app的内存占用越小,在手机上运行就会越流畅。
所以说,内存占用的大小,也是考量app性能的一个重要指标2.原理说明对于一个app,我们可以关注它在3种状态下的内存占用情况:空负荷————app已经在后台运行,但是用户没有使用;中负荷————app在前台运行,用户进行了少量操作;满负荷————用户持续频繁大量操作,app接近饱和状态运行。
然而,除了第一种情况,其它两种的主观性很强,不是很容易区分。
正常产品测试的时候,只要验证后台运行(5~10分钟为宜)和用户持续频繁大量操作(10~15分钟为宜)这两种情况下就可以了。
这样一来,就变成了如何持续统计并记录app所占内存的问题。
Procrank工具可以实现这个功能。
3.procrank的安装1)下载procrank压缩包,下载地址:/download/yincheng886337/94335382)解压,将procrank文件push到手机的 /system/xbin目录下;命令:adb push procrank /system/xbin将procmem文件push到手机的 /system/xbin目录下;命令:adb push procmem /system/xbin将libpagemap.so文件push到手机的 /system/lib目录下;命令:adb push libpagemap.so /system/lib3)进入adb shell,获取root权限,分别给procrank、procmem、libpagemap.so 三个文件777权限,如下:chmod 777 /system/xbin/procrankchmod 777 /system/xbin/procmemchmod 777 /system/xbin/libpagemap.so如果push不进三个文件或者修改不了三个文件的权限,那重新挂载一下system,再修改三个文件的权限,如下:mount -o remount,rw /system4. procrank各项值解析进入adb shell,获取root权限,输入命令:procrank即可,如下图:VSS - Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)RSS - Resident Set Size 实际使用物理内存(包含共享库占用的内存) PSS - Proportional Set Size 实际使用的物理内存(比例分配共享库占用的内存)USS - Unique Set Size 进程独自占用的物理内存(不包含共享库占用的内存)VSS和USS对查看某一进程自身的内存状况没什么作用,因为他们包含了共享库的内存使用,而往往共享库的资源占用比重是很大的,这样就稀释了对Process 自身创建内存波动。

用ADB命令解决手机替换系统文件导致死机或无限重启基础知识:adb 介绍adb的全称为Android Debug Bridge 调试桥,是连接Android手机与PC端的桥梁,通过adb可以管理、操作模拟器和设备,如安装软件、系统升级、运行shell命令等。
管理设备注:android手机、模拟器统一称为“设备”adb devices // 显示连接到计算机的设备adb get-serialno // 获取设备的ID和序列号serialNumber------------------重启----------------------------------------------adb reboot // 重启设备adb reboot bootloader // 重启到bootloader,即刷机模式adb reboot recovery // 重启到recovery,即恢复模式------------------发送命令到设备--------------------------------------adb [-d|-e|-s <serialNumber>] <command>-d 发送命令给usb连接的设备-e 发送命令到模拟器设备-s <serialNumber> 发送命令到指定设备adb相关adb kill-server // 终止adb服务进程adb start-server // 重启adb服务进程adb root // 已root权限重启adb服务adb wait-for-device // 在模拟器/设备连接之前把命令转载在adb的命令器中获取设备硬件信息adb shell cat /sys/class/net/wlan0/address // 获取mac地址adb shell cat /proc/cpuinfo // 获取cpu序列号管理设备appaapt d badging <apkfile> // 获取apk的packagename 