神经网络学习笔记及R实现
- 格式:docx
- 大小:153.74 KB
- 文档页数:6

深度神经网络及目标检测学习笔记https://youtu.be/MPU2HistivI上面是一段实时目标识别的演示,计算机在视频流上标注出物体的类别,包括人、汽车、自行车、狗、背包、领带、椅子等。
今天的计算机视觉技术已经可以在图片、视频中识别出大量类别的物体,甚至可以初步理解图片或者视频中的内容,在这方面,人工智能已经达到了3岁儿童的智力水平。
这是一个很了不起的成就,毕竟人工智能用了几十年的时间,就走完了人类几十万年的进化之路,并且还在加速发展。
道路总是曲折的,也是有迹可循的。
在尝试了其它方法之后,计算机视觉在仿生学里找到了正确的道路(至少目前看是正确的)。
通过研究人类的视觉原理,计算机利用深度神经网络(Deep Neural Network,NN)实现了对图片的识别,包括文字识别、物体分类、图像理解等。
在这个过程中,神经元和神经网络模型、大数据技术的发展,以及处理器(尤其是GPU)强大的算力,给人工智能技术的发展提供了很大的支持。
本文是一篇学习笔记,以深度优先的思路,记录了对深度学习(Deep Learning)的简单梳理,主要针对计算机视觉应用领域。
一、神经网络1.1 神经元和神经网络神经元是生物学概念,用数学描述就是:对多个输入进行加权求和,并经过激活函数进行非线性输出。
由多个神经元作为输入节点,则构成了简单的单层神经网络(感知器),可以进行线性分类。
两层神经网络则可以完成复杂一些的工作,比如解决异或问题,而且具有非常好的非线性分类效果。
而多层(两层以上)神经网络,就是所谓的深度神经网络。
神经网络的工作原理就是神经元的计算,一层一层的加权求和、激活,最终输出结果。
深度神经网络中的参数太多(可达亿级),必须靠大量数据的训练来“这是苹在父母一遍遍的重复中学习训练的过程就好像是刚出生的婴儿,设置。
.果”、“那是汽车”。
有人说,人工智能很傻嘛,到现在还不如三岁小孩。
其实可以换个角度想:刚出生婴儿就好像是一个裸机,这是经过几十万年的进化才形成的,然后经过几年的学习,就会认识图片和文字了;而深度学习这个“裸机”用了几十年就被设计出来,并且经过几个小时的“学习”,就可以达到这个水平了。

人工神经网络学习总结笔记主要侧重点:1.概念清晰2.进行必要的查询时能从书本上找到答案第一章:绪论1.1人工神经网络的概述“认识脑”和“仿脑”:人工智能科学家在了解人脑的工作机理和思维的本质的基础上,探索具有人类智慧的人工智能系统,以模拟延伸和扩展脑功能。
我认为这是人工神经网络研究的前身。
形象思维:不易被模拟人脑思维抽象推理逻辑思维:过程:信息概念最终结果特点:按串行模式人脑与计算机信息处理能力的不同点:方面类型人脑计算机记忆与联想能力可存储大量信息,对信息有筛选、回忆、巩固的联想记忆能力无回忆与联想能力,只可存取信息学习与认知能力具备该能力无该能力信息加工能力具有信息加工能力可认识事物的本质与规律仅限于二值逻辑,有形式逻辑能力,缺乏辩证逻辑能力信息综合能力可以对知识进行归纳类比和概括,是一种对信息进行逻辑加工和非逻辑加工相结合的过程缺乏该能力信息处理速度数值处理等只需串行算法就能解决的应用问题方便,计算机比人脑快,但计算机在处理文字图像、声音等类信息的能力远不如人脑1.1.2人脑与计算机信息处理机制的比较人脑与计算机处理能力的差异最根本的原因就是信息处理机制的不同,主要有四个方面方面类型人脑计算机系统结构有数百亿神经元组成的神经网络由二值逻辑门电路构成的按串行方式工作的逻辑机器信号形式模拟量(特点:具有模糊性。
离散的二进制数和二值逻辑容易被机器模拟的思维方式难以被机器模拟)和脉冲两种形式形式信息储存人脑中的信息分布存储于整个系统,所存储的信息是联想式的有限集中的串行处理机制信息处理机制高度并行的非线性信息处理系统(体现在结构上、信息存储上、信息处理的运行过程中)1.1.3人工神经网络的概念:在对人脑神经网络的基本认识的基础上,用数理方法从信息处理的角度对人脑神经网络进行抽象,并建立某种简化模型,称之为人工神经网络,是对人脑的简化、抽象以及模拟,是一种旨在模仿人脑结构及其功能的信息处理系统。
其他定义:由非常多个非常简单的处理单元彼此按某种方式相互连接而形成的计算系统,外部输入信息之后,系统产生动态响应从而处理信息。

神经网络模型的教程及使用方法神经网络模型是一种模仿人脑神经系统工作原理的计算模型。
随着人工智能和深度学习的发展,神经网络模型已经成为一种重要的工具,被广泛应用于图像识别、自然语言处理、推荐系统等领域。
本文将介绍神经网络模型的基本原理、常见的网络结构以及使用方法。
一、神经网络模型的基本原理神经网络模型受到人脑神经系统的启发,由神经元、权重和激活函数组成。
神经网络模型的基本思想是通过学习对输入数据进行逐层抽象和组合,最终得到对输入数据的预测输出。
1. 神经元(Neuron)神经元是神经网络的基本单元,接收来自上一层神经元的输入,并将其加权求和后经过激活函数得到输出。
神经元的输入可以来自于其他神经元的输出,也可以来自于外部的输入数据。
2. 权重(Weight)权重是连接神经元之间的参数,用于调节输入信号的重要性。
神经网络的训练过程就是通过不断调整权重的值来优化网络的性能。
3. 激活函数(Activation Function)激活函数决定了神经元的输出。
常用的激活函数包括Sigmoid函数、ReLU函数等。
激活函数的作用是引入非线性因素,提高神经网络模型的表达能力。
二、常见的神经网络模型结构1. 前馈神经网络(Feedforward Neural Network)前馈神经网络是最简单的神经网络结构,信号从输入层经过一层一层的传递到输出层,没有反馈连接。
前馈神经网络可以通过增加隐藏层的数量和神经元的个数来提高模型的表达能力。
2. 卷积神经网络(Convolutional Neural Network)卷积神经网络是一种专门用于图像识别的神经网络模型。
它通过局部感知和参数共享来提取图像的特征。
