Creating New CPU Schedulers with Virtual Time
- 格式:pdf
- 大小:45.20 KB
- 文档页数:4

华为突破技术封锁自主研发芯片英语作文Huawei Breaks Through Technology Blockade withSelf-developed ChipsWith the advancement of technology and the increasing competition in the global market, the issue of technological blockade has become more prominent. In recent years, Huawei, a leading global provider of information and communications technology (ICT) infrastructure and smart devices, has continuously faced technological challenges and restrictions. However, Huawei has successfully broken through the technology blockade by developing its own chips.In the face of the technology blockade, Huawei has invested heavily in research and development to develop its own chips. The company has established a strong research and development team comprised of experts in various fields, including chip design, semiconductor technology, and artificial intelligence. Through their collaborative efforts, Huawei has successfully developed a series of cutting-edge chips that have not only improved the performance of its products but also reduced its dependence on foreign suppliers.One of the key achievements of Huawei in breaking through the technology blockade is the development of its Kirin series of chips. The Kirin chips are designed to provide superior performance, energy efficiency, and security for Huawei's smartphones, tablets, and other devices. By using its own chips, Huawei has been able to optimize the performance of its devices and deliver a better user experience to its customers.In addition to the Kirin chips, Huawei has also developed its own Kunpeng and Ascend series of chips for its server and artificial intelligence products. The Kunpeng chips are designed to provide high-performance computing capabilities for Huawei's server products, while the Ascend chips are designed to provide advanced AI processing capabilities for Huawei's AI products. By developing its own chips, Huawei has been able to expand its product offerings and compete more effectively in the global market.Overall, Huawei's success in breaking through the technology blockade with its self-developed chips is a testament to the company's innovation and determination. By investing in research and development and fostering a culture of continuous improvement, Huawei has been able to overcome the technological challenges it faces and emerge as a global leaderin the ICT industry. As Huawei continues to develop new technologies and products, it is poised to further strengthen its position in the global market and drive innovation in the ICT industry.。

虚拟化性能调优之cpu篇CPU优化分析主要是两个阶段,虚拟化层和宿主机层。
前期主要怀疑是虚拟化层的影响,主要的怀疑点包括:1.超线程的影响关闭超线程之后单核性能有略微提升,但多核性能反而更差,排除超线程的因素2.NUMA架构和核迁移的影响按理说如果不按照NUMA的架构来做核绑定,由于缓存和迁移的影响,或造成较大的性能损失,通过绑定物理核测试发现并没有大的提升,排除该因素3.CPU模式的影响,包括指令集和缓存分析与vmware的差异,发现我们的指令集和cpu缓存与真实物理机不一致,通过cpu-passthrough和替换qemu版本将host cpu的特性透传仍然无法提升cpu性能排除了虚拟化层的影响,后来测试发现宿主机本身才是cpu性能的关键,部署了一个redhat对比环境发现宿主机跑分和redhat未经调优过系统差距很大。
分析了内核配置参数差异(sysctl)和编译参数差异,没有发现可疑的地方。
决定内核行为的并且用户可以干预的只剩下启动参数了,对比发现系统关闭了intel的cstate功能。
写了一个简单的死循环测试对比两个系统的表现,发现redhat内核有负载的cpu频率可以提高到3.1GHz,而当前host机只能达到2.6GHz,即使调整了cpufreq的模式为performance也无法让cpu达到更高的主频。
所以基本可以确认是这个参数导致的。
打开系统中cstate功能,跑speccpu可以达到和redhat类似的性能分数。
解决措施:目前发现cstate功能和调频功能有耦合,需要使能cstate 来解决cpu性能问题,去掉启动参数intel_idle.max_cstate=0 idle=pollintel cpu调频和节能相关的几个机制简介:cpufreq:提供频率调节功能,可以让cpu根据不同负载使用不同的频率,达到性能和功耗的动态可调整,服务器一般配置为performance,个人pc可以配置为ondemand或者powersave模式cstate:cpu深度睡眠节能模式,根据cpu睡眠器件,定义了多种睡眠状态,提供不同程度的节能选择,睡眠模式越高,唤醒代价越大。

