装盘规划问题的G4算法求解实现
- 格式:pdf
- 大小:217.28 KB
- 文档页数:3

.. . .. . ..算法分析与设计2016/2017(2)实验题目装载问题5种解法学生姓名学生学号. 专业学习资料... . .. . ..学生班级任课教师提交日期2017计算机科学与技术学目录一问题定义 (4)二解决方案 (4)1优先队列式分支限界法求解 (4)1.1算法分析 (4)1.2代码 (4)1.3运行结果 (17)2队列式分支限界法求解 (17)2.1算法分析 (17)2.2代码 (18)2.3测试截图 (30)3回朔法-迭代 (30)3.1算法分析 (30)3.2代码 (30)3.3测试截图 (35)4回朔法-递归 (35)4.1算法分析 (35)4.2代码 (35). 专业学习资料... . .. . ..4.3测试截图 (41)5贪心算法 (42)5.1算法分析 (42)5.2代码 (42)5.3测试截图 (46). 专业学习资料.一问题定义有一批共有n 个集装箱要装上两艘载重量分别为c1 和c2 的轮船,其中集装箱i 的重量为w[i], 且重量之和小于(c1 + c2)。
装载问题要求确定是否存在一个合理的装载方案可将这n 个集装箱装上这两艘轮船。
如果有,找出一种装载方案。
二解决方案1优先队列式分支限界法求解1.1算法分析活结点x在优先队列中的优先级定义为从根结点到结点x的路径所相应的载重量再加上剩余集装箱的重量之和。
优先队列中优先级最大的活结点成为下一个扩展结点。
以结点x为根的子树中所有结点相应的路径的载重量不超过它的优先级。
子集树中叶结点所相应的载重量与其优先级相同。
在优先队列式分支限界法中,一旦有一个叶结点成为当前扩展结点,则可以断言该叶结点所相应的解即为最优解。
此时可终止算法。
1.2代码1.2-1////MaxHeap.htemplate<class T>class MaxHeap{public:MaxHeap(int MaxHeapSize = 10);~MaxHeap() {delete [] heap;}int Size() const {return CurrentSize;}T Max(){ //查找if (CurrentSize == 0){throw OutOfBounds();}return heap[1];}MaxHeap<T>& Insert(const T& x); //增MaxHeap<T>& DeleteMax(T& x); //删void Initialize(T a[], int size, int ArraySize);private:int CurrentSize, MaxSize;T *heap; // element array};template<class T>MaxHeap<T>::MaxHeap(int MaxHeapSize){// Max heap constructor.MaxSize = MaxHeapSize;heap = new T[MaxSize+1];CurrentSize = 0;}template<class T>MaxHeap<T>& MaxHeap<T>::Insert(const T& x){// Insert x into the max heap.if (CurrentSize == MaxSize){cout<<"no space!"<<endl;return *this;}// 寻找新元素x的位置// i——初始为新叶节点的位置,逐层向上,寻找最终位置int i = ++CurrentSize;while (i != 1 && x > heap[i/2]){// i不是根节点,且其值大于父节点的值,需要继续调整heap[i] = heap[i/2]; // 父节点下降i /= 2; // 继续向上,搜寻正确位置}heap[i] = x;return *this;}template<class T>MaxHeap<T>& MaxHeap<T>::DeleteMax(T& x){// Set x to max element and delete max element from heap. // check if heap is emptyif (CurrentSize == 0){cout<<"Empty heap!"<<endl;return *this;}x = heap[1]; // 删除最大元素// 重整堆T y = heap[CurrentSize--]; // 取最后一个节点,从根开始重整// find place for y starting at rootint i = 1, // current node of heapci = 2; // child of iwhile (ci <= CurrentSize){// 使ci指向i的两个孩子中较大者if (ci < CurrentSize && heap[ci] < heap[ci+1]){ci++;}// y的值大于等于孩子节点吗?if (y >= heap[ci]){break; // 是,i就是y的正确位置,退出}// 否,需要继续向下,重整堆heap[i] = heap[ci]; // 大于父节点的孩子节点上升i = ci; // 向下一层,继续搜索正确位置ci *= 2;}heap[i] = y;return *this;}template<class T>void MaxHeap<T>::Initialize(T a[], int size,int ArraySize){// Initialize max heap to array a.delete [] heap;heap = a;CurrentSize = size;MaxSize = ArraySize;// 从最后一个内部节点开始,一直到根,对每个子树进行堆重整 for (int i = CurrentSize/2; i >= 1; i--){T y = heap[i]; // 子树根节点元素// find place to put yint c = 2*i; // parent of c is target// location for ywhile (c <= CurrentSize){// heap[c] should be larger siblingif (c < CurrentSize && heap[c] < heap[c+1]) {c++;}// can we put y in heap[c/2]?if (y >= heap[c]){break; // yes}// noheap[c/2] = heap[c]; // move child upc *= 2; // move down a level}heap[c/2] = y;}}1.2-2///6d3-2.cpp//装载问题优先队列式分支限界法求解#include "stdafx.h"#include "MaxHeap.h"#include <iostream>using namespace std;const int N = 4;class bbnode;template<class Type>class HeapNode{template<class Type>friend void AddLiveNode(MaxHeap<HeapNode<Type>>& H,bbnode *E,Type wt,bo ol ch,int lev);template<class Type>friend Type MaxLoading(Type w[],Type