基于决策树算法的医疗数据挖掘
一、实验目的
利用商业智能分析项目中的数据分析功能,对乳腺癌数据集breast-cancer基于决策树算法进行挖掘,产生相关规则,从而预测女性乳腺癌复发的高发人群。并通过本次实验掌握决策树算法关联规则挖掘的知识及软件操作,以及提高数据分析能力。
二、实验步骤
1、在SQL server 2005中建立breast-cancer数据库,导入breast-cancer数据集;
2、对该数据集进行数据预处理,包括列名的中文翻译、以及node-caps缺失值的填充,即将‘null’填充成‘?’;
3、新建数据分析服务项目,导入数据源、新建数据源视图、新建挖掘结构,其中,将breast-cancer表中的‘序号’作为标识,‘是否复发’作为分类;
4、部署;
5、查看决策树、依赖关系网络等,并根据结果进行分析、预测。
三、实验结果分析
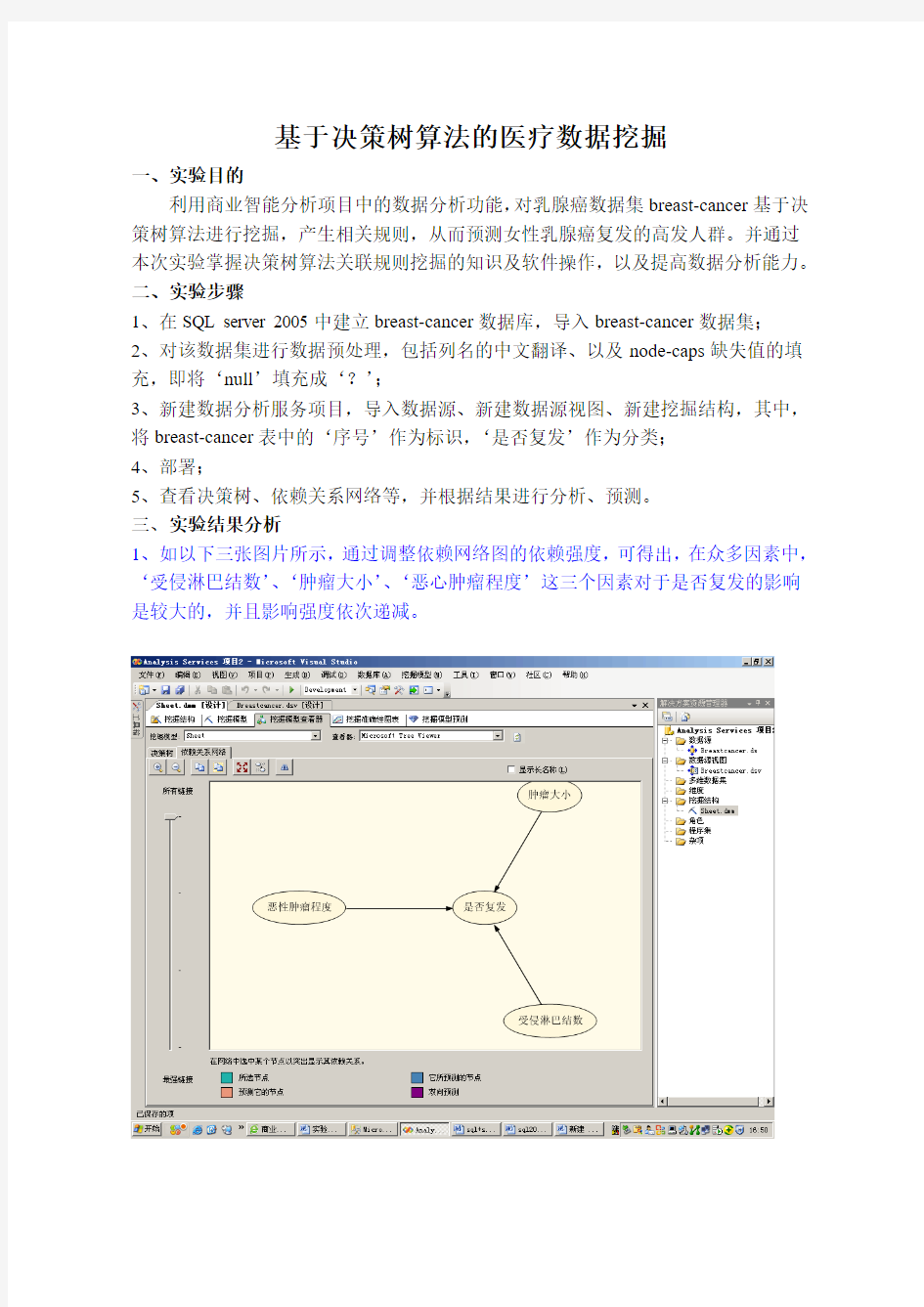
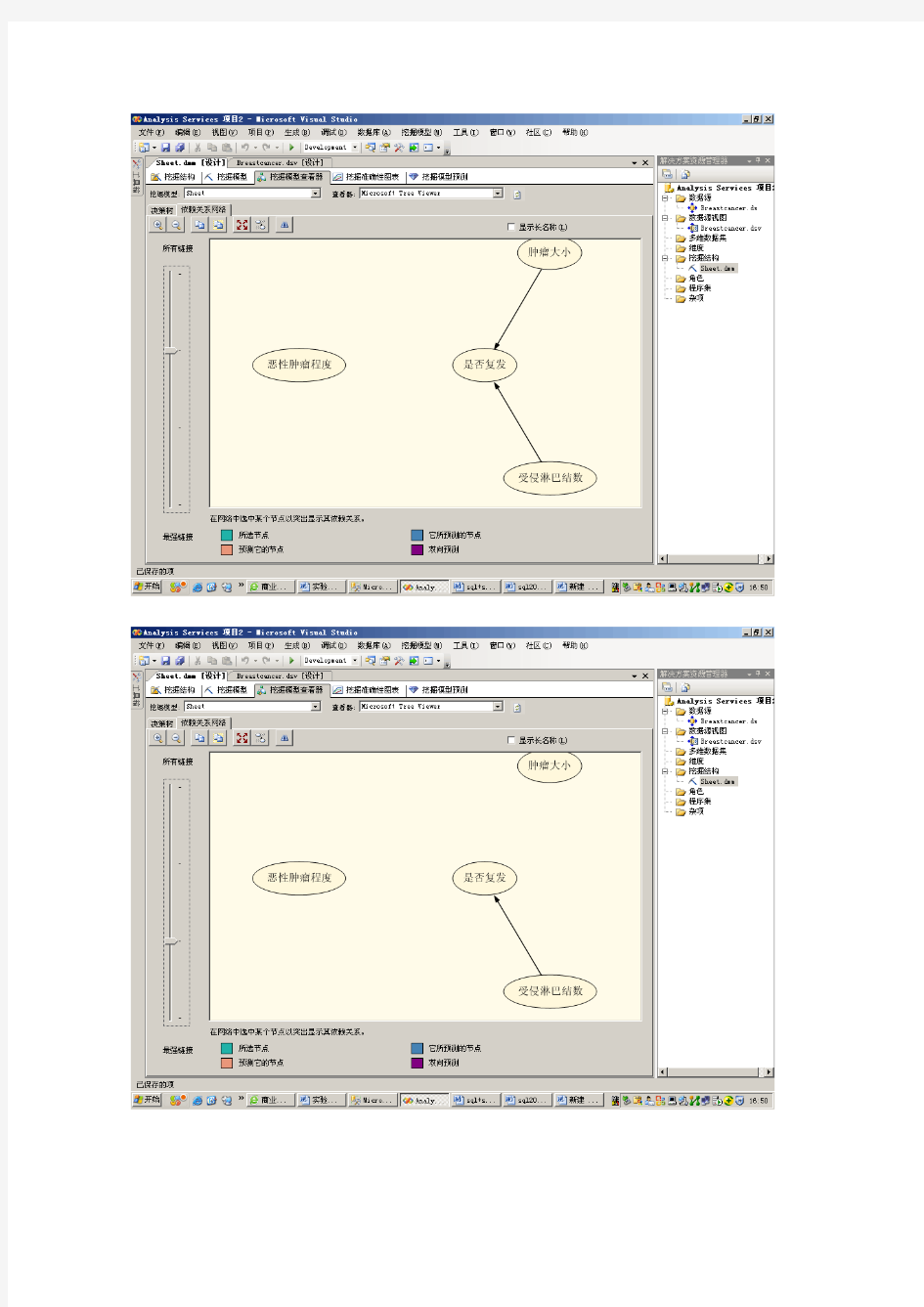
1、如以下三张图片所示,通过调整依赖网络图的依赖强度,可得出,在众多因素中,‘受侵淋巴结数’、‘肿瘤大小’、‘恶心肿瘤程度’这三个因素对于是否复发的影响是较大的,并且影响强度依次递减。
2、从‘全部’节点的挖掘图例可以看到,在breast-cancer数据集中,复发占了29.91%,不复发占了68.32%,说明乳腺肿瘤的复发还是占了相当一部分比例的,因此此挖掘是具备前提意义的。
3、由下两张图可知,‘受侵淋巴数’这一因素对于是否复发是决定程度是最高的。在‘受侵淋巴结数不等于0-2’(即大于0-2)节点中,复发占了50.19%的比例,不复发占了44.44%的比例,而在‘受侵淋巴结数=0-2’的节点中,复发只占了21.71%的比例,不复发占了77.98%的比例。由此可见,当受侵淋巴节点数大于‘0-2’时,复发的几率比较高。
4、由以下两张图可见,在‘受侵淋巴结数不等于0-2’(即大于0-2)的情况下,‘恶性肿瘤程度=3’(最高程度)时,复发占了69.55%,不复发占了27.57%;‘恶
性肿瘤程度不等于3’时,复发占了33.33%,不复发占了59.14%。也就是说,在受侵淋巴结数较多的情况下大于0-2的情况下,恶性肿瘤程度越高,复发的几率越高。
5、由以下两张图可见,在受侵淋巴结数等于0-2的情况下,‘肿瘤大小=10-14’时,复发概率为0;‘肿瘤大小不等于10-14’时(即大于10-14),复发占了24.68%,不复发占了74.99%。由此可见,在受侵淋巴结数等于‘0-2’的情况下,肿瘤复发只跟‘肿瘤大小’大于10-14的因素有关。
综上分析可得:
1、受侵淋巴结数越高、恶性肿瘤程度越高,越容易复发;
2、受侵淋巴结数越低、肿瘤越大,复发程度越高。
最后可预测:淋巴结数越高、恶性肿瘤程度越高、肿瘤越大,越容易复发。
四、实验总结
本次实验从数据的导入、进行挖掘、决策树的分析都能够顺利完成,这得益于课后的复习与老师同学的指导。本实验让我深深体会到数据挖掘与分析的魅力,自己也会多加深入了解这方面的知识。本次实验的另外一个收获便是,当在新建挖掘结构时,对各数据项进行类、标识、预测的选择无法决定是,可以通过点击右下方
的‘建议’按钮查看相关支持度,以确定选择哪一个数据项作为分类。
决策树算法研究及应用? 王桂芹黄道 华东理工大学实验十五楼206室 摘要:信息论是数据挖掘技术的重要指导理论之一,是决策树算法实现的理论依据。决 策树算法是一种逼近离散值目标函数的方法,其实质是在学习的基础上,得到分类规则。本文简要介绍了信息论的基本原理,重点阐述基于信息论的决策树算法,分析了它们目前 主要的代表理论以及存在的问题,并用具体的事例来验证。 