分布式数据流分类关键技术研究
- 格式:pdf
- 大小:415.87 KB
- 文档页数:6

IDC中的关键技术如何高效地处理海量数据海量数据处理是当今信息时代的重要任务之一。
在互联网快速发展的背景下,海量数据对于企业、科研机构和政府部门来说至关重要。
然而,海量数据的存储、传输、分析和管理是一个复杂而艰巨的任务。
为了高效地处理海量数据,IDC(Internet Data Center)中的关键技术起着重要作用。
本文将重点介绍IDC中的关键技术,并探讨它们如何高效地处理海量数据。
一、分布式存储技术分布式存储技术是IDC中处理海量数据的基础。
为了解决数据的分布和容灾问题,分布式存储技术将数据存储在多个节点上。
它通过数据分片、冗余备份和负载均衡来实现数据的高可用性和可扩展性。
分布式文件系统(DFS)和分布式数据库(DDB)是常用的分布式存储技术。
1. 分布式文件系统分布式文件系统是一种将文件划分为多个块,并在多个存储节点上进行分布存储的系统。
它通过文件的分片和冗余备份,实现了文件的高可用性和高吞吐量。
常见的分布式文件系统包括Hadoop Distributed File System(HDFS)和GlusterFS。
2. 分布式数据库分布式数据库是一种将数据划分为多个分片,并在多个节点上进行分布存储和处理的数据库系统。
它通过数据分片和负载均衡,实现了数据的高并发访问和高扩展性。
常见的分布式数据库包括Apache Cassandra和MongoDB。
二、数据传输和通信技术数据传输和通信技术是IDC中处理海量数据的关键技术之一。
在IDC中,海量数据的传输和通信需要考虑带宽、延迟和网络拓扑等因素。
1. 高速网络为了满足海量数据传输的需求,IDC中采用了高速网络技术。
例如,光纤通信技术可以提供更高的传输速度和带宽,以满足数据中心内部和数据中心之间的数据传输需求。
2. 数据压缩和加密为了降低海量数据的传输成本和保护数据的安全性,IDC中采用了数据压缩和加密技术。
数据压缩可以降低数据的传输量,提高传输效率;数据加密可以保护数据的机密性和完整性。

引言:随着信息技术的快速发展,大数据已经成为了当前社会经济发展的重要驱动力。
而在大数据的背后,有许多关键技术支撑着它的发展。
本文将详细阐述大数据的关键技术,并分析其在实际应用中的重要性。
概述:大数据是指数据量规模巨大,类型繁多,处理速度快的数据集合。
在处理大数据时,关键技术起着至关重要的作用。
这些关键技术包括存储技术、计算技术、分析技术、挖掘技术和隐私保护技术。
下面将逐一进行详细阐述。
正文:一、存储技术1. 分布式文件系统:分布式文件系统通过将大数据分布在多个物理节点上,实现数据的存储和管理。
典型的分布式文件系统包括Hadoop Distributed File System(HDFS)和Google File System (GFS)。
2. 分布式数据库:分布式数据库是指将数据分布在多个节点上进行存储和管理的数据库系统。
典型的分布式数据库包括Apache Cassandra和MongoDB等。
3. 列式存储:列式存储是一种将数据按照列进行存储的方式,相比于传统的行式存储,它能够提供更高的查询性能。
HBase和Cassandra等数据库采用了列式存储的方式。
二、计算技术1. 分布式计算:分布式计算是指将计算任务分布在多个计算节点上进行并行计算的技术。
Apache Spark和MapReduce是常用的分布式计算框架。
2. 并行计算:并行计算是指将一个大任务划分成多个子任务,并且这些子任务可以并行地进行计算。
典型的并行计算模型有共享内存模型和消息传递模型。
3. 可扩展性:可扩展性是指系统在面对大规模数据时,能够保持高性能和低延迟的能力。
具备良好可扩展性的系统能够自动根据工作负载的增加或减少来调整资源的分配。
三、分析技术1. 数据预处理:大数据分析的第一步是进行数据预处理,包括数据清洗、数据集成和数据转换等过程,以确保数据的质量和准确性。
2. 数据挖掘:数据挖掘是指从大数据中发现潜在模式、关联规则和异常值等有价值的信息。


