TCPIP在linux下的具体实现
- 格式:pdf
- 大小:284.38 KB
- 文档页数:19

linux tcp重传机制摘要:一、TCP 重传机制简介二、Linux TCP 重传机制的工作原理三、Linux TCP 重传机制的优化四、总结正文:一、TCP 重传机制简介TCP(传输控制协议)是互联网中使用最广泛的协议之一,它的可靠数据传输依赖于一系列复杂的机制,其中之一就是重传机制。
当数据包在网络中丢失或损坏时,TCP 会通过重传机制来重新发送这些数据包,以确保数据的可靠传输。
TCP 重传机制包括超时重传和重复确认重传两种方式。
二、Linux TCP 重传机制的工作原理Linux 操作系统中的TCP 重传机制遵循RFC 6298 标准,并在此基础上进行了一定的优化。
具体来说,Linux TCP 重传机制的工作原理可以分为以下几个步骤:1.当TCP 发送方发送数据包后,如果在规定的时间内没有收到接收方的确认(ACK),发送方会启动超时重传定时器(RTO)。
2.在RTO 超时之前,如果发送方收到接收方的重复确认(DUP ACK)信号,说明接收方已经成功接收了数据包,此时发送方会立即停止重传定时器,并重新计算RTO 值。
3.如果RTO 超时后,发送方仍然没有收到接收方的确认信号,发送方会重传数据包。
4.如果重传后,发送方仍然没有收到接收方的确认信号,发送方会继续重传数据包,直到达到最大重传次数(通常为3 次)或成功收到接收方的确认信号为止。
三、Linux TCP 重传机制的优化为了提高TCP 重传机制的性能,Linux 操作系统在实现TCP 重传机制时采用了一些优化措施,包括:1.避免不必要的重传:在收到DUP ACK 信号后,发送方会立即停止重传定时器,并重新计算RTO 值。
这样做可以避免在网络状况不佳的情况下,因误判而启动不必要的重传。
2.快速重传:当发送方连续收到多个DUP ACK 信号时,发送方会快速重传数据包,而不再等待RTO 超时。
这样可以减少重传的延迟,提高传输速度。
3.拥塞避免:当发送方检测到网络拥塞时,会减小发送速率,以避免进一步加剧拥塞。

Linux网络基础知识TCP/IP通讯协议采用了4层的层级结构,每一层都呼叫它的下一层所提供的网络来完成自己的需求。
这4层分别为:应用层:应用程序间沟通的层,如简单电子邮件传输(SMTP)、文件传输协议(FTP)、网络远程访问协议(Telnet)等。
传输层:在此层中,它提供了节点间的数据传送服务,如传输控制协议(TCP)、用户数据报协议(UDP)等,TCP和UDP给数据包加入传输数据并把它传输到下一层中,这一层负责传送数据,并且确定数据已被送达并接收。
网络层:负责提供基本的数据封包传送功能,让每一块数据包都能够到达目的主机(但不检查是否被正确接收),如网际协议(IP)。
网络接口层(网络接口层例如以太网设备驱动程序):对实际的网络媒体的管理,定义如何使用实际网络(如Ethernet、Serial Line等)来传送数据。
网络接口层在发送端将上层的IP数据报封装成帧后发送到网络上;数据帧通过网络到达接收端时,该结点的网络接口层对数据帧拆封,并检查帧中包含的MAC地址。
如果该地址就是本机的MAC地址或者是广播地址,则上传到网络层,否则丢弃该帧。
网络接口层可细分为数据链路层和物理层,数据链路层实际上就是网卡的驱动程序,物理层实际上就是布线、光纤、网卡和其它用来把两台网络通信设备连接在一起的东西。
链路层,有时也称作数据链路层或网络接口层,通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。
它们一起处理与电缆(或其他任何传输媒介)的物理接口细节。
网卡驱动程序主要实现发送数据帧与接受数据帧的功能,发送数据帧采用内核函数hard_start_xmit();接收数据帧采用内核函数netif_rx();网卡驱动程序主要是分配设置及注册net_dev结构体;数据帧的载体采用sk-buff结构体。
用浏览网页为例:发送方:1.输入网址:,按了回车键,电脑使用应用层用IE浏览器将数据从80端口发出,给了下一层协议——传输层。

TCP是⼀种⾯向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。
同时是计算机四级考试的重要内容,店铺整理了其知识点,⼀起来复习下吧。
计算机四级复习知识点:TCP/IP联⽹篇1 ⼀、TCP/IP实现基本原理 1、TCP/IP的实现⽅式: TSR常驻内存程序是⼀种安装在Windows之前在DOS上运⾏的程序。
缺点,不能动态分配内存,TSR需要动态链接库DLL帮助,才能让Windows程序访问⽹络。
⽬前只有在DOS环境下才使⽤TSR⽅式 DLL动态链接库是⼀个16位的Windows程序函数库,只有当⽤到其中的过程时才会被调⽤。
缺点,它们不能直接与⽹卡通信,它们依赖于Windows的调度程序。
VxD虚拟设备是在Windows 32位保护⽅式下实现的,⽤于实现⼀些关键的部分,如视频、⿏标及通信端⼝驱动程序。
它是通过硬件中断⽅式响应⽹络中的通信,可以彻底地访问Windwos和DOS 程序。
2、⽹络配置基本参数:PC中⽹络适配卡基本参数,I/O端⼝地址、内存地址及中断号IRQ。
与Microsoft相关的⽹络信息,主机标识、⼯作组名、WINS服务器地址、DHCP服务器地址;与TCP/IP ⽹络信息有关,IP地址、⼦⽹掩码、主机名、域名、域名服务器、默认⽹关IP地址。
⼆、Windows NT平台的TCP/IP联⽹ 三、UNIX平台的TCP/IP联⽹ 1、建⽴UNIX联⽹的⼏个步骤:设计物理和逻辑的⽹络结构;分配IP地址;安装⽹络硬件;为每个主机配置启动时候的⽹络接⼝;设⽴服务程序或者静态路由。
2、IP地址的获取和分配:可能通过/etc/hosts⽂件、DNS或者其他域名系统来实现。
3、⽹卡的配置:ifconfig命令可以设置⽹卡IP地址、⼦⽹掩码、⼴播地址、⽹卡的使能状态及其他选项参数。
Ifconfig interface [family] address up option ,其中interface是指定的⽹卡名,可以⽤netstat-i来检查当前系统⽹卡的芯⽚类型。