关键词:决策树算法分类应用 Study and Application in Decision Tree Algorithm WANG Guiqin HUANG Dao College of Information Science and Engineering, East China University of Science and Technology Abstract:The information theory is one of the basic theories of Data Mining,and also is the theoretical foundation of the Decision Tree Algorithm.Decision Tree Algorithm is a method to approach the discrete-valued objective function.The essential of the method is to obtain a clas-sification rule on the basis of example-based learning.An example is used to sustain the theory. Keywords:Decision Tree; Algorithm; Classification; Application 1 引言 决策树分类算法起源于概念学习系统CLS(Concept Learning System,然后发展 到ID3
《数据挖掘》Weka实验报告 姓名_学号_ 指导教师 开课学期2015 至2016 学年 2 学期完成日期2015年6月12日
1.实验目的 基于https://www.doczj.com/doc/0c12144003.html,/ml/datasets/Breast+Cancer+WiscOnsin+%28Ori- ginal%29的数据,使用数据挖掘中的分类算法,运用Weka平台的基本功能对数据集进行分类,对算法结果进行性能比较,画出性能比较图,另外针对不同数量的训练集进行对比实验,并画出性能比较图训练并测试。 2.实验环境 实验采用Weka平台,数据使用来自https://www.doczj.com/doc/0c12144003.html,/ml/Datasets/Br- east+Cancer+WiscOnsin+%28Original%29,主要使用其中的Breast Cancer Wisc- onsin (Original) Data Set数据。Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。 3.实验步骤 3.1数据预处理 本实验是针对威斯康辛州(原始)的乳腺癌数据集进行分类,该表含有Sample code number(样本代码),Clump Thickness(丛厚度),Uniformity of Cell Size (均匀的细胞大小),Uniformity of Cell Shape (均匀的细胞形状),Marginal Adhesion(边际粘连),Single Epithelial Cell Size(单一的上皮细胞大小),Bare Nuclei(裸核),Bland Chromatin(平淡的染色质),Normal Nucleoli(正常的核仁),Mitoses(有丝分裂),Class(分类),其中第二项到第十项取值均为1-10,分类中2代表良性,4代表恶性。通过实验,希望能找出患乳腺癌客户各指标的分布情况。 该数据的数据属性如下: 1. Sample code number(numeric),样本代码; 2. Clump Thickness(numeric),丛厚度;
创建Analysis Services 项目 更改存储数据挖掘对象的实例 创建数据源视图 创建用于目标邮件方案的挖掘结构 创建目标邮件方案的第一步是使用Business Intelligence Development Studio 中的数据挖掘向导创建新的挖掘结构和决策树挖掘模型。 在本任务中,您将基于Microsoft 决策树算法创建初始挖掘结构。若要创建此结构,需要首先选择表和视图,然后标识将用于定型的列和将用于测试的列 1.在解决方案资源管理器中,右键单击“挖掘结构”并选择“新建挖掘 结构”启动数据挖掘向导。 2.在“欢迎使用数据挖掘向导”页上,单击“下一步”。 3.在“选择定义方法”页上,确保已选中“从现有关系数据库或数据仓 库”,再单击“下一步”。 4.在“创建数据挖掘结构”页的“您要使用何种数据挖掘技术?”下, 选择“Microsoft 决策树”。 5.单击“下一步”。 6.在“选择数据源视图”页上的“可用数据源视图”窗格中,选择 Targeted Mailing。可单击“浏览”查看数据源视图中的各表,然后单击“关闭”返回该向导。 7.单击“下一步”。
