基于相位相关的全景图像拼接
- 格式:pdf
- 大小:615.85 KB
- 文档页数:4

基于深度学习的全景图像拼接技术研究随着科技的飞速发展,相机成为了我们日常生活中最为普遍的物品之一,拍摄照片也已经成为了人们生活中不可或缺的一部分。
而全景图像拼接技术就是在这样一个背景下逐渐走入人们的视野。
它利用图像处理技术,将多张不同角度或位置的图片拼接到一起,生成一个完整的全景图像。
本文将探讨基于深度学习的全景图像拼接技术,从理论到实践,从优点到缺点剖析这一技术。
一、基本原理全景图像拼接技术是将多张图片进行拼接,形成一个整体,使其具有一定的连续性和逼真度。
全景图像拼接技术的基本原理是利用摄像机捕捉连续的局部图像,然后将这些图像进行拼接。
在全景拼接中,最常用的方法是通过计算机程序将多幅图像进行配准,然后通过图像拼接技术将这些图像无缝拼接实现全景效果。
二、基于深度学习的全景图像拼接技术研究现状近年来,随着深度学习技术的不断发展,其在图像处理方面也得到了广泛的应用。
基于深度学习的全景图像拼接技术,尤其是卷积神经网络和生成对抗网络等技术的应用,大大提高了全景图像拼接的效果和速度。
在基于深度学习的全景图像拼接技术研究方面,不管是视角的拼接还是场景的拼接,都有很多成果。
例如,有一种名为DeepImageMeld的方法,它利用全景模板和深度图像将多张图片进行配准和拼接,从而产生了一些令人惊叹的结果。
同样,Swirski等人所提出的方法也可以将多张图片配准在一起,并在拼接过程中考虑到了姿态和光照的变化,从而实现更好的拼接效果和更完整的场景。
除了这些方法之外,还有一些其他的方法,如图像融合和全景运动重建等方法,都可以在一定程度上提高全景图像拼接效果。
三、基于深度学习的全景图像拼接技术的优点基于深度学习的全景图像拼接技术有很多优点。
首先,这种技术可以大幅提高全景图像拼接的效果和速度。
其次,这种技术能够自动进行图像配准、调整和拼接,减少了大量人工干预。
此外,基于深度学习的全景图像拼接技术在应对图像下采样和噪声等问题时也有所优势。


全景图像拼接技术研究及应用近几年,全景图像(Panorama)的应用越来越广泛,如旅游景点展示、地图制作、VR(虚拟现实)和AR(增强现实)等应用。
全景图像拼接技术是实现全景图像的关键技术,其主要目标是将多幅重叠的图像拼接为无缝的全景图像。
本文将着重探讨全景图像拼接技术的研究现状和应用。
一、全景图像拼接技术的研究现状1. 传统方法传统的全景图像拼接方法主要包括两种:基于特征点法和基于区域分割法。
前者是将所有图像的特征点匹配,并基于配对点拼接成全景图像;后者则是通过图像的最大重叠区域来进行拼接,适用于图像没有重大的形变或视角变化等情况。
这两种方法的缺点都是易受噪声和遮挡等问题的影响,导致拼接的效果不理想。
2. 基于深度学习的方法近年来,深度学习技术的崛起对于全景图像拼接技术的提升也起到了重要的作用。
通过使用卷积神经网络(Convolutional Neural Networks, CNN),可以提高全景图像拼接的效率和准确性。
2016年,百度提出了一种名为“DeepPano”的深度学习全景图像拼接算法,该方法利用神经网络从大量单张图像中学习特征和相机参数。
与传统方法相比,DeepPano算法具有更高的拼接速度和更好的拼接质量。
3. 基于视频的方法基于视频的全景图像拼接技术最近也引起了广泛的关注。
与多张照片的拼接不同,视频是连续的图像序列,具有更多的信息和上下文。
基于视频的全景图像拼接方法可以通过视频的连续性进一步提高拼接效果。
二、全景图像拼接技术的应用1. 地图制作全景图像拼接技术在地图制作上有广泛的应用。
通过利用卫星遥感图像、无人机摄影图像等数据源,可以快速生成高质量的地图制品,研究人员还利用全景图像拼接技术在地图中嵌入了VR功能,以帮助用户更好地了解地理信息。
2. 旅游景点展示全景图像拼接技术在旅游景点展示上也有广泛的应用。
通过拍摄景区周围的多张照片,将其拼接成一张完整的全景图像,游客可以更好地了解景区的地形、景观等信息。

