
转录组ref流程工作手册
一、Reference 流程生物学原理
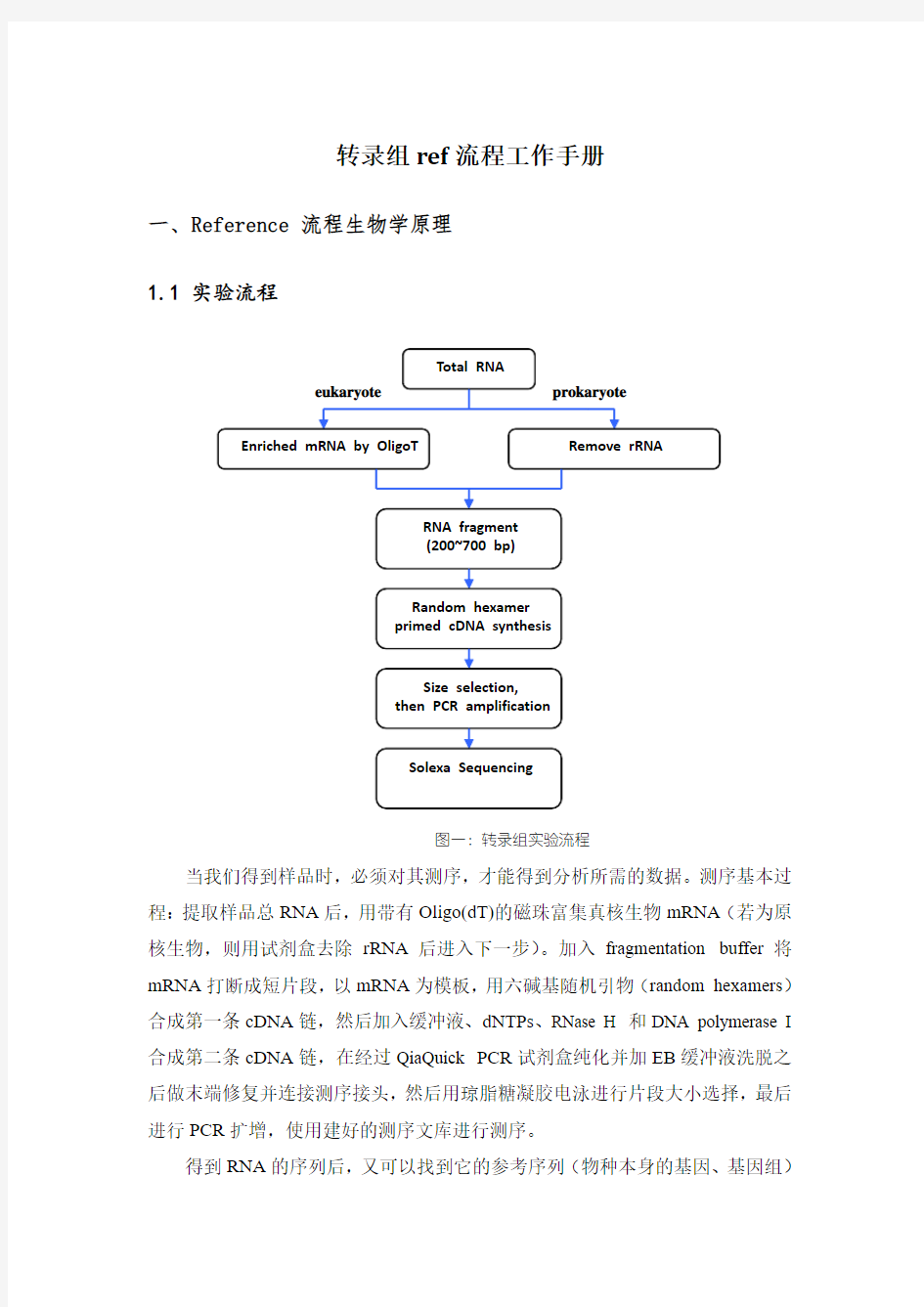
1.1 实验流程
RNA fragment Random hexamer Size selection,prokaryote
eukaryote
Total RNA
Enriched mRNA by OligoT Remove rRNA
(200~700 bp)
primed cDNA synthesis
then PCR amplification
Solexa Sequencing
图一:转录组实验流程
当我们得到样品时,必须对其测序,才能得到分析所需的数据。测序基本过程:提取样品总RNA后,用带有Oligo(dT)的磁珠富集真核生物mRNA(若为原核生物,则用试剂盒去除rRNA后进入下一步)。加入fragmentation buffer将mRNA打断成短片段,以mRNA为模板,用六碱基随机引物(random hexamers)合成第一条cDNA链,然后加入缓冲液、dNTPs、RNase H 和DNA polymerase I 合成第二条cDNA链,在经过QiaQuick PCR试剂盒纯化并加EB缓冲液洗脱之后做末端修复并连接测序接头,然后用琼脂糖凝胶电泳进行片段大小选择,最后进行PCR扩增,使用建好的测序文库进行测序。
得到RNA的序列后,又可以找到它的参考序列(物种本身的基因、基因组)
时,可以用reference流程对数据进行详细的分析。Reference后面所有的流程都是基于参考序列进行的,所以选择正确的参考序列十分重要。
1.2信息分析流程
得到测序序列后,即可利用比对软件,将所测序列比对到参考基因或基因组上,并进行后续分析,信息分析流程图如下:
图二:转录组信息流程
1.2.1原始fq序列简介
测序得到的原始图像数据经base calling转化为序列数据,我们称之为raw data或raw reads,结果以fastq文件格式存储,fastq文件为用户得到的最原始文件,里面存储reads的序列以及reads的测序质量。在fastq格式文件中每个read 由四行描述:
@read ID
TGGCGGAGGGATTTGAACCC
+
bbbbbbbbabbbbbbbbbbb
每个序列共有4行,第1行和第3行是序列名称(有的fq文件为了节省存储空间会省略第三行“+”后面的序列名称),由测序仪产生;第2行是序列;第4行是序列的测序质量,每个字符对应第2行每个碱基,第四行每个字符对应的ASCII值减去64,即为该碱基的测序质量值,比如h 对应的ASCII值为104,那么其对应的碱基质量值是40。碱基质量值范围为0到40。表 1为Solexa测序错误率与测序质量值简明对应关系,具体计算公式如下:
Q phred =-10 log10(e)
表 1 Solexa测序错误率与测序质量值简明对应关系
测序错误率测序质量值对应字符5% 13 M
1% 20 T
0.1% 30 ^
0.01% 40 h
1.2.2原始fq序列处理
某些原始序列带有adaptor 序列,或含有少量低质量序列。我们首先经过一系列数据处理以去除杂质数据,得到Clean reads。
按如下步骤进行处理:
1.去除含adaptor的reads
2.去除N的比例大于10%的reads
3.去除低质量reads(质量值Q <= 5的碱基数占整个read的50%以上)
4.获得 Clean reads
原始序列数据经过去除杂质后得到的数据称为Clean reads,后续分析都基于Clean reads
1.2.3比对
使用短reads比对软件SOAP2/SOAPaligner{Li, 2009 #155}将clean reads分别比对到参考基因组和参考基因序列(允许两个碱基错配)。
通过这一步骤,我们可以将测序得到的reads对应到基因及基因组上,后续分析都是基于上述比对结果。
1.2.4基本生物信息分析结果
基本信息分析结果包含以下内容:
1 测序数据产量及与Reference 比对结果概述
统计数据量的大小,得到测序数据产量;对soap结果进行处理得到测序数据与Reference序列比对的概况。
2 评价测序随机性
在转录组实验过程中,首先要通过物理或化学方法将转录本打断成短片段,然后上机测序。如果打断随机性差,reads偏向于来自基因特定区域,将会直接影响转录组的各项分析结果。
利用reads在基因上的分布来评价打断随机性。由于不同参考基因有不同长度,我们把reads在基因上的位置标准化到相对位置(reads在基因上的位置与基因长度的比值),然后统计基因的不同位置比对上的reads数。如果打断随机性好,reads在基因各部位应分布得比较均匀。
3 基因覆盖度、测序深度的分布
基因测序覆盖度指每个基因被reads覆盖的百分比,其值等于基因中unique mapping reads覆盖的碱基数跟基因编码区所有碱基数的比值。测序深度指基因被reads 覆盖的次数,其值等于reads覆盖到基因的碱基数与基因编码区所有碱基数的比值。
4 Reads 在参考基因组上的分布
该分析主要是以图形方式概括给出Reads在基因组各个位置的分布情况,以及该位置基因的分布情况。
1.2.5高级生物信息分析结果
高级生物信息分析包含以下结果:
1 对基因结构进行优化
通过比较测序结果和现有基因注释结果,对基因的5'端或3'端进行延长。如图三所示,首先,将reads比对到基因组,提取基因组中被unique mapping reads覆盖的次数大于或等于某阈值(默认为2)且位置连续的区域作为转录活性区(Transcription Active Region, TAR,图中蓝色方块区域);然后通过paired-end reads(图中紫色线条)将不同的TAR连接形成潜在的gene model;最后,通过比较潜在gene model与现有基因注释的差别,对基因的5'端和3'端进行延长(图中表现的仅是基因3’端发生延长的情况)。
图三:基因结构优化
2 鉴定基因的可变剪切
可变剪切使一个基因产生多个mRNA转录本,不同mRNA可能翻译成不同蛋白。因此,通过可变剪切一个基因可能产生多个蛋白,极大地增加了蛋白多样性{Black, 2003 #6}{Stamm, 2005 #21;Lareau, 2004 #22}。虽然已知可变剪切在真核生物中普遍存在,但我们可能仍低估了可变剪切的比例,最近,基于高通量测序的可变剪切研究在人{Pan, 2008 #3} {Wang,
2008 #4} {Sultan, 2008 #5}、小鼠{Tang, 2009 #18;Mortazavi, 2008 #19}、拟南芥{Filichkin, #156}中发现了很多新的可变剪切事件。
在生物体内,主要存在7种可变剪切类型:A)Exon skipping; B)Intron retention;
C) Alternative 5’splice site; D) Alternative 3’splice site; E) Alternative first exon; F) Alternative last exon; G) Mutually exclusive exon. 下图是我们利用高通量测序数据鉴别出来的7种可变剪切。图中每个位置的ExP.Level等于log2(Reads数)。
图四:可变剪切示意图
A) Exon Skipping. 基因AK070385发生可变剪切形成两种不同的转录本,第1种转录本比第2种转录组本多一个外显子(exon), 我们将这种外显子称为inclusive exon, inclusive exon两侧的两个外显子称为 constitutive exon。B) Intron retention. 基因AK072590发生可变剪切形成两种不同的转录本,第2种转录本由retained Intron 与两侧的外显子一起形成新的外显子。C) Alternative 5’ splice site. 基因AK067602发生可变剪切形成两种不同的转录本,它们的3’端剪切位点一致但5’端剪切位点不同。D) Alternative 3’splice site. 基因AK067602发生可变剪切形成两种不同的转录本,它们的5’端剪切位点一致但3’端剪切位点不同。E) Alternative First Exon. 基因AK068497发生可变剪切形成两种不同的转录本,它们的不同之处在于第一个外显子不同。F) Alternative Last Exon. 基因AK064908发生可变剪切形成两种不同的转录本,它们的不同
之处在于最后一个外显子不同。G) Mutually Exclusive Exon. 基因AK101575发生可变剪切形成两种不同的转录本,两转录本之间相同的外显子称为constitutive exon,不同的外显子称为inclusive exon,两个inclusive exon不能同时存在与同一转录本中,只能分别存在于不同转录本中。
下面,概述检测可变剪切的算法。首先,我们使用软件“tophat”{Trapnell, 2009 #1}鉴定转录本的剪切位点(junction site)(使用软件默认参数),剪切位点给出了转录本不同外显子的边界及组合关系,如图五,我们检测到三个剪切位点,分别表明Exon1和Exon2连接在一起,Exon2和Exon3连接在一起,Exon1和Exon3连接在一起。
图五剪切位点示意图
然后,通过分析同一基因的所有剪切位点,找出各种可变剪切事件。分析算法如下:
A) Exon Skipping.