MELSOFT-Software – GX IEC Developer Powerful integrated programming toolsGX IEC Developer is more than a powerful IEC 1131.3 programming and documenation package. It supports your entire MELSEC PLC impleentation from the initial project planning to everyday operation, with a wealth of advanced functions that will help you to cut costs and increase your productivity.The sophisticated program architecture comes with a range of new, user-friendly functions, including structured programming and support for function libraries.Top-down application architectureDuring the planning phase GX IEC Developer's structuring tools help you to organise your project efficiently: Use the intuitive graphical tools to identify and display tasks, functional units, dependencies, procedures and application structures. In addition to making your work easier, this also significantly reduces error frequency in later project stages.Flexible implementationIn the engineering phase you then choose the programming language that best matches the structure of your project.Program frequently-used functions in function blocks and organise them in libraries. This gives you the confidence that comes with knowing you are using tested, reliable code. Password support helps you to protect your valuable expertise.Simple configuration of control componentsConfiguration of controller components is performed quickly and efficiently in tables with interactive dialogs and graphical support. And this powerful support is available for standard and special function modules as well as for the controller CPUs. You no longer have to create application programs to configure your system.Setting up the hardware and network configuration Powerful testing and debugging tools provide information on the current status of the controllers and the network you are connected to. Network functions like status and error displays, remote SET/RST functions for controllers and peripherals, Live List, Cycle Time, Connection State and more enable you to locate and correct errors quickly and get your hardware and networks up and running in record time.Setting up the application programGX IEC Developer comes with everything you need to get your applications installed, set up and running as quickly as possible, including comprehensive online programming functions, fast and informative monitoring displays, the ability to manipulate device values with the graphical editors, manual and automatic step mode execution in IL, the display of manipulated device values in the EDM (Entry Data Monitor) and much more.Normal operationDuring normal daily operation you can also use GX IEC Developer to display important system status information, either in stand-alone mode or called by another program in the control room.Installation and maintenanceTop-down architecture, structured programming, comprehensive printed documentation and support for user-defined help for your function blocks all help to reduce the learning curve. You can make the information needed for installing and maintaining the system available to the operators quickly and efficiently, with minimum training overheads.Key features include:•Powerful "Top-down" development environment•Total overview of PLC project and resources•Suited to large and complex projects•One programming software for modular and compact PLCs (Q/A and FX Series) •Flexible program development•Superior program documentation for easy understanding•State-of-the-art PC software technology acc. to IEC 1131.3•Programming languages FBD, AWL, KOP, AS and STC•Powerful offline simulation•Online program modification•Function blocks (FB, FC)•Libraries Minimum downtimes。

Introduction to Dynamic Parallelism Stephen JonesNVIDIA CorporationImproving ProgrammabilityDynamic Parallelism Occupancy Simplify CPU/GPU Divide Library Calls from Kernels Batching to Help Fill GPU Dynamic Load Balancing Data-Dependent ExecutionRecursive Parallel AlgorithmsWhat is Dynamic Parallelism?The ability to launch new grids from the GPUDynamicallySimultaneouslyIndependentlyCPU GPU CPU GPU Fermi: Only CPU can generate GPU work Kepler: GPU can generate work for itselfWhat Does It Mean?CPU GPU CPU GPU GPU as Co-ProcessorAutonomous, Dynamic ParallelismData-Dependent ParallelismComputationalPower allocated toregions of interestCUDA Today CUDA on KeplerDynamic Work GenerationInitial GridStatically assign conservativeworst-case gridDynamically assign performancewhere accuracy is requiredFixed GridCPU-Controlled Work Batching CPU programs limited by singlepoint of controlCan run at most 10s of threadsCPU is fully consumed withcontrolling launchesCPU Control Threaddgetf2 dgetf2 dgetf2CPU Control Threaddswap dswap dswap dtrsm dtrsm