和classname------------------安装----------------------------------------------adb install <apkfile> // 安装apkadb install -r <apkfile> // 保留数据和缓存文件,重新安装apk,adb install -s <apkfile> // 安装apk到sd卡------------------卸载----------------------------------------------adb uninstall <package> // 卸载appadb uninstall -k <package> // 卸载app但保留数据和缓存文件------------------启动app-------------------------------------------------------------查看内存占用----------------------------------------adb shell top // 查看设备cpu和内存占用情况adb shell top -m 6 // 查看占用内存前6的appadb shell top -n 1 // 刷新一次内存信息,然后返回adb shell procrank // 查询各进程内存使用情况adb shell kill [pid] // 杀死一个进程adb shell ps // 查看进程列表adb shell ps -x [PID] // 查看指定进程状态adb shell service list // 查看后台services信息adb shell cat /proc/meminfo // 查看当前内存占用adb shell cat /proc/iomem // 查看IO内存分区文件操作//android中,sdcard代表内置存储,不同系统中tf卡的设备名可能不同,使用查看adb shell ls mnt查看所有存储设备名。

sas计算auc全文共四篇示例,供读者参考第一篇示例:SAS(统计分析系统)是一种强大的数据分析软件,广泛应用于医学、金融、市场研究等领域。
在数据分析过程中,评估模型的性能是至关重要的一环。
而AUC(Area Under the Curve)是评估分类模型性能的一种常用指标,它表示ROC曲线下的面积,常用来衡量模型的准确性。
在SAS中,计算AUC值有多种方法,本文将介绍几种常用的方法,并使用一个实例来演示如何在SAS中计算AUC值。
一、使用PROC LOGISTIC计算AUC值PROC LOGISTIC是SAS中用于逻辑回归分析的过程。
在进行逻辑回归分析时,可以通过设置ODS输出选项为ROC,来输出ROC曲线信息。
接着可以使用PROC ROCCONTRAST来计算AUC值。
具体步骤如下:1. 导入数据集```sasdata mydata;input x1 x2 y @@;datalines;1.12.2 1 2.33.4 0 3.54.6 1;run;```2. 运行PROC LOGISTIC```sasproc logistic data=mydata;model y= x1 x2;ods output roc=roc_info;run;```3. 运行PROC ROCCONTRAST计算AUC值```sasproc roccompare data=roc_info;roc contrast 'ROC analysis';run;```二、使用PROC SQL计算AUC值另一种计算AUC值的方法是使用PROC SQL,具体步骤如下:1. 生成ROC曲线数据```sasproc logistic data=mydata outroc=roc_info plots=roc; model y= x1 x2;run;```2. 使用PROC SQL计算AUC值```sasproc sql;select c.(c1 a format=5.3) as AUCfrom roc_info;quit;```以上即为使用PROC SQL计算AUC值的简要步骤。

tcl中的proc语句proc语句是Tcl中定义过程的关键字。
过程是一段可复用的代码块,可以通过给定的名称和参数来调用。
在Tcl中,使用proc语句来定义过程,语法如下:```proc procname {args} {body}```其中,procname是过程的名称,args是过程的参数列表,body 是过程的代码块。
下面是关于proc语句的一些示例:1. 示例一:定义一个简单的过程,用于打印Hello World。
```tclproc hello {} {puts "Hello World!"}```2. 示例二:定义一个带参数的过程,用于计算两个数的和。
