多元线性回归分析报告
- 格式:doc
- 大小:164.15 KB
- 文档页数:14

实验报告实验题目:多重共线性的研究指导老师:学生一:学生二:实验时间:2011 年10 月多重线性回归分析及其实验报告实验目的:为了更好地了解财政收入构成,需要定量地分析影响财政收入的因素模型设定及其估计:经分析,影响财政收入的主要因素,农业增加值X1,工业增加值X2,建筑业增加值X3,总人口X4,受灾面积X5.为此设定了如下形式的计量经济模型:丫= 1 + 2 X1+ 3 X2+ 4 X3+ 5 X4+ 6 X5+U0其中,丫为财政收入(元),X1农业增加值(元),X2为工业增加值(元),X3为建筑业增加值(元),X4为总人口(万人),X5为受灾面积(千公顷)为估计模型参数,收集佃78~2007年财政收入及其影响因素数据,如图:1978~2007年财政收入及其影响因素数据年份财政收入CS/亿元农业增加值NZ/亿元工业增加值GZ/亿元建筑业增加值JZZ/亿元总人口TPOP万人受火面积SZM千公顷1978 1132.3 1027.5 1607 138.2 96259 50790 1979 1146.6 1270.2 1769.7 143.8 97542 39370 1980 1159.9 1371.4 1996.5 195.5 98705 44526 1981 1175.8 1559.5 2048.5 207.1 100072 39790 1982 1212.3 1777.4 2162.3 220.7 101654 33130 1983 1367 1978.5 2375.8 270.6 103008 34710 1984 1642.5 2316.1 2789 316.7 104357 31890 1985 2004.6 2564.3 3448.5 417.9 105851 44365 1986 2122 2788.7 3987.5 525.7 107507 47170 1987 2199.4 3233 4565.9 665.8 109300 42090 1988 2357.6 3865.4 5062 810 111026 50870 1989 2664.5 5062 8087.3 794 112704 46991 1990 2937.4 5342.3 10284.5 859.4 114333 384741991 3149.48 5866.8 14188 1015.1 115823 55472 1992 3483.48 6963.6 19480.5 1415 117171 513331993 4348.95 9572.7 19480.4 2266.5 118517 48829 1994 5218.1 12315.7 24950.7 2964.7 119850 55043 1995 6242.2 14015.8 29447.6 3728.8 121121 45821 1996 7407.99 14441.8 32921.4 4387.4 122389 46898 1997 8615.14 14917.6 34018.4 4985.8 123626 53429 1998 9875.95 14944.5 40036 5172.1 124761 59145 1999 11444.08 15871.8 43580.6 5522.3 125786 499812000 13395.23 16537 47431.6 5913.7 126743 54688 2001 16386.04 17381.8 54945.5 6465.5 127627 52215 2002 18903.64 21412.7 65210 7490.8 128453 47119 2003 21715.25 22420 76912.6 8694.3 129227 54506 2004 26396.47 21224 87632.4 8967.8 129988 37106 2005 31649.29 22420 89834.5 10133.8 130756 388182006 38760.2 24040.9 91310.9 11851.1 131448 41091 2007 51321.45 28095 107367.2 14014.1 132129 48992利用Eviews软件,生成Y、X1、X2、X3、X4、X5等数据,采用这些数据进行OLS回归,结果如下Depe ndent Variable: YMethod: Least SquaresDate: 10/24/11 Time: 22:49Sample: 1978 2007In cluded observati ons: 30Variable Coefficie nt Std. Error t-Statistic Prob.C -6734.394 11259.37 -0.598115 0.5554X1 -1.678611 0.328371 -5.111937 0.0000X2 0.071078 0.081171 0.875666 0.3899X3 5.699199 0.745591 7.643870 0.0000X4 0.101481 0.114244 0.888277 0.3832X5 -0.010922 0.057578 -0.189691 0.8511 R-squared 0.983660 Mean depe ndent var 10047.83Adjusted R-squared 0.980255 S.D. dependent var 12585.61S.E. of regressi on 1768.473 Akaike info criteri on 17.97048Sum squared resid 75059958 Schwarz criteri on 18.25072Log likelihood -263.5572 F-statistic 288.9512Durb in -Watson stat 0.898668 Prob(F-statistic) 0.000000由此可见,该模型R2 =0.983660, R2=0.980255可决系数很高,F检验值为288.9512,明显显著。