dtrsmdgemm dgemm dgemmCPU Control ThreadMultiple LU-Decomposition, Pre-KeplerCPU Control ThreadCPU Control ThreadBatching via Dynamic ParallelismMove top-level loops to GPURun thousands of independent tasksRelease CPU for other workCPU Control ThreadCPU Control ThreadGPU Control Threaddgetf2 dswap dtrsm dgemm GPU Control Thread dgetf2 dswap dtrsm dgemm GPU Control Threaddgetf2dswapdtrsmdgemmBatched LU-Decomposition, Kepler__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }Programming Model BasicsCode ExampleCUDA Runtime syntax & semantics__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }Code ExampleCUDA Runtime syntax & semanticsLaunch is per-thread__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }Code ExampleCUDA Runtime syntax & semanticsLaunch is per-threadSync includes all launches by any thread in the block__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }CUDA Runtime syntax & semanticsLaunch is per-threadSync includes all launches by any thread in the blockcudaDeviceSynchronize() does not imply syncthreadsCode Example__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }Code ExampleCUDA Runtime syntax & semanticsLaunch is per-threadSync includes all launches by any thread in the blockcudaDeviceSynchronize() does not imply syncthreadsAsynchronous launches only__device__ float buf[1024];__global__ void dynamic(float *data) {int tid = threadIdx.x; if(tid % 2)buf[tid/2] = data[tid]+data[tid+1]; __syncthreads();if(tid == 0) {launch<<< 128, 256 >>>(buf); cudaDeviceSynchronize(); }__syncthreads();cudaMemcpyAsync(data, buf, 1024); cudaDeviceSynchronize(); }Code ExampleCUDA Runtime syntax & semanticsLaunch is per-threadSync includes all launches by any thread in the blockcudaDeviceSynchronize() does not imply syncthreadsAsynchronous launches only(note bug in program, here!)__global__ void libraryCall(float *a,float *b, float *c) {// All threads generate datacreateData(a, b);__syncthreads();// Only one thread calls library if(threadIdx.x == 0) {cublasDgemm(a, b, c);cudaDeviceSynchronize();}// All threads wait for dtrsm__syncthreads();// Now continueconsumeData(c);} CPU launcheskernelPer-block datagenerationCall of 3rd partylibrary3rd party libraryexecutes launchParallel useof resultSimple example: QuicksortTypical divide-and-conquer algorithmRecursively partition-and-sort dataEntirely data-dependent executionNotoriously hard to do efficiently on Fermi3 2 6 3 9 14 25 1 8 7 9 2 58 3 2 6 3 9 1 4 2 5 1 8 7 9 2 58 2 1 2 1 2 36 3 94 5 8 7 9 5 8 3 6 3 4 5 8 7 58 1 2 2 2 3 3 4 1 5 6 7 8 8 9 95 eventually...Select pivot valueFor each element: retrieve valueRecurse sort into right-handsubsetStore left if value < pivotStore right if value >= pivotall done?Recurse sort into left-hand subset NoYes__global__ void qsort(int *data, int l, int r) {int pivot = data[0];int *lptr = data+l, *rptr = data+r;// Partition data around pivot valuepartition(data, l, r, lptr, rptr, pivot);// Launch next stage recursively if(l < (rptr-data))qsort<<< ... >>>(data, l, rptr-data); if(r > (lptr-data))qsort<<< ... >>>(data, lptr-data, r); }。


进程绑定多核运行名词CPU affinity:中文称作“CPU亲和力”,是指在CMP架构下,能够将一个或多个进程绑定到一个或多个处理器上运行。
一、在Linux上修改进程的“CPU亲和力”在Linux上,可以通过taskset命令进行修改。
运行如下命令可以安装taskset工具。
在CentOS/Fedora 下安装schedutils:# yum install schedutils在Debian/Ubuntu 下安装schedutils:# apt-get install schedutils如果正在使用CentOS/Fedora/Debian/Ubuntu 的最新版本的话,schedutils/util-linux 这个软件包可能已经装上了。
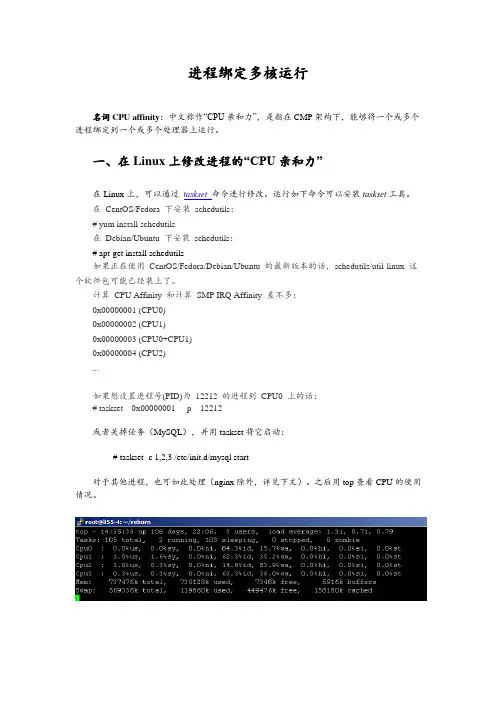
计算CPU Affinity 和计算SMP IRQ Affinity 差不多:0x00000001 (CPU0)0x00000002 (CPU1)0x00000003 (CPU0+CPU1)0x00000004 (CPU2)...如果想设置进程号(PID)为12212 的进程到CPU0 上的话:# taskset 0x00000001 -p 12212或者关掉任务(MySQL),并用taskset将它启动:# taskset -c 1,2,3 /etc/init.d/mysql start对于其他进程,也可如此处理(nginx除外,详见下文)。
之后用top查看CPU的使用情况。
二、配置nginx绑定CPU刚才说nginx除外,是因为nginx提供了更精确的控制。
在conf/nginx.conf中,有如下一行:worker_processes 1;这是用来配置nginx启动几个工作进程的,默认为1。
而nginx还支持一个名为worker_cpu_affinity的配置项,也就是说,nginx可以为每个工作进程绑定CPU。
我做了如下配置:worker_processes 3;worker_cpu_affinity 0010 0100 1000;这里0010 0100 1000是掩码,分别代表第2、3、4颗cpu核心。

systemd cpuquota 原理全文共四篇示例,供读者参考第一篇示例:Systemd是目前Linux系统中最流行的初始化系统之一,它被设计用来管理系统的启动进程以及后台服务。