航空照相机的全景图像拼接技术随着无人机技术的快速发展,航空照相机作为无人机上的重要组成部分,越来越被广泛应用于航空摄影、地理测绘、农业科学等领域。
而其中一项关键技术——航空照相机的全景图像拼接技术,则成为了许多专业摄影师和测绘工作者所关注和探索的重点。
全景图像拼接技术是指将多幅局部重叠的照片通过计算机算法进行自动拼接,生成一幅无缝衔接的大尺寸全景图像的过程。
这项技术的发展,使得我们可以更好地捕捉和保存大范围的景观,更准确地记录和表达真实世界的细节和信息。
航空照相机的全景图像拼接技术的关键在于如何实现照片之间的准确定位和重叠区域的自动识别。
在航空摄影中,由于无人机在拍摄过程中会发生姿态变化和高度变化,这就造成了照片之间的尺度差异和视角变化,在进行图像拼接时增加了一定的难度。
为了解决这一问题,研究人员提出了多种算法和方法。
其中,图像特征点匹配是一种常用的方法。
该方法通过寻找图像中的关键点,并计算关键点的描述子,然后通过匹配关键点和描述子来找到对应的点,从而实现图像的对齐和融合。
此外,还可以利用传感器数据、GPS信息和惯性导航系统等,提高航空照相机姿态、位姿的估计精度,进一步优化图像拼接的结果。
除了关键点匹配,多图像融合算法也是实现航空照相机全景图像拼接的重要手段之一。
该算法通过对多幅图像进行颜色、亮度、对比度等方面的调整,使得图像在拼接后具有一致的外观。
同时,还可以采用多重融合方法,将不同的图像特征和信息进行优化和融合,从而得到更准确的全景图像。
除了技术点的研究,航空照相机全景图像拼接技术的发展还需要考虑到实际应用中的需求和使用场景。
例如,对于航空摄影来说,拼接后的全景图像对于地理测绘、城市规划、农业科学等领域的应用至关重要。
因此,算法的稳定性、拼接效果的准确性和高效性等方面都需要进行综合考虑。
此外,在航空照相机全景图像拼接技术的研究和应用过程中,还需要关注数据的存储和处理。
航空照片的体积通常很大,因此如何高效地存储、传输和处理这些数据,也是一个需要解决的问题。
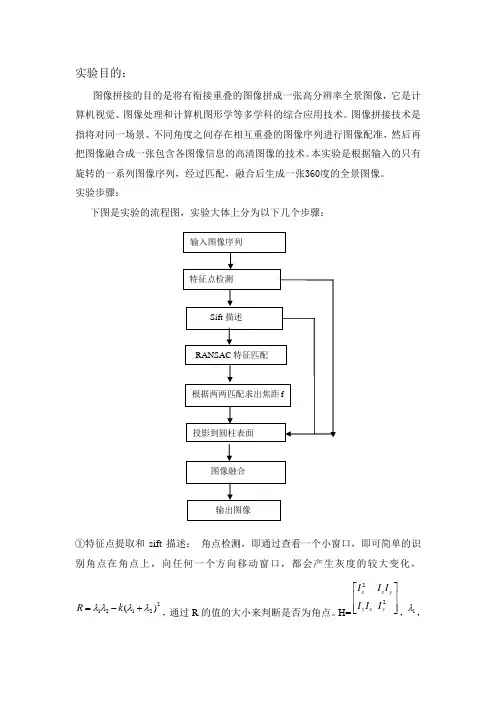
实验目的:图像拼接的目的是将有衔接重叠的图像拼成一张高分辨率全景图像,它是计算机视觉、图像处理和计算机图形学等多学科的综合应用技术。
图像拼接技术是指将对同一场景、不同角度之间存在相互重叠的图像序列进行图像配准,然后再把图像融合成一张包含各图像信息的高清图像的技术。
本实验是根据输入的只有旋转的一系列图像序列,经过匹配,融合后生成一张360度的全景图像。
实验步骤:下图是实验的流程图,实验大体上分为以下几个步骤:①特征点提取和sift 描述: 角点检测,即通过查看一个小窗口,即可简单的识别角点在角点上,向任何一个方向移动窗口,都会产生灰度的较大变化,21212()R k λλλλ=-+,通过R 的值的大小来判断是否为角点。
H=22x x y y x y I I I I I I ⎡⎤⎢⎥⎢⎥⎣⎦,1λ,输入图像序列 特征点检测 Sift 描述RANSAC 特征匹配根据两两匹配求出焦距f投影到圆柱表面图像融合输出图像为矩阵的两个特征值。
实验中的SIFT描述子是对每个角点周围进行4个区域2进行描述,分别是上下左右四个区域,每个方块大小为5*5,然后对每个方块的每个点求其梯度方向。
SIFT方向共有8个方向,将每个点的梯度方向做统计,最后归为8个方向中的一个,得到分别得到sift(k,0),sift(k,1)···sift(k,8),k为方块序列,0-8为方向,共有四个方块,所以生成32维的向量,然后按幅值大小对这32维向量进行排序,并找出最大的作为主方向。
图为角点检测和sift描述后的图②.如果直接根据描述子32维向量进行匹配的话,因为噪声的影响,角点检测的不准确,会导致找出一些错误的匹配对,如何去掉这些错误的匹配呢?RANSAC算法是基于特征的图像配准算法中的典型算法,其优点是:可靠、稳定、精度高,对图像噪声和特征点提取不准确,有强健的承受能力,鲁棒性强,并且具有较好的剔出误匹配点的能力,经常被使用在图像特征匹配中。