图六 Exon Skipping算法示意图
转录本1和转录本2分别同时检测到如图六所示三个剪切位点,可认为转录本1的Exon1、Exon2和Exon3存在Exon Skipping剪切方式;转录本2的Exon1、Exon3和Exon4也存在Exon Skipping剪切方式。
B) Intron Retention
图七 Intron Retention算法示意图
如图七所示,1)检测到Junction 1的存在,表明在某个成熟mRNA中Exon1和Exon2之间的Intron被剪切下来;2)Exon1和Exon2之间的Intron有90%以上的区域均有unique mapping reads覆盖,说明在某个成熟mRNA中该intron被保留下来了(考虑到转录的exon通常也不是100%被reads覆盖到,所以在这里以90%为阈值)。若同时满足以上两个条件,则认为该基因
Exon1和Exon2之间存在Intron Retention的可变剪切方式。
C) Alternative 5’ Splice Site
图八 Alternative 5’ Splice Site算法示意图
如图八,一个转录本的Junction 1位点被检测到,并且Junction 2 和Junction 3 中有一个被检测到(它们共同点是3’剪切位点和Junction 1相同,但5’剪切位点和Junction 1不同),那么就认为Exon1和Exon2 存在Alternative 5’ Splice Site的剪切方式。
D) Alternative 3’ Splice Site
图九 Alternative 3’ Splice Site算法示意图
如图九,一个转录本的Junction 1位点被检测到,并且Junction 2 和Junction 3 中有一个被检测到(它们共同点是5’剪切位点和junction 1相同,但3’剪切位点和junction 1不同),那么就认为Exon1和Exon2 存在Alternative 3’ Splice Site的剪切方式。
E) Alternative First Exon
图十 Alternative First Exon算法示意图
如图十,首先,要求检测到如图所示两个junction位点;其次,不能检测到支持Exon1和Exon2与5’端的Exons有连接的junction位点。要求以上两个条件同时满足,且这种情况出现在转录本的最5’端,但不要求Exon1为这个转录本的第一个外显子,也不要求被junction连接的外显子都是相邻的,如转录本2中的Exon2和Exon4。所以,图中转录本1的Exon1、Exon2和Exon3存在Alternative First Exon的可变剪切方式,转录本2中Exon1、Exon2和Exon4也存在Alternative First Exon的可变剪切方式。
F) Alternative Last Exon
图十一 Alternative Last Exon算法示意图
如图十一,转录本1为例,首先,要求检测到如图所示两个junction位点(Junction1和Junction2);其次,不能检测到支持Exon1和Exon2与3’端的Exons有连接的junction位点。要求以上两个条件同时满足,且这种情况出现在转录本的最3’端,但不要求Exon3为这个转录本的最后一个外显子,也不要求被junction连接的外显子都是相邻的,如转录本2中的Exon1和Exon4。所以,图中转录本1的Exon1、Exon2和Exon3存在Alternative Last Exon的可变剪切方式,转录本2中Exon1、Exon3和Exon4也存在Alternative Last Exon的可变剪切方式。
G) Mutually Exclusive Exon
图十二 Mutually Exclusive Exon算法示意图
检测到如图十二所示四个junction位点,且不能检测到支持Exon2和Exon3有连接位点的junction位点,则认为该转录本的Exon1、Exon2、Exon3和Exon4之间存在Mutually Exclusive Exon 的可变剪切方式。
3 发现新转录本
现有数据库中对转录本的注释可能还不全面,通过高通量测序我们能检测到新的转录本{Mortazavi, 2008 #103}。我们首先从潜在gene model中挑选出长度大于150bp且平均覆盖度大于2的gene model,再从中找出位于基因间区域(一个基因3’端下游200bp到下一个基因5’端上游200bp之间的区域)的潜在gene model作为候选的新转录本。
4 基因结构以及Reads 在基因组上分布的精确图形
该分析主要是以图形方式概括给出Reads在基因组各个位置的分布情况,以及该位置基因的分布情况。我们画出Reads在最长的25条染色体上的分布图,该图为SVG 矢量图,如果你的浏览器不支持SVG,请安装SVGView 插件。
5 基因差异表达分析
5.1基因表达量
基因表达量的计算使用RPKM法(Reads Per Kb per Million reads){Mortazavi, 2008 #103},其计算公式为:
设RPKM(A)为基因A的表达量,则C为唯一比对到基因A的reads数,N为唯一比对到基因组的总reads数,L为基因A编码区的碱基数。RPKM法能消除基因长度和测序量差异对计算基因表达的影响,计算得到的基因表达量可直接用于比较不同样品间的基因表达差异。
如果一个基因存在多个转录本,则用该基因的最长转录本计算其测序覆盖度和表达量。
5.2差异分析
差异表达分析找出在不同样本间存在差异表达的基因,并对差异表达基因做GO功能分析和KEGG Pathway分析。
参照Audic S.等人发表在Genome Research上的基于测序的差异基因检测方法{Audic, 1997 #8}(该文献已被引用超过五百次),我们开发了严格的算法筛选两样本间的差异表达基因。
假设观测到基因A对应的reads数为x,已知在一个大文库中,每个基因的表达量只占所有基因表达量的一小部分,在这种情况下,p(x)的分布服从泊松分布:
已知,样本一中唯一比对到基因组的总reads数为N1,样本二中唯一比对到基因组的总reads 数为N2,样本一中唯一比对到基因A的总reads数为x,样本二中唯一比对到基因A的总reads数为y,则基因A在两样本中表达量相等的概率可由以下公式计算:
然后,我们对差异检验的p value作多重假设检验校正,通过控制FDR(False Discovery Rate)来决定p value的域值。假设挑选了R个差异表达基因,其中S个是真正有差异表达的基因,另外V个是其实没有差异表达的基因,为假阳性结果。希望错误比例Q=V/R平均而言不能超过某个可以容忍的值,比如1%,则在统计时预先设定FDR不能超过0.01(Benjamini, Yekutieli. 2001)。在得到差异检验的FDR值同时,我们根据基因的表达量(RPKM值)计算该基因在不同样本间的差异表达倍数。FDR值越小,差异倍数越大,则表明表达差异越显著。在我们的分析中,差异表达基因定义为FDR≤0.001且倍数差异在2倍以上的基因。得到差异表达基因之后,我们对差异表达基因做GO功能分析和KEGG Pathway分析。
GO功能分析一方面给出差异表达基因的GO功能分类注释;另一方面给出差异表达基因的GO功能显著性富集分析。
GO功能分类注释给出具有某个GO功能的基因列表及基因数目统计。
GO功能显著性富集分析给出与基因组背景相比,在差异表达基因中显著富集的GO功能条目,从而给出差异表达基因与哪些生物学功能显著相关。该分析首先把所有差异表达基因向Gene Ontology数据库(https://www.doczj.com/doc/4519073714.html,/)的各个term映射,计算每个term的基因数目,然后应用超几何检验,找出与整个基因组背景相比,在差异表达基因中显著富集的GO条目,其计算公式为
其中,N为所有基因中具有GO注释的基因数目;n为N中差异表达基因的数目;M为所有基因中注释为某特定GO term的基因数目;m为注释为某特定GO term的差异表达基因数目。计算得到的p value通过Bonferroni校正之后,以corrected p value≤0.05为阈值,满足此条件的GO term定义为在差异表达基因中显著富集的GO term。通过GO功能显著性富集分析能确定差异表达基因行使的主要生物学功能。