```tclproc add {num1 num2} {set sum [expr $num1 + $num2]return $sum}```3. 示例三:定义一个带默认参数值的过程,用于计算两个数的乘积。
```tclproc multiply {num1 1 num2 1} {set product [expr $num1 * $num2]return $product}```4. 示例四:定义一个带变长参数的过程,用于计算一组数的平均值。
```tclproc average {args} {set sum 0foreach num $args {set sum [expr $sum + $num]}set avg [expr $sum / [llength $args]]return $avg}```5. 示例五:定义一个过程,用于查找列表中的最大值。
```tclproc max {list} {set max [lindex $list 0]foreach num $list {if {$num > $max} {set max $num}}return $max}```6. 示例六:定义一个过程,用于判断一个数是否为质数。

CLOSE作用:关闭游标。
语法:EXEC SQL CLOSE { cursor | :cursor_variable};参数:√cursor:SQL游标名。
√cursor_variable:PL/SQL游标变量名。
举例:EXEC SQL CLOSE auths_cursor;COMMIT作用:提交事务、释放内存、断开连接。
语法:EXEC SQL [AT { :host_variable | dbname }] COMMIT[WORK] [ { [COMMENT ‘text’] [RELEASE] | [FORCE ‘text’ [:integer] ] } ];参数:√dbname:使用DECLARE DATABASE语句定义,并使用CONNECT语句建立的数据库连接名。
√host_variable:宿主变量字符串,它是使用CONNECT语句建立的数据库连接名。
如果忽略AT 子句,那么使用缺省数据库连接。
√WORK:COMMIT与COMMIT WORK是等价的,使用该参数是为了与标准SQL兼容。
√COMMENT:用于指定与当前事务相关的注释,‘text’是用单引号括起来的不超过50个字符的字符串。
如果当前事务是“受怀疑的”,那么它将与事务ID号一起被存储到数据字典DBA_2PC_PENDING中。
√RELEASE:释放资源,断开连接。
√FORCE:手工提交“受怀疑的”分布式事务,该事务由‘text’所包含的事务ID号来标识,查询数据字典视图DBA_2PC_PENDING可以获得该ID号。
举例:/* 使用DECLARE DATEBASE语句定义aca_db */EXEC SQL AT aca_db COMMIT RELEASE;/* aca_db作为宿主变量使用 */EXEC SQL AT :aca_db COMMIT RELEASE;CONNECT作用:连接到数据库服务器。
语法:EXEC SQL CONNECT { :user IDENTIFIED assword | :user_password }[ AT { :host_variable | dbname }] [USING :server ][ ALTER AUTHORIZATION :new_password ];参数:√user:用户名。

PROC RANK是SAS程序中的一个过程,用于对数据进行排序和排名。
具体来说,PROC RANK可以将数据集中的观测值进行排序,并生成排名变量。
以下是PROC RANK的一些用法:1. 对单个变量进行排序:```sasPROC RANK DATA=dataset VAR=variable OUT=output;RUN;```其中,dataset是输入数据集的名称,variable是要排序的变量名称,output是输出数据集的名称。
2. 对多个变量进行排序:```sasPROC RANK DATA=dataset VAR=var1 var2 var3 OUT=output;RUN;```在上述示例中,多个变量通过空格分隔。
3. 指定排序顺序:```sasPROC RANK DATA=dataset VAR=variable OUT=output NORMAL; RUN;```NORMAL表示升序排序,DESC表示降序排序。
4. 生成排名变量:```sasPROC RANK DATA=dataset VAR=variable OUT=output RANK=rank_var;RUN;```在上述示例中,RANK=rank_var指定了生成排名变量的名称。
5. 使用ranks语句:如果想保留原来的变量值,可以使用ranks语句。