第1篇一、实验目的本次实验旨在通过多元线性回归模型,分析多个自变量与因变量之间的关系,掌握多元线性回归模型的基本原理、建模方法、参数估计以及模型检验等技能,提高运用计量经济学方法解决实际问题的能力。
二、实验背景随着经济的发展和社会的进步,影响一个变量的因素越来越多。
在经济学、管理学等领域,多元线性回归模型被广泛应用于分析多个变量之间的关系。
本实验以某地区居民消费支出为例,探讨影响居民消费支出的因素。
三、实验数据本实验数据来源于某地区统计局,包括以下变量:1. 消费支出(Y):表示居民年消费支出,单位为元;2. 家庭收入(X1):表示居民家庭年收入,单位为元;3. 房产价值(X2):表示居民家庭房产价值,单位为万元;4. 教育水平(X3):表示居民受教育程度,分为小学、初中、高中、大专及以上四个等级;5. 通货膨胀率(X4):表示居民消费价格指数,单位为百分比。
四、实验步骤1. 数据预处理:对数据进行清洗、缺失值处理和异常值处理,确保数据质量。
2. 模型设定:根据理论知识和实际情况,建立多元线性回归模型:Y = β0 + β1X1 + β2X2 + β3X3 + β4X4 + ε其中,Y为因变量,X1、X2、X3、X4为自变量,β0为截距项,β1、β2、β3、β4为回归系数,ε为误差项。
3. 模型估计:利用统计软件(如SPSS、R等)对模型进行参数估计,得到回归系数的估计值。
4. 模型检验:对估计得到的模型进行检验,包括以下内容:(1)拟合优度检验:通过计算R²、F统计量等指标,判断模型的整体拟合效果;(2)t检验:对回归系数进行显著性检验,判断各变量对因变量的影响是否显著;(3)方差膨胀因子(VIF)检验:检验模型是否存在多重共线性问题。
5. 结果分析:根据模型检验结果,分析各变量对因变量的影响程度和显著性,得出结论。
五、实验结果与分析1. 拟合优度检验:根据计算结果,R²为0.812,F统计量为30.456,P值为0.000,说明模型整体拟合效果较好。
多元线性回归模型一、实验目的通过上机实验,使学生能够使用Eviews 软件估计可化为线性回归模型的非线性模型,并对线性回归模型的参数线性约束条件进行检验。
二、实验内容(一)根据中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L进行回归分析。
(二)掌握可化为线性多元非线性回归模型的估计和多元线性回归模型的线性约束条件的检验方法(三)根据实验结果判断中国该年制造业总体的规模报酬状态如何?三、实验步骤(一)收集数据下表列示出来中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y,资产合计K及职工人数L。
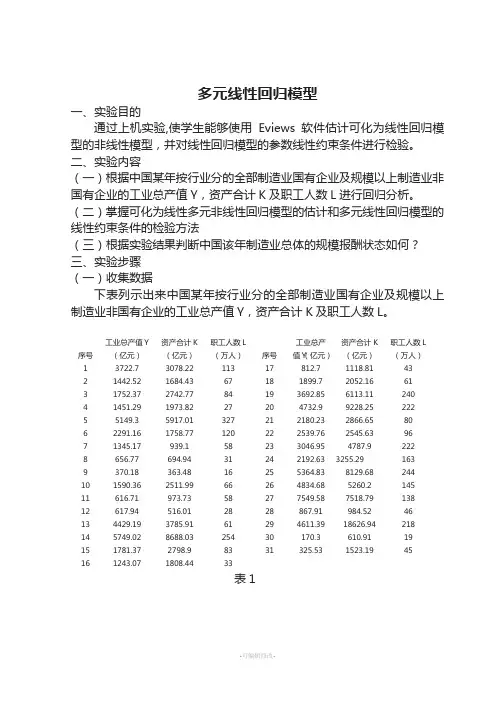
序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)序号工业总产值Y(亿元)资产合计K(亿元)职工人数L(万人)1 3722.7 3078.22 113 17 812.7 1118.81 432 1442.52 1684.43 67 18 1899.7 2052.16 613 1752.37 2742.77 84 19 3692.85 6113.11 2404 1451.29 1973.82 27 20 4732.9 9228.25 2225 5149.3 5917.01 327 21 2180.23 2866.65 806 2291.16 1758.77 120 22 2539.76 2545.63 967 1345.17 939.1 58 23 3046.95 4787.9 2228 656.77 694.94 31 24 2192.63 3255.29 1639 370.18 363.48 16 25 5364.83 8129.68 24410 1590.36 2511.99 66 26 4834.68 5260.2 14511 616.71 973.73 58 27 7549.58 7518.79 13812 617.94 516.01 28 28 867.91 984.52 4613 4429.19 3785.91 61 29 4611.39 18626.94 21814 5749.02 8688.03 254 30 170.3 610.91 1915 1781.37 2798.9 83 31 325.53 1523.19 4516 1243.07 1808.44 33表1(二)创建工作文件(Workfile)。

多元线性回归模型案例分析——中国人口自然增长分析一·研究目的要求中国从1971年开始全面开展了计划生育,使中国总和生育率很快从1970年的5.8降到1980年2.24,接近世代更替水平。
此后,人口自然增长率(即人口的生育率)很大程度上与经济的发展等各方面的因素相联系,与经济生活息息相关,为了研究此后影响中国人口自然增长的主要原因,分析全国人口增长规律,与猜测中国未来的增长趋势,需要建立计量经济学模型。
影响中国人口自然增长率的因素有很多,但据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。
(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
二·模型设定为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):表1 中国人口增长率及相关数据设定的线性回归模型为:1222334t t t t t Y X X X u ββββ=++++三、估计参数 利用EViews 估计模型的参数,方法是:1、建立工作文件:启动EViews ,点击File\New\Workfile ,在对话框“Workfile Range ”。