c,int n,int bestx[]);public:operator Type() const{return uweight;}private:bbnode *ptr; //指向活节点在子集树中相应节点的指针Type uweight; //活节点优先级(上界)int level; //活节点在子集树中所处的层序号};class bbnode{template<class Type>friend void AddLiveNode(MaxHeap<HeapNode<Type>>& H,bbnode *E,Type wt,bo ol ch,int lev);template<class Type>friend Type MaxLoading(Type w[],Type c,int n,int bestx[]);friend class AdjacencyGraph;private:bbnode *parent; //指向父节点的指针bool LChild; //左儿子节点标识};template<class Type>void AddLiveNode(MaxHeap<HeapNode<Type>>& H,bbnode *E,Type wt,bool ch,int l ev);template<class Type>Type MaxLoading(Type w[],Type c,int n,int bestx[]);int main(){float c = 70;float w[] = {0,20,10,26,15};//下标从1开始int x[N+1];float bestw;cout<<"轮船载重为:"<<c<<endl;cout<<"待装物品的重量分别为:"<<endl;for(int i=1; i<=N; i++){cout<<w[i]<<" ";}cout<<endl;bestw = MaxLoading(w,c,N,x);cout<<"分支限界选择结果为:"<<endl;for(int i=1; i<=4; i++){cout<<x[i]<<" ";}cout<<endl;cout<<"最优装载重量为:"<<bestw<<endl;return 0;}//将活节点加入到表示活节点优先队列的最大堆H中template<class Type>void AddLiveNode(MaxHeap<HeapNode<Type>>& H,bbnode *E,Type wt,bool ch,int l ev){bbnode *b = new bbnode;b->parent = E;b->LChild = ch;HeapNode<Type> N;N.uweight = wt;N.level = lev;N.ptr = b;H.Insert(N);}//优先队列式分支限界法,返回最优载重量,bestx返回最优解template<class Type>Type MaxLoading(Type w[],Type c,int n,int bestx[]){//定义最大的容量为1000MaxHeap<HeapNode<Type>> H(1000);//定义剩余容量数组Type *r = new Type[n+1];r[n] = 0;for(int j=n-1; j>0; j--){r[j] = r[j+1] + w[j+1];}//初始化int i = 1;//当前扩展节点所处的层bbnode *E = 0;//当前扩展节点Type Ew = 0; //扩展节点所相应的载重量//搜索子集空间树while(i!=n+1)//非叶子节点{//检查当前扩展节点的儿子节点if(Ew+w[i]<=c){AddLiveNode(H,E,Ew+w[i]+r[i],true,i+1); }//右儿子节点AddLiveNode(H,E,Ew+r[i],false,i+1);//取下一扩展节点HeapNode<Type> N;H.DeleteMax(N);//非空i = N.level;E = N.ptr;Ew = N.uweight - r[i-1];}//构造当前最优解for(int j=n; j>0; j--){bestx[j] = E->LChild;E = E->parent;}return Ew;}1.3运行结果2队列式分支限界法求解2.1算法分析在算法的循环体中,首先检测当前扩展结点的左儿子结点是否为可行结点。

指派问题的四个计算步骤
指派问题是一种优化问题,旨在找到最佳的分配方式。
解决指派问题通常有四个计算步骤:
1. 创建代价矩阵:将问题抽象为一个二维矩阵,其中每个元素表示将某个任务分配给某个工人的成本或者效益。
代价矩阵的大小为n行m列,其中n表示任务的数量,m表示工人的数量。
2. 匹配行和列:通过在代价矩阵中查找每一行和列的最小元素,将其标记为零。
如果需要,通过减去每一行和列的最小元素,可以使矩阵中至少有n个零。
3. 寻找最佳分配方案:通过选择代价矩阵中的一个零,并将其标记为星号,然后将与该零所在行或列相交的所有其他零标记为井号。
如果井号的数量等于n,则找到了一个最佳分配方案。
如果不是,请执行第4步。
4. 修改代价矩阵:通过选择未被标记的最小元素,并从该元素中减去所有未被标记的行和列的最小值,可以修改代价矩阵。
然后,返回第2步继续迭代,直到找到一个最佳分配方案。
这些计算步骤被称为匈牙利算法或者KM算法。
通过依次执
行这些步骤,可以找到指派问题的最优解。

算法——分⽀限界法(装载问题)对⽐回溯法回溯法的求解⽬标是找出解空间中满⾜约束条件的所有解,想必之下,分⽀限界法的求解⽬标则是找出满⾜约束条件的⼀个解,或是满⾜约束条件的解中找出使某⼀⽬标函数值达到极⼤或极⼩的解,即在某种意义下的最优解。
另外还有⼀个⾮常⼤的不同点就是,回溯法以深度优先的⽅式搜索解空间,⽽分⽀界限法则以⼴度优先的⽅式或以最⼩耗费优先的⽅式搜索解空间。
分⽀限界法的搜索策略在当前节点(扩展节点)处,先⽣成其所有的⼉⼦节点(分⽀),然后再从当前的活节点(当前节点的⼦节点)表中选择下⼀个扩展节点。
为了有效地选择下⼀个扩展节点,加速搜索的进程,在每⼀个活节点处,计算⼀个函数值(限界),并根据函数值,从当前活节点表中选择⼀个最有利的节点作为扩展节点,使搜索朝着解空间上有最优解的分⽀推进,以便尽快地找出⼀个最优解。
分⽀限界法解决了⼤量离散最优化的问题。
选择⽅法1.队列式(FIFO)分⽀限界法队列式分⽀限界法将活节点表组织成⼀个队列,并将队列的先进先出原则选取下⼀个节点为当前扩展节点。
2.优先队列式分⽀限界法优先队列式分⽀限界法将活节点表组织成⼀个优先队列,并将优先队列中规定的节点优先级选取优先级最⾼的下⼀个节点成为当前扩展节点。
如果选择这种选择⽅式,往往将数据排成最⼤堆或者最⼩堆来实现。
例⼦:装载问题有⼀批共n个集装箱要装上2艘载重量分别为c1,c2的轮船,其中集装箱i的重量为wi,且要求确定是否有⼀个合理的装载⽅案可将这n个集装箱装上这2艘轮船。
可证明,采⽤如下策略可以得到⼀个最优装载⽅案:先尽可能的将第⼀艘船装满,其次将剩余的集装箱装到第⼆艘船上。
