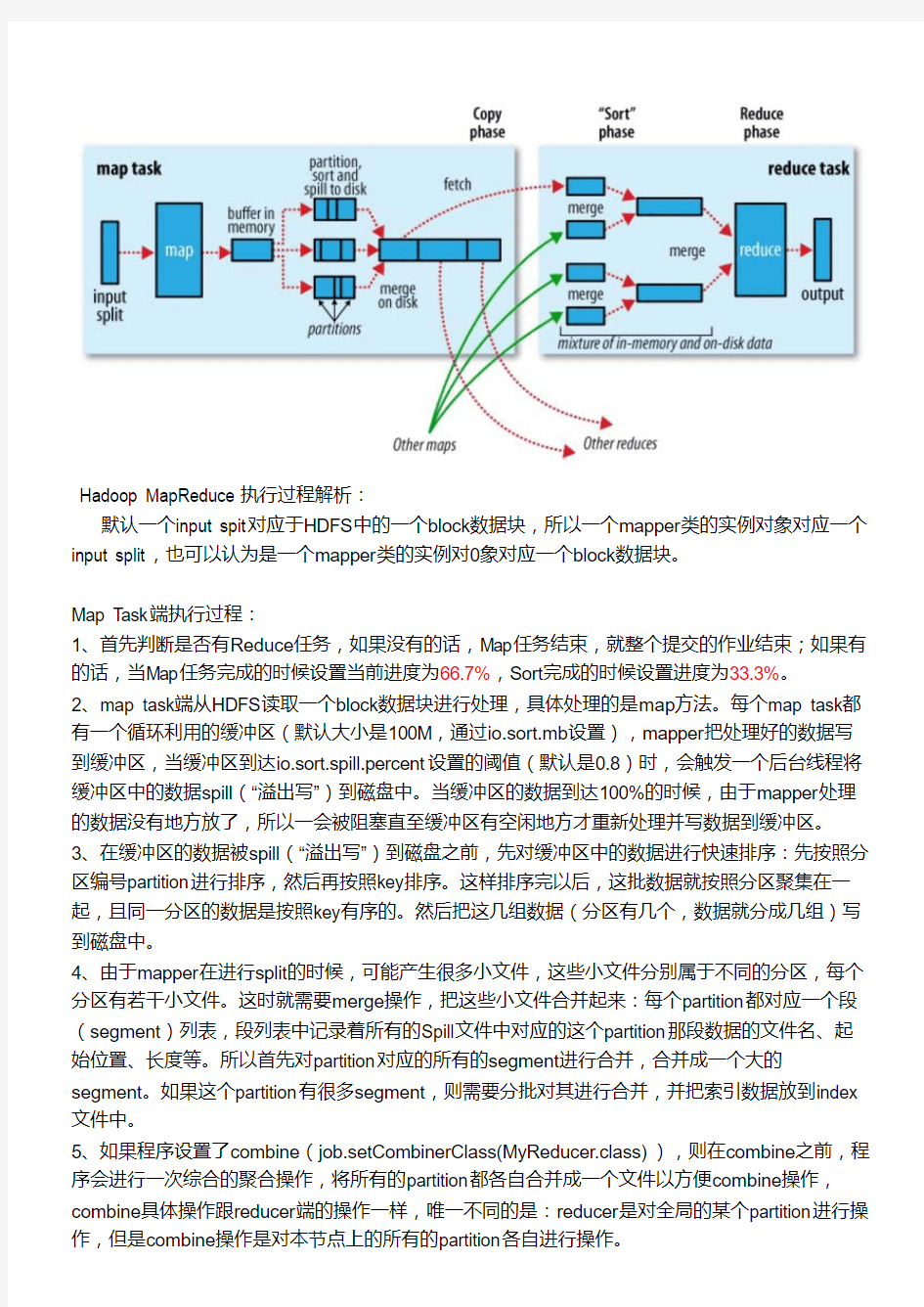

Hadoop MapReduce执行过程解析:
默认一个input spit对应于HDFS中的一个block数据块,所以一个mapper类的实例对象对应一个input split,也可以认为是一个mapper类的实例对0象对应一个block数据块。
Map Task端执行过程:
1、首先判断是否有Reduce任务,如果没有的话,Map任务结束,就整个提交的作业结束;如果有的话,当Map任务完成的时候设置当前进度为66.7%,Sort完成的时候设置进度为33.3%。
2、map task端从HDFS读取一个block数据块进行处理,具体处理的是map方法。每个map task都有一个循环利用的缓冲区(默认大小是100M,通过io.sort.mb设置),mapper把处理好的数据写到缓冲区,当缓冲区到达io.sort.spill.percent设置的阈值(默认是0.8)时,会触发一个后台线程将缓冲区中的数据spill(“溢出写”)到磁盘中。当缓冲区的数据到达100%的时候,由于mapper处理的数据没有地方放了,所以一会被阻塞直至缓冲区有空闲地方才重新处理并写数据到缓冲区。
3、在缓冲区的数据被spill(“溢出写”)到磁盘之前,先对缓冲区中的数据进行快速排序:先按照分区编号partition进行排序,然后再按照key排序。这样排序完以后,这批数据就按照分区聚集在一起,且同一分区的数据是按照key有序的。然后把这几组数据(分区有几个,数据就分成几组)写到磁盘中。
4、由于mapper在进行split的时候,可能产生很多小文件,这些小文件分别属于不同的分区,每个分区有若干小文件。这时就需要merge操作,把这些小文件合并起来:每个partition都对应一个段(segment)列表,段列表中记录着所有的Spill文件中对应的这个partition那段数据的文件名、起始位置、长度等。所以首先对partition对应的所有的segment进行合并,合并成一个大的segment。如果这个partition有很多segment,则需要分批对其进行合并,并把索引数据放到index 文件中。
5、如果程序设置了combine(job.setCombinerClass(MyReducer.class)),则在combine之前,程序会进行一次综合的聚合操作,将所有的partition都各自合并成一个文件以方便combine操作,combine具体操作跟reducer端的操作一样,唯一不同的是:reducer是对全局的某个partition进行操作,但是combine操作是对本节点上的所有的partition各自进行操作。
Reduce Task端执行过程:
1、reducer端主要有三大步骤:复制(copy)、排序(sort)和reducer操作。
2、复制:reducer执行前,先把数据从各个mapper节点中fetch(启动一组fetcher线程组去抓数据)到本节点。如果数据大小超过了一定的阈值(mapreduce.reduce.shuffle.input.buffer.percent默认配置0.9,也是属于溢出写),则把数据写到磁盘中(OnDiskMapOutput实例),否则就存储在内存中(InMemoryMapOutput实例)。在远程copy数据到本地的同时,reducer会启动两个后台线程对已经抓过来的存储在内存和磁盘的数据进行合并,防止内存使用过多和磁盘文件过多。
3、排序:sort操作相当于是map端sort的延续。排序操作会在所有的文件都复制到本地之后开启,使用Merger工具类进行排序(采用归并排序算法)所有的文件。经过排序过程后,会合并成一个大的文件。
4、reducer操作,reducer实例对象读取上述得到的大文件,并进行reduce操作,处理完毕后,将结果写入HDFS中
基于hadoop的大规模文本处理技术实验专业班级:软件1102 学生姓名:张国宇 学号: Setup Hadoop on Ubuntu 11.04 64-bit 提示:前面的putty软件安装省略;直接进入JDK的安装。 1. Install Sun JDK<安装JDK> 由于Sun JDK在ubuntu的软件中心中无法找到,我们必须使用外部的PPA。打开终端并且运行以下命令: sudo add-apt-repository ppa:ferramroberto/java sudo apt-get update sudo apt-get install sun-java6-bin sudo apt-get install sun-java6-jdk Add JAVA_HOME variable<配置环境变量>: 先输入粘贴下面文字: sudo vi /etc/environment 再将下面的文字输入进去:按i键添加,esc键退出,X保存退出;如下图: export JAVA_HOME="/usr/lib/jvm/java-6-sun-1.6.0.26" Test the success of installation in Terminal<在终端测试安装是否成功>: sudo . /etc/environment