8.在“指定表类型”页上,选中vTargetMail 的“事例”列中的复选 框以将其用作事例表,然后单击“下一步”。稍后您将使用 ProspectiveBuyer 表进行测试,不过现在可以忽略它。 9.在“指定定型数据”页上,您将为模型至少标识一个可预测列、一 个键列以及一个输入列。选中BikeBuyer行中的“可预测”列中的复选框。 10.单击“建议”打开“提供相关列建议”对话框。 只要选中至少一个可预测属性,即可启用“建议”按钮。“提供相关列建议”对话框将列出与可预测列关联最密切的列,并按照与可预测属性的相互关系对属性进行排序。显著相关的列(置信度高于95%)将被自动选中以添加到模型中。 查看建议,然后单击“取消”忽略建议。 11.确认在CustomerKey行中已选中“键”列中的复选框。 12.选中以下行中“输入”列中的复选框。可通过下面的方法来同 时选中多个列:突出显示一系列单元格,然后在按住Ctrl 的同时选中一个复选框。 1.Age https://www.doczj.com/doc/0c12144003.html,muteDistance 3.EnglishEducation 4.EnglishOccupation 5.Gender 6.GeographyKey
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
基于决策树算法的医疗数据挖掘 一、实验目的 利用商业智能分析项目中的数据分析功能,对乳腺癌数据集breast-cancer基于决策树算法进行挖掘,产生相关规则,从而预测女性乳腺癌复发的高发人群。并通过本次实验掌握决策树算法关联规则挖掘的知识及软件操作,以及提高数据分析能力。 二、实验步骤 1、在SQL server 2005中建立breast-cancer数据库,导入breast-cancer数据集; 2、对该数据集进行数据预处理,包括列名的中文翻译、以及node-caps缺失值的填充,即将‘null’填充成‘?’; 3、新建数据分析服务项目,导入数据源、新建数据源视图、新建挖掘结构,其中,将breast-cancer表中的‘序号’作为标识,‘是否复发’作为分类; 4、部署; 5、查看决策树、依赖关系网络等,并根据结果进行分析、预测。 三、实验结果分析 1、如以下三张图片所示,通过调整依赖网络图的依赖强度,可得出,在众多因素中,‘受侵淋巴结数’、‘肿瘤大小’、‘恶心肿瘤程度’这三个因素对于是否复发的影响是较大的,并且影响强度依次递减。
2、从‘全部’节点的挖掘图例可以看到,在breast-cancer数据集中,复发占了29.91%,不复发占了68.32%,说明乳腺肿瘤的复发还是占了相当一部分比例的,因此此挖掘是具备前提意义的。 3、由下两张图可知,‘受侵淋巴数’这一因素对于是否复发是决定程度是最高的。在‘受侵淋巴结数不等于0-2’(即大于0-2)节点中,复发占了50.19%的比例,不复发占了44.44%的比例,而在‘受侵淋巴结数=0-2’的节点中,复发只占了21.71%的比例,不复发占了77.98%的比例。由此可见,当受侵淋巴节点数大于‘0-2’时,复发的几率比较高。