(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公布号 (43)申请公布日 (21)申请号 201910129695.6(22)申请日 2019.02.21(71)申请人 武汉大学地址 430072 湖北省武汉市武昌区珞珈山(72)发明人 黄玉春 邱歆煜 田程硕 刘洋洋 (74)专利代理机构 武汉科皓知识产权代理事务所(特殊普通合伙) 42222代理人 王琪(51)Int.Cl.G06T 3/40(2006.01)G06T 7/80(2017.01)G06T 5/00(2006.01)(54)发明名称基于相机几何位置关系的全景影像拼接方法(57)摘要本发明提供一种基于相机几何位置关系的全景影像拼接方法,该方法包括步骤1,组装多相机系统并进行标定,所述多相机系统由多个相机构成;步骤2,建立全景坐标系,得到每个相机与全景坐标系之间的外参;步骤3,对原始畸变影像进行畸变纠正,获取满足物点-光心-像点三点共线的纠正后影像;去除相邻相机拍摄的影像间的部分重叠区域,并将去重叠后的影像映射到全景球面上;步骤4,将全景球面展开得到拼接后的全景影像。
本发明方法提高了全景影像的拼接效率,能在实时的层次上拼接得到全景影像。
权利要求书3页 说明书7页 附图5页CN 109903227 A 2019.06.18C N 109903227A1.一种基于相机几何位置关系的全景影像拼接方法,其特征在于,包括以下步骤:步骤1,组装多相机系统并进行标定,所述多相机系统由多个相机构成;步骤2,建立全景坐标系,得到每个相机与全景坐标系之间的外参;步骤3,对原始畸变影像进行畸变纠正,获取满足物点-光心-像点三点共线的纠正后影像,然后去除相邻相机拍摄的影像间的部分重叠区域,并将去重叠后的影像映射到全景球面上;步骤4,将全景球面展开得到拼接后的全景影像。
2.如权利要求1所述的一种基于相机几何位置关系的全景影像拼接方法,其特征在于:步骤1中所述多相机系统包括6个相机,其中顶部一个相机,光轴指向天顶方向,水平侧面呈正五边形规则分布5个相机,用于侧面拍摄水平方向场景,5个相机光心大致分布在一个圆上。

摘要全景图是虚拟现实中一种重要的场景表示方法。
通常获得高质量的全景图需要使用昂贵的专用设备,而且拍摄时需要精确地校准摄像机。
从普通摄像机图像拼接是获得全景图的一种低成本而且比较灵活的方法。
采用普通照相机拍摄的照片可能出现图像扭曲、交叠和倾斜,照片之问可能有一定色差,因此,在图像的拼接和建立全景图方面难度大。
本文中主要是通过对多种图像拼接算法的研究,提出图像拼接改进算法,该算法能够在较宽松的条件下能够较准确地匹配两幅图像,实验证明该算法能够有效地拼接普通相机拍摄的照片,消除图像扭曲、交叠和倾斜对于图像拼接的影响。
同时,在实现柱面全景图时,为了不改变物体在自然界中的几何信息,也进行了柱面投影研究,实现柱面全景图。
最后使用vC++和OpenGL技术实现了图像拼接系统和柱面全景图浏览器,该系统能够自动拼接按照数字排序的序列照片。
柱面全景图浏览器可以通过鼠标和键艋方向键360”浏览全景图。
关键字:图像拼接;全景图:柱面全景图:柱面投影AbstractAsallimagerepresentationofvirtualenviroarnent,panoramahasimportantapplicationsinVirtual—Reality.Generally,togetapanoramawithhighquality,weneedsomespecial,expensiveandcarefullycalibratedequipment.ImageMosaicisaninexpensiveandflexibleapproachtogetpanoramawithasimplehand-heldcamera.Thephotostakenwithahand—heldcamerausuallyhavelargeperspectivedistortion,smalloverlap,brightnessdifference,smallconcentricerrorsandcamerarotations.Thesecharacteristicsmakebothimagealignmentandpanoramabuildingmoredifficultthanusingphotostakenbycamerascalibratedbyspecialequipment.Basedonstudyingmanyimagemosaicalgorithms,wepresentabetteronethatisabletoaccuratelystitchtwosimilarimagesautomaticallywiththelimitationofthephotos.Theresultfromthethevalidityofthealgorithm.Atthesametime,Istudythecylindricalexperimentshowsprojectionalgorithmsandimplementcylindricalpanoramicimage.Atlast.Iimplementanimage—mosaicsystemandapanoramabrowserwithVC++andOpenGL.ThissystemCanstitchaserialofphotosorderedbynumbers.ThepanoramabrowserCallbeenusedtobrowsecylindricalpanoramicimagewithin360。

一种相机标定参数的柱面全景影像拼接方法随着人工智能的发展,现代的相机标定系统已经能够实现大规模的数字图像处理操作,包括柱面全景影像拼接。
柱面全景影像拼接技术的主要作用是,将多张全景图片拼接成一张完整的全景图片。
这需要计算机视觉技术完成图像校准和点匹配,以确定每张图片彼此之间的位置关系。
本文介绍了一种基于相机标定参数的柱面全景影像拼接方法,该方法通过检测相机标定参数来获取每张图片的空间中的归一化坐标,从而实现拼接操作。
具体来说,该方法首先需要针对每张图片进行头部校准,以确定图像在视觉坐标系中的位置。
然后,通过检测相机标定参数,将图像的视觉坐标系转换为归一化坐标系,以确定图像在空间中的位置关系。
最后,利用这些信息,系统将每张图片拼接在一起,从而实现柱面全景影像拼接。
该方法具有许多优点,首先,它非常有效:只需要针对每张图片的头部校准,就可以轻松地实现柱面全景影像拼接。
另外,它也能有效提高图像拼接的准确性:利用相机标定参数,可以精准地确定图像之间的位置关系。
最后,它能够很好地处理多种复杂的拼接情况,比如缩放、旋转和偏移等。
本文介绍了一种新颖的基于相机标定参数的柱面全景影像拼接方法,该方法既有效又能实现准确的拼接。
它有着多种优点,可以满足实际应用场景的要求。
然而,该方法仍然存在一些不足之处,例如,图像质量低时可能会影响标定精度,从而导致拼接效果不佳。
为了解决这一问题,可以考虑开发新的图像增强技术,以改善图像质量,提高拼接的准确性。
总之,基于相机标定参数的柱面全景影像拼接技术可以满足实际应用中的要求,它可以有效地实现高准确度、高效率的拼接操作。
未来,需要研究者进一步完善和改进该技术,以使其更加完善、精确、高效。

基于深度学习的全景图像拼接与三维场景重建研究全景图像拼接与三维场景重建在现代计算机视觉领域中占据着重要地位。
随着深度学习技术的迅猛发展,基于深度学习的方法在全景图像拼接和三维场景重建方面取得了显著的进展。
本文将介绍基于深度学习的全景图像拼接与三维场景重建的研究现状和主要方法。
首先,全景图像拼接是将多个局部图像拼接成一个全景图像的过程。
传统的全景图像拼接方法通常基于特征点匹配和图像对齐的算法,但在处理大规模场景和复杂纹理时存在一定的局限性。
基于深度学习的全景图像拼接方法通过使用卷积神经网络(CNN)进行特征提取和匹配,能够更准确地获得图像间的对应关系,从而实现更好的全景图像拼接效果。