Systemd提供了多种功能,其中就包括CPU配额(CPU quota)的管理。
CPU quota是一种可以限制进程使用CPU资源的技术,它可以帮助系统管理员在多任务环境中更好地管理CPU资源,避免某个进程占用过多的CPU导致系统负载过高。
Systemd通过cgroup(控制组)来管理系统资源,其中就包括CPU资源。
cgroup是Linux内核中的一种机制,它可以将一组进程归类到一个cgroup中,并对这个cgroup中的进程实施资源限制。
Systemd利用cgroup来对进程进行CPU配额的管理。
在Systemd中,可以通过设置CPUQuota字段来定义进程的CPU 配额。
CPUQuota字段的取值茹茹为一个百分比,表示进程在一个时间片内可以使用CPU的百分比。
如果将CPUQuota设置为50%,那么表示该进程在一个时间片内只能使用50%的CPU资源。
Systemd会根据CPUQuota的设置来限制进程的CPU使用。
当一个进程被启动时,Systemd会为这个进程创建一个cgroup,并将该进程归类到这个cgroup中。
然后Systemd根据CPUQuota的设定来对这个cgroup中的进程进行CPU资源的调度。
如果某个进程的CPU使用超出了设定的CPUQuota,Systemd会自动降低这个进程的CPU优先级,以确保其他进程能够正常运行。
这样就可以避免某个进程长时间占用CPU资源而导致其他进程无法运行的情况发生。
Systemd的CPUQuota原理是通过cgroup来管理系统资源,通过设置CPUQuota字段来对进程进行CPU配额限制,从而有效地管理系统中的CPU资源。
通过合理地配置CPUQuota,可以确保系统中的各个进程能够公平地竞争CPU资源,提升系统的性能和稳定性。

nerdctl restart策略nerdctl是一个用于与容器运行时接口(CRI)兼容的容器运行时。
它是Docker CLI的一种替代品,使用类似于Docker CLI的命令进行容器管理。
nerdctl支持包括重启策略在内的各种容器管理功能,为用户提供了更灵活、高效的容器操作体验。
重启策略是指在容器发生故障时,系统如何自动将容器重启起来。
nerdctl支持多种重启策略,可以根据具体情况选择适合的策略来保证容器的高可用性和稳定性。
nerdctl支持的重启策略有以下几种:1. no重启策略:当容器停止时,不会自动重启。
这是默认的重启策略。
2. always重启策略:当容器停止时,会自动重启容器。
这种策略适用于需要保持容器一直运行的场景,比如Web服务器。
3. on-failure重启策略:当容器非正常停止(退出状态码非零)时,会自动重启容器。
可以通过设置--restart flag来指定重启次数,比如--restart=on-failure:5表示在容器失败5次后停止重启。
4. unless-stopped重启策略:容器停止时,除非手动停止容器,否则会自动重启。
这种策略适用于需要容器一直运行,但允许用户手动停止容器的场景。
重启策略是通过在运行容器时使用--restart flag来指定的。
以下是一些使用示例:1.使用no重启策略:```nerdctl run --restart=no my-container```2.使用always重启策略:```nerdctl run --restart=always my-container```3.使用on-failure重启策略:```nerdctl run --restart=on-failure:5 my-container```4.使用unless-stopped重启策略:```nerdctl run --restart=unless-stopped my-container```通过合理选择重启策略,可以在容器发生故障时快速恢复服务,并确保容器的高可用性和稳定性。

mpirun each processor is running a
duplicate job
这个错误提示表明在使用 `mpirun` 运行 MPI 程序时,每个处理器都在运行相同的任务,而不是分配给不同的任务。
这种情况可能发生的原因有以下几种:
1. 你可能在使用 `mpirun` 命令时没有正确指定任务的数量或分配任务给不同的处理器。
请确保你使用正确的参数来指定要运行的任务数量,并将任务分配给不同的处理器。
2. 你的 MPI 程序可能没有正确地实现任务分配。
请检查你的程序代码,确保在初始化阶段正确地分配任务给不同的处理器。
3. 你的 MPI 实现可能存在问题。
尝试使用不同的 MPI 实现(如 OpenMPI、MPICH 等),看看问题是否仍然存在。
4. 你的硬件环境可能存在问题。
检查你的计算机是否支持 MPI 并行计算,并且确保所有的处理器都正常工作。
为了解决这个问题,你可以尝试以下步骤:
1. 检查你的 `mpirun` 命令参数,确保正确指定了任务数量和处理器分配。
2. 检查你的程序代码,确保在初始化阶段正确地分配任务给不同的处理器。
3. 尝试使用不同的 MPI 实现。
4. 检查你的硬件环境。
如果你仍然遇到问题,请提供更多的上下文和错误信息,以便更深入地了解问题所在并给出更具体的解决方案。

virtio gpu 原理virtio gpu是一种虚拟图形处理单元,它通过在虚拟机和宿主机之间建立高效的通信通道,实现了图形加速和渲染功能。
本文将介绍virtio gpu的原理及其在虚拟化环境中的应用。
虚拟化技术的发展使得在一台物理服务器上同时运行多个虚拟机成为可能。
然而,由于图形处理对性能要求较高且复杂,传统的软件模拟方式往往无法满足虚拟机中的图形需求。
为了解决这个问题,virtio gpu应运而生。
virtio gpu的核心思想是将图形处理任务卸载到宿主机的物理GPU 上,通过共享GPU资源来提供图形加速能力。
在虚拟机中安装virtio gpu驱动后,虚拟机可以直接调用该驱动来完成图形任务,而不再需要通过软件模拟的方式来处理图形操作。
这种虚拟化图形加速的方式大大提高了虚拟机的图形性能,并且减轻了宿主机的负担。
virtio gpu的实现依赖于virtio框架,该框架定义了一套通用的设备虚拟化接口。
在virtio gpu中,宿主机中的物理GPU被抽象成一个虚拟设备,虚拟机可以通过virtio接口与宿主机的虚拟设备进行通信。
当虚拟机需要进行图形操作时,它可以向virtio gpu发送相应的命令,并通过virtio接口传输相关数据。
宿主机的virtio gpu驱动收到虚拟机的请求后,将相应的图形任务提交到物理GPU上进行处理,并将结果返回给虚拟机。
在virtio gpu的实现中,采用了一些优化技术来提高性能。
首先,它使用了共享内存机制来加速数据传输,减少了虚拟机和宿主机之间的数据拷贝次数。
其次,它利用了GPU的硬件加速能力,可以在宿主机上进行高效的图形渲染和计算。
此外,virtio gpu还支持多个虚拟机共享同一个物理GPU的资源,提供了更好的资源利用率。
virtio gpu在虚拟化环境中有着广泛的应用。
首先,它可以提供高性能的图形加速能力,使得虚拟机可以运行图形密集型应用,如游戏、图形设计等。
其次,它可以提供虚拟机间的图形隔离,保证多个虚拟机之间的图形操作不会相互干扰。
cpuset策略是一种在Linux内核中用于控制进程CPU和内存分配的机制。
它提供了一种方式,可以将一组CPU和内存节点分配给一组任务,并限制任务的CPU 和内存访问权限。
在cpuset中,CPU集将任务的CPU和内存放置限制为仅任务当前cpuset中的资源。
它们形成虚拟文件系统中可见的嵌套层次结构。
这些是管理大型系统上动态作业放置所需的基本钩子,超出了已经存在的钩子。
任务的请求,使用sched_setaffinity系统调用将CPU包含在CPU关联掩码中,并使用mbind和set_mempolicy系统调用将内存节点包含在内存策略中,都通过该任务的CPU集进行过滤,过滤掉不在CPU集中的任何CPU或内存节点。
调度程序不会在其cpus_allowed向量中不允许的CPU上调度任务,并且内核页面分配器不会在请求任务的mems_allowed向量中不允许的节点上分配页面。
用户级代码可以在cgroup虚拟文件系统中按名称创建和销毁cpuset,管理这些cpuset的属性和权限以及分配给每个cpuset的CPU和内存节点,指定和查询任务分配给哪个cpuset,并列出分配给cpuset的任务pid。
此外,cpuset还支持CPU/内存的热插拔事件(注册通知链),它通过cpuset_track_online_nodes_nb函数检测cpu集的跟踪节点在线状态,当mems_allowed 跟踪node_states[N_MEMORY]发生变化时,调度工作队列cpuset_hotplug_work,处理cpuset的CPU/内存热插拔等相关的变化。
以上信息仅供参考,如需了解更多信息,建议咨询专业人士。
操作系统的CPU虚拟化作者:谭清宽来源:《计算机与网络》2020年第06期对CPU虚拟化的目的之一就是能够同时运行多个进程,实质就是对进程的切换,也就是快速的切换执行多个进程,这样对于用户而言,所有的进程都是同时进行的,但是应该如何让多个进程公平合理并安全高效的运行呢?所以,就出现了很多进程调度算法。
第一个就是最简单的先进先出(FIFO),也可以叫做先到先服务。
这个算法的最大优点就是简单。
没错,就是我们理解的哪个进程先来了,CPU就先处理哪个,等当前的处理结束,再处理下一个。
假设有3个进程,每1个进程处理需要10 s,这时,无论哪个进程先来,最后一个进程的完成时间都是30s,也就是说这种情况下最大完成时间是所有进程需要时间之和。
