机器学习_Villages Data(Bilkent大学村庄数据)
- 格式:pdf
- 大小:73.56 KB
- 文档页数:3

机器学习入门教程简介机器学习是一种人工智能(AI)领域的技术,它使计算机能够从数据中自动学习并改进性能,而不需要明确编程。
本教程旨在介绍机器学习的基础知识和常见的算法,以帮助初学者快速入门。
目录1.什么是机器学习2.机器学习的应用领域3.常见的机器学习算法•监督学习算法–线性回归–逻辑回归–决策树–支持向量机•无监督学习算法–K均值聚类–主成分分析(PCA)–关联规则挖掘(Apriori算法)4.数据预处理•数据清洗•特征选择和提取•数据转换和标准化5.模型评估与选择6.模型调优与参数优化7.实践案例展示什么是机器学习机器学习是一种通过对数据进行统计分析和模式识别来让计算机自动进行决策或预测的技术。
它基于数学和统计原理,利用算法和模型来让计算机从数据中学习,提取规律并应用于新的数据。
机器学习的应用领域机器学习已经广泛应用于各个领域,包括但不限于以下几个方面:•自然语言处理(NLP)•图像识别与处理•推荐系统•声音和语音识别•金融风控与欺诈检测•医疗诊断与预测•智能交通系统•智能物流和供应链管理常见的机器学习算法监督学习算法监督学习是一种通过已有的输入输出数据来训练模型,并利用该模型对未知数据进行预测或分类的方法。
线性回归线性回归是一种常见的监督学习算法,适用于对连续数值进行预测。
它建立了一个线性关系模型,通过最小化残差平方和来找到最优解。
逻辑回归逻辑回归是一种二分类问题的监督学习算法。
它通过将线性回归模型结合Sigmoid函数的输出进行转换,将连续值映射到概率范围内(0到1之间)。
决策树决策树是一种基于树状结构的分类算法,通过学习从特征到目标值的映射关系来进行预测。
它可以处理离散和连续型数据,并且易于解释和理解。
支持向量机支持向量机(SVM)是一种常用的监督学习算法,在二分类和多分类问题中都有良好的表现。
它通过在高维空间中找出最优分隔超平面来进行分类。
无监督学习算法无监督学习是一种通过对未标记数据的分析、挖掘和模式识别来进行模型训练的方法。

机器学习与数据挖掘考试试题及答案一、选择题1. 以下哪种算法常用于分类问题?A. 线性回归B. 支持向量机C. 聚类分析D. 主成分分析答案:B. 支持向量机2. 数据集划分为训练集和测试集的目的是什么?A. 增加模型的复杂度B. 验证模型的性能C. 加速模型训练过程D. 提高数据的可视化效果答案:B. 验证模型的性能3. 常见的神经网络结构不包括:A. 多层感知器(MLP)B. 卷积神经网络(CNN)C. 循环神经网络(RNN)D. 支持向量机(SVM)答案:D. 支持向量机(SVM)4. 在数据挖掘中,关联规则用来描述:A. 哪些属性是关键属性B. 哪些实例之间存在相似性C. 哪些属性之间存在相关性D. 哪些属性可以被忽略答案:C. 哪些属性之间存在相关性5. 在集成学习中,袋装法(Bagging)常用的基分类器是:A. 决策树B. 朴素贝叶斯C. K近邻D. 支持向量机答案:A. 决策树二、简答题1. 请简要解释什么是过拟合(Overfitting),并提供防止过拟合的方法。
过拟合指的是模型在训练集上表现良好,但在测试集或新数据上表现不佳的现象。
过拟合的原因是模型过度学习了训练集的噪声或细节,将其误认为普遍规律。
防止过拟合的方法包括:- 增加训练数据量,以使模型接触到更多的样本,减少过拟合的可能性。
- 使用正则化技术,如L1正则化或L2正则化,对模型参数进行约束,减小参数的影响。
- 采用特征选择或降维方法,去除冗余或不重要的特征,减少模型在噪声上的过拟合。
- 使用交叉验证技术,将数据集划分为多个训练集和验证集,选择最优模型,降低过拟合的风险。
2. 请简述决策树算法的基本原理,并说明如何进行特征选择。
决策树算法通过构建一棵树形结构来进行分类或回归。
其基本原理是根据属性的划分规则将样本逐步分到不同的节点,直到达到终止条件(如叶子节点纯度满足一定要求或树的深度达到一定限制等)。
特征选择是决策树算法中非常重要的一部分,常用的特征选择方法包括:- 信息增益(Information Gain):选择能够获得最大信息增益的属性作为划分属性。

《机器学习》期末考试试卷附答案一、选择题(每题5分,共25分)1. 机器学习的主要目的是让计算机从数据中____,以实现某些任务或预测未知数据。
A. 抽取特征B. 生成模型C. 进行推理D. 分类标签答案:B. 生成模型2. K-近邻算法(K-NN)是一种____算法。
A. 监督学习B. 无监督学习C. 半监督学习D. 强化学习答案:A. 监督学习3. 在决策树算法中,节点的分裂是基于____进行的。
A. 信息增益B. 基尼不纯度C. 均方误差D. 交叉验证答案:A. 信息增益4. 支持向量机(SVM)的主要目的是找到一个超平面,将不同类别的数据点____。
