pentaho介绍
- 格式:doc
- 大小:74.50 KB
- 文档页数:15

kettle 年月日变量理论说明1. 引言1.1 概述Kettle是一款开源的ETL工具,用于处理数据抽取、转换和加载的任务。
其中,年月日变量在Kettle中扮演着重要的角色。
本文将详细介绍Kettle年月日变量的理论说明,并探讨其在实际应用中的作用与应用场景。
1.2 文章结构本文共分为五个部分。
首先是引言部分,对整篇文章进行概述和背景介绍。
接下来是Kettle年月日变量的理论说明,包括Kettle介绍、变量概念与用途以及年月日变量的作用与应用场景。
第三部分将详细介绍使用Kettle年月日变量的步骤与方法,包括设置变量的格式和值,在转换中使用年月日变量以及在作业中使用年月日变量。
第四部分将列举常见问题并提供解决方案,涉及变量设置错误导致运行失败、年月日变量不生效以及动态日期需求处理等情况。
最后,结论部分总结了年月日变量在Kettle中的重要性与优势,并展望了未来Kettle发展趋势。
1.3 目的本文旨在深入理解Kettle年月日变量的概念与原理,帮助读者正确地使用和应用这一功能。
通过详细的步骤和实例,读者将能够更好地掌握在Kettle中使用年月日变量的技巧。
此外,通过解答常见问题并提供相应的解决方案,本文还旨在帮助读者避免在使用年月日变量过程中可能遇到的问题,并能够更加灵活地应对动态日期需求。
最后,本文还将展望未来Kettle发展趋势,为读者提供对该工具发展方向的参考和思考。
2. Kettle 年月日变量理论说明2.1 Kettle介绍Kettle,又称为Pentaho Data Integration,是一种强大的开源数据整合工具。
它可以帮助用户提取、转换和加载(ETL)数据,并将其存储到目标系统中。
Kettle 具有灵活的功能和丰富的插件集合,使其成为各种数据处理任务的理想选择。
2.2 变量概念与用途在Kettle中,变量是一种可用于存储和传递值的机制。
它们可以存储任何类型的数据,如字符串、数字或日期。

pentaho data integration中文文档概述及范文模板1. 引言1.1 概述Pentaho Data Integration是一种基于Java的开源ETL(抽取、转换和加载)工具,它提供了一个强大且灵活的平台,用于管理、处理和转换各种类型和规模的数据。
通过可视化设计界面和丰富的功能组件,Pentaho Data Integration可以帮助用户轻松地实现数据集成、数据清洗、数据加载等任务,使得企业能够更加高效地利用数据。
1.2 文章结构本文将以“pentaho data integration中文文档概述及范文模板”为主题,对Pentaho Data Integration中文文档进行全面介绍。
文章内容将包括引言、Pentaho Data Integration简介、Pentaho Data Integration中文文档概述以及Pentaho Data Integration中文文档范文模板等几个部分。
通过阅读本篇文章,读者将能够了解到Pentaho Data Integration工具的基本概念和特点,并且获得一个详细而系统的中文参考手册编写模板。
1.3 目的本文的目的是为读者提供关于Pentaho Data Integration中文文档概述和范文模板的详尽介绍。
首先,我们将简要介绍Pentaho Data Integration工具的定义和功能特点,帮助读者了解该工具的基本原理和使用场景。
接下来,我们将详细描述Pentaho Data Integration中文文档的内容和范围,并指导读者如何编写一篇规范而有序的参考手册。
最后,在结论部分,我们将对全文进行总结,并提出一些建议,以进一步改进Pentaho Data Integration中文文档的质量和实用性。
通过阅读本文,读者将能够更好地理解和应用Pentaho Data Integration工具,同时也能够为其他用户撰写高质量的中文文档提供参考和指导。
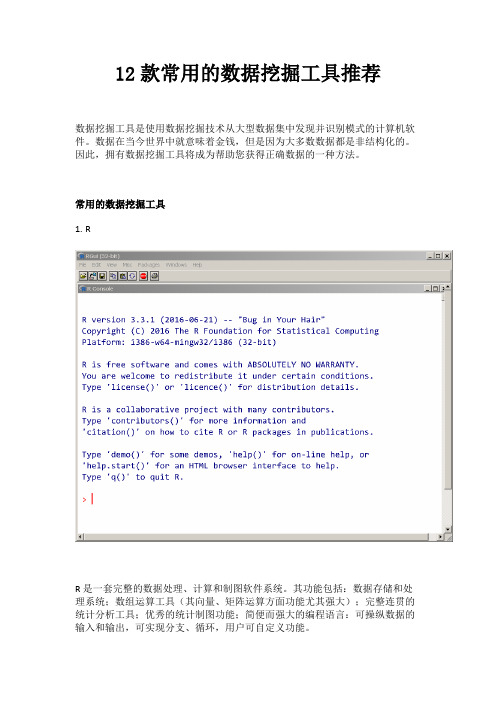
12款常用的数据挖掘工具推荐数据挖掘工具是使用数据挖掘技术从大型数据集中发现并识别模式的计算机软件。
数据在当今世界中就意味着金钱,但是因为大多数数据都是非结构化的。
因此,拥有数据挖掘工具将成为帮助您获得正确数据的一种方法。
常用的数据挖掘工具1.RR是一套完整的数据处理、计算和制图软件系统。
其功能包括:数据存储和处理系统;数组运算工具(其向量、矩阵运算方面功能尤其强大);完整连贯的统计分析工具;优秀的统计制图功能;简便而强大的编程语言:可操纵数据的输入和输出,可实现分支、循环,用户可自定义功能。
2.Oracle数据挖掘(ODM)Oracle Data Mining是Oracle的一个数据挖掘软件。
Oracle数据挖掘是在Oracle 数据库内核中实现的,挖掘模型是第一类数据库对象。
Oracle数据挖掘流程使用Oracle 数据库的内置功能来最大限度地提高可伸缩性并有效利用系统资源。
3.TableauTableau提供了一系列专注于商业智能的交互式数据可视化产品。
Tableau允许通过将数据转化为视觉上吸引人的交互式可视化(称为仪表板)来实现数据的洞察与分析。
这个过程只需要几秒或几分钟,并且通过使用易于使用的拖放界面来实现。
5. ScrapyScrapy,Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
6、WekaWeka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。
Weka高级用户可以通过Java编程和命令行来调用其分析组件。
同时,Weka也为普通用户提供了图形化界面,称为Weka KnowledgeFlow Environment和Weka Explorer。
和R相比,Weka在统计分析方面较弱,但在机器学习方面要强得多。