代码如下://分⽀限界法解装载问题//⼦函数,将当前活节点加⼊队列template<class Type>void EnQueue(Queue<Type> &Q, Type wt, Type &bestw, int i, int n){if(i == n) //可⾏叶结点{if(wt>bestw) bestw = wt ;}else Q.Add(wt) ; //⾮叶结点}//装载问题先尽量将第⼀艘船装满//队列式分⽀限界法,返回最优载重量template<class Type>Type MaxLoading(Type w[],Type c,int n){//初始化数据Queue<Type> Q; //保存活节点的队列Q.Add(-1); //-1的标志是标识分层int i=1; //i表⽰当前扩展节点所在的层数Type Ew=0; //Ew表⽰当前扩展节点的重量Type bestw=0; //bestw表⽰当前最优载重量//搜索⼦集空间树while(true){if(Ew+w[i]<=c) //检查左⼉⼦EnQueue(Q,Ew+w[i],bestw,i,n); //将左⼉⼦添加到队列//将右⼉⼦添加到队列即表⽰不将当前货物装载在第⼀艘船EnQueue(Q,Ew,bestw,i,n);Q.Delete(Ew); //取下⼀个节点为扩展节点并将重量保存在Ewif(Ew==-1) //检查是否到了同层结束{if(Q.IsEmpty()) return bestw; //遍历完毕,返回最优值Q.Add(-1); //添加分层标志Q.Delete(Ew); //删除分层标志,进⼊下⼀层i++;}}}算法MaxLoading的计算时间和空间复杂度为O(2^n).上述算法可以改进,设r为剩余集装箱的重量,当Ew+r<=bestw的时候,可以将右⼦树剪去。

面向对象组装技术中的构造法时间加减乘除四则运算
面向对象组装技术中的构造法时间加减乘除四则运算是指在面
向对象的设计模式中,使用构造法来实现时间的加减乘除四种基本数学运算。
这种技术可以在编程过程中简化代码结构,提高程序的可维护性和可读性。
构造法是指通过对象的构造函数来创建对象的方法。
在实现时间的加减乘除四种基本数学运算时,可以使用构造函数来创建一个新的时间对象,并根据业务需求对时间进行相应的加减乘除运算。
例如,在实现时间的加法时,可以创建一个新的时间对象,将两个时间对象的小时数、分钟数、秒数分别相加,并对结果进行处理,使其符合时间的格式要求。
在实现时间的减法时,可以创建一个新的时间对象,将两个时间对象的小时数、分钟数、秒数分别相减,并对结果进行处理,使其符合时间的格式要求。
通过使用构造法时间加减乘除四则运算,可以避免在编程过程中出现冗余的代码和重复的逻辑判断,从而提高程序的效率和可维护性。
同时,这种技术还可以使程序的结构更加清晰,使代码更易于理解和修改。
总之,面向对象组装技术中的构造法时间加减乘除四则运算是一种实用的编程技术,可以帮助程序员更加高效地实现时间的基本数学运算。
- 1 -。

最优装载问题(贪⼼)⼀、实验内容运⽤贪⼼算法解决活动安排问题(或最优装载问题)使⽤贪⼼算法解决最优装载问题。
⼆、所⽤算法基本思想及复杂度分析1.算法基本思想贪⼼算法是指在对问题求解时,总是做出在当前看来是最好的选择。
也就是说,不从整体最优上加以考虑,它所做出的仅是在某种意义上的局部最优解。
⽤局部解构造全局解,即从问题的某⼀个初始解逐步逼近给定的⽬标,以尽可能快的求得更好的解。
当某个算法中的某⼀步不能再继续前进时,算法停⽌。
2.问题分析及算法设计问题分析:(1)给定n个古董,要把它们装到装载量为c的装载船上。
(2)⾸先需要对这n个古董进⾏质量从⼩到⼤的排序。
(3)然后每次都选择最轻的,接着再从剩下的n-1件物品中选择最轻的。
(4)重复第(3)步骤,直到当前载重量⼤于装载船的最⼤装载量,停⽌装载。
(5)此时得到最优的贪⼼⽅案,记录下装载的最⼤古董数。
算法设计:(1)算法策略:把n件物品从⼩到⼤排序,然后根据贪⼼策略尽可能多的选出前i个物品,直到不能装为⽌。
(2)特例:算法复杂度分析由最优装载问题的贪⼼选择性质和最优⼦结构性质,可知将这些古董按照其重量从⼩到⼤排序,所以算法所需的计算时间为O(nlogn)。
三、源程序核⼼代码及注释(截图)四、运⾏结果五、调试和运⾏程序过程中产⽣的问题及解决⽅法,实验总结(5⾏以上)这⾥的调试,没有什么⼤问题,单纯的依次⽐较,判断,从⽽得到结果。
这次实验让我对贪⼼算法有了更深刻的认识,其主要是从问题的初始解出发,按照当前最佳的选择,把问题归纳为更⼩的相似的⼦问题,并使⼦问题最优,再由⼦问题来推导出全局最优解。
贪⼼算法虽然求的是局部最优解,但往往许多问题的整体最优解都是通过⼀系列的局部最优解的选择来达到的,所以贪⼼算法不⼀定可以得到能推导出问题的最优解,但其解法是最优解的近似解。
懂得算法的原理,还需要多去练习才能更好的掌握其⽤法。
源码:#include<iostream>#include<algorithm>#define MAXN 1000005using namespace std;int w[MAXN];//每件古董的重量int main(){int c,n;//c:载重量,n古董数int sum = 0;//装⼊古董的数量int tmp = 0;//装⼊古董的重量cin >> c >> n;for(int i= 1; i <= n; ++i)cin >> w[i];sort(w+1,w+1+n);for(int i = 1; i <= n; ++i){tmp += w[i];if(tmp <= c)++sum;elsebreak;}cout << sum << endl;return 0;}。
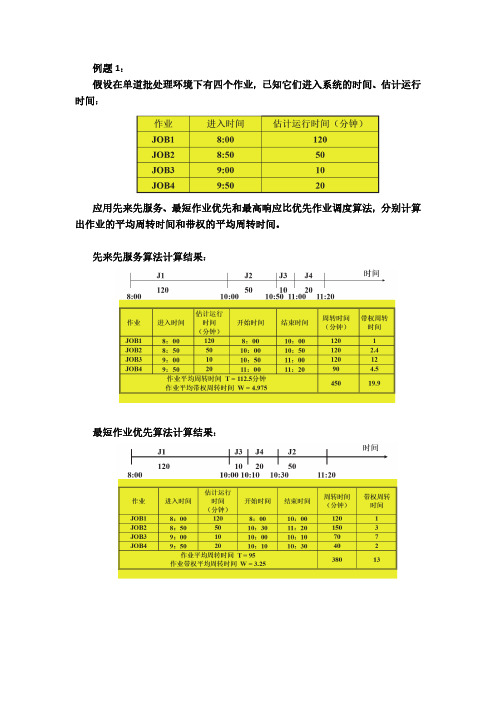
例题1:假设在单道批处理环境下有四个作业,已知它们进入系统的时间、估计运行时间:应用先来先服务、最短作业优先和最高响应比优先作业调度算法,分别计算出作业的平均周转时间和带权的平均周转时间。
先来先服务算法计算结果:最短作业优先算法计算结果:最高响应比算法计算结果例题2:在两道环境下有四个作业, 已知它们进入系统的时间、估计运行时间,作业调度采用短作业优先算法,作业被调度运行后不再退出, 进程调度采用剩余时间最短的抢先调度算法(假设一个作业创建一个进程)。
请给出这四个作业的执行时间序列,并计算出平均周转时间及带权平均周转时间。
10:00,JOB1进入,只有一作业,JOB1被调入执行,10:05,JOB2到达,最多允许两作业同时进入,所以JOB2也被调入;内存中有两作业,哪一个执行?题目规定当一新作业运行后,可按作业运行时间长短调整执行次序;即基于优先数可抢占式调度策略,优先数是根据作业估计运行时间大小来决定的,由于JOB2运行时间(20分)比JOB1少(到10:05,JOB1还需25分钟),所以JOB2运行,而JOB1等待。
10:10,JOB3到达输入井,内存已有两作业,JOB3不能马上进入内存;10:20,JOB4也不能进入内存,10:25,JOB2运行结束,退出,内存中剩下JOB1,输入井中有两作业JOB3和JOB4,如何调度?作业调度算法:最短作业优先,因此JOB3进入内存,比较JOB1和JOB3运行时间,JOB3运行时间短,故JOB3运行,同样,JOB3退出后,下一个是JOB4,JOB4结束后,JOB1才能继续运行。
四个作业的执行时间序列为:JOB1:10:00—10:05,10:40—11:05 JOB2:10:05—10:25JOB3:10:25—10:30JOB4:10:30—10:40。