我们的GO功能分析同时整合了表达模式聚类分析,研究人员能方便地看到具有某一功能的所有差异基因的表达模式。例,immune response为在差异表达基因中最显著富集的一个GO term(表2)。图十三显示了参与immune response的差异基因的表达模式。
表2 在差异表达基因中显著富集的GO-term
图十三参与immune response的差异基因表达模式聚类图
KEGG Pathway分析
在生物体内,不同基因相互协调行使其生物学功能,基于Pathway的分析有助于更进一步了解基因的生物学功能。KEGG是有关Pathway的主要公共数据库{Kanehisa, 2008 #96},Pathway显著性富集分析以KEGG Pathway为单位,应用超几何检验,找出与整个基因组背景相比,在差异表达基因中显著性富集的Pathway。该分析的计算公式同GO功能显著性富集分析,在这里N为所有基因中具有Pathway注释的基因数目;n为N中差异表达基因的数目;M为所有基因中注释为某特定Pathway的基因数目;m为注释为某特定Pathway的差异表达基因数目。FDR≤0.05的Pathway定义为在差异表达基因中显著富集的Pathway。通过Pathway显著性富集能确定差异表达基因参与的最主要生化代谢途径和信号转导途径。结果如表3所示。
表3pathway显著性富集分析列表
各列意义如下:
# 序号
Pathway 通路名
DEGs with pathway annotation (2085) 注释到该通路的差异表达基因的数目
All genes with pathway annotation
注释到该通路的所有基因的数目
(8986)
Pvalue 超几何检验的P 值
Qvalue Q 值(Q ≤ 0.05 为在差异表达基因中显著富集的Pathway)Pathway ID KEGG 数据库中的Pathway ID
注:Qvalue ≤ 0.05 的pathway 在差异表达基因中显著富集,见表中红框所示。
差异表达基因的pathway 显著性富集分析不但得到最有意义的pathway 列表,点击其中的pathway 链接还将得到KEGG 数据库中pathway 的详细信息,如点击表3第一列第三行的
B cell receptor signaling pathway,可以看到如图十四所示的详细信息,上调基因所在位置用
红色标记,下调基因所在位置用绿色标记。
图十四 KEGG 数据库中 B cell receptor signaling pathway 的详细信息
二、Reference 工作流程
工作流程如下:
2.1前期工作
1)创建项目目录:
由于每个子项目都有自己的子项目代码,且名字简洁,建议使用子项目代码为项目创建目录,随着手头做过项目的增加,如果有需要,建议先以时期为依据创建大目录,再在其下创建项目目录;
2) 项目记录:
随着项目的增加,所需记得项目各方面信息内容也会增加,如果需要的话,建议使用excel电子表格记录平时的项目信息,以方便查询,包括:项目名称、子项目代码、项目结果路径、开始时间、阶段性进展、结束时间、截止
时间、网址链接等等;
2.2写工作文件
1)文件模板
根据信息任务描述,选好两个文件的模板,放于所创建的项目目录下;
2)找fq文件
方法1:(根据文库名查找)
find /share/fqdata10/solexa/ -name "*ARAcqfTARAAPE*fq"
查找结果:
/share/fqdata10/solexa/HSZ09076_ARAcqfT_transcriptome_Transcriptome/ARAcqfTARAAPE/1 00114_I649_0002_FC42T26AAXX/100114_I649_FC42T26AAXX_L7_ARAcqfTARAAPE/100 114_I649_FC42T26AAXX_L7_ARAcqfTARAAPE_1.fq
/share/fqdata10/solexa/HSZ09076_ARAcqfT_transcriptome_Transcriptome/ARAcqfTARAAPE/1 00114_I649_0002_FC42T26AAXX/100114_I649_FC42T26AAXX_L7_ARAcqfTARAAPE/100 114_I649_FC42T26AAXX_L7_ARAcqfTARAAPE_2.fq
方法2:(根据项目编号查找)
cd /share/fqdata10/solexa/
cd HSZ09076 敲入tab键
查找结果:
dr-xr-xr-x 3 solexa solexa 41 Jan 25 13:28 ARAcqfTARAAPE
dr-xr-xr-x 3 solexa solexa 41 Jan 25 13:28 ARAcqfTBRAAPE
方法3:(根据子项目代码查找)
cd /share/fqdata10/solexa/
cd *_ARAcqfT_*
查找结果:
dr-xr-xr-x 3 solexa solexa 41 Jan 25 13:28 ARAcqfTARAAPE
dr-xr-xr-x 3 solexa solexa 41 Jan 25 13:28 ARAcqfTBRAAPE
数据存放路径:
一般在以下几个库中:
/share/fqdata12/solexa/ (2010年2-3月的数据)
/share/fqdata10/solexa/ (2010年1-2月的数据)
/share/fastdata1/solexa (09年11月份下机的数据)
/share/solid2/solexa-work/Project_solexa_fq (09年10-11月份下机的数据)/share/solid1/solexa-work/Project_solexa_fq (09年9-10月份下机的数据)
以下是09年9月之前可以查找的:
/share/raid007/ solexa-work/Project_solexa_fq
/share/raid009/ solexa-work/Project_solexa_fq
/share/raid7/ solexa-work/Project_solexa_fq
3)找参考序列(包括参考基因组、参考基因、psl文件)
如合作伙伴提供参考序列,则使用合作伙伴提供的参考序列。如合作伙伴未提供,找到相关数据后,将链接发送给合作伙伴确认可行后方能使用。
4)根据要求修改模板
不熟悉各个参数的作用,可以输入以下代码查看程序帮助:
Perl /ifs1/DGE_SR/hezengquan/bin/ref/reference_transcriptome_pipeline.pl
/ifs1/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/soap
2.3 投任务
1)运行运行文件
sh maid.sh
cd result/
2)nohup sh *_final.sh >*_final.sh.nohup &
2.4 查看任务进展
1)操作任务的命令行:
查看个人所有在跑任务:qstat -u * (用户是*)
查看某一个在跑任务:qstat -j 24832|less (任务号是24832)
杀掉个人所有在跑任务:qdel -u *
杀掉某一个在跑任务:qdel 24832
如果是因为某一个运行文件出错导致需要杀掉所要相关在跑任务,应该先杀掉这个在公共节点上跑的任务
如:上面*_final.sh出错了,可以按以下步骤处理:
top -u daichm
按c键查看详细信息,找出所要杀掉的任务,假设*_final.sh对应的任务号是23849
则可按k键,输入工作号,回车然后按9再回车即可杀掉该任务,再去做上面操作。
2)查看整个任务进展:
a.查看*_final.sh.nohup
b.进入part_shell目录,查看相应的任务运行信息,主要有可以查看以下几个文件:
*. globle
*.log
进入下一层目录,查看.o和.e文件。
找出问题所在并进行处理。
2.5 任务完成
1)结果检查:
a,结题报告是否完整生成?
b,打包数据中,相关文件是否齐全?
c,分析要求是否都做好了,差异分析有没有漏掉?
d,有没有空文件产生?
