关于文字识别中两种倾斜校正算法的比较研究
- 格式:doc
- 大小:22.50 KB
- 文档页数:3

基于识别反馈的文档图像倾斜校正的研究和应用随着现代科技的快速发展,文档图像的数字化处理已经成为一个重要的研究领域。
在文档数字化的过程中,图像倾斜是一个常见的问题,它会影响文档的可读性和识别准确性。
因此,研究和应用基于识别反馈的文档图像倾斜校正成为了当前的热点。
首先,了解文档图像倾斜校正的原理是非常重要的。
文档图像倾斜校正是通过对文档图像进行旋转操作,使得文本行与水平方向保持平行。
传统的图像倾斜校正方法通常是基于图像的几何特征进行处理,如直线检测和角度计算。
然而,这些方法往往需要先验知识或者手动选择参数,对于不同类型的文档图像效果不一致。
基于识别反馈的文档图像倾斜校正方法则是一种新的思路。
该方法首先通过OCR(Optical Character Recognition,光学字符识别)引擎对文档图像进行识别,然后根据识别结果来调整文档的倾斜角度。
具体来说,当OCR引擎在倾斜的图像上进行识别时,会产生一些错误的识别结果。
这些错误可以通过计算识别结果的置信度来量化,进而反映图像的倾斜程度。
根据置信度的变化,可以确定最佳的倾斜校正角度,从而实现文档图像的倾斜校正。
基于识别反馈的文档图像倾斜校正方法具有几个优点。
首先,它能够自动适应不同类型的文档图像,不需要手动选择参数。
其次,该方法可以通过不断迭代优化,提高倾斜校正的准确性和稳定性。
最后,这种方法不仅可以应用于文档图像的倾斜校正,还可以应用于其他类似的图像处理任务。
基于识别反馈的文档图像倾斜校正方法已经在实际应用中取得了一定的成果。
例如,在银行和邮政等行业,文档图像的倾斜校正是必不可少的任务。
采用这种方法可以提高文档图像的处理速度和准确性,从而提高工作效率和服务质量。
总之,基于识别反馈的文档图像倾斜校正是一种有效的方法,它可以通过OCR引擎的识别结果来校正文档图像的倾斜角度。
这种方法不仅简化了倾斜校正的流程,还提高了准确性和稳定性。
随着科技的不断发展,相信基于识别反馈的文档图像倾斜校正方法将在更多领域得到广泛应用。


手写数字识别算法的比较研究近年来,随着人工智能技术的不断发展,手写数字识别技术也得到了快速的发展。
手写数字识别算法作为人工智能领域的一个重要分支,已经被广泛应用于各个领域中,例如图像识别、语音识别等。
本文将比较研究几种手写数字识别算法,包括KNN算法、SVM算法、神经网络算法以及深度学习算法。
一、KNN算法KNN算法是一种基于邻居的分类算法。
该算法的基本思想是,对于一个待分类的观测对象,将其划分到与其距离最近的K个邻居所在的类别中。
在手写数字识别中,KNN算法通过计算待分类数字与训练数据集中所有数字的距离,将其归类为与其距离最近的K个数字的类别中。
KNN算法的优点是简单易懂,算法的准确度高,并且可以随时进行模型的更新,缺点是计算效率不高,对于大规模数据集,算法的时间复杂度会很高。
二、SVM算法SVM算法是一种常用的分类算法,其基本思想是通过构建一个最优化的超平面,将不同类别的数据点分隔开。
在手写数字识别中,SVM算法通过将数字图像特征提取出来,构造一个最优的超平面,将数字区分开来。
SVM算法的优点是可以处理高维空间数据、泛化能力强,并且算法的准确度很高,缺点是对于大规模数据集来说,算法的计算复杂度较高。
三、神经网络算法神经网络算法是一种基于神经元模型的分类算法,其基本思想是将输入样本数据传入多层神经元中,通过每个神经元的激活函数计算,最终得到输出结果。
在手写数字识别中,神经网络算法通过构建多层神经网络,对数字图像进行特征提取和分类识别。
神经网络算法的优点是对于非线性数据分类效果好,并且算法的准确度较高,缺点是需要大量的训练数据以及计算资源,同时运算速度较慢。
四、深度学习算法深度学习算法是一种基于深度神经网络的分类算法,其基本思想是通过多层神经元进行特征提取和分类识别。
在手写数字识别中,深度学习算法可以通过搭建一个深度卷积神经网络来实现数字图像特征提取和分类识别。