但是如果同样有3个进程,其中2个进程需要10s,另外1个进程需要100 s,这种情况,最大完成时间就是120 s,由于3个进程的各自完成时间不同,所以根据他们到达的顺序不同最终的影响也有很大差异。
假设3个进程A(10s)、B(10s)、C(100s),如果按照A、B、C的顺序到达,那么执行的过和我们预想的是一样的,开始10 s,A执行结束,20 s后,B执行结束,120 s,C执行结束。
但是如果是按照相反的顺序到达的呢?C、B、A,这样开始100 s后,C执行结束,110s,B执行结束,120 s后,A执行结束。
很显然,这种情况下,B和A都要等待时间最长的C结束才可以执行,所以这个算法的效率根据到达的顺序有很大关系。
显然,这并不是我们想要的。
在这里我们计算一下进程的平均周转时间,当3个进程都需要10s的时候平均周转时间:(10+20+30)/3=20,因为A在第10s完成,B在第20s完成,C在第30 s完成。
大家想一下当进程A、B、C时间分别为10 s,10 s,100 s呢?此时进程的顺序是C、B、A,那么平均周转时间就是:(100+110+120)/3=110。
这是我们不能接受的。
虚拟机内存迁移stop的原理虚拟机内存迁移的stop原理主要包括两个方面:内存页面迁移和上下文切换。
首先,内存页面迁移是指将虚拟机内存中的页面从一台物理主机迁移到另一台物理主机上。
虚拟机内存由多个页面组成,每个页面对应一定大小的内存块。
内存页面迁移可以通过两种方式实现:预复制和全量复制。
预复制方式是指在迁移过程中先复制一部分内存页面到目标主机上的内存,然后再通过增量复制的方式将剩余的内存页面逐步迁移过去。
预复制方式的主要优点是迁移过程中对网络带宽和目标主机内存的需求较低,迁移速度相对较快。
但是预复制可能导致迁移过程中产生一定的性能开销,因为虚拟机在迁移过程中会不停地访问修改的内存页面,从而导致频繁的页面复制。
全量复制方式是指在迁移过程中将所有内存页面一次性复制到目标主机上的内存。
全量复制方式的优点是不会产生频繁的页面复制开销,可以保证数据的一致性。
但是全量复制方式对网络带宽和目标主机内存的需求较高,迁移速度相对较慢。
其次,上下文切换是指将虚拟机的执行上下文从源主机切换到目标主机上。
执行上下文包括虚拟机的CPU寄存器、处理器状态和其他与执行环境相关的信息。
上下文切换需要保存当前虚拟机的执行状态,并将其恢复到目标主机上。
上下文切换的过程中主要包括以下几个步骤:首先,在源主机上暂停虚拟机的执行,保存当前虚拟机的执行状态。
然后,将保存的执行状态传输到目标主机,这需要借助网络通信。
接下来,在目标主机上恢复虚拟机的执行状态,包括恢复CPU寄存器、处理器状态等。
最后,目标主机上的虚拟机重新开始执行。
上下文切换过程中的关键问题是如何在源主机暂停执行和保存执行状态的过程中保持虚拟机的一致性。
为了保证数据的完整性,虚拟机迁移过程中会使用一些技术来解决数据一致性问题,比如使用广播机制通知迁移过程中数据的写入和读取。
虚拟机内存迁移的stop原理在保证迁移过程中数据的一致性和完整性的同时,尽可能地减少对网络带宽和目标主机资源的需求,从而实现快速高效的迁移。
diffusers scheduler原理
Diffusers scheduler是一种用于控制计算机任务调度的算法。
它的原理主要包括以下几个方面:
1. 高优先级任务优先级高并尽快执行:Diffusers scheduler会根据任务的优先级来确定任务的执行顺序,优先级高的任务会被尽快执行。
这样做的目的是确保重要任务的及时完成。
2. 任务分散执行:Diffusers scheduler会将任务尽可能分散到不同的处理器上执行,以提高系统的整体性能。
这样可以避免某些处理器被过多任务占用而导致其他处理器空闲的情况。
3. 避免任务抢占:Diffusers scheduler会根据任务的属性和运行状态来决定是否进行任务抢占。
当一个任务已经在执行,并且没有更高优先级的任务需要执行时,Diffusers scheduler会避免对其进行抢占,以避免频繁的任务切换带来的开销。
4. 周期性任务的处理:对于周期性任务,Diffusers scheduler
会根据其周期和要求,在合适的时间进行调度。
如果周期性任务的执行时间超过了其要求的周期,Diffusers scheduler也会进行适当的调整,以保持任务的正常执行。
总的来说,Diffusers scheduler利用任务的优先级和属性来对任务进行调度,确保高优先级任务优先执行,并尽可能分散任务的执行,以提高系统的整体性能。
同时,它也会避免频繁的任务抢占和适应周期性任务的要求,以保证任务的有效执行。
Creating New CPU Schedulers with Virtual TimeAndy BavierDepartment of Computer Science,Princeton UniversityPrinceton,NJ08544acb@AbstractWe propose a design methodology for producing CPU schedulers with provable real-time behaviors.Our ap-proach is grounded in the well-known technique of using virtual time to track afluid model representation of the sys-tem.However,our work aims to go beyond traditional fair sharing schedulers like Weighted Fair Queueing by laying bare the mathematical foundations of virtual time.We show how arbitrary changes described mathematically to the fair sharingfluid model can be manifested in real time in the running system.The BERT scheduler is presented as an example of how to use our framework.We hope that this work will enable the creation of new and interesting real-time scheduling algorithms.1IntroductionWe propose a methodology for creating complex and dy-namic schedulers with provable real-time properties.The key to our framework is using virtual time to track afluid model representation of the system.Though this technique has clearly been used to design schedulers(e.g.,WFQ in 1989),we believe that a general theory of virtual time has not been elaborated before.In fact,the BERT algorithm[2], which is the prime example of a scheduler designed in ac-cordance with our theory,actually preceded it.First we cre-ated and implemented BERT and convinced ourselves that it worked;the insight about why it worked came later,and led to our methodology.We realized that the steps we took to create BERT could be used to produce any number of real-time scheduling algorithms.Since modifying virtual-time schedulers to change their behaviors has been the subject of recent work[4,6],we hope that others willfind our ap-proach useful.To create a new scheduling algorithm using our method, the designer follows four steps:1.Mathematically describe changes to how processes ex-ecute in the fair queueingfluid model2.Track thefluid model changes using virtual time3.Modify the virtual timestamps of affected tasks4.Execute the task set in order of increasing stampsThe rest of this paper summarizes