研究数据流处理的方法与技术随着信息技术的不断发展,数据的收集和处理成为一项重要的任务。
而数据流处理(Data Stream Processing)则是处理连续的数据流的一种方法。
它已广泛应用于各种领域和行业,例如金融、电信、医疗等。
在本文中,我们将讨论数据流处理的方法和技术,并讨论未来的发展趋势。
一、数据流和数据流处理在数据流处理之前,我们需要先了解什么是数据流。
数据流指的是按照时间顺序形成的无限序列。
数据流通常是动态生成的,并且可以和传统的数据不同,因为它们可能有不同的特点,如高速率、持续性、不可重复性和不确定性等。
而数据流处理则是一种实时的数据处理技术,它可以分析和处理大量的数据流。
例如,当我们使用其他数据处理技术解析静态数据时,必须先存储整个数据集,然后再对其进行数据处理。
然而,数据流处理不需要存储完整的数据集,而是在数据流中实时处理数据,并根据流中的当前数据更新相应的结果。
二、数据流处理的方法在数据流处理中,主要有两种方法:流水线和事件流。
1.流水线方式流水线方式将数据流分成一系列的处理步骤,并在每个步骤中进行一定的数据转换和处理。
每个步骤的输出将成为下一个步骤的输入。
在流水线方式中,每个处理步骤都是独立的,并且可以同时执行。
流水线方式的优点是结构简单,具有很强的扩展性和适应性。
但是,流水线方式也存在一些问题,例如,如果数据流中的某个处理步骤非常耗时,整个流水线处理过程可能会非常缓慢。
2.事件流方式事件流方式将数据流组织为一系列事件。
每个事件包含一定的属性,例如事件发生的时间、地点以及相关联的数据等。
在事件流方式中,我们可以通过定义事件的规则来处理数据流。
例如,如果某个事件满足一定的条件,则我们可以触发一个特定的动作。
三、数据流处理的技术在数据流处理中,有许多技术可以用于数据分析和处理。
1.窗口技术窗口技术可以将数据流分成不同的时间段,然后在每个时间段内聚合和分析数据。
窗口类型通常包括滑动窗口和固定窗口。

分布式云数据中心架构及管理关键技术黄峰【摘要】目前业界流行的云计算旨在解决单个云数据中心的问题,而无法解决多个云数据中心之间资源共享、统一管理、提升业务服务质量的问题。
为此,提出了分布式云数据中心( DC2)的概念及架构,并研究了分布式云数据中心的管理及服务的关键技术。
分布式云数据中心能将传统数据中心的分散、分层、异构架构,改为全扁平式、统一资源管理的分布式云数据中心架构,从而将多个不同地域、不同阶段、不同规模的单体云数据中心所有资源,通过逻辑集中进行统一管理、统一运营,最终使云数据中心更高效、更可靠、更绿色。
%At present, the popularized cloud calculation in professional field can solve the issue of individual cloud data center, but cannot solve the issue among multiple cloud data centers, such as resource sharing, unified management, and upgrading the quality of business services. Thus the concept and architecture of distributed cloud data center( DC2 ) is proposed, and the critical technologies for management and services of the distributed cloud data center are researched. The distributed cloud data center can change the traditional data centers with scattered, hierarchical and heterogeneous architectures into distributed cloud data center with a whole flat architecture and unified resource management. The solution proposed makes all the resources in multiple individual cloud data centers located in different regions, different stages, and different scales integrated logically for unified management and operation, to reach the status of higherefficient, more reliable and more environment protection for cloud data center.【期刊名称】《自动化仪表》【年(卷),期】2014(000)008【总页数】5页(P1-4,9)【关键词】分布式云数据中心(DC2);数据中心即服务(DCaaS);管理即服务(MaaS);网络即服务(NaaS);存储虚拟化;网络虚拟化【作者】黄峰【作者单位】上海仪电电子集团公司,上海 200233【正文语种】中文【中图分类】TP302+.1Network as a service(NaaS) Storage virtualization Network virtualization 当前,云计算对于IT行业来说是一个巨变,就像用电网代替本地发电机一样。

分布式数据库技术分布式数据库技术是指将数据库系统分布在多个计算机节点上,以实现分布式数据管理和处理的一种技术。
它通过将数据库拆分为多个分片,并在不同的计算机节点上存储和处理这些分片的数据,从而提高数据处理的效率、可靠性和可扩展性。
本文将探讨分布式数据库技术的原理、应用、挑战以及未来发展方向。
一、分布式数据库技术的原理1. 数据分片在分布式数据库中,数据通常被划分为多个分片。
每个分片包含一部分数据,并且可以存储在不同的计算机节点上。
数据分片可以按照不同的策略进行,比如基于哈希、范围、复制等方式进行划分。
数据分片的目的是将数据均匀地分布在各个节点上,以实现负载均衡和提高系统的并行处理能力。
2. 数据复制为了提高系统的容错性和可靠性,分布式数据库通常会采用数据复制的方式。
数据复制是指将数据的副本存储在多个节点上,以防止数据丢失或节点故障导致的数据不可用。
数据复制可以通过同步复制或异步复制的方式进行,同步复制要求所有副本的一致性,而异步复制则允许有一定的延迟。
3. 数据一致性在分布式数据库中,数据一致性是一个重要的问题。
由于数据分片和数据复制的存在,不同节点上的数据可能会发生冲突或不一致的情况。
因此,分布式数据库需要采用相应的一致性协议,如分布式事务、多版本并发控制等,来保证数据的一致性和可靠性。
二、分布式数据库技术的应用1. 大规模Web应用随着互联网的快速发展,大规模Web应用对数据处理和存储的需求越来越大。
分布式数据库技术可以帮助大规模Web应用实现高并发、高可用的数据处理和存储,提高系统的性能和用户的体验。
2. 云计算和大数据云计算和大数据技术的兴起,对分布式数据库提出了更高的要求。
分布式数据库可以为云计算和大数据提供高性能、可扩展的数据存储和处理能力,支持大规模数据的分布式管理和分析。
3. 分布式事务处理分布式事务处理是分布式数据库技术的一个重要应用领域。
分布式事务处理涉及多个数据库节点之间的事务一致性和隔离性问题,需要采用分布式事务管理协议和算法来解决。