实验四决策树 一、实验目的 1.了解典型决策树算法 2.熟悉决策树算法的思路与步骤 3.掌握运用Matlab对数据集做决策树分析的方法 二、实验内容 1.运用Matlab对数据集做决策树分析 三、实验步骤 1.写出对决策树算法的理解 决策树方法是数据挖掘的重要方法之一,它是利用树形结构的特性来对数据进行分类的一种方法。决策树学习从一组无规则、无次序的事例中推理出有用的分类规则,是一种实例为基础的归纳学习算法。决策树首先利用训练数据集合生成一个测试函数,根据不同的权值建立树的分支,即叶子结点,在每个叶子节点下又建立层次结点和分支,如此重利生成决策树,然后对决策树进行剪树处理,最后把决策树转换成规则。决策树的最大优点是直观,以树状图的形式表现预测结果,而且这个结果可以进行解释。决策树主要用于聚类和分类方面的应用。 决策树是一树状结构,它的每一个叶子节点对应着一个分类,非叶子节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。构造决策树的核心问题是在每一步如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下分而治之的过程。 2.启动Matlab,运用Matlab对数据集进行决策树分析,写出算法名称、数据集名称、关键代码,记录实验过程,实验结果,并分析实验结果 (1)算法名称: ID3算法 ID3算法是最经典的决策树分类算法。ID3算法基于信息熵来选择最佳的测试属性,它选择当前样本集中具有最大信息增益值的属性作为测试属性;样本集的划分则依据测试属性的取值进行,测试属性有多少个不同的取值就将样本集划分为多少个子样本集,同时决策树上相应于该样本集的节点长出新的叶子节点。ID3算法根据信息论的理论,采用划分后样本集的不确定性作为衡量划分好坏的标准,用信息增益值度量不确定性:信息增益值越大,不确定性越小。因此,ID3算法在每个非叶节点选择信息增益最大的属性作为测试属性,这样可以得到当前情况下最纯的划分,从而得到较小的决策树。 ID3算法的具体流程如下: 1)对当前样本集合,计算所有属性的信息增益; 2)选择信息增益最大的属性作为测试属性,把测试属性取值相同的样本划为同一个子样本集; 3)若子样本集的类别属性只含有单个属性,则分支为叶子节点,判断其属性值并标上相应的符号,然后返回调用处;否则对子样本集递归调用本算法。 (2)数据集名称:鸢尾花卉Iris数据集 选择了部分数据集来区分Iris Setosa(山鸢尾)及Iris Versicolour(杂色鸢尾)两个种类。
实验三决策树算法实验 一、实验目的:熟悉和掌握决策树的分类原理、实质和过程;掌握典型的学习算法和实现技术。 二、实验原理: 决策树学习和分类. 三、实验条件: 四、实验内容: 1 根据现实生活中的原型自己创建一个简单的决策树。 2 要求用这个决策树能解决实际分类决策问题。 五、实验步骤: 1、验证性实验: (1)算法伪代码 算法Decision_Tree(data,AttributeName) 输入由离散值属性描述的训练样本集data; 候选属性集合AttributeName。 输出一棵决策树。(1)创建节点N; 资料.
(2)If samples 都在同一类C中then (3)返回N作为叶节点,以类C标记;(4)If attribute_list为空then (5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决(6)选择attribute_list 中具有最高信息增益的属性test_attribute; (7)以test_attribute 标记节点N; (8)For each test_attribute 的已知值v //划分samples ; (9)由节点N分出一个对应test_attribute=v的分支; (10令Sv为samples中test_attribute=v 的样本集合;//一个划分块(11)If Sv为空then (12)加上一个叶节点,以samples中最普遍的类标记; (13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点值。 (2)实验数据预处理 Age:30岁以下标记为“1”;30岁以上50岁以下标记为“2”;50岁以上标记为“3”。 Sex:FEMAL----“1”;MALE----“2” Region:INNER CITY----“1”;TOWN----“2”; RURAL----“3”; SUBURBAN----“4” Income:5000~2万----“1”;2万~4万----“2”;4万以上----“3” Married Children Car Mortgage 资料.