课程设计报告(本科)课程:计算机操作系统学号:姓名:班级:计算机科学与技术(2010网络工程)教师:时间:2012.12.17-2013.1.7计算机科学与技术系附件:源程序代码#include "stdio.h"#include "stdlib.h"void CopyL(int Sour[],int Dist[] ,int x); //数组Sour复制到数组Dist,复制到x个数void SetDI(int DiscL[]); //随机生成磁道数void Print(int Pri[],int x); //打印输出数组Privoid DelInq(int Sour[],int x,int y); //数组Sour把x位置的数删除,并把y前面的数向前移动,y后的数保持不变(即会出现2个y)void FCFS(int Han,int DiscL[]); //先来先服务算法(FCFS)void SSTF(int Han,int DiscL[]); //最短寻道时间优先算法(SSTF)int SCAN(int Han,int DiscL[],int x,int y); //扫描算法(SCAN)void CSCAN(int Han,int DiscL[]); //循环扫描算法(CSCAN)//void N_Step_SCAN(int Han1,int DiscL[]); //N步扫描算法(NStepScan)void PaiXu(); //寻道长度由低到高排序void Pri();int NAll=0;int Best[5][2]; //用作寻道长度由低到高排序时存放的数组int Limit=0; //输入寻找的范围磁道数iint Jage;float Aver=0;int main(){int i;int DiscLine[10]; //声明准备要生成的随机磁道号的数组int Hand; //磁道数int Con=1;int n;while(Con==1){Jage=0;printf("\n 请输入初始的磁道数(0<n<65536):");scanf("%d",&Hand);printf("\n+ 输入寻找的范围:");scanf("%d",&Limit);if(Limit>65536){printf("超出范围!");}else{printf(" *********************************************\n");printf(" **************** 磁盘调度算法******************\n");printf(" *********************************************\n");printf("* 1.先来先服务算法(FCFS) *\n");printf(" * 2.最短寻道时间优先算法(SSTF) *\n");printf(" * 3.扫描算法(SCAN) *\n");printf(" * 4.循环扫描算法(CSCAN) *\n");printf(" *********************************************\n");scanf("%d",&n);if(n==0) exit(0);printf("\n");switch(n){case 1:SetDI(DiscLine); //随机生成磁道数FCFS(Hand,DiscLine); //先来先服务算法(FCFS) break;case 2:SetDI(DiscLine); //随机生成磁道数SSTF(Hand,DiscLine); //最短寻道时间优先算法(SSTF) break;case 3:SetDI(DiscLine); //随机生成磁道数SCAN(Hand,DiscLine,0,9); //扫描算法(SCAN) break;case 4:SetDI(DiscLine); //随机生成磁道数CSCAN(Hand,DiscLine); //循环扫描算法(CSCAN) break;case 5:SetDI(DiscLine); //随机生成磁道数FCFS(Hand,DiscLine); //先来先服务算法(FCFS) SSTF(Hand,DiscLine); //最短寻道时间优先算法(SSTF) SCAN(Hand,DiscLine,0,9); //扫描算法(SCAN) CSCAN(Hand,DiscLine); //循环扫描算法(CSCAN) PaiXu(); //寻道长度由低到高排序printf("\n\n+ 寻道长度由低到高排序:");for(i=0;i<5;i++){printf("%4d ",Best[i][0]);}break;}printf("\n\n+ 是否继续(按0结束,按1继续)?");scanf("%5d",&Con);}}return 0;}//数组Sour复制到数组Dist,复制到x个数void CopyL(int Sour[],int Dist[] ,int x){int i;for(i=0;i<=x;i++){Dist[i]=Sour[i];}}//打印输出数组Privoid Print(int Pri[],int x){int i;for(i=0;i<=x;i++){printf("%5d",Pri[i]);}}//随机生成磁道数void SetDI(int DiscL[]){int i;for(i=0;i<=9;i++){DiscL[i]=rand()%Limit;//随机生成10个磁道号}printf("+ 需要寻找的磁道号:");Print(DiscL,9); //输出随机生成的磁道号printf("\n");}//数组Sour把x位置的数删除,并把y前面的数向前移动,y后的数保持不变(即会出现2个y)void DelInq(int Sour[],int x,int y){int i;for(i=x;i<y;i++){Sour[i]=Sour[i+1];x++;}}//先来先服务算法(FCFS)void FCFS(int Han,int DiscL[]){int RLine[10]; //将随机生成的磁道数数组Discl[]复制给数组RLine[]int i,k,All,Temp; //Temp是计算移动的磁道距离的临时变量All=0; //统计全部的磁道数变量k=9; //限定10个的磁道数CopyL(DiscL,RLine,9); //复制磁道号到临时数组RLineprintf("\n+ 按照FCFS算法磁道的访问顺序为:");All=Han-RLine[0];for(i=0;i<=9;i++){Temp=RLine[0]-RLine[1];//求出移动磁道数,前一个磁道数减去后一个磁道数得出临时的移动距离if(Temp<0)Temp=(-Temp);//移动磁道数为负数时,算出相反数作为移动磁道数printf("%5d",RLine[0]);All=Temp+All;//求全部磁道数的总和DelInq(RLine,0,k);//每个磁道数向前移动一位k--;}Best[Jage][1]=All;//Best[][1]存放移动磁道数Best[Jage][0]=1; //Best[][0]存放算法的序号为:1Jage++;//排序的序号加1Aver=((float) All)/10;//求平均寻道次数printf("\n+ 移动磁道数:<%5d> ",All);printf("\n+ 平均寻道长度:*%0.2f* ",Aver);}//最短寻道时间优先算法(SSTF)void SSTF(int Han,int DiscL[]){int i,j,k,h,All;int Temp; //Temp是计算移动的磁道距离的临时变量int RLine[10]; //将随机生成的磁道数数组Discl[]复制给数组RLine[]int Min;All=0; //统计全部的磁道数变量k=9; //限定10个的磁道数CopyL(DiscL,RLine,9); //复制磁道号到临时数组RLineprintf("\n+ 