pentaho report designer 生成excel报表-概述说明以及解释1.引言1.1 概述文章概述部分的内容可以从以下角度进行描述:概述:随着大数据时代的到来,数据分析和报表生成变得越来越重要。
而Excel报表作为业务人员最熟悉和普遍使用的工具之一,在企业中扮演着至关重要的角色。
然而,传统的Excel报表生成方式存在一些问题,如手动操作繁琐、容易出错,不便于数据更新和共享等。
为了解决这些问题,人们开始寻找更高效、自动化的Excel报表生成工具。
本文将重点介绍Pentaho Report Designer,一个强大的报表设计工具,可以帮助用户快速、灵活地生成Excel报表。
Pentaho Report Designer具有丰富的功能和友好的界面,不仅支持多种数据源的连接和查询,还提供了多种报表设计元素和样式,能够满足不同的报表需求。
文章结构:本文包括引言、正文和结论三个部分。
引言部分将对Pentaho Report Designer生成Excel报表的重要性和现实需求进行概述,介绍文章的结构和目的。
正文部分将详细介绍Pentaho Report Designer的功能和特点,并重点介绍了生成Excel报表的具体步骤。
结论部分将总结Pentaho Report Designer生成Excel报表的优势和挑战,并展望未来其发展的方向。
目的:本文的目的是帮助读者了解Pentaho Report Designer生成Excel 报表的基本原理和操作步骤,同时探讨其在实际应用中的优势和挑战。
通过阅读本文,读者可以加深对Pentaho Report Designer的了解,并在实际工作中更加高效地生成Excel报表。
希望本文能为读者提供有价值的信息和启示,促进Excel报表生成工作的改进和提升。
1.2文章结构文章结构部分将介绍本文的组织结构和各个章节的主要内容概要。
本文的文章结构如下:1. 引言- 1.1 概述:介绍Pentaho Report Designer生成Excel报表的背景和意义。

Pentaho工具使用手册目录BI 介绍 (2)Pentaho产品介绍 (2)Pentaho产品线设计 (3)Pentaho BI Platform安装 (4)Pentaho Data Integration-------Kettle (8)Pentaho Report Designer (13)Saiku (24)Schema Workbench (28)附件 (33)BI 介绍1. BI基础介绍挖掘技术对客户数据进行系统地储存和管理,并通过各种数据统计分析工具对客户数据进行分析,提供各种分析报告,为企业的各种经营活动提供决策信息。
其中的关键点是数据管理,数据分析,支持决策。
根据要解决问题的不同,BI系统的产出一般包括以下三种:2. BI系统的产出2.1 固定格式报表固定格式报表是BI最基本的一种应用,其目的是展示当前业务系统的运行状态。
固定格式报表一旦建立,用户就不可以更改报表的结构,只能依据数据库的数据不断刷新报表,以便取得较新的数据。
在pentaho产品线中,我们使用pentaho report designer来实现固定格式报表的需求。
2.2 OLAP分析OLAP分析是指创建一种动态的报表展示结构,用户可以在一个IT预定义的数据集中自由选择自己感兴趣的特性和指标,运用钻取,行列转换等分析手段实现得到知识,或者验证假设的目的。
在pentaho产品线中,我们使用Saiku来实现OLAP分析的需求。
2.3 数据挖掘数据挖掘是BI的一种高级应用。
数据挖掘是指从海量数据中通过数据挖掘技术得到有用的知识,并且以通俗易懂的方式表达知识,以便支持业务决策。
在pentaho产品线中,我们使用weka来实现数据挖掘的需求。
Pentaho产品介绍1. 产品介绍Pentaho是世界上最流行的开源商业智能软件,以工作流为核心的、强调面向解决方案而非工具组件的BI套件,整合了多个开源项目,目标是和商业BI相抗衡。