卷积神经网络一般由卷积层、池化层和全连接层组成。
3. 循环神经网络(Recurrent Neural Network)循环神经网络是一种具有记忆功能的神经网络模型。
它通过循环连接实现对序列数据的建模,可以处理时序数据和语言模型等任务。

神经网络与深度学习知识点整理●神经网络基础●MP神经元模型●可以完成任何数学和逻辑函数的计算●没有找到训练方法,必须提前设计出神经网络的参数以实现特定的功能●Hebb规则●两个神经元同时处于激发状态时,神经元之间的连接强度将得到加强●Hebb学习规则是一种无监督学习方法,算法根据神经元连接的激活水平改变权值,因此又称为相关学习或并联学习。
●●感知机模型●有监督的学习规则●神经元期望输出与实际输出的误差e作为学习信号,调整网络权值●●LMS学习规则是在激活函数为f(x)=x下的感知器学习规则●由于激活函数f的作用,感知器实际是一种二分类器●感知器调整权值步骤●单层感知器不能解决异或问题●BP网络●特点:●同层神经网络无连接●不允许跨层连接●无反馈连接●BP学习算法由正向传播和反向传播组成●BP网络的激活函数必须处处可导——BP权值的调整采用 Gradient Descent 公式ΔW=-η(偏E/偏w),这个公式要求网络期望输出和单次训练差值(误差E)求导。
所以要求输出值处处可导。
s函数正好满足处处可导。
●运算实例(ppt)●Delta( δ )学习规则●误差纠正式学习——神经元的有监督δ学习规则,用于解决输入输出已知情况下神经元权值学习问题●δ学习规则又称误差修正规则,根据E/w负梯度方向调整神经元间的连接权值,能够使误差函数E达到最小值。
●δ学习规则通过输出与期望值的平方误差最小化,实现权值调整●●1●自动微分●BP神经网络原理:看书●超参数的确定,并没有理论方法指导,根据经验来选择●BP算法已提出,已可实现多隐含层的神经网络,但实际只使用单隐层节点的浅层模型●计算能力的限制●梯度弥散问题●自编码器●●自编码器(Auto-Encoder)作为一种无监督学习方法网络●将输入“编码”为一个中间代码●然后从中间表示“译码”出输入●通过重构误差和误差反传算法训练网络参数●编码器不关心输出(只复现输入),只关心中间层的编码————ℎ=σ(WX+b)●编码ℎ已经承载原始数据信息,但以一种不同的形式表达!●1●正则编码器——损失函数中加入正则项,常用的正则化有L1正则和L2正则●稀疏自编码器——在能量函数中增加对隐含神经元激活的稀疏性约束,以使大部分隐含神经元处于非激活状态●去噪自编码器——训练数据加入噪声,自动编码器学习去除噪声获得无噪声污染的输入,迫使编码器学习输入信号更加鲁棒的表达●堆叠自编码器●自编码器训练结束后,输出层即可去掉,网络关心的是x到ℎ的变换●将ℎ作为原始信息,训练新的自编码器,得到新的特征表达.●逐层贪婪预训练●1●深度神经网络初始化●●卷积神经网络●全连接不适合图像任务●参数数量太多●没有利用像素之间的位置信息●全连接很难传递超过三层●卷积神经网络是一种前馈神经网络,其输出神经元可以响应部分区域内的输入信息,适宜处理图像类信息●1●1●Zero Padding:在原始图像周围补0数量●卷积尺寸缩小,边缘像素点在卷积中被计算的次数少,边缘信息容易丢失●●卷积神经网络架构发展●1●深度发展●LeNet●具备卷积、激活、池化和全连接等基本组件●但GPU未出现,CPU的性能又极其低下●LetNet只使用在手写识别等简单场景,未得到重视●LeNet主要有2个卷积层(5*5)、2个下抽样层(池化层)、3个全连接层●通过sigmoid激活●全连接层输出:共有10个节点分别代表数字0到9,采用径向基函数作为分类器●AlexNet●第一次采用了ReLU,dropout,GPU加速等技巧●AlexNet网络共有:卷积层 5个(1111,55,3*3),池化层 3个,全连接层3个●首次采用了双GPU并行计算加速模式●第一卷积模块:96通道的特征图被分配到2个GPU中,每个GPU上48个特征图;2组48通道的特征图分别在对应的GPU中进行ReLU激活●第一层全连接:同时采用了概率为0.5的Dropout策略●VGG●通过反复堆叠3x3卷积和2x2的池化,得到了最大19层的深度●卷积-ReLU-池化的基本结构●串联多个小卷积,相当于一个大卷积的思想●使用两个串联的3x3卷积,达到5x5的效果,但参数量却只有之前的18/25●串联多个小卷积,增加ReLU非线性激活使用概率,从而增加模型的非线性特征●VGG16网络包含了13个卷积层,5个池化层和3个全连接层。
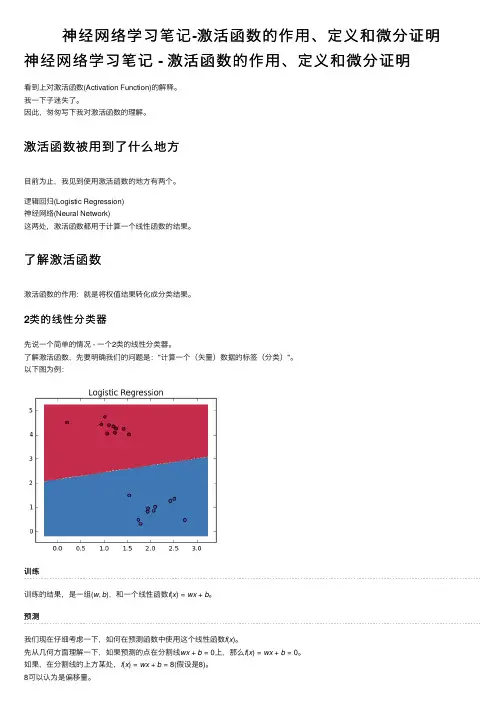
神经⽹络学习笔记-激活函数的作⽤、定义和微分证明神经⽹络学习笔记 - 激活函数的作⽤、定义和微分证明看到上对激活函数(Activation Function)的解释。
我⼀下⼦迷失了。
因此,匆匆写下我对激活函数的理解。
激活函数被⽤到了什么地⽅⽬前为⽌,我见到使⽤激活函数的地⽅有两个。
逻辑回归(Logistic Regression)神经⽹络(Neural Network)这两处,激活函数都⽤于计算⼀个线性函数的结果。
了解激活函数激活函数的作⽤:就是将权值结果转化成分类结果。
2类的线性分类器先说⼀个简单的情况 - ⼀个2类的线性分类器。
了解激活函数,先要明确我们的问题是:"计算⼀个(⽮量)数据的标签(分类)"。
以下图为例:训练训练的结果,是⼀组(w,b),和⼀个线性函数f(x)=wx+b。
预测我们现在仔细考虑⼀下,如何在预测函数中使⽤这个线性函数f(x)。
先从⼏何⽅⾯理解⼀下,如果预测的点在分割线wx+b=0上,那么f(x)=wx+b=0。
如果,在分割线的上⽅某处,f(x)=wx+b=8(假设是8)。
8可以认为是偏移量。
注:取决于(w, b),在分割线上⽅的点可以是正的,也可能是负的。
例如: y - x =0,和 x - y = 0,这两条线实际上是⼀样的。
但是,应⽤点(1, 9)的结果,第⼀个是8, 第⼆个是 -8。