在“Workfile frequency ”中选择“Annual ” (年度),并在“Start date ”中输入开始时间“1988”,在“end date ”中输入最后时间“2005”,点击“ok ”,出现“Workfile UNTITLED ”工作框。
其中已有变量:“c ”—截距项 “resid ”—剩余项。
实验题目:多元线性回归、异方差、多重共线性实验目的:掌握多元线性回归的最小二乘法,熟练运用Eviews软件的多元线性回归、异方差、多重共线性的操作,并能够对结果进行相应的分析。
实验内容:习题3.2,分析1994-2011年中国的出口货物总额(Y)、工业增加值(X2)、人民币汇率(X3),之间的相关性和差异性,并修正。
实验步骤:1.建立出口货物总额计量经济模型:错误!未找到引用源。
(3.1)1.1建立工作文件并录入数据,得到图1图1在“workfile"中按住”ctrl"键,点击“Y、X2、X3”,在双击菜单中点“open group”,出现数据表。
点”view/graph/line/ok”,形成线性图2。
图21.2对(3.1)采用OLS估计参数在主界面命令框栏中输入ls y c x2 x3,然后回车,即可得到参数的估计结果,如图3所示。
图 3根据图3中的数据,得到模型(3.1)的估计结果为(8638.216)(0.012799)(9.776181)t=(-2.110573) (10.58454) (1.928512)错误!未找到引用源。
错误!未找到引用源。
F=522.0976从上回归结果可以看出,拟合优度很高,整体效果的F检验通过。
但当错误!未找到引用源。
=0.05时,错误!未找到引用源。
=错误!未找到引用源。
2.131.有重要变量X3的t检验不显著,可能存在严重的多重共线性。
2.多重共线性模型的识别2.1计算解释变量x2、x3的简单相关系数矩阵。
点击Eviews主画面的顶部的Quick/Group Statistics/Correlatios弹出对话框在对话框中输入解释变量x2、x3,点击OK,即可得出相关系数矩阵(同图4)。
相关系数矩阵图4由图4相关系数矩阵可以看出,各解释变量相互之间的相关系数较高,证实解释变量之间存在多重共线性。
2.2多重共线性模型的修正将各变量进行对数变换,在对以下模型进行估计。

⑩陕&科技丈嗲实验报告成绩一、实验预习:1.多元回归模型。
2.多元回归模型参数的检验。
3.多元回归模型整体的检验。
二、实验的目的和要求:通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。
三、实验过程:(实验步骤、原理和实验数据记录等)软件:Eviews3.1数据:给定美国机动车汽油消费量研究数据。
1.实验步骤1)在Eviews7.0中,新建文件,并将给定的数据输入新建的文件中;2)分析变量间的相关关系;3)进行时间序列的平稳性检验,根据序列趋势图,对原序列进行ADF平稳性检验,再对时间序列数据的一阶差分进行ADF检验,并对结果进行分析讨论。
2.实验原理对于只有一个解释变量的模型,其参数估计方法是最简单的,一般形式如下:y t= A)+ +其中&称为被解释变量,人称为解释变量,%称为随机误差项。
模型可分为两部分:1)回归方程部分,2)随机误差部分,义㈣归分析就是根据样本观察值寻求从和成的估计值。
图一0 Series: S Torkfile: ADF::Adf\| VeA- J Proc: Object Properties ^nnt Name {Freeze J Default-n x| Options | Sample [Gerr j图二2)建立回归模型如卜:四、实验总结:(实验数据处理和实验结果讨论等)1.实验数据处理1)数据的预处理:通过绘制动态曲线、绘制散点图、计算变量之间的相关 关系为正式建模做准备。
可以画出美国汽车各项研究数据的趋势图如下:QMG = c(l) + c(2) * MOB + c(3) * PMG + c(4) * POP + c(5) * GNP 回归结果如下:Dependent Variable: QMG Method: LeastSquares Date: 06/10/14 Time: 16:19 Sample:1950 1987 Included observations: 38QMG=C(1)+C(2)*MOB+C(3)*PMG+C(4)*POP+C(5)*GNP由表中数据带入公式可写出线性回归表达式为:QMG = 24553723 + 1.418520 * MOB- 27995762 * PMG- 59.8748 * POP- 30540.88 * GNP3)进行模型检验从表Prob列的数据中发现c(0)与c(4)的值T检验未通过,可以考虑删除相应的自变量。

多元线性回归模型案例分析报告多元线性回归模型是一种用于预测和建立因变量和多个自变量之间关系的统计方法。
它通过拟合一个线性方程,找到使得回归方程和实际观测值之间误差最小的系数。
本报告将以一个实际案例为例,对多元线性回归模型进行案例分析。
案例背景:公司是一家在线教育平台,希望通过多元线性回归模型来预测学生的学习时长,并找出对学习时长影响最大的因素。
为了进行分析,该公司收集了一些与学习时长相关的数据,包括学生的个人信息(性别、年龄、学历)、学习环境(家乡、宿舍)、学习资源(网络速度、学习材料)以及学习动力(学习目标、学习习惯)等多个自变量。
数据分析方法:通过建立多元线性回归模型,我们可以找到与学习时长最相关的因素,并预测学生的学习时长。
首先,我们将根据实际情况对数据进行预处理,包括数据清洗、过滤异常值等。
然后,我们使用逐步回归方法,通过逐步添加和删除自变量来筛选最佳模型。
最后,我们使用已选定的自变量建立多元线性回归模型,并进行系数估计和显著性检验。
案例分析结果:经过数据分析和模型建立,我们得到了如下的多元线性回归模型:学习时长=0.5*年龄+0.2*学历+0.3*学习资源+0.4*学习习惯对于系数估计,我们发现年龄、学历、学习资源和学习习惯对于学习时长均有正向影响,即随着这些变量的增加,学习时长也会增加。
其中,年龄和学习资源的影响较大,学历和学习习惯的影响较小。