kettle 字段名变量-概述说明以及解释1.引言1.1 概述概述部分的内容可以写作如下:引言部分在现代数据处理和数据转换的领域中,Kettle(也称为Pentaho Data Integration)扮演着一个关键的角色。
Kettle是一种开源的ETL(抽取、转换和加载)工具,广泛应用于数据仓库、数据集成和数据转换等领域。
它提供了一种灵活、可扩展的方法来处理各种复杂的数据转换任务,并具备强大的数据处理能力。
在进行数据转换的过程中,Kettle使用字段名(Variables)来表示数据的属性或特征。
字段名充当了连接源数据和目标数据之间的桥梁,它们在Kettle中起到了至关重要的作用。
每个字段名都代表了源数据中的一个数据列,它们包含了关键的信息,如数据类型、长度、精度等等。
本文将重点探讨Kettle字段名在数据转换中的作用和定义。
我们将分析字段名的重要性,并展望其未来的发展趋势。
通过深入理解Kettle字段名,我们将能够更好地应用Kettle工具,提高数据转换和数据处理的效率。
接下来的章节将对Kettle的定义和功能进行介绍,并详细讨论Kettle 字段名的作用和定义。
通过对这些内容的探索,我们将能够更好地理解和应用Kettle工具,从而更好地满足不同场景下的数据处理需求。
1.2文章结构文章结构部分的内容应该是对整篇文章的组织结构进行介绍和说明。
可以从以下几个方面进行阐述:首先,介绍文章的整体框架和章节划分。
说明文章采用的大纲结构以及每个章节的主题和内容。
其次,说明每个章节的主要目的和内容。
简要介绍每个章节的主题和要点,让读者对整篇文章的内容有一个整体的把握。
接着,说明各个章节之间的衔接和关联。
指出每个章节之间的逻辑关系和衔接点,使读者能够理解各个章节之间的连贯性和一脉相承的思路。
最后,提醒读者如何通过文章的结构来理解和掌握文章内容。
可以提醒读者在阅读文章时关注每个章节的主题句和段落结构,以及章节之间的过渡和回顾,从而更好地掌握文章的逻辑和要点。

Pentaho Data Integration中的Carte介绍Pentaho Data Integration(PDI)是一款功能强大的ETL(Extract, Transform, Load)工具,用于数据集成和转换。
在PDI中,Carte是一个用于分布式执行作业和转换的服务器。
Carte服务器可以通过网络接受来自PDI客户端的请求,并将作业和转换分发给可用的节点进行执行。
它提供了一种灵活且可扩展的方式来处理大量数据处理任务。
本文将深入探讨Pentaho Data Integration中的Carte服务器,包括其功能、使用方法以及优势。
功能1. 分布式执行Carte服务器允许将作业和转换分发到多个节点上并行执行。
这种分布式执行可以极大地提高数据处理的效率和并发性能。
2. 负载均衡通过使用多个Carte节点,可以实现负载均衡。
当有多个作业或转换需要执行时,Carte服务器会根据系统负载情况自动将任务分配给可用节点,从而确保每个节点都能够均衡地处理任务负载。
3. 监控与管理Carte服务器提供了一个Web界面,可用于监控和管理正在运行的作业和转换。
通过该界面,用户可以实时查看任务的状态、日志信息以及性能指标,从而更好地了解任务的执行情况并进行必要的调整和优化。
4. 安全性Carte服务器支持基于角色的访问控制,可以对不同用户或用户组进行权限管理。
这样可以确保只有授权用户才能访问和执行作业和转换,提高数据安全性。
5. 可扩展性Carte服务器可以根据需求进行水平扩展。
通过添加更多的节点,可以增加系统的处理能力和容量,以满足不断增长的数据处理需求。
使用方法使用Carte服务器需要以下步骤:1. 配置Carte节点在PDI中配置Carte节点非常简单。
首先,在PDI安装目录下找到carte-config.xml文件,并编辑该文件。
在文件中,您需要配置以下信息:•监听地址和端口:指定Carte服务器监听的地址和端口号。

Pentaho数据集成工具的使用方法Pentaho是一款流行的开源商业智能(BI)和数据集成软件。
它被广泛应用于各种领域,如金融、医疗保健、制造业和零售业等。
有关Pentaho的许多功能和优点在其他文章中已经详细涉及,因此本文将专注于介绍Pentaho数据集成工具的使用方法。
Pentaho数据集成工具是一个可视化、易用的ETL(抽取、转化和加载)工具,是Pentaho开源商业智能软件套装中的一个子组件。
它可以将来自各种来源的数据整合到一个地方,如关系数据库、Web服务、本地或远程文件等。
通过使用Pentaho数据集成工具,您可以轻松地将数据从一个位置移动到另一个位置、将数据转换为不同的格式等等。
下面,我们将重点介绍一些使用Pentaho数据集成工具的技巧和步骤。
1. 连接数据源在使用Pentaho数据集成工具之前,您需要先连接到数据源。
Pentaho可以连接到多种数据源,如Oracle、MySQL、SQL Server 等。
要建立一个新的数据源连接,您需要使用菜单栏上的“文件”-> “新建”->“数据库连接”选项。
该选项将打开一个数据库连接向导,帮助您指定数据库类型、服务器名称、数据库名称、用户名等信息。
2. 设计转换转换是将数据从一个地方移动到另一个地方的过程,可以通过Pentaho数据集成工具的可视化设计工具完成。
首先从工具箱中选择一个或多个输入步骤,然后连接到一个或多个转换步骤,最后连接到一个或多个输出步骤。
每个步骤都有一些参数,如输入文件、输出文件、转换步骤等。
3. 添加输入步骤Pentaho数据集成工具有多种数据输入步骤,如文本文件、Excel文件和数据库等。
要添加一个输入步骤,您需要从工具箱中选择一个步骤,然后将其拖动到转换设计区域。
接下来,您需要指定输入文件的位置、格式和其他相关信息。
4. 添加转换步骤转换步骤是将输入数据转换为输出数据的过程。
Pentaho数据集成工具提供了多个转换步骤,如过滤器、排序器和连接器等。