在Linux系统中,TCP/IP网络是通过若干个文本文件进行配置的,有时需要编辑这些文件来完成联网工作。
vi /etc/sysconfig/network-scripts/ifcfg-eth0 :进入IP编译器按i 下面出现-- INSERT -- :写入模式出现下列信息# Advanced Micro Devices [AMD] 79c970 [PCnet32 LANCE]DEVICE=eth0BOOTPROTO=static // BOOTPROTO只有在static(静态)模式下才可以使用设置的IP信息HWADDR=00:0c:29:9e:43:e4ONBOOT=yesNETMASK=255.255.255.240 //掩码IPADDR=220.181.77.132 //添加IP地址GATEWAY=220.181.77.129 //添加网关TYPE=Ethernet按冒号:wq保存退出修改dnsvim /etc/resolv.conf重启网卡service network restart在此我们详细介绍如何使用命令行来手工配置TCP/IP网络。
与网络相关的配置文件和网络相关的一些配置文件有/etc/HOSTNAME、/etc/resolv.conf、/etc/host.conf、/etc/sysconfig/network、/etc/hosts等文件。
下面一一介绍。
/etc/HOSTNAME文件该文件包含了系统的主机名称,包括完全的域名,例如。
在Red Hat 7.2中,系统网络设备的配置文件保存在“/etc/sysconfig/network-scripts”目录下。
ifcfg-eth0包含第一块网卡的配置信息,ifcfg-eht包含第二块网卡的配置信息。
下面是“/etc/sysconfig/network-scripts/ifcfg-eth0”文件的示例:DEVICE=eth0IPADDR=208.164.186.1NETMASK=255.255.255.0NETWORK=208.164.186.0BROADCAST=208.164.186.255ONBOOT=yesBOOTPROTO=noneUSERCTL=no其中各变量关键词的解释如下:DEVICE=name name表示物理设备的名字IPADDR=addr addr表示赋给该卡的I P地址NETMASK=mask mask表示网络掩码NETWORK=addr addr表示网络地址BROADCE ST=addr addr表示广播地址ONBOOT=yes/no 启动时是否激活该卡BOOTPROTO=proto proto取值可以是none(无须启动协议)、bootp(使用bootp协议)、dhcp(使用DHCP协议)USERCTL=yes/no 是否允许非root用户控制该设备若希望手工修改网络地址或在新的接口上增加新的网络界面,可以通过修改对应文件(ifcfg-ethN)或创建新文件来实现。

Linux操作系统中的网络通信原理一、引言Linux操作系统是一种广泛应用于各种领域的开源操作系统,而网络通信则是其最重要的功能之一。
本文将深入探讨Linux操作系统中的网络通信原理,包括网络协议、套接字编程以及网络通信的实现机制等方面。
二、网络协议1. TCP/IP协议栈TCP/IP协议栈是Linux操作系统中实现网络通信的基础。
它由四个层次组成:网络接口层、网络层、传输层和应用层。
网络接口层负责将数据从应用层传输到网络层,网络层负责将数据从源主机传输到目标主机,传输层负责提供可靠的数据传输服务,而应用层则负责处理具体的网络应用。
2. IP地址和端口号IP地址是在Internet上对主机和路由器进行唯一标识的地址,而端口号则用于标识网络中的不同进程或服务。
Linux操作系统中使用IP 地址和端口号来实现网络通信的目的。
3. ICMP协议ICMP协议是Internet控制报文协议的缩写,用于在IP网络中发送控制消息和错误报文。
它有助于网络中的主机和路由器之间进行通信和故障排除。
三、套接字编程套接字是实现网络通信的一种机制,也是Linux操作系统中网络通信的核心。
通过套接字编程,可以在应用层使用socket函数进行网络通信的建立和数据传输。
1. 套接字类型在Linux操作系统中,套接字类型可以分为面向连接的套接字和无连接的套接字。
面向连接的套接字主要基于TCP协议,提供可靠的数据传输和连接管理功能;无连接的套接字则主要基于UDP协议,提供高效的数据传输和较低的开销。
2. 套接字编程流程套接字编程的一般流程包括创建套接字、绑定地址、监听连接、接受连接、数据传输和关闭套接字等步骤。
通过这些步骤,应用程序可以实现与其他主机或服务的通信。
四、网络通信实现机制1. 数据链路层数据链路层是网络通信中的第一层,主要负责将数据包从物理层传输到网络层。
在Linux操作系统中,数据链路层由网络接口卡驱动程序和相应的设备驱动程序实现。

Linux网络配置教程理解IP地址子网掩码和网关Linux网络配置教程——理解IP地址、子网掩码和网关在Linux操作系统中,网络配置是非常重要的一环。
正确配置IP地址、子网掩码和网关是保证网络通信的基础。
本教程将帮助您理解这些概念,并提供相应的网络配置方式。
一、IP地址IP地址是互联网中每个设备(如计算机、服务器、路由器等)在网络中的唯一标识。
它由一系列数字组成,以点分十进制表示(例如192.168.1.1)。
为了正确配置IP地址,您首先需要了解自己所在的网络环境。
一种常见的方式是使用DHCP(动态主机配置协议),它允许网络设备自动获取IP地址。
如果您的网络使用DHCP,请跳过以下内容,系统会自动为您分配IP地址。
如果您的网络不使用DHCP,您需要手动配置静态IP地址。
以下是静态IP地址的配置步骤:1. 打开终端,输入命令`sudo vi /etc/network/interfaces`,这会打开网络配置文件。
2. 您需要找到类似下面这样的行:```iface eth0 inet dhcp```3. 将上面的行改为:```iface eth0 inet staticaddress 192.168.1.100netmask 255.255.255.0gateway 192.168.1.1```其中,address为您配置的静态IP地址,netmask为子网掩码,gateway为网关地址。
4. 按下`Esc`键,输入`:wq`保存并退出。
5. 输入命令`sudo service networking restart`重启网络服务。
完成以上步骤后,您的静态IP地址就已经配置成功了。
您可以使用命令`ifconfig`来验证IP地址的配置情况。
二、子网掩码子网掩码用于划分IP地址中的网络部分和主机部分。
它由一系列数字组成,以点分十进制表示(例如255.255.255.0)。
子网掩码和IP 地址一起使用,决定了网络的范围。

使用nc命令在Linux终端中进行网络连接和数据传输一、前言在Linux终端中进行网络连接和数据传输是日常工作中常见的操作之一。
在Linux系统中,存在许多实用工具,其中nc(netcat)命令就是一种功能强大的网络工具,它可以通过TCP或UDP协议在网络上进行连接和数据传输。
本文将介绍nc命令的基本用法,包括建立网络连接、数据传输和监听网络端口等,以帮助读者更好地了解和使用该命令。
二、建立网络连接使用nc命令可以方便地在Linux终端上建立网络连接,无论是客户端还是服务器端。
下面将分别介绍这两种情况下的操作方法。
1. 客户端模式在客户端模式下,nc命令可以作为一个客户端,从而连接到指定的服务器,发送请求并接收响应。
使用以下命令可以建立一个基本的客户端连接:```shellnc [options] host port```其中,host代表目标服务器的主机名或IP地址,port代表目标服务器的端口号。
根据实际需求,可以在命令中添加一些选项来配置连接方式。
例如,要连接到IP地址为192.168.0.100的服务器的80端口,可以使用以下命令:```shellnc 192.168.0.100 80```2. 服务器端模式在服务器端模式下,nc命令可以作为一个服务器程序,监听指定的端口,并等待客户端的连接请求。
使用以下命令可以建立一个基本的服务器端连接:```shellnc -l [options] [hostname] [port]```其中,-l选项用于监听指定的端口。
如果不指定hostname,则nc命令将监听所有可用的IP地址。
根据实际需求,可以在命令中添加其他选项来配置服务器模式。
例如,要监听本机的8080端口,可以使用以下命令:```shellnc -l 8080```三、数据传输在建立网络连接后,可以使用nc命令进行数据的传输。
nc命令提供了多种方式来传输数据,包括标准输入输出、文件传输和端口转发等。