例如,Pix2pix网络通过生成对抗网络(GAN)的训练方式,能够实现语义级别的全景图像拼接,使得拼接后的图像具有更好的连续性和真实感。
其次,三维场景重建是利用图像信息恢复三维场景的过程。
传统的三维场景重建方法通常基于结构光、多视图几何等技术,但对于复杂场景的重建效果不佳。
基于深度学习的三维场景重建方法通过训练深度神经网络,能够直接从图像中预测出场景中每个像素的深度信息,从而实现更精确的三维场景重建。
例如,ShapeNet网络利用卷积神经网络学习图像和深度信息之间的映射关系,能够实现快速而准确的三维场景重建。
在基于深度学习的全景图像拼接和三维场景重建的研究中,研究者们还提出了许多改进方法。
其中之一是使用注意力机制,通过学习图像中不同区域的重要性,进一步提高图像匹配和深度预测的准确性。
另外,一些研究者探索了使用更复杂的网络结构,如生成对抗网络和循环神经网络,来提高全景图像拼接和三维场景重建的质量和真实感。
然而,基于深度学习的全景图像拼接和三维场景重建仍然面临一些挑战。
首先,深度学习方法通常需要大量的训练数据,但获取大规模带有标注信息的全景图像和三维场景数据是一项耗费时间和资源的任务。
其次,深度学习方法对于不同场景和光照条件的适应性仍然有待提高,特别是在夜间或光照不均匀的情况下。

全景图像拼接技术研究摘要:随着VR/AR技术的逐渐普及,全景图像呈现出了广泛的应用前景,本文介绍了全景图像拼接技术的实现方式、优缺点,同时对相关算法进行了分析和评估,并对未来的发展方向进行了展望。
第一章:绪论VR/AR技术的普及使得全景图像具备了非常广泛的应用前景,在游戏、旅游等领域得到了广泛的使用,同时也受到了科学家们的广泛关注,为了实现高质量的全景图像呈现有时需要进行多张图像的拼接,为此我们需要一种高效、准确的全景图像拼接技术。
第二章:全景图像拼接技术实现1.传统拼接方法传统的全景图像拼接方法主要是基于图像对接,并在对接时消除拼接位置的重叠部分。
这种方法需要针对拼接位置的交叉部分进行大量的处理,需要进行复杂的图像变换、像素的重新分配等操作,因此对计算资源有较高的需求,同时也会导致一定的误差。
2.基于特征点匹配的拼接方法基于特征点匹配的拼接方法主要是利用图像中的特征点来做匹配,并得出拼接后图像的变换矩阵,然而使用这种方法需要针对图像提前进行特征提取,同时在匹配阶段还需要进行特征点的匹配和筛选,这意味着这种方法会带来更多的计算开销,且针对具体的图像需要选择不同的特征点提取算法。
3.基于深度学习的拼接方法近年来,随着深度学习技术的发展,越来越多的学者开始尝试将其应用到全景图像拼接领域中,这种方法主要是根据大量的训练数据,使用卷积神经网络进行特征提取和图像匹配,这种方法能够克服传统拼接方法的缺陷,大幅度减小计算开销,并且还能够有效避免图像的失配问题。
第三章:全景图像拼接技术优缺点分析1.传统拼接方法优点:传统拼接方法较为简单易懂,可以在不需要大量计算资源和训练数据的情况下进行拼接。
缺点:算法难以消除图像拼接时产生的重叠区域,同时也难以保证拼接后的图像的准确性。
2.基于特征点匹配的拼接方法优点:在图像识别和匹配方面有较高的准确率,能够有效提高拼接图像的质量和准确性。
缺点:特征点的提取和匹配需要耗费大量计算资源,同时对于不同的图像场景需要选择不同的特征点提取算法。
一种快速全景图像拼接技术
张世阳;王俊杰;胡运发
【期刊名称】《计算机应用与软件》
【年(卷),期】2004(021)003
【摘要】目前,全景图像的拼接是基于图像绘制技术(IBR)研究的主要内容.本文提出一种新的快速有效的全景图像的拼接算法.在图像对齐中,对基于快速傅立叶变换(FFT)的相位相关度法进行了改进,提出了2幂子图像的概念,采用了基于2幂子图像的FFT对齐方法,从而减小了FFT的计算量,使改进后的算法对图像对齐更加快速和减小图像间重叠率.在柱面坐标下,使用迭代方法计算照相机焦距参数.并采用融合前平滑过渡的算法.最后就实际的系统IMV进行实验证明.