简介Pentaho Kettle,又称为Pentaho Data Integration,是一种开源的ETL (Extract, Transform, Load)工具,用于处理和转换数据。
它提供了强大而灵活的功能,帮助用户从各种数据源中提取数据,进行数据清理和转换,最后将数据加载到目标系统中。
本文将介绍Pentaho Kettle的主要特性、使用场景和解决方案。
特性Pentaho Kettle具有以下重要特性:1.数据提取:Pentaho Kettle可以从多种数据源中提取数据,包括关系型数据库、文件(如CSV、Excel等)、Web服务等。
它支持各种数据提取方法,如轮询、增量更新等。
2.数据清洗和转换:Pentaho Kettle提供了一系列强大的数据清洗和转换功能,包括数据过滤、字段重命名、数据类型转换、数据合并、排序等。
用户可以通过可视化界面轻松定义数据清洗和转换规则。
3.数据加载:Pentaho Kettle支持将处理后的数据加载到各种目标系统中,包括关系型数据库、数据仓库、Hadoop集群等。
它提供了各种加载方法,如批量加载、增量加载等。
4.数据集成与流程调度:Pentaho Kettle允许用户将多个数据处理和转换步骤组合成一个完整的数据集成流程,并支持定时执行和调度。
用户可以定义流程依赖关系和触发器,实现数据流程的自动化处理。
5.可扩展性和定制性:Pentaho Kettle基于插件架构,用户可以通过添加自定义插件来扩展功能。
它还提供了丰富的API和开发工具,使得用户可以根据自己的需求进行定制开发。
使用场景Pentaho Kettle适用于各种数据处理和转换场景,包括:1.数据仓库:Pentaho Kettle可以将来自多个数据源的数据加载到数据仓库中,进行数据清洗、转换和组合。
它支持事务控制和异常处理,确保数据的完整性和一致性。
2.业务智能分析:Pentaho Kettle可以将多个数据源中的数据整合到一起,用于业务智能分析和报表生成。

kettle 循环遍历结果集作为参数传入转换在数据处理和ETL(Extract, Transform, Load)的领域中,Kettle是一款非常强大的开源工具。
它可以帮助我们轻松地完成数据抽取、转换和加载的任务。
其中一个非常有用的功能是使用循环遍历结果集作为参数传入转换。
在本文中,我将深入探讨这个主题,并提供一些实际的例子来帮助你更好地理解。
1. 什么是Kettle?Kettle,即Pentaho Data Integration(PDI),是一款面向企业级的ETL工具。
它允许开发人员通过可视化和图形化编程方式来构建ETL 流程。
Kettle提供了一系列强大的转换步骤和作业,可以用于数据提取、转换和加载。
2. 循环遍历结果集的概念循环遍历结果集是指在Kettle中,可以通过设置循环步骤来遍历一个结果集,并将结果集中的每一行作为参数传递给下一个转换。
这个功能非常有用,可以帮助我们处理大量数据或需要迭代处理的情况。
3. 如何在Kettle中循环遍历结果集作为参数传入转换要在Kettle中实现循环遍历结果集作为参数传入转换,可以使用两个关键步骤:「获取数据」和「循环」。
步骤1:获取数据在Kettle中,可以使用「获取数据」步骤从数据库或其他数据源中获取数据。
我们可以定义一个SQL查询,将查询结果作为结果集传递给下一个步骤。
步骤2:循环在「循环」步骤中,我们可以定义循环条件和循环元素。
这里的循环元素即为步骤1中获取的结果集。
我们可以使用内部变量来引用结果集中的每一行。
在每次循环中,Kettle会自动将结果集中的下一行作为参数传递给下一个转换。
4. 实际应用示例为了更好地理解如何在Kettle中循环遍历结果集作为参数传入转换,让我们看一个具体的示例。
假设我们有一个数据库表「employees」,其中包含每个员工的尊称和薪水信息。
我们需要为每个员工计算出其年终奖的金额,并将结果插入到另一个表「bonus」中。

