Linux内核崩溃原因分析及错误跟踪技术
- 格式:pdf
- 大小:377.05 KB
- 文档页数:8

Linux Kernel Sysdump(系统转储)是一个在系统遇到严重错误时收集系统状态信息的机制,它可以帮助开发者和系统管理员分析和定位问题的原因。
Sysdump 类似于Windows 中的蓝屏技术或其他操作系统中的核心转储(core dump),但它专为Linux 系统设计。
Sysdump 原理Sysdump 的工作原理基于以下几个关键步骤:1.触发条件:当系统发生特定的错误(如内核崩溃、系统死锁等)时,或通过特定的手段(如使用SysRq 键)手动触发时,Sysdump 机制会被激活。
2.预留内存:为了确保在系统崩溃时还能成功执行Sysdump,Linux 系统通常会在启动时预留一段内存空间(例如通过内核参数crashkernel=X@Y 来设置)。
这部分内存不会被系统的正常操作所使用,只有在执行Sysdump 时才会用到。
3.捕获状态:一旦Sysdump 被触发,系统会尝试将当前的内核状态、寄存器内容、内存信息以及其他可能有助于问题分析的数据保存下来。
这些信息通常包括但不限于进程信息、内存映射、系统调用跟踪、加载的模块列表等。
4.写入磁盘:捕获到的信息会被写入到一个预先指定的位置,通常是硬盘上的一个特定分区或文件中。
这样即使系统无法正常启动,这些信息也能被保留下来,供后续分析。
5.分析:系统管理员或开发者可以使用特定的工具(如crash、kdump等)来分析Sysdump 生成的转储文件,以定位问题的根源。
Kdump 与Sysdump在Linux 系统中,Kdump 是实现Sysdump 功能的一种常见机制。
Kdump 使用kexec 技术,在系统发生崩溃时快速启动一个新的内核(称为crash kernel),并在这个新启动的内核环境中执行内存转储。
由于crash kernel 运行在一个干净的环境中,它可以避免被崩溃的主内核所影响,从而更可靠地完成内存转储任务。
当我们的程序崩溃时,内核有可能把该程序当前内存映射到core文件里,方便程序员找到程序出现问题的地方。
最常出现的,几乎所有C程序员都出现过的错误就是“段错误”了。
也是最难查出问题原因的一个错误。
下面我们就针对“段错误”来分析core文件的产生、以及我们如何利用core文件找到出现崩溃的地方。
何谓core文件当一个程序崩溃时,在进程当前工作目录的core文件中复制了该进程的存储图像。
core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
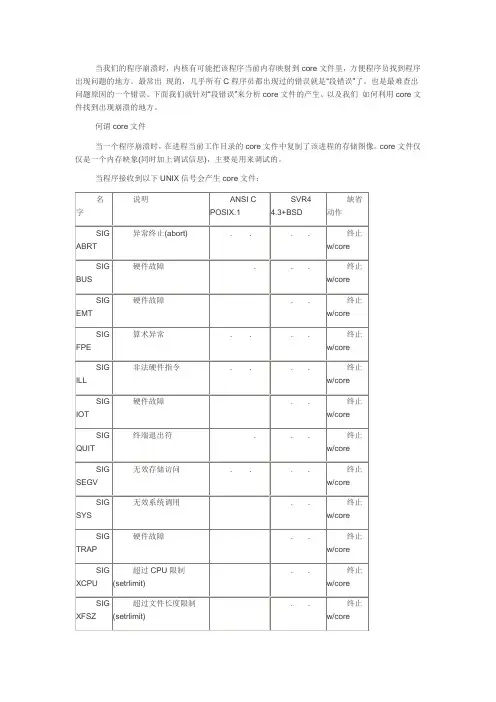
当程序接收到以下UNIX信号会产生core文件:在系统默认动作列,“终止w/core”表示在进程当前工作目录的core文件中复制了该进程的存储图像(该文件名为core,由此可以看出这种功能很久之前就是UNIX功能的一部分)。
大多数UNIX 调试程序都使用core文件以检查进程在终止时的状态。
core文件的产生不是POSIX.1所属部分,而是很多UNIX版本的实现特征。
UNIX第6版没有检查条件(a)和(b),并且其源代码中包含如下说明:“如果你正在找寻保护信号,那么当设置-用户-ID命令执行时,将可能产生大量的这种信号”。
4.3 + BSD产生名为core.prog的文件,其中prog是被执行的程序名的前1 6个字符。
它对core文件给予了某种标识,所以是一种改进特征。
表中“硬件故障”对应于实现定义的硬件故障。
这些名字中有很多取自UNIX早先在DP-11上的实现。
请查看你所使用的系统的手册,以确切地确定这些信号对应于哪些错误类型。
下面比较详细地说明这些信号。
? SIGABRT 调用abort函数时产生此信号。
进程异常终止。
? SIGBUS 指示一个实现定义的硬件故障。
? SIGEMT 指示一个实现定义的硬件故障。
EMT这一名字来自PDP-11的emulator trap 指令。
? SIGFPE 此信号表示一个算术运算异常,例如除以0,浮点溢出等。
? SIGILL 此信号指示进程已执行一条非法硬件指令。

内核卡死调试方法-概述说明以及解释1.引言1.1 概述内核卡死是指操作系统的内核无法继续执行下去,在特定的情景下,系统停止响应并无法正常运行。
这可能会导致系统崩溃、程序无法执行或者无法正常操作。
内核卡死调试方法是帮助我们解决这类问题的一种重要工具。
在本文中,我们将讨论内核卡死调试的方法和技巧,帮助读者更好地定位和解决内核卡死的问题。
首先,我们将介绍内核卡死的原因,包括硬件故障、软件错误和不兼容性等。
然后,我们将探讨内核卡死的常见表现,例如系统停止响应、屏幕冻结和错误信息等。
接着,我们将强调内核卡死调试的重要性。
内核卡死不仅会影响系统的稳定性和性能,还可能导致数据丢失和未完成的任务。
因此,在及时发现和解决内核卡死问题的同时,可以提高系统的可靠性和用户的体验。
最后,我们将总结内核卡死调试的方法和技巧。
这些方法包括使用系统日志和调试工具来分析和追踪系统状态,以及查找和修复可能的错误。
我们还将介绍一些常用的内核卡死调试工具和技术,如调试模式和堆栈跟踪。
通过本文的阅读,读者将能够更好地理解内核卡死调试的重要性和方法,使其能够快速解决内核卡死的问题,并提高系统的稳定性和可靠性。
1.2 文章结构文章结构是指对文章主要内容进行整体的组织和安排,以便读者能够清晰地了解文章的层次结构和脉络。
在讲述内核卡死调试方法的长文中,文章结构应该包括以下几个主要部分:1. 引言:在引言部分,我们将对内核卡死调试方法的重要性和必要性进行概述。
解释为什么需要调试内核卡死问题,以及通过本文能够掌握哪些相关的调试方法。
2. 内核卡死的原因:该部分将详细介绍导致内核卡死的各种原因,如硬件故障、软件错误、驱动冲突等。
通过对这些原因的分析,读者能够更好地理解内核卡死的根本问题。
3. 内核卡死的常见表现:在这一部分,我们将列举内核卡死的一些常见表现,如系统崩溃、黑屏、任务无响应等。
通过对这些表现的描述,读者能够判断出系统是否卡死,并能更好地定位具体问题。

linux系统故障及解决方法
Linux系统在使用过程中,难免会出现各种故障。