问题然后,你该怎么办???如何⽤这个偏移量来得到数据的标签?激活函数激活函数的作⽤是:将8变成红⾊。
怎么变的呢?⽐如:我们使⽤sigmoid函数,sigmoid(8) = 0.99966464987。
sigmoid函数的结果在区间(0, 1)上。
如果⼤于0.5,就可以认为满⾜条件,即是红⾊。
3类分类器的情况我们再看看在⼀个多类分类器中,激活函数的作⽤。
以下图为例:训练3类a,b,c分类器的训练结果是3个(w,b),三个f(x),三条分割线。
每个f(x),可以认为是针对⼀个分类的model。

神经⽹络学习笔记2-多层感知机,激活函数1多层感知机
定义:多层感知机是在单层神经⽹络上引⼊⼀个或多个隐藏层,即输⼊层,隐藏层,输出层
2多层感知机的激活函数:
如果没有激活函数,多层感知机会退化成单层
多层感知机的公式: 隐藏层 H=XW h+b h
输出层 O=HW0+b0=(XW h+b h)W0+b0=XW h W0+b0W0+b0
其中XW h W0相当于W,b0W0+b0相当于b,即WX+b的形式,与单层的同为⼀次函数,因此重新成为了单层
3激活函数的作⽤
(1)让多层感知机成为了真正的多层感知机,否则等于⼀层的感知机
(2)引⼊⾮线性,使⽹络逼近了任意的⾮线性函数,弥补了之前单层的缺陷
4激活函数的特质
(1) 连续可导(允许少数点不可导),便于数值优化的⽅法学习⽹络参数
(2)激活函数尽可能简单,提⾼计算效率
(3)激活函数的导函数的导函数的值域要在合适的区间,否则影响训练的稳定和效率
5 常见的激活函数
1 sigmod型
常见于早期的神经⽹络,RNN和⼆分类项⽬,值域处于0到1,可以⽤来输出⼆分类的概率
弊端:处于饱和区的函数⽆法再更新梯度,向前传播困难
2 tahn(双曲正切)
3 ReLu(修正线性单元)
最常⽤的神经⽹络激活函数,不存在饱和区,虽然再z=0上不可导,但不违背激活函数的特质(允许在少数点上不可导),⼴泛运⽤于卷积⽹络等。
![[鱼书笔记]深度学习入门:基于Python的理论与实现个人笔记分享](https://uimg.taocdn.com/0157d41d77c66137ee06eff9aef8941ea76e4be7.webp)
[鱼书笔记]深度学习⼊门:基于Python的理论与实现个⼈笔记分享为了完成毕设, 最近开始⼊门深度学习.在此和⼤家分享⼀下本⼈阅读鱼书时的笔记,若有遗漏,欢迎斧正!若转载请注明出处!⼀、感知机感知机(perceptron)接收多个输⼊信号,输出⼀个信号。
如图感知机,其接受两个输⼊信号。
其中θ为阈值,超过阈值神经元就会被激活。
感知机的局限性在于,它只能表⽰由⼀条直线分割的空间,即线性空间。
多层感知机可以实现复杂功能。
⼆、神经⽹络神经⽹络由三部分组成:输⼊层、隐藏层、输出层1. 激活函数激活函数将输⼊信号的总和转换为输出信号,相当于对计算结果进⾏简单筛选和处理。
如图所⽰的激活函数为阶跃函数。
1) sigmoid 函数sigmoid函数是常⽤的神经⽹络激活函数。
其公式为:h(x)=11+e−x如图所⽰,其输出值在 0到 1 之间。
2) ReLU 函数ReLU(Rectified Linear Unit)函数是最近常⽤的激活函数。
3) tanh 函数2. 三层神经⽹络的实现该神经⽹络包括:输⼊层、2 个隐藏层和输出层。
def forward(network, x): # x为输⼊数据# 第1个隐藏层的处理,点乘加上偏置后传⾄激活函数a1 = np.dot(x, W1) + b1z1 = sigmoid(a1)# 第2个隐藏层的处理a2 = np.dot(z1, W2) + b2z2 = sigmoid(a2)#输出层处理 identidy_function原模原样输出a3a3 = np.dot(z2, W3) + b3y = identify_function(a3)return y # y为最终结果3. 输出层激活函数⼀般来说,回归问题选择恒等函数,分类问题选择softmax函数。
softmax函数的公式:y k=e a k ∑n i=1e a i假设输出层有n个神经元,计算第k个神经元的输出y k。

神经网络实学习例子1通过神经网络滤波和信号处理,传统的sigmoid函数具有全局逼近能力,而径向基rbf函数则具有更好的局部逼近能力,采用完全正交的rbf径向基函数作为激励函数,具有更大的优越性,这就是小波神经网络,对细节逼近能力更强。
BP网络的特点①网络实质上实现了一个从输入到输出的映射功能,而数学理论已证明它具有实现任何复杂非线性映射的功能。
这使得它特别适合于求解内部机制复杂的问题。
我们无需建立模型,或了解其内部过程,只需输入,获得输出。
只要BPNN结构优秀,一般20个输入函数以下的问题都能在50000次的学习以内收敛到最低误差附近。
而且理论上,一个三层的神经网络,能够以任意精度逼近给定的函数,这是非常诱人的期望;②网络能通过学习带正确答案的实例集自动提取"合理的"求解规则,即具有自学习能力;③网络具有一定的推广、概括能力。
bp主要应用回归预测(可以进行拟合,数据处理分析,事物预测,控制等)、分类识别(进行类型划分,模式识别等),在后面的学习中,都将给出实例程序。
但无论那种网络,什么方法,解决问题的精确度都无法打到100%的,但并不影响其使用,因为现实中很多复杂的问题,精确的解释是毫无意义的,有意义的解析必定会损失精度。
BP注意问题1、BP算法的学习速度很慢,其原因主要有:a由于BP算法本质上为梯度下降法,而它所要优化的目标函数又非常复杂,因此,必然会出现"锯齿形现象",这使得BP算法低效;结论4:由上表可以看出,后者的初始权值比较合适些,因此训练的时间变短,误差收敛速度明显快些。
因此初始权值的选取对于一个网络的训练是很重要的。
1.4,用最基本的BP算法来训练BP神经网络时,学习率、均方误差、权值、阈值的设置都对网络的训练均有影响。
综合选取合理的值,将有利于网络的训练。
在最基本的BP算法中,学习率在整个训练过程是保持不变的,学习率过大,算法可能振荡而不稳定;学习率过小,则收敛速度慢,训练时间长。