LwIP源码分析 - 11.tcpip一般的实现方式有:●每一层一个进程,网络接口层,ip层,tcp层,应用程序层,这个方法的好处是各层之间结构清晰明了,容易阅读和调试,但是这种分层思想带来的通病就是效率低下,如果按照这种实现方式即上层应用接受一个数据包,要通过网络接口层进程->ip层进程->tcp层进程->应用程序层进程,这种效率是不能接受的。
●Tcp,ip协议栈处于内核态,属于操作系统内核的一部分,同属于内核进程,应用程序通过系统调用来和协议层通信,这样的好处就是协议层之间不需要耗时的频繁的协议间进程切换,但是这种方式只是在一些比较高级的操作系统中实现(至少要到虚拟内存管理mmu),比如windows和linux就是采用这种方式的。
●lwip采用了另外一种方式,它也是将协议层全部在一个进程中实现的,应用程序可以在协议层进程中实现(即利用lwip自己提供的一套内部回调函数来通信)也可以通过另外一个进程实现,如果应用程序另起一个进程的话则需要通过操作系统提供的进程间通信的机制(管道,邮箱等)来实现交互。
这种方式就带有相当的灵活性,而且由于对应用程序的进程没有特殊限制,一般的操作系统都能支持。
整个学习的过程也打算按照这种流程来学习,先从底层看起(这部分也是我最熟悉的),依次从network inte**ce layer -> internetwork layer -> transport layer -> application layer(这也是按照tcpip的经典四层分法的)。
首先来看网络接口层:这一层的主要文件位于/src/netif目录,主要是网络设备驱动文件(一个skeleton程序),一个loopback文件(非常简单),arp模块,ppp协议栈。
核心的netif的通用程序在/src/core目录下。
1.重要的结构体有:Struct netif{……}这个结构体相当linux中的net_device结构体,用lwip的原文来说就是整个网络接口层中都会用到的一个结构体,对于理解这一层非常重要。

在Linux终端中配置网络连接的方法Linux终端是一种功能强大的工具,它不仅可以执行各种命令和操作系统任务,还可以通过配置网络连接来实现对互联网的访问。
本文将介绍几种在Linux终端中配置网络连接的方法。
方法一:使用ifconfig命令在Linux终端中,可以使用ifconfig命令配置网络连接。
该命令可以查看和设置网络接口的配置信息。
以下是使用ifconfig命令配置网络连接的步骤:1. 打开终端并输入以下命令查看当前的网络接口:$ ifconfig2. 根据需要选择要配置的网络接口,例如eth0或wlan0。
3. 输入以下命令来配置选定的网络接口:$ ifconfig [接口名称] [IP地址] [掩码]其中,[接口名称]是网络接口的名称,[IP地址]是你希望设置的IP 地址,[掩码]是网段的掩码。
例如,要将eth0接口的IP地址设置为192.168.1.100,掩码为255.255.255.0,可以输入以下命令: $ ifconfig eth0 192.168.1.100 netmask 255.255.255.04. 输入以下命令来启用网络接口:$ ifconfig [接口名称] up例如,要启用eth0接口,可以输入以下命令:$ ifconfig eth0 up方法二:使用ip命令除了ifconfig命令外,还可以使用ip命令配置网络连接。
ip命令是一个更高级的网络配置工具,具有更多的功能和选项。
以下是使用ip命令配置网络连接的步骤:1. 打开终端并输入以下命令查看当前的网络接口:$ ip addr2. 根据需要选择要配置的网络接口,例如eth0或wlan0。
3. 输入以下命令来配置选定的网络接口:$ ip addr add [IP地址/掩码] dev [接口名称]其中,[IP地址/掩码]是你希望设置的IP地址和掩码,[接口名称]是网络接口的名称。
例如,要将eth0接口的IP地址设置为192.168.1.100/24,可以输入以下命令:$ ip addr add 192.168.1.100/24 dev eth04. 输入以下命令来启用网络接口:$ ip link set [接口名称] up例如,要启用eth0接口,可以输入以下命令:$ ip link set eth0 up方法三:编辑网络配置文件另一种配置网络连接的方法是通过编辑网络配置文件。

Linux系统网络配置教程一、引言在现代信息技术时代,网络已经成为我们生活和工作中不可或缺的一部分。
而对于使用Linux操作系统的用户来说,正确配置网络是十分重要的。
本章将介绍Linux系统网络配置的基本步骤和常见问题解决方法。
二、网络配置概述网络配置是指将计算机与网络相连,并配置正确的网络参数,以实现与其他计算机之间的通信。
Linux系统的网络配置可分为两个方面,即物理连接和逻辑配置。
2.1 物理连接物理连接是指将计算机与网络相连的操作。
首先要确保计算机已经正确连接到局域网或因特网。
如果是有线连接,需要插入以太网线到计算机的网卡插槽和路由器的网络接口;如果是无线连接,需要确保无线网卡已经连接到正确的无线网络。
2.2 逻辑配置逻辑配置是指在物理连接完成后,需要对计算机进行相应的软件设置,以使其能够正确地与其他网络设备进行通信。
逻辑配置的主要内容包括IP地址的配置、网关的配置、DNS的配置以及防火墙的配置等。
三、IP地址配置IP地址是互联网中用于标识和定位计算机的一种地址。
在Linux系统中,可以通过以下两种方式来配置IP地址:3.1 动态IP地址配置动态IP地址配置是指使用DHCP服务器为计算机分配IP地址的方式。
DHCP是一种网络协议,它可以自动为计算机分配IP地址和其他网络配置信息。
要使用动态IP地址配置,在终端中输入以下命令:```shellsudo dhclient eth0```其中,eth0是计算机的网卡接口名,根据实际情况进行相应更改。
3.2 静态IP地址配置静态IP地址配置是指手动为计算机分配一个固定的IP地址。
这种方式适用于需要长期使用特定IP地址的情况。
要进行静态IP 地址配置,需要编辑网络配置文件。
在终端中输入以下命令:```shellsudo nano /etc/network/interfaces```在文件中添加以下配置信息:```shellauto eth0iface eth0 inet staticaddress 192.168.0.100netmask 255.255.255.0gateway 192.168.0.1```其中,eth0是计算机的网卡接口名,address是计算机的IP地址,netmask是子网掩码,gateway是网关地址。
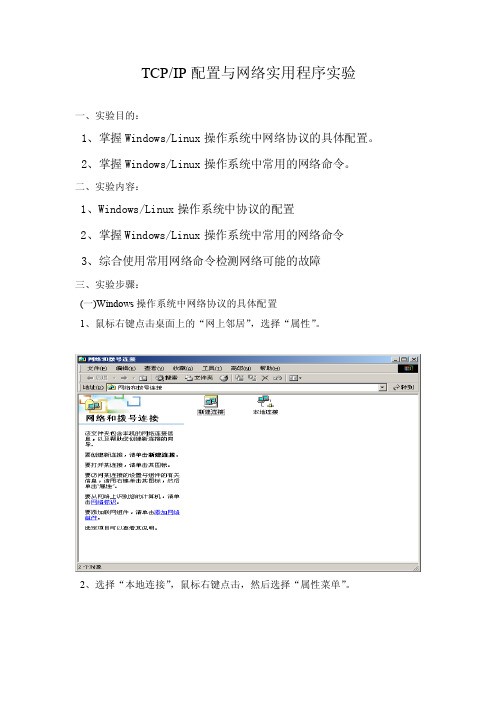
TCP/IP配置与网络实用程序实验一、实验目的:1、掌握Windows/Linux操作系统中网络协议的具体配置。
2、掌握Windows/Linux操作系统中常用的网络命令。
二、实验内容:1、Windows/Linux操作系统中协议的配置2、掌握Windows/Linux操作系统中常用的网络命令3、综合使用常用网络命令检测网络可能的故障三、实验步骤:(一)Windows操作系统中网络协议的具体配置1、鼠标右键点击桌面上的“网上邻居”,选择“属性”。
2、选择“本地连接”,鼠标右键点击,然后选择“属性菜单”。
3、此时,可以安装、卸载各种协议并查看及其属性。
4、选择”Internet协议(TCP/IP)”,然后点击“属性”菜单。
5、根据网络具体情况进行配置,如果网络使用DHCP服务的话,则选择“自动获得IP地址与自动获得DNS服务器地址”,否则,手工配置IP地址,子网掩码、网关或者DNS服务器地址。
6、点击“高级”选择然后分别选择“IP设置、DNS、WINS、选项等”进行其他配置。
7、协议配置好之后,可在命令行中使用ipconfig命令查看配置情况,该命令尤其在采用DHCP分配地址的时候十分有用。
点击”开始 运行”,输入“cmd”然后回车,进入命令行。
c:\>ipconfig 命令显示每个已经配置且处于活动状态的网络接口的IP地址、子网掩码和默认网关。
c:\>ipconfig/all 除了上述信息外,还能显示DNS和WINS服务器信息,网卡的MAC地址,如果是DHCP获得IP配置,还可显示IP地址及租用地址的预计失效日期。
c:\>ipconfig /release 。
在采用DHCP自动配置的情况下,该命令将所租用的IP 地址返还给DHCP服务器。
C:\>ipconfig/renew 表示本地计算机设法与DHCP服务器取得联系,且重新租用一个IP地址。
C:\>ipconfig/flushdns 清除本机DNS解析器缓存中的内容。