2)数据备份:
由于各方面的原因,产生的数据有可能会丢失,建议对一些重要的数据在相对稳定的盘阵里做多一个备份,以免发生不必要的大麻烦。
三、Reference 流程程序模块说明
配置文件:ref.lib
主程序脚本:maid.sh
perl reference_transcriptome_pipeline.pl -name huyang -lib ref.lib -outdir /ifs1/DGE_SR/daichm/project/HUYlfvT/result -diff -filter -2bwt -soap 2.20 -genome Populus_euphratica.0114.genome -gene Populus_euphratica.0114.cds -psl Populus_euphratica.0114.gff.psl -doall -verbose
关键程序:reference_transcriptome_pipeline.pl
其各项参数代表意思:
Usage
basic parameters:--基本参数
-name
-lib
-outdir
-genome
-gene
-psl
analysis options:--分析选项
-soap
-filter Filter reads--过滤数据,得到clean reads,一般也是必须选项
-div Divide analysis by chromosome name,if all chromosomes' size is large.--基因组大时按染色体分块处理
-doall Do all analysis below,including 5 parts.--包括以下五个选项
-basic Do basic analysis.--基本生物信息分析
-alter Alternative Splice analysis--高级生物信息分析中的可变剪切
-novel Novel Transcript analysis--高级生物信息分析中的发现新转录本
-utr ExtendGene analysis--高级生物信息分析中的基因结构优化
-svg Produce SVG figure--基因结构以及Reads 在基因组上分布的精确图形
-diff Gene expression difference--高级生物信息分析中的差异表达基因
-verbose output verbose information to screen--输出运行信息到标准
输出上
-help
使用参数说明:
命令示例:
1) bwt,filter
对应程序:/ifs1/DGE_SR/daichm/project/HUYlfvT/result/part_shell/bwt_filter.sh
详细情况:
a).基因组建库:
/panfs/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/2bwt-builder
/ifs1/DGE_SR/daichm/project/HUYlfvT/Populus_euphratica.0114.genome
b).基因建库:
/panfs/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/2bwt-builder
/ifs1/DGE_SR/daichm/project/HUYlfvT/Populus_euphratica.0114.cds
c).样本数据过滤(举其中一例):
sh /ifs1/DGE_SR/daichm/project/HUYlfvT/result/part_shell/Filter.huiyang_chuli_L1.sh
2) soap
a).对基因组所建的库跑soap:(举其中一例)
/panfs/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/soap -a /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Reads/huiyang_chuli_L1_1.fq -b /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Reads/huiyang_chuli_L1_2.fq -D /ifs1/DGE_SR/daichm/project/HUYlfvT/Populus_euphratica.0114.genome.index -m 0 -x 10000 -s 40 -l 35 -v 3 -o /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Alignment/Genome/huiyang_chuli_L1.Genome.P ESoap -2 /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Alignment/Genome/huiyang_chuli_L1.Genome.P ESoapSingle
b).对基因所建的库跑soap:(举其中一例)
/panfs/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/soap -a /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Reads/huiyang_chuli_L1_1.fq -b /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Reads/huiyang_chuli_L1_2.fq -D /ifs1/DGE_SR/daichm/project/HUYlfvT/Populus_euphratica.0114.cds.index -m 0 -x 1000 -s 40 -l 35 -v 3 -r 2 -o /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Alignment/Gene/huiyang_chuli_L1.Gene.PESoap -2
/ifs1/DGE_SR/daichm/project/HUYlfvT/result/Alignment/Gene/huiyang_chuli_L1.Gene.PESoap Single
关键程序:/panfs/DGE_SR/hezengquan/soft/SOAPaligner/soap2.20release/soap
其各项参数代表意思:
Usage: soap [options]
-a
-b
-D
-o
-M
0: exact match only
1: 1 mismatch match only
2: 2 mismatch match only
4: find the best hits
-u
-t output reads id instead reads name, [none]
-l
-n
-r [0,1,2] how to report repeat hits, 0=none; 1=random one; 2=all, [1]
-m
-x
-2
-v
-s
-g
-R for long insert size of pair end reads RF. [none](means FR pair)
-e
-p
-h this help
3) posCoverage
a)对单样本处理
/ifs1/DGE_SR/daichm/project/HUYlfvT/result/part_shell/samples_pos.sh
其中用到的程序为:
/nas/DGE_SR01/daichm/ref/posCoverage
b)合并所有样本
/ifs1/DGE_SR/daichm/project/HUYlfvT/result/part_shell/posCoverage.sh
其中用到的程序为:
/nas/DGE_SR01/daichm/ref/merge_poscoverage.pl
4) transcript-unit
/ifs1/DGE_SR/daichm/project/HUYlfvT/result/part_shell/TranscritUnit.sh
a).PosCoverage.TAR
其中用到的程序为:
/nas/DGE_SR01/daichm/ref/Mask2Tar.pl
b).Filter
其中用到的程序为:
awk '$3>35 {print}'
/ifs1/DGE_SR/daichm/project/HUYlfvT/result/Poscoverage/AllChr.AllTissue.PosCoverage.TAR > /ifs1/DGE_SR/daichm/project/HUYlfvT/result/Poscoverage/AllTissue.PosCoverage.TAR.Filter
计划部作为承接设计生产及市场销售前后各个环节的核心部门,其主要功能在予通过严谨的 科学分析和市场调查制订出合理的生产物流计划,并指导市场销售工作。根据计划部目前的 实际情况和工作要求现将计划分析工作职能明细如下: 一、生产计划: a 、工作职责 1 、依据公司企业高层管理所制订的下年度和下季度的销售指标和市场拓展方向,结合 计划部分析 员所提供的公司上年度和上季度的实际销售情况和对季末总仓库存的预测量,同时对本 行业和外部环境的发展方向作一预测,在此基础上制订出各个不同季度的产品总体开发计划; 2 、依据本年度的市场反馈情况和调查资料给设计部提供下一年度的款式开发方向。(要求时间: 春夏季 5 月15 日之前;秋冬季10 月15 日之前) 3 、依据计划部分析员对上季度所销售货品的详细分析结果,通过对每次参与商务部所 召开的每旬 销售分析会议中的各区域市场的动态状况进行季末汇总,辅之以生产计划员对公司不同 区域市场的一手调查资料,从而制订出各个不同季度的产品生产开发计划(达标要求:①、每季新品的主款比重要占到新品总款数的30%;②、必须将每季新品划分为主款( 含以低价冲击市场的畅销款) 、尝试款、陪衬款三大块;③、主款数量以全铺为原则按原定生产计划走;陪 衬款为一次性做货分片区销售,原则上不进行补单;尝试款为首单少量投放重点有代表性片 区试销,视其销售效果而决定是否加单及加单量的大小;④、陪衬款及尝试款的开发量及首 单规格比要以物流分布计划员的前期总体物流分布计划为依据标准制订); 4 、将经过公司企业高层管理讨论核准后的各个不同季度的产品详细生产开发计划下达 至开发部 的设计人员,并对开发部的新款设计过程进行指导与追踪,以确保设计研发结果能与市 场的需求保持方向上的统一; 5 、依据物流计划员在确定新品款式、颜色的同期所必须制订的上市货期计划安排,将 其登录到生 产订单所对应的出货期一栏并下达至开发部并严格要求其按照货期单走货,以确保公司 和各专卖店的销售和新货品的上市推广; 6 、为有效地将规避风险和尽最大限度地保证各专卖店的货源的供给这两方面结合起来, 生产计划 员要与开发部一道制订可大大提高加单速度的可实施性的备布、染布计划,并进行监督; 7 、每个不同销售季节不定期下派到占公司销售重点的有代表性的不同区域市场开展市 场调查工 作,调查的目标重点是:a、休闲服的年龄定位发展趋势;b、休闲服主要消费者的性别 比例变化趋势;c、休闲服的款式、版形、颜色、面料的流行趋势;d、休闲服的类别的变化 发展趋势等等; 7 、要加强对休闲服装的专业化知识的学习,提高自身的素养和技能水平——附加的一项 重要要求。 b 、工作流程: 1 、产品生产计划制定流程: (分单)(生产) 2 、货期计划流程: c 、工作时间要求:
全基因组重测序数据分析 1. 简介(Introduction) 通过高通量测序识别发现de novo的somatic和germ line 突变,结构变异-SNV,包括重排 突变(deletioin, duplication 以及copy number variation)以及SNP的座位;针对重排突变和SNP的功能性进行综合分析;我们将分析基因功能(包括miRNA),重组率(Recombination)情况,杂合性缺失(LOH)以及进化选择与mutation之间的关系;以及这些关系将怎样使 得在disease(cancer)genome中的mutation产生对应的易感机制和功能。我们将在基因组 学以及比较基因组学,群体遗传学综合层面上深入探索疾病基因组和癌症基因组。 实验设计与样本 (1)Case-Control 对照组设计; (2)家庭成员组设计:父母-子女组(4人、3人组或多人); 初级数据分析 1.数据量产出:总碱基数量、Total Mapping Reads、Uniquely Mapping Reads统计,测序深度分析。 2.一致性序列组装:与参考基因组序列(Reference genome sequence)的比对分析,利用贝叶斯统计模型检测出每个碱基位点的最大可能性基因型,并组装出该个体基因组的一致序列。3.SNP检测及在基因组中的分布:提取全基因组中所有多态性位点,结合质量值、测序深度、重复性等因素作进一步的过滤筛选,最终得到可信度高的SNP数据集。并根据参考基 因组信息对检测到的变异进行注释。 4.InDel检测及在基因组的分布: 在进行mapping的过程中,进行容gap的比对并检测可信的short InDel。在检测过程中,gap的长度为1~5个碱基。对于每个InDel的检测,至少需 要3个Paired-End序列的支持。 5.Structure Variation检测及在基因组中的分布: 能够检测到的结构变异类型主要有:插入、缺失、复制、倒位、易位等。根据测序个体序列与参考基因组序列比对分析结果,检测全基因组水平的结构变异并对检测到的变异进行注释。
商 品 部 作 业 手 册 商品信息部适用 年月 目录
一、商品部的职能架构 二、商品部的部门职责描述 三、商品部的岗位职责描述 四、商品部人员素质要求 五、商品采购管理 六、商品上市管理 七、商品销售管理 八、商品库存管理 九、商品信息管理 十、商品部工作表格 十一、总公司相关部门负责人联络表
一、商品部职能架构 解说: 商品部的工作核心是采购。采购任务由商品部及商品采购人员计划和执行,参与采购过程的人员主要有: 、商品部经理 主要负责采购任务规划,收集各种同类产品信息并做出决策 、商品采购专员 商品部经理制定期货采购的初步计划以后,由数据分析专员做数据分析,由商品采购专员、 销售部、零售发展部提出采购建议。商品部经理在整个采购过程中起主要决策作用。其他相关 人员或部门由于直面客户,了解客户及当地市场的具体情况,能够提供新鲜有力的采购建议, 因此,其在采购决策中的地位也是极其重要的。
二、商品部工作职责 商品部的主要日常工作就是商品的规划管理,这实际上是个循环往复的过程:采购→货品计划(上市、推广、发货)→发货→商品、市场信息收集、分析→调整采购计划→下一季采购。详细的工作职责如下: (一)采购计划管理 制定完整的全年及应季采购计划与补货、调划计划,并逐月分摊到每个月 配合总公司,分公司的市场推广计划作相应的产品规划 (二)采购管理 根据采购计划科学、合理、准确地完成一年季的商品采购目标 协同零售发展部制订商品上市、推广策略并监督执行 (三)货品计划管理 结合总公司的到货时间反馈,制定发货计划 制定货品统一发货安排表,由销售部执行
商品部工作规划 商品部工作规划简介:作为商品的企划、控制、管理部门,商品部的工作是对公司整体产品链在.商品部工作规划正文:作为商品的企划、控制、管理部门,商品部的工作是对公司整体产品链在各个运作环节上的规划、控制、支持与反馈。 在产品链前端,商品部配合设计部做好产品上市波段规划、产品品类结构规划、产品价位规划、产品主题规划、面料,色彩,款型建议等。 在产品打样阶段,商品部配合板房及生产部做好产品技术控制与工艺品质指导。 在产品生产阶段,商品部做好定价工作,配合生产部进行出货期安排。 工厂成品产出后,商品部配合生产部及物流部做好商品入库与POS系统档案维护工作。 产品上市时,商品部配合营销部做好产品的上市配发工作。 产品销售阶段商品部配合营销部做好商品的补、配、调、退工作。 为营销部提供销售分析数据支持,为营销部促销活动提供方案支持。 产品销售阶段,商品部为设计部、生产部、物流部、营销部提供货品反馈意见,并协调各部门对所出现的问题及时进行调整。 产品销售周期结束,商品部对季度货品进行总结性分析,结合终端的各方面意见反馈,为各部门在后续产品方面的工作提供相应支持。 商品部具体工作内容: 一、商品企划工作。 1、季度产品总体开发前,做好季度产品总体运作时间节点规划,规划产品开发、打样、生产、上市等起止时间段,有效控制季度货品总体进度。
2、季度产品上市波段、品类结构、价位结构规划,同时协助设计部做好波段主题规划,面料、色彩、款型等规划。 3、季度货品销售数据总结,为下一季度货品开发提供数据支持。 4、商品档案、资料整理,商品零售价制定,为评审会及订货会提供货品资料与订货支持。 5、ERP系统的商品信息的更新与维护。 二、商品管理工作。 1、新品到仓入库跟进,并根据产品上市波段安排货品上市工作。 2、了解每家店铺的货场面积、货架结构,计算每家店铺不同季节货品的铺货量及存货量,对店铺货品总量进行控制。 3、每周对每家店铺进行货品销存分析,及时了解店铺每款、色、码产品的库存与销售情况,并与店铺保持沟通,为店铺进行补货、调拨、退货等工作。 4、通过巡店与数据分析,了解每家店铺的销售特性,顾客年龄结构,顾客喜好的情况,有针对性对店铺进行货品调控及季度订货指导。 5、与物流部的日常沟通工作。 6、整理收集店铺对货品方面的信息反馈。 三、销售分析工作。 1、每周、月、季度对货品、店铺销售情况进行总结与对比分析。 2、针对不同促销活动进行活动效果分析,为店铺以后活动推广提供经验总结。 3、了解公司总体货品的进、销、存情况,并进行销售预估,及时协助营销部提出相关促销与折扣方案。
全基因组从头测序(de novo测序) https://www.doczj.com/doc/4519073714.html,/view/351686f19e3143323968936a.html 从头测序即de novo 测序,不需要任何参考序列资料即可对某个物种进行测序,用生物信息学分析方法进行拼接、组装,从而获得该物种的基因组序列图谱。利用全基因组从头测序技术,可以获得动物、植物、细菌、真菌的全基因组序列,从而推进该物种的研究。一个物种基因组序列图谱的完成,意味着这个物种学科和产业的新开端!这也将带动这个物种下游一系列研究的开展。全基因组序列图谱完成后,可以构建该物种的基因组数据库,为该物种的后基因组学研究搭建一个高效的平台;为后续的基因挖掘、功能验证提供DNA序列信息。华大科技利用新一代高通量测序技术,可以高效、低成本地完成所有物种的基因组序列图谱。包括研究内容、案例、技术流程、技术参数等,摘自深圳华大科技网站 https://www.doczj.com/doc/4519073714.html,/service-solutions/ngs/genomics/de-novo-sequencing/ 技术优势: 高通量测序:效率高,成本低;高深度测序:准确率高;全球领先的基因组组装软件:采用华大基因研究院自主研发的SOAPdenovo软件;经验丰富:华大科技已经成功完成上百个物种的全基因组从头测序。 研究内容: 基因组组装■K-mer分析以及基因组大小估计;■基因组杂合模拟(出现杂合时使用); ■初步组装;■GC-Depth分布分析;■测序深 度分析。基因组注释■Repeat注释; ■基因预测;■基因功能注释;■ ncRNA 注释。动植物进化分析■基因家族鉴定(动物TreeFam;植物OrthoMCL);■物种系统发育树构建; ■物种分歧时间估算(需要标定时间信息);■基因组共线性分析; ■全基因组复制分析(动物WGAC;植物WGD)。微生物高级分析 ■基因组圈图;■共线性分析;■基因家族分析; ■CRISPR预测;■基因岛预测(毒力岛); ■前噬菌体预测;■分泌蛋白预测。 熊猫基因组图谱Nature. 2010.463:311-317. 案例描述 大熊猫有21对染色体,基因组大小2.4 Gb,重复序列含量36%,基因2万多个。熊猫基因组图谱是世界上第一个完全采用新一代测序技术完成的基因组图谱,样品取自北京奥运会吉祥物大熊猫“晶晶”。部分研究成果测序分析结果表明,大熊猫不喜欢吃肉主要是因为T1R1基因失活,无法感觉到肉的鲜味。大熊猫基因组仍然具备很高的杂合率,从而推断具有较高的遗传多态性,不会濒于灭绝。研究人员全面掌握了大熊猫的基因资源,对其在分子水平上的保护具有重要意义。 黄瓜基因组图谱黄三文, 李瑞强, 王俊等. Nature Genetics. 2009. 案例描述国际黄瓜基因组计划是由中国农业科学院蔬菜花卉研究所于2007年初发起并组织,并由深圳华大基因研究院承担基因组测序和组装等技术工作。部分研究成果黄瓜基因组是世界上第一个蔬菜作物的基因组图谱。该项目首次将传