【总页数】3页(P77-79)
【作者】张世阳;王俊杰;胡运发
【作者单位】复旦大学计算机信息技术系,上海,200433;复旦大学计算机信息技术系,上海,200433;复旦大学计算机信息技术系,上海,200433
【正文语种】中文
【中图分类】TP39
【相关文献】
1.一种快速的柱面全景图像拼接算法 [J], 华顺刚;曾令宜;欧宗瑛
2.一种快速的柱面全景图像拼接算法 [J], 安然;张秀林;刘玉
3.基于拼接缝自适应消除和全景图矫直的快速图像拼接算法 [J], 杨春德; 成燕菲
4.一种汽车全景影像监测系统图像拼接品质测试方法的研究 [J], 甘长红;白云;彭俊;孙玉祥
5.一种改进的快速全景图像拼接算法 [J], 常伟;刘云
因版权原因,仅展示原文概要,查看原文内容请购买。
全景图像拼接融合算法研究1 引言随着计算机视觉、计算机图形学、多媒体通信等技术的发展,各类虚拟现实系统都力图构建具有高度真实感的虚拟场景,因此在背景图像及三维模型纹理图像方面都会选择真实图像作为素材,通过将不同角度的图像进行拼接融合获得广视角图像。
因此,无缝平滑的图像拼接融合是构建逼真的模拟训练环境的重要基础。
本文对图像拼接融合算法进行了深入研究,力图构建可以满足各类虚拟现实系统需求的广视角图像。
经验证,本文方法可以稳定高效得对多幅图像实现拼接融合,具有较高的实际应用价值。
2 图像拼接融合算法原理2.1 图像拼接为了实现相邻间有部分重叠的图像序列的拼接,需要首先确定这些图像序列之间的空间对应关系,这一步工作称之为图像配准。
为了确定图像之间的对应关系,需要知道其相应的对应关系模型,一旦确定了图像之间的关系模型,则图像之间的配准问题就转化成确定该模型的参数问题。
目前常用的一些关系模型有平移变换模型、刚性变换模型、仿射变换模型以及投影变换模型等。
其中,刚体变换是平移变换、旋转变换与缩放变换的组合,仿射变换是较刚体变换更为一般的变换。
仿射变换和刚体变换模型则又是投影变换模型的特例。
投影变换关系模型可以用齐次坐标表示为:⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡111~~76543210y x m m m m m m m m y x ……………………………………(1) ⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=176543210m m m m m m m m M ………………………………………… (2) 其中,投影变换矩阵M 中各参数的意义如下:0m 、1m 、3m 、4m 表示尺度和旋转量;2m 、5m 表示水平和垂直方向位移;6m 、7m 表示水平和垂直方向的变形量。
图像配准的实质便是求解投影变换阵M 中的参数。
目前对M 求解的典型方法有:模板匹配法、基于图像灰度的配准法、基于图像特征的方法[1]等。
使用计算机视觉技术进行图像配准和拼接的方法在现代科技的发展中,计算机视觉技术在图像处理和分析领域发挥着重要作用。
其中,图像配准和拼接是计算机视觉中的重要任务之一。
图像配准是将多幅图像对齐到一个统一的坐标系中,以实现后续的图像拼接、特征提取和目标识别等应用。
本文将介绍几种常用的图像配准和拼接方法。
1. 特征点匹配法特征点匹配法是一种常用的图像配准方法。
它通过检测图像中的特征点,并使用特征描述子对这些特征点进行描述。
然后,在两幅图像中寻找相同的特征点,并计算这些特征点之间的差异。
