DB2_pureScale_for_SAP_101110
- 格式:ppt
- 大小:3.30 MB
- 文档页数:46

IBM® DB2® pureScale Feature™ deployment FAQ for IBM® System x®This FAQ presents a collection of advice and best practices for IBM DB2 pureScale Feature deployment on IBM System x hardware. The principles are similar to already supported POWER6® and POWER7 Systems™ hardware and extend to future supported System x hardware. All the advice provided is based on supported features. If any question is specific to an unsupported feature or configuration, it will be noted. This document is for internal use only.The current list of supported System x servers is 3650 M3, 3690 X5 and 3850 X5. Additional information is available from the Installation prerequisites for the DB2 pureScale Feature topic in the DB2 Information Center.InfiniBand™At the core of the DB2 pureScale Feature on System x hardware is the InfiniBand (IB) communications infrastructure, which consists of:•IB Quad Data Rate (QDR) adapters•IB cables•IB switches.For the successful deployment of the DB2 pureScale Feature, all of the matching part numbers and units need to be ordered, installed, cabled, and assembled correctly.What InfiniBand QDR switch is needed?The following table lists the supported DB2 pureScale Feature InfiniBand QDR switches:Mellanox Switch Part Number Switch descriptionMIS5030Q-1SFC Mellanox IB Switch (36 ports) - InfiniScale® IV QDRInfiniBand Switch, 36 Quad Small Form-FactorPluggable (QSFP) portsTable 1. Supported DB2 pureScale Feature InfiniBand QDR switchesWhat InfiniBand QDR adapters are needed?The following table lists the supported DB2 pureScale Feature InfiniBand adapters: Mellanox IB Adapter PartNumberAdapter descriptionMHQH29B-XTR Mellanox IB Adapter ConnectX®-2 VPI adaptercard, dual-port QSFP, IB 40Gb/sTable 2. Supported DB2 pureScale Feature InfiniBand QDR adapterWhat InfiniBand cables are needed?The selection of InfiniBand cables depends on their length considering how far your DB2 pureScale environment will be from the switch.Mellanox IB Cable PartNumberCable descriptionMCC4Q30C-002 IB Cable (2M copper) - 4x QSFP latch, 30 AWG, 2metersMCD4Q26C-005 IB Cable (10M copper) - 4x QSFP latch, 26 AWG, 5metersMFP4R12CB-010 IB Cable (10M fiber) - 40Gb/s InfiniBand QSFP, 10meters fiber optic cableTable 3. Supported InfiniBand cablesCan InfiniBand QDR adapter be virtualized?Currently, there is no support for IB adapter virtualization on System x servers. You need to use a dedicated InfiniBand QDR adapter.How many InfiniBand QDR adapters are supported by System x servers? Can more than 1 IB adapter be used?The number of InfiniBand QDR adapters is limited by the number of PCI-E slots. However, without virtualization, you can only use 1 InfiniBand QDR adapter per server.IBM System x server model Max numberadaptersCommentX3650 M3 4 4 second-generation PCI-Express x8 slots /convertible via riser(s) to 2 PCI-E x16 or 4 64-bit133MHz PCI-XX3690 x5 42 x8 PCIe slots and 2 x8 Low Profile slotsX3850 x5 7 7 PCI-E slots Gen 2, 5Gb/sTable 4. System x Server models and maximum number of QDR adaptersHow are the IB card(s) connected to the System x servers?An IB card is connected through a PCI-e gen2 slot. For example, on a 3690 X5 and 3850 X5, slot 7 is a good choice.System x Server requirements and setupThis section discusses the DB2 pureScale Feature requirements and setup on System x servers. Due to the importance of InfiniBand to the DB2 pureScale Feature, only servers with a PCI-E x8 slot are supported.What System x servers can the DB2 pureScale Feature be deployed on?The DB2 pureScale Feature can be deployed on the following System x servers:•X3650 M3•X3690 x5•X3690 x5•X3850 x5What are the CPU, Memory, Ethernet, InfiniBand, and fiber channel (FC) requirements?These requirements will depend on the deployment you choose. The DB2 pureScale Feature offers a wide range of deployments. For prerequisites and minimum requirements, see the DB2 Information Center. A few deployment examples are listed as reference in the appendix of this document.Remember that high availability (HA) is one of the DB2 pureScale Feature’s primary characteristics and you should avoid a single point of failure in your deployment. For example, the Ethernet and FC HBA adapter setup should be redundant. Scale out is also an important consideration, especially since configurations with a single cluster caching facility (CF) are allowed.As each deployment has its own specifics, use the expertise of TechLine. Fill out the sizing questionnaire and request sizing estimation for each of your projects. Techline will provide a sizing based on the DB2 Enterprise Server Edition. Contact a DB2 pureScale Feature specialist for assistance in your overall sizing of the DB2 pureScale environment. Techline is a world wide IBM unit that, among its other benefits, provides IBM server sizing for IBM software (DB2, WebSphere®, Domino®). Contact your IBM representative for access to TechLine.Storage controller considerationsThere are a wide range of storage providers and storage topologies. Usually the storage division within a business mandates certain storage types and topologies. The DB2 pureScale Feature is designed to work with a wide range of fiber channel attached storage. What storage controllers and subsystems are supported?The DB2 pureScale Feature uses GPFS and, in general, all storage supported by GPFS is supported by the DB2 pureScale Feature. As this list evolves, consult the GPFS FAQ. The DB2 pureScale Feature will also run on almost any disk subsystem similar to existing, non-DB2 pureScale Feature deployments.Can you direct attach servers to the storage controller?Yes, however this may not be possible depending on the amount of available ports and throughput requirements. Consider a SAN topology that allows for future growth and redundancy, while retaining good performance characteristics.How many disks do you need for a DB2 pureScale Feature solution?The number of disks depends largely on the type of workload and on storage requirements. The minimum requirements are described in the Installation prerequisites for the DB2 pureScale Feature topic of the DB2 Information Center.In general, the disk requirements for a given workload are similar to those of the DB2 Enterprise Server Edition. As each member has its own separate log devices, you will need more disks when you add more members. You can work with TechLine to determine an accurate assessment of your needs.DB2 member and CF deployment scenariosThere are numerous combinations for deployment of the DB2 pureScale Feature. This section will address some of the most common questions.Can I run with only 1 CF?Although this is possible, it is strongly recommended to run with at least 2 CFs. This scenario eliminates a single point of failure and takes advantage of the DB2 pureScale Feature’s HA solution.Can both primary and secondary CFs co-exist on the same physical server?This scenario is not supported. Co-existence on the same physical server is not advised as it presents a single point of failure for your DB2 pureScale environment.Can I run a CF on its own physical server?Yes, in this scenario, full IB and CPU resources are allocated to CF processing. This scenario also assists in cluster scale out as all you need to do is add additional members. What is the advised proportion of member to CF processing power?This proportion varies widely depending on the workload. For example, for most update intensive workloads, you should use a proportion of up to 5 members to 1 primary CF, where both the member and the CF are of equal capacity.For most non-update-intensive workloads, you should use a proportion of up to 12 members (or higher in some cases) to 1 primary CF. You need to monitor CF usage and adjust the member-to-CF ratio appropriately. You should size and adjust resources of the secondary CF to match the configuration of the primary CF server after tuning.Figure 1. 2 System x servers configuration with 2 members and 2 CFsWhat is the minimum number of physical servers needed to maintain High Availability (HA) characteristics while performing maintenance on one of the System x servers?At a minimum, 3 physical servers are needed to provide this level of HA. For example, a configuration with a minimum of 3 servers is required to perform maintenance on 1 machine while still retaining HA on the remaining 2 machines (assuming 1 CF will be always on-line). In this scenario, 3 physical servers will each have 1 member, and on 2 of the 3 physical servers, there will be 2 CFs (primary and secondary - 1 per physical server). How can I scale out a cluster of 2 System x servers?You can scale out the cluster by adding additional System x servers. Ensure IO and CF capacity is increased proportionally as that is key in achieving overall cluster scalability. When adding new members, the CF may require more computing resources, and in that case, you should adjust the CF_NUM_WORKERS DBM configuration parameter. Eventually, in a large cluster, the CF might be running on a dedicated machine.Figure 2. 