A. 完全分开B. 尽量分开C. 部分分开D. 不分开答案:B. 尽量分开5. 哪种优化算法通常用于训练深度学习模型?A. 梯度下降B. 牛顿法C. 拟牛顿法D. 以上都对答案:D. 以上都对二、填空题(每题5分,共25分)1. 机器学习可以分为监督学习、无监督学习和____学习。
A. 半监督B. 强化C. 主动学习D. 深度答案:A. 半监督2. 线性回归模型是一种____模型。
A. 线性B. 非线性C. 混合型D. 不确定型答案:A. 线性3. 在进行特征选择时,常用的评估指标有____、____和____。
A. 准确率B. 召回率C. F1 分数D. AUC 值答案:B. 召回率C. F1 分数D. AUC 值4. 神经网络中的激活函数通常用于引入____。
A. 非线性B. 线性C. 噪声D. 约束答案:A. 非线性5. 当我们说一个模型具有很好的泛化能力时,意味着该模型在____上表现良好。
A. 训练集B. 验证集C. 测试集D. 所有集答案:C. 测试集三、简答题(每题10分,共30分)1. 请简要解释什么是过拟合和欠拟合,并给出解决方法。
2. 请解释什么是交叉验证,并说明它的作用。
答案:交叉验证是一种评估模型泛化能力的方法,通过将数据集分成若干个互斥的子集,轮流用其中若干个子集作为训练集,其余子集作为验证集,对模型进行评估。

机器学习的基础原理和应用机器学习(Machine Learning)是一种一直被广泛使用且备受瞩目的技术,它可以让计算机在没有明确编程指令的情况下自动实现某些任务,例如识别图像、自然语言处理和预测结果等。
机器学习的基础原理机器学习的基础在于算法能够通过大量的数据自动完成某项任务。
其中,训练数据是机器学习算法的基础之一,可以是有标签的数据(即已经被标注的数据),也可以是无标签的数据。
机器学习的算法可以根据选择的算法类型分类为监督学习、无监督学习和半监督学习。
监督学习是在算法被告知正确答案的情况下进行的,无监督学习是在算法没有被告知正确答案的情况下进行的,而半监督学习则是在算法被告知部分正确答案的情况下进行的。
机器学习的应用机器学习已经广泛应用于各个领域中,如自然语言处理、机器翻译、计算机视觉、人工智能等。
自然语言处理(NLP):NLP 是机器学习在语言处理领域中的一种应用,可用于自动化翻译、语音识别和情感分析等。
例如,谷歌翻译应用程序就利用了机器学习技术。
机器翻译:机器翻译是一项很复杂的任务,对于不同语言之间的语法和词汇有着复杂的要求。
机器翻译主要利用了深度学习技术、掌握语言学知识的翻译专家以及语言学习技术。
近年来,机器翻译在短文、新闻以及社交媒体等方面已取得了巨大的进展。
计算机视觉:计算机视觉是机器学习在计算机视觉领域中的一种应用,通常用于追踪、安全、质量控制等方面。
例如,像AlexNet 和 VGG 这样的卷积神经网络已被用于图像分类,分割以及目标检测等操作。
人工智能:人工智能应用了多机器学习技术,例如图像识别、数据分析和认知计算,已被应用于很多不同的领域,如自驾车和工业自动化。
结论机器学习技术的范围和适用性越来越广泛,其与其他技术的结合也越来越成为一个人工智能生态系统的基础。
预计,在未来几年内,随着机器学习技术的进一步发展和应用,人们对其了解和使用的,也会越来越普遍。

机器学习知识点整理机器学习是人工智能领域的重要分支,它研究计算机系统如何通过经验和数据来提高性能。
在这篇文章中,我们将整理一些机器学习的基本知识点,帮助读者对这一领域有一个全面的了解。
1.机器学习的定义:机器学习是一种通过从数据中学习并自动改进经验的方法,以实现任务完成的能力。
它的目标是让机器能够从数据中发现模式、进行预测和做出决策。
2. 监督学习:监督学习是机器学习中最常见的类型之一。
它的目标是通过给定的输入和相应的输出数据,训练模型来预测新的输入对应的输出。
常见的监督学习算法包括线性回归、逻辑回归和决策树等。
3. 无监督学习:无监督学习是指从无标签数据中自动发现模式和结构的机器学习方法。
它的目标是在没有任何先验知识的情况下,对数据进行聚类、降维和关联规则挖掘等任务。
常见的无监督学习算法包括K-means聚类和主成分分析(PCA)等。
4. 强化学习:强化学习是一种通过学习如何在给定环境中采取动作来最大化累积奖励的方法。
它的目标是建立一个智能体(agent),让它能够在与环境的交互中学习来做出最优的决策。
常见的强化学习算法包括Q学习和深度强化学习等。
5. 模型评估:在机器学习中,评估模型的性能是至关重要的。
常用的评估指标包括准确率、召回率、F1分数和ROC曲线等。
此外,交叉验证和混淆矩阵也是评估模型性能的重要工具。
6. 特征选择:在机器学习任务中,选择合适的特征对于提高模型性能非常重要。
特征选择的目标是从原始特征集中选择一组最相关的特征。