java –version 2. Check SSH Setting<检查ssh的设置> ssh localhost 如果出现“connection refused”,你最好重新安装 ssh(如下命令可以安装): sudo apt-get install openssh-server openssh-client 如果你没有通行证ssh到主机,执行下面的命令: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 3. Setup Hadoop<安装hadoop> 安装 apache2 sudo apt-get install apache2 下载hadoop: 1.0.4 解压hadoop所下载的文件包: tar xvfz hadoop-1.0.4.tar.gz 下载最近的一个稳定版本,解压。编辑/ hadoop-env.sh定义java_home “use/library/java-6-sun-1.6.0.26”作为hadoop的根目录: Sudo vi conf/hadoop-env.sh 将以下内容加到文件最后: # The java implementation to use. Required. export JAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26
云凡教育Hadoop网络培训第二期 开课时间:2014年1月20日 授课方式:YY在线教育+课程视频+资料、笔记+辅导+推荐就业 YY教育平台:20483828 课程咨询:1441562932 大胃 云凡教育Hadoop交流群:306770165 费用: 第二期优惠特价:999元; 授课对象: 对大数据领域有求知欲,想成为其中一员的人员 想深入学习hadoop,而不只是只闻其名的人员 基础技能要求: 具有linux操作一般知识(因为hadoop在linux下跑) 有Java基础(因为hadoop是java写的并且编程也要用java语言) 课程特色 1,以企业实际应用为向导,进行知识点的深入浅出讲解; 2,从零起步,循序渐进,剖析每一个知识; 3,萃取出实际开发中最常用、最实用的内容并以深入浅出的方式把难点化于无形之中 学习安排: Hadoop的起源与生态系统介绍(了解什么是大数据;Google的三篇论文;围绕Hadoop形成的一系列的生态系统;各个子项目简要介绍)
1_Linux系统环境搭建和基本命令使用 针对很多同学对linux命令不熟悉,在课程的学习中,由于命令不熟悉导致很多错误产生,所以特意增加一节linux基础课程,讲解一些常用的命令,对接下来的学习中做好入门准备; 02_Hadoop本地(单机)模式和伪分布式模式安装 本节是最基本的课程,属于入门级别,主要对Hadoop 介绍,集中安装模式,如何在linux上面单机(本地)和伪分布模式安装Hadoop,对HDFS 和MapReduce进行测试和初步认识。 03_HDFS的体系结构、Shell操作、Java API使用和应用案例 本节是对hadoop核心之一——HDFS的讲解。HDFS是所有hadoop操作的基础,属于基本的内容。对本节内容的理解直接影响以后所有课程的学习。在本节学习中,我们会讲述hdfs的体系结构,以及使用shell、java不同方式对hdfs 的操作。在工作中,这两种方式都非常常用。学会了本节内容,就可以自己开发网盘应用了。在本节学习中,我们不仅对理论和操作进行讲解,也会讲解hdfs 的源代码,方便部分学员以后对hadoop源码进行修改。 04_MapReduce入门、框架原理、深入学习和相关MR面试题 本节开始对hadoop核心之一——mapreduce的讲解。mapreduce是hadoop 的核心,是以后各种框架运行的基础,这是必须掌握的。在本次讲解中,掌握mapreduce执行的详细过程,以单词计数为例,讲解mapreduce的详细执行过程。还讲解hadoop的序列化机制和数据类型,并使用自定义类型实现电信日志信息的统计。最后,还要讲解hadoop的RPC机制,这是hadoop运行的基础,通过该节学习,我们就可以明白hadoop是怎么明白的了,就不必糊涂了,本节内容特别重要。 05_Hadoop集群安装管理、NameNode安全模式和Hadoop 1.x串讲复习 hadoop就业主要是两个方向:hadoop工程师和hadoop集群管理员。我们课程主要培养工程师。本节内容是面向集群管理员的,主要讲述集群管理的知
https://www.doczj.com/doc/e08192545.html, 大数据培训学习心得体会_光环大数据 来光环大数据学习大数据已经有一段时间了,这段时间感触颇多,下面我就我在大数据培训学习心得体会做个简单的分享。大数据(big data)也成为海量数据、海量资料。在面对海量数据资料时,我们无法透过主流的软件工具在合理的时间内进行管理、处理并整理成为对需求者有价值的信息时,就涉及到了我们现在所学的大数据技术。大数据的特点目前已经从之前的4V升级到了5V,即Volume(大量)、Velocity (速率)、Variety(多样性)、Veracity (真实)、Value(价值)。进一步可以理解为大数据具有数据体量巨大、处理速度快、数据种类繁多、数据来源真实可靠、价值巨大等特性。目前大数据所用的数据记录单位为PB(2的50次方)和EB(2的60次方),甚至到了ZB(2的70次方)。数据正在爆炸式的增长,急需一批大数据人才进行处理、挖掘、分析。大数据的一个重大价值就在于大数据的预测价值。如经济指数预测、经典预测、疾病预测、城市预测、赛事预测、高考预测、电影票房预测等。在光环大数据培训班学习期间,我感受到了光环大数据良好的学习氛围和先进的教学方式。几乎是零基础入学的我,从Java编程开始学起,目前已经进入了大数据的入门课程阶段。光环大数据的课程安排十分合理,不同科目的讲师风格各异,授课方式十分有趣,教学内容都可以轻松记下来。光环大数据还安排了充足的自习时间,让我们充分消化知识点,全程都有讲师、助教陪同,有疑问随时就可以得到解答,让我的学习特别高效。阶段性的测试让我能够充分认识到自己的学习漏洞,讲师也会根据我们测试反映的情况对课程进行调整。光环大数据还专门设置了大数据实验室,我们每天学习时均使用了真实的大数据环境,让我们真正体会到了大数据之美。在光环大数据的大数据学习时间还要持续3个月左右,我会及时分享我在光环大数据的大数据培训学习心得体会,为想要学习大数据的同学提供帮助。 为什么大家选择光环大数据! 大数据培训、人工智能培训、培训、大数据培训机构、大数据培训班、数据