在显著性检验中,我们发现该模型的拟合度较好,因为相关自变量的p值均小于0.05,表明它们对学习时长的影响具有统计学意义。
案例启示:本案例的分析结果为在线教育平台提供了重要的参考。
公司可以针对年龄较大、学历高、学习资源丰富和有良好学习习惯的学生,提供个性化的学习服务和辅导。
同时,公司也可以通过提供更好的学习资源和培养良好的学习习惯,来提升学生的学习时长和学习效果。
总结:多元线性回归模型在实际应用中具有广泛的应用价值。
通过对因变量和多个自变量之间的关系进行建模和分析,我们可以找到相关影响因素,并预测因变量的取值。

多元回归分析实验报告心得引言回归分析是一种常用的统计分析方法,能够探究多个自变量与一个因变量之间的数学关系。
在本次实验中,我们使用了多元回归分析方法来研究多个自变量对一个因变量的影响。
通过本次实验,我对多元回归分析有了更深入的理解,并学到了一些关键的技巧和注意事项。
实验设计本次实验的目的是研究某城市的房屋价格如何受到位置、房龄和房屋面积等多个因素的影响。
我们收集了一定数量的样本数据,其中自变量包括房屋的地理位置、房龄和面积,因变量为房屋的价格。
我们首先进行了数据预处理,包括数据清洗、缺失值处理和变量转换,然后使用多元回归分析方法建立了一个回归模型。
多元回归模型多元回归模型是用来建立多个自变量与一个因变量之间的数学关系的模型。
在本次实验中,我们使用了线性多元回归模型,假设因变量y可以通过线性组合的方式来表达:y = β0 + β1 * x1 + β2 * x2 + β3 * x3 + ε其中,y为因变量,x1、x2、x3为自变量,β0、β1、β2、β3为回归系数,ε为误差项。
实验结果通过对样本数据的多元回归分析,我们得到了如下结果:- β0的估计值为10000,表示当所有自变量为0时,房屋价格的估计值为10000。
- β1的估计值为2000,表示当自变量x1的值增加1单位时,房屋价格的估计值会增加2000。
- β2的估计值为-3000,表示当自变量x2的值增加1单位时,房屋价格的估计值会减少3000。
- β3的估计值为5000,表示当自变量x3的值增加1单位时,房屋价格的估计值会增加5000。
根据模型的拟合效果,我们得到了一个R-squared值为0.8,说明我们的模型可以解释80%的因变量变异。
结论与讨论通过本次实验,我深刻理解了多元回归分析的过程和意义。
多元回归模型可以用于预测或解释因变量与多个自变量之间的关系。
不仅如此,我还学到了一些关键的技巧和注意事项,包括选择自变量、处理缺失值和变量转换等。

多元线性回归模型实验报告实验报告:多元线性回归模型1.实验目的多元线性回归模型是统计学中一种常用的分析方法,通过建立多个自变量和一个因变量之间的模型,来预测和解释因变量的变化。
本实验的目的是利用多元线性回归模型,分析多个自变量对于因变量的影响,并评估模型的准确性和可靠性。
2.实验原理多元线性回归模型的基本假设是自变量与因变量之间存在线性关系,误差项为服从正态分布的随机变量。
多元线性回归模型的表达形式为:Y=b0+b1X1+b2X2+...+bnXn+ε,其中Y表示因变量,X1、X2、..、Xn表示自变量,b0、b1、b2、..、bn表示回归系数,ε表示误差项。
3.实验步骤(1)数据收集:选择一组与研究对象相关的自变量和一个因变量,并收集相应的数据。
(2)数据预处理:对数据进行清洗和转换,排除异常值、缺失值和重复值等。
(3)模型建立:根据收集到的数据,建立多元线性回归模型,选择适当的自变量和回归系数。
(4)模型评估:通过计算回归方程的拟合优度、残差分析和回归系数的显著性等指标,评估模型的准确性和可靠性。
4.实验结果通过实验,我们建立了一个包含多个自变量的多元线性回归模型,并对该模型进行了评估。
通过计算回归方程的拟合优度,我们得到了一个较高的R方值,说明模型能够很好地拟合观测数据。
同时,通过残差分析,我们检查了模型的合理性,验证了模型中误差项的正态分布假设。
此外,我们还对回归系数进行了显著性检验,确保它们是对因变量有显著影响的。
5.实验结论多元线性回归模型可以通过引入多个自变量,来更全面地解释因变量的变化。
在实验中,我们建立了一个多元线性回归模型,并评估了模型的准确性和可靠性。
通过实验结果,我们得出结论:多元线性回归模型能够很好地解释因变量的变化,并且模型的拟合优度较高,可以用于预测和解释因变量的变异情况。
同时,我们还需注意到,多元线性回归模型的准确性和可靠性受到多个因素的影响,如样本大小、自变量的选择等,需要在实际应用中进行进一步的验证和调整。

中国税收增长的分析一、研究的目的要求改革开放以来,随着经济体制的改革深化和经济的快速增长,中国的财政收支状况发生了很大的变化,中央和地方的税收收入1978年为519.28亿元到2002年已增长到17636.45亿元25年间增长了33倍。
为了研究中国税收收入增长的主要原因,分析中央和地方税收收入的增长规律,预测中国税收未来的增长趋势,需要建立计量经济学模型。
影响中国税收收入增长的因素很多,但据分析主要的因素可能有:〔1〕从宏观经济看,经济整体增长是税收增长的基根源泉。
〔2〕公共财政的需求,税收收入是财政的主体,社会经济的开展和社会保障的完善等都对公共财政提出要求,因此对预算指出所表现的公共财政的需求对当年的税收收入可能有一定的影响。
〔3〕物价水平。
我国的税制结构以流转税为主,以现行价格计算的DGP等指标和和经营者收入水平都与物价水平有关。
〔4〕税收政策因素。
我国自1978年以来经历了两次大的税制改革,一次是1984—%。
但是第二次税制改革对税收的增长速度的影响不是非常大。
因此可以从以上几个方面,分析各种因素对中国税收增长的具体影响。
二、模型设定为了反映中国税收增长的全貌,选择包括中央和地方税收的‘国家财政收入’中的“各项税收〞〔简称“税收收入〞〕作为被解释变量,以反映国家税收的增长;选择“国内生产总值〔GDP〕〞作为经济整体增长水平的代表;选择中央和地方“财政支出〞作为公共财政需求的代表;选择“商品零售物价指数〞作为物价水平的代表。