这些故障有些是因为用户的误操作,有些则是由于系统本身的问题所导致。
下面是一些常见的Linux系统故障及其解决方法。
1. 内存泄漏
内存泄漏指的是在程序运行过程中,申请的内存一直得不到释放,最终会导致系统崩溃。
通常情况下,内存泄漏是由于程序中存在漏洞或者编程不良造成的。
解决方法是通过工具检测内存泄漏,找出问题代码并进行修复。
2. 网络连接问题
Linux系统中,网络连接问题可能是由于网络协议配置不正确或者网络设备出现故障所导致。
解决方法是通过检查网络协议的配置以及检测网络设备的连接状态,找出问题所在并进行修复。
3. 硬盘故障
硬盘故障是指硬盘出现物理损坏或者软件问题导致无法正常工作。
解决方法是通过硬件检测工具对硬盘进行检测,找出问题并进行修复,或者更换故障硬盘。
4. 系统崩溃
系统崩溃是指系统出现严重的错误,导致系统无法正常工作。
解决方法是通过系统日志找出错误信息,然后进行相应的修复工作。
5. 软件安装问题
在Linux系统中,软件安装可能会出现依赖关系、版本不兼容等
问题。
解决方法是通过包管理工具进行软件安装或者手动安装所需的依赖库,确保软件正常运行。
总之,Linux系统故障的解决方法需要根据具体情况进行分析和解决,有时候需要借助一些工具,有时候则需要手动修复。
但是,无论出现什么故障,及时处理才能避免更大的损失。

linux崩溃有效排查方法1. 查看系统日志:系统日志记录了系统的活动和错误信息。
你可以查看 `/var/log` 目录下的日志文件,如 `/var/log/syslog`、`/var/log/messages` 等,以获取关于崩溃的线索。
2. 使用 dmesg 命令:dmesg 命令用于显示内核环形缓冲区的消息。
它可以提供有关系统启动时的信息以及内核检测到的错误消息。
执行 `dmesg` 命令可以查看系统崩溃前的最后一些消息。
3. 分析崩溃转储文件:如果系统崩溃导致生成了崩溃转储文件(例如,`/var/crash/` 目录下的文件),你可以使用相关工具来分析这些文件,以确定崩溃的原因。
常用的工具包括 `gdb`、`mdb` 等。
4. 检查硬件问题:硬件故障也可能导致系统崩溃。
你可以检查硬件设备,如内存、硬盘、电源等是否正常工作。
可以使用硬件检测工具来进行诊断。
5. 查看进程状态:使用如 `top`、`ps` 等命令来查看系统当前的进程状态。
如果有异常的进程占用了大量资源或导致系统不稳定,可能是崩溃的原因之一。
6. 检查内核模块:某些内核模块的问题也可能导致系统崩溃。
你可以使用 `lsmod` 命令查看加载的内核模块,并检查是否有异常的模块。
7. 进行系统更新:确保你的 Linux 系统以及相关的软件包都是最新的版本。
有时更新可以修复已知的漏洞和问题。
8. 寻求专家帮助:如果你无法确定崩溃的原因或无法解决问题,可以寻求 Linux 专家或相关技术支持人员的帮助。
需要根据具体情况选择适当的排查方法。
在排查过程中,记录你所采取的步骤和结果,这有助于更快速地定位和解决问题。

Linux常见死机原因分析介绍宕机,指操作系统无法从一个严重系统错误中恢复过来,或系统硬件层面出问题,以致系统长时间无响应,而不得不重新启动计算机的现象。
Linux系统也一样。
不过原因有所不同。
在排除了硬件故障/firmware版本/BIOS等等问题之外, Linux死机通常可能碰到如下几种情况方法步骤1,如果你的Linux死机的时候控制台上有乱七八糟的字符。
恭喜你,这种情况叫做oops. 通常是Linux kernel认为自己发生了异常造成的。
可以通过oops消息查找出错的地方。
2,如果你的机器僵死,那么问题麻烦了。
这种时候,通常是Kernel出现了死锁。
Kernel不会知道自己死锁了,所以不会在屏幕上显示任何咚咚。
如果运气好,此时Kernel也许可能能够响应中断。
不管怎样,你都无法进一步操作了。
3,严格来说,这第三种情况不算死机,现象如下:输入命令回车之后命令不能返回任何结果,但是控制台对回车可能有相应。
但是命令无法结束,也不会有输出结果。
但是可以换到下一个控制台,而且还可以继续输入命令,但是输入命令之后还是没有输出。
这种情况会有很多可能。
通常是应用程序的系统调用长时间没有返回或者是满足不了应用的要求。
以上三种情况,system log的作用都不大。
通常日志都不会纪录。
所以只能使用Kernel的Debug工具。
补充:预防死机的小技巧1、不要在同个硬盘安装多个操作系统2、不要一次性打开多个网页浏览3、在关闭电脑时,不要直接按电源按钮,否则会导致文件丢失,下次使用不能正常开机导致死机4、别让CPU、显卡超频,电脑温度过高5、及时清理机箱内的灰尘6、更换电脑硬件配置时,一定要插牢固7、不要使用来历不明的软件和光盘,以免传染病毒8、对系统文件或重要文件,最好使用隐含属性,以免因误操作而删除或覆盖这些文件9、在安装应用软件时,若提示是否覆盖当前文件,一定不要覆盖,通常当前的系统文件是最好的10、在运行大型应用软件时,不要在运行状态下退出以前运行的程序,否则会引起整个Windows崩溃相关阅读:死机宕机实例介绍自2015年3月11日下午5点起,据苹果用户反应AppStore、Mac AppStore、iTunesStore均为宕机状态,iTunes Connect无法登陆,iBooks商店没有响应。

Linux常见故障排错思路Linux操作系统因其开源、稳定、安全等特点,在服务器领域得到广泛应用。
但在使用过程中,无论是初学者还是经验丰富的系统管理员,都可能会遇到各种问题。
本文将详细阐述Linux系统中常见的故障及其排错思路,旨在帮助读者快速定位并解决问题。
一、启动故障1. GRUB引导加载器问题- 故障现象:系统启动时,无法加载GRUB或出现GRUB错误提示。
- 排错思路:- 检查GRUB配置文件是否正确。
- 使用Live CD/USB启动,进入救援模式修复GRUB。
- 重新安装GRUB到MBR。
2. 内核问题- 故障现象:启动过程中内核崩溃或无法继续启动。
- 排错思路:- 查看启动日志,分析内核报错信息。
- 尝试更换不同版本的内核启动。
- 检查硬件兼容性,如内存、CPU等。
3. 文件系统损坏- 故障现象:系统提示文件系统损坏,无法正常挂载。