Linux命令高级技巧使用nc命令进行网络调试与测试Linux命令高级技巧:使用nc命令进行网络调试与测试在Linux系统中,nc(netcat)是一个功能强大的网络工具,它可以被用来创建 TCP/IP 连接、发送数据,以及进行网络调试和测试。
本文将介绍如何使用nc命令进行网络调试与测试,并分享一些高级技巧。
一、nc命令简介nc命令是Linux系统中的一个工具,可以用来建立连接、监听端口和传输数据等。
它可以用作简单的TCP/IP应用程序,也可以作为调试和测试工具使用。
二、使用nc命令建立TCP连接在使用nc命令建立TCP连接之前,我们需要明确两个概念:客户端和服务器端。
客户端发起连接请求,服务器端响应连接请求并接受连接。
使用nc命令可以在Linux系统上实现这两个角色。
1. 建立客户端连接要建立一个客户端连接,可以使用以下命令:```shellnc <服务器IP地址> <服务器端口号>```例如,要连接到IP地址为192.168.0.100的服务器的端口号8080,可以使用以下命令:```shellnc 192.168.0.100 8080```连接成功后,你可以向服务器发送数据。
2. 建立服务器连接要建立一个服务器连接,可以使用以下命令:```shellnc -l <监听端口号>```例如,要监听本地的端口号1234,可以使用以下命令:```shellnc -l 1234```当有客户端连接到该端口时,你可以接收来自客户端的数据。
三、使用nc命令进行网络调试与测试nc命令不仅可以用来建立连接,还可以用于网络调试和测试。
下面介绍一些常见的使用场景。
1. 端口扫描通过nc命令,你可以扫描一个主机的指定端口是否开放。
使用以下命令:```shellnc -zv <主机IP地址> <起始端口号>-<结束端口号>```例如,要扫描192.168.0.100主机上8080到8090的端口,可以使用以下命令:```shellnc -zv 192.168.0.100 8080-8090```这将显示哪些端口处于活动状态。

Linux高级网络性能调优使用TCPIP堆栈参数在Linux系统中,网络性能的优化是一项重要且常见的任务。
为了提高网络传输速度、降低延迟和提高网络吞吐量,我们可以通过调整TCPIP堆栈参数来实现。
TCPIP堆栈是Linux操作系统中实现网络通信的关键模块,它负责处理数据包的传输、路由和错误检测等功能。
通过调整堆栈的参数,我们可以优化网络性能。
下面将介绍一些常见的TCPIP堆栈参数以及如何使用它们进行网络性能调优。
1. 窗口大小调优TCP协议使用滑动窗口来控制数据传输的速度和可靠性。
窗口大小决定了每次发送数据的量。
默认情况下,Linux系统的窗口大小较小,可能导致网络性能较低。
可以通过调整窗口大小来提高网络吞吐量。
使用以下命令可以查看当前的窗口大小:```$ sysctl net.ipv4.tcp_rmem```可以通过修改`net.ipv4.tcp_rmem`参数来调整接收窗口大小,并通过修改`net.ipv4.tcp_wmem`参数来调整发送窗口大小。
例如,将窗口大小调整为4096字节:```$ sysctl -w net.ipv4.tcp_rmem="4096 87380 6291456"```2. 拥塞控制算法选择Linux系统支持多种拥塞控制算法,如TCP Reno、TCP Cubic等。
不同的算法在网络负载和延迟控制方面表现不同。
为了适应不同的网络环境,可以通过修改拥塞控制算法来优化网络性能。
可以使用以下命令将拥塞控制算法更改为TCP Cubic:```$ sysctl -w net.ipv4.tcp_congestion_control=cubic```3. SYN队列长度调优SYN队列用于存放等待建立TCP连接的请求。
默认情况下,Linux 系统的SYN队列长度较小,可能导致连接延迟和丢失。
可以通过调整SYN队列长度来提高网络性能。
使用以下命令可以查看当前的SYN队列长度:```$ sysctl net.ipv4.tcp_max_syn_backlog```可以通过修改`net.ipv4.tcp_max_syn_backlog`参数来调整SYN队列长度。