kettle数据检验传递字段Kettle(又称为Pentaho Data Integration)是一款功能强大的开源数据集成工具,广泛应用于ETL(抽取、转换和加载)过程中。
数据检验传递字段在Kettle中起着重要作用,本文将从以下几个方面详细介绍。
一、什么是数据检验传递字段数据检验传递字段(Field Validation and Derivation)是指在数据集成过程中对字段进行校验和转换的过程。
在Kettle中,通过使用各种校验规则和表达式,可以对字段的内容进行验证和清洗,将满足要求的数据传递给下一个步骤。
二、数据检验传递字段的作用1.数据清洗和规范化:通过对数据进行校验和清洗,可以排除无效、重复或错误的数据,保证数据的准确性和一致性。
同时,可以将不规范的数据转换为标准格式,方便后续处理和分析。
2.数据过滤和筛选:通过设置校验规则,可以根据特定的条件过滤和筛选出符合要求的数据。
这可以帮助我们减少数据集成的复杂度,提高数据处理的效率。
3.数据补全和衍生:在数据集成过程中,有时会遇到缺失或需要衍生的字段。
通过使用特定的表达式和函数,可以根据已有的数据进行计算和补全,生成新的字段传递给下一个步骤。
4.数据质量控制:数据质量是数据集成过程中一个重要的环节。
通过检验传递字段,可以对数据进行完整性、准确性、一致性等方面的校验,确保数据的质量符合要求。
三、Kettle中的数据检验传递字段的实现方式在Kettle中,可以使用以下几种方式实现数据检验传递字段的功能。
1.使用校验步骤:Kettle提供了多种校验步骤,例如"校验字段值"、"正则表达式校验"等。
在这些步骤中,可以设置校验规则,并根据规则的结果将数据分流到不同的输出流中。
2.使用过滤步骤:Kettle中的"过滤行"步骤可以根据条件过滤数据。
通过设置过滤条件,可以将满足条件的数据传递给下一个步骤,过滤掉不符合条件的数据。

开源报表指标管理开源报表指标管理是一种用于管理和分析数据的工具,它可以帮助企业更好地了解业务运营情况,并进行决策和优化。
本文将介绍开源报表和指标管理的概念、优势以及一些常见的开源工具。
开源报表是指通过开源软件实现的报表设计和生成工具。
开源软件是指可以自由使用、修改和分发的软件,它通常具有透明、可定制和可扩展的特点。
开源报表工具可以帮助企业快速生成各种类型的报表,包括统计报表、财务报表、销售报表等,并提供多种方式展示数据,如表格、图表、图形等。
指标管理是指通过设定和监控关键指标来评估企业绩效和实现目标的过程。
指标是衡量业务绩效的重要标准,可以用于评估业务活动的效果和效率。
通过指标管理,企业可以及时了解业务状况,及时调整策略和措施,以实现业务目标。
开源报表和指标管理的结合,可以为企业提供全面的数据管理和分析解决方案。
下面介绍几个常见的开源工具,用于实现开源报表和指标管理。
1. JasperReports:JasperReports是一个基于Java的开源报表生成工具。
它提供了丰富的报表设计功能,可以生成各种类型的报表,并支持多种输出格式。
JasperReports还提供了灵活的参数设置和数据源连接功能,方便用户根据需要进行报表生成和数据分析。
2. Pentaho:Pentaho是一个综合的商业智能平台,提供了开源报表和指标管理的功能。
它包括报表设计、数据集成、数据挖掘、OLAP分析等多个模块,可以满足企业对数据管理和分析的各种需求。
Pentaho的报表设计工具支持多种报表类型和数据源连接方式,用户可以根据需要自定义报表和指标。
3. BIRT:BIRT是一个基于Eclipse的开源报表工具。
它提供了强大的报表设计和生成功能,支持多种数据源和输出格式。
BIRT的报表设计工具集成在Eclipse开发环境中,用户可以方便地使用Java 或JavaScript进行报表设计和数据处理。
除了上述开源工具,还有其他一些开源报表和指标管理工具,如SpagoBI、Metabase等,它们都提供了丰富的功能和灵活的扩展性,可以根据企业的需求选择适合的工具。

pentaho开源商业智能平台的搭建(1)Pentaho项目QQ群:164774111pentaho是世界上最流行的开源商务只能软件。
它是一个基于java平台的商业智能(Business Intelligence,BI)套件,之所以说是套件是因为它包括一个web server平台和几个工具软件:报表,分析,图表,数据集成,数据挖掘等,可以说包括了商务智能的方方面面。
pentaho是世界上最流行的开源商务只能软件。
它是一个基于java平台的商业智能(Business Intelligence,BI)套件,之所以说是套件是因为它包括一个web server平台和几个工具软件:报表,分析,图表,数据集成,数据挖掘等,可以说包括了商务智能的方方面面。
整个系统的架构如下图:根据官网的介绍,其客户包括有sun,msyql等这样知名的企业,真可谓“很好很强大”。
更难能可贵的是,它是开源的,社区版完全免费!!官网: /products/sourceforge项目: /projects/pentaho/下面是几张使用界面的截图(图1,2,3)图1图2图3细心的你可能已经发现了,里面还有google maps的身影,是不是很让人兴奋呢?Pentaho是跨平台的,linux,windows上都可以安装,而且安装十分简单,就两个步骤:解压,执行。
这样说来这篇文章也没啥好写的,但是这是默认情况:数据库是用的自带的HSQL,备份维护都十分不方便。
这显然不是我们所希望的。
如何利用mysql呢?很可惜官方文档资料十分有限,而且有用的基本上只对企业用户开放。
社区的资料少还不说,而且还有错误。
这真的是难坏了我们的社区用户。
这里我就以个人的经历,给大家介绍。
pentaho开源商业智能平台的搭建(2)pentaho是世界上最流行的开源商务只能软件。
它是一个基于java平台的商业智能(Business Intelligence,BI)套件,之所以说是套件是因为它包括一个web server平台和几个工具软件:报表,分析,图表,数据集成,数据挖掘等,可以说包括了商务智能的方方面面。

