统计学原理第三章
- 格式:pdf
- 大小:978.46 KB
- 文档页数:70

第三章:编制次数分配数列1.根据所给资料分组并计算出各组的频数和频率,编制次数分布表;根据整理表计算算术平均数。
例题:某单位40名职工业务考核成绩分别为: 68 89 88 84 86 87 75 73 72 68 75 82 97 58 81 54 79 76 95 76 71 60 90 65 76 72 76 85 89 92 64 57 83 81 78 77 72 61 70 81单位规定:60分以下为不及格,60─70分为及格,70─80分为中,80─90分为良,90─100分为优。
要求:(1)将参加考试的职工按考核成绩分为不及格、及格、中、良、优五组并编制一张考核成绩次数分配表;(2)指出分组标志及类型及采用的分组方法;(3)根据考核成绩次数分配表计算本单位职工业务考核平均成绩; (4)分析本单位职工业务考核情况。
解答:(1)(2)此题分组标志是按“成绩"分组,其标志类型是“数量标志”; 分组方法是“变量分组中的组距式分组的等距分组,而且是开口式分组";(3)根据考核成绩次数分配表计算本单位职工业务考核平均成绩。
(4)分析本单位职工考核情况。
本单位的考核成绩的分布呈两头小,中间大的“钟形分布”(即正态分布),不及格和优秀的职工人数较少,分别占总数的7.5%和10%,本单位大部分职工的考核成绩集中在70—90分之间,占了本单位的为67.5%,说明该单位的考核成绩总体良好。
)(774095485127515656553分=⨯+⨯+⨯+⨯+⨯==∑∑f xf x第四章:计算加权算术平均数、加权调和平均数(已知某年某月甲、乙两农贸市场A 、B 、C 三种农产品价格和成交量、成交额资料,试比较哪一个市场农产品的平均价格 较高?并说明原因。
)、标准差、变异系数2.根据资料计算算术平均数指标;计算变异指标;比较平均指标的代表性。
例题:某车间有甲、乙两个生产组,甲组平均每个工人的日产量为36件,标准差为9.6件;乙组工人日产量资料如下:要求:⑴计算乙组平均每个工人的日产量和标准差;⑵比较甲、乙两生产小组哪个组的日产量更 有代表性? 标准差的计算参考教材P102页。



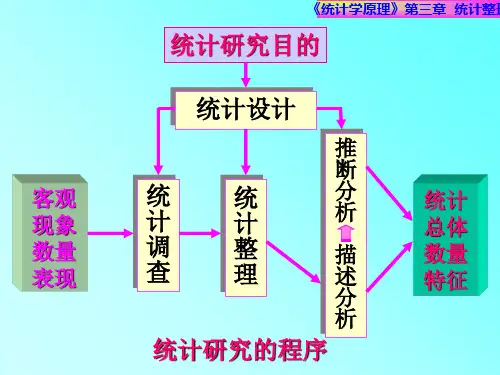



思考与练习(第三章)一、单项选择题1.下面属于按品质标志分组的是(A )。
A.工人按性别分组B.教师按年龄分组C.学生按成绩分组D.商业按销售额分组2.下面属于按数量标志分组的是(B )。
A.工人按政治面貌分组B.工人按年龄分组C.工人按性质分组D.工人按民族分组3.变量数列中各组变量值在决定总体数量大小时所起的作用就其实质而言(C )。
A.与比重、频率或比率大小无关B.与次数或频数大小有关C.与比重、频率或比率大小有关D.与次数或频数大小有关,与比重、频率或比率大小无关4.组距式变量数列的全距等于(D )。
A.最大组的上限与最小组的上限之差B.最大组的下限与最小组的下限之差C.最大组的下限与最小组的上限之差D.最大组的上限与最小组的下限之差5.对于越高越好的现象按连续型变量分组,如第一组为60以下,第二组为60~70,第三组为70~80,第四组为80以上,则数据(A )。
A.70在第三组B.60在第一组C.80在第三组D.70在第二组6.按连续型变量分组,其第一组为开口组,上限为1000.已知相邻组的组中值为1250,则该组组中值为(C )。
A.1000B.500C.750D.8507.对连续性变量分组( B )。
A.要用单项式分组B.要用组距式分组C.单项式或组距式分组都可以D.要用等距式分组8.划分连续性变量的组限时,相邻组的组限必须(AB )。
A.重叠B.相等C.不相等D.间断9.统计分组的关键是( C )。
A.划分分组界限B.确定组数C.选择分组标志D.划定分组形式10.次数分配中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( B )。