- 排错思路:- 使用fsck工具检查和修复文件系统。
- 分析dmesg输出,查找与文件系统相关的错误。
- 在必要时恢复备份数据。
二、网络故障1. 无法连接到网络- 故障现象:系统无法访问外部网络或局域网。
- 排错思路:- 检查网络接口是否启动。
- 使用ping命令测试网络连通性。
- 查看/etc/resolv.conf文件中的DNS设置。
- 检查防火墙和网络策略配置。
2. SSH连接问题- 故障现象:无法通过SSH远程连接到服务器。
- 排错思路:- 检查SSH服务是否运行。
- 查看SSH配置文件(如/etc/ssh/sshd_config)是否正确。
- 使用netstat或ss命令检查SSH端口监听状态。
- 查看系统日志(如/var/log/auth.log)中的SSH相关记录。
三、性能问题1. 系统负载过高- 故障现象:系统响应缓慢,CPU、内存或磁盘负载过高。
- 排错思路:- 使用top、htop或vmstat命令监控系统资源使用情况。
- 分析系统日志,查找可能导致高负载的原因。

快速解决Linux系统崩溃的个实用技巧快速解决Linux系统崩溃的实用技巧Linux作为一种稳定可靠的操作系统,被广泛应用于服务器、嵌入式系统等领域。
然而,有时候我们可能会遇到Linux系统崩溃的情况,这不仅会给我们的工作和生活带来不便,还可能导致数据丢失甚至系统无法正常启动。
在本文中,我将介绍几种快速解决Linux系统崩溃的实用技巧,希望能对大家有所帮助。
1. 重启系统当Linux系统崩溃时,最简单的解决方法是通过重启系统。
你可以按下Ctrl + Alt + Delete组合键来执行软重启,或者按住电源按钮强制关机再重新启动系统。
这种方法通常可以解决一些临时的系统崩溃问题,但并不能解决所有的故障。
2. 查看日志文件Linux系统提供了丰富的日志记录功能,我们可以通过查看相关的日志文件来了解系统崩溃的原因。
常见的日志文件包括/var/log/messages、/var/log/syslog等。
你可以使用命令行工具如cat、less等来查看这些日志文件的内容,从中寻找系统崩溃的相关信息。
3. 运行系统诊断工具Linux系统提供了一些专门用于诊断和修复问题的工具。
例如,我们可以使用fsck命令来检查和修复文件系统的错误,使用top命令来监控系统的资源利用情况,使用dmesg命令来查看系统启动时的错误信息等。
这些工具可以帮助我们更深入地分析和解决系统崩溃的问题。
4. 更新系统软件有时候,系统崩溃可能是由于软件包的错误或漏洞导致的。
为了解决这种问题,我们可以尝试更新系统软件。
你可以使用包管理器如apt、yum等来更新系统的软件包,或者手动下载最新的软件包进行安装。
更新软件包可以修复一些已知的问题,并提供更好的系统稳定性。
5. 检查硬件故障除了软件问题外,硬件故障也是导致系统崩溃的一个常见原因。
例如,内存、硬盘、电源等硬件设备的故障都可能导致系统无法正常运行。
为了排除硬件故障的可能性,我们可以使用一些硬件测试工具进行检查。

Linux系统进程崩溃日志分析脚本尽管Linux系统一直以来都被认为是稳定可靠的操作系统,但是在某些情况下,进程崩溃仍然会发生。
当进程崩溃时,系统会生成相应的日志文件,这些日志文件包含了进程崩溃的详细信息。
为了更好地理解崩溃的原因以及采取相应的措施,我们可以编写一个Linux系统进程崩溃日志分析脚本。
脚本的主要目标是自动化分析日志文件,提取有用的信息,并将其呈现给管理员。
下面,我将介绍脚本的主要功能和使用步骤。
## 功能介绍1. 日志文件路径设置:脚本允许管理员通过指定日志文件的路径来进行分析。
这样的设置将在脚本的开头进行,在此之后,脚本将基于指定的路径来读取日志文件。
2. 进程崩溃信息提取:脚本将从日志文件中提取关键信息,包括崩溃原因、崩溃的时间和进程的相关信息。
脚本将使用字符串匹配和正则表达式来查找和提取这些信息。
3. 崩溃原因分类:脚本将根据崩溃原因对日志进行分类。
这将有助于管理员更好地理解崩溃的原因,并采取相应的措施。
4. 分析报告生成:脚本将生成分析报告,其中包括进程崩溃的统计信息和分类结果。
报告将以易读的方式呈现,并提供相应的建议和解决方案。
## 使用步骤1. 设置日志文件路径:在脚本的开头,管理员可以设置要分析的日志文件的路径。
确保指定的路径是正确的,以便脚本能够找到并读取日志文件。
2. 运行脚本:运行脚本时,它将读取指定路径下的日志文件,并自动进行分析。
脚本将显示进程崩溃的统计信息和分类结果。
3. 查看分析报告:脚本将生成一个分析报告文件,其中包含了进程崩溃的详细信息和建议。
管理员可以查看报告并根据需要采取相应的措施。
## 示例代码以下是一个简单的示例代码,展示了如何实现Linux系统进程崩溃日志分析脚本:```bash#!/bin/bash# 设置日志文件路径log_path="/var/log/syslog"# 提取崩溃信息crash_logs=$(grep -i "crash" $log_path)# 崩溃原因分类memory_crash=$(grep -i "out of memory" <<< $crash_logs)disk_crash=$(grep -i "disk I/O error" <<< $crash_logs)network_crash=$(grep -i "network failure" <<< $crash_logs)# 生成分析报告report_path="/tmp/crash_analysis_report.txt"echo "进程崩溃日志分析报告" > $report_pathecho "===================" >> $report_pathecho "崩溃统计信息:" >> $report_pathecho "---------------" >> $report_pathecho "总崩溃次数:$(wc -l <<< $crash_logs)" >> $report_path echo "内存崩溃次数:$(wc -l <<< $memory_crash)" >> $report_path echo "硬盘崩溃次数:$(wc -l <<< $disk_crash)" >> $report_path echo "网络崩溃次数:$(wc -l <<< $network_crash)" >> $report_path echo "" >> $report_pathecho "崩溃分类结果:" >> $report_pathecho "---------------" >> $report_pathecho "内存崩溃:$memory_crash" >> $report_pathecho "硬盘崩溃:$disk_crash" >> $report_pathecho "网络崩溃:$network_crash" >> $report_pathecho "分析报告已生成:$report_path"```以上示例代码只是一个简单的实现,实际的脚本可以根据需求进行更多的定制和改进。