3 System x servers configuration with 3 members and 2 CFsIs the deployment of the DB2 pureScale Feature on heterogeneous cluster components advised? (For example, varying memory, CPU count, and CPU frequency)You should deploy members in environments with equal amount of memory. Mixing servers of System x for members is permitted; however, you should adjust the member to CF ratio accordingly. For primary and secondary CFs, you should use a homogeneous environment, which allows for production level workloads to continue unaffected during primary CF maintenance or during an unlikely failure event. The DB2 pureScale Feature’s Workload Balancing would properly balance the client workload, even if the members do not have equal CPU capacity.Figure 3. Scale out X3850 x5 configurationDB2 pureScale Feature monitoring on System x serversHow do I monitor member and CF RDMA network bandwidth usage?You can use the OFED-supplied tool called perfquery to monitor the RDMA packet rates and sizes. You can also use the netstat command to monitor TCP/IP over IB traffic. In addition, you can use the InfiniBand switch statistics.Are there any tools that can modify and collect system configuration on System x servers?A tool called DSA (Dynamic Systems Analysis) can generate a *.gz file that has details on the hardware, firmware, and software configuration installed on the system. The tool has versions for various operating systems.Another tool to consider is ASU (Advanced Settings Utility). You can use the ASU tool to set the UEFI variables on the system. You can also use it to query all F1 setting variables.How can I monitor CF capacity?Use the MON_GET_CF UDF or the db2pd –cfinfo command. You can also use the performance commands on Linux® such as top, sar, free, iostat, or vmstat.What CF CPU usage should I target?The CF is highly tuned and will function well at high usage. However, workloads tend to have extreme transient peaks. You should plan for an average CF use of 50% during normal production hours. However, do not rely on the vmstat output, as the CF polling model will typically show that an idle CF is running at 100% CPU use.Additional softwareWhat version of Systems x firmware, OFED level, and software are needed?For hardware, firmware, and software prerequisites see the Installation prerequisites for the DB2 pureScale Feature topic in the DB2 Information Center:Can I install additional software on a DB2 member or CF, such as third party management tools (for example, BMC PATROL)?Yes, as long as these products support the DB2 pureScale Feature V9.8. However, any cluster managers and clustered file systems (for example, Veritas) other than DB2 Cluster Services are not supported.APPENDIXThis appendix provides several possible deployment configurations of the DB2 pureScale Feature, which can be used to help design your DB2 pureScale solution. As each project has its own specifics, you should employ the expertise of TechLine to obtain a sizing estimation.Sample Configuration 1 - X3690 x5Processor Model: E6540Quantity of Servers: 2Sockets: 1Cores: 6Memory Dimms: 16 - 4GB DIMMsTotal Memory Populated: 64 GBEthernet: Dual port GBSystem Power supplies: 2IB Adapter – Mellanox IB Adapter ConnectX®-2 VPI 2Fiber Channel Adapters – QLogic 8Gb FC Dual-Port HBA for IBM System: 4QDR Switch - Mellanox IB Switch (36 ports): 1QDR Cables: at choice from supported list (length/cooper/fiber) 2* NOTE: You may consider 2 adapters/cards when the CF and a member are placed on the same machine Sample Configuration 2 - X3690 x5Processor Model: E6540Quantity of Servers: 3Sockets: 1Cores: 6Memory Dimms: 16 - 4GB DIMMsTotal Memory Populated: 64 GBEthernet: Dual port GBSystem Power supplies: 2IB Adapter – Mellanox IB Adapter ConnectX®-2 VPI 3Fiber Channel Adapters – QLogic 8Gb FC Dual-Port HBA for IBM System: 6QDR Switch - Mellanox IB Switch (36 ports): 1QDR Cables: at choice from supported list (length/cooper/fiber) 3Sample Configuration 3 - X3650 M3Processor Model: E5680Quantity of Servers: 5Sockets: 1Cores: 6Memory Dimms: 16 - 4GB DIMMsTotal Memory Populated: 64 GBEthernet: Dual port GBSystem Power supplies: 2IB Adapter – Mellanox IB Adapter ConnectX®-2 VPI 5Fiber Channel Adapters – QLogic 8Gb FC Dual-Port HBA for IBM System: 10QDR Switch - Mellanox IB Switch (36 ports): 1QDR Cables: at choice from supported list (length/cooper/fiber) 5Sample Configuration 4 - X3690 x5Processor Model: E6550Quantity of Servers: 8Sockets: 2Cores: 8Memory Dimms: 32 - 4GB DIMMsTotal Memory Populated: 128 GBEthernet: Dual port GBSystem Power supplies: 2IB Adapter – Mellanox IB Adapter ConnectX®-2 VPI 8 Fiber Channel Adapters – QLogic 8Gb FC Dual-Port HBA for IBM System: 16 QDR Switch - Mellanox IB Switch (36 ports): 1 QDR Cables: at choice from supported list (length/cooper/fiber) 8。

DB2使⽤⼿册第⼀部分DB2系统管理命令1. Db2有域,实例,和数据库三层的概念。
2.查看数据库服务器中有⼏个数据库。
包括⽹络中数据库的引⽤。
进⼊数据库安装⽬录下的bin⽬录:C:\Program Files\IBM\SQLLIB\BIN执⾏db2 list database directory命令3.查看命令选项说明list command options4.查看运⾏的数据库服务器中关联了多少个引⽤程序对数据库的访问。
进⼊数据库安装⽬录下的bin⽬录:C:\Program Files\IBM\SQLLIB\BINdb2 list applications命令可以通过db2 force application(进程id) 杀死对应的进程。
5.如何强制断开应⽤程序和数据库的连接。
进⼊数据库安装⽬录下的bin⽬录:C:\Program Files\IBM\SQLLIB\BIN⾏下列的命令 db2 force applications 可以强制断开应⽤程序和数据库的连接。
6.如何备份数据库进⼊db2的操作环境,然后运⾏backup database 数据库别名 user ⽤户名 using 密码命令7.停⽌数据库的服务器。
进⼊数据库安装⽬录下的bin⽬录:C:\Program Files\IBM\SQLLIB\BIN或db2操作环境中,如果在db2操作环境中必须通过的db2 terminate命令终结db2操作环境中启动的所有⼦进程(即停⽌所有命令⾏处理器回话)再执⾏db2stop命令。
注意:在执⾏此命令的时候,必须没有应⽤程序或⽤户和数据库连接。
可以在执⾏停⽌命令之前查看于db2服务器连接的应⽤程序和⽤户。
然后执⾏牵制断开命令断开连接的数据库和⽤户。
8.如何从旧版本中把数据库迁移到新的安装版本中(在新版数据库种运⾏下列代码)1. 验证数据库是否可以被迁移。
⽤db2ckmig命令,db2ckmig /e 数据库别名 /l 验证信息保存路径 /u ⽤户名 /p 密码1. 执⾏数据库的迁移命令MIGRATE database 数据库别名 user ⽤户名 using 密码命令9.启动DB2服务器进⼊数据库安装⽬录下的bin⽬录:C:\Program Files\IBM\SQLLIB\BIN或db2操作环境中执⾏db2start命令10.关于命令⾏编辑器的使⽤使⽤命令⾏编辑器之前要连接到⼀个数据库。

DB2V10.5PureScale安装指导书forLinuxandAIX(⾮infiniband)IBM DB2 V10.5 PureScale forLinux and AIX安装指导书1⽬录1⽬录 (1)2⽂档说明 (3)2.1⽂档版本 (3)2.2⽂档类型 (3)2.3⽂档摘要 (3)3准备⼯作 (4)3.1缩写释义 (4)3.2实验安装环境 (4)3.3预安装检查 (4)3.3.1AIX安装要求 (4)3.3.2AIX集群环境配置 (10)3.3.3Linux安装要求 (14)3.3.4Linux集群环境配置 (19)3.4介质准备 (24)3.4.1AIX系统介质准备 (24)3.4.2Linux系统介质准备 (24)3.5核⼼⽂件安装 (26)3.5.1使⽤ db2_install安装 (26)3.5.2GPFS ⽂件系统配置与挂载 (30)3.5.3db2 许可证配置 (32)4DB2实例配置及验证 (34)4.1创建数据库组和⽤户标识 (34)4.1.1⽤户和组命名说明 (34)4.1.2创建组和⽤户 (36)4.2创建实例及版本验证 (37)4.2.1创建实例 (37)4.2.2db2 版本检查 (39)4.3查看实例的集群状态 (40)4.4启动实例 (40)4.5添加member (41)4.6添加CF (42)4.7为实例配置 TCP/IP 通信 (43)4.7.1更新 services ⽂件 (43)4.7.2更新数据库管理器配置 (44)4.8配置 DB2 服务器通信 (44)5数据库创建 (44)5.1实例注册变量设置 (44)5.1.1注册变量设置 (44)5.1.2注册变量检查 (45)5.2创建SAMPLE数据库 (45)2⽂档说明2.1⽂档版本⽂档历史2.2⽂档类型2.3⽂档摘要本⽂档描述数据库产品 DB2 V10.5.0.4 PureScale在Linux 和 Unix平台的安装、配置等内容。

DB2的常见SQLCODE所表示负数的含义SQL0007 SQLCODE -07 SQLSTATE 42601Explanation: Character &1 (HEX &2) not valid in SQL statement. SQL0010 SQLCODE -10 SQLSTATE 42603Explanation: String constant beginning &1 not delimited.SQL0029 SQLCODE -29 SQLSTATE 42601Explanation: INTO clause missing from embedded SELECT statement. SQL0051 SQLCODE -51 SQLSTATE 3C000Explanation: Cursor or procedure &1 previously declared.SQL0060 SQLCODE -60 SQLSTATE 42815Explanation: Value &3 for argument &1 of &2 function not valid. SQL0078 SQLCODE -78 SQLSTATE 42629Explanation: Parameter name required for routine &1 in &2.SQL0080 SQLCODE -80 SQLSTATE 42978Explanation: Indicator variable &1 not SMALLINT type.SQL0084 SQLCODE -84 SQLSTATE 42612Explanation: SQL statement not allowed.SQL0090 SQLCODE -90 SQLSTATE 42618Explanation: Host variable not permitted here.SQL0097 SQLCODE -97 SQLSTATE 42601Explanation: Use of data type not valid.SQL0099 SQLCODE -99 SQLSTATE 42992Explanation: Operator in join condition not valid.SQL0101 SQLCODE -101 SQLSTATE 54001, 54010, 54011 Explanation: SQL statement too long or complex.SQL0102 SQLCODE -102 SQLSTATE 54002Explanation: String constant beginning with &1 too long. SQL0103 SQLCODE -103 SQLSTATE 42604Explanation: Numeric constant &1 not valid.SQL0104 SQLCODE -104 SQLSTATE 42601Explanation: Token &1 was not valid. Valid tokens: &2.SQL0105 SQLCODE -105 SQLSTATE 42604Explanation: Mixed or graphic string constant not valid. SQL0106 SQLCODE -106 SQLSTATE 42611Explanation: Precision specified for FLOAT column not valid.SQL0107 SQLCODE -107 SQLSTATE 42622Explanation: &1 too long. Maximum &2 characters.SQL0109 SQLCODE -109 SQLSTATE 42601Explanation: &1 clause not allowed.SQL0110 SQLCODE -110 SQLSTATE 42606Explanation: Hexadecimal constant beginning with &1 not valid.SQL0112 SQLCODE -112 SQLSTATE 42607Explanation: Argument of function &1 is another function.SQL0113 SQLCODE -113 SQLSTATE 28000, 2E000, 42602Explanation: Name &1 not allowed.SQL0114 SQLCODE -114 SQLSTATE 42961Explanation: Relational database &1 not the same as current server &2. SQL0115 SQLCODE -115 SQLSTATE 42601Explanation: Comparison operator &1 not valid.SQL0117 SQLCODE -117 SQLSTATE 42802Explanation: Statement inserts wrong number of values.SQL0118 SQLCODE -118 SQLSTATE 42902Explanation: Table &1 in &2 also specified in a FROM clause.SQL0119 SQLCODE -119 SQLSTATE 42803Explanation: Column &1 in HAVING clause not in GROUP BY. SQL0120 SQLCODE -120 SQLSTATE 42903Explanation: Use of column function &2 not valid.SQL0121 SQLCODE -121 SQLSTATE 42701Explanation: Duplicate column name &1 in INSERT or UPDATE. SQL0122 SQLCODE -122 SQLSTATE 42803Explanation: Column specified in SELECT list not valid. SQL0125 SQLCODE -125 SQLSTATE 42805Explanation: ORDER BY column number &1 not valid.SQL0128 SQLCODE -128 SQLSTATE 42601Explanation: Use of NULL is not valid.SQL0129 SQLCODE -129 SQLSTATE 54004Explanation: Too many tables in SQL statement.SQL0130 SQLCODE -130 SQLSTATE 22019, 22025Explanation: Escape character &1 or LIKE pattern not valid. SQL0131 SQLCODE -131 SQLSTATE 42818Explanation: Operands of LIKE not compatible or not valid.SQL0132 SQLCODE -132 SQLSTATE 42824Explanation: LIKE predicate not valid.SQL0133 SQLCODE -133 SQLSTATE 