TCPIP及内核参数优化调优Linux下TCP/IP及内核参数优化有多种⽅式,参数配置得当可以⼤⼤提⾼系统的性能,也可以根据特定场景进⾏专门的优化,如TIME_WAIT 过⾼,DDOS攻击等等。
如下配置是写在sysctl.conf中,可使⽤sysctl -p⽣效,相关参数仅供参考,具体数值还需要根据机器性能,应⽤场景等实际情况来做更细微调整。
dev_max_backlog = 400000#该参数决定了,⽹络设备接收数据包的速率⽐内核处理这些包的速率快时,允许送到队列的数据包的最⼤数⽬。
net.core.optmem_max = 10000000#该参数指定了每个套接字所允许的最⼤缓冲区的⼤⼩net.core.rmem_default = 10000000#指定了接收套接字缓冲区⼤⼩的缺省值(以字节为单位)。
net.core.rmem_max = 10000000#指定了接收套接字缓冲区⼤⼩的最⼤值(以字节为单位)。
net.core.somaxconn = 100000#Linux kernel参数,表⽰socket监听的backlog(监听队列)上限net.core.wmem_default = 11059200#定义默认的发送窗⼝⼤⼩;对于更⼤的 BDP 来说,这个⼤⼩也应该更⼤。
net.core.wmem_max = 11059200#定义发送窗⼝的最⼤⼤⼩;对于更⼤的 BDP 来说,这个⼤⼩也应该更⼤。
net.ipv4.conf.all.rp_filter = 1net.ipv4.conf.default.rp_filter = 1#严谨模式 1 (推荐)#松散模式 0net.ipv4.tcp_congestion_control = bic#默认推荐设置是 htcpnet.ipv4.tcp_window_scaling = 0#关闭tcp_window_scaling#启⽤ RFC 1323 定义的 window scaling;要⽀持超过 64KB 的窗⼝,必须启⽤该值。

TCPIP详解TCP/IP不是⼀个协议,⽽是⼀个协议族的统称。
⾥⾯包括了IP协议,IMCP协议,TCP协议,以及我们更加熟悉的http、ftp、pop3协议等等。
TCP/IP协议分层提到协议分层,我们很容易联想到ISO-OSI的七层协议经典架构,但是TCP/IP协议族的结构则稍有不同。
如图所⽰TCP/IP协议族按照层次由上到下,层层包装。
最上⾯的就是应⽤层了,这⾥⾯有http,ftp,等等我们熟悉的协议。
第⼆层则是传输层,著名的TCP和UDP(User Datagram Protocol)协议就在这个层次。
第三层是⽹络层,IP协议就在这⾥,它负责对数据加上IP地址和其他的数据以确定传输的⽬标。
第四层是叫数据链路层,这个层次为待传送的数据加⼊⼀个以太⽹协议头,并进⾏CRC编码,为最后的数据传输做准备。
再往下则是硬件层次了,负责⽹络的传输,这个层次的定义包括⽹线的制式,⽹卡的定义等等发送协议的主机从上⾃下将数据按照协议封装,⽽接收数据的主机则按照协议从得到的数据包解开,最后拿到需要的数据。
这种结构⾮常有栈的味道,所以某些⽂章也把tcp/ip协议族称为tcp/ip协议栈。
⼀些基本的常识互联⽹地址(ip地址):⽹络上每⼀个节点都必须有⼀个独⽴的Internet地址(也叫做IP地址)。
现在,通常使⽤的IP地址是⼀个32bit的数字,也就是我们常说的IPv4标准,这32bit的数字分成四组,也就是常见的255.255.255.255的样式。
IPv4标准上,地址被分为五类,我们常⽤的是B类地址。
具体的分类请参考其他⽂档。
需要注意的是IP地址是⽹络号+主机号的组合,这⾮常重要。
域名系统:域名系统是⼀个分布的数据库,它提供将主机名(就是⽹址啦)转换成IP地址的服务。
RFC:RFC是什么?RFC就是tcp/ip协议的标准⽂档,它⼀共有4000多个协议的定义,当然,我们所要学习的,也就是那么⼗⼏个协议⽽已。
端⼝号(port):这个端⼝号是⽤在TCP,UDP上的⼀个逻辑号码,并不是⼀个硬件端⼝,我们平时说把某某端⼝封掉了,也只是在IP层次把带有这个号码的IP包给过滤掉了⽽已。

linux ipip隧道原理IP in IP(IPIP)隧道是一种在IP网络上进行数据封装和隧道传输的技术。
它允许将一个IP数据报封装在另一个IP数据报中,以便在不同的网络之间进行传输。
在Linux系统中,可以使用内核模块来实现IPIP隧道。
IPIP隧道的原理是通过在原始IP数据报的头部添加一个新的IP头部来封装数据。
发送端将要传输的数据包封装在一个新的IP 数据包中,目的地址设置为隧道的目的地,然后通过现有网络发送出去。
接收端收到数据包后,会解析外层IP头部,找到内层的IP 数据包,并将其传递到目标主机。
在Linux系统中,可以使用ip命令来配置IPIP隧道。
首先需要加载ipip内核模块,然后使用ip命令配置隧道的本地和远程IP 地址。
例如,可以使用以下命令创建一个IPIP隧道:bash.sudo modprobe ipip.sudo ip tunnel add tunnel0 mode ipip remote <远程IP地址> local <本地IP地址>。
sudo ip link set tunnel0 up.sudo ip addr add <隧道IP地址/子网掩码> dev tunnel0。
这将创建一个名为tunnel0的IPIP隧道,并将其配置为使用指定的本地和远程IP地址。
隧道IP地址是隧道两端用于通信的虚拟接口的IP地址。
总的来说,IPIP隧道通过在IP数据包的头部添加新的IP头部来实现数据的封装和隧道传输。
在Linux系统中,可以使用ip命令和内核模块来配置和管理IPIP隧道。
这种技术可以帮助实现不同网络之间的数据传输和连接。

tcpip拥塞控制、重传、丢包、优化弱⽹环境是丢包率较⾼的特殊场景,TCP 在类似场景中的表现很差,当 RTT 为 30ms 时,⼀旦丢包率达到了 2%,TCP 的吞吐量就会下降89.9%[3],从下⾯的表中我们可以看出丢包对 TCP 的吞吐量极其显著的影响:概念理解4种计时器1.重传计时器:Retransmission Timer A发报⽂时创建计时器,计时器到期内收到回报⽂ACK,就撤销计时器2.持久计时器:Persistent Timer B告诉A,接收窗⼝填满了(0窗⼝通报),告诉A停⽌发送,进⼊等待,直到B发送报⽂告诉A已有“⾮零窗⼝”,但此时若这个报⽂丢失,B⾃⼰不知道,等着A发数据过来,双⽅都进⼊等待死锁,解决这个问题要在A端创建持久计时器,当收到B发送过来的0窗⼝通报报⽂后,计时器启动,计时器过期后,A发⼀个探测报⽂给B,询问是否有⾮0窗⼝,如果超时还没ack恢复则发探查报⽂,如果超时前收到到ack回复依然是0窗⼝,则将计时器复位并且翻倍时间值(1,2,4,8最⼤60s),如此循环,直到收到B的重开窗⼝确认包。
3.保活计时器:Keeplive Timer 长连接中A发送数据给B,发送⼏个数据包之后,A出故障了,B等待2⼩时后发10个探测报⽂段(每个75分钟发⼀次),如果没有响应就终⽌连接4.时间等待计时器:Timer_Wait Timer time_wati状态下发出的给被关闭端ack报⽂后等待时间(30~120s),⼀般设置⼀个msl(最长报⽂寿命)是60s包重传的原因tcp可靠性通过序列号和ack确认包保障,当tcp发送包之后,将这个包的副本数据段放到重传队列上启动重传计时器1、如果对⽅反馈ack,则销毁数据段和计时器2、如果对⽅没有反馈ack,则在计时器到期后发起重传快速重传:A向B发送4个tcp报⽂段(n1,n2,n3,n4),B只收到(n1,n2,n4),其中n3丢失(也许只是延时到达),B发现失序⽴即⽣成重复ACK包(重复确认n3),且发送三次给A,A重传该数据包超时重传:定时器超时之后,重传包,计时器的时间为“⼤于平均往返延迟”伪超时和重传:过早的判断了超时时间,导致发送⽅触发重传,RTT(连接往返时间)增长超过RTO(重传超时时间)包失序:ip层的包没有按顺序传输,严重失序时,接收⽅误以为包丢失,通知发送端重传,需要设置合理的重传阀值解决包重复:重传包含⼀个数据包,以及两个副本,多次重复会导致B收到过多重复包,从⽽B⽣成重复的ack,容易触发伪快速重传,使⽤sack 避免sack:当出现包失序、⽹络丢包导致的接收⽅数据序队列出现空洞,sack选项可以提供确认信息(描述乱序、空洞),帮助A⽅有效的重传。