按照SSTF算法磁道的访问顺序为:");for(i=0;i<=9;i++){Min=64000;for(j=0;j<=k;j++) //内循环寻找与当前磁道号最短寻道的时间的磁道号{if(RLine[j]>Han) //如果第一个随机生成的磁道号大于当前的磁道号,执行下一句Temp=RLine[j]-Han; //求出临时的移动距离elseTemp=Han-RLine[j]; //求出临时的移动距离if(Temp<Min) //如果每求出一次的移动距离小于Min,执行下一句{Min=Temp; //Temp临时值赋予Minh=j; //把最近当前磁道号的数组下标赋予h}}All=All+Min; //统计一共移动的距离printf("%5d",RLine[h]);Han=RLine[h];DelInq(RLine,h,k); //每个磁道数向前移动一位k--;}Best[Jage][1]=All;//Best[][1]存放移动磁道数Best[Jage][0]=2;//Best[][0]存放算法的序号为:2Jage++;//排序序号加1Aver=((float)All)/10;//求平均寻道次数printf("\n+ 移动磁道数:<%5d> ",All);printf("\n+ 平均寻道长度:*%0.2f* ",Aver);}//扫描算法(SCAN)int SCAN(int Han,int DiscL[],int x,int y){int j,n,k,h,m,All;int t=0;int Temp;int Min;int RLine[10]; //将随机生成的磁道数数组Discl[]复制给数组RLine[]int Order;Order=1;k=y;m=2; //控制while语句的执行,即是一定要使当前磁道向内向外都要扫描到All=0; //统计全部的磁道数变量CopyL(DiscL,RLine,9); //复制磁道号到临时数组RLineprintf("\n+ 按照SCAN算法磁道的访问顺序为:");Min=64000;for(j=x;j<=y;j++) //寻找与当前磁道号最短寻道的时间的磁道号{if(RLine[j]>Han) //如果第一个随机生成的磁道号大于当前的磁道号,执行下一句Temp=RLine[j]-Han; //求出临时的移动距离elseTemp=Han-RLine[j]; //求出临时的移动距离if(Temp<Min){Min=Temp; //Temp临时值赋予Minh=j; //把最近当前磁道号的数组下标赋予h}}All=All+Min;printf("%5d",RLine[h]);if(RLine[h]>=Han){ //判断磁道的移动方向,即是由里向外还是由外向里Order=0;t=1;}Han=RLine[h];DelInq(RLine,h,k); //每个磁道数向前移动一位k--;while(m>0){if(Order==1) //order是判断磁盘扫描的方向标签,order是1的话,磁道向内移动{for(j=x;j<=y;j++){h=-1;Min=64000;for(n=x;n<=k;n++) //判断离当前磁道最近的磁道号{if(RLine[n]<=Han){Temp=Han-RLine[n];if(Temp<Min){Min=Temp; //Temp临时值赋予Minh=n; //把最近当前磁道号的数组下标赋予h}}}if(h!=-1){All=All+Min; //叠加移动距离printf("%5d",RLine[h]);Han=RLine[h]; //最近的磁道号作为当前磁道DelInq(RLine,h,k);k--;}}Order=0; //当完成向内的移动,order赋予0,执行else语句,使磁道向外移动m--; //向内完成一次,m减一次,保证while循环执行两次}else //order是0的话,磁道向外移动{for(j=x;j<=y;j++){h=-1;Min=64000;for(n=x;n<=k;n++) //判断离当前磁道最近的磁道号{if(RLine[n]>=Han){Temp=RLine[n]-Han;if(Temp<Min){Min=Temp; //Temp临时值赋予Minh=n; //把最近当前磁道号的数组下标赋予h}}}if(h!=-1){All=All+Min; //叠加移动距离printf("%5d",RLine[h]);Han=RLine[h]; //最近的磁道号作为当前磁道DelInq(RLine,h,k);k--;}}Order=1; //当完成向内的移动,order赋予0,执行else语句,使磁道向外移动m--; //向内完成一次,m减一次,保证while循环执行两次}}NAll=NAll+All;if((y-x)>5){Best[Jage][1]=All;//Best[][1]存放移动磁道数Best[Jage][0]=3;//Best[][0]存放算法的序号为:3Jage++;//排序序号加1Aver=((float)All)/10;//求平均寻道次数printf("\n+ 移动磁道数:<%5d> ",All);printf("\n+ 平均寻道长度:*%0.2f* ",Aver);}if(t==1) printf("\n+ 磁道由内向外移动");else printf("\n+ 磁道由外向内移动");return(Han);}//循环扫描算法(CSCAN)void CSCAN(int Han,int DiscL[]){int j,h,n,Temp,m,k,All,Last,i;int RLine[10]; //将随机生成的磁道数数组Discl[]复制给数组RLine[]int Min;int tmp=0;m=2;k=9;All=0; //统计全部的磁道数变量Last=Han;CopyL(DiscL,RLine,9); //复制磁道号到临时数组RLineprintf("\n+ 按照CSCAN算法磁道的访问顺序为:");while(k>=0){for(j=0;j<=9;j++) //从当前磁道号开始,由内向外搜索离当前磁道最近的磁道号{h=-1;Min=64000;for(n=0;n<=k;n++){if(RLine[n]>=Han){Temp=RLine[n]-Han;if(Temp<Min){Min=Temp;h=n;}}}if(h!=-1){All=All+Min; //统计一共移动的距离printf("%5d",RLine[h]);Han=RLine[h];Last=RLine[h];DelInq(RLine,h,k);k--;}}if(k>=0){ tmp=RLine[0];for(i=0;i<k;i++)//算出剩下磁道号的最小值{if(tmp>RLine[i]) tmp=RLine[i];}Han=tmp;//把最小的磁道号赋给HanTemp=Last-tmp;//求出最大磁道号和最小磁道号的距离差All=All+Temp;}}Best[Jage][1]=All;//Best[][1]存放移动磁道数Best[Jage][0]=4;//Best[][0]存放算法的序号为:4Jage++;//排序序号加1Aver=((float)All)/10;//求平均寻道次数printf("\n+ 移动磁道数:<%5d> ",All);printf("\n+ 平均寻道长度:*%0.2f* ",Aver);}void PaiXu(){int i,j,Temp;for(i=0;i<5;i++){for(j=0;j<4;j++){if(Best[j][1]>Best[j+1][1]) //如果前一个算法的移动磁道距离大于后一个移动磁道数,执行下面语句{Temp=Best[j+1][1]; //从这起下三行执行冒泡法将移动距离大小排序,排完后则执行每个算法的排序Best[j+1][1]=Best[j][1];Best[j][1]=Temp;Temp=Best[j+1][0]; //将每个算法的序号用冒泡法排序Best[j+1][0]=Best[j][0];Best[j][0]=Temp;}}}}。