42906Explanation: Operator on correlated column in SQL function not valid.SQL0134 SQLCODE -134 SQLSTATE 42907Explanation: Argument of function too long.SQL0136 SQLCODE -136 SQLSTATE 54005Explanation: ORDER BY or GROUP BY columns too long.SQL0137 SQLCODE -137 SQLSTATE 54006Explanation: Result too long.SQL0138 SQLCODE -138 SQLSTATE 22011Explanation: Argument &1 of SUBSTR function not valid.SQL0144 SQLCODE -144 SQLSTATE 58003Explanation: Section number not valid.SQL0145 SQLCODE -145 SQLSTATE 55005Explanation: Recursion not supported for an application server other than the AS/400 system.SQL0150 SQLCODE -150 SQLSTATE 42807Explanation: View or logical file &1 in &2 read-only.SQL0151 SQLCODE -151 SQLSTATE 42808Explanation: Column &1 in table &2 in &3 read-only.SQL0152 SQLCODE -152 SQLSTATE 42809Explanation: Constraint type not valid for constraint &1 in &2. SQL0153 SQLCODE -153 SQLSTATE 42908Explanation: Column list required for CREATE VIEW.SQL0154 SQLCODE -154 SQLSTATE 42909Explanation: UNION and UNION ALL for CREATE VIEW not valid. SQL0156 SQLCODE -156 SQLSTATE 42809Explanation: &1 in &2 not a table.SQL0157 SQLCODE -157 SQLSTATE 42810Explanation: View &1 in &2 not valid in FOREIGN KEY clause. SQL0158 SQLCODE -158 SQLSTATE 42811Explanation: Number of columns specified not consistent.SQL0159 SQLCODE -159 SQLSTATE 42809Explanation: &1 in &2 not correct type.SQL0160 SQLCODE -160 SQLSTATE 42813Explanation: WITH CHECK OPTION not allowed for view &1 in &2.SQL0161 SQLCODE -161 SQLSTATE 44000Explanation: INSERT/UPDATE not allowed due to WITH CHECK OPTION. SQL0170 SQLCODE -170 SQLSTATE 42605Explanation: Number of arguments for function &1 not valid.SQL0171 SQLCODE -171 SQLSTATE 42815Explanation: Argument &1 of function &2 not valid.SQL0175 SQLCODE -175 SQLSTATE 58028Explanation: COMMIT failed.SQL0180 SQLCODE -180 SQLSTATE 22007Explanation: Syntax of date, time, or timestamp value not valid. SQL0181 SQLCODE -181 SQLSTATE 22007Explanation: Value in date, time, or timestamp string not valid. SQL0182 SQLCODE -182 SQLSTATE 42816Explanation: A date, time, or timestamp expression not valid.SQL0183 SQLCODE -183 SQLSTATE 22008Explanation: The result of a date or timestamp expression not valid.SQL0184 SQLCODE -184 SQLSTATE 42610Explanation: Parameter marker not valid in expression.SQL0187 SQLCODE -187 SQLSTATE 42816Explanation: Use of labeled duration is not valid.SQL0188 SQLCODE -188 SQLSTATE 22503, 28000, 2E000Explanation: &1 is not a valid string representation of an authorization name or a relational database name.SQL0189 SQLCODE -189 SQLSTATE 22522Explanation: Coded Character Set Identifier &1 is not valid.SQL0190 SQLCODE -190 SQLSTATE 42837Explanation: Attributes of column &3 in &1 in &2 not compatible.SQL0191 SQLCODE -191 SQLSTATE 22504Explanation: MIXED data not properly formed.SQL0192 SQLCODE -192 SQLSTATE 42937Explanation: Argument of TRANSLATE function not valid.SQL0194 SQLCODE -194 SQLSTATE 42848Explanation: KEEP LOCKS not allowed.SQL0195 SQLCODE -195 SQLSTATE 42814Explanation: Last column of &1 in &2 cannot be dropped.SQL0196 SQLCODE -196 SQLSTATE 42817Explanation: Column &3 in &1 in &2 cannot be dropped with RESTRICT. SQL0197 SQLCODE -197 SQLSTATE 42877Explanation: Column &1 cannot be qualified.SQL0198 SQLCODE -198 SQLSTATE 42617Explanation: SQL statement empty or blank.SQL0199 SQLCODE -199 SQLSTATE 42601Explanation: Keyword &1 not expected. Valid tokens: &2.SQL0203 SQLCODE -203 SQLSTATE 42702Explanation: Column &1 is ambiguous.SQL0204 SQLCODE -204 SQLSTATE 42704Explanation: &1 in &2 type *&3 not found.SQL0205 SQLCODE -205 SQLSTATE 42703Explanation: Column &1 not in table &2.SQL0206 SQLCODE -206 SQLSTATE 42703Explanation: Column &1 not in specified tables.SQL0208 SQLCODE -208 SQLSTATE 42707Explanation: ORDER BY column &1 not in results table.SQL0212 SQLCODE -212 SQLSTATE 42712Explanation: Duplicate table designator &1 not valid.SQL0214 SQLCODE -214 SQLSTATE 42822Explanation: ORDER BY expression is not valid.SQL0221 SQLCODE -221 SQLSTATE 42873Explanation: Number of rows &2 not valid.SQL0225 SQLCODE -225 SQLSTATE 42872Explanation: FETCH not valid; cursor &1 not declared with SCROLL.SQL0226 SQLCODE -226 SQLSTATE 24507Explanation: Current row deleted or moved for cursor &1.SQL0227 SQLCODE -227 SQLSTATE 24513Explanation: FETCH not valid, cursor &1 in unknown position.SQL0228 SQLCODE -228 SQLSTATE 42620Explanation: FOR UPDATE OF clause not valid with SCROLL for cursor &1. SQL0231 SQLCODE -231 SQLSTATE 22006Explanation: Position of cursor &1 not valid for FETCH of current row.SQL0250 SQLCODE -250 SQLSTATE 42718Explanation: Local relational database not defined in the directory. SQL0251 SQLCODE -251 SQLSTATE 2E000, 42602Explanation: Character in relational database name &1 is not valid. SQL0255 SQLCODE -255 SQLSTATE 42999Explanation: DB2 Multisystem query error.SQL0256 SQLCODE -256 SQLSTATE 42998Explanation: Constraint &1 in &2 not allowed on distributed file. SQL0270 SQLCODE -270 SQLSTATE 42997Explanation: Unique index not allowed.SQL0301 SQLCODE -301 SQLSTATE 07006,42895Explanation: Input host variable &2 or argument &1 not valid.SQL0302 SQLCODE -302 SQLSTATE 22001, 22003, 22023, 22024 Explanation: Conversion error on input host variable &2.SQL0303 SQLCODE -303 SQLSTATE 22001, 42806Explanation: Host variable &1 not compatible with SELECT item.SQL0304 SQLCODE -304 SQLSTATE 22003, 22023, 22504Explanation: Conversion error in assignment to host variable &2.SQL0305 SQLCODE -305 SQLSTATE 22002Explanation: Indicator variable required.SQL0306 SQLCODE -306 SQLSTATE 42863Explanation: Undefined host variable in REXX.SQL0311 SQLCODE -311 SQLSTATE 22501Explanation: Length in a varying-length host variable not valid. SQL0312 SQLCODE -312 SQLSTATE 42618Explanation: Host variable &1 not defined or not usable.SQL0313 SQLCODE -313 SQLSTATE 07001, 07004Explanation: Number of host variables not valid.SQL0328 SQLCODE -328 SQLSTATE 42996Explanation: Column &1 not allowed in partitioning key.SQL0329 SQLCODE -329 SQLSTATE 0E000Explanation: The SET PATH name list is not valid.SQL0330 SQLCODE -330 SQLSTATE 22021Explanation: Character conversion cannot be performed.SQL0331 SQLCODE -331 SQLSTATE 22021Explanation: Character conversion cannot be performed.SQL0332 SQLCODE -332 SQLSTATE 57017Explanation: Character conversion between CCSID &1 and CCSID &2 not valid.SQL0334 SQLCODE -334 SQLSTATE 22524Explanation: Character conversion has resulted in truncation.SQL0338 SQLCODE -338 SQLSTATE 42972Explanation: JOIN expression not valid.SQL0340 SQLCODE -340 SQLSTATE 42726Explanation: Duplicate name &1 for common table expression.SQL0341 SQLCODE -341 SQLSTATE 42835Explanation: Cyclic references between common table expressions.SQL0346 SQLCODE -346 SQLSTATE 42836Explanation: Recursion not allowed for common table expressions.SQL0350 SQLCODE -350 SQLSTATE 42962Explanation: Column &1 is not valid as key field for index or constraint.SQL0351 SQLCODE -351 SQLSTATE 56084Explanation: The AR is not at the same level and DB2/400 cannot transform the data type to a compatible type.SQL0352 SQLCODE -352 SQLSTATE 56084Explanation: The AS is not at the same level and DB2/400 cannot transform the data type to a compatible type.SQL0357 SQLCODE -357 SQLSTATE 57050Explanation: File server &1 used in DataLink not currently available.SQL0358 SQLCODE -358 SQLSTATE 428D1Explanation: Error &1 occurred using DataLink data type.SQL0392 SQLCODE -392 SQLSTATE 42855Explanation: Assignment of LOB to specified host variable not allowed.SQL0398 SQLCODE -398 SQLSTATE 428D2Explanation: AS LOCATOR cannot be specified for a non-LOB parameter.SQL0401 SQLCODE -401 SQLSTATE 42818Explanation: Comparison operator &1 operands not compatible.SQL0402 SQLCODE -402 SQLSTATE 42819Explanation: &1 use not valid.SQL0404 SQLCODE -404 SQLSTATE 22001Explanation: Value for column &1 too long.SQL0405 SQLCODE -405 SQLSTATE 42820Explanation: Numeric constant &1 out of range.SQL0406 SQLCODE -406 SQLSTATE 22003, 22023, 22504 Explanation: Conversion error on assignment to column &2.SQL0407 SQLCODE -407 SQLSTATE 23502Explanation: Null values are not allowed in column &1.SQL0408 SQLCODE -408 SQLSTATE 42821Explanation: INSERT or UPDATE value for column &1 not compatible. SQL0410 SQLCODE -410 SQLSTATE 42820Explanation: Floating point literal &1 not valid.SQL0412 SQLCODE -412 SQLSTATE 42823Explanation: Subquery with more than one result column not valid. SQL0414 SQLCODE -414 SQLSTATE 42824Explanation: Column &1 not valid in LIKE predicate.SQL0415 SQLCODE -415 SQLSTATE 42825Explanation: UNION operands not compatible.SQL0417 SQLCODE -417 SQLSTATE 42609Explanation: Combination of parameter markers not valid.SQL0418 SQLCODE -418 SQLSTATE 42610Explanation: Use of parameter marker is not valid.SQL0419 SQLCODE -419 SQLSTATE 42911Explanation: Negative scale not valid.SQL0420 SQLCODE -420 SQLSTATE 22018Explanation: Character in CAST argument not valid.SQL0421 SQLCODE -421 SQLSTATE 42826Explanation: Number of UNION operands not equal.SQL0423 SQLCODE -423 SQLSTATE 0F001Explanation: LOB locator &1 not valid.SQL0428 SQLCODE -428 SQLSTATE 25501Explanation: SQL statement cannot be run.SQL0429 SQLCODE -429 SQLSTATE 54028Explanation: The maximum number of concurrent LOB locators has been reached. SQL0432 SQLCODE -432 SQLSTATE 42841Explanation: A parameter marker cannot have the user-defined type name &1.SQL0433 SQLCODE -433 SQLSTATE 22001Explanation: Significant digits truncated during CAST from numeric to character. SQL0440 SQLCODE -440 SQLSTATE 