具体如下:```sasPROC RANK DATA=dataset VAR=variable OUT=output;RANKS r_var;RUN;```在上述示例中,r_var是新生成的排名变量。
原来的variable变量值将被保留,同时生成排名变量r_var。

27. 秩和检验〔一〕参数检验与非参数检验通常情况下,对数据进展分析时,总是假定误差项服从正态分布,因为正态分布的原始出发点就是来自于误差分布,至于当样本相当大时,数据的正态近似,这是由于大样本理论所保证的。
但有些资料不一定满足上述要求,或不能测量具体数值,其观察结果往往只有程度上的区别,如颜色的深浅、反响的强弱等,此时就不适用参数检验的方法,而只能用非参数统计方法来处理。
这种方法对数据来自的总体不作任何假设或仅作极少的假设,因此在实用中颇有价值,适用面很广。
一、统计方法分为参数统计和非参数统计参数统计——总体分布类型,对未知参数进展统计推断,依赖于特定分布类型,比拟的是参数;非参数统计——不以特定的总体分布为前提,不对总体参数推断;比拟分布或分布位置;适用围广,可用于任何类型资料〔等级资料〕。
二、参数检验与非参数检验的特点、优缺点、应用比照〔二〕符号检验和Wilcoxon符号秩检验一、单样本的符号检验符号检验,最简单的非参数检验方法,是根据正、负号的个数来假设检验。
符号检验可用于:〔1〕样本中位数和总体中位数的比拟;〔2〕数据的升降趋势的检验;〔3〕特别适用于总体分布不服从正态分布或分布不明的配对资料;〔4〕定性表示的当配对资料〔如试验前后比拟结果为颜色从深变浅、程度从强变弱,成绩从一般变优秀〕。
对于配对资料,符号检验的根本步骤为:首先定义成对数据指定正号或负号的规那么,然后计数:正号的个数S+与负号的个数S-. 注意:不能标记正负号的观察值要从资料中剔除;1. 当小样本〔n≤20〕时,用二项分布〔1〕检验配对资料试验前后有无变化原假设H0:配对资料试验前后无变化〔S+和S-可能性相等〕,正号/负号出现的概率均为p=0.5, 故S+和S-均服从二项分布B(n,0.5).〔2〕检验试验后正号有无增加原假设H0:正号出现的概率p≤0.5. 假设p>0.5那么拒绝H0,说明正号有增加;〔3〕检验试验后正号有无减少原假设H0:正号出现的概率p≥0.5. 假设p<0.5那么拒绝H0,说明正号有减少。
常用抽样SAS程序目前,各医学论坛上都有大量的‘执业医师考题’等内容。
对于选择题而言,最让人感兴趣的是那部分带答案的考题。
显然,希望能做一下,后与答案对照验证和锻炼自己的实际水平。
但是,带答案内容的弊病就是当读者阅读考题时便不由自主的先看了答案,使目的不能达到。
改变这种尴尬状态需要事先把考题和其对应的答案部分分离出来,进行自我测验完毕后再根据需要调配答案自动对照改分。
由于该种抽样一个观测会包含很多的行,加之此后还有拆、合变化实际操作起来会有很大的困难,所以目前,不论是医学杂志亦或是相关网站,还是专业统计学论坛、书籍、杂志针对这样类型的抽样未见。
基于此,本人根据实际使用经验,针对固定格式的txt文件写了sas代码,运行效果满意。
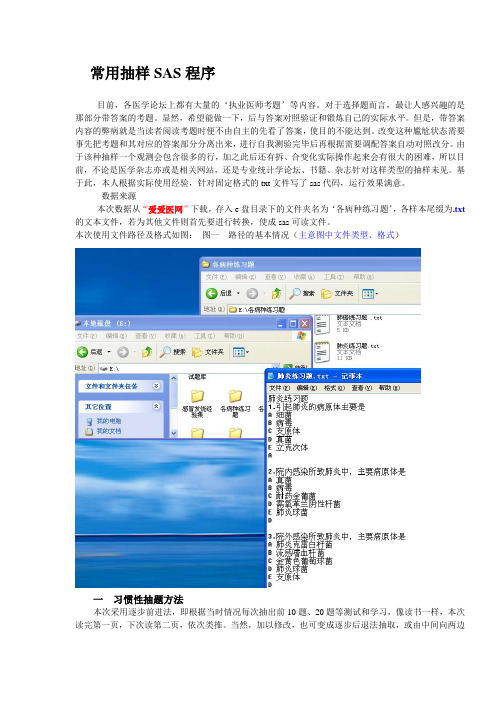
数据来源本次数据从“爱爱医网”下载,存入e盘目录下的文件夹名为‘各病种练习题’,各样本尾缀为.txt 的文本文件,若为其他文件则首先要进行转换,使成sas可读文件。
本次使用文件路径及格式如图:图一路径的基本情况(主意图中文件类型、格式)一习惯性抽题方法本次采用逐步前进法,即根据当时情况每次抽出前10题、20题等测试和学习,像读书一样,本次读完第一页,下次读第二页,依次类推。
当然,加以修改,也可变成逐步后退法抽取,或由中间向两边抽取等。
1 考题和答案的分离处理编程将考题内容输出到output窗口和桌面,而考题答案输出到桌面txt文档供以后需要时调用、打开观。
程序第一部分data a;infile'e:\各病种练习题\肺炎练习题.txt';length x $ 100.;do i=1to7;input x & $;if _n_<=71 | _n_ >91then delete;/*选第11-20题*/output;end;data b(keep=x);set a;file'桌面\试题集内容.txt';where i<7;put x $;data c;set a;file'桌面\试题集答案.txt'; where i=7;put x $;proc print data=b noobs;run;2 答题环境的进一步发展通过以上几步处理,已经达到考题内容与答案分离的目的,可以打开桌面的考题内容进行自测然后与桌面的考题答案对照。

Linux内存工具解析之RSSVSSUSSPSS区别于联系对于Linux系统程序开发人员,经常需要和进程所使用的内存情况打交道,比如,分析程序的内存泄漏问题。