0034算法笔记——【分⽀限界法】最优装载问题问题描述有⼀批共个集装箱要装上2艘载重量分别为C1和C2的轮船,其中集装箱i的重量为Wi,且装载问题要求确定是否有⼀个合理的装载⽅案可将这个集装箱装上这2艘轮船。
如果有,找出⼀种装载⽅案。
容易证明:如果⼀个给定装载问题有解,则采⽤下⾯的策略可得到最优装载⽅案。
(1)⾸先将第⼀艘轮船尽可能装满;(2)将剩余的集装箱装上第⼆艘轮船。
1、队列式分⽀限界法求解在算法的循环体中,⾸先检测当前扩展结点的左⼉⼦结点是否为可⾏结点。
如果是则将其加⼊到活结点队列中。
然后将其右⼉⼦结点加⼊到活结点队列中(右⼉⼦结点⼀定是可⾏结点)。
2个⼉⼦结点都产⽣后,当前扩展结点被舍弃。
活结点队列中的队⾸元素被取出作为当前扩展结点,由于队列中每⼀层结点之后都有⼀个尾部标记-1,故在取队⾸元素时,活结点队列⼀定不空。
当取出的元素是-1时,再判断当前队列是否为空。
如果队列⾮空,则将尾部标记-1加⼊活结点队列,算法开始处理下⼀层的活结点。
节点的左⼦树表⽰将此集装箱装上船,右⼦树表⽰不将此集装箱装上船。
设bestw是当前最优解;ew是当前扩展结点所相应的重量;r是剩余集装箱的重量。
则当ew+r为了在算法结束后能⽅便地构造出与最优值相应的最优解,算法必须存储相应⼦集树中从活结点到根结点的路径。
为此⽬的,可在每个结点处设置指向其⽗结点的指针,并设置左、右⼉⼦标志。
找到最优值后,可以根据parent回溯到根节点,找到最优解。
算法具体代码实现如下:1、Queue.h[cpp]view plain copy1.#include/doc/951702836.htmling namespace std;3.4.template5.class Queue6.{7.public:8. Queue(int MaxQueueSize=50);9. ~Queue(){delete [] queue;}10.bool IsEmpty()const{return front==rear;}11.bool IsFull(){return ( ( (rear+1) %MaxSize==front )?1:0);}12. T Top() const;13. T Last() const;14. Queue& Add(const T& x);15. Queue& AddLeft(const T& x);16. Queue& Delete(T &x);17.void Output(ostream& out)const;18.int Length(){return (rear-front);}19.private:20.int front;21.int rear;22.int MaxSize;23. T *queue;24.};25.26.template27.Queue::Queue(int MaxQueueSize)28.{29. MaxSize=MaxQueueSize+1;30. queue=new T[MaxSize];31. front=rear=0;32.}33.34.template35.T Queue::Top()const36.{37.if(IsEmpty())38. {39. cout<<"queue:no element,no!"<40.return 0;41. }42.else return queue[(front+1) % MaxSize];43.}44.45.template46.T Queue ::Last()const47.{48.if(IsEmpty())49. {50. cout<<"queue:no element"<51.return 0;52. }53.else return queue[rear];54.}55.56.template57.Queue& Queue::Add(const T& x)58.{59.if(IsFull())cout<<"queue:no memory"<60.else61. {62. rear=(rear+1)% MaxSize;63. queue[rear]=x;64. }65.return *this;66.}67.68.template69.Queue& Queue::AddLeft(const T& x)70.{71.if(IsFull())cout<<"queue:no memory"<72.else73. {74. front=(front+MaxSize-1)% MaxSize;75. queue[(front+1)% MaxSize]=x;76. }77.return *this;78.}79.80.template81.Queue& Queue ::Delete(T & x)82.{83.if(IsEmpty())cout<<"queue:no element(delete)"<84.else85. {86. front=(front+1) % MaxSize;87. x=queue[front];88. }89.return *this;90.}91.92.93.template94.void Queue ::Output(ostream& out)const95.{96.for(int i=rear%MaxSize;i>=(front+1)%MaxSize;i--)97. out<98.}99.100.template101.ostream& operator << (ostream& out,const Queue& x) 102.{x.Output(out);return out;} 2、6d3-1.cpp[cpp]view plain copy1.//装载问题队列式分⽀限界法求解2.#include "stdafx.h"3.#include "Queue.h"4.#include/doc/951702836.htmling namespace std;6.7.const int N = 4;8.9.template10.class QNode11.{12.template13.friend void EnQueue(Queue*>&Q,Type wt,int i,int n,Type bestw,QNode*E,QNode *&bestE,int bestx[],bool ch);14.15.template16.friend Type MaxLoading(Type w[],Type c,int n,int bestx[]);17.18.private:19. QNode *parent; //指向⽗节点的指针20.bool LChild; //左⼉⼦标识21. Type weight; //节点所相应的载重量22.};23.24.template25.void EnQueue(Queue*>&Q,Type wt,int i,int n,Type bestw,QNode >*E,QNode *&bestE,int bestx[],bool ch);26.27.template28.Type MaxLoading(Type w[],Type c,int n,int bestx[]);29.30.int main()31.