Linux宕机故障分析案例Linux宕机故障分析案例马化辉背景在Linux系统环境下,服务器宕机发⽣的频率⽐较⼩,但是不少⼯程师或多或少都会遇到这种情况,有时候会⼿⾜⽆措,不知从何⼊⼿。
笔者将借助⼀次案例分析,展⽰下Linux宕机故障事件的处理⽅法和思路。
宕机发⽣的原因不⼀,或者是硬件原因,或者是性能原因,或者是服务器触发了Linux的bug,导致内核崩溃等等。
案例分析1、案情还原;⽣产系统服务器dcspodsaa1在4⽉25⽇凌晨00:49分发⽣服务器宕机故障,当时系统管理员对硬件报错进⾏了截图(保留现场很重要),看字⾯意思应该是服务器的swap设备发⽣损坏:2、分析⽅法⼀:使⽤sosreport收集系统⽇志,检查/var/log/messages⽇志,查找系统重启前是否存在错误⽇志,图中kernel***/proc/kmsg started代表系统启动的第⼀条⽇志,在此之前没有发现异常⽇志,3、分析⽅法⼆:检查服务器开启了kdump服务,并在/var/crash⽬录找到了当天⽣成的vmcore⽂件,使⽤crash⼯具分析vmcore⽂件,如下:服务器发⽣了严重的系统崩溃panic错误对kdmp⽂件的错误⽇志进⾏分析,发现了⼤量的swap 设备读写错误:5、分析⽅法三:检查系统历史性能记录,/var/log/sa/路径下记录了每天由sysstat服务收集的sar(system activity report)⽂件,默认每10分钟记录⼀次系统资源使⽤情况的信息,包括CPU、内存等。
通过sar命令查看系统宕机时负载情况,没有发现资源使⽤异常,基本可以排除不是系统因性能不⾜从⽽导致宕机4.25号性能记录⽂件使⽤命令sar –A –F sa25 | more检查CPU性能信息和内存性能信息,没有发现异常情况。
其他配置1. 开启kdump:安装依赖包启动服务设置开启启动修改默认crashkernel参数为256M, 注意需重启系统才⽣效2. 使⽤crash⼯具分析vmcore⽂件:1) 安装crash包,可使⽤yum安装2) 安装kernel-debug内核版本,该rpm包必需和故障系统的内核版本⼀致先使⽤unamre –r查看故障机版本安装相应包3) 启动crash检查⼩结因此,在处理故障时,⼀般的思路是:1. ⾸先应查找故障前的错误⽇志线索,可以通过检查系统messages⽇志中的错误⽇志;2. 如果没有,进⽽排查系统是否触发kdump服务(在系统由于内核崩溃⽽导致宕机时,可以捕获故障时内存中的故障信息);3. 另外也需要分析系统资源(CPU、内存等)使⽤上出现异常。
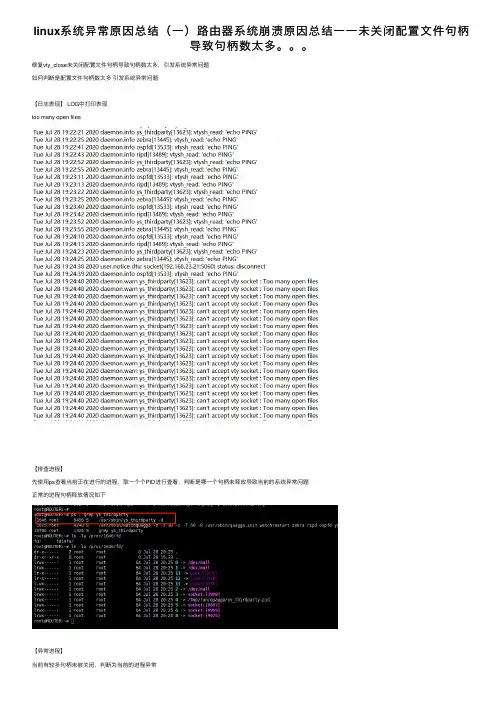
linux系统异常原因总结(⼀)路由器系统崩溃原因总结⼀⼀未关闭配置⽂件句柄导致句柄数太多。
修复vty_close未关闭配置⽂件句柄导致句柄数太多,引发系统异常问题如何判断是配置⽂件句柄数太多引发系统异常问题【⽇志表现】 LOG中打印表现too many open files【排查进程】先使⽤ps查看当前正在进⾏的进程,取⼀个个PID进⾏查看,判断是哪⼀个句柄未释放导致当前的系统异常问题正常的进程句柄释放情况如下【异常进程】当前有较多句柄未被关闭,判断为当前的进程异常可以看到上⾯蓝⾊的字表⽰的为句柄****句柄⼩知识*****在windows中,句柄是⼀个32位的整数,是内存中维护的⼀个对象的地址列表的整数索引,这些对象包括:窗⼝(window)、块(module)、任务(task)、实例 (instance)、⽂件(file)、内存块(block of memory)、菜单(menu)、控制(control)、字体(font)、资源(resource),包括图标(icon),光标 (cursor),字符串(string)等、GDI对象(GDI object),包括位图(bitmap),画刷(brush),元⽂件(metafile),调⾊板(palette),画笔(pen),区域(region),以及设备描述表(device context)。
在Linux中,每⼀个进程都由task_struct 数据结构来定义,即PCB,进程通过PCB中的⽂件描述符表找到⽂件描述符fd所指向的⽂件指针filp,内核(kernel)利⽤⽂件描述符(file descriptor)来访问⽂件。
⽂件描述符是⾮负整数。
打开现存⽂件或新建⽂件时,内核会返回⼀个⽂件描述符。
读写⽂件也需要使⽤⽂件描述符来指定待读写的⽂件。
⽂件描述符表是⼀个指针数组,每⼀个元素都指向⼀个内核的打开⽂件对象,⽽fd,就是这个表的下标。
当⽤户打开⼀个⽂件时,内核会在内部⽣成⼀个打开⽂件对象,并在这个表⾥找到⼀个空项,让这⼀项指向⽣成的打开⽂件对象,并返回这⼀项的下标作为fd,Linux中的⽂件描述符类似于Windows下⽂件句柄的概念,但区别是Windows的⽂件句柄是⼀个全局的概念,⽽Linux下⽂件句柄的作⽤域只在本进程空间,其中0(标准输⼊)、1(标准输出)、2(标准错误)是每⼀个进程中相同的⽂件描述符,由操作系统规定好,⽂件描述符所指向元素的⽂件指针为struct file结构体,在系统中是⼀个全局的指针。
linux crash的用法"Linux Crash"的用法引言:Linux是一种开源操作系统,它的稳定性和可靠性广受赞誉。
然而,就像任何其他操作系统一样,Linux也可能会出现崩溃的情况。
本文将详细探讨"Linux Crash"的用法,包括可能导致崩溃的因素以及如何应对和解决这些问题。