神经网络的基本原理与使用教程神经网络是一种模拟人脑神经元之间相互连接的计算模型,它具备学习和自适应的能力,被广泛应用于图像识别、自然语言处理、智能推荐等领域。
本文将介绍神经网络的基本原理和使用教程,帮助读者更好地理解和应用这一强大的工具。
一、神经网络的基本原理神经网络由输入层、隐藏层和输出层组成。
输入层接收外部输入数据,隐藏层进行信息处理和特征提取,输出层产生最终的结果。
每个神经元接收来自上一层神经元的输入,并通过激活函数进行非线性转换,将结果传递给下一层神经元。
在神经网络中,最常用的激活函数是Sigmoid函数和ReLU函数。
Sigmoid函数将输入值映射到0到1之间的概率值,适用于输出层的二分类问题。
ReLU函数在输入大于0时输出输入值,小于0时输出0,适用于隐藏层的非线性变换。
神经网络的训练过程通过反向传播算法实现。
首先,随机初始化神经网络的权重和偏置。
然后,将输入数据送入神经网络,计算输出结果。
接着,根据输出结果与真实标签之间的误差,通过梯度下降法更新权重和偏置,不断优化网络的性能。
重复这一过程直到收敛,即网络的输出与真实标签之间的误差达到可接受的范围。
二、神经网络的使用教程1. 数据预处理在使用神经网络之前,需要对输入数据进行预处理。
常见的预处理方法包括数据归一化、特征选择和数据增强。
数据归一化可以将输入数据缩放到0到1之间,提高神经网络的收敛速度和稳定性。
特征选择可以从原始数据中选择最具有代表性的特征,减少输入维度,提高网络的泛化能力。
数据增强可以通过旋转、平移、缩放等操作扩充数据集,增加样本的多样性,提高网络的鲁棒性。
2. 网络结构设计神经网络的结构设计是应用中的关键一步。
合理的网络结构可以提高网络的性能和效率。
常见的网络结构包括全连接神经网络、卷积神经网络和循环神经网络。
全连接神经网络适用于处理结构化数据,如表格数据和时间序列数据。
卷积神经网络适用于处理图像数据,通过卷积和池化操作提取图像的局部特征。

神经网络使用方法及步骤详解随着人工智能的快速发展,神经网络成为了一个热门的研究方向。
神经网络是一种模拟人脑神经元相互连接的计算模型,它可以用来解决各种复杂的问题。
本文将详细介绍神经网络的使用方法及步骤。
一、神经网络的基本原理神经网络由多个神经元组成,这些神经元之间通过连接进行信息传递。
每个神经元都有一个权重,用来调整信号的传递强度。
神经网络通过不断调整权重,从而学习到输入和输出之间的映射关系。
这个过程称为训练。
二、神经网络的训练步骤1. 数据准备:首先,需要准备一组有标签的训练数据。
标签是指输入和输出之间的对应关系。
例如,如果要训练一个神经网络来识别手写数字,那么输入就是一张手写数字的图片,输出就是对应的数字。
2. 网络结构设计:接下来,需要设计神经网络的结构。
神经网络通常包括输入层、隐藏层和输出层。
输入层负责接收输入数据,隐藏层用来提取特征,输出层用来产生结果。
3. 权重初始化:在训练之前,需要对神经网络的权重进行初始化。
通常可以使用随机数来初始化权重。
4. 前向传播:在训练过程中,需要将输入数据通过神经网络进行前向传播。
前向传播是指将输入数据从输入层经过隐藏层传递到输出层的过程。
在每个神经元中,输入数据将与权重相乘,并经过激活函数处理,得到输出。
5. 计算损失:在前向传播之后,需要计算神经网络的输出与标签之间的差距,这个差距称为损失。
常用的损失函数有均方误差和交叉熵等。
6. 反向传播:反向传播是指根据损失来调整神经网络的权重,使得损失最小化。
反向传播通过计算损失对权重的导数,然后根据导数来更新权重。
7. 权重更新:通过反向传播计算得到权重的导数之后,可以使用梯度下降等优化算法来更新权重。
优化算法的目标是使得损失函数最小化。
8. 重复训练:以上步骤需要重复多次,直到神经网络的损失收敛到一个较小的值为止。
三、神经网络的应用神经网络在各个领域都有广泛的应用。
其中,图像识别是神经网络的一个重要应用之一。
神经网络模型的使用教程与实践案例神经网络模型是近年来人工智能领域中备受关注的热门技术之一。
它模仿人脑的神经元网络,通过学习和训练,可以实现识别、分类、预测等复杂任务。
本文将为大家介绍神经网络模型的使用教程和一些实践案例,帮助读者更好地理解和应用这一技术。
一、神经网络的基本结构和原理神经网络模型由多个神经元(节点)组成,分为输入层、隐藏层和输出层。
每个神经元通过带有权重的连接与其他神经元相连,这些权重表示了不同神经元之间传递信息的强度。
神经网络通过将输入数据传递给神经元,并经过权重调整和激活函数的处理,最终输出预测结果。
神经网络的训练过程是通过与已知结果进行比对,不断调整网络中的权重值来实现的。
常用的训练算法包括反向传播算法(backpropagation)和梯度下降算法(gradient descent)。
这两种算法可以根据网络的反馈误差进行权重的更新,使得网络的输出结果逼近已知结果,从而提高预测准确性和学习能力。
二、神经网络模型的使用教程1. 数据准备和预处理在使用神经网络之前,首先需要准备好合适的数据集。
数据集的品质直接影响模型的训练效果和预测准确性。
同时,还需要对数据进行预处理,包括数据清洗、归一化、特征选择等操作。
这样可以提高神经网络模型对数据的理解和学习能力,避免因数据质量问题导致模型性能下降。
2. 构建神经网络模型神经网络模型的构建需要确定输入层、隐藏层和输出层的节点数量,以及各个节点之间的连接关系。
常用的神经网络类型包括前馈神经网络、循环神经网络和卷积神经网络等。
根据待解决的问题类型选择合适的网络类型。
3. 网络训练与优化神经网络的训练是一个迭代的过程。
需要确定合适的损失函数(loss function)来度量模型的预测误差,并选择合适的优化算法来更新权重值。
在训练过程中,可以使用交叉验证的方法来评估模型的性能,并根据验证结果进行调整和改进,以获得更好的模型效果。
4. 模型评估和预测完成训练后,需要对模型进行评估和验证。