1.BIRT :BIRT是基于Eclipse的报表系统,很有竞争力。
拥有和Dreamweaver一般的操作界面,可以像画table一样画报表,生成图片,导出Excel,html分页样样齐全,样式和script设置简单。
基于Eclipse 开发平台的面向下一代商业应用的大型报表软件系统。
该项目是由美国Actuate 软件公司与清华大学信息研究院Web 与软件技术研究中心合作开发的。
利用Eclipse 平台,面向商务智能(Business Intelligence) 和报表空间,其功能集中在从数据源提取数据、处理数据并显示数据。
BIRT 的最初目标是使用Eclipse 提供一个框架,用以在某组织内设计、布置和查看报表,并包含查询等工具。
BIRT 的报表有四个主要部分:数据(Data) 、数据转换(Data Transforms) 、业务逻辑(Business Logic) 、展示(Presentation) 。
使用BIRT ,用户可以在应用中增加多种形式的报表:列表(Lists) 、图表(Charts) 、交叉表(Crosstabs) 、文档(Letters &Documents) 、组合报告(Compound Reports) 。
BIRT 包括下面几个工具:Eclipse Report Designer(ERD) 、Eclipse Report Engine(ERE) 、Eclipse Charting Engine(ECE) 、Web Based Report Designer(WRD) 。
由于背后有公司支撑,BIRT发展很迅速,在JAVA开源报表工具领域大有后来居上的势头;目前国内普元的EOS报表、杭州数新的Java报表都是基于这个开源的产品改进的,当然还有很多国内的公司用BIRT作为自己的内部报表解决方案,并不直接对外销售,只是打包在自己的项目解决方案中。
2.PentahoPentaho Report Designer是一款所见即所得的开源报表设计工具。

Pentaho report designer 3.5文档前言Pentaho Report Designer是一款所见即所得的开源报表设计工具。
在设计报表的时候,用户可以随意拖放和设置各种报表的控件,还可以快速方便地设置报表的数据来源。
在报表的设计过程中,用户可以随时预览报表的结果。
是一款不错的报表设计工具。
下面简单列出Pentaho Report Designer的一些主要技术特点:1、以JFreeReport为核心引擎;2、是一款所见即所得的報表设计工具。
图形化界面,支持拖放,支持5种格式(PDF, HTML, XLS, RTF, CSV)预览和生成报表。
3、是一个独立的报表设计工具。
可以不依赖Pentaho的报表服务器。
4、提供基本的画图功能。
包括:直线、长方形、椭圆等;5、提供SQL query builder。
使得用户创建自定义查询非常方便;6、支持XQuery, Mondrian和自定义数据源;7、提供联机报表校验功能,随时提示用户当前报表存在什么错误。
8、可以很方便地发布报表到Pentaho应用服务器。
Pentaho Report Designer目前的一些不足地方:1、目前没有汉化。
2、不支持画斜线。
如果碰到一些需要画斜线的中国式报表就没有办法了。
3、报表格式调整的功能有些弱。
为了调整多个文本框成等高、等宽、上下左右对齐还挺费劲的。
4、当前用户比较少,还存在着一些易见的bug。
=============================================================================一、Run按钮1、Print Preview -------------->打印预览2、PDF -------------->pdf3、HTML -------------->html4、XLS -------------->Excel5、RTF -------------->word6、Preview As Text -------------->text7、CSV -------------->Excel=============================================================================二、test例子Page Header -------------->页报头Report Header -------------->报表报头Details -------------->详细资料Report Footer -------------->报表页脚Page Footer -------------->页页脚Style -------------->风格Attributables -------------->属性Formula -------------->规则inherit -------------->继承structure -------------->结构master -------------->主要的watermark -------------->水印function -------------->功能parameter -------------->参数============================================================================= 三、菜单功能==============FileNewReport Wizard--------------OpenOpen From Repository仓库Open Recent--------------CloseClose AllSaveSave AsPublish出版--------------Export输出Preview预览as--------------PrintPage SetupPrint Preview预览--------------Report Properties道具configuration配置resource资源--------------exit==============EditUndoRedo--------------CutCopyPastePaste Formatting格式化Delete--------------Select AllClear All Selections--------------Groupspreferences参数--------------Report Wizard==============ViewPreview预览--------------Grids栅格Guides指导Element-Names要素Element-Alignment队列-Hints 暗示Snap to ElementsShow Overlapping重叠Elements --------------Outline大纲SelectionClamp夹住Selection--------------UnitsZoomLayout规划Bands装饰==============FormatFont字体Size & Border边界Paragraph段落Hyperlinks超链接Row-Banding联合--------------Arrange排列--------------Align排列Distribute--------------Morph形素--------------Chart图表==============DataAdd Data SourceAdd FuntionAdd ParameterEdit Parameter参数, 参量==============WindowReport Explorer资源管理器Element要素Properties道具Messages消息--------------Select Next Tab制表Select Previous早先的Tab--------------test==============HelpWelcomeDecumentation--------------System InformationCheck for UpdatesReport a Bug缺陷Online Forum 论坛About============================================================================= 四、菜单功能1、label说明:显示标签,可以以数字和文字。