42884Explanation: Number of arguments on CALL must match procedure.SQL0441 SQLCODE -441 SQLSTATE 42601Explanation: Clause or keyword &1 not valid where specified.SQL0442 SQLCODE -442 SQLSTATE 54023Explanation: Maximum # of parameters on CALL exceeded.SQL0443 SQLCODE -443 SQLSTATE 2Fxxx, 38501Explanation: Trigger program or external procedure detected on error. SQL0444 SQLCODE -444 SQLSTATE 42724Explanation: External program &4 in &1 not found.SQL0446 SQLCODE -446 SQLSTATE 22003Explanation: Conversion error in assignment of argument &2.SQL0448 SQLCODE -448 SQLSTATE 54023Explanation: Maximum parameters on DECLARE PROCEDURE exceeded.SQL0449 SQLCODE -449 SQLSTATE 42878Explanation: External program name for procedure &1 in &2 not valid. SQL0451 SQLCODE -451 SQLSTATE 42815Explanation: Attributes of parameter &1 not valid for procedure.SQL0452 SQLCODE -452 SQLSTATE 428A1Explanation: Unable to access a file that is referred to by a file reference variable. SQL0453 SQLCODE -453 SQLSTATE 42880Explanation: Return type for function &1 in &2 not compatible with CAST TO type. SQL0454 SQLCODE -454 SQLSTATE 42723Explanation: Function &1 in &2 with the same signature already exists.SQL0455 SQLCODE -455 SQLSTATE 42882Explanation: Specific name not same as procedure name.SQL0456 SQLCODE -456 SQLSTATE 42710Explanation: Specific name &3 in &2 already exists.SQL0457 SQLCODE -457 SQLSTATE 42939Explanation: Name &1 in &2 not allowed for function.SQL0458 SQLCODE -458 SQLSTATE 42883Explanation: Function &1 in &2 not found with matching signature.SQL0461 SQLCODE -461 SQLSTATE 42846Explanation: Cast from &1 to &2 not supported.SQL0463 SQLCODE -463 SQLSTATE 39001Explanation: SQLSTATE &4 returned from routine &1 in &2 not valid..SQL0469 SQLCODE -469 SQLSTATE 42886Explanation: IN, OUT, INOUT not valid for parameter &4 in procedure &1 in &2. SQL0470 SQLCODE -470 SQLSTATE 39002Explanation: NULL values not allowed for parameter &4 in procedure.SQL0473 SQLCODE -473 SQLSTATE 42918Explanation: User-defined type &1 cannot be created.SQL0475 SQLCODE -475 SQLSTATE 42866Explanation: RETURNS data type for function &3 in &4 not valid.SQL0476 SQLCODE -476 SQLSTATE 42725Explanation: Function &1 in &2 not unique.SQL0478 SQLCODE -478 SQLSTATE 42893Explanation: Object &1 in &2 of type &3 cannot be dropped.SQL0483 SQLCODE -483 SQLSTATE 42885Explanation: Parameters for function &1 in &2 not same as sourced function. SQL0484 SQLCODE -484 SQLSTATE 42733Explanation: Routine &1 in &2 already exists.SQL0487 SQLCODE -487 SQLSTATE 38001Explanation: SQL statements not allowed.SQL0490 SQLCODE -490 SQLSTATE 428B7Explanation: Numeric value &1 not valid.SQL0491 SQLCODE -491 SQLSTATE 42601Explanation: RETURNS clause required on CREATE FUNCTION statement.SQL0492 SQLCODE -492 SQLSTATE 42879Explanation: Data type for function &1 in &2 not valid for source type. SQL0501 SQLCODE -501 SQLSTATE 24501Explanation: Cursor &1 not open.SQL0502 SQLCODE -502 SQLSTATE 24502Explanation: Cursor &1 already open.SQL0503 SQLCODE -503 SQLSTATE 42912Explanation: Column &3 cannot be updated.SQL0504 SQLCODE -504 SQLSTATE 34000Explanation: Cursor &1 not declared.SQL0507 SQLCODE -507 SQLSTATE 24501Explanation: Cursor &1 not open.SQL0508 SQLCODE -508 SQLSTATE 24504Explanation: Cursor &1 not positioned on locked row.SQL0509 SQLCODE -509 SQLSTATE 42827Explanation: Table &2 in &3 not same as table in cursor &1. SQL0510 SQLCODE -510 SQLSTATE 42828Explanation: Cursor &1 for file &2 is read-only.SQL0511 SQLCODE -511 SQLSTATE 42829Explanation: FOR UPDATE OF clause not valid.SQL0513 SQLCODE -513 SQLSTATE 42924Explanation: Alias &1 in &2 cannot reference another alias. SQL0514 SQLCODE -514 SQLSTATE 26501Explanation: Prepared statement &2 not found.SQL0516 SQLCODE -516 SQLSTATE 26501Explanation: Prepared statement &2 not found.SQL0517 SQLCODE -517 SQLSTATE 07005Explanation: Prepared statement &2 not SELECT statement. SQL0518 SQLCODE -518 SQLSTATE 07003Explanation: Prepared statement &1 not found.SQL0519 SQLCODE -519 SQLSTATE 24506Explanation: Prepared statement &2 in use.SQL0520 SQLCODE -520 SQLSTATE 42828Explanation: Cannot UPDATE or DELETE on cursor &1.SQL0525 SQLCODE -525 SQLSTATE 51015Explanation: Statement not valid on application server.SQL0527 SQLCODE -527 SQLSTATE 42874Explanation: ALWCPYDTA(*NO) specified but temporary result required for &1.SQL0530 SQLCODE -530 SQLSTATE 23503Explanation: Insert or UPDATE value not allowed by referential constraint.SQL0531 SQLCODE -531 SQLSTATE 23001, 23504Explanation: Update prevented by referential constraint.SQL0532 SQLCODE -532 SQLSTATE 23001, 23504Explanation: Delete prevented by referential constraint.SQL0536 SQLCODE -536 SQLSTATE 42914Explanation: Delete not allowed because table referenced in subquery can be affected. SQL0537 SQLCODE -537 SQLSTATE 42709Explanation: Duplicate column name in definition of key.SQL0538 SQLCODE -538 SQLSTATE 42830Explanation: Foreign key attributes do not match parent key.SQL0539 SQLCODE -539 SQLSTATE 42888Explanation: Table does not have primary key.SQL0541 SQLCODE -541 SQLSTATE 42891Explanation: Duplicate UNIQUE constraint already exists.SQL0543 SQLCODE -543 SQLSTATE 23511Explanation: Constraint &1 conflicts with SET NULL or SET DEFAULT rule. SQL0544 SQLCODE -544 SQLSTATE 23512Explanation: CHECK constraint &1 cannot be added.SQL0545 SQLCODE -545 SQLSTATE 23513Explanation: INSERT or UPDATE not allowed by CHECK constraint.SQL0546 SQLCODE -546 SQLSTATE 42621Explanation: CHECK condition of constraint &1 not valid.SQL0551 SQLCODE -551 SQLSTATE 42501Explanation: Not authorized to object &1 in &2 type *&3.SQL0552 SQLCODE -552 SQLSTATE 42502Explanation: Not authorized to &1.SQL0557 SQLCODE -557 SQLSTATE 42852Explanation: Privilege not valid for table or view &1 in &2.SQL0573 SQLCODE -573 SQLSTATE 42890Explanation: Table does not have matching parent key.SQL0574 SQLCODE -574 SQLSTATE 42894Explanation: Default value not valid.SQL0577 SQLCODE -577 SQLSTATE 38002, 2F002Explanation: Modifying SQL data not permitted.SQL0578 SQLCODE -578 SQLSTATE 2F005Explanation: RETURN statement not executed for SQL function &1 in &2. SQL0579 SQLCODE -579 SQLSTATE 38004, 2F004Explanation: Reading SQL data not permitted.SQL0580 SQLCODE -580 SQLSTATE 42625Explanation: At least one result in CASE expression must be not NULL. SQL0581 SQLCODE -581 SQLSTATE 42804Explanation: The results in a CASE expression are not compatible. SQL0583 SQLCODE -583 SQLSTATE 42845Explanation: Use of function &1 in &2 not valid.SQL0585 SQLCODE -585 SQLSTATE 42732Explanation: Library &1 is used incorrectly on the SET PATH statement SQL0590 SQLCODE -590 SQLSTATE 42734Explanation: Name &1 specified in &2 not unique.SQL0601 SQLCODE -601 SQLSTATE 42710Explanation: Object &1 in &2 type *&3 already exists.SQL0602 SQLCODE -602 SQLSTATE 54008Explanation: More than 120 columns specified for CREATE INDEX.SQL0603 SQLCODE -603 SQLSTATE 23515Explanation: Unique index cannot be created because of duplicate keys. SQL0604 SQLCODE -604 SQLSTATE 42611Explanation: Attributes of column not valid.SQL0607 SQLCODE -607 SQLSTATE 42832Explanation: Operation not allowed on system table &1 in &2.SQL0612 SQLCODE -612 SQLSTATE 42711Explanation: &1 is a duplicate column name.SQL0613 SQLCODE -613 SQLSTATE 54008Explanation: Primary or unique key constraint too long.SQL0614 SQLCODE -614 SQLSTATE 54008Explanation: Length of columns for CREATE INDEX too long.SQL0615 SQLCODE -615 SQLSTATE 55006Explanation: Object &1 in &2 type *&3 not dropped. It is in use. SQL0616 SQLCODE -616 SQLSTATE 42893Explanation: &1 in &2 type &3 cannot be dropped with RESTRICT. SQL0624 SQLCODE -624 SQLSTATE 42889Explanation: Table already has primary key.SQL0628 SQLCODE -628 SQLSTATE 42613Explanation: Clauses are mutually exclusive.SQL0629 SQLCODE -629 SQLSTATE 42834Explanation: SET NULL not allowed for referential constraint. SQL0631 SQLCODE -631 SQLSTATE 54008Explanation: Foreign key for referential constraint too long. SQL0637 SQLCODE -637 SQLSTATE 42614Explanation: Duplicate &1 keyword.SQL0642 SQLCODE -642 SQLSTATE 54021Explanation: Maximum number of constraints exceeded.SQL0658 SQLCODE -658 SQLSTATE 42917Explanation: Function cannot be dropped.SQL0666 SQLCODE -666 SQLSTATE 57005Explanation: Estimated query processing time exceeds limit.SQL0667 SQLCODE -667 SQLSTATE 23520Explanation: Foreign key does not match a value in the parent key.SQL0675 SQLCODE -675 SQLSTATE 42892Explanation: Specified delete rule not allowed with existing trigger.SQL0679 SQLCODE -679 SQLSTATE 57006Explanation: Object &1 in &2 type *&3 not created due to pending operation. SQL0683 SQLCODE -683 SQLSTATE 42842Explanation: FOR DATA or CCSID clause not valid for specified type.SQL0707 SQLCODE -707 SQLSTATE 42939Explanation: Name &1 in &2 not allowed for distinct type.SQL0713 SQLCODE -713 SQLSTATE 42815Explanation: Host variable for &2 is NULL.SQL0724 SQLCODE -724 SQLSTATE 54038Explanation: Too many cascaded trigger programs.SQL0751 SQLCODE -751 SQLSTATE 42987Explanation: SQL statement &1 not allowed in stored procedure or trigger. SQL0752 SQLCODE -752 SQLSTATE 0A001Explanation: Connection cannot be changed. Reason code is &1.SQL0773 SQLCODE -773 SQLSTATE 20000Explanation: Case not found for CASE statement.SQL0774 SQLCODE -774 SQLSTATE 2D522Explanation: Statement cannot be executed within a compound SQL statement. SQL0775 SQLCODE -775 SQLSTATE 42910Explanation: Statement not allowed in a compound SQL statement.SQL0776 SQLCODE -776 SQLSTATE 428D4Explanation: Cursor &1 specified in FOR statement not allowed.SQL0777 SQLCODE -777 SQLSTATE 42919Explanation: Nested compound statements not allowed.SQL0778 SQLCODE -778 SQLSTATE 428D5Explanation: End label &1 not same as begin label.SQL0779 SQLCODE -779 SQLSTATE 42736Explanation: Label &1 specified on LEAVE statement not valid.SQL0780 SQLCODE -780 SQLSTATE 428D6Explanation: UNDO specified for a handler and ATOMIC not specified. SQL0781 SQLCODE -781 SQLSTATE 42737Explanation: Condition &1 specified in handler not defined.SQL0782 SQLCODE -782 SQLSTATE 428D7Explanation: Condition value &1 specified in handler not valid. SQL0783 SQLCODE -783 SQLSTATE 42738Explanation: Select list for cursor &1 in FOR statement not valid. SQL0784 SQLCODE -784 SQLSTATE 42860Explanation: Check constraint &1 cannot be dropped.SQL0785 SQLCODE -785 SQLSTATE 428D8Explanation: Use of SQLCODE or SQLSTATE not valid.SQL0802 SQLCODE -802 SQLSTATE 22003, 22012, 22023, 22504 Explanation: Data conversion or data mapping error.SQL0803 SQLCODE -803 SQLSTATE 23505Explanation: Duplicate key value specified.SQL0804 SQLCODE -804 SQLSTATE 07002Explanation: SQLDA not valid.SQL0805 SQLCODE -805 SQLSTATE 51002Explanation: SQL package &1 in &2 not found.SQL0811 SQLCODE -811 SQLSTATE 21000Explanation: Result of SELECT INTO or subquery more than one row. SQL0818 SQLCODE -818 SQLSTATE 51003Explanation: Consistency tokens do not match.SQL0822 SQLCODE -822 SQLSTATE 51004Explanation: Address in SQLDA not valid.SQL0827 SQLCODE -827 SQLSTATE 42862Explanation: &1 in &2 type *SQLPKG cannot be accessed.SQL0840 SQLCODE -840 SQLSTATE 54004Explanation: Number of selected items exceeds 8000.SQL0842 SQLCODE -842 SQLSTATE 08002Explanation: Connection already exists.SQL0843 SQLCODE -843 SQLSTATE 08003Explanation: Connection does not exist.SQL0858 SQLCODE -858 SQLSTATE 08501Explanation: Cannot disconnect relational database due to LU protected conversation.SQL0862 SQLCODE -862 SQLSTATE 55029Explanation: Local program attempted to connect to a remote relational database.SQL0871 SQLCODE -871 SQLSTATE 54019Explanation: Too many CCSID values specified.SQL0900 SQLCODE -900 SQLSTATE 08003Explanation: Application process not in a connected state.SQL0901 SQLCODE -901 SQLSTATE 58004Explanation: SQL system error.SQL0904 SQLCODE -904 SQLSTATE 57011Explanation: Resource limit exceeded.SQL0906 SQLCODE -906 SQLSTATE 24514Explanation: Operation not performed because of previous error.SQL0907 SQLCODE -907 SQLSTATE 27000Explanation: Attempt to change same row twice.SQL0910 SQLCODE -910 SQLSTATE 57007Explanation: Object &1 in &2 type *&3 has a pending change.SQL0913 SQLCODE -913 SQLSTATE 57033Explanation: Row or object &1 in &2 type *&3 in use.SQL0917 SQLCODE -917 SQLSTATE 42969Explanation: Package not created.SQL0918 SQLCODE -918 SQLSTATE 51021Explanation: Rollback required.SQL0950 SQLCODE -950 SQLSTATE 42705Explanation: Relational database &1 not in relational database directory. SQL0951 SQLCODE -951 SQLSTATE 55007Explanation: Object &1 in &2 not altered. It is in use.SQL0952 SQLCODE -952 SQLSTATE 57014Explanation: Processing of the SQL statement ended by ENDRDBRQS command. SQL0969 SQLCODE -969 SQLSTATE 58033Explanation: Unexpected client driver error.SQL0971 SQLCODE -971 SQLSTATE 57011Explanation: Referential constraint &4 in check pending state.。

DB2的参数配置说明DB2是一种关系型数据库管理系统(RDBMS),它支持在各种计算环境中存储、操作和检索数据。
在使用DB2时,通过合理的参数配置可以提高数据库的性能和可靠性。
以下是关于DB2参数配置的详细说明。
1.内存参数配置:1.1DB2_MEM_PERCENT:指定了DB2实例可使用的内存百分比,默认值为100。
可以根据实际情况调整此参数,以确保系统有足够的内存资源运行DB21.2DB2_MAX_IOSERVERS:指定了DB2实例可以使用的最大IO服务器数目,默认值为10。
可以根据服务器的硬件配置和负载情况调整此参数,以获得更好的IO性能。
1.3DB2_MAX_MEMORY:指定了DB2实例可以使用的最大内存量,默认为系统可用内存的一半。
可以根据系统的内存情况和负载调整此参数,以提高数据库的性能。
2.查询优化参数配置:2.1DB2_PARALLEL_IO:指定是否允许并行IO,默认为OFF。
可以在高负载环境下启用此参数,以提高查询性能。
2.2DB2_PARALLELISM:指定了DB2查询的并行度,默认为1、可以根据系统的CPU核心数和负载情况调整此参数,以提高查询的并行执行能力。
2.3DB2_STMT_CONC:指定了单个DB2会话中并行执行的最大语句数目,默认为1、可以根据系统的负载情况调整此参数,以提高并行执行的效率。
3.缓存参数配置:3.1DB2_NUM_IOSERVERS:指定了DB2实例可以使用的IO服务器数目,默认为10。
可以根据服务器硬件配置和负载情况调整此参数,以提高IO性能。
3.2DB2_NUM_CHEKBUFFERS:指定了每个缓冲池中的检查缓冲区数目,默认为100。
可以根据系统的内存情况和负载调整此参数,以提高缓存的性能。
3.3DB2_LOGFILSIZ:指定了每个日志文件的大小,默认为64MB。
可以根据系统的IO性能和重做日志的生成速度调整此参数,以避免日志文件的频繁切换。

2007 Wellesley Information Services. All rights reserved.Everything Users Need to Know to 1Creating a report using SAP Query basic screens Creating a report using SAP Query advanced screens Many organizations use a combination of solutions to This session focuses on the SAP Query reporting _____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________7InfoSet Query (Formerly Known As Ad Hoc Query)•Quick one-timelookup utility for fast access to basic data •WYSIWYG (What You See Is What You Get) “quick and dirty”utility to access counts and simple basic lists•Create WYSIWYG views of data called QuickViews•QuickViews are not reports that can be exchanged among users•You can convertQuickViews to reports to be used with ____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________9Third-Party Add-On SolutionsA separately purchased, licensed, and installed solution available to attach to your SAP solutionA pre-configured integrated repository that summarizes data from SAP R/3 plus external sources into a management-level strategic database_____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________15Each Solution Addresses a Different Business NeedReal time reports and analysisExecutive UsersStrategicPower UsersTacticalOperationalEnd UsersReal time reports and analysisSummarized analysisSummarized analysisSummarized analysisIntegrated Executive Analysis and SummaryCasual UserAd Hoc List Inquiry 16Each Solution Addresses a Different Business Need (cont.)Executive UsersStrategicPower UsersTacticalOperationalEnd UsersCasual UserSAP standard canned reports and SAP queriescreated by more savvy users (via transaction codes)SAP QuerySAP Query Module-specific ISInfoSet Query and QuickViewerThird-Party SolutionsBusiness Information Warehouse (BW)Best Practice Recommendation for Query Use•Using a single query reporting tool ensures that:Data is collected and presented in the same format using the same criteriaSecurity is the same for allStandardization for naming conventions, storage, etc., is compliantYou are not at risk for pulling different numbers with different toolsRecommendationUse SAP Query for all HR and Payroll query reporting needs____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________One-Time Configuration Takes Only Five Minutes!Step 1 –Create InfoSets (data source)Step 2 –Create query groupsStep 3 –Assign InfoSet to query grouph View the take-home CD for the session “MasteringStandard SAP Query Tools: Strategic Decisions,Configuration Steps, and Ongoing Administration”h This session covers everything you need to know toperform the one-time configuration of the SAP Query tool _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________Use the forward arrow to proceed through the seven screens Screen #2 –Select Field Groups _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________Screen #4 –Add Fields to the Selection Screen••Click Basic List to proceed to the next screen Screen #5 –Basic List Line Structure Screen _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________31 Screen #7 –Your Finished ReportCompare the Report Output with Screen #5_________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________A Detailed Look at Screen #1 (cont)_________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________A Detailed Look at Screen #2A Detailed Look at Screen #3This screen opens all the Field Groups(from screen #2) to show all fieldsavailable for reportingUse the page up and down buttons toscroll through the multiple fields andselect the fields of interest _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________A Detailed Look at Screen #4 (cont)A Detailed Look at Screen #5Basic list with box:basic ABAP list with lines separating thecolumnsColumns separated by |:lists; inserts a vertical bar after each field on aline except the last. An underscore is outputbefore and after each control level text (ifsorting and sub-totaling is used) and insertedbefore and after each total. In addition, theindividual columns in the standard header are _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________A Detailed Look at Screen #6•Default information contained on the selection screen is based on the logical database selected; each has its own values•For example, the SAP Training Flight Scheduling System F1S database has the fields shown here associated with it. Often, the most common fields are available for selection.Use the toolbar buttons to extract your finished report to Microsoft and other applications. Your Take-Home CD has a guide to what eachbutton does!