由于税制改革难以量化,而且1985年以后财税体制改革对税收增长影响不是很大,可暂不考虑。
所以解释变量设定为可观测“国内生产总值〔GDP〕〞、“财政支出〞、“商品零售物价指数〞从《中国统计年鉴》收集到以下数据年份财政收入〔亿元〕Y国内生产总值(亿元〕X2财政支出〔亿元〕X3商品零售价格指数〔%)X419781979 102 1980 106 1981198219831984 717119851986 106 1987198819891990199119921993199419951996199719981999 97 200020012002设定线性回归模型为:Y i=β0+β2X2+β3X3+β4X4+μ三、参数估计利用eviews软件可以得到Y关于X2的散点图:可以看出Y和X2成线性相关关系Y关于X3的散点图:可以看出Y和X3成线性相关关系Y关于X4的散点图:Dependent Variable: YMethod: Least SquaresDate: 12/01/09 Time: 13:16Sample: 1978 2002Included observations: 25Variable Coefficient Std. Error t-Statistic Prob.CX2X3X4R-squared Mean dependent varAdjusted R-squared S.D. dependent varS.E. of regression Akaike info criterionSum squared resid 1463163. Schwarz criterionLog likelihood F-statisticDurbin-Watson stat Prob(F-statistic)模型估计的结果为:Y i=+0.022067X2+X3+X4(940.6119) (0.0056) (0.0332) (8.7383)t={-2.7458} {3.9567} {21.1247} {2.7449}R2=0.997 R2=0.997 F=2717.254 df=21四、模型检验模型估计结果说明,在假定其他变量不变的情况下,当年GDP每增长1亿元,税收收入就会增长0.02207亿元;在假定其他变量不变的情况下,当年财政支出每增长1亿元,税收收入就会增长0.7021亿元;在假定其他变量不变的情况下,当零售商品物价指数上涨一个百分点,税收收入就会增长23.985亿元。
实验三:多元线性回归实验内容习题一(P64例3.1)(1)打开SPSS软件,输入数据如下(部分):选择“分析”中“回归--线性”,以y为应变量,以x1-x9为自变量,点击“确定”得:所以得回归方程为:y=1.465x1+2.575x2+2.005x3+0.891x5+0.67x6+0.28x7+11.405x8-160.711x9-2721.493从回国方程可以看到,x1-x9对居民的消费支出起正影响,x9对居民的消费性支出起负影响。
(2)F检验。
用SPSS软件计算出的方差分析图如下:从输出结果可知,Sig即显著性P值,由P值为0.000可知,此回归方程高度显著。
t检验。
通过定性分析,先剔除x4,用y与其他8个变量做回归分析,计算结果如下图:剔除x4之后,仍然有不显著的自变量,此时最大的P值为p8=0.827,因此进一步剔除x8,用y与其余6个变量作回归,回归系数表如下图:T检验中,依次剔除P值最大的自变量,直到最后所有的自变量在显著性水平为0.05时都显著。
习题二(P93.例4.3)(1)打开SPSS软件,输入数据如下图:(2)建立y对x的普通最小二乘回归,决定系数R2=0.912,回归标准差为247.62.方差分析表和回归系数输出表如下:(3)在原始数据中增加一列变量RES_1,即残差值,如图:然后以x(居民收入)为x轴,残差值为y轴画散点图:从残差图看出,误差项具有明显的异方差性,误差随着x的增加而呈现出增加的趋势。
(4)计算等级相关系数。
先计算出残差的绝对值,如图:然后选择分析中的“相关--双变量”,选择x和e为变量,在相关系数一栏里选择Spearman 打钩,点击确定即得到等级相关系数,如下图所示:从上图可知,相关系数为0.686,P值=2.055E-5,即残差绝对值e与自变量x显著相关,存在异方差。
(5)用加权最小二乘法来消除异方差。
选择“分析”中“回归--权重估计”,以x为自变量,y为因变量,对x进行加权估计,得:然后画出加权最小二乘残差图,如下:比较前后两幅残差图,可以得出,加权最小二乘估计的效果好于普通最小二乘估计效果。
多元线性回归实例分析报告多元线性回归是一种用于预测目标变量和多个自变量之间关系的统计分析方法。
它可以帮助我们理解多个自变量对目标变量的影响,并通过建立回归模型进行预测。
本文将以一个实例为例,详细介绍多元线性回归的分析步骤和结果。
假设我们研究了一个电子产品公司的销售数据,并想通过多元线性回归来预测销售额。
我们收集了以下数据:目标变量(销售额)和三个自变量(广告费用、产品种类和市场规模)。
首先,我们需要对数据进行探索性分析,了解数据的分布、缺失值等情况。
我们可以使用散点图和相关系数矩阵来查看变量之间的关系。
通过绘制广告费用与销售额的散点图,我们可以观察到一定的正相关关系。
相关系数矩阵可以用来度量变量之间的线性关系的强度和方向。
接下来,我们需要构建多元线性回归模型。
假设目标变量(销售额)与三个自变量(广告费用、产品种类和市场规模)之间存在线性关系,模型可以表示为:销售额=β0+β1*广告费用+β2*产品种类+β3*市场规模+ε其中,β0是截距,β1、β2和β3是回归系数,ε是误差项。
我们可以使用最小二乘法估计回归系数。
最小二乘法可以最小化目标变量的预测值和实际值之间的差异的平方和。
通过计算最小二乘估计得到的回归系数,我们可以建立多元线性回归模型。
在实际应用中,我们通常使用统计软件来进行多元线性回归分析。
通过输入相应的数据和设置模型参数,软件会自动计算回归系数和其他统计指标。
例如,我们可以使用Python的statsmodels库或R语言的lm函数来进行多元线性回归分析。