基于分布式系统的数据并行处理技术研究一、简介随着大数据时代的到来,数据处理的难度越来越大,传统的数据处理方式已经无法满足现代社会对数据分析的需求,需要使用分布式系统来解决数据处理的问题。
分布式系统的数据并行处理技术主要是指将大数据集合拆分成多个小数据集合,每个小数据集合可以在不同的节点上并行处理,最后将结果汇总为一个整体。
本文将围绕基于分布式系统的数据并行处理技术进行研究。
二、分布式系统分布式系统是由多台计算机组成的系统,这些计算机可以在不同的地理位置上,通过网络相互连接,共同完成一项任务。
分布式系统的目的是提高计算机系统的可靠性、可扩展性、可维护性和性能。
分布式系统中最常见的两个特点是分布和并行。
在分布式系统中,任务可以分为多个子任务,分派到多个计算机上并行执行,从而实现高效的计算。
三、数据并行处理在大规模数据处理中,所有计算机节点共同处理整个数据集,一旦其中一个节点出现故障,整个任务将被破坏,使得整个系统无法运行。
分布式系统的数据并行处理技术可以将大数据集合拆分成多个小数据集合,每个小数据集合可以在不同的节点上并行处理,从而大大提高了计算效率,减少了数据集合的处理时间。
数据并行处理可以使得代码更加简单,计算效率更高,而且可以很好的支持分布式系统。
四、数据并行处理的核心技术数据并行处理的核心在于分发任务和数据并行计算。
1.分发任务分发任务是指将整个任务划分为多个子任务,并将这些子任务分配到各个计算机节点上平行处理。
在这个过程中,最重要的问题是负载均衡。
如果一个节点的工作负载过高,它的处理速度会变慢,这将导致整个系统的速度降低。
分布式系统通过将任务分配给各个节点以平衡负载。
负载平衡通常需要解决两个问题:- 如何将任务动态地分配给不同的节点- 如何避免冗余的流量并通过网络传输问题来最小化开销2.数据并行计算数据并行计算是指将整个数据情况分成多个小的数据集合,并将这些数据集合分发到不同的节点上并行处理,最后将结果进行汇总。

分布式系统技术的研究和应用随着信息技术的快速发展,我们身处的数字化世界正在经历前所未有的变革。
在这个背景下,分布式系统技术逐渐成为了一种重要的技术手段,被广泛应用于各种应用场景中。
本文将对分布式系统技术的研究和应用进行探讨。
一、分布式系统技术的定义分布式系统技术是指将一个大型系统分割成为多个独立的部分,并且这些部分可以在不同的计算机上运行,相互协作以完成整个系统的功能。
分布式系统的核心在于多个实体通过网络互相协作,将各自处理的数据、计算结果传输给其他实体,而整个系统的动态性、可靠性、可扩展性、安全性等也得以保障。
二、分布式系统技术的研究方向在分布式系统技术的研究方向中,主要包括分布式计算、分布式存储、分布式通信等多个领域。
1、分布式计算分布式计算是指在多个计算机上分布式地执行计算任务,以达到提高计算效率和处理能力的目的。
分布式计算的重点在于任务的分解和调度,如何将任务分解为多个子任务,并且如何解决任务之间的依赖关系和结果的整合。
分布式计算相关的技术包括任务分解、任务调度、数据管理、结果收集等。
2、分布式存储分布式存储是指将大量数据分散保存在多个节点上,并且利用网络协议将这些节点组织成一个分布式存储系统,以达到数据备份、高可用、负载均衡等目的。
分布式存储的关键在于数据的分区、分片和备份策略,以及数据的读写一致性问题等。
分布式存储相关的技术包括数据分区、数据备份、数据一致性控制、容错处理等。
3、分布式通信分布式通信是指将多个计算机通过网络协议连接在一起,以形成一个分布式系统,并实现各个节点之间的消息传递、数据交换等功能。
分布式通信的关键在于网络传输协议、消息格式、消息路由等。
分布式通信相关的技术包括网络协议、消息编解码、消息路由、QoS控制等。
三、分布式系统技术的应用场景分布式系统技术可以广泛应用于各领域的分布式应用中,如大规模数据处理、云计算、大数据分析、移动互联网、物联网、分布式数据库等。
以下是分布式系统技术在不同领域的典型应用:1、大规模数据处理在大规模数据处理领域,分布式系统技术可以被用于构建分布式计算平台,如Hadoop和Spark等。