深度学习算法的优点是可以自动提取特征、训练时间短、准确度高,并且对于数字识别问题来说,深度学习算法的效果最好。

基于字素分割的蒙古文手写识别研究范道尔吉;高光来;武彗娟【摘要】隐马尔科夫模型(HMM)对序列数据有很强的建模能力,在语音和手写识别中都得到了广泛的应用.利用HMM研究蒙古文手写识别,首先需要解决的问题是手写文字的序列化.从蒙古文的构词和书写特点看,蒙古文由多个字素从上到下串联构成.选择字素集合和词的字素分割是手写识别的基础,也是影响识别效果的关键因素.该文根据蒙古文音节和编码知识确定了蒙古文字母集合,共包括1171个字母.通过相关性处理、H M M排序筛选等手段得到长字素集合,共包括378个字素.对长字素经过人工分解,获得了50个短字素.最后利用两层映射给出了词转字素序列的算法.为了验证长短字素在手写识别中的效果,我们在HTK(hidden Markov model tool-kit)环境下利用小规模字库实现了手写识别系统,实验结果表明短字素比长字素有更好的性能.文中给出的字素集合和词转字素序列的算法为后续基于HMM的蒙古文手写识别研究奠定了基础.%Hidden Markov Models(HMM ) has strong modeling capabilities for sequence data,and it is widely used in speech recognition and handwriting recognition task.HMM-based Mongolian handwriting recognizers require the data to be analyzed sequentially.According to Mongolian word formation and writing style,it is evident that a Mon-golian word consists of grapheme seamless connected from top to down.The selection of grapheme and segmentation word to grapheme is a preliminary work for handwriting recognition with substantial effects on recognition accuracy. In this paper,according to knowledge of syllables and coding,we collect a Mongolian letters set of 1171 letters. The long grapheme set which contain 378 grapheme is thenextracted from letters set by correlation process and HMM based sorting method.The short grapheme set which contain 50 shapes is extracted from long grapheme set via decompose long grapheme by hands.We present an algorithm to decompose a word to grapheme by two layers mapping.Experimental results show that the short grapheme get better performance than long grapheme.【期刊名称】《中文信息学报》【年(卷),期】2017(031)005【总页数】7页(P74-80)【关键词】蒙古文;字素;HMM;手写识别【作者】范道尔吉;高光来;武彗娟【作者单位】内蒙古大学计算机学院,内蒙古呼和浩特010021;内蒙古大学计算机学院,内蒙古呼和浩特010021;内蒙古大学电子信息工程学院,内蒙古呼和浩特010021【正文语种】中文【中图分类】TP391各种语言的手写体识别是人工智能领域最具有挑战性的研究课题之一,主要包括脱机手写体识别和联机手写体识别。