常见的特征选择方法包括相关系数、卡方检验和信息增益等。
7. 过拟合和欠拟合:过拟合和欠拟合是机器学习中常见的问题。
过拟合指的是模型过于复杂,过度适应训练数据,导致在新数据上表现不佳。
欠拟合指的是模型过于简单,无法很好地拟合训练数据和新数据。
解决过拟合和欠拟合问题的方法包括增加数据样本、正则化和模型集成等。
8. 神经网络:神经网络是一种受到生物神经系统启发的算法模型,在机器学习中应用广泛。

生物大数据技术的机器学习算法解析随着生物学研究的不断进展和生物大数据的爆发式增长,机器学习算法逐渐成为处理生物大数据的重要工具。
生物大数据技术的机器学习算法能够帮助科学家从大量的数据中提取有用的信息,快速分析复杂的生物过程,并为生物学研究和医学应用提供有力支持。
机器学习是一种通过训练数据来构建模型,并利用该模型对新数据进行预测或分类的方法。
在生物大数据技术中,机器学习算法扮演着至关重要的角色,能够处理复杂的生物大数据并发现其中的规律和模式。
以下将介绍几种常见的生物大数据技术中使用的机器学习算法。
首先,在基因组学领域,机器学习算法被广泛应用于基因表达数据的分析和预测。
基因表达数据反映了不同基因在特定条件下的表达水平。
这些数据量庞大,传统的统计方法无法有效处理。
机器学习算法可以通过学习大量的基因表达数据,分析基因与特定生物过程之间的关系,如生物发育、疾病发生等。
常见的机器学习算法包括支持向量机(Support Vector Machine,SVM)、随机森林(Random Forest)和深度学习算法等。
在蛋白质结构预测和功能注释领域,机器学习算法也发挥了巨大的作用。
蛋白质是生物大分子中的重要组成部分,其结构和功能对生物学过程至关重要。
机器学习算法能够通过学习大量已知的蛋白质结构和功能数据,预测未知蛋白质的结构和功能。
这些算法包括支持向量机、神经网络、随机森林等。
通过这些算法,科学家能够准确地预测蛋白质的结构和功能,为药物设计和疾病治疗提供重要的依据。
此外,在医学影像分析和疾病诊断中,机器学习算法也被广泛应用。
医学影像数据具有复杂性和多样性,通过机器学习算法可以实现自动分割、特征提取、病变检测等操作,从而帮助医生进行疾病诊断和治疗决策。
例如,卷积神经网络(Convolutional Neural Network,CNN)可以通过学习大量的医学影像数据,精准地识别和定位病变区域,为医生提供更准确的诊断结果。

机器学习的基础知识点机器学习是一门涉及计算机科学、人工智能和统计学的跨学科领域,它研究如何通过计算机算法使计算机能够从数据中自动学习和改进。
机器学习已经广泛应用于各个领域,例如自然语言处理、图像识别和预测分析等。
本文将介绍机器学习的基础知识点,以帮助读者了解这个领域的基本概念和技术。
一、监督学习监督学习是机器学习的一种常见方法,它通过给算法提供带有标记的训练数据,让算法学习如何预测新的未标记数据的标签。
监督学习的算法可以分为分类和回归两大类。
分类算法用于将数据划分到不同的类别中,而回归算法则用于预测连续值。
1. K近邻算法K近邻算法是一种基本的分类算法,它基于实例的学习方法。
该算法会根据离未标记数据最近的K个已标记数据的标签来判断未标记数据的类别。
2. 决策树决策树是一种基于树结构的分类算法。
它通过一系列的判断条件来对数据进行分类。
决策树的每个节点代表一个判断条件,而每个叶子节点代表一个类别。
3. 朴素贝叶斯分类器朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法。
它假设属性之间是相互独立的,在给定已标记数据的情况下,通过计算后验概率来判断未标记数据的类别。
4. 支持向量机支持向量机是一种二分类算法,它通过将数据映射到高维空间来找到一个最大间隔的超平面,以实现对数据的分类。
二、无监督学习无监督学习是另一种常见的机器学习方法,它不依赖于带有标记的训练数据,而是通过对数据的结构和特征进行分析和挖掘,来学习数据的隐藏模式和结构。
1. 聚类聚类是一种无监督学习的算法,它将数据集划分为具有相似特征的不同组(簇)。
聚类算法通过衡量数据之间的相似性来确定簇的个数和样本的分配。
2. 关联规则学习关联规则学习用于挖掘数据项之间的关联关系。
该算法通过发现频繁项集和强关联规则来揭示数据中的隐藏模式。
三、深度学习深度学习是机器学习的一个分支,它以人工神经网络为基础,通过多层次的非线性变换来实现从数据中学习和提取特征。
深度学习已经在图像识别、语音识别和自然语言处理等领域取得了显著的成果。
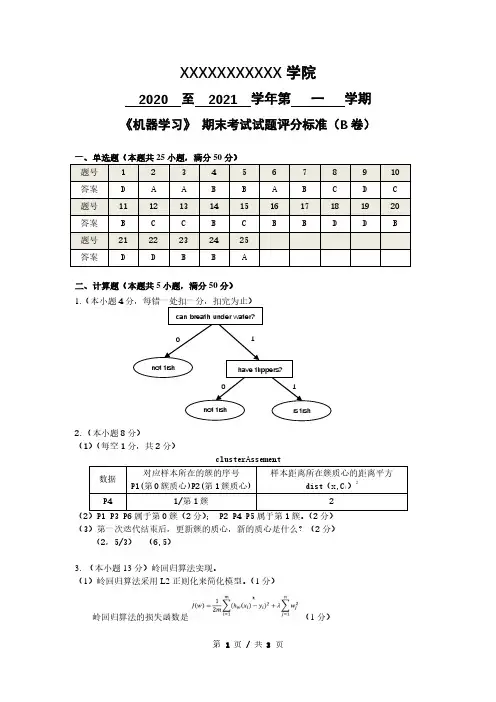