A.钟型分布B.U型分布C.J型分布D.洛伦茨分布11.对总体进行分组时,采用等距数列还是异距数列,决定于( A )。
A.次数的多少B.变量的大小C.组数的多少D.现象的性质和研究的目的12.区分简单分组与复合分组的根据是( C )。
思考与练习(第三章)一、单项选择题1.下面属于按品质标志分组的是(A )。
A.工人按性别分组B.教师按年龄分组C.学生按成绩分组D.商业按销售额分组2.下面属于按数量标志分组的是(B )。
A.工人按政治面貌分组B.工人按年龄分组C.工人按性质分组D.工人按民族分组3.变量数列中各组变量值在决定总体数量大小时所起的作用就其实质而言(C )。
A.与比重、频率或比率大小无关B.与次数或频数大小有关C.与比重、频率或比率大小有关D.与次数或频数大小有关,与比重、频率或比率大小无关4.组距式变量数列的全距等于(D )。
A.最大组的上限与最小组的上限之差B.最大组的下限与最小组的下限之差C.最大组的下限与最小组的上限之差D.最大组的上限与最小组的下限之差5.对于越高越好的现象按连续型变量分组,如第一组为60以下,第二组为60~70,第三组为70~80,第四组为80以上,则数据(A )。
A.70在第三组B.60在第一组C.80在第三组D.70在第二组6.按连续型变量分组,其第一组为开口组,上限为1000.已知相邻组的组中值为1250,则该组组中值为(C )。
A.1000B.500C.750D.8507.对连续性变量分组( B )。
A.要用单项式分组B.要用组距式分组C.单项式或组距式分组都可以D.要用等距式分组8.划分连续性变量的组限时,相邻组的组限必须(AB )。
A.重叠B.相等C.不相等D.间断9.统计分组的关键是( C )。
A.划分分组界限B.确定组数C.选择分组标志D.划定分组形式10.次数分配中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种分布的类型是( B )。
A.钟型分布B.U型分布C.J型分布D.洛伦茨分布11.对总体进行分组时,采用等距数列还是异距数列,决定于( A )。
A.次数的多少B.变量的大小C.组数的多少D.现象的性质和研究的目的12.区分简单分组与复合分组的根据是( C )。


精品文档《统计学原理》常用公式汇总及计算题目分析第一部分常用公式第三章统计整理a)组距=上限-下限b)组中值=(上限+下限)÷2c)缺下限开口组组中值=上限-1/2邻组组距d)缺上限开口组组中值=下限+1/2邻组组距第四章综合指标i.相对指标1.结构相对指标=各组(或部分)总量/总体总量2.比例相对指标=总体中某一部分数值/总体中另一部分数值3.比较相对指标=甲单位某指标值/乙单位同类指标值4.强度相对指标=某种现象总量指标/另一个有联系而性质不同的现象总量指标5.计划完成程度相对指标=实际数/计划数=实际完成程度(%)/计划规定的完成程度(%)ii.平均指标精品文档.精品文档简单算术平均数:1.2.加权算术平均数或iii.变异指标1.全距=最大标志值-最小标志值 = : 简单σ加权= ;σ2.标准差 :3.标准差系数抽样估计第五章1.平均误差:重复抽样:不重复抽样:抽样极限误差2.3.重复抽样条件下:平均数抽样时必要的样本数目精品文档.精品文档成数抽样时必要的样本数目4.不重复抽样条件下:平均数抽样时必要的样本数目第七章相关分析相关系数1.y=a+bx配合回归方程2.3.估计标准误:第八章指数分数一、综合指数的计算与分析数量指标指数(1)精品文档.精品文档此公式的计算结果说明复杂现象总体数量指标综合变动的方向和程度。
)(-此差额说明由于数量指标的变动对价值量指标影响的绝对额。
质量指标指数(2)此公式的计算结果说明复杂现象总体质量指标综合变动的方向和程度。
-()此差额说明由于质量指标的变动对价值量指标影响的绝对额。
=加权算术平均数指数加权调和平均数指数=复杂现象总体总量指标变动的因素分析(3) 相对数变动分析:×= 绝对值变动分析:精品文档.精品文档)×(-)= (--第九章动态数列分析一、平均发展水平的计算方法:由总量指标动态数列计算序时平均数(1)①由时期数列计算②由时点数列计算在间断时点数列的条件下计算: a.若间断的间隔相等,则采用“首末折半法”计算。