商品部工作流程与管理制度 一、经销商 1:总则: 为做好公司产品宣传、推广、销售以及公司品牌形象宣传,提高销售业绩,制定本制度。所有商品部成员均应以本制度为依据开展工作。商品部经理对所属商品部成员进行考核和管理。 2:商品部工作流程: 1)订货会流程: A:根据前期销售数据、仓库库存状况,同季度货品销售状况,制定订货结构(包括:品类、颜色、配码、数量比例); B:根据总部下达的任务,客户同季度的销售情况做好预期任务分期; C:根据各区域销售情况,总部的订货政策制定相应的经销商期货政策; D:政策交由副总经理审核; E:给经销商下达订货任务; F:订货会现场选货、订货、输单、与客户核对订单,无误签字确认,收取订金; G:总部评审后删除款告知客户,要求补货; H:总部下达合同后做订货评审; I:按政策未评审到的款式及时跟经销商沟通,更换其他货品; J:安排上货 2)客户回款发货流程: A:客房补单;
B:排单员查货并报给客户总金额; C:客户打款; D:排单员见款后安排发货; 3)客房回访流程: A:排单员按照客户销售业绩自行设计和计划个人月、周和每天的客户电访计划; B:排单员在每周五的部门例会上向商品部经理汇报下周的客户沟通重点计划情况,并接受指导,最终确定下周沟通重点; C:排单员按照客户电访计划对客户进行电访; D:在电访结束后,应将相关信息如实记录; E:及时将电访信息向商品部主管汇报; F:商品主管对排单员的工作予以指导和安排; G:每周六排单员及商品主管向商品部经理汇报一周的电访情况及未(难)解决的问题,经理组织大家一起讨论,最后由经理给出相应的解决方案; 4)仓库入库流程: A:在货运站到货后,由仓库根据到货单核对到货数量,确认无误后交由仓库主管进行复查并签具单据; B:统计在系统中导出入库单,入库单交由仓管; C:仓管安排入库人员先进行库位整理,整理时按出库整理要求进行整理,然后在进行入库; D:入库时,根据系统建议和库位实际情况进行入库; E:入库人员入库时应和库存的货号、颜色叠放在一起,不能随意乱叠,
DNA测序标准实验流程(V1.2版)1.对DNA的要求 纯度:OD 260 / OD 280 = 1.6 ~ 2.0, PCR产物用量:每反应15 -20ng(片段大于3KB可加两倍DNA)。 质粒DNA用量:每反应20 -25ng(插入片段大于3KB质粒要加两倍DNA)。 1300载体本身序列就比较长,我们建议每反应加50-80ng。 每个小组一次配100份BD MIX(BD 0.4ul,5*buffer 1.8ul,water 2.8ul)长期保存,每个反应体系加5ul 2.P CR产物的测序PCR反应(测序PCR反应中只要加一个引物就可以,需要加热盖) 标准反应体系: 10ul体系 试剂用量 纯化的P CR产物(15-20 ng / μL) 1 μL (片段大于3KB可加两倍DNA) 引物(2 pmol / μL) 1 μL BigDye (2.5 x) 0.4 μL BigDye Seq Buffer (5 x) 1.8μL 灭菌去离子水 5.8μL 96 °C 1 min → (96 °C 10 sec → 50 °C 5 sec → 60 °C 2 min) x 25个循环→ 4 °C保温 质粒DNA的测序PCR反应 标准反应体系: 10ul体系 试剂用量 质粒DNA (20-25 ng / μL) 1 μL (插入片段大于3KB质粒要加两倍DNA) 引物(2 pmol / μL) 1 μL BigDye (2.5 x) 0.4 μL BigDye Seq Buffer (5 x) 1.8 μL 灭菌去离子水 5.8 μL 96 °C 1 min → (96 °C 10 sec → 50 °C 5 sec → 60 °C 2 min) x 25个循环→ 4 °C保温 注意:BigDye (2.5 x)是一种含有DNA聚合酶和荧光物质的混合物,非常昂贵,平时都放在-20度保存。加之前拿出来放在冰上融化,用完马上放回-20冰箱。BigDye (2.5 x)和BigDye Seq Buffer (5 x)可以混合后一起加到反应体系,有多的话可以放在-20冰箱,下次还能使用。 BIGDYE尽量避光,一般用铝珀纸遮盖。P CR样品处理过程中如在室温放置和酒精挥发阶段都尽量用铝珀纸遮盖或者放入抽屉,有利于样品的稳定性。 3.测序产物纯化 单个0.2 mL离心管离心方法: 1. 每孔加入1μL 7.5M NH3Ac,26μL 100%酒精,盖好,震荡4次。(酒精和NH3Ac先混合好,而且要比样品数多预算几个) 2. 台式离心机12000 x g 4°C离心20 min,马上用枪吸尽上清液。(DNA很微量,基本看不到,所以枪头不要碰到DNA沉积处) 3. 每孔加入100μL 75% 酒精,12000 x g 4°C离心10 min,马上用枪吸尽上清液。(如果不是马上操作,DNA沉淀很可能 浮起,被吸走,所以如果没有及时吸去上清的话,要重新离心5MINS。) 4. 让酒精在室温避光(抽屉)挥发干净(至少20mins),加入10 μL Hi-Di Formamide溶解DNA。 5. 在PCR仪上变性:95 °C 4 min,4 °C 4 min。上机测序。 96孔板整板离心方法: 1. 每孔加入1μL 7.5M NH3Ac,26μL 100%酒精,盖好,震荡4次。(酒精和NH3Ac先混合好,而且要比样品数多预算几个) 2. 板式离心机4000 x rpm 4°C离心30min;马上倒置96孔板,弃上清,倒置在洗水纸上,离心500rpm,1mins。 3. 加100μL 75% 酒精,4000 rpm 4°C离心20 min;马上倒置96孔板,弃上清,离心500rpm,1mins。 4.让酒精在室温避光(抽屉)挥发干净(至少15mins),加入10 μL Hi-Di For mamide溶解DNA。 5. 在PCR仪上变性:95 °C 4 min,4 °C 4 min。上机测序。 4. 部分相关试剂 酒精:100%酒精使用国产分析纯;75%酒精用去离子水配制。 BigDye (2.5 x) -20度保存 BigDye Seq Buffer (5 x) 4度保存 7.5M NH3Ac 4度保存 Hi-Di For mamide -20度保存 黄方亮 2009.10.27日整理
连锁药店商品部日常工作流程 一、日常工作 每周: 1.每周一早上门店上交三类周计划到商品部吴菲菲处,三类周计划(日化副 食器械)样表已做好,直接根据门店需求填写所需的数量和门店。门店上交截止时间:上午12:00,抽奖记录(样表已做好),直接汇总上周会员日抽奖赠送的礼品数量上交到商品部XXX处,同时前台随单下账,下账时间仅限每周一下午,其他时间下账一律按违规处理 上交截止时间:下午16:30. 小票保存好在下月店长会同抽奖登记表一同上交 2.每周二早上门店上交上周下发的市调表,店长根据收到市调表后打印平均分 给店内同事,店内员工去周边最具竞争力的药店市调店长汇总完后上交,上交前请核实一下所调商品的信息、价格的准确性,在市调表里填上对应的市调门店及市调价格、本店零售价、建议价,截止时间:上午12:00。商品部在3个工作日内调价并通知门店更换价签 每天: 3.每天下午16:00—17:00发放每天商品信息变更《换价签明细》,门店及时更 换价签。打印价签操作流程:信息中心------其他资料-------自定价签条码----机构标示选择自己所在的门店-----输入需要换价签产品的货号---------打印—自定义打印 4.每天早上汇总门店的每日必交工作表(新品需求、价格带需求、市调)及成 功案例分享表(要求每天上午10点之前上报一个前一天门店销售做的最优秀的案例到商品部XXX处,同时商品部会选择前一天上交的成功案例挑选一个最成功的上传至云办,同时奖励该销售员工5元现金,各门店下载并在交接班会组织大家学习,成功案例的查询方法:零售中心------零售业务数据------零售明细查询-----选择查询的日期及门店--------运行--------交易流水明细-----选择一个最优秀的案例记录单据号及销售明细填在成功案例分享表中上交),样表已传共享,商品部每天下午对前天门店上报的市调
第一章商品部工作内容 第一节商品部职能 商品部担负公司各家电商场与超市(以下简称门店)的采购商品、确定商品结构、毛利结构及仓储、配送等职能。通过争取最优惠的交易条件,选择最佳采购渠道,建立起满足顾客需要的最佳商品结构;不断取得供应厂商的促销支持,追求最合理的商品毛利空间和最大化的经营业绩;最大限度地降低仓储及配送成本,努力争取更多的营业外收入,促进公司营运持续、有序、健康的发展。 售后服务中心的存货及商品也划归商品部管理。 商品部的采购业务简述如下: 1、统筹安排各门店的商品采购,筛选合作的供应商,确定品项、筛选新品、清理滞销品; 2、确定采购渠道,发展直供厂家; 3、与供应商洽谈合同条款,签订合同; 4、制定快讯品项,组织厂商进行促销; 5、获得营业外收入,招募店内、外广告; 6、定期市调,合理调整商品结构、价格、渠道,努力提升业绩、提高毛利; 7、进行大宗商品、新品、快讯商品、季节性商品的下单、催货,满足营业需要; 8、参与门店盘点,控制订货批量,建立合理库存; 9、协助财务部查清账务差异,确认供应商付款; 10、定期与门店沟通,培训门店员工的商品知识并协助门店处理客诉; 11、规范采购资料录入,进行统一归口管理,建立完善的档案资料。 第二节商品部管理要求 一、降低成本、增加盈利 1、降低进货价格,提高毛利率; 2、提高商品周转率,降低库存; 3、缩短商品的采购、配送环节,提高效率; 4、研究供货政策,向供应商要求相应折扣。 二、维护门店形象 1、保证采购商品的价格低廉以维护门店的平价形象; 2、保证采购商品的质量以维护门店的质量可靠形象; 3、保证采购商品的丰富且不断货以维护门店货品充足的形象; 4、帮助门店科学合理地陈列、展示商品。 三、与供应商成为战略伙伴