XXXXXXXXXXX 学院2020 至 2021 学年第 一 学期《机器学习》 期末考试试题评分标准(B 卷)一、单选题(本题共25小题,满分50分) 题号 1 2 3 4 5 6 7 8 9 10 答案 D A A B B A B C D C 题号 11 12 13 14 15 16 17 18 19 20 答案 B C C B C B B D D B 题号 21 22 23 24 25 答案DDBBA二、计算题(本题共5小题,满分50分) 1.(本小题4分,每错一处扣一分,扣完为止)2.(本小题8分) (1)(每空1分,共2分)clusterAssement数据 对应样本所在的簇的序号P1(第0簇质心)P2(第1簇质心)样本距离所在簇质心的距离平方dist (x,C i )2P41/第1簇2(2)P1 P3 P6属于第0簇(2分); P2 P4 P5属于第1簇。
(2分) (3)第一次迭代结束后,更新簇的质心,新的质心是什么?(2分) (2,5/3) (6,5)3. (本小题13分)岭回归算法实现。
(1)岭回归算法采用L2正则化来简化模型。
(1分)岭回归算法的损失函数是(1分)can breath under water?have flippers?not fishnot fishis fish0 11(2)(1分)(3)(10分)def ridgeRegres(xArr, yArr, lam):xMat = np.mat(xArr) (1分)yMat = np.mat(yArr).T(1分)xTx = xMat.T * xMat (1分)denom = xTx + np.eye(np.shape(xMat)[1]) * lam(2分)if np.linalg.det(denom) == 0.0: (1分)print(“矩阵为奇异矩阵,不能求逆") (1分)return (1分)ws = denom.I * (xMat.T * yMat) (1分)return ws (1分)4. (本小题15分)(1)写出KNN算法思想的基本步骤。

《机器学习导论》题集一、选择题(每题2分,共20分)1.以下哪个选项不是机器学习的基本类型?A. 监督学习B. 无监督学习C. 强化学习D. 深度学习2.在监督学习中,以下哪个选项是标签(label)的正确描述?A. 数据的特征B. 数据的输出结果C. 数据的输入D. 数据的预处理过程3.以下哪个算法属于无监督学习?A. 线性回归B. 逻辑回归C. K-均值聚类D. 支持向量机4.在机器学习中,过拟合(overfitting)是指什么?A. 模型在训练集上表现很好,但在新数据上表现差B. 模型在训练集上表现差,但在新数据上表现好C. 模型在训练集和新数据上表现都很好D. 模型在训练集和新数据上表现都差5.以下哪个选项不是交叉验证(cross-validation)的用途?A. 评估模型的泛化能力B. 选择模型的超参数C. 减少模型的训练时间D. 提高模型的准确性6.在梯度下降算法中,学习率(learning rate)的作用是什么?A. 控制模型训练的迭代次数B. 控制模型参数的更新速度C. 控制模型的复杂度D. 控制模型的训练数据量7.以下哪个激活函数常用于神经网络中的隐藏层?A. Sigmoid函数B. Softmax函数C. ReLU函数D. 线性函数8.以下哪个选项不是决策树算法的优点?A. 易于理解和解释B. 能够处理非线性数据C. 对数据预处理的要求不高D. 计算复杂度低,适合大规模数据集9.以下哪个评价指标适用于二分类问题?A. 准确率(Accuracy)B. 召回率(Recall)C. F1分数(F1 Score)D. 以上都是10.以下哪个算法属于集成学习(ensemble learning)?A. 随机森林B. K-近邻算法C. 朴素贝叶斯D. 感知机二、填空题(每空2分,共20分)1.在机器学习中,数据通常被分为训练集、_______和测试集。
2._______是一种常用的数据预处理技术,用于将数值特征缩放到一个指定的范围。

贝叶斯机器学习贝叶斯机器学习是计算机科学中一个新兴的研究领域,它的目的是使用统计技术来构建模型,以改善机器学习任务的性能。
贝叶斯机器学习是基于以下两个基本假设:(1)事件的未知概率可以通过概率分布表示;(2)可以根据新数据来更新概率分布,以改进预测。
贝叶斯机器学习的核心方法是贝叶斯定理,这是一个关于随机事件的统计原理,可以用来更新发生某个事件的可能性分布,以改善预测能力。
贝叶斯定理可以用来推断未知概率,并且可以帮助我们更好地理解我们的数据和解决问题。
贝叶斯机器学习的基本思想是:在给定的模型参数的情况下,对观测数据进行估计,我们可以改进模型的表现。
贝叶斯机器学习的应用包括贝叶斯决策理论、贝叶斯回归、贝叶斯聚类、无监督学习、贝叶斯推断,等等。
最近,贝叶斯机器学习也被广泛应用于深度学习,因为它可以帮助机器学习系统自动上手新数据集,从而改善模型性能。
贝叶斯机器学习的优势在于它能够为模型提供可衡量的不确定性,因此在机器学习任务中有更多的利用空间。