人工智能及识别技术本栏目责任编辑:唐一东云计算平台上两种中文分词算法的实现对比研究周寅,龙广富(武汉船舶职业技术学院,湖北武汉430050)摘要:现如今,常用的中文分词算法为IKAnalyzer (简称为:IK )和ICTCLAS (简称为:IC )两种,这两种算法也可以说是如今的主流中文分词算法,为了能够更好的研究两种算法的性能,本文首先利用理论对两种算法在单机环境下的性能进行分析,而后通过Hadoop 分布式文件管理系统(简称为:HDFS )、Hadoop 集群和并行处理大数据集的MapReduce 所共同组成的系统框架,并将算法优化后,通过开展大量的实践性实验对两种不同算法在分布式环境下对大数据集进行处理后的表现进行比较,而后得出具体的分析结果,希望能够为相关人士带来帮助。
关键词:云计算;IKAnalyzer ;ICTCLAS ;Hadoop ;比较中图分类号:TP3文献标识码:A文章编号:1009-3044(2021)09-0191-02开放科学(资源服务)标识码(OSID ):对于中文分词法来说,该方法最初被北京航空航天大学的梁南元教授所提出,属于一种在查字典分析方法基础上的分词方法,近些年来,由于我国经济水平和社会发展的速度越来越快,中文在整个世界舞台中所占据的地位也越来越重要,并且吸引了更多学者加入中文分词法的研究中,现如今已经实现了基于多种词典和概率统计的中文分词算法,而在面对这些大量的中文信息时,必须要确保文本分词结果,在满足本身词义的基础上,尽可能延长词组长度,而现如今的中文分词算法种类非常多,但是可以将其大致分为三种,分别为基于字符串匹配的分词、基于理解的分词以及基于统计的分词,在这种情况下也出现了多种分词算法产品,比如SCWS 、HTTPCWS.IKAnalyz⁃er 2012、FudanNLP 、ICTCLAS 等,而这些分词算法均不能算作为开源,而考虑到虽然IKAnalyzer 2012、ICTCLAS 等算法属于开源,但是这些算法却大多应用在单机环境下,考虑这一前提条件,可以将这两种算法引入到云计算平台上,进而使其能够与更多应用进行结合。

西北工业大学硕士学位论文印刷体文字识别方法研究姓名:张炜申请学位级别:硕士专业:计算机应用技术指导教师:赵荣椿19990301摘要《文字楚人类茨怠交滚爨垂簧手段,印别然汉字鼋}:{裂霹以有效黥提高印刷资料的录入速度,它的突破会极大的促进全球的信息化进程。
本文逶邋对国内拜多静文字谬剩方法静深入磅究,结合爨】麓蒋汉字静自身特点,提出了一种多级分类的综合统计识别方法。
经过实验,取、得了令人满意的效采。
P_,一一/一般的文字谚{别系绞出预处理、特征提取、模式匹配和后处理四大模块组成。
本文在许多关键技术方面提出了自己的方法:酋先,在联处矬除段,晨嬲一‘秽麓棼毂颇斜较澎算法,若姆文字归~怨为36t36点阵而爿;是传统的48+48点阵,宵效的减少了计算量,且几乎不会造黢罄{鬟奉麴降低;撬爨馥送懿基予羚攫豹筠…纯,避免了笔爨浚失;其次,在特征提取时,采用一种改进的粗外围特征,并进行二重分割,充分傈涯特征的高度稳定经;采用162维平均线密度特蔹斓于鲴分类:第三,程模式躁配时,针对各级特点,分别采用绝对值距离、欧氏距离、以及类似泼加权准则判别;最詹,在后处理阶段,根据语言、文字学知谈,采躜字频艇投秘上”F文缝溷关系分烈处理。