商品部职责及流程管理 一、商品部职责 1、负责公司商品、道具、工具等物品的采购、接收、标价、入库、出库等管理工作; 2、负责店面调拨、退换货处理的管理工作; 3、规定、控制各店的报货时间,严格审核各店报货单,做到合理补充货品;负责各店货款申请,及时报总经理审批,并跟踪完成付款; 4、保证货品运输途中的安全、负责货到及时上柜,及时协调向上游索要发票; 5、针对季节转换,敦促卖场折扣、价格调整、清货、调拨等工作,降低整体存货,优化库存商品资金使用,提高效益; 6、负责顾客临时订单,保证准确、及时到货工作; 7、及时处理旧金、旧货的返厂工作;减少在库时间; 8、负责各门店进出货品的核对工作以及非正常销售(礼品、赠品、失货等)处理控制工作; 9、及时关注竞争品牌的货品变动情况,做出快速反应,及时传递信息,配合店面有效提高货品市场竞争力; 10、与上游工厂及相关对口单位建立有效沟通渠道,完善货品结构; 11、了解消费趋势,及时做好市场调查工作,提供适合各门店需要的适销对路的商品,做好进、销、存数据分析,随时为公司提供决策所需的数据; 12、结合财务定期盘点门店库存,保证门店货品做到帐实相符,商品无损坏。 13、及时制定公司滞销商品的处理方案,保证库存商品的完好和品质,降低滞销商品造成的损失; 14、指导门店库存资金的使用比例,提高资金的使用效率。 二、岗位职责 (一)商品部经理工作职责 1、制定和完善内部的工作流程(进货、盘货、出货),使工作流程实现逐步规范化、制度化,确保货品在流通过程中的绝对安全; 2、加强与兄弟部门的协作配合关系,减少部门之间因工作协作带来的效率降低; 3、逐步实现库存的合理化(建立在正确的、全面的、合理的货品分析之上),优化货品结构,建构合理的库存; 4、扭转观念,树立服务意识,最大限度的为兄弟部门提供优良合理服务; 5、明确货品部工作人员的工作分工和责任;内部的工作分工(进货、盘货、打标签、出货);对外的工作分工(对各个店面的衔接,做到专人对口) 6、对外的工作分工(对各个上游渠道商厂家的衔接,做到专人对口) 7、建立商品部进货、请款台账,加强对进货、请款的管理; 8、建立供货单位的相关信息资料,为多样化进货渠道提供信息支持; 9、督促商品部工作人员完成公司安排的各项工作; 10、接待供货单位到总部送货或出差人员,并洽谈相关业务; 11、积极主动完成领导交办的其他工作事项。 (二)采购部员工工作职责
1 技术优势 全基因组测序(Whole Genome Sequencing,WGS)是利用高通量测序平台对人类不同个体或群体进行全基因组测序,并在个体或群体水平上进行生物信息分析。可全面挖掘DNA 水平的遗传变异,为筛选疾病的致病及易感基因,研究发病及遗传机制提供重要信息。 全基因组测序 平台优势 HiSeq X 测序平台 读长:PE150 通量:1.8T/run 测序周期:3 天 专为人全基因组测序准备、测序周期短、通量高
生物信息分析 技术路线 技术参数 样品要求 样本类型:DNA 样品 样本总量:≥1.0 μg DNA (提取自新鲜及冻存样本) ≥1.5 μg DNA (提取自FFPE 样本)样品浓度:≥ 20 ng/μl 测序平台及策略HiSeq X PE150 测序深度 肿瘤:癌组织(50X),癌旁组织/血液样本(30X)遗传病:30~50 X 项目周期37天
3 案例解析 该研究选取3个家系中6个患者和1个正常个体,首先使用基因芯片寻找纯合突变位点,然后对其中无亲缘关系的2例患者采用全基因组测序研究,在2例患者非编码区域均发现相同的变异,10号染色体PTF1A 末端发生一个点突变(chr10:23508437 A>G),且变异在患病人群和细胞试验中均得到了验证。研究解释了生长发育启动子隐性变异是罕见孟德尔遗传病的常见致病原因,同时说明许多疾病的致病突变也可能位于非编码区。 图1 检出的变异信息 智力障碍是影响新生儿心智发育的一类疾病。这项研究选取50个经过基因芯片和全外显子测序未确诊致病因子的trio 家系,全基因组测序检出84个de novo SNVs 和8个de novo CNVs,及一些结构变异(如VPS13B、STAG1、IQSEC2-TENM3),检出率为42%。揭示编码区的de novo SNVs 和de novo CNVs 是导致智力障碍的主要因素,全基因组测序可以作为可靠的遗传性检测应用工具。 案例一 单基因病研究——全基因组测序鉴定PTF1A末端增强子常染色体隐性突变导致胰腺 发育不全[1] 案例二 复杂疾病研究——全基因组测序解析智力障碍的主要致病因素[2] 图2 PTF1A 的家系图谱
商品部工作流程与管理 规定 集团标准化工作小组 #Q8QGGQT-GX8G08Q8-GNQGJ8-MHHGN#
商品部工作流程与管理制度一、经销商 1:总则: 为做好公司产品宣传、推广、销售以及公司品牌形象宣传,提高销售业绩,制定本制度。所有商品部成员均应以本制度为依据开展工作。商品部经理对所属商品部成员进行考核和管理。 2:商品部工作流程: 1)订货会流程: A:根据前期销售数据、仓库库存状况,同季度货品销售状况,制定订货结构(包括:品类、颜色、配码、数量比例); B:根据总部下达的任务,客户同季度的销售情况做好预期任务分期; C:根据各区域销售情况,总部的订货政策制定相应的经销商期货政策; D:政策交由副总经理审核; E:给经销商下达订货任务; F:订货会现场选货、订货、输单、与客户核对订单,无误签字确认,收取订金; G:总部评审后删除款告知客户,要求补货; H:总部下达合同后做订货评审; I:按政策未评审到的款式及时跟经销商沟通,更换其他货品; J:安排上货 2)客户回款发货流程:
A:客房补单; B:排单员查货并报给客户总金额; C:客户打款; D:排单员见款后安排发货; 3)客房回访流程: A:排单员按照客户销售业绩自行设计和计划个人月、周和每天的客户电访计划; B:排单员在每周五的部门例会上向商品部经理汇报下周的客户沟通重点计划情况,并接受指导,最终确定下周沟通重点; C:排单员按照客户电访计划对客户进行电访; D:在电访结束后,应将相关信息如实记录; E:及时将电访信息向商品部主管汇报; F:商品主管对排单员的工作予以指导和安排; G:每周六排单员及商品主管向商品部经理汇报一周的电访情况及未(难)解决的问题,经理组织大家一起讨论,最后由经理给出相应的解决方案; 4)仓库入库流程: A:在货运站到货后,由仓库根据到货单核对到货数量,确认无误后交由仓库主管进行复查并签具单据; B:统计在系统中导出入库单,入库单交由仓管; C:仓管安排入库人员先进行库位整理,整理时按出库整理要求进行整理,然后在进行入库; D:入库时,根据系统建议和库位实际情况进行入库;
商品部工作流程与 管理制度
商品部工作流程与管理制度 一、经销商 1:总则: 为做好公司产品宣传、推广、销售以及公司品牌形象宣传,提高销售业绩,制定本制度。所有商品部成员均应以本制度为依据开展工作。商品部经理对所属商品部成员进行考核和管理。 2:商品部工作流程: 1)订货会流程: A:根据前期销售数据、仓库库存状况,同季度货品销售状况,制定订货结构(包括:品类、颜色、配码、数量比例); B:根据总部下达的任务,客户同季度的销售情况做好预期任务分期; C:根据各区域销售情况,总部的订货政策制定相应的经销商期货政策; D:政策交由副总经理审核; E:给经销商下达订货任务; F:订货会现场选货、订货、输单、与客户核对订单,无误签字确认,收取订金; G:总部评审后删除款告知客户,要求补货; H:总部下达合同后做订货评审; I:按政策未评审到的款式及时跟经销商沟通,更换其它货品; J:安排上货 2)客户回款发货流程:
A:客房补单; B:排单员查货并报给客户总金额; C:客户打款; D:排单员见款后安排发货; 3)客房回访流程: A:排单员按照客户销售业绩自行设计和计划个人月、周和每天的客户电访计划; B:排单员在每周五的部门例会上向商品部经理汇报下周的客户沟通重点计划情况,并接受指导,最终确定下周沟通重点; C:排单员按照客户电访计划对客户进行电访; D:在电访结束后,应将相关信息如实记录; E:及时将电访信息向商品部主管汇报; F:商品主管对排单员的工作予以指导和安排; G:每周六排单员及商品主管向商品部经理汇报一周的电访情况及未(难)解决的问题,经理组织大家一起讨论,最后由经理给出相应的解决方案; 4)仓库入库流程: A:在货运站到货后,由仓库根据到货单核对到货数量,确认无误后交由仓库主管进行复查并签具单据; B:统计在系统中导出入库单,入库单交由仓管; C:仓管安排入库人员先进行库位整理,整理时按出库整理要求进行整理,然后在进行入库; D:入库时,根据系统建议和库位实际情况进行入库;
服装商品部工作计划 篇一:服装行业商品部主管工作职责和工作流程 商品部主管工作职责和工作流程一、职责1、协助店长进行部门销售计划、毛利计划的编制并努力达成目标2、负责区域店铺销售费用的计划编制并努力达成目标3、负责销售、毛利、损耗、库存、促销计划执行、商品陈列率及订退货等管理4、维持商品整齐生动的陈列保持商品结构配置合理以实现最佳销售效果5、与店长及总部各部门协调沟通协助全店管理 6 、协助营运经理进行紧急事件的处理。二、对内对外工作关系协调1、对内协调A 接受营运经理的领导B与门店各部门协调工作保持部门间沟通渠道顺畅C督导部属维持工作标准遵守工作纪律完成工作任务。2、对外协调A与采购部协调新品引进、提高业绩的设想等事宜B 与配货中心协调订、退、到货等事宜C、供应商协调供货、现场促销等事宜三、每月工作重点●当月工作目标检讨●拟订下月工作计划●业绩毛利追踪检讨●商品结构分析●盘点检讨●损耗追踪检讨●月报提交●教育训练四、每周工作重点●业绩追踪●订单审核●报表阅读●陈列调整计划●滞销、清仓商品处理●破损商品处理●商品品质检查●促销计划执行情况追踪●缺货检讨●商品损耗审核●顾客
退货情况了解●市调执行两周一次●退货情况追踪五、每日工作重点●业绩追踪●报表阅读●订单审核●顾客服务●巡视卖场货架————整齐、清洁、饱满促销区、————整齐、清洁、饱满促销商品 ————不缺货、陈列位置明显通道————通畅、通视、无杂物堆放破损商品存放区————整齐有序、当日处理仓库区————整理有序、清洁商品品质————符合标准营业设备————运行正常营业用具————定位整齐放置人员管理————不闲置充分利用 篇二:服装公司商品部工作手册 广州市阿衣迪优服饰有限公司 REDU服饰有限公司 商品部工作手册 审核:审批:编号:编制日期: 适用范围:广州市阿衣迪优服饰有限公司商品部员工。编制目的:规范公司数据化管理流程。 知道是没有力量的,相信并做到才有力量! 1 / 29 目录 第一章商品部工作简介 (3) 第二章商品部工作操作流程细