分布式系统常用技术及案例分析随着互联网和移动互联网的快速发展,分布式系统成为了大规模数据处理和高并发访问的重要技术手段。
分布式系统能够充分利用多台计算机的资源,实现数据存储和计算任务的分布式处理,提高系统的可靠性和扩展性。
本文将围绕分布式系统的常用技术和相关案例进行分析,希望能够为读者提供一些参考和启发。
首先,我们来介绍一些常用的分布式系统技术。
分布式文件系统是分布式系统的重要组成部分,它能够将文件存储在多台计算机上,并提供统一的文件访问接口。
Hadoop分布式文件系统(HDFS)就是一个典型的分布式文件系统,它采用了主从架构,将大文件分割成多个块存储在不同的计算节点上,实现了高可靠性和高吞吐量的文件存储和访问。
另外,分布式计算框架也是分布式系统中的关键技术之一。
MapReduce是一个经典的分布式计算框架,它能够将大规模的数据集分解成多个小任务,并在多台计算机上并行处理这些任务,最后将结果汇总起来。
通过MapReduce框架,用户可以方便地编写并行计算程序,实现大规模数据的分布式处理。
除了以上介绍的技术之外,分布式数据库、分布式消息队列、分布式缓存等技术也是分布式系统中常用的组件。
这些技术能够帮助系统实现数据的高可靠性存储、实时消息处理和高性能的数据访问。
在实际的系统设计和开发中,根据具体的业务需求和系统规模,可以选择合适的分布式技术来构建系统架构。
接下来,我们将通过一些实际案例来分析分布式系统的应用。
以电商行业为例,大型电商平台需要处理海量的用户数据和交易数据,这就需要构建高可靠性和高性能的分布式系统。
通过采用分布式文件系统存储用户数据和商品信息,采用分布式计算框架实现数据分析和推荐系统,再配合分布式缓存和消息队列实现实时交易处理,可以构建一个完善的分布式系统架构。
另外,互联网金融领域也是分布式系统的重要应用场景。
互联网金融平台需要处理大量的交易数据和用户行为数据,保障数据的安全性和一致性是至关重要的。
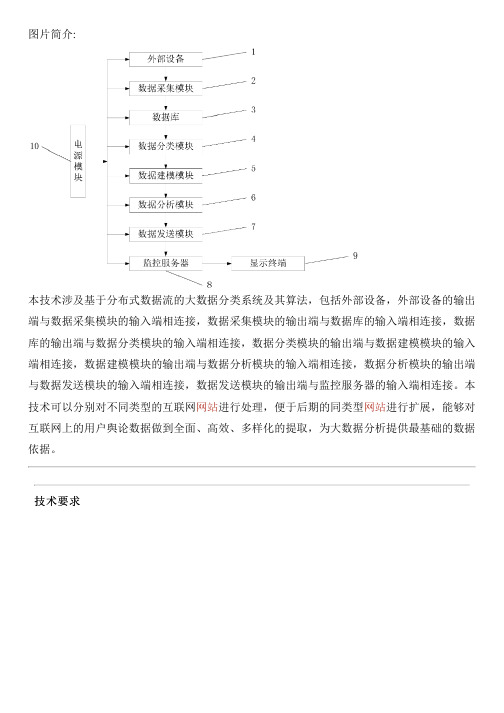
图片简介:本技术涉及基于分布式数据流的大数据分类系统及其算法,包括外部设备,外部设备的输出端与数据采集模块的输入端相连接,数据采集模块的输出端与数据库的输入端相连接,数据库的输出端与数据分类模块的输入端相连接,数据分类模块的输出端与数据建模模块的输入端相连接,数据建模模块的输出端与数据分析模块的输入端相连接,数据分析模块的输出端与数据发送模块的输入端相连接,数据发送模块的输出端与监控服务器的输入端相连接。
本技术可以分别对不同类型的互联网网站进行处理,便于后期的同类型网站进行扩展,能够对互联网上的用户舆论数据做到全面、高效、多样化的提取,为大数据分析提供最基础的数据依据。
技术要求1.基于分布式数据流的大数据分类系统,其特征在于,包括外部设备(1),所述外部设备(1)的输出端与数据采集模块(2)的输入端相连接,所述数据采集模块(2)的输出端与数据库(3)的输入端相连接,所述数据库(3)的输出端与数据分类模块(4)的输入端相连接,所述数据分类模块(4)的输出端与数据建模模块(5)的输入端相连接,所述数据建模模块(5)的输出端与数据分析模块(6)的输入端相连接,所述数据分析模块(6)的输出端与数据发送模块(7)的输入端相连接,所述数据发送模块(7)的输出端与监控服务器(8)的输入端相连接,所述监控服务器(8)的输出端与显示终端(9)的输入端相连接。
2.如权利要求1所述的基于分布式数据流的大数据分类系统,其特征在于,还包括电源模块(10),所述电源模块(10)均与外部设备(1)、数据采集模块(2)、数据库(3)、数据分类模块(4)、数据建模模块(5)、数据分析模块(6)、数据发送模块(7)和监控服务器(8)电性连接。
3.如权利要求2所述的基于分布式数据流的大数据分类系统,其特征在于,所述电源模块(10)为锂电池或者太阳能电池板。
4.如权利要求1所述的基于分布式数据流的大数据分类系统,其特征在于,所述数据库(3)包括若干个数据存储模块。