这时候我们可能使用ps、top、procrank、dumpsys(后两个命令为Android系统)来跟踪、调试进程内存的使用情况。
上述几个工具进程涉及到的几个比较的重要的概念:VSS、RSS、PSS、USS,对于这几个概念,大家总是存在一种似曾相识,却又不甚了解的感觉,这对于真正的把握进程内存使用情况是十分有害的。
所以,本文旨在彻底分析这个四个概念,弄清各个量之间的联系和区别,提供有助于解释各种工具的内存报告的信息,以便确定Linux进程和系统的实际内存使用量,为以后分析内存问题提供坚实的理论基础。
基本概念•VSS:Virtual Set Size 虚拟耗用的内存(包含与其他进程共享占用的虚拟内存)•RSS:Resident Set Size 实际使用的物理内存(包含与其他进程共享占用的内存)•PSS:Proportional Set Size 实际使用的物理内存(按比例包含与其他进程共享占用的内存)•USS:Unique Set Size 进程独自占用的物理内存(不包含与其他进程共享占用的内存)对于单个进程,一般来说内存占用大小排序如下:VSS >= RSS >= PSS >= USS概念解析Android有一个名为procrank(/system/xbin/procrank)的工具,它列出了Linux进程的内存使用量,并按使用量的高低排序。
每个进程报告的内存使用情况分为VSS、RSS、PSS和USS。
为了简单起见,在这个描述中,内存将用页面而不是字节来表示。
像我们这样的Linux系统在最低级别上以4096字节的页面管理内存。
下面分别具体解释一下各个概念的含义:1.VSS(ps工具中表示为VSZ)表示进程总的可访问地址空间。

多个样本及其两两比较的秩和检验SAS程序多个样本及其两两比较的秩和检验SAS程序广东医学院预防医学教研室(524023)丁元林孔丹莉秩和检验是医学实践中较为常用的一大类非参数统计方法,目前国内几本较具权威性SAS专著11,22,均介绍了秩和检验的一些SAS程序,宇氏132也作了进一步的探讨和总结,但对于不同资料类型和特征的多个样本比较的秩和检验SAS程序阐述得不够全面,而且几乎未涉及到两两比较的SAS程序,但实际工作者往往对两两比较的结果更为感兴趣。
为此,本文结合实例,根据常见类型资料的特点,给出了多个样本及其两两比较的秩和检验SAS程序。
11成组设计的原始数据多个样本及其两两比较这种类型资料一般为成组设计的定量资料,但各个样本的总体呈偏态分布或方差不齐,且未整理成其他形式(如频数表),检验其总体分布是否相同的常用秩和检验方法是Kruska-l Wallis法,在SAS软件中实现的过程步有以下三种:NPAR1WAY过程、FREQ 过程以及RANK和ANOVA两过程的结合。
各个样本两两比较一般可通过RANK和ANOVA两过程的结合,采用M EANS语句来实现。
对文献142第139页表1中的数据进行Kruska-l Wallis检验及两两比较的SAS程序如下: /*以下为建立数据库*/data dy1;do group=1to3;input x@@;output;end;cards;918016014101211211910162102121310 214215141031121814184113111516510 3171516519319211671441624101316710;/*以下为调用F REQ过程*/proc fr eq;t ables group*x/scores=rank cmh2noprint;/*以下为调用N PAR1WAY过程*/proc npar1way w ilcoxon;class group;v ar x;/*以下为调用RA NK过程*/proc rank data=dy1out=a;v ar x;ranks r;/*以下为调用A NOV A过程*/proc anova;class group;model r=group;means group/lsd;r un;以上程序中调用FREQ过程产生的第二个CMH 统计量、NPAR1WAY过程产生的卡方统计量以及ANOVA过程产生的R2与T 总之积,即为为Kruska-l Wallis检验结果。
Proc rank 的用法(SAS)
proc rank 其实最主要的是掌握那几个选项,该proc 的整体语法结构如下:
proc rank <选项>;
var 变量;
ranks 新变量名字;
by 分组变量;
run;
这是一个整体的语法结构,举例,比如说我要对sashelp中的height排名次:
proc rank data=sashelp.class out=result;
var height;
run;