?项目 ?维基 ?Hadoop 0.18文档 Last Published: 07/01/2009 00:38:20 文档 概述 快速入门 集群搭建 HDFS构架设计 HDFS使用指南 HDFS权限指南 HDFS配额管理指南 命令手册 FS Shell使用指南 DistCp使用指南 Map-Reduce教程 Hadoop本地库 Streaming Hadoop Archives Hadoop On Demand API参考 API Changes 维基 常见问题 邮件列表 发行说明 变更日志 PDF Hadoop快速入门 ?目的 ?先决条件 o支持平台 o所需软件 o安装软件 ?下载 ?运行Hadoop集群的准备工作 ?单机模式的操作方法 ?伪分布式模式的操作方法
o配置 o免密码ssh设置 o执行 ?完全分布式模式的操作方法 目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop 分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等。 先决条件 支持平台 ?GNU/Linux是产品开发和运行的平台。 Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证。 ?Win32平台是作为开发平台支持的。由于分布式操作尚未在Win32平台上充分测试,所以还不作为一个生产平台被支持。 所需软件 Linux和Windows所需软件包括: 1.Java TM1.5.x,必须安装,建议选择Sun公司发行的Java版本。 2.ssh必须安装并且保证sshd一直运行,以便用Hadoop 脚本管理远端 Hadoop守护进程。 Windows下的附加软件需求 1.Cygwin - 提供上述软件之外的shell支持。 安装软件 如果你的集群尚未安装所需软件,你得首先安装它们。 以Ubuntu Linux为例: $ sudo apt-get install ssh $ sudo apt-get install rsync
Hadoop云计算实验报告
Hadoop云计算实验报告 1实验目的 在虚拟机Ubuntu上安装Hadoop单机模式和集群; 编写一个用Hadoop处理数据的程序,在单机和集群上运行程序。 2实验环境 虚拟机:VMware 9 操作系统:ubuntu-12.04-server-x64(服务器版),ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop 1.2.1 Jdk版本:jdk-7u80-linux-x64 Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x86_64 Hadoop集群:一台namenode主机master,一台datanode主机salve, master主机IP为10.5.110.223,slave主机IP为10.5.110.207。 3实验设计说明 3.1主要设计思路 在ubuntu操作系统下,安装必要软件和环境搭建,使用eclipse编写程序代码。实现大数据的统计。本次实验是统计软件代理系统操作人员处理的信息量,即每个操作人员出现的次数。程序设计完成后,在集成环境下运行该程序并查看结果。 3.2算法设计 该算法首先将输入文件都包含进来,然后交由map程序处理,map程序将输入读入后切出其中的用户名,并标记它的数目为1,形成
1 系统总体架构 impala在Dremel的启发下开发,不再使用缓慢的Hive+MapReduce批处理,而是通过与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或者HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。 Impala设计目标: ?分布式环境下通用SQL引擎:既支持OLTP也支持OLAP ?SQL查询的规模和粒度:从毫秒级到小时级 ?底层存储依赖HDFS和HBase ?使用更加高效的C++编写 ?SQL的执行引擎借鉴了分布式数据库MPP的思想而不再依赖MapReduce Impala 1.0的特性,完成了所有Hadoop上实现SQL的事项:用以避免网络瓶颈的本地处理、交互式响应、本地数据的单储存池以及可同时对相同数据做不同类型的处理:?支持ANSI-92 SQL所有子集,包括CREATE, ALTER, SELECT, INSERT, JOIN和subqueries ?支持分区join、完全分布式聚合以及完全分布式top-n查询 ?支持多种数据格式:Hadoop原生格式(pache Avro, SequenceFile, RCFile with Snappy, GZIP, BZIP或未压缩)、文本(未压缩或者LZO压缩)和Parquet(Snappy或未压缩) ——最新及最先进的列式存储 ?支持所有CDH4 64位包:Ubuntu、Debian、LES ?可以通过JDBC、ODBC、Hue GUI或者命令行shell进行连接 ?Kerberos认证及MR/Impala资源隔离 上图中,黄色部分谓Impala模块,蓝色部分为运行Impala依赖的其他模块。 从部署上看,Impala整体分为两部分: ?StateStore ?Impalad 其中StateStore是一个集群状态服务进程。在集群中只存在一个实例。Impalad是分布式的存在于集群中的worker进程。每一个Impalad又包含了以下部分:
Hadoop面试题目及答案(附目录) 选择题 1.下面哪个程序负责HDFS 数据存储。 a)NameNode b)Jobtracker c)Datanode d)secondaryNameNode e)tasktracker 答案C datanode 2. HDfS 中的block 默认保存几份? a)3 份b)2 份c)1 份d)不确定 答案A 默认3 份 3.下列哪个程序通常与NameNode 在一个节点启动? a)SecondaryNameNode b)DataNode c)TaskTracker d)Jobtracker 答案D 分析:hadoop 的集群是基于master/slave 模式,namenode 和jobtracker 属于master,datanode 和tasktracker 属于slave,master 只有一个,而slave 有多个SecondaryNameNode 内存需求和NameNode 在一个数量级上,所以通常secondaryNameNode(运行在单独的物理机器上)和NameNode 运行在不同的机器上。 JobTracker 和TaskTracker JobTracker 对应于NameNode,TaskTracker 对应于DataNode,DataNode 和NameNode 是针对数据存放来而言的,JobTracker 和TaskTracker 是对于MapReduce 执行而言的。mapreduce 中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:jobclient,JobTracker 与TaskTracker。 1、JobClient 会在用户端通过JobClient 类将应用已经配置参数打包成jar 文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker 创建每一个Task(即MapTask 和ReduceTask)并将它们分发到各个TaskTracker 服务中去执行。 2、JobTracker 是一个master 服务,软件启动之后JobTracker 接收Job,负责调度Job 的每一个子任务task 运行于TaskTracker 上,并监控它们,如果发现有失败的task 就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。 3、TaskTracker 是运行在多个节点上的slaver 服务。TaskTracker 主动与JobTracker 通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS 的DataNode 上。 4. Hadoop 作者 a)Martin Fowler b)Kent Beck c)Doug cutting 答案C Doug cutting 5. HDFS 默认Block Size a)32MB b)64MB c)128MB 答案:B 6. 下列哪项通常是集群的最主要瓶颈 a)CPU b)网络c)磁盘IO d)内存 答案:C 磁盘 首先集群的目的是为了节省成本,用廉价的pc 机,取代小型机及大型机。小型机和大型机
Hadoop基本操作指令 假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop,默认认为Hadoop环境已经由运维人员配置好直接可以使用 启动与关闭 启动Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/start-all.sh 关闭Hadoop 1. 进入HADOOP_HOME目录。 2. 执行sh bin/stop-all.sh 文件操作 Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。 查看文件列表 查看hdfs中/user/admin/aaron目录下的文件。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -ls /user/admin/aaron 这样,我们就找到了hdfs中/user/admin/aaron目录下的文件了。 我们也可以列出hdfs中/user/admin/aaron目录下的所有文件(包括子目录下的文件)。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -lsr /user/admin/aaron 创建文件目录 查看hdfs中/user/admin/aaron目录下再新建一个叫做newDir的新目录。 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -mkdir /user/admin/aaron/newDir 删除文件 删除hdfs中/user/admin/aaron目录下一个名叫needDelete的文件 1. 进入HADOOP_HOME目录。 2. 执行sh bin/hadoop fs -rm /user/admin/aaron/needDelete 删除hdfs中/user/admin/aaron目录以及该目录下的所有文件
Hadoop云计算平台实验报告V1.1