关键词文字识另(印刷体汉字识彬多级分影预处理,婶、Y《Nv"文字识别,印刷体汉字识别’、多级分类’,预处理,(行、翔一纯V,二耄务彤耨鬣提醇羯爨准潮<ABSTRAC零Writtenlanguageisanimportantmeansofcommunication,recognitionofmachineprintedcharacterCallimprovetheefficiencyofmaterialinputcommendably,thebreakthroughofitcanacceleratetheprocedureofworld’sinformationexchange,Inthispaper,basedonthecharacteristicsofprintedcharacters,Weproposeamulti-stagesynthesizedstatisticalmethodaftercarefullystudiedmanykindsofrecognitionmethodintheworld。

汉字应用水平测试字形辨误试题对比研究【摘要】本研究旨在比较汉字应用水平测试中的字形辨误试题在不同设计下的效果。
通过介绍测试方法并对比分析试题设计,进行实验结果讨论及数据统计分析,从而得出结论。
实验结果显示不同设计对测试结果影响显著,可为今后汉字教育提供参考。
结论部分总结了实验结果,并展望未来研究方向。
通过本研究,我们深入探讨了汉字应用水平测试的关键问题,为汉字教学和评估提供了理论基础和方法支持。
研究的背景和意义在于提高汉字教学的有效性和质量,为学生提供更好的学习体验和提高汉字应用能力。
【关键词】汉字应用水平测试、字形辨误、对比研究、测试方法、试题设计、实验结果、数据统计、结论推理、实验总结、研究展望。
1. 引言1.1 研究背景汉字是中国文化的瑰宝,汉字的书写和认读一直被认为是中国教育中的重要部分。
随着时代的发展,汉字的传统认读方式可能会面临挑战。
有些学生可能会因为书写不规范或者字形相似而出现辨认错误的情况。
为了解决这一问题,汉字应用水平测试字形辨误试题对比研究应运而生。
在过去的研究中,虽然有一些关于汉字辨误测试的研究,但是大多数研究都是基于传统的文化认知和笔画结构。
随着社会的发展和教育改革的不断深化,传统的认读方式可能已经无法完全适应现代社会的需要。
有必要对汉字应用水平测试字形辨误试题进行更加深入的研究,以提高学生的汉字书写和认读能力。
本研究旨在通过对汉字应用水平测试字形辨误试题的设计和对比分析,探讨不同测试方法对学生的辨认能力和书写准确性的影响。
通过实验结果的讨论和数据统计分析,我们希望能为提高学生汉字书写和认读能力提供一定的参考。
1.2 研究目的研究目的是通过对汉字应用水平测试的字形辨误试题进行对比研究,探讨不同试题设计对测试结果的影响,分析测试方法的有效性和准确性。
具体来说,我们希望通过比对不同设计的试题,了解学生在汉字辨认和书写能力上的表现差异,从而为提高汉字教育质量提供参考依据。
通过对实验结果进行讨论和数据统计分析,我们也将探讨不同试题设计对学生学习汉字的效果和影响,为教育教学实践提供有益建议。

四款主流语料对齐工具性能对比探析
王琴;王宇春
【期刊名称】《南阳理工学院学报》
【年(卷),期】2024(16)1
【摘要】利用实验研究的方法,以科技、旅游、文学、政治四种中英双语文本为样本,对四款语料对齐工具进行了对比研究。
研究发现,从基础技术指标来看,Matecat Aligner、ABBYY Aligner 2.0、Tmxmall Aligner更有优势;从非基础技术指标来看,Matecat Aligner和DéjàVu X3 Alignment在断句准确率方面更为突
出,ABBYY Aligner 2.0在对齐准确率方面要优于其他工具;ABBYY Aligner 2.0和Matecat Aligner具有纠错功能。
通过具体分析发现,使用不同类型的文本,对齐质
量也有所不同;不同的语料对齐工具适合不同文本的对齐。
【总页数】8页(P45-52)
【作者】王琴;王宇春
【作者单位】山西工商学院外国语学院
【正文语种】中文
【中图分类】H059
【相关文献】
1.语料对齐研究与Macken句子层以下对齐模式介评
2.纳-汉双语语料库构建及双语语料对齐
3.基于Tkinter的多语语料库分段与对齐工具实现研究
4.信息处理用彝、