what is involved at each step.We use the BERT algorithm as an example of how to use our method,and we intersperse our description with the explanation of why it works.2BERTThe BERT(Best Effort and Real-Time)scheduler is designed to schedule a mix of real-time and best effort (i.e.,conventional)processes in Scout,a communication-oriented OS.BERT’s focus is on producing good system behavior despite the problems of overload and changing ap-plication requirements that are widespread in multimedia systems.BERT reasons that a best effort process wants a CPU share;on the other hand,a multimedia process would like its deadlines met,regardless of the share needed to do so.When these requirements conflict,as they are bound to do in an overloaded system,the system should use the im-portance of processes to the user to resolve conflicts in an intuitive way.BERT comprises a virtual-time-based scheduling algo-rithm,a simple policy framework,and a minimal user inter-face.The scheduling algorithm combines the WF Q+fair sharing algorithm[3]and a mechanism called stealing.The policy framework divides all processes into two priority lev-els,important and unimportant,and defines how processes in each class interact with those in other classes;its main feature is that an important real-time process can steal cy-cles from unimportant processes to meet its deadlines.The user interface includes a button on the frame of each appli-cation window that the user clicks to indicate that she con-siders the application important.In this discussion we will focus on BERT’s scheduling algorithm,and particularly on the stealing mechanism.BERT exploits the relationship between virtual and real time implied by the bounded lag of the WF Q+algorithm.BERT notes that if a task’s deadline falls after the lag bound of the algorithm,then the deadline will be met because thetask will have completed running by then.Furthermore, BERT uses stealing to give an important real-time task extra cycles to meet its deadline when its share is too small.Steal-ing manipulates thefluid model and virtual time to explic-itly redistribute the reserved service of unimportant tasks toan important real-time task.Stealing introduces a dynamic dimension into static fair sharing of the CPU.The stealing mechanism is spread across several levels offair sharing theory and implementation.First,it mathemat-ically describes the virtual multiplexing of tasks within the context of thefluid model.Second,the stealing mechanismcalculates how virtual timeflows for the affected processes in the modifiedfluid model—one process gets delayed a lit-tle(in virtual time)while the other speeds up.Third,the timestamps of tasks belonging to the processes are modified to reflect the changes in virtual time.Stealing uses virtualtime to track changes in thefluid model,resulting in tasks receiving new timestamps.It is crucial that stealing preserves the relationship be-tween virtual and real time on which BERT depends.In the rest of this paper,we demonstrate why stealing works inreal time,and in the process outline a framework for deriv-ing new scheduling mechanisms based on virtual time.3MethodologyThe Fair Queueing Fluid Model(FQFM for short)forms the foundation of fair sharing algorithms like Weighted Fair Queueing.The model describes the real-time behavior of anideal,fluid system in which each process receives at least its reserved rate whenever it is active.The FQFM can begiven a concise mathematical definition as follows.Let the processes in the system be indexed from to.Each process generates a sequence of tasks that represent chunksof work of known duration.Let be the th process and be the th task it generates.reserves a cycle rate that can be expressed in any units,for example,cycles per second.Let be the total cycles that process has received so far.Also,let be the actual processor rate, and let be the set containing the indices of all currently active processes.At all times,thefluid model defines the instantaneous execution rates of the current task belonging to:(1)The above simply states that the instantaneous execution rate of