import java.util.HashMap; import java.util.HashSet; import java.util.LinkedHashSet; import java.util.Iterator; //调试过程中发现4个错误,感谢宇宙无敌的调试工具——print //1、selectAtrribute中的一个数组下标出错 2、两个字符串相等的判断 //3、输入的数据有一个错误 4、selectAtrribute中最后一个循环忘记了i++ //决策树的树结点类 class TreeNode { String element; //该值为数据的属性名称 String value; //上一个分裂属性在此结点的值 LinkedHashSet
理工大学信息工程与自动化学院学生实验报告 ( 2016 — 2017 学年第学期) 信自楼444 一、上机目的及容 目的: 1.理解数据挖掘的基本概念及其过程; 2.理解数据挖掘与数据仓库、OLAP之间的关系 3.理解基本的数据挖掘技术与方法的工作原理与过程,掌握数据挖掘相关工具的使用。 容: 给定AdventureWorksDW数据仓库,构建“Microsoft 决策树”模型,分析客户群中购买自行车的模式。 要求: 利用实验室和指导教师提供的实验软件,认真完成规定的实验容,真实地记录实验中遇到的 二、实验原理及基本技术路线图(方框原理图或程序流程图) 请描述数据挖掘及决策树的相关基本概念、模型等。 1.数据挖掘:从大量的、不完全的、有噪音的、模糊的、随机的数据中,提取隐含在其中的、 人们事先不知道的、但又潜在有用的信息和知识的过程。
项集的频繁模式 分类与预测分类:提出一个分类函数或者分类模型,该模型能把数据库中的数据项 映射到给定类别中的一个; 预测:利用历史数据建立模型,再运用最新数据作为输入值,获得未来 变化趋势或者评估给定样本可能具有的属性值或值的围 聚类分析根据数据的不同特征,将其划分为不同数据类 偏差分析对差异和极端特例的描述,揭示事物偏离常规的异常现象,其基本思想 是寻找观测结果与参照值之间有意义的差别 3.决策树:是一种预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个 节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从 根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输 出,可以建立独立的决策树以处理不同输出。 算法概念 ID3 在实体世界中,每个实体用多个特征来描述。每个特征限于在一 个离散集中取互斥的值 C4.5 对ID3算法进行了改进: 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选 择取值多的属性的不足;在树构造过程中进行剪枝;能够完成对 连续属性的离散化处理;能够对不完整数据进行处理。 三、所用仪器、材料(设备名称、型号、规格等或使用软件) 1台PC及Microsoft SQL Server套件 四、实验方法、步骤(或:程序代码或操作过程) (一)准备 Analysis Services 数据库 1.Analysis Services 项目创建成功
决策树算法 一、决策树算法简介: 决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。决策树方法的基本思想是:利用训练集数据自动地构造决策树,然后根据这个决策树对任意实例进行判定。其中决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。 决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪技:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数扼集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除、决策树方法最早产生于上世纪60年代,到70年代末。由J Ross Quinlan 提出了ID3算法,此算法的目的在于减少树的深度。但是忽略了叶子数目的研究。C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大改进,既适合于分类问题,又适合于回归问题。 本节将就ID3算法展开分析和实现。 ID3算法: ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。 在ID3算法中,决策节点属性的选择运用了信息论中的熵概念作为启发式函数。
决策树分类算法 学号:20120311139 学生所在学院:软件工程学院学生姓名:葛强强 任课教师:汤亮 教师所在学院:软件工程学院2015年11月
12软件1班 决策树分类算法 葛强强 12软件1班 摘要:决策树方法是数据挖掘中一种重要的分类方法,决策树是一个类似流程图的树型结构,其中树的每个内部结点代表对一个属性的测试,其分支代表测试的结果,而树的每个 叶结点代表一个类别。通过决策树模型对一条记录进行分类,就是通过按照模型中属 性测试结果从根到叶找到一条路径,最后叶节点的属性值就是该记录的分类结果。 关键词:数据挖掘,分类,决策树 近年来,随着数据库和数据仓库技术的广泛应用以及计算机技术的快速发展,人们利用信息技术搜集数据的能力大幅度提高,大量数据库被用于商业管理、政府办公、科学研究和工程开发等。面对海量的存储数据,如何从中有效地发现有价值的信息或知识,是一项非常艰巨的任务。数据挖掘就是为了应对这种要求而产生并迅速发展起来的。数据挖掘就是从大型数据库的数据中提取人们感兴趣的知识,这些知识是隐含的、事先未知的潜在有用的信息,提取的知识表示为概念、规则、规律、模式等形式。 分类在数据挖掘中是一项非常重要的任务。 分类的目的是学会一个分类函数或分类模型,把数据库中的数据项映射到给定类别中的某个类别。分类可用于预测,预测的目的是从历史数据记录中自动推导出对给定数据的趋势描述,从而能对未来数据进行预测。分类算法最知名的是决策树方法,决策树是用于分类的一种树结构。 1决策树介绍 决策树(decisiontree)技术是用于分类和预测 的主要技术,决策树学习是一种典型的以实例为基础的归纳学习算法,它着眼于从一组无次序、无规则的事例中推理出决策树表示形式的分类规则。