汉、英三语平行语料库的建设与语料对齐技术研究5.基于汉语标点句的汉英双语对齐语料库构建及对齐语序分析
因版权原因,仅展示原文概要,查看原文内容请购买。


文本校对算法(最新版)目录一、文本校对算法的概述二、文本校对算法的原理与方法三、文本校对算法的应用实例四、文本校对算法的优缺点及发展前景正文一、文本校对算法的概述文本校对算法是一种基于自然语言处理技术的计算机程序,用于检查和纠正文本中的拼写、语法和标点错误。
在当今信息爆炸的时代,文本校对算法在提高文本质量、保证信息传递的准确性方面发挥着越来越重要的作用。
二、文本校对算法的原理与方法1.基于词典的方法:通过构建一个词典,将文本中的单词与其正确的拼写进行匹配。
如果发现不匹配的单词,则将其替换为正确的拼写。
此方法适用于拼写错误的检测和纠正。
2.基于统计的方法:通过对大量正确文本的分析,计算单词出现的概率分布。
当检测到异常的单词出现概率时,判断其可能为错误,并尝试用概率更高的单词进行替换。
此方法适用于拼写和语法错误的检测和纠正。
3.基于机器学习的方法:通过训练模型,学习正确文本的特征。
当输入文本与模型的特征不符时,模型将输出纠正后的文本。
此方法适用于复杂的语法和标点错误检测和纠正。
4.基于深度学习的方法:利用神经网络模型学习文本的表示,从而实现对错误文本的自动纠正。
此方法适用于各类错误类型的检测和纠正,尤其适用于长篇和复杂文本的校对。
三、文本校对算法的应用实例1.搜索引擎:通过文本校对算法,提高搜索结果的准确性,提升用户体验。
2.智能输入法:在用户输入文本时,实时检测和纠正拼写、语法和标点错误,提高输入效率。
3.在线编辑器:在用户编辑文本时,实时检测和纠正错误,保证文本质量。
4.自动翻译:在跨语言翻译过程中,通过文本校对算法,提高翻译的准确性。
四、文本校对算法的优缺点及发展前景优点:1.提高文本质量,保证信息传递的准确性。
2.减轻人工校对工作量,提高工作效率。
3.适应多种文本类型和场景。
缺点:1.对复杂的语言结构和语义理解能力有限。
2.可能出现误校,需要人工审核。
发展前景:随着自然语言处理技术的不断发展,文本校对算法的准确性和智能化水平将不断提高。
场景文字识别技术研究综述随着图像和视频数据的快速增长,场景文字识别技术在许多应用领域变得越来越重要。
本文将概述场景文字识别技术的现状、主要方法及其优缺点,并对其进行综合比较和评价。
场景文字识别是指从图像或视频中识别和理解文本信息的过程。
这些信息可能位于各种自然和复杂的环境中,如街道、广告牌、招牌、书籍等。
场景文字识别对于许多应用领域如自动驾驶、智能监控、人机交互等具有重要意义。
本文将重点场景文字识别技术的发展现状、主要方法及各方法的优缺点。
场景文字识别通常涉及图像处理、机器学习和深度学习等技术。
图像处理用于预处理图像,包括去噪、二值化、分割等操作,以改善文字的识别效果。
机器学习用于训练模型以自动识别和解析文字,其方法包括基于特征的方法和基于深度学习的方法。
深度学习是机器学习的一个分支,它利用人工神经网络模拟人脑的学习方式,以获得更好的识别效果。
目前,场景文字识别技术的研究主要集中在基于图像处理的技术、基于机器学习的方法和基于深度学习的方法。
基于图像处理的技术主要利用各种图像处理算法对输入图像进行处理,以提取文字区域并进行识别。
基于机器学习的方法利用有监督学习训练分类器以识别文字,其方法包括支持向量机(SVM)、随机森林等。
基于深度学习的方法利用卷积神经网络(CNN)或循环神经网络(RNN)等进行文字识别,其方法包括CRNN、CTC等。
虽然目前场景文字识别技术已经取得了一定的成果,但仍存在一些不足。
主要问题包括文字的定位精度和识别准确率有待提高,对于复杂背景和不同字体、颜色的文字识别能力有待加强现有的场景文字识别技术对于大规模数据的处理能力有待提高,同时需要更好地结合领域知识和语言模型进行优化。
本文对场景文字识别技术进行了全面的综述,包括技术原理、研究现状和存在的不足。
目前,场景文字识别技术已经在许多领域得到了广泛的应用,但仍存在一些挑战性问题需要进一步研究和解决。