a process is the proportion of the CPU equal to its re-served rate over the sum of the rates of all active processes. Since admission control ensures that the sum of all rates never exceeds the CPU rate,each running process will al-ways receive at least its reserved rate in the model.Note that the units of the reservation(e.g.,cycles per second)do not matter since the model describes an instantaneous exe-cution rate.BERT provides an example of how to dynamically mod-ify thefluid model description of the system.The FQFM provides the base of the BERT algorithm,but BERT de-parts from the FQFM when one process steals from another. BERT describes stealing at the lowest level in terms of mod-ifying theflow of thefluid model:conceptually,stealing pauses one process in thefluid model and gives its alloca-tion to another for a predefined interval.Formally,this is expressed as follows.When process steals from process ,the cycles that would receive during the steal are diverted to.If was idle at the start of stealing,it is considered active(i.e.,)while the stealing is going on.During the stealing interval:(2)process(i.e.,the rate expressed in terms of virtual time)to be constant and equal to the rate the process has reserved. That is,virtual time lets us provide a simplified description of the system in which each process runs on its own CPU of speed.So,if is the current virtual time,then virtual timeflows at the rate:(4)We can combine Eqs.1and4to express the rate of pro-cess in virtual time:(6)If an algorithm dynamically alters thefluid model de-scription,as BERT does,then this can change the virtual finish time of a task that had previously been assigned a timestamp.In this case,it is necessary to change the times-tamp of the affected task so that the ready queue continues to reflect thefluid model.When one process steals from another,the virtualfinish times of tasks are affected as described at the end of Sec-tion3.1.BERT modifies the timestamps of tasks in the sys-tem accordingly—however,care must be taken when doing so.The reason is that some tasks which are still“execut-ing”in thefluid model may in reality have already run,and so are no longer in the system.It is not possible to modify the virtual timestamp of such a task and so it must not be stolen from.Rather than checking whether or not a task is in the sys-tem before stealing from it,BERT’s approach is to rely on the known workahead bound of a process.The workahead indicates the amount of a process’s reservation that can be received in the real system in advance of thefluid model;in [1]we show that this quantity is bounded for BERT.Prior to stealing,BERT calculates the amount of cycles that can be stolen from a process before a particular deadline.Since the workahead bound represents cycles that a process may have already received,BERT subtracts them from the total. Though conservative,this allows BERT to safely steal from processes without having to track whether particular tasks have already run.3.3Execution OrderVirtual time algorithms execute the task set in order of increasing timestamps.We have outlined the progress of a virtual time algorithm through thefluid model definition, tracking the model using virtual time,and assigning times-tamps.At this point we tie it all together and show how running tasks by increasing timestamps leads to a real-time algorithm that provably conforms to itsfluid model descrip-tion.Figueira and Pasquale establish two very powerful re-sults in[5].First,if the eligible task sequence is schedulable under any policy,then it is schedulable under preemptive deadline-ordered scheduling—for our purposes,deadline-oriented scheduling is the same as Earliest Deadline First, or EDF.Second,this same task sequence is-schedulable under nonpreemptive deadline-ordered scheduling.Simply stated,these results mean that if it is possible to meet all deadlines using some scheduling discipline,then preemp-tive EDF will meet them,and nonpreemptive EDF will miss them by no more than a quantity,which is the runtime of the longest task in the system.With these results in hand,the significance