目录 1实验目标 (3) 2实验原理 (4) 2.1H ADOOP工作原理 (4) 2.2实验设计 (6) 2.2.1可扩展性 (6) 2.2.2稳定性 (7) 2.2.3可靠性 (7) 3实验过程 (9) 3.1实验环境 (9) 3.1.1安装Linux操作系统 (10) 3.1.2安装Java开发环境 (14) 3.1.3安装SSH (15) 3.1.4配置网络 (15) 3.1.5创建SSH密钥安全联机 (19) 3.1.6配置Hadoop云计算系统 (19) 3.1.7配置Slaves节点 (23) 3.1.8格式化Hadoop系统 (23) 3.1.9启动Hadoop集群 (23) 3.22.实验过程 (25) 3.2.1可扩展性 (25) 3.2.1.1动态扩展 (25) 3.2.1.2动态缩减 (27) 3.2.2稳定性 (28) 3.2.3可靠性 (31) 3.2.4MapReduce词频统计测试 (32) 4实验总结 (35)
1. 掌握Hadoop安装过程 2. 理解Hadoop工作原理 3. 测试Hadoop系统的可扩展性 4. 测试Hadoop系统的稳定性 5. 测试Hadoop系统的可靠性
2.1Hadoop工作原理 Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价的硬件设备组成集群上运行应用程序,为应用程序提供一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce 的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算、存储提供了底层支持。 HDFS采用C/S架构,对外部客户机而言,HDFS就像一个传统的分级文件系统。可以对文件执行创建、删除、重命名或者移动等操作。HDFS中有三种角色:客户端、NameNode和DataNode。HDFS的结构示意图见图1。 NameNode是一个中心服务器,存放着文件的元数据信息,它负责管理文件系统的名字空间以及客户端对文件的访问。DataNode节点负责管理它所在节点上的存储。NameNode对外暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,文件被分成一个或多个数据块,这些块存储在一组DataNode上,HDFS通过块的划分降低了文件存储的粒度,通过多副本技术和数据校验技术提高了数据的高可靠性。NameNode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体DataNode节点的映射。DataNode负责存放数据块和处理文件系统客户端的读写请求。在NameNode的统一调度下进行数据块的创建、删除和复制。
HBase学习报告 0 引言 随着互联网的发展,用户的使用量和使用范围变得越来越广,因此会产生大量的数据,对于这些数据的储存、处理,传统的数据库表现出越来越多的问题,从目前发展情况看,关系数据库已经不适应这种巨大的存储量和计算要求,查询效率随着数据量的增长变得越来越低。面对这些问题,一些新型的数据库应运而生,对海量数据的存储和处理提出了解决方案,HBase就是其中之一。 1 HBase简介 Hbase是Apache Hadoop的数据库,能够对大数据提供随机、实时的读写访问,具有开源、分布式、可扩展及面向列存储的特点。HBase的目标是处理大型的数据,具体来说就是使用普通的硬件配置即可处理成千上万行的列和行组成的大数据。 HBase是一个分布式的,多版本的,面向列的存储模型。它可以使用本地文件系统。也可以使用HDFS文件存储系统,但是,为了提高系统的健壮性和可靠性,并充分发挥HBase的大数据处理能力,使用HDFS作为文件存储系统更合适,使用MapReduce来处理海量数据,利用Zookeeper作为协同服务。 另外,HBase的存储结构是松散性数据,它使用简单的key和value的映射关系,但又不是简单的映射关系,这种关系为超大规模的高并发的海量数据实时响应系统提供了一个很好的解决方案。HBase的存储的数据从逻辑上来看就像是一张很大的表,并且,它的数据可以根据需求动态地增加。HBase还具有这样的特点:它向下提供了存储,向上提供了运算。这样的特点使它将数据存储和并行计算完美地结合在了一起。 2 HBase体系结构 HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion服务器群和HBase Master服务器构成。HBase Master服务器负责管理所有的HRegion服务器,而HBase中的所有服务器都是通过ZooKeeper来进行协调并处理HBase服务器运行期间可能遇到的错误。HBase Master本身并不储存HBase中的任何数据。HBase Master服务器中存储的是从数据到HRegion服务器的映射。 2.1 HRegion服务器 所有的数据库数据一般都是保存在HaDoop的分布式文件系统上,用户通过一系列的HRegion服务器获取这些数据。HRegion服务器包含两大部分:HLOG部分和HRegion部分。其中HLOG用来粗存数据日志,采取的是预写日志的方式。HRegion部分由很多的HRegion 组成,用来存储实际数据。每一个HRegion又由很多Store组成,每一个Store存储一个列