它可以更好地表达非线性问题,并且可以帮助机器学习系统更好地处理异常值和缺失值。
因此,贝叶斯机器学习在提高机器学习系统性能方面发挥着重要作用。
虽然贝叶斯机器学习有许多优势,但是也有一些局限性。
主要的问题是,贝叶斯模型假定概率分布是一个确定的分布,实际上它可能并不是一个确定的分布。
此外,贝叶斯模型的构建和训练通常需要相当大的数据量,而许多实际问题的数据量往往比较小,因此贝叶斯模型的构建和训练可能会遇到困难。
总的来说,贝叶斯机器学习是一个广泛应用的机器学习研究领域,它可以帮助我们更好地理解数据,并改善机器学习系统的性能。
贝叶斯机器学习在深度学习、计算机视觉和自然语言处理等方面发挥着重要作用,它将在未来机器学习领域发挥更大的作用。

机器学习中常用的数据集及其收集方法机器学习是计算机科学的一个子领域,它研究如何让计算机可以自动学习,从而可以完成一些复杂的任务。
而在机器学习中,数据集是非常重要的一环,因为它决定了机器学习算法的训练效果。
在本文中,我们将介绍一些常用的数据集以及它们的收集方法。
一、图像数据集1、MNIST手写数字数据集MNIST手写数字数据集包含了6万张训练图像和1万张测试图像,每张图像大小为28x28像素。
每个数字都由单个灰度图像组成,图像标签为0到9的数字。
这个数据集通常用来训练图像分类算法,并且已经成为了机器学习领域的一个标准数据集。
2、CIFAR图像数据集CIFAR是加拿大大学计算机科学教授Alex Krizhevsky等人创建的一个图像分类数据集。
该数据集分为两个版本,分别为CIFAR-10和CIFAR-100。
CIFAR-10包含10个类别,每个类别有6000张32x32的彩色图像。
CIFAR-100包含100个类别,每个类别有600张图像。
这个数据集被广泛用于图像分类的研究和训练。
二、文本数据集1、IMDB电影评论数据集IMDb是全球最大的电影数据库之一,其中的电影评论数据集是一个非常著名的数据集,它包含了50,000条电影评论,每条评论都被标记为正面或负面。
用于文本分类算法的训练。
2、20 Newsgroups数据集20 Newsgroups数据集包含了20个不同主题的新闻组文章,每个主题有数百篇文章。
这个数据集被广泛用于文本分类算法的研究和训练。
三、语音数据集1、TIMIT语音数据集TIMIT数据集是一个美国国家标准技术研究所发布的语音数据库,它包含了多种语言和方言的语音,在目前的语音识别系统中被广泛使用。
2、VOXCELEB语音数据集VOXCELEB是一个包含了数万条发音不同的名人语音样本的数据集。
它可以用于语音识别、语音情感识别、及语音转换等。
四、收集数据集的方法1、数据爬虫数据爬虫是一种自动化工具,它可以从网站或其他资源中抓取数据。
近年来,生物信息学领域的迅速发展使得研究人员能够更好地理解生物系统的复杂性。
在生物信息学研究中,大量的生物数据需要进行分析和解释,而机器学习技术的应用为这一过程提供了新的可能性。
本文将探讨如何利用机器学习技术进行生物信息学数据分析,以及机器学习在生物信息学研究中的应用。
一、生物信息学数据的特点生物信息学数据通常具有高维度、复杂性和多样性的特点。
例如,基因组学数据包括基因序列、基因表达数据和遗传变异等多种类型的信息。
传统的统计学方法在处理这些数据时往往面临着维度灾难和复杂度问题,而机器学习技术可以通过建立模型来发现数据中的规律和模式,为生物信息学研究提供了新的解决方案。
二、机器学习在生物信息学中的应用在生物信息学研究中,机器学习技术被广泛应用于基因组学、蛋白质组学和代谢组学等领域。
例如,基于机器学习的基因表达数据分析可以帮助研究人员识别潜在的生物标志物和基因调控网络,从而揭示疾病发生和发展的机制。
此外,机器学习算法还可以用于生物序列分析、蛋白质结构预测和代谢物组学数据解释等方面,为生物信息学研究提供了强大的工具支持。
三、常用的机器学习算法在生物信息学数据分析中,常用的机器学习算法包括支持向量机(SVM)、随机森林(Random Forest)、深度学习(Deep Learning)和贝叶斯网络等。
这些算法具有不同的特点和适用范围,研究人员可以根据具体的数据类型和研究目的选择合适的算法进行分析和建模。
四、生物信息学数据分析的挑战和发展趋势尽管机器学习技术在生物信息学数据分析中取得了显著的进展,但仍然面临着一些挑战。
例如,生物信息学数据的质量和标注问题、样本量不足和数据集偏差等都会影响机器学习模型的性能和稳定性。
未来,研究人员需要进一步开发新的机器学习算法和工具,以应对生物信息学数据分析中的挑战,并不断提升分析的准确性和可靠性。
综上所述,机器学习技术在生物信息学数据分析中扮演着重要的角色,为研究人员提供了强大的工具和方法来探索生物系统的复杂性。
生物信息学是一个跨学科的领域,涵盖生物学、计算机科学、统计学等多个学科。