三代基因组测序技术原理简介 【写在前面的话】:首先,这一篇博文中的内容并非原创,而是对多篇文献中内容的直接摘录,有些图片和资料还来自身边的同事(在此深表谢意!),再夹杂自己的零星想法,写在这里分享与大家,同时也是为了方便自己日后若有需要能够方便获得,文章比较长。 摘要:从1977年第一代DNA测序技术(Sanger法)1,发展至今三十多年时间,测序技术已取得了相当大的发展,从第一代到第三代乃至第四代,测序读长从长到短,再从短到长。虽然就当前形势看来第二代短读长测序技术在全球测序市场上仍然占有着绝对的优势位置,但第三和第四代测序技术也已在这一两年的时间中快速发展着。测序技术的每一次变革,也都对基因组研究,疾病医疗研究,药物研发,育种等领域产生巨大的推动作用。在这里我主要对当前的测序技术以及它们的测序原理做一个简单的小结。 图1: 测序技 术的发 展历程 生命体 遗传信 息的快 速获得 对于生 命科学 的研究 有着十分重要的意义。以上(图1)所描述的是自沃森和克里克在1953年建立DNA双螺旋结构以来,整个测序技术的发展历程。 第一代测序技术 第一代DNA测序技术用的是1975年由桑格(Sanger)和考尔森(Coulson)开创的链终止法或者是1976-1977年由马克西姆(Maxam)和吉尔伯特(Gilbert)发明的化学法(链降解). 并在1977年,桑格测定了第一个基因组序列,是噬菌体X174的,全长5375个碱基1。自此,人类获得了窥探生命遗传差异本质的能力,并以此为开端步入基因组学时代。研究人员在Sanger法的多年实践之中不断对其进行改进。在2001年,完成的首个人类基因组图谱就是以改进了的Sanger法为其测序基础,Sanger法核心原理是:由于ddNTP的2’和3’都不含羟基,其在DNA的合成过程中不能形成磷酸二酯键,因此可以用来中断DNA合成反应,在4个DNA合成反应体系中分别加入一定比例带有放射性同位素标记的ddNTP(分为:ddATP,ddCTP,ddGTP和ddTTP),通过凝胶电泳和放射自显影后可以根据电泳带的位置确定待测分子的DNA序列(图2)。这个网址为sanger测序法制作了一个小短片,形象而生动。
广州市阿衣迪优服饰有限公司REDU服饰有限公司 商品部工作手册 审核: 审批: 编号: 编制日期: 适用范围:广州市阿衣迪优服饰有限公司商品部员工。 编制目的:规范公司数据化管理流程。
目录 第一章商品部工作简介 (3) 第二章商品部工作操作流程细则 (5) 第三章相关工作流程及要求 (22) 第四章代理加盟商发货操作流程 (23) 第五章员工内购流程 (25) 第六章直营店铺盘点操作流程 (26) 第七章商品部岗位职责说明书 (27) 知道是没有力量的,相信并做到才有力量! 2 / 30
第一章商品部工作简介 1、简介:主要负责公司回货、出货、数据分析、库存控制,协助各分区做好销售分析及库存控制的工作。 2、商品部工作职能: 2.1制定公司各季节产品结构需求; 2.2订货会前期基础资料及价格资料的核实; 2.3订货会前各区域销售资料的统计,各区域销售目标的初步拟定。 2.4订货会后订单的统计汇总,货品进仓时间的确认,下生产单到生产部; 2.5货品进仓的跟进、汇报; 2.6客户上货计划的审核,客户分波段出货的跟进; 2.7客户出货进度的跟进,直营店上货情况的跟进; 2.8公司数据资料的收集、汇总、存档; 2.9制订年、季、月度工作计划、销售计划、并监控实施情况 2.10月度、季度、年度销售资料的汇总、汇报; 2.11执行上级交办事项 2.12月底工作总结及下月工作计划 3、部门员工工作要求: 3.1要求有计划性地工作,各项工作要求日清月结,公司相关部门、客户反馈的问题,必须在0.5个工 作日内给予回复,如果不能及时解决的问题,必须及时向上级领导报告,并回复相关部门、客户预计解决日期。 3.2要求工作责任心强,提倡高工作效率和高工作质量; 3.3提升独立处理日常工作的能力,多提对本部门工作有利的意见和建议; 3.4每位员工都要熟悉本部门其他同事的工作内容、掌握本部门每个职位的工作技能,了解本部门其他 同事的工作情况;提倡部门员工之间互相帮助、互相关心。在其他同事工作量大的时候,能主动为同事分担部分工作; 3.5学会与人沟通的技巧,注意与客户沟通的方式方法,处理问题是要考虑到客户的满意度和承受能力; 3.6要求分区管理人员按规定定期对客户进行综合评估,主要内容为;客户对本部门工作支持度、客户 销售情况、客户店铺发展情况、客户回款情况、客户货品销售情况等等; 3.7要求加强本部门之间的信息共享和沟通,及时为相关同事提供有效的信息资源; 3.8要求本部门员工不断提升自身的综合素质,从多方面学习各项工作技能,改进现有工作方法中的不 好之处。
竭诚为您提供优质文档/双击可除 商品部工作计划范文 篇一:商品部年度工作计划 计划部作为承接设计生产及市场销售前后各个环节的 核心部门,其主要功能在予通过严谨的 科学分析和市场调查制订出合理的生产物流计划,并指导市场销售工作。根据计划部目前的 实际情况和工作要求现将计划分析工作职能明细如下: 一、生产计划: a、工作职责 1、依据公司企业高层管理所制订的下年度和下季度的销售指标和市场拓展方向,结合 计划部分析 员所提供的公司上年度和上季度的实际销售情况和对 季末总仓库存的预测量,同时对本 行业和外部环境的发展方向作一预测,在此基础上制订出各个不同季度的产品总体开发计划; 2、依据本年度的市场反馈情况和调查资料给设计部提
供下一年度的款式开发方向。(要 求时间: 春夏季5月15日之前;秋冬季10月15日之前) 3、依据计划部分析员对上季度所销售货品的详细分析 结果,通过对每次参与商务部所 召开的每旬 销售分析会议中的各区域市场的动态状况进行季末汇总,辅之以生产计划员对公司不同 区域市场的一手调查资料,从而制订出各个不同季度的产品生产开发计划(达标要求:①、每 季新品的主款比重要占到新品总款数的30%;②、必须 将每季新品划分为主款(含以低价冲击 市场的畅销款)、尝试款、陪衬款三大块;③、主款数 量以全铺为原则按原定生产计划走;陪 衬款为一次性做货分片区销售,原则上不进行补单;尝试款为首单少量投放重点有代表性片 区试销,视其销售效果而决定是否加单及加单量的大小; ④、陪衬款及尝试款的开发量及首 单规格比要以物流分布计划员的前期总体物流分布计 划为依据标准制订); 4、将经过公司企业高层管理讨论核准后的各个不同季 度的产品详细生产开发计划下达
差异位点分析流程步骤分解 数据准备: mkdir 1.QC cd 1.QC ln -s /root/mdna-data/reseq/1.QC/*.fastq . Ls cd .. mkdir 2.mapping cd 2.mapping ln -s /root/mdna-data/reseq/2.mapping/ref.fasta . 步骤1:参考基因建索引 cd 2.mapping ##bwa建索引: bwa index ref.fasta Expected Result:得到一系列BWA 进行alignment 需要的文件。 ##samtools建索引: samtools faidx ref.fasta Expected Result:生成refgene.fasta.fai。每行都是fasta 文件中每条contig 的record,每条record 由contig name, size, location, basesPerLine 和bytesPerLine 组成。 ##生成字典: java -jar /root/mdna_software/picard-tools-1.102/CreateSequenceDictionary.jar R=ref.fasta O=ref.dict Expected Result:生成refgene.dict。描述fasta 文件内容,类似SAM header 格式。 步骤2:bwa比对 ##用bwa作比对: nohup bwa aln -e 3 -i 10 -t 1 -R 100 -q 20 ref.fasta ../1.QC/test_trim1.fastq -f 1.sai & nohup bwa aln -e 3 -i 10 -t 1 -R 100 -q 20 ref.fasta ../1.QC/test_trim2.fastq -f 2.sai & nohup bwa aln -e 3 -i 10 -t 1 -R 100 -q 20 ref.fasta ../1.QC/test_trim_unpaired.fastq -f s.sai & jobs
商品部的工作流程 ?一、以商品规划为中心 ? 商品规划贯穿于企业运作的各个环节,源头的设计到终端的销售都需要商品规划来将其有机串联并贯通。 商品规划在企业的供应系统方面主要是做好以下几点: 1、完善上市节奏、货品结构和颜色结构,避免结构性错误。 企业最怕的不是个别商品生产不合理,而是出现整个批次的货品缺失,或者整个类别的货品缺失,或者整个颜色不成系统,这种结构性错误往往导致灾难性后果。 整批货品的缺失主要发生在换季的时候。我们常常会发现秋装和冬装很多,秋冬之交的很少;或者冬装和春装很多,冬春之交的很少。店铺 里货品要么已过季,要么季节没来,就是没有应季商品,店主的心和店铺一样空荡荡的。这就是上市节奏不合理。 如何才能节奏合理?要先设计节奏,后设计款式。开始设计时,计划部门协助设计部门按月划分时段,为每个月都规划一盘货,解决断层问题。 看起来很简单,但你真的这样做了吗?也许没有做,也许没做全,也许后来打乱了,也许做太细而相互干扰了,都是不好的。 每季度整盘货品的款量规划是开发计划中很重要的一环,这要以店铺面积以及店铺销售能力为基础,首先要根据店铺档案及季度预计开店规划来核算各种面积店铺数量占总店铺数量,并按照占比数最大的店铺面积和货品上市节奏来规划季度货品开发款量,其次要根据各店铺实际销售货品的大类结构比例来具体细化到每个货品大类每个上市波段的款量。 货品结构中一类货品的缺失主要发生在裤装和配件上。由于裤子款式相近,很容易被看成雷同款而被拿下,配件由于历史原因也不被重视,有些品牌甚至没有配件。殊不知,裤子和配件是利润最高的,最没季节性的。 因此在分好批次后,要为各批次完善货品结构,尤其要注意裤子和配件,裤子的重点是牛仔裤,配件的重点是包和鞋。 颜色第一、款式第二、面料第三。服装是“远观色,近看花”,品牌的个性首先是在颜色上体现出来,她当然也更为重要;其次各品牌每季的款式越来越多,为保证清晰的店铺形象,大家都是先按色系陈列再做微调。 综上所述,我们不仅要在每个款的颜色上下功夫,更要保证颜色的系统性,陈列的系统性。在设计时,首先设计颜色系统,然后设计款式细节,最后考虑面料的丰富性。 2、以适度饥饿为原则,编制弹性预算,分批生产。 生产计划是根据系统店铺预估销售来指定,既然是预估的,那么,生产计划是做不准的,计划水平的高低其实是纠错能力的高低。 提高纠错能力首先要调整好心态,不要怕缺货。经验表明,如果怕缺货,想到“万一不够怎么办?”,就会为“万一”做足“一万”。如果做多了,厂里可不会自己吃掉,你就哭吧。反之如果你想,如果做少了,后面可以加量或加新款来补救,前期适度饥饿没关系。这种“适度饥饿”的心理暗示会极大地改变计划模式,计划未定,已成功了一半。