《Hadoop集群程序设计与开发》教学 大纲 课程名称:Hadoop集群程序设计与开发 课程类别:必修 适用专业:大数据技术类相关专业 总学时:64学时 总学分:4.0学分 一、课程的性质 本课程是为大数据技术类相关专业学生开设的课程。大数据技术蓬勃发展,基于开源技术的Hadoop在行业中应用广泛。Hadoop开源免费、社区活跃,框架具备分布式存储和计算的核心功能,并且有企业成功的案例(如如淘宝、百度等)。本课程首先通过企业项目发展历程介绍了大数据与云计算的概念并将Hadoop在这二个领域中的作用与地位进行阐述。通过Hadoop源码片断与理论及实操结合的模式介绍Hadoop分布式存储框架HDFS与分布式计算框架MapReduce的用法。对于HDFS不能很好支持小条目读取的缺陷,引入HBase 框架进行应用说明。对于MapReduce框架对于项目专业人员的技能要求门槛高,复杂业务开发周期较长的问题引入了Hive框架进行应用说明。Hadoop与HBase和Hive结合进行项目中大数据的存取与统计计算在企业中的运用越来越广泛,学习Hadoop框架已然是进入大数据行业所必不可少的一步。 二、课程的任务 通过本课程的学习,使学生对Hadoop框架有一个全面的理解,课程内容主要包括了Hadoop基本原理与架构、集群安装配置、HDFS应用、HDFS I/O操作、MapReduce工作原理与应用编程、HBase基本应用、Hive基本应用,关键知识点配置Hadoop源码片断和实操案例进行辅助。涉及的知识点简要精到,实践操作性强。
三、教学内容及学时安排
四、考核方式 突出学生解决实际问题的能力,加强过程性考核。课程考核的成绩构成= 出勤(10%)+ 平时作业与课堂练习(30%)+ 课程设计(60%)。 五、教材与参考资料
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。 搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助 jackrabbit封装hadoop的设计与实现 https://www.doczj.com/doc/e08192545.html,/thread-60444-1-1.html 用Hadoop进行分布式数据处理 https://www.doczj.com/doc/e08192545.html,/thread-60447-1-1.html
Hadoop源代码eclipse编译教程 https://www.doczj.com/doc/e08192545.html,/thread-60448-1-2.html Hadoop技术讲解 https://www.doczj.com/doc/e08192545.html,/thread-60449-1-2.html Hadoop权威指南(原版) https://www.doczj.com/doc/e08192545.html,/thread-60450-1-2.html Hadoop源代码分析完整版 https://www.doczj.com/doc/e08192545.html,/thread-60451-1-2.html 基于Hadoop的Map_Reduce框架研究报告 https://www.doczj.com/doc/e08192545.html,/thread-60452-1-2.html Hadoop任务调度 https://www.doczj.com/doc/e08192545.html,/thread-60453-1-2.html Hadoop使用常见问题以及解决方法 https://www.doczj.com/doc/e08192545.html,/thread-60454-1-2.html HBase:权威指南
Hadoop 在Hadoop上运行MapReduce命令 实验jar:WordCount.jar 运行代码:root/……/hadoop/bin/hadoop jar jar包名称使用的包名称input(输入地址) output(输出地址) 生成测试文件:echo -e "aa\tbb \tcc\nbb\tcc\tdd" > ceshi.txt 输入地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input 输出地址:/data2/u_lx_data/qiandongjun/eclipse/crjworkspace/output 将测试文件转入输入文件夹:Hadoop fs -put ceshi.txt /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt 运行如下代码:hadoop jar /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/WordCount.jar WordCount /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/input/ceshi.txt /data2/u_lx_data/qiandongjun/eclipse/crjworkspace/output Hadoop架构 1、HDFS架构 2、MapReduce架构 HDFS架构(采用了Master/Slave 架构) 1、Client --- 文件系统接口,给用户调用 2、NameNode --- 管理HDFS的目录树和相关的的文件元数据信息以及监控DataNode的状 态。信息以“fsimage”及“editlog”两个文件形势存放 3、DataNode --- 负责实际的数据存储,并将数据定期汇报给NameNode。每个节点上都 安装一个DataNode 4、Secondary NameNode --- 定期合并fsimage和edits日志,并传输给NameNode (存储基本单位为block) MapReduce架构(采用了Master/Slave 架构) 1、Client --- 提交MapReduce 程序并可查看作业运行状态 2、JobTracker --- 资源监控和作业调度 3、TaskTracker --- 向JobTracker汇报作业运行情况和资源使用情况(周期性),并同时接 收命令执行操作 4、Task --- (1)Map Task (2)Reduce Task ——均有TaskTracker启动 MapReduce处理单位为split,是一个逻辑概念 split的多少决定了Map Task的数目,每个split交由一个Map Task处理 Hadoop MapReduce作业流程及生命周期 一共5个步骤 1、作业提交及初始化。JobClient将作业相关上传到HDFS上,然后通过RPC通知JobTracker,