_________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________How to Create an SAP Query Using the Advanced ScreensAdd sub-totals to the reportChange sub-total textsFormat the list lineAlter the column widths, add colors, hide leadingzeros, and create templates_________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________52See What the Sub-Total Looks LikeBefore AfterScreen #9 –Change Sub-Total Texts on the Report•Any field selected on screen #8 for sub-totaling is available here•Use this screen to modify how sub-total texts appear on a report____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________54 Before AfterScreen #10 –Change Line Output Options•Change the color of thelist, remove headers,and insert blank linesor pagesSee What the Changes Look LikeBefore _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________See What the Changes Look LikeBeforeAfterScreen #12 –Insert Text Before Data Output•Any field selected onscreen #11 for thetemplate is available•Insert text into thereport output for eachindividual line item _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________60See What the Changes Look LikeBeforeAfterSee What the Changes Look LikeBefore After____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________See What the Changes Look LikeWhat We’ll Cover …•Reporting options available for SAP•Using SAP Query•Creating a report using SAP Query basic screens •Creating a report using SAP Query advanced screens •Exploring configuration decisions•Uncovering tips and tricks•Wrap-up _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________Query GroupsFormerly known as User GroupsUse to create, modify, and execute reports in a certain area within SAP R/3Users are grouped byPayrollFinanceAccounts PayableSalesHR _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ __________________________________________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________ _________________________________One-Time Configuration Takes Only Five Minutes!Create InfoSets (Data Source)Create Query GroupsAssign InfoSet to Query GroupThe one-time, technical configuration is the easy part____________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________。
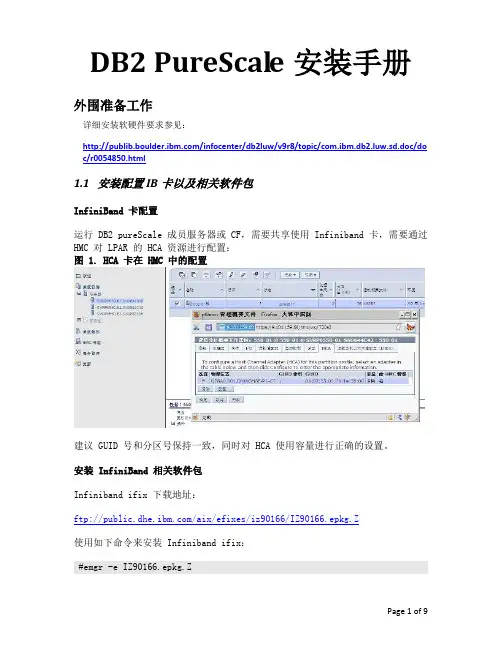
DB2 PureScale安装手册外围准备工作详细安装软硬件要求参见:/infocenter/db2luw/v9r8/topic/com.ibm.db2.luw.sd.doc/do c/r0054850.html1.1安装配置IB卡以及相关软件包InfiniBand 卡配置运行 DB2 pureScale 成员服务器或 CF,需要共享使用 Infiniband 卡,需要通过HMC 对 LPAR 的 HCA 资源进行配置:图 1. HCA 卡在 HMC 中的配置建议 GUID 号和分区号保持一致,同时对 HCA 使用容量进行正确的设置。
安装 InfiniBand 相关软件包Infiniband ifix 下载地址:ftp:///aix/efixes/iz90166/IZ90166.epkg.Z使用如下命令来安装 Infiniband ifix:#emgr -e IZ90166.epkg.ZPage 1 of 9配置 Infiniband Communication Manager在 4个节点上执行如下命令,创建 icm 设备:#mkdev -c management -s infiniband -t icm配置 Infiniband IP 地址在 4个节点上使用如下命令,并输入相关参数:#smit chinet图 2. Infiniband IP 配置需要注意的是,HCA Adapter 必须明确指定 Infiniband 适配器设备,如 iba0,否则服务器重启后 Infiniband 网卡 IP 将无法正常工作,另外Adapter ’ s port number 需要指定到连接了 Infiniband 线缆的端口(Infiniband 网卡为双口)。
配置域名解析在 4 个节点上编辑 /etc/hosts 文件,增加如下条目:172.16.24.121 db2m0172.16.24.122 db2m1172.16.24.123 db2cf0172.16.24.124 db2cf110.10.10.1 db2m0-ib010.10.10.2 db2m1-ib010.10.10.3 db2cf0-ib010.10.10.4 db2cf1-ib01.2其他系统配置共享磁盘赋予 PVID在 4个节点上分别对GPFS的Disk执行如下命令,赋予 PVID: #chdev -l hdisk6 -a pv="yes"配置 IOCP在 4 个节点上执行如下命令,配置 IOCP 设备:#mkdev -l iocp01.3验证DB2 Purescale安装环境1. 检查系统微码级别(firmware level)$ lsmcode –A2. 检查操作系统版本TL和SP,不低于AIX6.1.TL6 SP3$ oslevel -s3. 确认(uDAPL) 已经安装并且配置好。

集群里有三个节点:172.19.2.12(ZBBB_DB1) cf+mem,172.19.2.14(ZBBB_DB2) cf+mem;172.19.2.16(ZBBB_DB3) mem故障现象一:在172.19.2.12上执行df –k查看磁盘情况,发现有一个节点的共享存储掉了其中一个cf显示文件系统挂不上了,df -k看到共享存储的三个文件系统异常;故障现象二:Errpt检查发现有PH报错(adapter报错,机房检查发现机器的hba1亮黄灯)。
故障现象三:三个节点每台机器上都有两块万兆光线卡(hba),两块卡做了绑定,一块坏不应影响网络运行。
但是DB1与DB2互通;DB2与DB3互通;DB1与DB3不通。
问题:1.节点在集群里面吗?重新挂能挂上吗?不知道怎么检查2.盘掉了吗?盘没掉(使用/usr/lpp/mmfs/bin/mmlsnsd可以查看每个文件系统的NSD 配置),每个节点上的NSD servers都为“directly attached”则说明每个节点与网络存储都是正常连接的。
NSD神马意思?,不知道Db2sdin1与root用户的Lspv查看结果分别为:3.Gpfs有问题吗?使用/usr/lpp/mmfs/bin/mmgetstat –a 查看gpfs状态。
在三个节点上分别执行,发现三个节点状态不一致。
mmgetstate看到DB1处于arbitrating状态;DB2是active;DB3是unkown此时即便在ZBBB_DB1上执行/usr/lpp/mmfs/bin/mmount –a也不能把文件系统挂载上,因为DB1不是active状态。
在ZBBB_DB1上执行/usr/lpp/mmfs/bin/mmstartup –a(这是启动所有节点),状态依旧。
在ZBBB_DB1上手工停掉GPFS,然后再启动。
在ZBBB_DB3上也执行该操作,此时ZBBB_DB1执行/usr/lpp/mmfs/bin/mmgetstat –a 查看gpfs状态发现node1和node2为active状态,node3为unknown状态;在ZBBB_DB3执行/usr/lpp mmfs/bin/mmgetstat –a发现node2和node3为active;在ZBBB_DB2/usr/lpp mmfs/bin/mmgetstat –a发现node1和node3为unknown状态,node2为active状态。

【SAP】动态内表代码⽰例*&---------------------------------------------------------------------**& Report YTEST7*&---------------------------------------------------------------------**&*&---------------------------------------------------------------------*REPORT ytest7.*&---------------------------------------------------------------------**& TYPE-POOLS & TABLES*&---------------------------------------------------------------------*TYPE-POOLS: slis.TABLES:mara.*&---------------------------------------------------------------------**& PROGRAM VARIABLES & CONSTANTS*&---------------------------------------------------------------------*DATA: gs_layout TYPE lvc_s_layo,gt_fieldcat TYPE TABLE OF lvc_s_fcat,gs_fieldcat TYPE lvc_s_fcat,gr_grid TYPE REF TO cl_gui_alv_grid,gs_variant LIKE disvariant,gt_events TYPE TABLE OF slis_alv_event,gs_events TYPE slis_alv_event.*&---------------------------------------------------------------------**& DEFINE TABLE*&---------------------------------------------------------------------*TYPES:BEGIN OF ty_tab,sel TYPE c,END OF ty_tab.DATA:gt_tab TYPE TABLE OF ty_tab,gs_tab TYPE ty_tab.FIELD-SYMBOLS: <dyn_table> TYPE STANDARD TABLE.*&---------------------------------------------------------------------**& DEFINITION*&---------------------------------------------------------------------*DEFINE mcr_field.CLEAR gs_fieldcat.gs_fieldcat-fieldname = &1.gs_fieldcat-scrtext_l = &2.gs_fieldcat-colddictxt = &3.gs_fieldcat-qfieldname = &4.gs_fieldcat-no_zero = &5.gs_fieldcat-edit = &6.gs_fieldcat-ref_table = &7.gs_fieldcat-ref_field = &8.gs_fieldcat-hotspot = &9.APPEND gs_fieldcat TO gt_fieldcat.END-OF-DEFINITION.*----------------------------------------------------------------------** SELECTION SCREEN*----------------------------------------------------------------------*PARAMETERS p_col TYPE string OBLIGATORY. "填⼊动态创建的列名,以逗号分隔*----------------------------------------------------------------------** START-OF-SELECTION*----------------------------------------------------------------------*START-OF-SELECTION.PERFORM frm_dis_data . "展⽰数据*&---------------------------------------------------------------------**& Form frm_dis_data*&---------------------------------------------------------------------**& text*&---------------------------------------------------------------------**& --> p1 text*& <-- p2 text*&---------------------------------------------------------------------*FORM frm_dis_data .CLEAR: gs_layout.gs_layout-cwidth_opt = 'X'.gs_layout-zebra = 'X'.PERFORM frm_fill_fieldcat.CALL FUNCTION 'REUSE_ALV_GRID_DISPLAY_LVC'EXPORTINGi_callback_program = sy-repid* i_callback_pf_status_set = 'FRM_STATUS'* i_callback_user_command = 'FRM_COMMAND'is_layout_lvc = gs_layoutit_fieldcat_lvc = gt_fieldcat[]is_variant = gs_variantit_events = gt_eventsi_default = 'X'i_save = 'A'TABLESt_outtab = <dyn_table>EXCEPTIONSprogram_error = 1OTHERS = 2.ENDFORM.*&---------------------------------------------------------------------**& Form frm_fill_fieldcat*&---------------------------------------------------------------------**& text*&---------------------------------------------------------------------**& --> p1 text*& <-- p2 text*&---------------------------------------------------------------------*FORM frm_fill_fieldcat .SPLIT p_col AT ',' INTO TABLE DATA(gt_col).LOOP AT gt_col ASSIGNING FIELD-SYMBOL(<fs_col>).DATA(lv_txt) = <fs_col> && '描述'.mcr_field:<fs_col> lv_txt 'L'''''''''''''.ENDLOOP.PERFORM frm_create_dyn. "创建动态内表&&填充数据ENDFORM.*&---------------------------------------------------------------------**& Form FRM_CREATE_DYN*&---------------------------------------------------------------------**& text*&---------------------------------------------------------------------**& --> p1 text*& <-- p2 text*&---------------------------------------------------------------------*FORM frm_create_dyn .DATA:lt_table TYPE REF TO data."创建动态内表CALL METHOD cl_alv_table_create=>create_dynamic_tableEXPORTINGit_fieldcatalog = gt_fieldcatIMPORTINGep_table = lt_tableEXCEPTIONSgenerate_subpool_dir_full = 1OTHERS = 2.ASSIGN lt_table->* TO <dyn_table>.PERFORM frm_write_data_to_dyntable. "向动态内表中写数ENDFORM.*&---------------------------------------------------------------------**& Form frm_write_data_to_dyntable*&---------------------------------------------------------------------**& text*&---------------------------------------------------------------------**& --> p1 text*& <-- p2 text*&---------------------------------------------------------------------*FORM frm_write_data_to_dyntable .DATA:ls_new_line TYPE REF TO data.FIELD-SYMBOLS:<dyn_wa>,<field>.SPLIT p_col AT ',' INTO TABLE DATA(gt_col)."建⽴⼀个与动态内表结构相同的数据对象CREATE DATA ls_new_line LIKE LINE OF <dyn_table>.ASSIGN ls_new_line->* TO <dyn_wa>.DESCRIBE TABLE gt_col LINES DATA(lv_col)."填充数据DO 3 TIMES.DO lv_col TIMES.DATA(lv_index) = sy-index.ASSIGN COMPONENT sy-index OF STRUCTURE <dyn_wa> TO FIELD-SYMBOL(<fs_field>). <fs_field> = '填充值' && lv_index .ENDDO.APPEND <dyn_wa> TO <dyn_table>.ENDDO. ENDFORM.。

DB2 purescale 集群 HADR 环境联机升级从DB2 V10.5开始,DB2 pureScale集群支持HADR容灾解决方案和联机安装修订包。
本文主要通过实际环境操作,介绍如何在DB2 pureScale集群HADR环境滚动联机升级补丁包:升级前所需要做的准备工作,升级步骤,升级检查等。
Db2 pureScale集群HADR特性介绍Db2 pureScale功能为数据库提供了本地高可用的集群架构。
在本地高可用的基础上,Db2的HADR功能能够满足企业远程灾备的需要。
从Db2 V10.5开始,HADR功能与pureScale功能开始结合在一起,共同为数据库提供了本地高可用加远程灾备的解决方案。
在pureScale架构里面,多个成员共同为一个数据库服务。
每个成员都会记载各自的日志。
所以在Db2 pureScale集群架构里面,Db2生成了多个日志流。
基于这种多日志流,Db2 HADR功能会去合并日志流,然后重放,从而达到同步的功能。
Db2 pureScale集群HADR容灾架构在Db2 pureScale集群HADR容灾架构的体系中,主备站点都是Db2 pureScale集群。
对于所有在主集群的成员产生的日志流,备集群会在其中一个成员节点上接受所有的日志流,合并并重放,从而达到同步的目的。
图1. Db2 pureScale HADR架构Db2 pureScale集群HADR功能也能很好的应用pureScale集群的高可用特性。
如果主集群的成员出现故障,其他成员节点可以帮助传输日志到备集群,因为存储是共享的,所以所有日志流都是集群内部节点都可见的。
如果是备集群的HADR回放节点出现故障,其他健康的成员节点也可以自动接管回放的工作。