很显然就是这样写,用var来指定要排名次的变量,但是你运行该程序后会发现一个问题,就是原来的height的值都被名次代替了。
如果我想保留原来的height值,那就需要用ranks 语句了:
proc rank data=sashelp.class out=result;
var height;
ranks r_height;
run;
这样原来的height变量就不会动,生成名次变量r_height,这就是ranks的作用。
接着讲选项,排名次默认的方法是从小排到大的,那你如果需要从大到小来排,你就需要在选项proc rank <选项>;制定,比如说我要对sashelp的升高按照从大到小排名次,那么程序如下:
proc rank data=sashelp.class out=result descending;
var height;
ranks r_height;
run;
接着再讲相同值名次怎么算,比如说45 68 68 9,这四个数字从小到大排名次,sas默认拍出来的结果是
4 2.
5 2.5 1 也就是相同值得话,名次怎么排,就是把相同的值得名次相加作平均。
4 5 5 5
6 排名次的结果应该是 1 3 3 3 5 这些明白?OK?继续
那么还有一种相同值的名次处理方法,刚才那种取名次均值得方法叫做mean
proc rank data=sashelp.class out=result descending;
var height;
ranks r_height;
run;
等价
proc rank data=sashelp.class out=result descending ties=mean;
var height;
ranks r_height;
run;
也就是说sas默认相同值得名次用均值名次处理,然而sas还提供了另外两种处理方法:
一种就是去小的那个名次,举例子:4 5 5 5 6 排名次的结果应该是1 2 2 2 5
proc rank data=sashelp.class out=result descending ties=low;
var height;
ranks r_height;
run;
另外一种就是取大的那个名次,4 5 5 5 6 排名次的结果应该是1 4 4 4 5
proc rank data=sashelp.class out=result descending ties=high;
var height;
ranks r_height;
run;
所以可以通过制定ties=选项值来让sas知道如何去处理相同值的名次
接着讲一个选项,名次用分数来表示,用排到的名次除以总人数,来作为rank的值。
这时候就需要各选项fraction,用这个选项的时候一定要注意,如果你没有用ties=选项,那么sas 默认的不再用均值处理名次
而是用最大的那种方法
proc rank data=sashelp.class out=result descending ties=mean fraction;
var height;
ranks r_height;
run;
这里拍出的rank实际上就是名次/总人数,这里的ties=mean不能身略,如果身略,那么sas 默认ties=high
所以这里要注意。
NPLUS1 这个选项类同于fraction,前者除以(总人数+1) k/(n+1),后者处以(总人数) k/n
还有你把除出来的值进行百分比,也就是说你要再乘以100,那么就用percent选项。
proc rank data=sashelp.class out=result descending ties=mean percent;
var height;
ranks r_height;
run;
proc rank data=sashelp.class out=result descending ties=mean fraction;
var height;
ranks r_height;
run;
前者是k/n*100 ,后者是k/n 仅此区别而已。
接着再讲一个分组选项,有点份为数的意思,1 2 3 4 5 6 分成两组,首先从小到大或从大到小排列,然后均分成2组:
proc rank data=sashelp.class out=result descending ties=mean groups=2;
var height;
ranks r_height;
run;
groups=是用来指定分成几组,这里不是随机分组,是按照顺序以后的分组,也就是说排好名次后按名次顺序分组。
最后还剩下2个选项,一个选项是normal= 貌似将名次再正态化,有三种正态化方法blom 、 tukey 、vw 这三种方法统计上怎么去正态化名次,公式分别是什么,请参照帮助。
最后一个选项SAVAGE ,就是对名次进行指数分布,公式参见帮助。
讲完了!。