RBF、GRNN、PNN神经⽹络学习笔记RBF神经⽹络:径向基函数神经⽹络(Radical Basis Function)GRNN神经⽹络:⼴义回归神经⽹络(General Regression Neural Network)PNN神经⽹络:概率神经⽹络(Probabilistic Neural Network)径向基函数神经⽹络的优点:逼近能⼒,分类能⼒和学习速度等⽅⾯都优于BP神经⽹络,结构简单、训练简洁、学习收敛速度快、能够逼近任意⾮线性函数,克服局部极⼩值问题。
原因在于其参数初始化具有⼀定的⽅法,并⾮随机初始化(见习下⾯的代码)。
⾸先我们来看RBF神经⽹络隐藏层中神经元的变换函数即径向基函数是对中⼼点径向对称且衰减的⾮负线性函数,该函数是局部响应函数,具体的局部响应体现在其可见层到隐藏层的变换,跟其它的⽹络不同。
RBF神经⽹络的基本思想:⽤RBF(径向基函数)作为隐单元的“基”构成隐藏层空间,隐藏层对输⼊⽮量进⾏变换,将低维的模式输⼊数据变换到⾼维空间内,使得在低维空间内的线性不可分问题在⾼维空间内线性可分。
详细⼀点就是⽤RBF的隐单元的“基”构成隐藏层空间,这样就可以将输⼊⽮量直接(不通过权连接)映射到隐空间。
当RBF的中⼼点确定以后,这种映射关系也就确定了。
⽽隐含层空间到输出空间的映射是线性的(注意这个地⽅区分⼀下线性映射和⾮线性映射的关系),即⽹络输出是因单元输出的线性加权和,此处的权即为⽹络可调参数。
《模式识别与只能计算》中介绍:径向基⽹络传递函数是以输⼊向量与阈值向量之间的距离|| X-Cj ||作为⾃变量的,其中|| X -Cj ||是通过输⼊向量和加权矩阵C的⾏向量的乘积得到。
此处的C就是隐藏层各神经元的中⼼参数,⼤⼩为(隐层神经元数⽬*可见层单元数)。
再者,每⼀个隐神经元中⼼参数C都对应⼀个宽度向量D,使得不同的输⼊信息能被不同的隐层神经元最⼤程度地反映出来。
得到的这个R就是隐藏层神经元的值。
神经网络的基本知识点总结一、神经元神经元是组成神经网络的最基本单元,它模拟了生物神经元的功能。
神经元接收来自其他神经元的输入信号,并进行加权求和,然后通过激活函数处理得到输出。
神经元的输入可以来自其他神经元或外部输入,它通过一个权重与输入信号相乘并求和,在加上偏置项后,经过激活函数处理得到输出。
二、神经网络结构神经网络可以分为多层,一般包括输入层、隐藏层和输出层。
输入层负责接收外部输入的信息,隐藏层负责提取特征,输出层负责输出最终的结果。
每一层都由多个神经元组成,神经元之间的连接由权重表示,每个神经元都有一个对应的偏置项。
通过调整权重和偏置项,神经网络可以学习并适应不同的模式和规律。
三、神经网络训练神经网络的训练通常是指通过反向传播算法来调整网络中每个神经元的权重和偏置项,使得网络的输出尽可能接近真实值。
神经网络的训练过程可以分为前向传播和反向传播两个阶段。
在前向传播过程中,输入数据通过神经网络的每一层,并得到最终的输出。
在反向传播过程中,通过计算损失函数的梯度,然后根据梯度下降算法调整网络中的权重和偏置项,最小化损失函数。
四、常见的激活函数激活函数负责对神经元的输出进行非线性变换,常见的激活函数有Sigmoid函数、Tanh函数、ReLU函数和Leaky ReLU函数等。
Sigmoid函数将输入限制在[0,1]之间,Tanh函数将输入限制在[-1,1]之间,ReLU函数在输入大于0时输出等于输入,小于0时输出为0,Leaky ReLU函数在输入小于0时有一个小的斜率。
选择合适的激活函数可以使神经网络更快地收敛,并且提高网络的非线性拟合能力。
五、常见的优化器优化器负责更新神经网络中每个神经元的权重和偏置项,常见的优化器有梯度下降法、随机梯度下降法、Mini-batch梯度下降法、动量法、Adam优化器等。
这些优化器通过不同的方式更新参数,以最小化损失函数并提高神经网络的性能。
六、常见的神经网络模型1、全连接神经网络(Fully Connected Neural Network):每个神经元与下一层的每个神经元都有连接,是最基础的神经网络结构。
深度学习笔记(3)神经⽹络,学习率,激活函数,损失函数神经⽹络(NN)的复杂度空间复杂度:计算神经⽹络的层数时只统计有运算能⼒的层,输⼊层仅仅起到将数据传输进来的作⽤,没有涉及到运算,所以统计神经⽹络层数时不算输⼊层输⼊层和输出层之间所有层都叫做隐藏层层数 = 隐藏层的层数 + 1个输出层总参数个数 = 总w个数 + 总b个数时间复杂度:乘加运算次数学习率以及参数的更新:w t+1=w t−lr∗∂loss ∂w t指数衰减学习率的选择及设置可以先⽤较⼤的学习率,快速得到较优解,然后逐步减⼩学习率,使模型在训练后期稳定。
指数衰减学习率 = 初始学习率 * 学习率衰减率(当前轮数 / 多少轮衰减⼀次)指数衰减学习率=初始学习率∗学习率衰减率当前轮数多少轮衰减⼀次#学习率衰减import tensorflow as tfw = tf.Variable(tf.constant(5, dtype=tf.float32))epoch = 40LR_BASE = 0.2LR_DECAY = 0.99LR_STEP = 1for epoch in range(epoch):lr = LR_BASE * LR_DECAY**(epoch / LR_STEP)with tf.GradientTape() as tape:loss = tf.square(w + 1)grads = tape.gradient(loss, w)w.assign_sub(lr * grads)print("After %2s epoch,\tw is %f,\tloss is %f\tlr is %f" % (epoch, w.numpy(), loss,lr)) After 0 epoch, w is 2.600000, loss is 36.000000 lr is 0.200000After 1 epoch, w is 1.174400, loss is 12.959999 lr is 