竭诚为您提供优质文档/双击可除eth协议数据结构篇一:linuxtcpip协议栈的关键数据结构socketbuffer linuxtcp/ip协议栈的关键数据结构socketbuffersk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。
它在中定义,并包含很多成员变量供网络代码中的各子系统使用。
这个结构在linux内核的发展过程中改动过很多次,或者是增加新的选项,或者是重新组织已存在的成员变量以使得成员变量的布局更加清晰。
它的成员变量可以大致分为以下几类:layout布局general通用Feature-specific功能相关managementfunctions管理函数这个结构被不同的网络层(mac或者其他二层链路协议,三层的ip,四层的tcp或udp等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。
l4向l3传递前会添加一个l4的头部,同样,l3向l2传递前,会添加一个l3的头部。
添加头部比在不同层之间拷贝数据的效率更高。
由于在缓冲区的头部添加数据意味着要修改指向缓冲区的指针,这是个复杂的操作,所以内核提供了一个函数skb_reserve(在后面的章节中描述)来完成这个功能。
协议栈中的每一层在往下一层传递缓冲区前,第一件事就是调用skb_reserve在缓冲区的头部给协议头预留一定的空间。
skb_reserve同样被设备驱动使用来对齐接收到包的包头。
如果缓冲区向上层协议传递,旧的协议层的头部信息就没什么用了。
例如,l2的头部只有在网络驱动处理l2的协议时有用,l3是不会关心它的信息的。
但是,内核并没有把l2的头部从缓冲区中删除,而是把有效荷载的指针指向l3的头部,这样做,可以节省cpu时间。
1.网络参数和内核数据结构就像你在浏览tcp/ip规范或者配置内核时所看到的一样,网络代码提供了很多有用的功能,但是这些功能并不是必须的,比如说,防火墙,多播,还有其他一些功能。
TCP/IP在linux下的具体实现(初稿,未整理)杭州和利时软件开发部刘小树2005-2-25目录TCP/IP在linux下的具体实现(初稿,未整理) (1)目录 (1)1 通用TCP/IP逻辑结构; (2)2 .TCP/IP协议栈在linux下的层次 (3)2.2跟实现tcp/ip有关的linux基础知识: (3)2.3 各层之间的关系; (6)3基本数据结构 (7)3.1 msghdr结构 (7)3.2.sk_buff_head{}结构 (7)3 .3socket{}类型; (10)3.4.INET Socket: sock{} (11)3.5以上个结构的跳转及函数指针集合 (15)3.6 struct net_device{ (15)4实例:收发数据包流程图 (15)4.2数据接收过程:以下以图表说明(大致原理类似接受过程): (17)1 通用TCP/IP逻辑结构;与ISO提出的OSI定义网络层次(7层)不同,tcp/ip就定义了五层.各层的主要功能及对应的硬件:物理层:定义传输的电平及硬件接口标准..数据链路层:对应的是网卡的驱动(在这层调用具体的read/write函数把包通过网卡发出去)网络层:用来路由的,负责把一个包发到指定的网络机器等;传输层:把收到的包传给具体的进程(根据端口号)等;应用层:把有用的数据进行重新组装,定义要传输的端口等等;2 .TCP/IP协议栈在linux下的层次LINUX下tcp/ip协议栈是以4.4 BSD为模板,估计目前大多数操作系统都是以此为模板的,支持BSD Socket 编程,即常用的网络编程模型;在服务器端:1.调用socket()创建一个socket;2.bind()3.listen()4.accept();5.read/write()在客户端1socket();2connect();3read/write();2.2跟实现tcp/ip有关的linux基础知识:在linux下,所有的设备都当作文件节点来管理,网络设备也不例外,即对一个进程中的socket 进行读写就相当于对进程中的已打开的文件读写,具体的不同体现在读写函数的不同;可以大致看看进程,文件系统及socket之间的关系;进程数据结构://只关心跟文件有关的那部分struct task_struct {…..//省略大部分内容/* filesystem information *///跟进程有关的文件;struct fs_struct *fs;/* open file information */struct files_struct *files;};省略了很多很多结构,跟文件有关就fs_struct *fs 跟files_struct *files两个结构;前者是关于文件信息的,后者关于已打开文件的信息;主要关注一下fisle_struct 结构如下定义:struct files_struct {atomic_t count;rwlock_t file_lock; /* Protects all the below members. Nests inside tsk->alloc_lock */int max_fds;int max_fdset;int next_fd;struct file ** fd; /* current fd array */fd_set *close_on_exec;fd_set *open_fds;fd_set close_on_exec_init;fd_set open_fds_init;struct file * fd_array[NR_OPEN_DEFAUL T];};fd_array[]数组为改进程打开的文件列表.file 对应的为每个具体的文件,file中有个inode结构体,对应着具体的文件系统类型(如常见的文件系统类型:ext2,ntfs,msdos,qnx4,socket_t),这个创建的socket对应的文件系统类型就属于socket_t类型;各结构之间的应用关系如下图示”进程结构文件该文件读写函数上面仅是稍微介绍一下tcp/ip实现有关的文件系统.大体上可以这么理解的:一个进程创建了一个socket进行网络传输,相当于打开了一个文件,文件类型是socket_t,在编程人员看来相当于是打开了一个普通文件,而后对该socket进行读写时就相当于对普通文件读写一样可以调用read/write了.至于socket的read/write(不同的文件系统实现都不一样,如fat32 跟ext2,ntfs之间都不一样)函数怎样实现属于操作系统的事情;这正是要重点讨论得; 在file结构里有个struct file_oprations;用于指向文件的操作函数指针集合,典型定义如下:不同文件系统对应到的具体函数不一样.如对socket操作时相应的函数集合为(应用层时): static struct file_operation socket_file_ops={llseek:sock_lseek;// 函数read:sock_read,write:sock_write;open:sock_no_open;//没有这个函数,网卡为特殊设备,通过系统调用socket() 来打开. Realse:sock_release;……….}以上介绍的是跟实现tcp/ip有关的一些linux基础知识,继续回到层次关系;Linux网络系统基本可分为硬件层/数据链路层,Ip(tcp,ip,arp等)层,INET Socket层,BSD Socket层和应用层五部分;其中linux内核中包含了前四部分,应用层和BSD SOCKET层之间的应用程序接口以4.4 BSD为模板.Inet socket 层在ip 协议层上一层,对ip 分组排序,控制网络效率等; Ip 层即tcp/ip 协议栈的互联网层实现部分,整个协议栈的核心部分; 硬件层跟数据链路层对应着网卡及其驱动程序;2.3 各层之间的关系;讨论的核心是图中的内核层及硬件设备层,主要关注在这些不同的逻辑层次上是通过什么样办法把数据包一层一层往下传递或上传的以及各层之间的接口;先简单介绍一个各层的关系: 应用层中操作的对象是socket 的文件描述符,通过文件系统定义的通用接口,使用系统调应用程序()硬件设备用从用户空间切换到内核空间,控制socket文件描述府对应的就是对BSD SOCKET的操作,从而进入到bsd socket层的操作,在BSD socket层中,操作的socket{}结构,每一个这样的结构对应的是一个网络连接,通过网络地址族的不同来区分不同的操作方法,判断是否该进入到INET socket层,这一层数据存放在msghdr{}结构中,在INET socket层,分成udp跟tcp两种连接.这一层操作的对象是sock{}类型的数据.数据存放在sk_buff{}结构中.从INET Socket层到IP层,主要是路由过程,发送时确定发送的下一个机器地址,接受时判断是转发该包还是传给INET socket层,ip层是整个网络协议的核心,基本上整个网络安全都是在这里实现的(在这一层,基于2.4版的内核,提供了五个钩子函数可用于防火墙的实现,基于linux的防火墙软件设计都是在这一层下的五个钩子函数里添加自己的防火墙策略(详细可参考:国防科大出版社编的<<基于linux的防火墙设计与实现>>).从ip层到硬件层,即调用网卡驱动程序.现面介绍以下核心的数据结构3基本数据结构整个网络实现中,数据包(在有效数据前加上包头及一些控制信息)是最重要的部分,影响网络速率和效率的关键就在于在内存中对数据包的管理.在内核中,分不同的层次,使用两种数据结构来保存数据.在BSD Socket层内用msghdr{}结构保存数据,在INET Socket层以下用sk_buff{}保存数据.