第三章综合指标1、下列指标属于时期指标的有()。
A、货物周转量B、社会商品零售额C、全社会固定资产投资总额D、年末人口数E、年平均人口数2、下列指标属于动态相对指标的有()。
A、1981年到1990年我国人口平均增长1.48%B、1990年国民生产总值为1980年的236.3%C、1990年国民生产总值中,第一二三产业分别占28.4%、44.3%、27.3%D、1990年国民收入为1952年的2364.2%E、1990年国民收入使用额中积累和消费分别占34.1%和65.9%3、 下列指标属于时期指标的有( ) 。
A 、总产出 B 、职工人数 C 、存款余额 D 、存款利息 E 、出生人数4、下列各项属于数量指标的有( ) 。
A 、金融系统职工人数B 、金融系统职工工资总额C 、金融系统职工平均工资D 、银行存(贷)款期末(初)余额E 、具有大专以上文化程度职工占全系统职工的比重5、下列指标中,属于强度相对指标的有( )。
A 、人均国内生产总值 B 、人口密度 C 、人均钢产量 D 、商品流通费E 、每百元资金实现的利税额6、调和平均数的计算公式有( )。
x1n E 、m x1m D 、ff xC 、fxf B 、nx A 、∑∑∑∑∑∑∑∑7.标志变异指标可以说明( )。
A 、分配数列中变量的离中趋势 B 、分配数列中各标志值的变动范围 C 、分配数列中各标志值的离散程度 D 、总体单位标志值的分布特征 E 、分配数列中各标志值的集中趋势8、相对指标的计量单位有( )。
A 、百分数 B 、千分数 C 、系数或倍数 D 、成数 E 、复名数9、平均数的种类有( )。
A 、算术平均数 B 、众数C、中位数D、调和平均数E、几何平均数10、加权算术平均数的大小受哪些因素的影响()。
A、受各组频率和频数的影响B、受各组标志值大小的影响C、受各组标志值和权数的共同影响D、只受各组标志值大小的影响E、只受权数的大小的影响11、在什么条件下,加权算术平均数等于简单算术平均数()。
统计学原理多项选择题第三章统计指标部门: xxx时间: xxx整理范文,仅供参考,可下载自行编辑第三章综合指标1、下列指标属于时期指标的有<)。
A、货物周转量B、社会商品零售额C、全社会固定资产投资总额D、年末人口数E、年平均人口数2、下列指标属于动态相对指标的有<)。
A、1981年到1990年我国人口平均增长1.48%B、1990年国民生产总值为1980年的236.3%C、1990年国民生产总值中,第一二三产业分别占28.4%、44.3%、27.3%D、1990年国民收入为1952年的2364.2%E、1990年国民收入使用额中积累和消费分别占34.1%和65.9%3、下列指标属于时期指标的有< )。
A、总产出B、职工人数C、存款余额D、存款利息E、出生人数4、下列各项属于数量指标的有< )。
A、金融系统职工人数B、金融系统职工工资总额C、金融系统职工平均工资D、银行存<贷)款期末<初)余额E、具有大专以上文化程度职工占全系统职工的比重5、下列指标中,属于强度相对指标的有< )。
A、人均国内生产总值B、人口密度C、人均钢产量D、商品流通费E、每百元资金实现的利税额6、调和平均数的计算公式有< )。
7.标志变异指标可以说明< )。
A、分配数列中变量的离中趋势B、分配数列中各标志值的变动范围C、分配数列中各标志值的离散程度D、总体单位标志值的分布特征E、分配数列中各标志值的集中趋势8、相对指标的计量单位有< )。
A、百分数B、千分数C、系数或倍数D、成数E、复名数9、平均数的种类有< )。
A、算术平均数B、众数C、中位数D、调和平均数E、几何平均数10、加权算术平均数的大小受哪些因素的影响< )。
A、受各组频率和频数的影响B、受各组标志值大小的影响C、受各组标志值和权数的共同影响D、只受各组标志值大小的影响E、只受权数的大小的影响11、在什么条件下,加权算术平均数等于简单算术平均数< )。