未来的研究方向可以包括以下几个方面:改进技术算法:进一步探索和开发更有效的图像处理、机器学习和深度学习算法,以提高场景文字的定位精度和识别准确率。
基于hough变换倾斜文档校正的改进方法
文本:
Hough变换是一种图像处理中常用的方法,可以用于识别图像中的直线或者曲线等。
在文档处理中,由于文档的拍摄或者扫描会产生一些倾斜,需要进行校正,常用的方法就是基于Hough变换。
但是,在实际应用中,使用基本的Hough变换可能存在一些问题,比如对于一些曲线较复杂的文档,校正效果不够理想,同时处理速度也比较缓慢。
因此,有必要对Hough变换进行改进。
一种改进的方法是基于区域的Hough变换。
将图像划分为若干个区域,然后在每个区域中进行Hough变换。
这种方法可以有效地处理曲线较复杂的文档,并且处理速度也较快。
但是,需要注意的是,如果将区域划分太细,则Hough变换的计算量会变大,因此需要选取合适的区域大小。
另一种改进的方法是基于深度学习的文档校正方法。
通过训练深度神经网络,可以实现文档的自动校正。
这种方法可以处理各种类型的文档,并且校正效果比较理想。
但是,需要大量的训练数据和计算资源,同时训练时间也比较长。
综上所述,根据实际情况选择适合的文档校正方法是非常重要的。
对于简单的文档,使用基本的Hough变换可能已经足够,而对于复杂的文档,则需要考虑使用更加高级的文档校正方法。
基于傅里叶变换和Hough变换的商标图案倾斜校正胡仁伟;张希仁;杨立峰;林道锋;成祎珊【摘要】针织物商标图案加工过程中会产生形变,影响纺织品等级和质量.针对商标图案形变检测过程中出现倾斜现象而降低形变测量精度的问题,采用Hough变换提取商标图案频谱图的旋转角度,以实现图案的倾斜校正.应用结果表明该算法能精确提取商标图案的倾斜角度并进行倾斜校正.算法不改变图案的原始形貌,提高了运行效率.%The appearance and quality of clothing is affected by the deformation of the fabric trademark pattern during manufacturing.But the measurement accuracy of deformation of trademark pattern is decreased due to trademark pattern tilting.In this paper the method based on the Fourier and Hough transform was proposed and used to measure and correct the rotation angle of tilted trademark pattern.The application shows that the method proposed can be used to correct the tilted fabric pattern.The algorithm guarantees the original shape of the pattern and improves the efficiency.【期刊名称】《轻工机械》【年(卷),期】2018(036)001【总页数】4页(P62-65)【关键词】针织物商标图案;傅里叶变换;Hough变换;倾斜校正【作者】胡仁伟;张希仁;杨立峰;林道锋;成祎珊【作者单位】电子科技大学光电信息学院,四川成都 610054;电子科技大学光电信息学院,四川成都 610054;电子科技大学光电信息学院,四川成都 610054;昆山联滔电子有限公司,江苏昆山 215324;电子科技大学光电信息学院,四川成都 610054【正文语种】中文【中图分类】TP391.41商标是产品的身份证,具有独特的代表意义。