最后,根据差异结果对图像进行变换,以实现图像的配准和对齐。
特征点匹配法的核心在于特征点检测和匹配算法的选择。
常见的特征点检测算法包括SIFT(尺度不变特征变换)和SURF(加速稳健特征)等。
而特征点匹配算法有最近邻算法和RANSAC(随机一致性算法)等。
这些算法能够根据图像的特征来进行匹配,从而达到图像配准的目的。
2. 相位相关法相位相关法是一种基于频域分析的图像配准方法。
它通过计算两幅图像在频域上的相位差异来进行配准。
具体而言,首先将两幅图像进行傅里叶变换,然后计算它们的频谱,并将频谱进行归一化处理。
接下来,将归一化的频谱相乘,再进行逆傅里叶变换得到相位差谱。
最后,根据相位差谱进行图像的配准和拼接。
相位相关法具有高精度和鲁棒性的特点,尤其适用于红外图像和遥感图像等领域。
然而,由于相位相关法对图像噪声和失真敏感,因此在实际应用中需要进行预处理和参数优化。
3. 基于拓扑结构的配准方法基于拓扑结构的配准方法是利用图像的拓扑信息进行图像配准的一种方法。
它通过将图像转换为拓扑图,然后计算图像之间的拓扑结构差异来实现配准。
具体而言,首先使用图像分割算法将图像转换为图,然后利用拓扑学理论计算图的拓扑结构。
最后,根据拓扑结构的差异来进行图像的配准。
基于拓扑结构的配准方法适用于具有复杂几何结构的图像,比如医学图像和地形图像等。
它具有较好的稳定性和准确度,但由于计算复杂度较高,需要考虑算法的效率问题。
全景图像处理中的图像拼接与去畸变技术图像拼接和去畸变是全景图像处理中的两个重要技术,它们能够将多幅图像拼接成一幅无缝的全景图像,并且去除由于摄像机镜头畸变引起的图像形变。
这些技术在虚拟现实、机器视觉和摄影等领域中得到广泛应用。
图像拼接技术是将多个局部图像拼接成一个完整的全景图像。
在图像拼接过程中,主要涉及到特征提取、特征匹配和图像融合等步骤。
首先,特征提取是通过图像中的关键点来描述图像局部特征的过程。
常用的特征提取算法有SIFT (Scale-Invariant Feature Transform)、SURF (Speeded Up Robust Features)和ORB (Oriented FAST and Rotated BRIEF)等。
这些算法通过检测图像中的角点、边缘、纹理等关键点,并计算出其描述子来表示图像的局部特征。
其次,特征匹配是将不同图像中的特征点进行匹配的过程。
特征匹配可以通过计算特征点之间的相似度来找到对应的匹配点对。
常用的特征匹配算法有基于距离的匹配方法,如最近邻匹配和最佳匹配,以及基于几何关系的匹配方法,如RANSAC (Random Sample Consensus)算法。
这些算法能够在多幅图像中找到对应的特征点,并进行匹配,从而建立局部图像之间的对应关系。
最后,图像融合是将匹配的局部图像拼接成一幅无缝的全景图像的过程。
图像融合主要包括图像配准和图像合成两个步骤。
图像配准是将不同图像中的匹配特征点进行坐标变换,使得它们能够在同一坐标系下对齐。
图像合成是将配准后的图像进行融合,常用的图像融合方法有重叠区域的像素平均、像素加权平均和多重保留等方法,以实现无缝的全景图像拼接。
与图像拼接相对应的是图像去畸变技术。
当使用广角或鱼眼镜头拍摄图像时,由于光学畸变的存在,图像中的直线可能会产生弯曲的效果。
去畸变技术旨在通过数学模型和算法来消除光学畸变,以还原图像中的真实场景。
常见的图像去畸变方法包括基于几何模型的方法和基于校正图像的方法。