{32.float c = 70;33.float w[] = {0,20,10,26,15};//下标从1开始34.int x[N+1];35.float bestw;36.37. cout<<"轮船载重为:"<38. cout<<"待装物品的重量分别为:"<39.for(int i=1; i<=N; i++)40. {41. cout<42. }43. cout<44. bestw = MaxLoading(w,c,N,x);45.46. cout<<"分⽀限界选择结果为:"<47.for(int i=1; i<=4; i++)48. {49. cout<50. }51. cout<52. cout<<"最优装载重量为:"<53.54.return 0;55.}56.57.//将活节点加⼊到活节点队列Q中58.template59.void EnQueue(Queue*>&Q,Type wt,int i,int n,Type bestw,QNode >*E,QNode *&bestE,int bestx[],bool ch)60.{61.if(i == n)//可⾏叶节点62. {63.if(wt == bestw)64. {65.//当前最优装载重量66. bestE = E;67. bestx[n] = ch;68. }69.return;70. }71.//⾮叶节点72. QNode *b;73. b = new QNode;74. b->weight = wt;75. b->parent = E;76. b->LChild = ch;77. Q.Add(b);78.}79.80.template81.Type MaxLoading(Type w[],Type c,int n,int bestx[])82.{//队列式分⽀限界法,返回最优装载重量,bestx返回最优解83.//初始化84. Queue*> Q; //活节点队列85. Q.Add(0); //同层节点尾部标识86.int i = 1; //当前扩展节点所处的层87. Type Ew = 0, //扩展节点所相应的载重量88. bestw = 0, //当前最优装载重量89. r = 0; //剩余集装箱重量90.91.for(int j=2; j<=n; j++)92. {93. r += w[j];94. }95.96. QNode *E = 0, //当前扩展节点97. *bestE; //当前最优扩展节点98.99.//搜索⼦集空间树100.while(true)101. {102.//检查左⼉⼦节点103. Type wt = Ew + w[i];104.if(wt <= c)//可⾏节点105. {106.if(wt>bestw)107. {108. bestw = wt;109. }110. EnQueue(Q,wt,i,n,bestw,E,bestE,bestx,true); 111. } 112.113.//检查右⼉⼦节点114.if(Ew+r>bestw)115. {116. EnQueue(Q,Ew,i,n,bestw,E,bestE,bestx,false); 117. } 118. Q.Delete(E);//取下⼀扩展节点119.120.if(!E)//同层节点尾部121. {122.if(Q.IsEmpty())123. {124.break;125. }126. Q.Add(0); //同层节点尾部标识127. Q.Delete(E); //取下⼀扩展节点128. i++; //进⼊下⼀层129. r-=w[i]; //剩余集装箱重量130. }131. Ew =E->weight; //新扩展节点所对应的载重量132. }133.134.//构造当前最优解135.for(int j=n-1; j>0; j--)136. {137. bestx[j] = bestE->LChild;138. bestE = bestE->parent;139. }140.return bestw;141.}程序运⾏结果如图:2、优先队列式分⽀限界法求解解装载问题的优先队列式分⽀限界法⽤最⼤优先队列存储活结点表。



四向穿梭车路径算法拆解程序好嘞,今天我们来聊聊四向穿梭车的路径算法,这个话题听起来可能有点枯燥,但其实它背后隐藏着许多有趣的东西。
想象一下,你家里有个小车车,能在四个方向自由穿梭,像小精灵一样灵活。
这车子可不是随便乱走的,它得有个聪明的计划,知道去哪儿、怎么走,才不会迷了路。
想想你自己逛超市,目标明确,知道要买啥,那种感觉是不是特踏实?说到算法,这词听起来就像是个高深的学问,其实说白了就是一套规则,教这车子怎么在复杂的环境中找路。
就像我们平时看地图,得找到最佳的路线一样。
这小车车可不想绕来绕去,浪费电还浪费时间。
它的目标就是用最少的步骤,快速到达目的地。
想象一下,车子在仓库里穿行,左转、右转、前进、后退,像在玩游戏一样,真是让人惊叹!然后,有了这些算法,车子也能更智能地避开障碍物。
你知道的,仓库里可不是一片坦途,可能有货物、托盘,甚至是其他小车子在那儿。
如果没有好的路径规划,车子真会碰个头破血流,闹出一堆笑话来。
嘿,谁会想看一辆车子在货物堆里打转呢?我们可不希望这种情况发生。
要是车子聪明点,提前判断出前方有障碍,就能优雅地避开,继续前进,真是省心又省力。
再说说路径的优化,这个可重要了。
就像我们出去玩,提前把路线规划好,才能玩得尽兴。
小车车也是一样,得利用一些聪明的算法,比如说A*算法,听起来很高大上,但其实就是个聪明的小助手。
它通过计算,评估每个路径的成本和收益,挑出最佳的那条路。
就像我们吃饭时挑菜,看到最美味的那道,心里立马就有数了,哪有犹豫的时间?路径算法也会考虑时间和距离的因素。
咱们都知道,时间就是金钱,不想花太久在路上,赶紧去完成任务更实际。
车子如果能在最短的时间内完成运输,老板肯定会开心得合不拢嘴。
毕竟谁不想在高效的工作中,顺便还省点油呢?这就好比我们上班时,提前做好计划,才能在高峰期避免拥堵,愉快地到达办公室。
有些时候我们会遇到动态的环境,意思就是周围的情况随时在变。
车子要是遇上这种情况,得随时调整自己的路径。

操作系统课程设计-磁盘调度算法前言摘要:本课程设计的目的是通过设计一个磁盘调度模拟系统,从而使磁盘调度算法更加形象化,使磁盘调度的特点更简单明了,这里主要实现磁盘调度的四种算法,分别是:1、先来先服务算法(FCFS) 2、最短寻道时间优先算法(SSTF) 3、扫描算法(SCAN) 4、循环扫描算法(CSCAN)。
启动磁盘执行输入输出操作时,要把移动臂移动到指定的柱面,再等待指定扇区的旋转到磁头位置下,然后让指定的磁头进行读写,完成信息传送;因此,执行一次输入输出所花的时间有:寻找时间——磁头在移动臂带动下移动到指定柱面所花的时间。
延迟时间——指定扇区旋转到磁头下所需的时间。
传送时间——由磁头进程读写完成信息传送的时间,寻道时间——指计算机在发出一个寻址命令,到相应目标数据被找到所需时间;其中传送信息所花的时间,是在硬件设计时固定的,而寻找时间和延迟时间是与信息在磁盘上的位置有关;然后设计出磁盘调度的设计方式,包括算法思路、步骤,以及要用到的主要数据结构、函数模块及其之间的调用关系等,并给出详细的算法设计,对编码进行了测试与分析。
最后进行个人总结与设计体会。