前者是为了跟BSD 4.4兼容而定义的.sk_buff{}是INET Socket及以下层次中存放数据的结构,在不同层次进行数据包传递,就是通过它进行的(有效数据是通过指针指向的,在不同层次间传递包仅需添加改层次上的相应信息到skb_buff{}里)3.1 msghdr结构struct msghdr {//在bsd socket层使用此数据结构void * msg_name; /* Socket name */int msg_namelen; /* Length of name */struct iovec * msg_iov; /* Data blocks *///从应用层传下来的数据,通过指针指向,不是把数据拷贝过来,__kernel_size_t msg_iovlen; /* Number of blocks *///从应用层传下的数据包个数void * msg_control; /* Per protocol magic (eg BSD file descriptor passing) */__kernel_size_t msg_controllen; /* Length of cmsg list */unsigned msg_flags;};3.2.sk_buff_head{}结构此数据结构很重要,在整个tcp/ip实现中,都要用到它,删除了一些不重要的元素struct sk_buff {/* These two members must be first. */struct sk_buff * next; /* Next buffer in list */struct sk_buff * prev; /* Previous buffer in list */struct sk_buff_head * list; /* List we are on */struct sock *sk; /* Socket we are owned by 跟一个读写此包的sock 关联*/struct timeval stamp; /* Time we arrived */struct net_device *dev; /* Device we arrived on/are leaving by 该包即将要通过网卡设备或已通过的网卡设备*//* Transport layer header */union{struct tcphdr *th;struct udphdr *uh;struct icmphdr *icmph;struct igmphdr *igmph;struct iphdr *ipiph;struct spxhdr *spxh;unsigned char *raw;} h;//tcp/udp层的协议头,在INET Socket层时会填充;/* Network layer header */union{struct iphdr *iph;struct ipv6hdr *ipv6h;struct arphdr *arph;struct ipxhdr *ipxh;unsigned char *raw;} nh//ip层协议头,在ip层时填充;/* Link layer header */union{struct ethhdr *ethernet;unsigned char *raw;} mac//链路层协议头,在链路层填充;struct dst_entry *dst;//路由信息表,下一个要到达机器地址,此结构里有个output函数,在发包时调用此output把包传给硬件层.整个网络路由表初始化过程不讨论了,/** This is the control buffer. It is free to use for every* layer. Please put your private variables there. If you* want to keep them across layers you have to do a skb_clone()* first. This is owned by whoever has the skb queued A TM.*/char cb[48]; //存放控制命令与控制数据,每层都可自由使用.unsigned int len; /* Length of actual data 实际数据长度,即tial-data */unsigned int data_len;unsigned int csum; /* Checksum */unsigned char __unused, /* Dead field, may be reused */ cloned, /* head may be cloned (check refcnt to be sure). */pkt_type, /* Packet class */ip_summed; /* Driver fed us an IP checksum */ __u32 priority; /* Packet queueing priority */atomic_tusers; /* User count - see datagram.c,tcp.c */unsigned short protocol; /* Packet protocol from driver. 以太网协议*/ //常见的有x.25,arp,以太网ipunsigned short security; /* Security level of packet 包优先级*/ unsigned int truesize; /* Buffer size 缓冲区长度,不是)*/unsigned char *head; /* Head of buffer */unsigned char *data; /* Data head pointer */unsigned char *tail; /* Tail pointer */unsigned char *end; /* End pointer *///指向实际有效数据(从应用层传下来的数据)的指针void (*destructor)(struct sk_buff *); /* Destruct function */#ifdef CONFIG_NETFIL TER/* Can be used for communication between hooks. */unsigned long nfmark;/* Cache info */__u32 nfcache;/* Associated connection, if any */struct nf_ct_info *nfct;#ifdef CONFIG_NETFIL TER_DEBUGunsigned int nf_debug;#endif#endif /*CONFIG_NETFILTER*/#if defined(CONFIG_HIPPI)union{__u32 ifield;} private;#endif#ifdef CONFIG_NET_SCHED__u32 tc_index; /* traffic control index */#endif};从这个结构可以看出,skb_buff{}主要工作在INET Socket层,ip层和硬件层.内核中有很多对此结构操作的函数,由于时间问题,不作进一步讨论.3 .3socket{}类型;struct socket{socket_state state;//连接状态,如SS_CONNECTTED和SS_UNCONNECTED两种,unsigned long flags;struct proto_ops *ops;//指向不同地址族的操作函数集合,对INET 地址族值为inet_proto_ops.为一系列函数指针集合.如下示/*static struct file_operation socket_file_ops={//在应用层时,即文件系统socket_I对应的方法llseek:sock_lseek;// 函数read:sock_read,write:sock_write;open:sock_no_open;//没有这个函数,网卡为特殊设备,通过系统调用socket() 来打开. Realse:sock_release;……以后在此socket上read/write系统调用都会转到sock_read/sock_write函数上;}*/在BSD SOCKET层时,以连接方式SOCK_STREAM为例此时ops初始化为inet_dgram_ops,此结构下的具体函数指针集合如下:/*PF_INET;Inet_release(),inet_bind,inet_stram_connect(),sock_no_sockpair(),inet_accept(),inet_getname(), Tcp_poll(),inet_ioctl(),inet_listen(),inet_shutdown(),inet_setsockopt,inet_sendmsg(),inet_recvmsg ();*///linux支持的地址族类型:UNIX:用于本机进程间通讯的,类似与共享内存及消息队列INET:INET套接字,建立在TCP/IP实现上的.是这次要讨论的AX.25:/以下几种属于别的网络通讯协议Nowell IPX:AppkeTalk:DDP:struct inode *inode;//文件节点,inode.socket_I成员指向对应的socket{}结构指针struct fasync_struct *fasync_list; /* Asynchronous wake up list */struct file *file; /* File back pointer for gc *///struct sock *sk;//很重要的一个数据结构,在INET Socket层中用到,二者互相指向.wait_queue_head_t wait;short type;unsigned char passcred;};代表BSD Socket层中的socket控制结构.