基于机器视觉和神经网络的低质量文本识别研究李少辉;周军;刘波;钱俞好;吴闽仪【摘要】针对流水线产品上的文本图片含有较多噪声和缺陷,造成机器视觉产品中字符识别准确率低,鲁棒性差的问题,对文本识别中的图像预处理、字符切分和归一化、字符识别等方面进行了研究,采用机器视觉技术中基于仿射变换的预处理方法对文本图片进行了倾斜校正,保证了后续字符的精确切分;提出了一种基于改进的BP 神经网络算法,显著提高了字符识别的准确率和鲁棒性,利用附加动量法和自适应学习速率方法,避免了传统BP神经网络训练过程中易陷入局部极小值的情况,并提高了神经网络模型的收敛速度.研究结果表明:该方法能使倾斜的图片得到有效校正,神经网络模型的训练效率得到有效提高,且在含有噪声和缺陷的字符图片中仍能保持较高的识别率和鲁棒性.【期刊名称】《机电工程》【年(卷),期】2018(035)009【总页数】5页(P1006-1010)【关键词】机器视觉;流水线;文本识别;倾斜校正;改进BP神经网络【作者】李少辉;周军;刘波;钱俞好;吴闽仪【作者单位】河海大学机电工程学院,江苏常州213000;河海大学机电工程学院,江苏常州213000;河海大学机电工程学院,江苏常州213000;河海大学机电工程学院,江苏常州213000;河海大学机电工程学院,江苏常州213000【正文语种】中文【中图分类】TP242.6+2;TH390 引言近年来,为了进一步提升生产车间流水线的自动化水平,提高生产效率,大部分流水线开始采用机器视觉产品代替人眼来识别产品上的文本信息,如生产日期、产品批号、条形码等[1]。
传统的文字识别分类器有模板匹配、支持向量机等,早在20世纪80年代,OCR技术就已进入商用阶段,但是对文字背景的要求很高,需要很好的成像质量;近年来,随着人工神经网络技术在很多问题上有着突破性进展,该技术也被引入文本识别领域中。
2014年ICPR会议上,微软亚洲研究院团队训练的一个浅层BP神经网络在自然场景文字检测的标准数据集上取得了92.1%的检测精度,让自然场景图像中的文字检测实现了突破[2];谷歌公司2015年发布的tensorflow深度学习框架中,深度卷积神经网络对手写数字图片集MNIST的识别准确率达到了99%以上[3]。
汉字应用水平测试字形辨误试题对比研究汉字是中国传统的文字,但是由于汉字的复杂性,对于汉字的识别和辨认也成为了一个重要的研究课题。
尤其对于学习者来说,正确辨认汉字的水平不仅关系到个人的语文能力,还直接影响到学习成绩和学习效果。
对于汉字应用水平测试的研究成为了教育领域的重要课题之一。
本文将通过对汉字应用水平测试中的字形辨误试题进行对比研究,探讨不同测试方式对于学生辨认汉字水平的影响,以期为汉字教学和应用水平测试提供一定的参考和借鉴。
一、字形辨误测试的意义汉字是一种表意文字,通常由象形、指示、形声、会意和假借等构造方式构成。
汉字的书写结构复杂,字形相似的情况也比较常见,因此汉字的辨认和辨误是学习者学习汉字过程中的重要环节。
通过对学生进行字形辨误测试,可以了解学生对于常见汉字的辨认能力,并且通过对比分析学生在不同测试方式下的表现,可以找出学生存在的问题,为教学提供有针对性的改进方案。
二、传统字形辨误试题与现代字形辨误试题对比传统的字形辨误试题通常采用填空或选择题的形式,测试学生对于常用汉字的识别能力。
这种测试方式主要考察学生对于汉字结构、笔画和构造的掌握程度,但是对于学生的理解能力和应用能力的测试相对较少。
而现代的字形辨误试题更加注重学生的理解和应用能力。
除了对于常用汉字的辨认外,还注重测试学生对于词语语境的理解和活用,以及对于同音字、近音字的区分能力。
这种测试方式更贴近实际应用,更有利于检测学生的真实水平。
三、不同测试方式的优缺点分析1. 传统字形辨误测试方式的优点:(1)简单直接,容易操作。
(2)能够直接检测学生对于字形结构的掌握程度。
传统字形辨误测试方式的缺点:(1)对学生的理解能力和应用能力的测试相对较少。
(2)对于多音字、谐音字的辨认难度较大。
2. 现代字形辨误测试方式的优点:(1)能够更全面地测试学生的辨认能力。
(2)更符合实际应用,有利于培养学生的语言实际运用能力。