第一部分:Linux系统崩溃的原因1. 硬件故障:硬件故障是导致Linux系统崩溃的常见原因之一。
例如,内存故障、硬盘故障、电源问题等都可能导致系统无法正常运行。
2. 软件错误:软件错误也是Linux系统崩溃的常见原因之一。
例如,操作系统内核或其他关键软件的错误可能导致系统崩溃。
3. 驱动程序问题:Linux系统通常需要使用特定的驱动程序来与硬件设备进行交互。
不正确的驱动程序或驱动程序的冲突可能导致系统崩溃。
4. 内存管理问题:Linux系统使用虚拟内存管理机制来管理系统内存。
如果出现内存管理问题,例如内存泄漏或内存访问错误,系统可能会崩溃。
第二部分:应对Linux系统崩溃的步骤1. 重新启动系统:在系统崩溃后,第一步是尝试重新启动系统。
这可能是因为崩溃只是一个偶然事件,重新启动系统后问题可能会得到解决。
2. 分析错误日志:Linux系统通常会生成错误日志,记录系统崩溃时的相关信息。
通过分析错误日志,我们可以获得有关崩溃原因的线索,以便采取适当的措施。
- 使用命令"cat /var/log/syslog"来查看系统日志。
- 使用命令"dmesg"来查看内核日志。
3. 更新和修复软件:如果崩溃是由软件错误引起的,更新和修复软件可能是解决问题的方法之一。
通过使用包管理器来更新软件包,可以获得最新的错误修复和安全补丁。
- 在Debian或Ubuntu系统中,使用命令"apt-get update"和"apt-get upgrade"来更新软件包。
常见Linux系统故障及解决方法Linux系统是一种非常稳定和可靠的操作系统,但仍然可能发生一些故障。
以下是一些常见的Linux系统故障及其解决方法。
1. 系统无响应:当系统无法响应用户的输入或命令时,可能是由于资源耗尽或进程崩溃引起的。
解决方法包括使用Ctrl+Alt+Del重新启动系统,或在命令行中使用kill命令终止问题进程。
2.网络连接问题:网络连接问题可能包括无法连接到互联网、无法访问特定网站等。
解决方法包括检查网络连接是否正常,重启网络服务,更新网络驱动程序或重新配置网络设置。
3. 文件系统损坏:文件系统损坏可能导致文件丢失或无法访问文件。
解决方法包括使用fsck命令修复文件系统,使用备份文件替换损坏的文件,或使用专业的数据恢复工具。
4. 内存不足:当系统内存不足时,可能导致系统变慢或无法运行一些程序。
解决方法包括关闭不必要的程序或服务,增加系统内存,或使用swap分区来扩展虚拟内存。
7.内核崩溃:内核崩溃可能导致系统无法启动或频繁崩溃。
解决方法包括更新内核到最新版本,检查硬件兼容性,或按照错误提示进行进一步的故障排除。
8. 用户权限问题:用户权限问题可能导致无法访问一些文件或执行一些操作。
解决方法包括使用sudo命令获取超级用户权限,更改文件或目录的权限,或添加用户到适当的用户组。
9.日志文件错误:日志文件错误可能导致无法跟踪系统问题或分析错误原因。
解决方法包括检查日志文件的权限和大小,清理或备份日志文件,或使用日志分析工具来查找问题。
总之,遇到Linux系统故障时,重要的是保持冷静,并使用正确的工具和方法进行故障排除。
如果无法解决问题,请参考Linux社区的文档和论坛,或寻求专业的技术支持。
2019,55(6)1引言复杂的应用程序会在执行期间产生多个子进程或者线程,这些进程还有可能通过网络和其他进程进行通信。
分析此类应用程序的出错原因,需要动态地发现并跟踪,此应用程序创建的子进程以及和这些进程通过网络通信的其他进程。
在Linux 系统中有ftrace 、systemtap 、gdb 、strace 等多种工具可以跟踪系统调用信息。
ftrace [1]采用静态trace_point [2]的方法,在系统调用分发的进入和返回代码处对系统调用的进入和返回信息进行了采集,其对系统调用的参数和返回值没有做任何解析[3]。
systemtap [4]利用kprobe 和kretprobe [5]对系统调用处理函数的调用和返回信息进行了采集,其可以通过argstr 变量输出系统调用参数信息。
gdb 的catch syscall 命令和strace 工具,利用ptrace [6]Linux 系统调用跟踪和进程错误退出分析毛英明1,陆慧梅1,向勇21.北京理工大学计算机学院,北京1000812.清华大学计算机科学与技术系,北京100084摘要:现有的Linux 系统调用跟踪工具存在跟踪上下文信息不全、无法高效地对通过网络通信的多进程应用程序进行跟踪以及跟踪结果缺少图形化展现的问题。
通过扩展Linux 系统调用跟踪工具strace ,实现了启发式跟踪工具heuristic-strace ,其能够实时发现和自动跟踪应用程序中通过网络通信的进程,形成进程创建关系图、进程网络通信关系图,并结合系统调用的栈回溯信息,定位进程的错误退出原因。
实验结果表明,此工具对能对典型的GUI 和网络应用软件进行跟踪,引入的性能开销比较低,并能保证被跟踪软件的正常交互。
关键词:Linux 系统调用;启发式跟踪;网络通信;进程错误退出分析文献标志码:A 中图分类号:TP 316.81doi :10.3778/j.issn.1002-8331.1805-0105毛英明,陆慧梅,向勇.Linux 系统调用跟踪和进程错误退出分析.计算机工程与应用,2019,55(6):57-66.MAO Yingming,LU Huimei,XIANG Yong.Linux syscall trace and process error exit puter Engineering and Applications,2019,55(6):57-66.Linux Syscall Trace and Process Error Exit AnalysisMAO Yingming 1,LU Huimei 1,XIANG Yong 21.School of Computer Science and Technology,Beijing Institute of Technology,Beijing 100081,China2.Department of Computer Science and Technology,Tsinghua