关键词:最短寻道时间优先算法、扫描算法、总寻道长度.3.2 实现过程中用到的数据结构1.最短寻道时间优先(SSTF)图a SSTF调度算法示例图ciidao[]={55,58,39,18,90,160,150,38,184}(可随机生成多个)用冒泡法对磁道数组进行排序用户输入当前磁道号now,比较当前返回内侧(外侧)扫描将当前磁道号与剩余没有图b SSTF算法流程示例图原磁道号随机组成的数组:cidao[]={55,58,39,18,90,160,150,38,184};排序后的数组={18,38,39,5,58,90,150,160,184};输入当前磁道号:now=100;3839 39 55 55 55 58 58 58 58 90 90 90 90 90 now值:100 90 58 55 39 184160 160150 150 15018 18 18 1838 38 38 3839 39 39 3955 55 55 5558 58 58 5890 90 90 90now值:18 150 160 184图c SSTF算法队列示意图(按磁道访问顺序)2.扫描(SCAN)算法图d SCAN算法示例图原磁道号随机组成的数组:cidao[]={55,58,39,18,90,160,150,38,184};排序后的数组={18,38,39,5,58,90,150,160,184};输入当前磁道号:now=100;选择磁道移动方向;以磁道号增加的方向移动为例:55 58 58 90 90 90 184 184 184 184 160 160 160 160 160 150 150 150 150 150 150 now值:100 150 160 184 90 58 1838 3839 39 3955 55 5558 58 5890 90 90184 184 184160 160 160150 150 150now值:55 39 38图e SCAN算法队列示意图(按磁道访问顺序)3.3 实现过程中用到的系统调用系统模块调用关系图4. 程序设计与实现4.1 最短寻道时间优先算法(SSTF )模块4.1.1程序流程图磁盘调度算法最短寻道扫描算法退出4.1.2 程序说明算法分析①优点:相较于先来先服务算法(FCFS)有更好的寻道性能,使每次的寻道时间最短。

货运物流管理系统中的路径规划算法使用方法随着现代物流业的发展,货运物流管理系统越来越普遍地应用于各个领域。
在这些系统中,路径规划算法起着关键作用,它能够有效地优化货物的运输路径,提高物流效率。
本文将介绍货运物流管理系统中常用的路径规划算法的使用方法,以帮助读者更好地理解和应用这些算法。
1. Dijkstra算法Dijkstra算法是一种用于寻找最短路径的经典算法,在货运物流管理系统中被广泛使用。
该算法的基本思想是从起点开始,逐步更新节点的最短路径,直到找到终点。
下面是使用Dijkstra算法的步骤:步骤一:初始化。
将起点标记为当前节点,并将其他节点的最短路径初始化为无穷大。
步骤二:计算最短路径。
对于当前节点的所有邻接节点,计算通过当前节点到达邻接节点的路径长度,如果该路径长度小于邻接节点的当前最短路径,则更新最短路径。
步骤三:选择下一个节点。
从尚未处理的节点中选择具有最短路径的节点作为下一个当前节点,并将其标记为已处理。
步骤四:重复步骤二和步骤三,直到找到终点或所有节点都被处理。
2. A*算法A*算法是一种综合了Dijkstra算法和启发式搜索的路径规划算法,其在货运物流管理系统中的应用越来越广泛。
A*算法通过评估节点的代价函数来选择最佳路径,代价函数通常由节点到目标节点的实际路径长度和启发函数估计值组成。
下面是使用A*算法的步骤:步骤一:初始化。
将起点标记为当前节点,并计算当前节点到目标节点的启发式函数估计值。
步骤二:计算代价。
对于当前节点的所有邻接节点,计算通过当前节点到达邻接节点的代价,其中代价由当前节点到达邻接节点的实际路径长度和到目标节点的启发式函数估计值组成。
步骤三:选择下一个节点。
从尚未处理的节点中选择具有最小代价的节点作为下一个当前节点,并将其标记为已处理。
步骤四:重复步骤二和步骤三,直到找到终点或所有节点都被处理。
3. Floyd-Warshall算法Floyd-Warshall算法是一种用于解决所有节点间最短路径问题的动态规划算法,在一些货运物流管理系统中得到了广泛应用。

机器人依次夹四个盘子路径规划
对于机器人夹取四个盘子的路径规划,可以使用以下的方案:
1. 确定起点和终点:首先确定机器人的起点位置和四个盘子的终点位置。
假设机器人起点位置为A,四个盘子的终点位置分别为B、C、D、E。
2. 确定夹取顺序:根据具体需求和机器人的特性,确定夹取盘子的顺序。
假设夹取顺序为B、
C、D、E。
3. 生成路径规划:使用路径规划算法,比如A*算法或Dijkstra算法,根据机器人的移动能力和地图布局,生成从起点到终点的最短路径。
4. 考虑夹取操作:在生成路径规划的过程中,还需要考虑机器人夹取盘子的操作。
具体操作可以根据机器人的夹取方式和逻辑进行设定,确保机器人能够顺利夹取并运送盘子。
5. 执行路径规划:将生成的路径规划应用到机器人的控制系统中,使机器人按照规划的路径从起点A依次前往盘子B、C、D、E的终点位置。
需要注意的是,具体的路径规划方案还要考虑地图布局、机器人的移动和夹取能力等因素,并结合实际情况进行调整和优化。
以上仅是一个简单的路径规划思路,具体实施需要根据实际需求进行设计和实现。

生成最优二划分装盘方案的递归算法
孙英;何冬黎;崔耀东
【期刊名称】《计算机仿真》
【年(卷),期】2009(0)9
【摘要】针对物流领域的研究装盘问题,为提高装载效率,在矩形托盘中正交的布置最多数目同尺寸长方体小箱,并且小箱之间不发生重叠.采用二划分装盘方案.所谓"二划分",是指一条划分线总是贯穿被划分的区域,将区域划分为二个较小的矩形子区域.二划分方案可以通过使用水平或竖直的划分线,将装裁区域递归地二划分为若干个子区域,每一子区域有且仅有一个小箱.采用递归算法,通过适当设置成本参数,生成排数最少的最优二划分装盘方案.实验计算结果表明所述算法可以有效地简化装箱方案.
【总页数】4页(P160-163)
【作者】孙英;何冬黎;崔耀东
【作者单位】楚雄师范学院计算机科学系,云南,楚雄,675000;广西师范大学计算机科学系,广西,桂林,541004;广西师范大学计算机科学系,广西,桂林,541004
【正文语种】中文
【中图分类】TP301.6
【相关文献】
1.生成矩形毛坯最优两段排样方式的递归算法 [J], 崔耀东;季君;曾窕俊
2.生成矩形毛坯最优T形排样方式的递归算法 [J], 崔耀东
3.使用队列生成二叉链表树的非递归算法实现 [J], 高永平;陆玲
4.使用队列生成二叉链表树的非递归算法实现 [J], 高永平;陆玲
5.数据结构中二叉树的生成及遍历非递归算法浅析 [J], 吉冬梅
因版权原因,仅展示原文概要,查看原文内容请购买。



试用带限界的回溯法求解装船问题的实例n=4,w=[8,6,2,
1.试用带限界的回溯法求解装船问题的实例:n= 4,w= [ 8 , 6 ,
2 ,
3 ],c1 = 12,。
要求(1)写出两种限界方法 (2)展开的部分状态空间树(使用定长元组表示)并标明相应的参数。
2.使用带限界的回溯法求解以下带截止期的调度问题的实例:
n=4,作业集:{(5,1,1),(10,3,2),(6,2,1),(5,3,1)},每个3元组的第一个分量为罚款额,第二个分量为截止期,第三个分量为作业的执行时间。
要求:
1)给出限界条件;
2)画出展开的部分状态空间树,并标明相应的参数值.
3.试用分枝限界法求解以下最小罚款额调度问题:令三元组(p i,d i,t i)表示作业的罚款额、截止期和执行时间,4个作业分别为(8,2,1)、(4,2,1)、(9,3,2)、(2,1,1)。
要求:写出所使用的限界函数,画出分枝限界过程中展开的部分状态空间树。
(使用变长元组表示)。