它采用自顶向下的递归方式,在决策树的内部节点进行属性的比较,并根据不同属性判断从该节点向下的分支,在决策树的叶节点得到结论。所以从根到叶节点就对应着一条合取规则,整棵树就对应着一组析取表达式规则。 把决策树当成一个布尔函数。函数的输入为物体或情况的一切属性(property),输出为”是”或“否”的决策值。在决策树中,每个树枝节点对应着一个有关某项属性的测试,每个树叶节点对应着一个布尔函数值,树中的每个分支,代表测试属性其中一个可能的值。 最为典型的决策树学习系统是ID3,它起源于概念学习系统CLS,最后又演化为能处理连续属性的C4.5(C5.0)等。它是一种指导的学习方法,该方法先根据训练子集形成决策树。如果该树不能对所有给出的训练子集正确分类,那么选择一些其它的训练子集加入到原来的子集中,重复该过程一直到时形成正确的决策集。当经过一批训练实例集的训练产生一棵决策树,决策树可以根据属性的取值对一个未知实例集进行分类。使用决策树对实例进行分类的时候,由树根开始对该对象的属性逐渐测试其值,并且顺着分支向下走,直至到达某个叶结点,此叶结点代表的类即为该对象所处的类。 决策树是应用非常广泛的分类方法,目前有多种决策树方法,如ID3,C4.5,PUBLIC,
实验三-决策树算法实验实验报告
实验三决策树算法实验 一、实验目的:熟悉和掌握决策树的分类原理、实质和过程;掌握典型的学习算法和实现技术。 二、实验原理: 决策树学习和分类. 三、实验条件: 四、实验内容: 1 根据现实生活中的原型自己创建一个简单的决策树。 2 要求用这个决策树能解决实际分类决策问题。 五、实验步骤: 1、验证性实验: (1)算法伪代码 算法Decision_Tree(data,AttributeName) 输入由离散值属性描述的训练样本集
data; 候选属性集合AttributeName。 输出一棵决策树。(1)创建节点N; (2)If samples 都在同一类C中then (3)返回N作为叶节点,以类C标记;(4)If attribute_list为空then (5)返回N作为叶节点,以samples 中最普遍的类标记;//多数表决(6)选择attribute_list 中具有最高信息增益的属性test_attribute; (7)以test_attribute 标记节点N; (8)For each test_attribute 的已知值v //划分samples ; (9)由节点N分出一个对应test_attribute=v的分支; (10令Sv为samples中test_attribute=v 的样本集合;//一个划分块(11)If Sv 为空then (12)加上一个叶节点,以samples中最普遍的类标记; (13)Else 加入一个由Decision_Tree(Sv,attribute_list-test_attribute)返回节点
决策树是分类应用中采用最广泛的模型之一。与神经网络和贝叶斯方法相比,决策树无须花费大量的时间和进行上千次的迭代来训练模型,适用于大规模数据集,除了训练数据中的信息外不再需要其他额外信息,表现了很好的分类精确度。其核心问题是测试属性选择的策略,以及对决策树进行剪枝。连续属性离散化和对高维大规模数据降维,也是扩展决策树算法应用范围的关键技术。本文以决策树为研究对象,主要研究内容有:首先介绍了数据挖掘的历史、现状、理论和过程,然后详细介绍了三种决策树算法,包括其概念、形式模型和优略性,并通过实例对其进行了分析研究 目录 一、引言 (1) 二、数据挖掘 (2) (一)概念 (2) (二)数据挖掘的起源 (2) (三)数据挖掘的对象 (3) (四)数据挖掘的任务 (3) (五)数据挖掘的过程 (3) (六)数据挖掘的常用方法 (3) (七)数据挖掘的应用 (5) 三、决策树算法介绍 (5) (一)归纳学习 (5) (二)分类算法概述 (5) (三)决策树学习算法 (6) 1、决策树描述 (7) 2、决策树的类型 (8) 3、递归方式 (8) 4、决策树的构造算法 (8) 5、决策树的简化方法 (9) 6、决策树算法的讨论 (10) 四、ID3、C4.5和CART算法介绍 (10) (一)ID3学习算法 (11) 1、基本原理 (11) 2、ID3算法的形式化模型 (13) (二)C4.5算法 (14) (三)CART算法 (17) 1、CART算法理论 (17) 2、CART树的分支过程 (17) (四)算法比较 (19) 五、结论 (24) 参考文献...................................................................................... 错误!未定义书签。 致谢.............................................................................................. 错误!未定义书签。
ID3算法实验 08级第一小组介绍: ID3算法可分为主算法和建树算法两种。 (1)ID3主算法。主算法流程如图所示。其中PE、NE分别表示正例和反例集,它们共同组成训练集。PE'、PE''和NE'、NE''分别表示正例集和反例集的子集。 ID3主算法流程 (2)建树算法。采用建树算法建立决策树。首先,对当前子例进行同类归集。其次,计算各集合属性的互信息,选择互信息最大的属性Ak。再次,将在Ak处取值相同的子例归于同一子集,Ak取几个值就几个子集。最后,对既含正例又含反例的子集递归调用建树算法。若子集仅含正例或反例,对应分支标上P或N,返回调用处。 ID3算法采用自顶向下不回溯的策略搜索全部属性空间并建立决策树,算法简单、深度小、分类速度快。但是,ID3算法对于大的属性集执行效率下降快、准确性降低,并且学习能力低下。考虑到本文所涉及到的数据量并很小,下文分类分析采用了该算法。 决策树学习是把实例从根结点排列到某个叶子结点来分类实例,叶子结点即为实例所属的分类。学习到的决策树能再被表示成多个if-then的规则。ID3算法是一种决策树算法。 对下载的ID3算法程序进行阅读和调试后,做了相关实验,以下是相关记录。 1、试验数据 该算法的试验数据有两个:data.dat和data.tag,分别存放训练样例和各个属性列表:
data.dat: data.tag: 其中,训练样例集合的试验数据由课本第3.4。2节给出,分别将其属性使用离散值数据表示,在data.tag文件中可以看到离散值其表示的属性分别对应。 2、运行结果 试验结果,是以if-then形式输出决策树,其运行界面如图:
实验(实习)名称决策树分析 一.实验要求: (1)学习决策树分类学习方法,学习其中C4.5学习算法,了解其他ADtree、Id3等其它分类学习方法。 (2)应用Weka软件,学会导入数据文件,并对数据文件进行预处理。 (3)学会如何选择学习函数并调节学习训练参数以达到最佳学习效果。 (4)学习并应用其他决策树学习算法,可以进行各种算法对照比较。 二.实验操作 (1)在开始程序(或者桌面图标)中找到WEKA3.6.2,单击即可启动WEKA,启动WEKA 时会发现首先出现的一个命令提示符。接着将出现如下Weka GUI Chooser界面。 (2)选择GUI Chooser中的探索者(Explorer)用户界面。点击预处理(Preprocess)功能按钮的,Open file,选择其中的“weather”数据作关联规则的分析。打开“weather.arff”,可以看到“Current relation”、“Attributes”“Selected attribute”三个区域。 (3)点击“Classify”选项卡。单击左上方的Choose按钮,在随后打开的层级式菜单中的tree部分找到J48。 (4)选中J48分类器后,J48以及它的相关默认参数值出现在Choose按钮旁边的条形框中。单击这个条形框会打开J48分类器的对象编辑器,编辑器会显示J48的各个参数的含义。根据实际情况选择适当的参数,探索者通常会合理地设定这些参数的默认值。 三.实验结果:
计算正确率可得: (74+132)/(74+30+64+132)=0.69 四.实验小结: 通过本次试验,我学习了决策树分类方法,以及其中C4.5算法,并了解了其他ADtree、Id3等其它分类方法,应用Weka软件,学会导入数据文件,并对数据文件进行预处理,今后还需努力。 。
数据挖掘论文——决策树 1.什么是决策树 1.决策树(Decision Tree)是在已知各种情况发生概率的基础上,通 过构成决策树来求取净现值的期望值大于等于零的概率,评价项目 风险,判断其可行性的决策分析方法,是直观运用概率分析的一种 图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策 树。 2.决策树图示 1. 3.实例描述 1.女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。 2.这个女孩的决策过程就是典型的分类树决策。相当 于通过年龄、长相、收入和是否公务员对将男人分 为两个类别:见和不见。假设这个女孩对男人的要 求是:30岁以下、长相中等以上并且是高收入者或 中等以上收入的公务员,那么这个可以用下图表示 女孩的决策逻辑:
2. 4.决策树的组成 1.□——决策点,是对几种可能方案的选择,即最后选择的最佳方案。 如果决策属于多级决策,则决策树的中间可以有多个决策点,以决 策树根部的决策点为最终决策方案。[1] 2.○——状态节点,代表备选方案的经济效果(期望值),通过各状 态节点的经济效果的对比,按照一定的决策标准就可以选出最佳方 案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出 现的自然状态数目每个分枝上要注明该状态出现的概率。[1] 1.——结果节点,将每个方案在各种自然状态下取得的损益值 标注于结果节点的右端 5.决策树的构建 1.不同于贝叶斯算法,决策树的构造过程不依赖领域知识,它使用属 性选择度量来选择将元组最好地划分成不同的类的属性。所谓决策 树的构造就是进行属性选择度量确定各个特征属性之间的拓扑结 构。 2.构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点 处按照某一特征属性的不同划分构造不同的分支,其目标是让各个 分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集 中待分类项属于同一类别。分裂属性分为三种不同的情况:
河海大学物联网工程学院 《模式识别》 课程实验报告 学号 _______________ 专业 ____计算机科学与技术_____ 授课班号 _________________________ 学生姓名 ___________________ 指导教师 ___________________ 完成时间 _______________
实验报告格式如下(必要任务必须写上,可选的课后实验任务是加分项,不是必要任务,可不写): 实验一、Fisher分类器实验 1.实验原理 如果在二维空间中一条直线能将两类样本分开,或者错分类很少,则同一类别样本数据在该直线的单位法向量上的投影的绝大多数都应该超过某一值。而另一类数据的投影都应该小于(或绝大多数都小于)该值,则这条直线就有可能将两类分开。 准则:向量W的方向选择应能使两类样本投影的均值之差尽可能大些,而使类內样本的离散程度尽可能小。 2.实验任务 (1)两类各有多少组训练数据?(易) (2)试着用MATLAB画出分类线,用红色点划线表示(中) (3)画出在投影轴线上的投影点(较难) 3.实验结果 (1)第一类数据有200组训练数据,第二类数据有100组训练数据。 (2)如图所示,先得出投影线的斜率,后求其投影线的垂直线的斜率,即分类线的斜率,再求分类线的过的中垂点,加上即可得出。 画出红线代码:m = (-40:0.1:80); kw = w(2)/w(1); b = classify(w1, w2, w, 0); disp(b);
n = (-1/kw).* m + b; plot(m,n,'r-', 'LineWidth', 3); (3)画出投影上的投影点 如图,点用X表示。 代码: u = w/sqrt(sum(w.^2)); p1 = w1*u*u'; plot(p1(:,1),p1(:,2),'r+') p2 = w2*u*u'; plot(p2(:,1),p2(:,2),'b+') 实验二、感知器实验 1.实验原理 (1)训练数据必须是线性可分的 (2)最小化能量,惩罚函数法-错分样本的分类函数值之和(小于零)作为惩罚值(3)方法:梯度下降法,对权值向量的修正值-错分样本的特征向量 2.实验任务 (1)训练样本不线性可分时,分类结果如何?