University,Beijing 100084,ChinaAbstract :The existing Linux syscall tracing tools can ’t effectively trace multi process applications that communicate with other processes through network.The tracing result ’s context information is incomplete and lacks of graphical dis-play.So a new tracing tool named heuristic-strace is designed based on the existing syscall tracing tool strace.It can auto-matically find and trace the processes that communicate through network.Moreover,it can display the tracing result in the form of process creation graph and network communication bined with the stack trace info,it can locate the process error exit reason.The experimental results show that this tool can trace typical GUI and network applications with lower performance overhead and ensure normal interact with the traced software.Key words :Linux syscall;heuristic trace;network communication;process error exit analysis基金项目:核高基项目(No.2012ZX01039-004-41,No.2012ZX01039-003)。
Linux系统调用跟踪和进程错误退出分析摘要:Linux操作系统由于其稳定、高效的特点,在现代IT行业中广泛应用。
随着应用程序和系统内核功能日益复杂化,涉及到的系统调用越来越多,进程意外退出的情况也越来越常见。
本文主要讨论Linux系统调用跟踪和进程错误退出分析的相关技术和方法。
首先介绍系统调用的概念和原理,然后详细说明在Linux系统中如何跟踪各种不同类型的系统调用,并对系统调用的用法和性能优化进行分析。
然后,我们探讨了进程错误退出的原因和种类,并提出了相应的调试方法和技巧,例如使用调试器分析进程内存、跟踪日志、利用CoreDump等。
最后,本文总结了Linux系统调用跟踪和进程错误退出分析的相关经验和技巧,为开发者和系统管理员提供实用的参考和建议。
关键词: Linux操作系统;系统调用;跟踪;错误退出;调试方法第一章、引言Linux操作系统是一种免费开源的Unix-like操作系统,已广泛应用于服务器、嵌入式系统等领域。
与其他操作系统相比,Linux操作系统具有高度的灵活性和可定制性,可以适应多种不同的应用场景。
但是,随着操作系统和应用程序的日益复杂化,Linux系统中可能出现各种错误和故障,这些错误和故障有时会导致应用程序崩溃、运行缓慢,甚至会导致系统崩溃。
因此,在Linux系统中进行系统调用跟踪和进程错误退出分析具有重要的实际意义。
本文将讨论这些相关的技术和方法。
第二章、系统调用的概念和原理系统调用是操作系统提供的一组功能接口,允许应用程序向操作系统请求服务和资源。
在Linux系统中,系统调用是通过一个特殊的中断指令实现的,应用程序可以向操作系统发送中断信号以请求系统调用服务。
常用的系统调用包括文件操作、进程管理、网络通信等。
第三章、系统调用的跟踪技术系统调用的跟踪是Linux系统中的一种重要调试技术,可以用于检测系统调用的使用情况和性能瓶颈,提高应用程序的可靠性和性能。
Linux系统中有多种系统调用跟踪工具,例如strace、ltrace等。
Linux内核崩溃原因分析及错误跟踪技术随着嵌入式Linux系统的广泛应用,对系统的可靠性提出了更高的要求,尤其是涉及到生命财产等重要领域,要求系统达到安全完整性等级3级以上[1],故障率(每小时出现危险故障的可能性)为10-7以下,相当于系统的平均故障间隔时间(MTBF)至少要达到1141年以上,因此提高系统可靠性已成为一项艰巨的任务。
对某公司在工业领域14 878个控制器系统的应用调查表明,从2004年初到2007年9月底,随着硬软件的不断改进,根据错误报告统计的故障率已降低到2004年的五分之一以下,但查找错误的时间却增加到原来的3倍以上。
这种解决问题所需时间呈上升的趋势固然有软件问题,但缺乏必要的手段以辅助解决问题才是主要的原因。
通过对故障的统计跟踪发现,难以解决的软件错误和从发现到解决耗时较长的软件错误都集中在操作系统的核心部分,这其中又有很大比例集中在驱动程序部分[2]。
因此,错误跟踪技术被看成是提高系统安全完整性等级的一个重要措施[1],大多数现代操作系统均为发展提供了操作系统内核“崩溃转储”机制,即在软件系统宕机时,将内存内容保存到磁盘[3],或者通过网络发送到故障服务器[3],或者直接启动内核调试器[4]等,以供事后分析改进。
基于Linux操作系统内核的崩溃转储机制近年来有以下几种:(1) LKCD(Linux Kernel Crash Dump)机制[3];(2) KDUMP(Linux Kernel Dump)机制[4];(3) KDB机制[5];(4) KGDB机制[6]。
综合上述几种机制可以发现,这四种机制之间有以下三个共同点:(1) 适用于为运算资源丰富、存储空间充足的应用场合;(2) 发生系统崩溃后恢复时间无严格要求;(3) 主要针对较通用的硬件平台,如X86平台。
在嵌入式应用场合想要直接使用上列机制中的某一种,却遇到以下三个难点无法解决:(1) 存储空间不足嵌入式系统一般采用Flash作为存储器,而Flash容量有限,且可能远远小于嵌入式系统中的内存容量。