实时数据流处理中的流式计算与分布式处理策略在当今大数据时代,实时数据处理变得越来越重要。
实时数据流处理是一种处理连续流数据的方式,它可以快速而准确地分析、处理和提取有用的信息。
在实时数据流处理的过程中,流式计算和分布式处理策略是两个核心概念。
流式计算是指对流数据进行实时处理和计算的过程。
与传统的批处理不同,流式计算能够快速处理数据,并即时生成结果。
流式计算通常基于流数据的特点,它可以处理无限的数据流,而不需要事先知道数据的总量或到达时间。
流式计算可以实时地对数据进行过滤、聚合、计算和转换,从而得到有用的信息。
在实时数据流处理中,分布式处理策略是实现高效处理的关键。
分布式处理是将任务分发给多个计算节点,并将结果合并起来,以加快处理速度。
分布式处理能够充分利用多台计算机的计算资源,实现大规模数据的快速处理。
在分布式处理中,计算节点之间通过通信来交换数据和共享计算结果。
这样的分布式处理架构可以实现高可靠性和可扩展性,并能够适应不断增长的数据规模。
为了实现流式计算和分布式处理,一些流行的技术和工具被广泛使用。
Apache Kafka是一种开源的流式处理平台,它可以实现高吞吐量的实时数据流处理。
Kafka可以将数据流分发给多个消费者,并将结果写入到分布式存储系统中。
同时,Apache Flink是另一个流式计算框架,它支持快速而准确的数据流处理,并提供了丰富的操作符和API。
使用Flink,可以方便地进行流式处理和分布式计算。
在实时数据流处理中,处理大规模数据的效率和性能是非常关键的。
为了实现高效的数据处理,通常需要考虑以下几个方面的策略:1. 数据分区和并行计算:将数据划分成多个分区,并在多个计算节点上进行并行计算,可以充分利用计算资源,提高处理速度。
2. 任务优化和负载均衡:根据任务的复杂度和计算资源的可用性,优化任务的调度和分配,以确保计算节点的负载均衡,避免资源浪费和任务堵塞。
3. 状态管理和容错机制:在处理实时数据流时,通常需要维护一些状态信息。


大数据分析知识:分布式大数据处理的技术和实现方案随着Internet和云计算的兴起,大数据已经成为各个行业的热门话题,通过大数据分析可以发掘客观的信息,并给企业带来巨大的商业价值。
由于数据量的增大和数据之间的关系变得更加复杂,传统的数据处理方式已经无法满足实际需求,因此分布式大数据处理成为了当前行业主流的技术方案之一。
一、分布式大数据处理技术分布式大数据处理是将一段数据分割成小块,由多台计算机分别处理,最后再将处理结果合并起来的一种处理方式。
这种方式具备以下几个优点:1.效率:由于分布式处理可以在多台计算机上同时执行,因此可以大大缩短处理时间,提升数据分析效率。
2.可扩展性:随着数据量的增长,分布式处理可以简单地增加处理节点,而无需改变现有的架构,从而轻松实现可扩展性。
3.可靠性:由于分布式处理可以通过副本和容错机制保证数据的可靠性,即使某个节点出现问题,也可以保证数据不会丢失。
目前常用的分布式大数据处理技术主要包括Hadoop、Spark和Flink等。
1. HadoopHadoop是一个由Apache组织开发的分布式大数据处理框架,可以支持海量数据的处理和存储,具有快速、可靠和高效的处理能力。
Hadoop主要包括HDFS和MapReduce两个主要组成部分。
其中,HDFS用于数据存储,将数据分成块后存储在多个节点上,通过数据副本和故障转移来保证数据的可靠性。
而MapReduce则用于数据处理,将数据放到各个节点上进行计算,将每个节点上的数据处理结果合并起来得到最终结果。
2. SparkSpark是一个由Apache开源组织开发的基于内存的分布式大数据处理框架,它可以使得分布式大数据处理更加高效,有着比Hadoop更优秀的处理速度和性能。
Spark支持多种数据处理模式,包括批处理、交互式处理、流处理等。
Spark的核心框架由Spark Core、Spark SQL、Spark Streaming 和MLlib等几个主要模块组成。