最后,我们需要评估回归模型的拟合程度和预测能力。
常见的评估指标包括R方值和调整R方值。
R方值可以描述自变量对因变量的解释程度,值越接近1表示拟合程度越好。
调整R方值考虑了模型中自变量的个数,避免了过度拟合的问题。
在我们的实例中,假设我们得到了一个R方值为0.8的多元线性回归模型,说明模型可以解释目标变量80%的方差。
这个模型还可以用来进行销售额的预测。
多元线性回归分析报告1. 研究背景在数据科学和统计学领域,多元线性回归是一种常用的分析方法。
它用于探究多个自变量与一个因变量之间的关系,并且可以用于预测和解释因变量的变化。
本文将通过多元线性回归分析来研究一个特定问题,探讨自变量对因变量的影响程度和统计显著性。
2. 数据收集和准备在进行多元线性回归分析之前,需要收集和准备相关的数据。
数据的收集可以通过实验、调查问卷或者从已有的数据集中获得。
在本次分析中,我们使用了一个包含多个自变量和一个因变量的数据集。
首先,我们导入数据集,并进行数据的初步观察和预处理。
这些预处理步骤包括去除缺失值、处理异常值和标准化等。
经过数据准备之后,我们可以开始进行多元线性回归分析。
3. 回归模型建立在多元线性回归分析中,我们建立一个数学模型来描述自变量和因变量之间的关系。
假设我们有p个自变量和一个因变量,可以使用以下公式表示多元线性回归模型:Y = β0 + β1X1 + β2X2 + … + βpXp + ε其中,Y表示因变量,X1, X2, …, Xp分别表示自变量,β0, β1, β2, …, βp表示模型的系数,ε表示模型的误差项。
4. 模型拟合和参数估计接下来,我们使用最小二乘法来估计模型的参数。
最小二乘法通过最小化观测值与模型预测值之间的差异来确定最佳拟合线。
通过估计模型的系数,我们可以得到每个自变量对因变量的影响程度和显著性。
在进行参数估计之前,我们需要检查模型的假设前提,包括线性关系、多重共线性、正态性和异方差性等。
如果模型的假设不成立,我们需要采取相应的方法进行修正。
5. 模型评估和解释在完成模型的参数估计后,我们需要对模型进行评估和解释。
评估模型的好坏可以使用多个指标,如R方值、调整R方值、F统计量和t统计量等。
这些指标可以帮助我们判断模型的拟合程度和自变量的显著性。
解释模型的结果需要注意解释模型系数的大小、符号和显著性。
系数的大小表示自变量对因变量的影响程度,符号表示影响的方向,显著性表示结果是否具有统计意义。
《应用回归分析》---多元线性回归分析实验报告
二、实验步骤:
1、计算出增广的样本相关矩阵
2、给出回归方程
Y=-65.074+2.689*腰围+(-0.078*体重)3、对所得回归方程做拟合优度检验
4、对回归方程做显著性检验
5、对回归系数做显著性检验
三、实验结果分析:
1、计算出增广的样本相关矩阵相关矩阵
2、给出回归方程
回归方程:Y=-65.074+2.689*腰围+(-0.078*体重)
3、对所得回归方程做拟合优度检验
由表可知x与y的决定性系数为r2=0.800,说明模型的你和效果一般,x与y 线性相关系数为R=0.894,说明x与y有较显著的线性关系,当F=33.931,显著性Sig.p=0.000,说明回归方程显著
4、对回归方程做显著性检验
5、对回归系数做显著性检验
Beta的t检验统计量t=-6.254,对应p的值接近0,说明体重和体内脂肪比重对腰围数据有显著影响
6、结合回归方程对该问题做一些基本分析
从上面的分析过程中可以看出腰围和脂肪比重以及腰围和体重的相关性都是很大的,通过检验可以看出回归方程、回归系数也很显著。
其次可以观察到腰围、脂肪比重、体重的数据都是服从正态分布的。
多元线性回归模型实验报告计量经济学多元线性回归模型是一种比较常见的经济学建模方法,其可用于对多个自变量和一个因变量之间的关系进行分析和预测。
在本次实验中,我们将使用一个包含多个自变量的数据集,对其进行多元线性回归分析,并对分析结果进行解释。
数据集介绍本次实验使用的数据集来自于UCI Machine Learning Repository,数据集包含有关汽车试验的多个自变量和一个连续因变量。
数据集中包含了204条记录,其中每条记录包含了一辆汽车的14个属性,分别是:MPG(燃油效率),气缸数(Cylinders)、排量(Displacement)、马力(Horsepower)、重量(Weight)、加速度(Acceleration)、模型年(Model Year)、产地(Origin)等。
模型建立在进行多元线性回归分析之前,我们首先需要对数据进行预处理。
为了确保数据的可用性,我们需要先检查数据是否存在缺失值和异常值。
如果有,需要进行相应的处理,以确保因变量和自变量之间的关系受到了正确地分析。
在对数据进行预处理之后,我们可以使用Python中的statsmodels包来对数据进行多元线性回归分析。
具体建模过程如下:```import statsmodels.api as sm# 准备自变量和因变量数据X = data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]y = data['MPG']# 添加常数项X = sm.add_constant(X)# 拟合线性回归模型model = sm.OLS(y, X).fit()# 输出模型摘要print(model.summary())```在上述代码中,我们首先通过data[['Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']]选择了所有自变量列,用于进行多元线性回归分析;然后,我们又通过`sm.add_constant(X)`,向自变量数据中添加了一列全为1的常数项,用于对截距进行建模;最后,我们使用`sm.OLS(y, X).fit()`来拟合线性回归模型,并使用`model.summary()`输出模型摘要。
摘要:中国是一个农业大国,几千年传统的原始落后的农耕社会使得中国的农业发展滞后于全社会经济的发展。