分析如何查找Linux死机的原因 内核虽然号称“不死族”,⼏乎不会崩溃或者死机,但是特殊情况下,还是有⼀定⼏率会宕机的。
因为 Linux ⼴泛⽤于⽣产环境,所以每⼀次宕机都会引起相当⼤的损失。
它 Uptime 达到上百天也许你习以为常,但是只要 Down ⼗⼏秒,就会⽴即急的满头⼤汗。
真的很难以想象证交所宕机会怎么样,也许全国股民会闹翻天。
所以我们需要⼀些⼩技巧来查找死机的原因,从⽽避免死机或者内核崩溃。
(话说windows 天天蓝屏也没感觉呀:-o 难道已经⿇⽊了:oops: ) 请注意:以下⽅法可能不适⽤于 Server,因为桌⾯环境和 Server 还是有很⼤区别的。
X Crash 事实上 Linux 内核很少出错,平常我们所遇到的“死机”都是 X ⽆响应造成的错觉。
那 X 没响应了应该怎么处理呢? 通常套路是 Ctrl + Alt +F7 (F8) 切换到某个 tty,然后⽤ root 登陆,执⾏ top 查看吃资源最多的程序,然后使⽤ pkill/kill/killall 等命令杀死该程序。
或使⽤组合键 Ctrl +Alt + Backspace重启 X (⿊⽇⽩⽉注:这个快捷键组合在最新的和中关闭)。
如果偶遇切换 tty 失败或者没响应,可以试着使⽤登陆此电脑,然后再杀死程序。
也许只是 X不响应,⽽内核和 SSH daemon 仍然⼯作,故此可以实施此法。
arch 配置 SSH daemon 万⼀ X 不给⼒,各种⽅法试了⽆效,⼜没有办法通过 SSH 登陆到此 pc,那怎么办呢?别着急,我们还有万能的 “reisub” ⼤法。
不过在启⽤前先要激活内核 sysrq 功能 (via) .系统启动时执⾏:echo “1” > /proc/sys/Kernel/sysrq 或者修改/etc/sysctl.conf ⽂件,设置 Kernel.sysrq = 1.系统异常时依次按下 Alt+sysrq+{reisub} ,然后系统会⾃动重启。
Linux内核崩溃原因分析及错误跟踪技术随着嵌入式Linux系统的广泛应用,对系统的可靠性提出了更高的要求,尤其是涉及到生命财产等重要领域,要求系统达到安全完整性等级3级以上[1],故障率(每小时出现危险故障的可能性)为10-7以下,相当于系统的平均故障间隔时间(MTBF)至少要达到1141年以上,因此提高系统可靠性已成为一项艰巨的任务。
对某公司在工业领域14 878个控制器系统的应用调查表明,从2004年初到2007年9月底,随着硬软件的不断改进,根据错误报告统计的故障率已降低到2004年的五分之一以下,但查找错误的时间却增加到原来的3倍以上。
这种解决问题所需时间呈上升的趋势固然有软件问题,但缺乏必要的手段以辅助解决问题才是主要的原因。
通过对故障的统计跟踪发现,难以解决的软件错误和从发现到解决耗时较长的软件错误都集中在操作系统的核心部分,这其中又有很大比例集中在驱动程序部分[2]。
因此,错误跟踪技术被看成是提高系统安全完整性等级的一个重要措施[1],大多数现代操作系统均为发展提供了操作系统内核“崩溃转储”机制,即在软件系统宕机时,将内存内容保存到磁盘[3],或者通过网络发送到故障服务器[3],或者直接启动内核调试器[4]等,以供事后分析改进。
基于Linux操作系统内核的崩溃转储机制近年来有以下几种:(1) LKCD(Linux Kernel Crash Dump)机制[3];(2) KDUMP(Linux Kernel Dump)机制[4];(3) KDB机制[5];(4) KGDB机制[6]。
综合上述几种机制可以发现,这四种机制之间有以下三个共同点:(1) 适用于为运算资源丰富、存储空间充足的应用场合;(2) 发生系统崩溃后恢复时间无严格要求;(3) 主要针对较通用的硬件平台,如X86平台。
在嵌入式应用场合想要直接使用上列机制中的某一种,却遇到以下三个难点无法解决:(1) 存储空间不足嵌入式系统一般采用Flash作为存储器,而Flash容量有限,且可能远远小于嵌入式系统中的内存容量。
因此将全部内存内容保存到Flash不可行。
(2) 记录时间要求尽量短嵌入式系统一般有复位响应时间尽量短的要求,有的嵌入式操作系统复位重启时间不超过2s,而上述几种可用于Linux系统的内核崩溃转储机制耗时均不可能在30s内。
写Flash的操作也很耗时间,实验显示,写2MB数据到Flash 耗时达到400ms之多。
(3) 要求能够支持特定的硬件平台嵌入式系统的硬件多种多样,上面提到的四种机制均是针对X86平台提供了较好的支持,而对于其他体系的硬件支持均不成熟。
由于这些难点的存在,要将上述四种内核崩溃转储机制中的一种移植到特定的嵌入式应用平台是十分困难的。
因此,针对上述嵌入式系统的三个特点,本文介绍一种基于特定平台的嵌入式Linux内核崩溃信息记录机制LCRT(Linux Crash Record and Trace),为定位嵌入式Linux系统中软件故障和解决软件故障提供辅助手段。
1 Linux内核崩溃的分析分析Linux内核对于运行期间各种“陷阱”的处理可以得知,Linux内核对于应用程序导致的错误可以予以监控,在应用程序发生除零、内存访问越界、缓冲区溢出等错误时,Linux内核的异常处理例程可以对这些由应用程序引起的异常情况予以处理。
当应用程序产生不可恢复的错误时,Linux内核可以仅仅终止产生错误的应用程序,其他应用程序仍然可以正常运行。
如果Linux内核本身或者新开发的Linux内核模块存在bug,产生了“除零”,“内存访问越界”、“缓冲区溢出”等错误,同样会由Linux内核的异常处理例程来处理。
Linux内核通过在异常处理程序中判断,如果发现是“严重的不可恢复”的内核异常,则会导致“内核恐慌”(kernel panic),即Linux 内核崩溃。
图1所示为Linux内核对异常情况的处理流程。
2 LCRT机制的设计与实现通过对Linux内核代码的分析可知,Linux内核本身提供了一种“内核通知机制”[7-8],并预定义了“内核事件通知链”,使得Linux内核扩展开发人员可以通过这些预定义的内核事件通知链在特定的内核事件发生时执行附加的处理流程。