随着生物技术的不断发展,生物信息学数据的规模也越来越庞大,而传统的数据分析方法已经无法满足对大规模数据的处理和分析需求。
机器学习作为一种强大的数据分析工具,正在被广泛应用于生物信息学领域。
本文将介绍如何利用机器学习进行生物信息学数据分析。
一、机器学习在生物信息学中的应用机器学习是一种通过数据训练模型,使其具有预测能力的技术。
在生物信息学中,机器学习可以用于基因组学、蛋白质组学、代谢组学等多个方面。
例如,基因组学数据中包含大量的基因表达、DNA序列等信息,通过机器学习算法可以挖掘出基因之间的相互作用关系,发现新的基因功能等。
在蛋白质组学研究中,机器学习可以用于预测蛋白质的结构和功能,识别蛋白质相互作用。
在代谢组学中,机器学习可以帮助鉴定代谢产物,分析代谢通路等。
二、机器学习算法在生物信息学数据分析中的应用在生物信息学数据分析中,常用的机器学习算法包括支持向量机、随机森林、深度学习等。
支持向量机是一种用于分类和回归分析的算法,在生物信息学中常用于基因表达数据的分类和预测。
随机森林是一种集成学习方法,可以用于基因的特征选择、分类和回归分析。
深度学习是一种神经网络算法,可以用于图像识别、序列分析等。
这些算法在生物信息学数据分析中发挥着重要的作用,可以帮助研究人员从庞大的数据中挖掘出有意义的信息。
三、机器学习在生物信息学数据分析中的挑战尽管机器学习在生物信息学数据分析中具有巨大的潜力,但也面临着一些挑战。
首先,生物信息学数据通常具有高维度、复杂性和噪声干扰,这给机器学习算法的训练和预测带来了困难。
其次,生物信息学数据的规模巨大,需要大量的计算资源和时间进行处理和分析。
此外,生物信息学数据往往是非平衡的,即正例和负例的样本数量差异很大,这也给机器学习算法的训练和预测带来了挑战。
四、如何利用机器学习进行生物信息学数据分析为了克服机器学习在生物信息学数据分析中面临的挑战,研究人员可以采取一些策略。
机器学习在农业领域的应用研究随着科技的不断发展,机器学习技术被越来越广泛地应用在不同领域中。
其中,农业领域也逐渐开始探索机器学习技术在提高农业生产效率和质量方面的应用研究。
本文将探讨机器学习在农业领域的应用及其研究进展。
一、机器学习在农业领域中的应用1、农业机器人随着人们对高效农业生产的需求不断提高,农业机器人逐渐成为提高农业生产效率不可或缺的一种工具。
通过机器学习技术,农业机器人可以快速准确地检测作物的生长情况,及时发现病虫害,进行无损检测,提高农业生产效率。
2、农作物预测通过机器学习技术,可以对土壤反应、气象条件、农作物类型等因素进行分析和建模,从而预测农作物的产量及发展趋势。
这样可以为农民提供更加准确的信息,帮助他们更好地管理自己的农田。
3、减少农作物损失农作物在生长过程中可能会受到自然灾害、病虫害、气候变化等因素的影响,导致农作物大量损失。
但通过机器学习技术,可以对这些因素进行预测和分析,及时采取措施,减少农作物损失。
4、农产品分类及质量诊断机器学习技术还可以用于农产品分类及质量诊断。
通过对农产品外形、大小、颜色、硬度等多个因素进行数据采集和分析,可以建立起精准有效的诊断模型,帮助农民实现快速高效的农产品分类与质量诊断。
二、机器学习在农业领域的研究进展近年来,机器学习在农业领域的应用与研究持续快速发展。
目前,主流的机器学习技术主要包括神经网络(NN)、支持向量机(SVM)、随机森林(RF)和卷积神经网络(CNN)等。
同时,在机器学习技术的应用过程中,也面临着一些挑战。
例如,由于农业领域的数据集较小,导致很难建立起具有较高精度的模型,同时数据的标注和采集也存在一定的难度。
为了克服这些挑战,研究者们也提出了一些新的方法和技术。
例如,采用半监督学习的方式对数据集进行扩充,同时结合专家系统和机器学习等多种方法建立起精准有效的诊断模型,提高农业生产效率和质量。
三、结论随着机器学习技术的不断发展和成熟,在农业领域中,机器学习技术也将会被越来越广泛地应用。
机器学习的基本原理解析机器学习(Machine Learning)是一门涉及人工智能和数据科学的领域,通过让计算机系统从数据中学习和改进,以实现任务的自主完成。
在这篇文章中,我们将深入探讨机器学习的基本原理。
一、什么是机器学习机器学习是一种使计算机系统从经验中学习的方法,而无需显式编程指令。
它通过数据驱动的方式,让计算机系统从输入数据中提取规律,并据此进行预测和决策。
机器学习的主要任务包括分类、回归、聚类和推荐等。
在机器学习的过程中,我们需要提供带有标签的训练数据,通过算法模型对这些数据进行训练,使其能够自动推广到未标记数据。
机器学习的核心目标是改善计算机系统的性能,使其可以适应不断变化的环境和任务。
二、监督学习与无监督学习机器学习可以分为监督学习和无监督学习两种类型。
1. 监督学习监督学习是指训练集中的样本都有相应的标签,算法模型通过学习有标签数据的规律,实现对未标记数据的预测和分类。