现代字形辨误测试方式的缺点:(1)操作相对较复杂,评分难度较大。
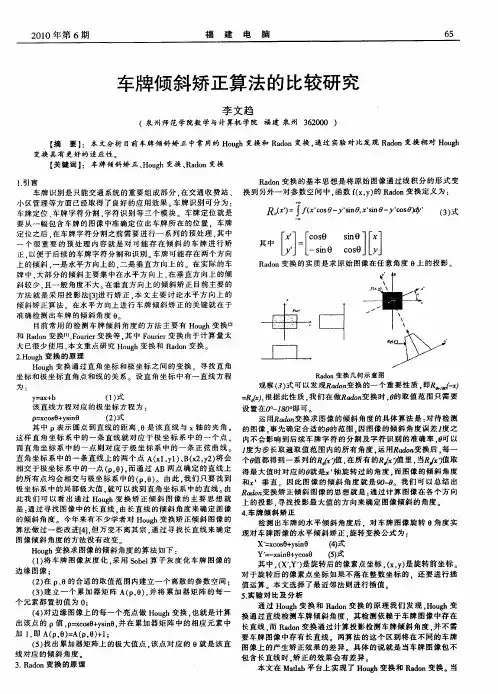
关于文字识别中两种倾斜校正算法的比较研究
摘要:本文针对字符识别中的倾斜校正(即调整字符角度)问题,提出了一种新的校正方法,先经过灰度化,二值化的预处理,再提取字符图像每列的边缘点,经过公示算法计算出这些点所在的参考直线的倾斜角度,这个角度就是字符图像的倾斜角度,本文将这种方法与常用的hough变换校正法进行了比较,实验结果表明本文的算法不仅校正效果更好,而且大量节约了系统资源和简化了计算难度。
关键字:图像处理,计算机字符识别,倾斜校正,hough变换法比较
【中图分类号】tp391.41
文字识别是模式识别的重要内容之一,在进行文字识别的过程中由于种种人为因素或角度问题,待识别图像往往是存在一定的倾斜角度的。
当倾斜角度较大时就会对后续的字符分割和字符识别的结果造成很大的影响。
所以,在进行字符识别之前,进行文档图像的倾斜校正是非常有必要的。
1 本文采用的参考直线校正法
本文处理的文字识别图像需不包含复杂的背景图像,首行没有图表的干扰。
本文算法首先对原图像做预处理,包括灰度变换、阈值设定去噪和二值化处理。
校正算法的大致思想是利用检测直线拟合,先检测每列的第一个非零点(即每个汉字的最上缘)作为边缘点,将他们
代入拟合的检测直线,看是否最多的符合检测直线,如果边缘点符合直线方程的越多,越可以认为这条直线就是符合图像文字倾斜的倾斜直线。
求文档图像倾斜角度的关键就在于找到文档图像的参考直线并计算这条线的倾斜角度,进而求出图像的倾斜角度。
本文选用matlab语言编写程序,依次对图像做灰度化处理,二值化处理,将字符图像处理为字符部分为1,背景部分为0的形式。
为了避免其他费字符部分的灰度干扰,本文在二值化之前加上了一组判定语句,将灰度化之后的图像灰度值大于120的像素点变为255,其余像素点变为0,这样,字符图像就只包含有两种数值,进行二值化后,就只有字符部分和背景部分了,去除非字符部分干扰。
由分析可知本文的算法只提取字符图像每列的元素值,并计算这些值所在直线倾斜的角度,所以这种方法大大缩减了计算量,减少了计算的复杂性,并且大量节省了存储空间,这是它最大的优点。
2 hough变换法进行文档图像的倾斜校正
hough变换的基本原理是利用图像空间中的目标像素坐标计算参数空间中参考点的可能轨迹,并在累加器中给计算出的参考点计数,进行变换时要将经过空间直线的点(x,y)对应的直线斜率a 和截距b分别求出,每一次求出a和b都要进行累加,由于可能存在竖直线即a为无穷大的情况,所以参数空间一般采用极坐标的形式。
3 试验对比结果及结论
由以上分析可知,hough变换的优点是抗噪性能较好,能连接共
线的直线,缺点是需要耗费大量的时间和空间,而且校正结果有时并不理想;而利用本文的算法校正结果比较好,校正角度更为精确,由于本文的校正算法只提取最边缘点,所以计算量和所需存储空间并不大,但抗噪性能不如hough变换,所以本文程序中加入了对待检测图像灰度变换后的阈值限制,进行初步去噪,由于噪声点大都低于字符的灰度,所以这样去噪也能达到很好的效果。
参考文献:
1 张华,张航.汉字识别方法综述.计算机工程,2010,36(20):194-197
2 j.illingworth and j.kittle.a survey of the hough transform.cvgip.vol.44,1988,87-116
3 吴佑寿,丁晓青.汉字识别原理方法与实现,高等教育出版社,1992
4 k.hansen,j.d.anderson.understanding the hough transform:hough cell support and its utilization,image and vision computing,vol.15,1997,20-218
5 张忻中.汉字识别技术[m].清华大学出版社.1992。