通过对Linux内核源代码的研究发现,对于上文中提到的“严重不可恢复的内核异常”,预定义了一个通知链和通知点,使得在发生Linux内核崩溃之后,可以在Linux内核的panic函数中预定义的一个“内核崩溃通知链”[7]上挂接LCRT机制来获得Linux内核崩溃现场的一些信息并记录到非易失性存储器中,以便分析引起Linux内核崩溃的原因。
2.1 设计要点LCRT机制的设计和实现基于如下特定的机制:(1) 编译器选项与内核依赖Linux内核及相应的驱动程序都采用GNU[9]的开源编译器GCC[9]编译,为了结合LCRT机制方便地提取信息和记录信息,需要采用特定的GCC编译器选项来编译Linux内核和相关的驱动程序以及应用程序。
用到的选项为:-mpoke-function-name[9]。
使用这个选项编译出的二进制程序中可以包含C语言函数名称的信息,以方便函数调用链回溯时记录信息的可读性。
(2) Linux内核notify_chain机制[8]Linux内核提供“通知链”功能,并预定义了一个内核崩溃通知链,在Linux 内核的异常处理例程中判断出系统进入“不可恢复”状态时,会沿预定义的通知链顺序调用注册到相应链中的通知函数。
(3) 函数调用的栈布局Linux内核的绝大部分由C语言实现,而且C语言也多用来进行Linux内核开发。
Linux内核及使用LKM扩展而加入Linux内核执行环境的代码是有规律可循的,这些代码在执行过程中产生的栈布局和这些规律的代码相关联。
例如,这些函数在执行函数之前会保存本函数调用后的返回地址、本函数被调用时传递过来的参数及调用本函数的函数所拥有的栈帧的栈底。
2.2 LCRT机制的设计思想LCRT机制分为Linux内核模块[8]部分和Linux用户程序部分。
内核模块部分的设计采用了Linux内核模块的模式而不是直接修改Linux内核。
这样的设计降低了Linux内核和LCRT机制之间的耦合度,同时满足了Linux内核和LCRT机制独立升级完善的便利性。
用户程序部分完成从非易失性存储器中读取、清除LCRT机制保存的信息等相关功能。
在LCRT机制的设计中,针对嵌入式系统的特点,其设计决策有:(1) 将对于解决和定位问题最具辅助意义的函数调用关系链记录下来。
(2) 为了不占用过多的存储空间,有选择性地将函数调用序列上的函数各自用到的栈内容保存起来,而不是保存全部内容。
(3) 将记录的信息保存到非易失性存储器中,这样既达到了掉电保存的目的、又缩短了写入时间。
LCRT机制的设计包括以下五个方面。
(1) 设计Linux内核模块、动态地加载LCRT机制、尽量少地修改Linux内核代码。
(2)在相应、预定义的Linux内核通知链上挂接LCRT的通知函数。
(3) 在LCRT机制的通知处理函数中进行堆栈回溯得到函数调用信息。
(4) 记录回溯到的函数调用信息和堆栈空间内容到非易失性存储器。
(5) 开发用户空间的工具,可以从非易失性存储器中读取保存的信息。
2.3 LCRT机制的实现LCRT机制的实现可参照2.2节的设计思想,分步予以实现。
限于篇幅,本文不过多涉及Linux内核模块的原理和实现相关的细节,仅仅给出LCRT机制的内核模块实现伪代码。
用伪代码描述LCRT机制的加载函数如下:int lcrt_init(void){printk("Registering my__panic notifier. ");bt_nvram_ptr=(volatile unsigned char*)ioremap_nocache (BT_NVRAM_BASE,BT_NVRAM_LENGTH);bt_nvram_index+=sizeof(struct bt_info);*)bt_nvram_ptr,BT_NVRAM_LENGTH);notifier_chain_register(&panic_notifier_list,&my_panic_block);return 0;}LCRT机制的通知处理函数完成函数调用关系回溯、得到函数名称、函数栈内容等工作,限于篇幅,在这里用下面伪代码说明:void ll_bt_information(struct pt_regs *pr){变量定义等初始化工作do {reglist=*(unsigned long *)(*myfp-8);//从函数栈帧的顶部获取函数开始执行时保存的寄存器信息//从函数的代码区中取得函数的名称//从函数的栈帧里取出函数执行函数体代码之前保存的函数参数信息//从本函数的栈帧中得到调用本函数的代码所在位置和调用本函数的函数栈帧的栈底}while(直到函数调用链的链头);//取得函数调用栈帧的内容//填充信息记录的记录头部//将上面的循环中取得的信息保存到非易失性存储器中write_to_nvram((void*)bt_nvram_ptr,&bt_record_header,sizeof(bt_info_t));}3 验证评估LCRT机制3.1 部署LCRT机制部署LCRT机制,使LCRT机制发挥作用前需要做的相关工作有:(1)针对目标Linux内核编译LCRT机制的Linux内核模块部分;(2) 将LCRT机制的内核模块部分载入Linux内核。
3.2 实验结果为了实验LCRT机制的作用效果,构造一个会造成Linux内核崩溃的设备驱动模块,记这个内核驱动模块为bugguy.ko,列出如下所示的bugguy.ko中会引起Linux内核崩溃的代码如下所示:my_timer_interrupt(int irq,void *dev_id,struct pt_regs* regs){确认硬件状态并清除中断状态if(ujiffies > 5000) {void * ill_pointer=NULL;*(unsigned long *)ill_pointer=0;}else {ujiffies++;}return IRQ_HANDLED;}说明:用黑体标出的代码即为产生bug的代码从上面的代码可以看出,这个错误是对空指针进行解析而造成的。
在一个中断处理函数中如果发生对空指针的解析,将会引起Linux内核的崩溃。
在部署完成LCRT机制的嵌入式linux系统上将这个bugguy.ko载入Linux内核,使得会引起Linux内核崩溃的中断处理程序得以运行,LCRT机制可以将相关的信息保存到非易失性存储器中,在系统复位后,通过LCRT机制的用户空间工具,可以将保存的信息读取出来。