启动Hadoop ?进入HADOOP_HOME目录。 ?执行sh bin/start-all.sh 关闭Hadoop ?进入HADOOP_HOME目录。 ?执行sh bin/stop-all.sh 1、查看指定目录下内容 hadoopdfs –ls [文件目录] eg: hadoopdfs –ls /user/wangkai.pt 2、打开某个已存在文件 hadoopdfs –cat [file_path] eg:hadoopdfs -cat /user/wangkai.pt/data.txt 3、将本地文件存储至hadoop hadoopfs –put [本地地址] [hadoop目录] hadoopfs –put /home/t/file.txt /user/t (file.txt是文件名) 4、将本地文件夹存储至hadoop hadoopfs –put [本地目录] [hadoop目录] hadoopfs –put /home/t/dir_name /user/t (dir_name是文件夹名) 5、将hadoop上某个文件down至本地已有目录下hadoopfs -get [文件目录] [本地目录] hadoopfs –get /user/t/ok.txt /home/t 6、删除hadoop上指定文件 hadoopfs –rm [文件地址] hadoopfs –rm /user/t/ok.txt 7、删除hadoop上指定文件夹(包含子目录等)hadoopfs –rm [目录地址] hadoopfs –rmr /user/t
8、在hadoop指定目录内创建新目录 hadoopfs –mkdir /user/t 9、在hadoop指定目录下新建一个空文件 使用touchz命令: hadoop fs -touchz /user/new.txt 10、将hadoop上某个文件重命名 使用mv命令: hadoop fs –mv /user/test.txt /user/ok.txt (将test.txt重命名为ok.txt) 11、将hadoop指定目录下所有内容保存为一个文件,同时down至本地hadoopdfs –getmerge /user /home/t 12、将正在运行的hadoop作业kill掉 hadoop job –kill [job-id] 1、列出所有Hadoop Shell支持的命令 $ bin/hadoopfs -help 2、显示关于某个命令的详细信息 $ bin/hadoopfs -help command-name 3、用户可使用以下命令在指定路径下查看历史日志汇总 $ bin/hadoop job -history output-dir 这条命令会显示作业的细节信息,失败和终止的任务细节。 4、关于作业的更多细节,比如成功的任务,以及对每个任务的所做的尝试次数等可以用下面的命令查看 $ bin/hadoop job -history all output-dir 5、格式化一个新的分布式文件系统: $ bin/hadoopnamenode -format 6、在分配的NameNode上,运行下面的命令启动HDFS: $ bin/start-dfs.sh bin/start-dfs.sh脚本会参照NameNode上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动DataNode守护进程。 7、在分配的JobTracker上,运行下面的命令启动Map/Reduce: $ bin/start-mapred.sh bin/start-mapred.sh脚本会参照JobTracker上${HADOOP_CONF_DIR}/slaves文件的内容,在所有列出的slave上启动TaskTracker守护进程。 8、在分配的NameNode上,执行下面的命令停止HDFS: $ bin/stop-dfs.sh
期末实践报告 题目:Linux集群、MapReduce和 CloudSim实践 成绩: 学号:161440119 姓名:罗滔 登录邮箱:750785185@https://www.doczj.com/doc/e08192545.html, 任课老师:许娟 2016年11月12日 目录 实验一:AWS身份与访问管理(P2~P11)实验二:Amazon Relational Database Service(P11~P20) 实验三:Hadoop实验报告(P21~)
AWS 管理控制台 使用 qwikLABS 登录 AWS 管理控制台 6. 在 AWS 管理控制台中,单击【服务/Services】,然后单击【IAM 或身份与访问管理/ IAM or Identity & Access Management】。 7. 在 IAM 控制台的左侧面板中,单击【用户/Users】。
8. 找到“userone”,然后单击其名称以显示有关该用户的详细信息。在用户详细信息中,找到有关该用户的以下三方面的信息: a. 已向该用户分配了一个密码 b. 该用户不属于任何组 c. 目前没有任何策略与该用户关联(“附加到”该用户)