0.198000After 2 epoch, w is 0.321948, loss is 4.728015 lr is 0.196020After 3 epoch, w is -0.191126, loss is 1.747547 lr is 0.194060After 4 epoch, w is -0.501926, loss is 0.654277 lr is 0.192119After 5 epoch, w is -0.691392, loss is 0.248077 lr is 0.190198After 6 epoch, w is -0.807611, loss is 0.095239 lr is 0.188296After 7 epoch, w is -0.879339, loss is 0.037014 lr is 0.186413After 8 epoch, w is -0.923874, loss is 0.014559 lr is 0.184549After 9 epoch, w is -0.951691, loss is 0.005795 lr is 0.182703After 10 epoch, w is -0.969167, loss is 0.002334 lr is 0.180876After 11 epoch, w is -0.980209, loss is 0.000951 lr is 0.179068After 12 epoch, w is -0.987226, loss is 0.000392 lr is 0.177277After 13 epoch, w is -0.991710, loss is 0.000163 lr is 0.175504After 14 epoch, w is -0.994591, loss is 0.000069 lr is 0.173749After 15 epoch, w is -0.996452, loss is 0.000029 lr is 0.172012After 16 epoch, w is -0.997660, loss is 0.000013 lr is 0.170292After 17 epoch, w is -0.998449, loss is 0.000005 lr is 0.168589After 19 epoch, w is -0.999308, loss is 0.000001 lr is 0.165234After 20 epoch, w is -0.999535, loss is 0.000000 lr is 0.163581After 21 epoch, w is -0.999685, loss is 0.000000 lr is 0.161946After 22 epoch, w is -0.999786, loss is 0.000000 lr is 0.160326After 23 epoch, w is -0.999854, loss is 0.000000 lr is 0.158723After 24 epoch, w is -0.999900, loss is 0.000000 lr is 0.157136After 25 epoch, w is -0.999931, loss is 0.000000 lr is 0.155564After 26 epoch, w is -0.999952, loss is 0.000000 lr is 0.154009After 27 epoch, w is -0.999967, loss is 0.000000 lr is 0.152469After 28 epoch, w is -0.999977, loss is 0.000000 lr is 0.150944After 29 epoch, w is -0.999984, loss is 0.000000 lr is 0.149434After 30 epoch, w is -0.999989, loss is 0.000000 lr is 0.147940After 31 epoch, w is -0.999992, loss is 0.000000 lr is 0.146461After 32 epoch, w is -0.999994, loss is 0.000000 lr is 0.144996After 33 epoch, w is -0.999996, loss is 0.000000 lr is 0.143546After 34 epoch, w is -0.999997, loss is 0.000000 lr is 0.142111After 35 epoch, w is -0.999998, loss is 0.000000 lr is 0.140690After 36 epoch, w is -0.999999, loss is 0.000000 lr is 0.139283After 37 epoch, w is -0.999999, loss is 0.000000 lr is 0.137890After 38 epoch, w is -0.999999, loss is 0.000000 lr is 0.136511After 39 epoch, w is -0.999999, loss is 0.000000 lr is 0.135146激活函数sigmoid 函数tf.nn. sigmoid(x)f (x )=11+e−x图像:相当于对输⼊进⾏了归⼀化多层神经⽹络更新参数时,需要从输出层往输⼊层⽅向逐层进⾏链式求导,⽽sigmoid 函数的导数输出是0到0.25之间的⼩数,链式求导时,多层导数连续相乘会出现多个0到0.25之间的值连续相乘,结果将趋近于0,产⽣梯度消失,使得参数⽆法继续更新且sigmoid 函数存在幂运算,计算⽐较复杂tanh 函数tf.math. tanh(x)f (x )=1−e −2x1+e−2x图像:和上⾯提到的sigmoid 函数⼀样,同样存在梯度消失和幂运算复杂的缺点Relu 函数tf.nn.relu(x)f (x )=max (x ,0)=0(x <0)时或者x (x >=0)时图像:Relu 函数在正区间内解决了梯度消失的问题,使⽤时只需要判断输⼊是否⼤于0,计算速度快训练参数时的收敛速度要快于sigmoid 函数和tanh 函数输出⾮0均值,收敛慢Dead RelU 问题:送⼊激活函数的输⼊特征是负数时,激活函数输出是0,反向传播得到的梯度是0,致使参数⽆法更新,某些神经元可能永远不会被激活。