新世纪中国发展的关键在于解决九亿农民的发展问题,其实质就在于提高农民的实际收入。
建立投资额模型,研究某地区实际投资额与国民生产总值 ( GNP ) 及物价指数 ( PI ) 的关系,根据对未来GNP及PI的估计,预测未来投资额。
以下是地区连续20年的统计数据,为了增加数据可比性,投资额和国民生产总值是以第一年为基期将数据换算后的。
:关键词:投资额国民生产总值物价指数1实验目的掌握运用eviews软件进行多元回归分析的基本操作方法和步骤,并能够对软件运行结果进行解释。
2变量选择建立投资额模型,研究某地区实际投资额与国民生产总值 ( GNP ) 及物价指数 ( PI ) 的关系,根据对未来GNP及PI的估计,预测未来投资额。
以下是地区连续20年的统计数据,为了增加数据可比性,投资额和国民生产总值是以第一年为基期将数据换算后的。
下面是进行简单的多元回归:Dependent Variable: YMethod: Least SquaresDate: 11/05/15 Time: 20:32Sample: 1994 2013Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.X1 0.636132 0.068555 9.279108 0.0000X2 -892.3898 127.2399 -7.013442 0.0000C 334.7074 47.71633 7.014525 0.0000R-squared 0.991022 Mean dependent var 234.8000 Adjusted R-squared 0.989965 S.D. dependent var 125.7070S.E. of regression 12.59240 Akaike infocriterion 8.041544 Sum squared resid 2695.663 Schwarz criterion 8.190904Log likelihood -77.41544 Hannan-Quinncriter. 8.070701 F-statistic 938.2299 Durbin-Watson stat 0.828098 Prob(F-statistic) 0.000000各个解释变量都都用过了t检验,总体也通过了F检验。
第二次作业五、异方差的诊断与修正1)图形检验法首先,产生序列。
e 2=resid^2用残差的平方和X作图。
X作为X轴,残差的平方作为Y轴。
这是得出的X1与e2的散点图从图中我们可以看到,随着X 的增加,e2有着增加的趋势,但不是很明显,很难判断是否存在异方差。
010*******400500X1E 22)戈里瑟检验结论:由下图知F-statistic ,Obs*R-squared , P 值大于0.05,所以不存在异方差。
Heteroskedasticity Test: GlejserF-statistic 0.389602 Prob. F(2,17) 0.6832 Obs*R-squared 0.876533 Prob. Chi-Square(2) 0.6452 Scaled explained SS0.602108 Prob. Chi-Square(2) 0.7400Test Equation:Dependent Variable: ARESID Method: Least Squares Date: 11/08/15 Time: 19:10 Sample: 1994 2013Included observations: 20VariableCoefficientStd. Error t-Statistic Prob. C 9.410399 25.28480 0.372176 0.7144 X1 0.004852 0.036327 0.133552 0.8953 X2 -5.85997967.42423 -0.086912 0.9318010*******400500X2E 2R-squared 0.043827 Mean dependent var 9.757171 Adjusted R-squared -0.068664 S.D. dependent var 6.454763S.E. of regression 6.672690 Akaike infocriterion 6.771404 Sum squared resid 756.9214 Schwarz criterion 6.920764Log likelihood -64.71404 Hannan-Quinncriter. 6.800561 F-statistic 0.389602 Durbin-Watson stat 1.521978 Prob(F-statistic) 0.6832213)怀特检验打开x与y的等式,从视图窗口导出怀特检验图,如下图Heteroskedasticity Test: WhiteF-statistic 0.466019 Prob. F(5,14) 0.7953 Obs*R-squared 2.853746 Prob. Chi-Square(5) 0.7225 Scaled explained SS 1.058796 Prob. Chi-Square(5) 0.9577Test Equation:Dependent Variable: RESID^2Method: Least SquaresDate: 11/05/15 Time: 20:37Sample: 1994 2013Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.C 3452.888 9317.534 0.370580 0.7165X1 6.339848 26.29923 0.241066 0.8130X1^2 0.002261 0.018970 0.119173 0.9068X1*X2 -10.59972 70.23460 -0.150919 0.8822X2 -13390.41 49003.38 -0.273255 0.7886X2^2 11944.62 65113.09 0.183444 0.8571R-squared 0.142687 Mean dependent var 134.7832 Adjusted R-squared -0.163496 S.D. dependent var 140.1420S.E. of regression 151.1648 Akaike infocriterion 13.11794 Sum squared resid 319911.3 Schwarz criterion 13.41666Log likelihood -125.1794 Hannan-Quinncriter. 