数据挖掘技术与应用实验报告 专业:_______________________ 班级:_______________________ 学号:_______________________ 姓名:_______________________ 2012-2013学年第二学期 经济与管理学院
实验名称:SPSS Clementine 软件安装、功能演练 指导教师: 实验日期: 成绩: 实验目的 1、熟悉SPSS Clementine 软件安装、功能和操作特点。 2、了解SPSS Clementine 软件的各选项面板和操作方法。 3、熟练掌握SPSS Clementine 工作流程。 实验内容 1、打开SPSS Clementine 软件,逐一操作各选项,熟悉软件功能。 2、打开一有数据库、或新建数据文件,读入SPSS Clementine,并使用各种输出节点,熟悉数据输入输出。(要求:至少做access数据库文件、excel文件、txt文件、可变文件的导入、导出) 实验步骤 一实验前准备: 1.下载SPSS Clementine 软件安装包和一个虚拟光驱。 2.选择任意盘区安装虚拟光驱,并把下载的安装包的文件(后缀名bin)添加到虚拟光驱上,然后双击运行。 3.运行安装完成后,把虚拟光驱中CYGiSO文件中的lservrc文件和PlatformSPSSLic7.dll文件复制替换到安装完成后的bin文件中,完成破解,获得永久免费使用权。 4.运行中文破解程序,对SPSS Clementine 软件进行汉化。 二实验操作: 1、启动Clementine:从Windows 的“开始”菜单中选择:所有程序/SPSS Clementine 12.0/SPSS Clementine client 12.0 2、Clementine窗口当第一次启动Clementine 时,工作区将以默认视图打开。中间的区域称作流工作区。在Clementine 中,这将是用来工作的主要区域。Clementine 中绝大部分的数据和建模工具都在选项板中,该区域位于流工作区的下方。每个选项卡都包含一组以图形表示数据挖掘任务的节点,例如访问和过滤数据,创建图形和构建模型。 Clementine 中绝大部分的数据和建模工具都在选项板中,该区域位于流工作区的下方。每个选项卡都包含一组以图形表示数据挖掘任务的节点,例如访问和过滤数据,创建图形和构建模型。 要将节点添加到工组区,可在节点选项板中双击图标或将其拖拽至工作区后释
数据挖掘实验报告 班级统计121班学号姓名胡越 实验名称实验三:分类知识挖掘实验类型综合性实验 实验目的: (1)掌握利用决策树(C4.5算法)进行分类的方法。 (2)掌握利用朴素贝叶斯分类的方法。 实验要求: (1)对数据集bankdata.arff利用决策树(C4.5算法)进行分类,给出得出的决策树及分类器的性能评价指标,并利用建立的分类模型对下列表中给出的实例进行分类。 age sex region income married children car save_act current_act mortgage pep 21 MALE TOWN 5014.21 NO 0 YES YES YES YES 42 MALE INNER_CITY 17390.1 YES 0 NO YES YES NO 59 FEMALE RURAL 35610.5 NO 2 YES NO NO NO 45 FEMALE TOWN 26948 NO 0 NO YES YES YES 58 FEMALE TOWN 34524.9 YES 2 YES YES NO NO 30 MALE INNER_CITY 27808.1 NO 3 NO NO YES NO (2)对数据集bankdata.arff利用朴素贝叶斯分类方法进行分类,给出分类模型的参数及分类器的性能评价指标,并利用建立的分类模型对上表中给出的实例进行分类。 实验结果: (1) 分类器的性能评价指标: Kappa statistic 0.7942 age sex region income married children car save_act current_act mortgage pep 21 MALE TOWN 5014.21 NO 0 YES YES YES YES no 42 MALE INNER_CITY 17390.1 YES 0 NO YES YES NO no 59 FEMALE RURAL 35610.5 NO 2 YES NO NO NO yes 45 FEMALE TOWN 26948 NO 0 NO YES YES YES no 58 FEMALE TOWN 34524.9 YES 2 YES YES NO NO yes 30 MALE INNER_CITY 27808.1 NO 3 NO NO YES NO no
Bagging与AdaBoostM2的Matlab中的实现 在集成学习过去的研究中发现:Bagging集成学习算法和Boosting算法结合决策树基础学习器的实现的划分的效果是最好的。针对这种情况,我这次实现的问题就是在Matlab中利用决策树基础学习器实现Bagging集成学习算法和Boosting算法当前最流行的版本AdaBoostM2算法。 程序主要模块 Bagging集成学习算法的实现 下面主要介绍我的Bagging集成学习算法的实现程序,由于matlab直接集成了Bagging的决策树函数,所以Bagging实现很简单,只需对TreeBagger系统函数进行简单的参数设置就可以实现最强大的Bagging集成学习算法。我主要建了两个脚本文件实现Bagging集成学习算法,分别是classify.m文件和BaggingUseDT.m两个文件。 Classify函数 classify.m文件主要的功能是对建立好的集成学习器进行调用实现分类的目的。Classify 函数主要有三个输入参数和一个输出参数: 输入参数1:meas:代表的是训练集样本的属性矩阵,每一行代表一个样本的一组属性值。 输入参数2:species:代表的是训练集样本的真实类别列向量,species的行数由于meas 一致。 输入参数3:attList:代表的要进行分类的样本的一组属性值组成的行向量,该行向量的列数与meas矩阵的行数相同。 输出参数:class返回集成学习器判断attList向量对应的样本所属的类。BaggingUseDT函数 BaggingUseDT.m文件主要的功能是建立基于决策树的Bagging集成学习器,BaggingUseDT函数也有三个输入参数和一个输出参数。 输入参数1:X:代表的是训练集样本的属性矩阵,每一行代表一个样本的一组属性值。 输入参数2:Y:代表的是训练集样本的真实类别列向量,species的行数由于meas一致。 输入参数3:ens:返回利用训练集样本属性矩X和训练集样本的真实类别列向量Y训练得到的集成学习器。