分布式数据库技术路线及方案分类数据库的重要性:数据库作为大多数信息系统的基础设施,向下发挥硬件算力,向上使能上层应用,是IT行业中大厦的地基、飞船的引擎、更是开发者的必备武器。
数据库的速度、易用性、稳定性、扩展性、成本都对企业的基础业务与增长弹性至关重要。
假如数据库从未诞生,程序员需要面对海量的数据关系与不可靠的计算机系统。
而在数据库的基础上,程序员不需要重新设计复杂的系统流程保证数据处理的事务性,转而只需要增删改查CRUD的简单操作,大大降低了数据存储与处理的复杂性。
数据库的定义与分类:是按照特定数据结构组织,存储和管理数据的基础软件。
分布式数据库是用计算机网络将物理上分散的多个数据库单元连接起来组成的一个逻辑上统一的数据库。
本篇报告从分布式架构的视角出发,多方位关注数据库行业的前沿动向。
分布式数据库概念及技术发展沿革:数据库已经经历了半个世纪的发展,经历了学术界驱动、商业化落地、论文工业实现、企业应用需求驱动等技术发展阶段。
从一开始的层面模型,网状模型,关系模型,到对象模型,对象关系模型,半结构化等,数据模型一直是数据库的核心和理论基础,而扎实的理论支撑和更佳的逻辑独立性仍然将是未来数据库的根本。
在商业化落地后,Oracle带着MySQL、微软的SQL Server等领衔关系型数据库占领市场多年。
从SQL、NoSQL到NewSQL,甚至是HTAP,都在迭代中推动着业务能力的发展。
当前,云+分布式已经成为了企业极限需求的唯一解决方案,并造就了当前数据库行业的爆发期。
在当前与持续的行业周期中,先进的产品与技术都需要围绕市场,才能成为最重要的竞争优势。
分布式数据库行业支撑体系:中国分布式数据库的发展取得了人口红利。
而技术创新需要先进的学术研究体系,产研结合需要紧密的产业交流,行业渗透则需要紧跟时代需求的人才培训体系。
中国数据库产品图谱:中国数据库厂商分为传统数据库厂商、新兴数据库厂商、云厂商、ICT跨界厂商四类,各家提供不同的集中式数据库与分布式数据库产品中国数据库厂商及代表数据库产品传统数据库厂商达梦数据库。

PTN原理及关键技术PTN(Packet Transport Network)是一种基于数据包交换技术的新一代传输网络,其原理和关键技术主要包括网络拓扑结构、数据包交换、流量控制和服务质量保证等。
下面将详细介绍PTN的原理及关键技术。
1.网络拓扑结构PTN的网络拓扑结构通常包括中心节点(Core Node)和边缘节点(Edge Node)。
中心节点负责整个网络的核心交换和路由功能,边缘节点则负责连接用户设备与核心网络之间的转发任务。
这种分布式结构能够有效降低网络时延和提高网络吞吐量。
2.数据包交换PTN采用数据包交换技术进行数据传输,将用户数据进行分组并封装成数据包进行传送。
数据包中包含了源地址、目标地址、有效载荷和校验码等信息。
在传输过程中,数据包经过一系列中转节点按照目标地址进行转发,最终到达目标设备。
3.流量控制PTN通过流量控制机制来管理网络中的数据流量,以确保网络资源的合理利用和数据传输的稳定性。
流量控制主要包括拥塞控制、队列管理和流量优化等方面的技术。
拥塞控制通过监测网络负载和延迟,动态调整传输速率,避免网络拥塞。
队列管理则通过对数据包进行排队和调度,避免数据包丢失和延迟增加。
4.服务质量保证PTN通过一系列的服务质量保证技术,提供多种不同的服务质量等级,满足不同应用场景下的数据传输需求。
这些技术包括流量分类、带宽分配、优先级队列和延迟保证等。
流量分类将网络数据流按照不同的服务质量需求进行分类,以便在网络中进行差异化服务。
带宽分配是指按需分配网络带宽,确保每个数据流都能获得足够的带宽资源。
优先级队列则根据数据流的优先级进行队列调度,保证高优先级的数据能够优先传输。
延迟保证则通过控制网络传输时延,保证需要低延迟的数据能够及时传输。
5.多层次的网络管理在PTN中,多层次的网络管理是实现网络可靠性和稳定性的关键技术之一、多层次网络管理包括网络监控、故障管理、配置管理、性能管理和安全管理等方面的技术。