常见的监督学习算法包括决策树、支持向量机和神经网络等。
2. 无监督学习无监督学习是指训练集中的样本没有标签信息,算法模型通过对数据的相似性、关联性等进行分析和聚类,从而发现数据中的隐藏规律和结构。
常见的无监督学习算法包括聚类分析、关联规则挖掘和降维等。
三、机器学习的主要算法机器学习涵盖了多种算法和技术,下面介绍几种常见的机器学习算法。
1. 决策树决策树是一种用于分类和回归问题的可视化模型。
它通过将数据集划分为不同的决策条件,以生成类别标签或连续数值的预测结果。
决策树算法简单直观,易于解释和理解,常用于需要可解释性的任务。
2. 支持向量机支持向量机是一种基于统计学习理论的分类和回归算法。
它通过将数据映射到高维空间,找到一个最优的超平面来实现分类或回归。
支持向量机适用于小样本、高维空间和非线性问题。
3. 神经网络神经网络是一种模仿人脑神经元结构和功能的计算模型。
它由多层神经元组成,通过正向传播和反向传播算法进行训练和优化。
基于机器学习的农产品产量预测技术研究近年来,随着机器学习技术的不断发展和应用,农业领域也开始涌现出了各种基于机器学习的预测技术。
这些技术可以帮助农民预测农产品产量、天气变化、病虫害预防等方面,大大提高了农业生产效率,减少了农业损失。
本文主要探讨基于机器学习的农产品产量预测技术,介绍其原理和应用情况,并对其未来发展进行展望。
一、技术原理基于机器学习的农产品产量预测技术主要是通过对历年来的农产品产量数据、天气、肥料、灌溉等多种因素进行分析和学习,从而预测出接下来的农产品产量。
常用的机器学习算法包括决策树、随机森林、神经网络、支持向量机等。
其中,决策树是一种基于树形结构的分类或回归模型。
在农产品产量预测中,决策树可以通过对历史数据的学习,构建出一颗决策树,该树的每个节点代表一个特征变量,每条路径代表一种可能的决策结果。
随机森林(Random Forest)依托多个决策树,通过投票的方式得到最终的预测结果。
与单个决策树相比,随机森林具有更高的准确性和鲁棒性,尤其适用于大规模的数据集。
神经网络(Neural Network)是一种基于生物神经网络的学习算法,通过多层神经元的连通和不同层之间的权重来自适应地拟合训练数据。
在农产品产量预测中,神经网络可以通过对历年数据的分析和训练,构建出一个多层神经网络,从而预测出未来的产量。
支持向量机(Support Vector Machine)是一种分类或回归算法,其基本思想是将输入空间中的数据映射到高维空间中,然后在高维空间中寻找一个分割超平面来实现分类或回归。
在农产品产量预测中,支持向量机可以通过对历年数据的学习,构建出一个超平面,从而进行产量预测。
二、技术应用目前,基于机器学习的农产品产量预测技术已经开始广泛应用于各种农业领域。
其应用范围涵盖了大豆、小麦、玉米、水稻、棉花、果树等多个作物。
在大豆产量预测方面,研究人员通过分析历年来大豆的种植面积、气温、降雨量等因素,建立了一个基于随机森林的预测模型。
机器学习工作原理解析机器学习是一种人工智能的分支,它通过让计算机系统从数据中学习和改进,而不是通过明确的编程来实现特定任务。
机器学习的工作原理涉及到数据的收集、特征提取、模型训练和预测等多个环节。
本文将对机器学习的工作原理进行详细解析。
一、数据收集在机器学习中,数据是至关重要的。
数据的质量和数量直接影响到机器学习算法的性能和准确度。
数据可以从多个渠道收集,例如传感器、数据库、社交媒体等。
收集到的数据需要经过清洗和预处理,以去除噪声和异常值,确保数据的准确性和一致性。
二、特征提取在机器学习中,特征是描述数据的属性或特性。
特征提取是将原始数据转化为可用于机器学习算法的特征向量的过程。
特征提取的目标是选择和提取对目标任务有用的特征,并且减少特征的维度,以提高算法的效率和准确度。
常用的特征提取方法包括主成分分析(PCA)、线性判别分析(LDA)等。
三、模型训练在机器学习中,模型是通过训练数据得到的,它可以对未知数据进行预测和分类。
模型训练是指通过使用已有的数据集来调整模型的参数,使其能够更好地拟合数据,并能够在未知数据上进行准确的预测。
常用的机器学习算法包括决策树、支持向量机(SVM)、神经网络等。
训练过程中需要选择合适的损失函数和优化算法来调整模型的参数。
四、预测和评估在模型训练完成后,可以使用训练好的模型对未知数据进行预测和分类。
预测过程是将输入数据通过模型映射到输出空间的过程。
预测结果可以根据任务的不同进行解释和评估。
常用的评估指标包括准确率、精确率、召回率等,用于衡量模型的性能和准确度。
五、模型优化在机器学习中,模型的优化是指通过调整模型的参数或改进算法来提高模型的性能和准确度。
模型优化可以通过调整超参数、增加训练数据、改进特征提取方法等方式来实现。
优化过程需要进行实验和验证,以找到最佳的参数设置和算法配置。