注意在应用层socket()是个函数,用于创建一个socket结构.3.4.INET Socket: sock{}在INET Socket数据结构中,管理数据包存放和调度的数据结构示sock,在INET Socket层以下都使用sock{}定义如下://删除了一些次要的元素struct sock {/* Socket demultiplex comparisons on incoming packets. */__u32 daddr; /* Foreign IPv4 addr */__u32 rcv_saddr; /* Bound local IPv4 addr */__u16 dport; /* Destination port */unsigned short num; /* Local port */int bound_dev_if; /* Bound device index if != 0 *//* Main hash linkage for various protocol lookup tables. */struct sock *next;struct sock **pprev;struct sock *bind_next;struct sock **bind_pprev;volatile unsigned char state, /* Connection state */zapped; /* In ax25 & ipx means not linked */__u16 sport; /* Source port */unsigned short family; /* Address family */unsigned char reuse; /* SO_REUSEADDR setting */ unsigned char shutdown;atomic_t refcnt; /* Reference count */socket_lock_t lock; /* Synchronizer... */int rcvbuf; /* Size of receive buffer in bytes最大接受缓冲区大小*/ wait_queue_head_t *sleep; /* Sock wait queue */struct dst_entry *dst_cache; /* Destination cache */rwlock_t dst_lock;atomic_t rmem_alloc; /* Receive queue bytes committed 已用的收缓冲区*/ struct sk_buff_head receive_queue;/* Incoming packets收到的包放在此队里*/ atomic_t wmem_alloc;/* Transmit queue bytes committed已用的写缓冲区*/ struct sk_buff_head write_queue; /* Packet sending queue */atomic_t omem_alloc; /* "o" is "option" or "other" */int wmem_queued; /* Persistent queue size */int forward_alloc; /* Space allocated forward. */__u32 saddr; /* Sending source */unsigned int allocation; /* Allocation mode */int sndbuf; /* Size of send buffer in bytes最大发送缓冲区大小*/ */struct sock *prev;/* Not all are volatile, but some are, so we might as well say they all are.* XXX Make this a flag word -DaveM*/volatile char dead,done,urginline,keepopen,linger,destroy,no_check,broadcast,bsdism;unsigned char debug;unsigned char rcvtstamp;unsigned char use_write_queue;unsigned char userlocks;/* Hole of 3 bytes. Try to pack. */int route_caps;int proc;unsigned long lingertime;int hashent;struct sock *pair;/* The backlog queue is special, it is always used with* the per-socket spinlock held and requires low latency* access. Therefore we special case it's implementation.*/struct {struct sk_buff *head;struct sk_buff *tail;} backlog;//在此sock在读写时,如有数据到达,新的数据包保存在此结构中,读包时如果receive_queue;没有数据,在看此结构中有无.rwlock_t callback_lock;/* Error queue, rarely used. */struct sk_buff_head error_queue;struct proto *prot;#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)union {struct ipv6_pinfo af_inet6;} net_pinfo;#endifunion {struct tcp_opt af_tcp;#if defined(CONFIG_INET) || defined (CONFIG_INET_MODULE)struct raw_opt tp_raw4;#endif#if defined(CONFIG_IPV6) || defined (CONFIG_IPV6_MODULE)struct raw6_opt tp_raw;#endif /* CONFIG_IPV6 */#if defined(CONFIG_SPX) || defined (CONFIG_SPX_MODULE)struct spx_opt af_spx;#endif /* CONFIG_SPX */} tp_pinfo;int err, err_soft; /* Soft holds errors that don'tcause failure but are the causeof a persistent failure not just'timed out' */unsigned short ack_backlog;unsigned short max_ack_backlog;__u32 priority;unsigned short type;unsigned char localroute; /* Route locally only */unsigned char protocol;struct ucred peercred;int rcvlowat;long rcvtimeo;long sndtimeo;#ifdef CONFIG_FIL TER/* Socket Filtering Instructions */struct sk_filter *filter;#endif /* CONFIG_FILTER *//* This is where all the private (optional) areas that don't* overlap will eventually live.*/union {除了tcp/ip/udp之外的一些协议的私有数据,} protinfo;/* This part is used for the timeout functions. */struct timer_list timer; /* This is the sock cleanup timer. */ struct timeval stamp;//时间信息./* Identd and reporting IO signals */struct socket *socket;/* RPC and TUX layer private data */void *user_data;/* Callbacks */void (*state_change)(struct sock *sk);void (*data_ready)(struct sock *sk,int bytes);void (*write_space)(struct sock *sk);void (*error_report)(struct sock *sk);int (*backlog_rcv) (struct sock *sk,struct sk_buff *skb);void (*create_child)(struct sock *sk, struct sock *newsk);void (*destruct)(struct sock *sk);};3.5以上个结构的跳转及函数指针集合.BSD Socket:proto_ops{}INET Socket:proto{},通过BSD Socket的proto_ops结构将操作对象从socket{}切换到sock{};INET Socket的proto{}函数指针集合成员如下(以tcp为例,udp也类似){TCP,tcp_close,tcp_v4_connect,tcp_disconnect,tcp_accept,tcp_ioctl,tcp_v4_init_sock Tcp_sendmsg,tcp_recvmsg,tcp_v4_do_rcv,….//相当于对tcp协议的实现就是对这些函数的实现,}考虑到这四个结构的重要性及相互引用的复杂性,归纳一下这四个结构之间的关系及应用的层次:msghdr{}及socket{}结构在bsd socket层用到,往下转到inet socket及以下层时就改用sock{}跟skb_buff{}结构.在socket中有一个指向sock及inode的指针,但是没有指向msghdr的指针,msghdr中没有任何指向剩下三个的指针.在bsd socket 层会把buf数据的指针付给msghd->iov;注意仅仅是指针赋值,不涉及数据拷贝.让iov与buf指向同一数据区.3.6 struct net_device{//省略大部分内容void *priv;初始化时指向pci-dev[];用于读取一些端口资源。