分布式数据库的设计与优化研究随着互联网的迅猛发展和大数据时代的来临,分布式数据库成为了处理海量数据和提供高并发服务的重要技术。
本文将深入探讨分布式数据库的设计与优化研究,包括数据分片、一致性与可用性、负载均衡和性能优化等方面。
1. 数据分片在分布式数据库中,数据分片是将海量数据按照某种规则划分为多个分片,分别存储在不同的节点上。
合理的数据分片方案可以提高数据库的读写性能,并且能够支撑更大规模的数据存储。
常见的数据分片策略有垂直切分和水平切分。
垂直切分是根据数据的业务属性将不同的列或表拆分到不同的节点上,使得每个节点只负责部分数据的存储和查询。
这样可以减少单个节点的负载,提高数据库的并发处理能力。
然而,垂直切分会导致跨节点查询变得复杂,需要进行数据合并和关联查询。
水平切分是将数据按照某个规则拆分为多个分片,每个分片存储一部分数据。
水平切分可以通过数据的范围、哈希或者一致性哈希等方式进行。
水平切分可以有效地提高查询和写入的性能,但是需要解决数据平衡、数据迁移和跨节点查询等问题。
2. 一致性与可用性在分布式数据库中,一致性与可用性一直是一个矛盾的问题。
一致性要求分布式数据库的各个节点之间达成一致的数据状态,而可用性则要求数据库能够在部分节点故障的情况下继续提供服务。
常见的实现一致性的方法有两阶段提交(2PC)和三阶段提交(3PC)等。
2PC是指将分布式事务分为准备阶段和提交阶段,通过协调者节点来实现事务的一致性。
3PC在2PC的基础上引入了准备阶段的超时机制,提高了错误恢复的效率。
为了提高分布式数据库的可用性,通常会采用主从复制和多主复制的方式。
主从复制是指一个节点作为主节点负责写入操作,其他节点作为从节点负责复制主节点的数据。
多主复制则是多个节点同时作为主节点处理写入操作,并通过同步协议实现数据的一致性。
3. 负载均衡分布式数据库要实现高性能和高可用性,负载均衡是必不可少的。
负载均衡可以将客户端的请求均匀地分发到不同的节点上,从而提高系统的整体性能和可扩展性。

分布式数据库技术的研究与应用一、概述随着物联网、大数据和云计算等技术的不断发展,数据的存储和管理变得越来越困难。
在这种背景下,分布式数据库技术逐渐成为了解决数据处理问题的重要手段。
本文主要介绍分布式数据库技术的研究现状及其在实际应用中的表现。
二、分布式数据库技术的基本原理1. 数据分片数据分片是分布式数据库技术的基础,它将数据库中的数据按照一定的规则分成多个片段,将这些片段分别存储在不同的节点上。
在数据查询时,分布式数据库系统通过查询每个节点上的数据片段,最终将结果集合并返回。
2. 数据复制为了保证数据的可靠性和高可用性,分布式数据库系统一般会将数据进行复制。
将每个分片的数据分别复制到多个节点上,以提高系统的数据可靠性和可用性。
3. 数据同步数据同步是分布式数据库系统中的一个核心问题。
在每个节点的数据进行修改、添加、删除操作时,需要将这些变更操作同步到其他节点,以保证所有节点的数据一致性。
4. 数据查询优化分布式数据库系统的数据查询需要涉及多个节点,因此在查询优化方面需要考虑多个节点中数据的分布和不同节点之间的通讯成本等因素。
三、分布式数据库技术的研究现状目前,国内外学者已经对分布式数据库技术进行了广泛的研究,并提出了多种不同的解决方案。
其中,以下几种方案是比较典型的:1. 垂直分片在垂直分片方案中,将不同的数据表分得很细,并将其存储在不同的节点上。
此方案适用于各个节点上的数据结构差异较大的情况,例如OLAP(On-Line Analytical Processing)场景中的数据仓库。
2. 水平分片在水平分片方案中,将同一个数据表中的数据分为多个片段,每个片段存储在不同的节点上。
此方案适用于各个节点上的数据结构基本相同的情况,例如OLTP(On-Line Transaction Processing)场景中的电子商务系统。
3. 数据复制方案数据复制方案将每个分片的数据复制到多个节点上,以提高系统的数据可靠性和可用性。

大数据处理与分析的前沿技术在当今信息时代,数据处理与分析技术越来越成为各行各业探索和解决问题的重要手段。
特别是在大数据时代,这项技术更是发挥着越来越重要的作用。
本文将就大数据处理与分析的前沿技术展开探讨。
一、大数据处理技术随着互联网时代的到来,数据的产生量与数据的处理难度急剧增加,所以如何有效地处理这些庞大的数据成为了各行各业面临的共同问题。
幸运的是,各种大数据处理技术逐渐发展起来。
1. 分布式计算技术分布式计算技术是指把庞大的计算任务分解成若干个较小的计算任务,再将其分配给多个计算机进行并行计算的技术。
通过使用分布式计算技术,可以缩短数据处理时间,提高计算效率。
2. 内存计算技术内存计算技术是指直接使用内存进行计算,而非使用磁盘进行读写,在数据处理过程中,常用的数据都被加载到内存中,从而大大提高了数据的处理速度。
3. 数据流技术数据流技术是指用户在不等待传统批处理的结果的情况下,以数据流的方式实时处理数据,使数据可以更快地到达数据仓库并分析处理,从而使数据处理的效率更高。
4. 数据可视化技术数据可视化技术是指使用图表、图形等方式直观呈现数据,使得数据更加直观易懂,便于分析与处理。
二、大数据分析技术大数据分析技术是指针对庞大的数据进行深度挖掘和分析的技术。
在这个时代,大数据技术不仅仅应用于互联网公司,其他企业也纷纷走上了大数据分析的道路。
以下介绍一下现在最流行的大数据分析技术。
1. 数据挖掘技术数据挖掘技术是指通过各种方法和工具,从数据中提取有价值的信息,并转化为可接受的形式,例如规则、模型、模式等。
数据挖掘技术主要用于数据检索、数据分析、市场分析、预测和分类等领域。
2. 机器学习技术机器学习技术是指使用包括人工神经网络、决策树、聚类等算法的强大系统,使计算机可以自主地学习和改进其性能,从而实现更高级的学习功能。
机器学习技术的应用领域非常广泛,例如自然语言处理、图像识别、数据分类、预测分析等领域。