9. 现在,单击左侧导航窗格中的【组/Groups】。 本实验的 CloudFormation 模板还创建了三个组。在 IAM 控制台中的【用户/Users】仪表板中可以看到, 自动化 CloudFormation 脚本在创建这些组时为其提供了唯一的名称。这些唯一名称包含以下字符串: “EC2support” “EC2admin” “S3admin” 完整组名的格式如下所示: arn:aws:iam::596123517671:group/spl66/qlstack2--labinstance--47090--666286a4--f8c--EC2support--GA9LGREA 7X4S 从现在开始,我们在本实验中将使用上面这些简写名称来指代这些组。您可以在【组/Groups】仪表板中搜 索子字符串,以便为后续实验操作确定正确的组。 10. 单击“EC2support”对应的组名。其格式应与上面的类似。 11. 向下滚动至组详细信息页面中的【权限/Permissions】部分后,在【内联策略/Inline Policies】部分, 可以看到一个名称为“EC2supportpolicy”的策略与该组关联。 在策略中,您可以规定将允许或拒绝对特定 AWS 资源执行哪些操作。您可以使用自定义策略,或通过 选择 AWS 托管策略来使用一组预定义的权限。 12. 虽然我们不会更改此策略,但请单击【编辑策略/Edit Policy】,使其显示在一个窗口中,以便您进行查 看和滚动。 请留意 IAM 策略中语句的基本结构。“Action”部分指定了该服务内的 AWS 服务和功能。“Resource”部 分定义了该策略规则所涵盖的实体范围,而“Effect”部分则定义了所需结果。更多有关定义 IAM 策略的 信息,请访问“AWS Identity and Access Management:权限和策略”文档页面。
学习《云计算》心得体会 说实话,刚接触这门课,我对《云计算》的认识比较狭隘,只是知道它是一种商业服务计算技术和存储技术,对其他不甚了解。但是通过十几周的不断深入学习,我从跟班上改变对《云计算》的认识。可能作为一名非计算机网络专业学员,我还没有能力在短短十几周内学会弄懂教员所传授的Vmware云计算和Hadoop使用,并进行编程计算。但是我深刻认识到这不仅是一门高科技技术知识课程,更是我军在未来军事战场上的杀手锏。 一、云计算的正确理解。 通过学习,我知道云计算是在2007年诞生的新词。虽然它产生的较晚。但并不能掩盖它的火热程度。仅仅过了半年多,受到关注程度就超过网格计算,而且关注度至今一直高居不下。 云计算普遍认为是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使用能够按需获取计算存储空间和信息服务。 这里所说的“云”不是我们通常所理解的云。它
是一些可以自我维护和管理的虚拟计算资源。通常是一些大型服务器集群,包括计算服务器、存储服务器和宽带资源等。 从研究现状上看,云计算有以下特点。 1、超大规模。“云”具有相当的规模。它需要有几十万台服务器同时工作。因此它能赋予用户前所未有的计算能力。 2、虚拟化。云计算支持用户在任意位置使用各种终端获取服务。随着我国信息技术产业突飞猛进,3G 技术不断发展,越来越多人通过各种通信电子产品使用云计算服务。例如我们平时使用3G手机上网淘宝或用云存储将自己手机上的资源备份到网盘上等等。 3、高可靠性。“云”使用了数据多副本容错。计算节点同构可互换等措施来保障服务的高可靠性,使用云计算比使用本地计算机更加可靠。 4、通用性。云计算不针对特定的应用。云计算应用非常广泛,可以涵盖整个网络计算,它并不拘泥于某一项功能而是围绕3G、4G等新型高速运算网络展开的多功能多领域的应用。 5、高可伸缩性。“云”的规模可以动态伸缩。这一点与传统固态存储有本质区别。因为传统存储介质有存储容量限制而“云计算”它的边界是模糊的。它
实验报告 课程名称虚拟化与云计算学院计算机学院 专业班级11级网络工程3班学号3211006414 姓名李彩燕 指导教师孙为军 2014 年12 月03日
EXSI 5.1.0安装 安装准备 安装VSPHERE HYPERVISOR SEVER(EXSI 5.1.0)需要准备: 无操作系统的机器(如有系统,安装过程中会格式化掉),需切换到光盘启动模式。BOIS中开启虚拟化设置(virtualization设置成enable) VMware vSphere Hypervisor 自启动盘 安装过程 1.安装VMware vSphere Hypervisor确保机器中无操作系统,并且设置BIOS到光盘启 动模式 2.插入光盘,引导进入安装界面。 3.选择需要安装在硬盘 4.选择keyboard 类型,默认US DEFAULT
5.设置ROOT的密码 6.安装完毕后,请注意弹出光盘。然后重启。 7.F2进入系统配置界面。
8.选择到Configure management network去配置网络。
9.配置完毕后,注意重启网络以使设置生效,点击restart management network,测 试网络设置是否正确,点test management network。至此,sever端安装完毕。配置 1.添加机器名:在DNS服务器上添加相关正反解析设置。 2.License设置:Vsphere client登陆后,清单→配置→已获许可的功能→编辑 输入license
3.时间与NTP服务设置:Vsphere client登陆后,清单→配置→时间配置→属性 钩选上NTP客户端 选项中,NTP设置设添加NTP服务器,然后在常规中开启NTP服务