of the steps in our method becomes clear.Executing tasks by increas-ing timestamps runs them in the same order as theirfluid model deadlines,and so is equivalent to EDF.By definition, thefluid model itself shows that there exists a method,al-beit impractical,of scheduling the tasks to meet these dead-lines.Therefore,preemptive scheduling by virtual times-tamps meets allfluid model deadlines,and nonpreemptive scheduling misses them by no more than the described above.That is,the preemptive algorithm never lags itsfluid model description,and the nonpreemptive algorithm has its lag bounded by.In either case,the actual running system conforms to its idealfluid model description in real time in a quantifiable way.The progress of a process in thefluid model never lags the virtual CPU of the process.The reason is that Eq.4 shows that when the sum of all reserved rates is less than the rate of the CPU.As long as this is true,then vir-tual time(showing progress on the virtual CPU)flows faster than real time;this means that,for any interval of time,the cycles received by the process in thefluid model are always at least what it would receive on its dedicated CPU.There-fore,since we have established lag bounds relative to the fluid model,the same lag bounds apply to the virtual CPU description of a process’s progress.This result is at least as powerful as those which bound an algorithm’s lag relative to virtual time.BERT depends entirely on this conformity for its effec-tiveness.As originally described in[2],BERT is a nonpre-emptive scheduling algorithm.When BERT needs to meet the time constraint of a task,itfirst assumes that the task’s process will receive no more than its reserved rate in the fluid model and calculates a conservativefluid modelfinish time for the task.It then steals enough capacity from less important tasks to ensure that the latestfluid modelfinish time for the task is at least before the timing constraint. With this accomplished,BERT can guarantee that the con-straint will be met.4Future DirectionsOur methodology provides scheduler designers with two additional degrees of freedom over traditional fair sharing. First,the dynamic behavior of the system can be modified in specific and controlled ways on thefly.The designer describes changes to afluid model of execution,and uses virtual time to manifest the changes in real time in the run-ning system.BERT is a prime example of this.Second,the mathematical basis of the FQFM and virtual time appears to leave room for a process to request any cycle function as its reservation—for example,it could reserve a sine function or a square wave.We must simply do the math to calculate vir-tual timestamps for tasks according to the reservation func-tion,and theory takes care of the rest.A non-constant rate function may allow a process to describe its resource needs more precisely than a simple“slice of the CPU”.We intend to investigate both of these directions more fully in future work.References[1] A.Bavier and L.Peterson.The power of virtual time for mul-timedia scheduling.In Proceedings of the Tenth International Workshop for Network and Operating System Support for Dig-ital Audio and Video,pages65–74,June2000.[2] A.Bavier,L.Peterson,and D.Mosberger.BERT:A schedulerfor best effort and realtime tasks.Technical Report TR-602-99,Department of Computer Science,Princeton University, Mar.1999.[3]J.C.R.Bennett and H.Zhang.Hierarchical packet fair queue-ing algorithms.In Proceedings of the SIGCOMM’96Sympo-sium,pages143–156,Palo Alto,CA,Aug.1996.ACM. [4]K.J.Duda and D.R.Cheriton.Borrowed-virtual-time(BVT)scheduling:supporting latency-sensitive threads in a general-purpose scheduler.In Proceedings of the17th ACM Sympo-sium on Operating System Principles,Dec.1999.[5]N.R.Figueira and J.Pasquale.A schedulability condition fordeadline-ordered service disciplines.ACM Transactions on Networking,5(2):232–244,Apr.1997.[6]J.Nieh and m.The design,implementation and evalua-tion of SMART:A scheduler for multimedia applications.In Proceedings of the Sixteenth Symposium on Operating System Principles,pages184–197,Oct.1997.。