六、应用领域机器学习的应用领域非常广泛,包括自然语言处理、图像识别、推荐系统、金融风控等。
Villages Data(Bilkent大学村庄数据)
数据摘要:
Concerns informattion about villages belong to a Center Anatolian province.
中文关键词:
村庄,安纳托利亚,省,土耳其,
英文关键词:
Village,Anatolian,province,Turkey,
数据格式:
TEXT
数据用途:
For the research and analysis.
数据详细介绍:
Villages Data
1. Title: Villages Data
2. Sources:
(a) Original Source: This dataset was taken from the Turkish Government Officials.
(b) Year: 1999
3. Relevant Information:
Concerns informattion about villages belong to a Center Anatolian province.
4. Number of Instances: 766 (Each instance is a different village)
5. Number of Attributes: 28 continuous attributes (excluding "class" attribute "SHEEP"), 3 categorical attributes.
6. Attribute Information:
1. DISTRICT District ID. (CATEGORICAL)
2. SETTLE Number of conneced settlements.
3. DISTP Distance to the center of province.
4. DISTD Distance to the center of district.
5. CLASR Number of total classrooms in primary schools.
6. STDB Number of students (boys).
7. STDG Number of students (girls).
8. TEACHER Number of teachers.
9. HOUSET Number of houses separated for teachers.
10. MIDSCH Number of middle schools.
11. ASPHALT Total lengt of asphalt roads. (KM)
12. STAB Total lengt of stabilized roads. (KM)
13. WATERD Drinking Water System. (1 if exists, or 0 otherwise)
14. WATERC Drinking water condition.
15. FOUNT Number of fountains.
16. HEALTH Number of health houses.
17. CLINIC Number of village clinics.
18. MANSION Number of village mansions.
19. CANAL Canalization network.
20. LAUND Number of laundaries.
21. TOIL Number of public toilets.
22. AGRICA Agricultural area. (One-tenth of a hectare)
23. TRACTOR Number of tractors.
24. COW Number of cows.
25. BEEHIVE Number of beehives.
26. ELECTR Electric network.
27. MOSQUE Number of mosques.
28. POST Post office.
29. GUARD Number of village guards.
30. SETTLEP Settlement plan. (1 if exists, or 0 otherwise)
31. CENTER Belong to the center of province. (1 if belongs, or 0 otherwise)
32. POPUL Population.
33. SHEEP Number of sheep. (TARGET ATTRIBUTE)
数据预览:
点此下载完整数据集。