总之一切都是为了高可用,零宕机。
Db2 pureScale集群环境联机修订包升级特性介绍Db2 pureScale集群最大的特点之一就是本地高可用性。
无论是意外宕机还是计划的停机维护,pureScale集群都能够通过滚动维护的方式,完成维护工作的同时,保证数据库提供服务不中断。
Deploy IBM DB2 pureScale on AzureBy Benjamin Guinebertière, Alessandro Vozza, Jonathon Frost, Mukesh Kumar, and Larry Mead Azure Customer Advisory Team (AzureCAT)Commercial Software Engineering Team (CSE)Data Migration JumpStart Team (DMJ)May 2018This document is provided “as-is”. Information and views expressed in this document, including URL and other Internet Web site references, may change without notice.Some examples depicted herein are provided for illustration only and are fictitious. No real association or connection is intended or should be inferred.This document does not provide you with any legal rights to any intellectual property in any Microsoft product. You may copy and use this document for your internal, reference purposes.© 2018 Microsoft. All rights reserved.ContentsIntroduction (3)Architecture (4)Compute considerations (5)Storage considerations (5)Networking considerations (6)Solution deployment (7)How the deployment works (7)DB2 pureScale response file (8)Troubleshooting and known issues (9)Learn more (10)IntroductionEnterprises have long used traditional RDBMS platforms to cater to OLTP needs. These days, many are migrating their mainframe-based database environments to the Azure cloud as a way to expand capacity, reduce costs, and maintain a steady operational cost structure. Migration is often the first step in modernizing a legacy platform.The AzureCAT, CSE, and DMJ teams recently worked with an enterprise that rehosted their IBM DB2 environment running on z/OS to IBM DB2 pureScale on Azure. The DB2 pureScale database cluster solution provides high availability and scalability on Linux operating systems. We successfully ran DB2 standalone on a large scale-up system on Azure prior to installing DB2 pureScale.While not identical to original environment, IBM DB2 pureScale on Linux delivers similar high availability and scalability features as IBM DB2 for z/OS running in a Parallel Sysplex environment on the mainframe.This guide describes the steps we took during the migration so you can take advantage of our learnings. Installation scripts are available in the repository on GitHub. These scripts are based on the architecture we used for a typical medium-sized OLTP workload.Consider this guide and the scripts a starting point for your DB2 implementation plan. Your business requirements will differ, but the same basic pattern applies. This architectural pattern may also be used for OLAP applications on Azure.This guide does not cover differences and possible migration tasks for moving IBM DB2 for z/OS to IBM DB2 pureScale running on Linux. Nor does it provide equivalent sizing estimations and workload analyses for moving from DB2 z/OS to DB2 pureScale architectures. Before you decide on the best DB2 pureScale architecture for your environment, we highly recommend that you complete a full sizing estimation exercise and establish a hypothesis. Among other factors, on the source system make sure to consider DB2 z/OS Parallel Sysplex with Data Sharing Architecture, Coupling Facility configuration, and DDF usage statistics.NOTE: This guide is intended to describe one approach to DB2 migration, but there are others. For example, DB2 pureScale can also run in virtualized environments on premises. IBM supports DB2 on Microsoft Hyper-V in various configurations. For more information, see Db2 pureScale virtualization architecture in the IBM knowledge Center.ArchitectureTo support high availability and scalability on Azure, we set up a scale-out, shared data architecture for DB2 pureScale. We used the following architecture for our customer migration.Figure 1. DB2 pureScale on Azure VM, Network and Storage DiagramThis diagram depicts a DB2 pureScale cluster where two nodes are used for the cache and are known as the caching facilities (CF). A minimum of two nodes are used for the database engineand are known as cluster members. The cluster is connected via iSCSI to a three-node GlusterFS shared storage cluster to provide scale-out storage and high availability. DB2 pureScale is installed on Azure virtual machines running Linux.Consider our approach a template that you can modify as needed to suit the size and scale needed by your organization. Our architectural approach is based on the following:•Two or more database nodes are combined with at least two CF nodes that handle the global buffer pool (GBP) for shared memory and global lock manager (GLM) services to controlshared access and lock contention from multiple active nodes. One CF node acts as theprimary and the other as the secondary CF node. A minimum of four nodes are required for a DB2 pureScale cluster.•High-performance shared storage (shown in P30 size in the diagram above), which is used by each of the Gluster FS nodes..•High-performance networking for the data nodes and shared storage.Compute considerationsThis architecture runs the application, storage, and data tiers on Azure virtual machines. The setup scripts create the following:•DB2 pureScale cluster. The type of compute resources you need on Azure depend on your setup. In general, there are two approaches:•Use a multi-node, high-performance computing (HPC)-style network where multiple small to medium-sized instances access the shared storage. For this HPC type of configuration, Azure memory-optimized G-series or storage-optimized L-series virtual machines provide the needed compute power.•Use fewer large virtual machine instances for the data engines. For large instances, the largest memory optimized M-series virtual machines are ideal for heavy in-memoryworkloads, but a dedicated instance may be required depending on the size of theLogical Partition (LPAR) that runs DB2.•The DB2 CF uses memory-optimized VMs such as G-series or L-series.•GlusterFS storage uses Standard_DS4_v2 virtual machines running Linux.• A GlusterFS jumpbox is a Standard_DS2_v2 virtual machine running Linux.•The client is a Standard_DS3_v2 virtual machine running Windows to use for testing.• A witness server is a Standard_DS3_v2 virtual machine running Linux used for DB2 pureScale.In either case, a minimum of two DB2 instances are required in a DB2 pureScale cluster. A Cache instance and Lock Manager instance are also required.Storage considerationsLike Oracle RAC, DB2 pureScale is a high-performance block I/O, scale-out database. We recommend using the largest available Azure Premium Storage that suits your needs. For example, smaller storage options may be suitable for a test environment while productionenvironments often use larger. We chose P30 because of its ratio of IOPS to size and price. Regardless of size, use Premium Storage for best performance.DB2 pureScale uses a shared everything architecture, where all data is accessible from all cluster nodes. Premium storage must be shared across multiple instances—whether on-demand or on dedicated instances.A large DB2 pureScale cluster can require 200 terabytes (TB) or higher of Premium shared storage, with IOPS of 100,000. DB2 pureScale supports an iSCSI block interface that can be used on Azure. The iSCSI interface requires a shared storage cluster that can be implemented with GlusterFS, S2D, or another tool. This type of solution creates a virtual SAN (vSAN) device in Azure. DB2 pureScale uses the vSAN to install the General Parallel File System (GPFS) used to share data among multiple VMs.1For this architecture, we use the GlusterFS file system, a free, scalable, open source distributed file system specifically optimized for cloud storage.Networking considerationsIBM recommends InfiniBand networking for all nodes in a DB2 pureScale cluster (both data and management nodes). For performance, DB2 pureScale also uses RDMA (where available) for the caching node.During setup, an Azure resource group is created to contain all the virtual machines. In general, resources are grouped based on their lifetime and who will manage them. The virtual machines in this architecture require accelerated networking, an Azure feature that provides consistent, ultra-low network latency via single root I/O virtualization (SR-IOV) to a virtual machine.Every Azure virtual machine is deployed into a virtual network that is segmented into multiple subnets: main, Gluster FS front end (gfsfe), Gluster FS back end (bfsbe), DB2 pureScale (db2be), and DB2 purescale front end (db2fe). The installation script also creates the primary NICs on the virtual machines in the main subnet.Network security groups (NSGs) are used to restrict network traffic within the virtual network and isolate the subnets.On Azure, DB2 pureScale needs to use TCP/IP as the network connection for storage.1 The performance benchmarks for the various vSAN implementations have yet to be established as this writing.Solution deploymentTo deploy this architecture, run the deploy.sh script in the DB2onAzure repository on GitHub.In addition, the repository also includes scripts you can use to set up a Grafana dashboard that supports querying Prometheus.NOTE: The deploy.sh script on the client creates private SSH keys and passes them to the deployment template over HTTPS. For greater security, we recommend using Azure Key Vault to How the deployment worksThe deploy.sh script creates and configures the Azure resources that are used in this architecture. The script prompts you for the Azure subscription and VMs for the target environment and then creates the following resources:•Sets up the resource group, virtual network, and subnets on Azure for the installation.