大数据数据分布式存储关键技术
大数据的分布式存储关键技术主要包括以下几个方面:
1. 分布式文件系统:大数据需要分布式文件系统来存储和管理海量的数据。
Hadoop Distributed File System (HDFS) 是目前最常用的分布式文件系统之一,它可以将数据分散存储在多个节点上,并提供高可用性和容错能力。
2. 数据分片和分区:为了提高数据存储和处理的效率,大数据需要将数据进行分片和分区存储。
分片是将数据划分为多个较小的块,分区是将数据按照某种规则划分为多个独立的部分。
这样可以将数据进行并行处理,加速数据的读写和计算。
3. 数据冗余备份:为了保证数据的可靠性和容错能力,大数据需要对数据进行冗余备份。
通过将数据复制到多个节点上,可以防止数据丢失和节点故障导致的数据不可用问题。
4. 数据一致性和同步:由于分布式存储涉及到多个节点,节点之间需要保持数据一致性和同步。
这涉及到数据复制、数据同步和数据处理等方面的技术,确保多节点之间的数据一致性。
5. 数据索引和查询:大数据的存储需要支持高效的数据索引和查询。
通过建立索引,可以提高数据的检索速度和查询效率,提供更快的响应时间。
6. 负载均衡和故障恢复:分布式存储需要考虑负载均衡和故障恢复机制。
负载均衡可以将数据均匀分配到各个节点上,避免
单点压力过大;故障恢复可以保证在节点故障时,数据能够自动迁移到其他节点上,保证业务的连续性。
以上技术是大数据分布式存储关键技术的一部分,还有很多其他的技术也在不断发展和演进。
大数据的分布式存储技术是多领域的综合技术,涉及到分布式系统、数据库、网络通信、并行计算等多个领域的知识和技术。

物联网中的数据流分类与处理技术研究随着物联网技术的不断发展,数据流的分类与处理技术越来越受到重视。
物联网中的设备、传感器等都会产生大量的数据流,如果不加以分类和处理,这些数据流就会成为噪音,对于对应的应用产生干扰。
因此,有必要对物联网中的数据流进行分类与处理。
一、物联网中数据流的分类物联网中的数据流主要可以分为四类:1. 时间序列数据:时间序列数据是根据时间顺序存储的数据,如传感器采集的温度、湿度、气压等数据。
时间序列数据的特点是具有连续性和周期性,需要专门的算法进行处理。
2. 图像与视频数据:图像与视频数据是物联网中产生的另一类数据,这类数据需要进行图像处理、识别、分类等处理。
例如,通过监控摄像头捕捉到人脸,需要对人脸数据进行处理,以识别人脸的特征。
3. 位置数据:位置数据是指设备或用户在空间中的位置信息,例如GPS数据、Wi-Fi数据等。
这类数据需要进行定位、轨迹跟踪等处理。
4. 交互数据:交互数据是指物联网设备和用户之间交互产生的数据,例如用户在智能音箱上的语音指令。
这类数据需要进行语音识别、自然语言处理等处理。
二、物联网中数据流的处理技术针对不同类型的数据流,需要采用不同的处理技术。
下面列举了常见的数据流处理技术。
1. 时间序列数据处理时间序列数据处理主要包括峰值检测、周期性检测、事件检测等。
这些技术可以让我们了解温度、湿度等数据的趋势和变化,从而更好地了解设备的状态。
另外,时间序列数据处理还可以进行预测和异常检测,这些技术可以在设备状态异常时及时发现问题并解决。
2. 图像与视频数据处理对于图像和视频数据,处理技术包括图像识别、图像分类、目标检测等。
这些技术可以用于人脸识别、车牌识别、场景分类等应用。
另外,对于视频数据,还可以进行运动检测、行为分析、智能监控等处理。
3. 位置数据处理位置数据处理技术主要包括定位算法、轨迹推荐等。
通过对用户位置数据的处理,可以实现电子围栏、定位导航等功能。