Deep Learning(深度学习)学习笔记整理系列目录:一、概述二、背景三、人脑视觉机理四、关于特征4.1、特征表示的粒度4.2、初级(浅层)特征表示4.3、结构性特征表示4.4、需要有多少个特征?五、Deep Learning的基本思想六、浅层学习(Shallow Learning)和深度学习(Deep Learning)七、Deep learning与Neural Network八、Deep learning训练过程8.1、传统神经网络的训练方法8.2、deep learning训练过程九、Deep Learning的常用模型或者方法9.1、AutoEncoder自动编码器9.2、Sparse Coding稀疏编码9.3、Restricted Boltzmann Machine(RBM)限制波尔兹曼机9.4、Deep BeliefNetworks深信度网络9.5、Convolutional Neural Networks卷积神经网络十、总结与展望十一、参考文献和Deep Learning学习资源接上注:下面的两个Deep Learning方法说明需要完善,但为了保证文章的连续性和完整性,先贴一些上来,后面再修改好了。
9.3、Restricted Boltzmann Machine (RBM)限制波尔兹曼机假设有一个二部图,每一层的节点之间没有链接,一层是可视层,即输入数据层(v),一层是隐藏层(h),如果假设所有的节点都是随机二值变量节点(只能取0或者1值),同时假设全概率分布p(v,h)满足Boltzmann 分布,我们称这个模型是Restricted BoltzmannMachine (RBM)。
下面我们来看看为什么它是Deep Learning方法。
首先,这个模型因为是二部图,所以在已知v的情况下,所有的隐藏节点之间是条件独立的(因为节点之间不存在连接),即p(h|v)=p(h1|v)…p(h n|v)。
循环神经网络RNN学习笔记
一、循环神经网络简介
循环神经网络,英文全称:Recurrent Neural Network,或简单记为RNN。
需要注意的是,递归神经网络(Recursive Neural Network)的简写也是RNN,但通常RNN指循环神经网络。
循环神经网络是一类用于处理序列数据的神经网络。
它与其他神经网络的不同是,RNN 可以更好的去处理序列的信息,即认准了前后的输入之间存在关系。
在NLP中,去理解一整句话,孤立的理解组成这句话的词显然是不够的,我们需要整体的处理由这些词连接起来的整个序列。
如:(1) 我饿了,我要去食堂___。
(2) 我饭卡丢了,我要去食堂___。
很显然,第一句话是想表明去食堂就餐,而第二句则很有可能因为刚吃过饭,发现饭卡不见了,去食堂寻找饭卡。
而在此之前,我们常用的语言模型是N-Gram,无论何种语境,可能去食堂大概率匹配的是“吃饭”而不在乎之前的信息。
RNN就解决了N-Gram的缺陷,它在理论上可以往前(后)看任意多个词。
此文是我在学习RNN中所做的笔记,参考资料在文末提及。
二、循环神经网络分类
a.简单的MLP神经网络
简单的MLP三层网络模型,x、o为向量,分别表示输入层、输出层的值;U、V为矩阵,U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵。
b.循环神经网络
与简单的MLP神经网络不容的是,循环神经网络的隐藏层的值s不仅取决于当前的这次输入x,还取决于上一次隐藏层的值s。
权重就在W就是隐藏层上一次的值作为这一次输入的输入的权重。
将上图展开:。
神经网络
一、神经网络简介
人工神经网络(ANN),简称神经网络,是一种模仿生物神经网络的结构和功能的数学模型或计算模型。
神经网络由大量的人工神经元联结进行计算。
大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。
现代神经网络是一种非线性统计性数据建模工具,常用来对输入和输出间复杂的关系进行建模,或用来探索数据的模式物理结构:人工神经元将模拟生物神经元的功能
计算模拟:人脑的神经元有局部计算和存储的功能,通过连接构成一个系统。
人工神经网络中也有大量有局部处理能力的神经元,也能够将信息进行大规模并行处理存储与操作:人脑和人工神经网络都是通过神经元的连接强度来实现记忆存储功能,同时为概括、类比、推广提供有力的支持
训练:同人脑一样,人工神经网络将根据自己的结构特性,使用不同的训练、学习过程,自动从实践中获得相关知识
神经网络是一种运算模型,由大量的节点(或称“神经元”,或“单元”)和之间相互联接构成。
每个节点代表一种特定的输出函数,称为激励函数。
每两个节点间的连接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。
网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。
而网络自身通常都是对自然界某种算法或者函数的逼近,也可能是对一种逻辑策略的表达。
二、BP神经网络算法描述
1、sigmoid函数分类
回顾我们前面提到的感知器,它使用示性函数作为分类的办法。
然而示性函数作为分类器它的跳点让人觉得很难处理,幸好sigmoid函数y=1/(1+e^-x)有类似的性质,且有着光滑性这一优良性质。
我们通过下图可以看见sigmoid函数的图像:
错误!
Sigmoid函数有着计算代价不高,易于理解与实现的优点但也有着欠拟合,分类精度不高的特性,我们在支持向量机一章中就可以看到sigmoid函数差劲的分类结果
确定隐藏层的节点个数
2、BP神经网络结构
BP (Back Propagation)神经网络,即误差反传误差反向传播算法的学习过程,由信息的正向传播和误差的反向传播两个过程组成。
由下图可知,BP神经网络是一个三层的网络:
输入层(input layer):输入层各神经元负责接收来自外界的输入信息,并传递给中间层各神经元;
隐藏层(Hidden Layer):中间层是内部信息处理层,负责信息变换,根据信息变化能力的需求,中间层可以设计为单隐层或者多隐层结构;最后一个隐层传递到输出层各神经元的信息,经进一步处理后,完成一次学习的正向传播处理过程;
输出层(Output Layer):顾名思义,输出层向外界输出信息处理结果;
当实际输出与期望输出不符时,进入误差的反向传播阶段。
误差通过输出层,按误差梯度下降的方式修正各层权值,向隐藏层、输入层逐层反传。
周而复始的信息正向传播和误差反向传播过程,是各层权值不断调整的过程,也是神经网络学习训练的过程,此过程一直进行到网络输出的误差减少到可以接受的程度,或者预先设定的学习次数为止
3、反向传播算法
反向传播这一算法把我们前面提到的delta规则的分析扩展到了带有隐藏节点的神经网络。
为了理解这个问题,设想Bob给Alice讲了一个故事,然后Alice又讲给了Ted,Ted 检查了这个事实真相,发现这个故事是错误的。
现在 Ted 需要找出哪些错误是Bob造成的而哪些又归咎于Alice。
当输出节点从隐藏节点获得输入,网络发现出现了误差,权系数的调整需要一个算法来找出整个误差是由多少不同的节点造成的,网络需要问,“是谁让我误入歧途?到怎样的程度?如何弥补?”这时,网络该怎么做呢?
同样源于梯度降落原理,在权系数调整分析中的唯一不同是涉及到t(p,n)与y(p,n)的差分。
通常来说Wi的改变在于:
alpha * s'(a(p,n)) * d(n) *X(p,i,n)
其中d(n)是隐藏节点n的函数,让我们来看:
n 对任何给出的输出节点有多大影响;
输出节点本身对网络整体的误差有多少影响。
一方面,n 影响一个输出节点越多,n 造成网络整体的误差也越多。
另一方面,如果输出节点影响网络整体的误差越少,n 对输出节点的影响也相应减少。
这里d(j)是对网络的整体误差的基值,W(n,j) 是 n 对 j 造成的影响,d(j) * W(n,j) 是这两种影响的总和。
但是 n 几乎总是影响多个输出节点,也许会影响每一个输出结点,这样,d(n) 可以表示为:SUM(d(j)*W(n,j))
这里j是一个从n获得输入的输出节点,联系起来,我们就得到了一个培训规则。
第1部分:在隐藏节点n和输出节点j之间权系数改变,如下所示:
alpha *s'(a(p,n))*(t(p,n) - y(p,n)) * X(p,n,j)
第 2 部分:在输入节点i和输出节点n之间权系数改变,如下所示:
alpha *s'(a(p,n)) * sum(d(j) * W(n,j)) * X(p,i,n)
这里每个从n接收输入的输出节点j都不同。
关于反向传播算法的基本情况大致如此。
通常把第 1部分称为正向传播,把第2部分称为反向传播。
反向传播的名字由此而来。
4、最速下降法与其改进
最速下降法的基本思想是:要找到某函数的最小值,最好的办法是沿函数的梯度方向探寻,如果梯度记为d,那么迭代公式可写为w=w-alpha*d,其中alpha可理解为我们前面提到的学习速率。
最速下降法有着收敛速度慢(因为每次搜索与前一次均正交,收敛是锯齿形的),容易陷入局部最小值等缺点,所以他的改进办法也有不少,最常见的是增加动量项与学习率可变。
增加冲量项(Momentum)
修改权值更新法则,使第n次迭代时的权值的更新部分地依赖于发生在第n‐1次迭代时的更新
Delta(w)(n)=-alpha*(1-mc)*Delta(w)(n)+mc*Delta(w)(n-1)
右侧第一项就是权值更新法则,第二项被称为冲量项
梯度下降的搜索轨迹就像一个球沿误差曲面滚下,冲量使球从一次迭代到下一次迭代时以同样的方向滚动
冲量有时会使这个球滚过误差曲面的局部极小值或平坦区域
冲量也具有在梯度不变的区域逐渐增大搜索步长的效果,从而加快收敛。
改变学习率
当误差减小趋近目标时,说明修正方向是正确的,可以增加学习率;当误差增加超过一个范围时,说明修改不正确,需要降低学习率。
R语言实现
library(AMORE)
# 数据载入及处理
dat <- read.table('german.data-numeric', header=F)
for (i in 1:25) {
dat[,i] <- as.numeric(as.vector(dat)[,i])
}
# 划分训练集和测试集
train_dat <- dat[1:500,]
test_dat <- dat[501:1000,]
# 进行训练
net <- newff(n.neurons=c(24,8,2,1), learning.rate.global=1e-2,
momentum.global=0.5,
error.criterium="LMS", Stao=NA, yer="tansig",
yer="purelin", method="ADAPTgdwm")
result <- train(net, train_dat[1:24], train_dat[25], error.criterium="LMS", report=TRUE, show.step=100, n.shows=5 )
# 进行测试
y <- sim(result$net, test_dat[1:24])
y[which(y<1.5)] <- 1
y[which(y>=1.5)] <- 2
# 计算正确率
sum = 0
for(i in 1:500){
if(y[i]==test_dat[i,25]){ sum =sum+1
}
}
cat("正确率", sum/500, "n")。