kettle unexpected error during job meta load-回复kettle(也称为Pentaho Data Integration)是一种强大的开源数据集成和ETL(抽取、转换和加载)工具,在大数据处理和数据仓库中得到广泛应用。
然而,有时候在使用kettle时,可能会遇到一些意外错误,例如“kettle unexpected error during job meta load”。
本文将从头开始详细介绍和解决这个问题,帮助使用kettle的人了解并克服这种错误。
首先,我们需要了解一些基本的背景知识。
kettle的工作流程通常由作业和转换组成。
作业是一个由多个转换组成的有序集合,而转换是kettle中最基本的单元,用于处理和转换数据。
因此,当我们在kettle中遇到“kettle unexpected error during job meta load”错误时,很可能是在加载作业元数据过程中出现了某些意外错误。
为了解决这个问题,我们可以采取以下步骤:步骤一:检查日志文件kettle会生成详细的日志文件,记录了每个操作的执行情况。
我们可以找到最新的日志文件,在其中搜索关键词“unexpected error”。
这些日志文件通常存储在kettle安装目录下的“logs”文件夹中,文件名类似于“kettle.log”。
通过查看日志文件,我们可以获得更多有关错误的细节,帮助我们确定问题的原因。
步骤二:检查作业和转换文件“kettle unexpected error during job meta load”错误可能是由于作业或转换文件中的错误导致的。
我们可以打开相关的作业和转换文件,检查是否存在格式错误、命名错误或缺失的组件等等。
确保所有的组件都正确配置和连接,没有任何潜在的问题。
步骤三:检查数据库连接kettle通常与关系型数据库进行连接,例如MySQL、Oracle等。