13.17626F-statistic 0.466019 Durbin-Watson stat 1.399326Prob(F-statistic) 0.795252在 H 0 : x1 =x2 =C=0 的原假设下, nR^2 渐进地服从X0.052(5)。
若 nR^2>X0.052(5),则拒绝H 0 ,接受 H 1 ,表明回归模型中参数至少有一个显著地不为零,即随机误差项存在异方差性。
反之,则认为不存在异方差性。
在此结果中,nR^2= Obs*R-squared =2.853746<X0.052(5)=11.070。
故接受原假设,认为不存在异方差性。
六、多重共线性首先,先对解释变量进行相关系数检验,如图相关系数表其次,拿X1、x2分别跟y做回归,选出最优的解释变量,如下图1)X1与Y:Dependent Variable: YMethod: Least SquaresDate: 11/05/15 Time: 20:44Sample: 1994 2013Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.X1 0.156005 0.006998 22.29189 0.0000C 2.810295 11.72423 0.239700 0.8133R-squared 0.965044 Mean dependent var 234.8000Adjusted R-squared 0.963102 S.D. dependent var 125.7070S.E. of regression 24.14699 Akaike infocriterion 9.300836 Sum squared resid 10495.38 Schwarz criterion 9.400409Log likelihood -91.00836 Hannan-Quinncriter. 9.320273 F-statistic 496.9285 Durbin-Watson stat 1.274525 Prob(F-statistic) 0.000000回归的不错2)x2与y:Dependent Variable: YMethod: Least SquaresDate: 11/05/15 Time: 20:45Sample: 1994 2013Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.X2 286.6090 16.21126 17.67962 0.0000C -101.1043 20.15924 -5.015286 0.0001R-squared 0.945548 Mean dependent var 234.8000 Adjusted R-squared 0.942523 S.D. dependent var 125.7070S.E. of regression 30.13737 Akaike infocriterion 9.744048 Sum squared resid 16348.70 Schwarz criterion 9.843621Log likelihood -95.44048 Hannan-Quinncriter. 9.763486 F-statistic 312.5690 Durbin-Watson stat 1.254911 Prob(F-statistic) 0.000000下面进行二元回归:X1与x2与Y的回归:Dependent Variable: YMethod: Least SquaresDate: 11/05/15 Time: 20:32Sample: 1994 2013Included observations: 20Variable Coefficient Std. Error t-Statistic Prob.X1 0.636132 0.068555 9.279108 0.0000X2 -892.3898 127.2399 -7.013442 0.0000C 334.7074 47.71633 7.014525 0.0000R-squared 0.991022 Mean dependent var 234.8000 Adjusted R-squared 0.989965 S.D. dependent var 125.7070S.E. of regression 12.59240 Akaike infocriterion 8.041544 Sum squared resid 2695.663 Schwarz criterion 8.190904Log likelihood -77.41544 Hannan-Quinncriter.8.070701 F-statistic 938.2299 Durbin-Watson stat 0.828098 Prob(F-statistic)0.000000所以最优的回归方程是 Y = 0.636131593744*X1 - 892.389823974*X2 + 334.707383297七、序列自相关性1)散点图 X1与y 的散点图X2与y 散点图5001,0001,5002,0002,5003,0003,500YX 12)残差的诊断 X1与y的残差图:X2与y 的残差图:0.60.81.01.21.41.61.82.02.2YX 2可以看出,逆转的次数很少。