•Sets up the NSGs and SSH for the environment.•Sets up multiple NICs on both the GlusterFS and DB2 pureScale virtual machines.•Creates the GlusterFS storage virtual machines.•Creates the jumpbox virtual machine•Creates the DB2 pureScale virtual machines.•Creates the witness virtual machine that DB2 pureScale pings.•Creates a Windows virtual machine to use for testing but does not install anything on it. Next, the deployment scripts set up iSCSI vSAN for shared storage on Azure. In this example, iSCSI connects to GlusterFS. This solution also gives you the option to install the iSCSI targets as a single Windows node. iSCSI provides a shared block storage interface over TCP/IP that allows the DB2 pureScale setup procedure to use a device interface to connect to shared storage. For GlusterFS basics, see the Architecture: Types of volumes topic in Getting started with GlusterFS. The deployment scripts follow these general steps:1.Sets up a shared storage cluster on Azure. We use GlusterFS to set up our shared storagecluster. This involves at least two Linux nodes. For setup details, see Setting up Red HatGluster Storage in Microsoft Azure in the Red Hat Gluster documentation.2.Sets up an iSCSI Direct interface on target Linux servers for GlusterFS. For setup details,GlusterFS iSCSI in the GlusterFS Administration Guide.3.Sets up the iSCSI Initiator on the Linux virtual machines that will access the GlusterFS clusterusing iSCSI Target. For setup details, see the How To Configure An iSCSI Target And Initiator In Linux in the RootUsers documentation.4.Installs GlusterFS as the storage layer for the iSCSI interface.After creating the iSCSI device, the final step is to install DB2 pureScale. The DB2 pureScale setup also compiles and installs IBM GPFS on the GlusterFS cluster. GPFS enables DB2 pureScale toshare data among the multiple virtual machines that run the DB2 pureScale engine. To tune your configuration, see Best Practices: DB2 databases and the IBM GPFS.For more information, see Install and configure General Parallel File System (GPFS) on xSeries on the IBM website. These installation instructions are for x86 versions of Linux but also apply to Linux virtual machines on Azure. To tune your configuration, see Best Practices: DB2 databases and the IBM GPFS.DB2 pureScale response fileThe repo includes DB2server.rsp, a response (.rsp) file that enables you to generate an automated script for the DB2 pureScale installation. The following table lists the DB2 pureScale options that the response file uses for setup. You can customize the response file for your installation environment. A sample response file (DB2server.rsp) is included. If you use this response file, you must edit it to work in your environment.Choose a Product DB2 Version 11.1.2.2. Server Editions with DB2 pureScaleConfiguration Directory /data1/opt/ibm/DB2/V11.1 '' Select the installationtypeTypical'' I agree to the IBMtermsCheckedInstance Owner Existing User ForInstance, User nameDB2sdin1Fenced User Existing User, UsernameDB2sdfe1Cluster File System Shared disk partitiondevice path/dev/dm-2'' Mount point /DB2sd_1804a '' Shared disk for data /dev/dm-1'' Mount point (Data) /DB2fs/datafs1 '' Shared disk for log /dev/dm-0'' Mount point (Log) /DB2fs/logfs1 '' DB2 Cluster ServicesTiebreaker. Devicepath/dev/dm-3Host List d1 [eth1], d2 [eth1],cf1 [eth1], cf2 [eth1]'' Preferred primary CF cf1 '' Preferred secondaryCFcf2Response File and Summary first option Install DB2 Server Edition with the IBM DB2pureScale feature and save my settings in aresponse file'' Response file name /root/DB2server.rspNote that /dev-dm0, /dev-dm1, /dev-dm2 and /dev-dm3 can change after a reboot on the virtual machine where the setup takes place (d0 in the automated script). To find the right values, you can issue the following command before completing the response file on the server where the setup will be run:[root@d0 rhel]# ls -als /dev/mappertotal 00 drwxr-xr-x 2 root root 140 May 30 11:07 .0 drwxr-xr-x 19 root root 4060 May 30 11:31 ..0 crw------- 1 root root 10, 236 May 30 11:04 control0 lrwxrwxrwx 1 root root 7 May 30 11:07 db2data1 -> ../dm-10 lrwxrwxrwx 1 root root 7 May 30 11:07 db2log1 -> ../dm-00 lrwxrwxrwx 1 root root 7 May 30 11:26 db2shared -> ../dm-20 lrwxrwxrwx 1 root root 7 May 30 11:08 db2tieb -> ../dm-3The setup scripts use aliases for the iSCSI disks so that the actual names can be found easily. Also, when the setup is run on d0, the /dev/dm-* values may be different on d1, cf0 and cf1. The pureScale setup doesn’t car e.Troubleshooting and known issuesThe GitHub repo includes a Knowledge Base maintained by the authors. It lists potential issues you may encounter and resolutions to try. For example, known issues can occur when:•Trying to reach the gateway IP address.•Compiling GPL.•The security handshake between hosts fails.•The DB2 installer detects an existing file system.•Manually installing GPFS.•Installing DB2 pureScale when GPFS is already created.•Removing DB2 pureScale and GPFS.For more information about these and other known issues, see kb.md in the DB2onAzure repo.Learn moreGlusterFS iSCSICreating required users for a DB2 pureScale Feature installationDB2icrt - Create instance commandDB2 pureScale Clusters Data SolutionIBM Data StudioPlatform Modernization Alliance: IBM DB2 on AzureAzure Virtual Data Center Lift and Shift GuideFeedback and suggestionsIf you have feedback or suggestions for improving this data migration asset, please contact the Data Migration Jumpstart Team (******************************). Thanks for your support! Note:For additional information about migrating various source databases to Azure, see the Azure Database Migration Guide.。
DB2 pureScale工作负载均衡特性介绍DB2 pureScale是IBM专门针对OLTP工作负载类型的推出的数据库集群技术,集成了持续可用,高扩展性以及对应用透明三大特性,可以为用户提供不间断的数据库服务以及无风险的横向扩展能力以满足业务增长需求。
因此DB2 pureScale也成为面向OLTP业务类型的最佳集群解决方案。
图一 DB2 pureScale系统概览在一个DB2 pureScale集群中,采用共享数据的架构,同一时刻集群中的多个数据库服务器成员节点可以同时对外提供数据库服务。
而DB2 purescale的工作负载均衡技术,正是实现DB2 pureScale集群的持续可用性,高扩展性和应用透明性的保障。
DB2 pureScale集群只有充分利用每个成员的处理能力,将来至应用程序端的数据库服务请求均衡的分布在集群中的各个成员节点上,才能使应用获得最大的工作吞吐量和最小的响应时间。
通常情况下,连接到DB2 pureScale数据库集群的客户端应用无需知道自己实际连接的是哪一个成员,以及某一特定的工作负载被分发到哪个成员节点上。
所有的这一切对应用程序都是透明的,而且一旦某一成员节点发生故障,该成员节点上的连接和工作负载可以很快的被转移到其他正常的成员节点上继续执行。
如果DB2 pureScale集群中有新的成员节点恢复或加入,新加入的成员节点可以立刻分担之前运行在其它成员上节点上的工作负载。
DB2 pureScale集群成员负载信息列表DB2 pureScale集群采用了动态的工作负载均衡分发机制,而不是传统的固定轮转(Round Robin)的方式。
传统的固定轮转的工作负载均衡分发机制如下图所示,假如集群中一共有四个成员节点,因此每个成员节点被分配了25%的来自客户端应用的请求。
假如每个来自客户端应用的请求对数据库资源的需求是相同的或相似的,那么这种方式是有效的。
但实际的生产环境中往往每个客户端过来的请求是不一样的,假设被分配到Member0上的客户端应用请求中有一个是某部门领导在查看销售报表时发起的,该操作中查询非常复杂,将访问大量的数据和消耗大量的服务器资源。
什么是 DB2 pureScale?让 DB2 获得极限的可伸缩性和可用性2009 年10 月,IBM 宣布了一项新技术,该技术名为IBM DB2 pureScale,主要针对在线事务处理(online transaction processing,OLTP)向外扩展(scale-out)集群。
DB2 pureScale 是一种新特性,它为在 Power Systems 服务器上的 AIX 上运行的 IBM DB2 提供向外扩展的主动-主动服务。
它的设计是为了提供最高级别的分布式可用性和可伸缩性,这种分布式可用性和可伸缩性包装在经过深思熟虑的构建-运行式的路径中,操作起来比其他集群数据库系统容易得多。
在本文中,我们将从技术角度介绍DB2 pureScale 的基本知识,展示DB2 pureScale 如何同时提供透明的应用程序可伸缩性和极高的可用性。
我看到你在那里做了什么如果您熟悉 DB2 for z/OS 上的数据共享,那么 DB2 pureScale 架构看上去非常熟悉,因为它就是那样的! IBM 采用 DB2 for z/OS 数据共享的基本原则,并将这些原则与最新的分布式技术相结合,从而为分布式平台提供空前的可用性和可伸缩性服务。
在此要注意一点:System z 服务器上运行的 DB2 已经能够提供一流的可用性。
例如,Toronto Dominion Bank (TD Bank)连续 10 年保持客户信息 100%的可用性,期间还包括两次 DB2 for z/OS 升级。
连我们最大竞争对手的 CEO 也这样说 DB2 for z/OS:“它是一项一流的技术。
”图1 显示DB2 pureScale 环境的一个例子。
每个属于pureScale 集群的 DB2 服务器被称作一个成员。
每个成员可以同时访问相同的数据库,包括读和写操作。
目前,pureScale 集群的最大成员数是 128。
图1:在DB2 pureScale 集群中,每个成员可直接对PowerHA pureScale 服务器的集中式锁和缓存服务进行基于内存的访问。
DB2 pureScale方案前景分析施青华【摘要】随着信息技术的不断发展,银行业实现开放平台数据库共享的需求也越来越强烈,迫切希望实现开放平台数据库健壮性和处理容量的提升。
2009年,IBM推出DB2 pureScale技术,为数据库技术翻开了暂新的一页。
【期刊名称】《中国金融电脑》【年(卷),期】2011(000)008【总页数】3页(P50-52)【关键词】DB2;数据库共享;信息技术;开放平台;数据库技术;银行业;健壮性;IBM 【作者】施青华【作者单位】交通银行股份有限公司信息技术管理部【正文语种】中文【中图分类】TP311.13随着信息技术的不断发展,银行业实现开放平台数据库共享的需求也越来越强烈,迫切希望实现开放平台数据库健壮性和处理容量的提升。
2009年,IBM推出DB2 pureScale技术,为数据库技术翻开了暂新的一页。
一、DB2 pureScale 产生的背景在提高数据库可用性和工作量负载上,DB2 for z/OS现已成为业界数据库技术的标准。
作为主要数据库运行平台,DB2 在主机平台已经实现了数据共享(datasharing),以提供大工作流量负载和数据库健壮性。
DB2 在开放平台的高可用性,则主要通过操作系统提供的HA技术来保障;而处理容量的提高,主要依靠单台主机的资源配置。
综合考察开放平台DB2目前提供的解决方案,还存在以下不足:HA切换过程中,会有2~5分钟的时间中断;HA的切换是否成功,取决于数据库启动脚本作者能力的高低,实际工作环境中,由于考虑不周全,导致数据库HA 切换不成功的情况经常出现,从而进一步影响可用性;开放平台只能实现一个数据库实例对外工作,无法做到工作流量多台主机均衡负载,尤其是当其承担的工作量超越单台硬件主机的容量时;在实例失效的情况下,数据库将无法继续对外服务;无法实现多节点主机对单份数据对象的访问。
这些问题导致当前银行业主要业务系统在建设时无法横向扩展处理容量,也无法支持多节点处理;对于有双中心建设需求的银行,数据库必须在一个中心集中处理,高可用性也无法进一步提高。
IBMDB2pureScale集群化数据库架构和技术概述本系列文章共分为两个部分,第 1 部分介绍了 DB2 pureScale 的架构和技术,第 2 部分将介绍 DB2 pureScale 应用程序配置。
持续可用性、应用程序集群透明度和极限容量:无论在怎样的市场营销资料中,这些热门关键词总是与 IBM DB2 pureScale 密不可分。
但它们真正的含义是什么?DB2 pureScale 绝不只是一项特性,而是一种观察 DB2 数据库的全新方式。
您在访问数据时不再受限于单独一个主机,不再需要为了保证每个主机都拥有一个分区而划分数据分区。
DB2 pureScale 提供了一种集群化的解决方案,利用多个主机来访问相同的数据分区,从而提高了容量,加强了持续可用性。
DB2 pureScale 技术图 1. DB2 pureScale 架构图字:Automatic workload balancing:自动工作负载平衡Leverages the global lock and memory manager technology from z/OS:利用 z/OS 提供的全局锁和内存管理器技术Integrated Cluster manager:集成化集群管理器Shared data:共享数据InfiniBand network and db2 cluster services:InfiniBand 网络和 DB2 集群服务Clusters of DB2 nodes:DB2节点集群DB2 pureScale 特性基于业界领先的 IBM System z 数据共享架构。
DB2 pureScale是一种紧密集成的数据库集群化解决方案,它利用 IBM DB2 for Linux, UNIX and Windows 作为核心引擎,运行于IBM POWER 和 IBM System x 硬件服务器之上。
DB2 pureScale 可安装在AIX、SUSE Linux Enterprise Server 或Redhat Enterprise Linux 上。