kettle多表关联循环分页迁移数据的完整例子Kettle(又名Pentaho Data Integration)是一款功能强大的ETL (Extract, Transform, Load)工具,可用于从不同的数据源中提取数据、进行转换和加载到目标数据仓库或数据库。
在实际数据迁移或数据分析项目中,往往需要进行多表关联、循环和分页处理。
下面我们通过一个完整的例子来介绍如何使用Kettle进行多表关联循环分页迁移数据。
假设我们需要从一个名为"source_database"的关系型数据库中将数据迁移到另一个名为"target_database"的关系型数据库中,两个数据库之间没有直接的链接。
我们需要将source_database中的两个表"table1"和"table2"进行关联,并分页读取数据迁移到target_database的对应表"table3"和"table4"中。
首先,我们需要在Kettle中创建两个数据库连接,分别命名为"source_db"和"target_db",并配置数据库连接信息。
在Kettle界面上,点击左上角的"文件"菜单,选择"新建"->"新建数据库连接",依次按照提示输入数据库连接相关信息。
接下来,我们需要创建一个转换(Transforation),用于定义数据的抽取、转换和加载过程。
在Kettle界面上,点击左上角的"编辑"菜单,选择"新建"->"新建转换"。
在转换中,我们首先需要添加两个输入步骤(Input),用于从source_database的"table1"和"table2"中读取数据。
一、Pentaho 整体架构cc二、Client tools1. Report Designer报表创建工具。
如果想创建复杂数据驱动的报表,这是合适工具。
2. Design Studio这是基于eclipse的工具,你可以使用它来创建手工编辑的报表或分析视图xaction 文件,一般用来对在report designer中无法增加修改的报表进行修改。
3. Aggregation Designer帮助改善Mondrian cube 性能的图形化工具。
4. Metadata Editor用来添加定制的元数据层到已经存在的数据源。
一般不需要,但是它对应业务用户在创建报表时解析数据库比较容易。
5. Pentaho Data Integration这是kettle etl工具。
6. Schema Workbench帮助你创建rolap的图形化工具。
这是为分析准备数据的必须步骤。
三、Pentaho BI suit community editon安装硬件要求:RAM:At least 2GBHard drive space:At least 1GBProcessor:Dual-core AMD64 or EM64T软件要求:需要JRE 1.5版本,1.4版本已经不再支持。
修改默认的端口8080,打开\biserver-ce\tomcat\conf目录下的server.xml文件,修改<connector port=8080为你想要的端口号。
同时在这部分可以调整Apache Tomcat参数。
在修改了该端口号后,必须同时修改\tomcat\webapps\pentaho\WEB-INF目录下的web.xml文件中的<context-param><param-name>base-url</param-name><param-value>http://localhost:8080/pe ntaho</param-value></context-param>中的端口号。
否则administration-console中不能连接到bi server。
四、配置数据库连接如果要是pentaho bi server能连接到关系数据库,需要将相应数据库driver的jar包拷贝到server/biserver-ce/tomcat/common/lib目录。
为了能在administration console中创建数据库连接并测试,需要将相应的数据库driver 的jar包拷贝到server/administration console/jdbc目录。
下面是具体关系数据库连接设置说明。
1、连接oracle数据库。
需要将oracle的driver类class12.jar包拷贝到/Pentaho/server/enterprise-console-server/jdbc/或/biserver-ee/server/enterprise-console-server/jdbc//Pentaho/server/bi-server/tomcat/common/lib/或/biserver-ee/server/bi-server/tomcat/common/lib/目录。
执行\Pentaho\Server\administration-console目录下的start-pac.bat启动admin console或bi server。
在Adminstrator console中配置数据库连接:在iE中输入http://localhost:8099/后进入管理界面,点左边的administrator,在右边窗口中点database connection进入下面的界面。
在name中输入要创建的数据库连接的名称,在driver class中选择要使用的driver类,user name中输入访问数据库的用户、password中输入相应的密码,在url中输入访问数据库的连接信息:jdbc:oracle:thin:@xzq:1521:oradata。
在@之前的是固定信息,@之后分别是服务器名称或IP:端口号:数据库服务名。
2、连接MS Sql server数据库在iE中输入http://localhost:8099/后进入管理界面,点左边的administrator,在右边窗口中点database connection进入下面的界面。
在name中输入要创建的数据库连接的名称,在driver class中选择要使用的driver类,user name中输入访问数据库的用户、password中输入相应的密码,在url中输入访问数据库的连接信息:jdbc:Microsoft:sqlserver://localhost:41433;DatabaseName=GOSLDW。
//前的字符是固定的,//后是数据库服务器名或ip地址:端口号;DatabaseName=数据库名。
五、Report Designer创建报表5.1. 创建步骤第一步:定义数据源,创建dataset第二步:定义report layout,report layout有一组band构成,包括reportheader、report footer、group header、group footer以及detail构成。
第三步:部署报表到BI server.5.2. 创建report title在左边的工具栏上拖一个label报表元素到reportheader band中,双击label报表元素输入你想要的report title,如图5-2。
你可以在右边的属性窗口中对该title进行属性定义,包括字体大小、颜色、样式等。
图5-2 创建report title5.3. 创建column header在report title下加几个label报表元素,构成你需要的columnheader,如图5.3所示。
图5-3 创建column header5.4. 创建report detail报表的Detail本身将产生报表的明细记录,这些记录有dataset提供,因此需要将dataset 中的字段拖入report detail band即可,如图5-4。
图5-4 产生reportdetail5.5. 创建report summary在report footer band加上汇总元素的描述标签和相应的汇总计算字段,如图5-5所示。
这里的关键是需要生产汇总计算字段,图中生成了两个library count 和total library size,要产生这两个汇总字段,需要在右边data页的function中增加function字段,分别利用了count(running)和summary(running)函数5.6. 画布大小设置点击菜单file->pagesetup,出现图5.6所示的界面,在该界面中可以设置画布的大小图5.65.7. 创建图表所有图表都有一个showlabel属性,默认是hidelabel,在这种情况下,图表上不会显示相应的值,图表上能显示的值一般有三种情况,分别是0、1、2(对pie chart有3),分别表示系列的描述、category描述、项值,如果需要组合显示,可以采用{0},{2}这样的格式来表示。
5.7.1. Bar chartBar chart对比较不同类别数据的大小是有用的。
在左边的工具按钮中拖入chart图标到report header,如图5.7.1图5.7.1双击该图出现图5.7.2所示的属性窗口图5.7.2 bar chart属性设置在左边窗口中设置相关的显示属性,在右边窗口中指定显示的数据字段。
这样就完成了图形报表的创建。
技巧:Pentaho中的数据集是同报表绑定的,如果想在同一报表中显示多张chart报表,需要利用sub report,在不同的sub report中分别创建报表完成。
5.7.2. 区域图(Area chart)区域图用于比较两个或多个数据集间的差异是有用的。
5.7.3. 线性图(line chart)线性图对分析发展趋势是有用的。
注意,堆积和堆积百分比(stackand stack percent)不能用于linechart。
5.7.4. 饼图(pie chart)饼图一般用来分析不同category占总值的占比分析。
饼图有一个labelformat属性,该属性值有以下几种:{0}:series name,{1}::series raw value{2}:percentage value{3}:total raw value5.7.5. 环形图(ring chart)环形图类似于饼图,除了它呈现为环形,而饼图是实体填充外,没有什么差异。
5.7.6. 多饼图(muti pie chart)根据category呈现一组饼图,每一个category对应一个饼图。
5.7.7. 瀑布图(warterfall chart)瀑布图呈现了唯一一个跨category的stacked bar chart。
这种图形对于一个category同另一个category进行比较时是有用的。
通常最后一个category等于所有别的category的总和。
5.7.8. 条形和线形组合图(bar line chart)在比较category值的同时查看趋势。
这是一个需要两个category 数据集的图形,第一个产生bar chart,第二个产生line chart。
5.7.9. 冒泡图(bubble chart)冒泡图允许你查看三维数据,前两维是传统的X/Y维,也就是域和范围(domainand range)。
第三维代表单个气泡的大小。
六、将pentaho的资料库迁移到oracle数据库默认情况下是使用HSQLDB数据库作为pentaho的资料库。
迁移步骤:1、将oracle JDBC驱动class12.jar拷贝到..\tomcat\webapps\pentaho\WEB-INF\lib 或..\tomcat\common\lib目录,供pentaho BI服务器访问oracle 数据库使用。
另外也需要将oracle JDBC驱动拷贝到administration-console\jdbc目录,否则用户不能正常使用pentaho管理控制台。
2、初始化Oracle 10g数据库。
依次执行下面的sql包,在执行sql包前先创建两个用户,quartz/password,用于存储quartz相关信息,另一个用户hibuser/password用户存储pentaho bi服务本身资料库。