结构体与链表
- 格式:ppt
- 大小:256.00 KB
- 文档页数:41

汇编语言链表结构全文共四篇示例,供读者参考第一篇示例:汇编语言是一种底层编程语言,用于直接操作计算机硬件。
在汇编语言中,链表结构是一种常见的数据结构,用于存储和组织数据。
链表可以灵活地添加或删除元素,并且可以在任意位置访问元素,使其在编程中具有重要作用。
本文将介绍汇编语言中链表结构的实现及其运用。
在汇编语言中,链表通常由节点构成。
每个节点包含两部分:数据部分和指针部分。
数据部分用于存储实际数据,而指针部分用于指向下一个节点。
通过不断跟随指针,可以在链表中遍历所有节点。
链表的头节点通常用一个特殊的指针来表示,称为头指针。
在汇编语言中,创建链表时需要定义节点的结构。
以下是一个简单的示例:```assemblynode STRUCTdata DWORD ?next DWORD ?node ENDS```上面的代码定义了一个节点结构体,包含一个数据部分和一个指向下一个节点的指针。
在实际编程中,可以根据需要定义更复杂的节点结构。
创建链表时,首先需要初始化头指针为空。
然后逐个添加节点到链表中。
以下是一个示例代码:```assembly; 初始化链表mov DWORD PTR head, 0; 添加第一个节点push 1call addNodeaddNode PROC; 申请内存空间用于新节点pushadmov edx, 8call mallocmov esi, eaxpopad; 将数据部分赋值mov DWORD PTR [esi], eax; 将指针部分赋值mov DWORD PTR [esi + 4], DWORD PTR head; 将新节点设置为头节点mov DWORD PTR head, esiretaddNode ENDP```上面的示例代码演示了如何创建一个简单的链表并向其中添加节点。
在addNode过程中,首先申请内存空间用于新节点,然后将数据部分和指针部分填充,并将新节点设置为头节点。
通过调用addNode 过程,可以逐个向链表中添加节点。
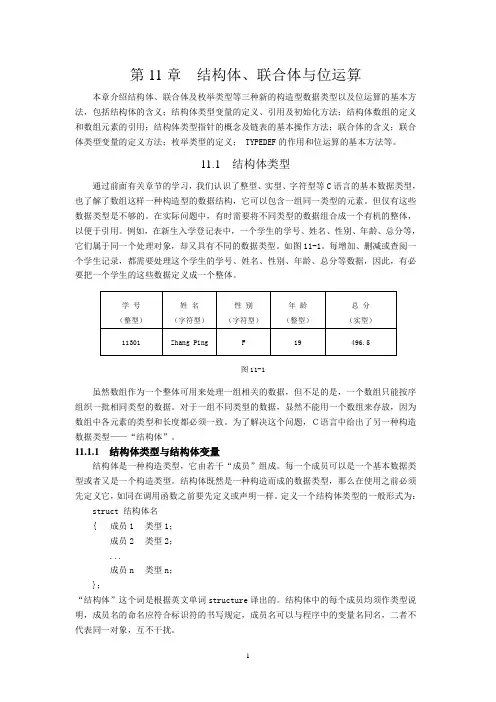
第11章结构体、联合体与位运算本章介绍结构体、联合体及枚举类型等三种新的构造型数据类型以及位运算的基本方法,包括结构体的含义;结构体类型变量的定义、引用及初始化方法;结构体数组的定义和数组元素的引用;结构体类型指针的概念及链表的基本操作方法;联合体的含义;联合体类型变量的定义方法;枚举类型的定义; TYPEDEF的作用和位运算的基本方法等。
11.1 结构体类型通过前面有关章节的学习,我们认识了整型、实型、字符型等C语言的基本数据类型,也了解了数组这样一种构造型的数据结构,它可以包含一组同一类型的元素。
但仅有这些数据类型是不够的。
在实际问题中,有时需要将不同类型的数据组合成一个有机的整体,以便于引用。
例如,在新生入学登记表中,一个学生的学号、姓名、性别、年龄、总分等,它们属于同一个处理对象,却又具有不同的数据类型。
如图11-1。
每增加、删减或查阅一个学生记录,都需要处理这个学生的学号、姓名、性别、年龄、总分等数据,因此,有必要把一个学生的这些数据定义成一个整体。
图11-1虽然数组作为一个整体可用来处理一组相关的数据,但不足的是,一个数组只能按序组织一批相同类型的数据。
对于一组不同类型的数据,显然不能用一个数组来存放,因为数组中各元素的类型和长度都必须一致。
为了解决这个问题,C语言中给出了另一种构造数据类型——“结构体”。
11.1.1 结构体类型与结构体变量结构体是一种构造类型,它由若干“成员”组成。
每一个成员可以是一个基本数据类型或者又是一个构造类型。
结构体既然是一种构造而成的数据类型,那么在使用之前必须先定义它,如同在调用函数之前要先定义或声明一样。
定义一个结构体类型的一般形式为:struct 结构体名{ 成员1 类型1;成员2 类型2;...成员n 类型n;};“结构体”这个词是根据英文单词structure译出的。
结构体中的每个成员均须作类型说明,成员名的命名应符合标识符的书写规定,成员名可以与程序中的变量名同名,二者不代表同一对象,互不干扰。

C语⾔结构体使⽤之链表⽬录⼀、结构体的概念⼆、结构体的⽤法三、结构体数组和指针四、结构体指针五、包含结构体的结构体六、链表七、静态链表⼋、动态链表⼀、结构体的概念⽐如说学⽣的信息,包含了学⽣名称、学号、性别、年龄等信息,这些参数可能有些是数组型、字符型、整型、甚⾄是结构体类型的数据。
虽然这些都是不同类型的数据,但是这些都是⽤来表达学⽣信息的数据。
⼆、结构体的⽤法1、struct 结构体名称访问⽅法:结构体变量名.成员{undefined成员1;成员2;};2、 typedef struct{undefined成员1;成员2;}结构体名称;在中⼤型产品中⼀般⽤第2种,因为结构体多了以后通过别名的⽅式定义结构体变量能够⼤⼤提⾼代码可读性。
三、结构体数组和指针1、直接⽤struct声明⼀个结构体,然后在定义结构体数组,struct 结构体名称数组名[数组⼤⼩]2、⽤typedef struct声明⼀个结构体,并且为结构体重命名,通过重命名的⽅法定义结构体数组。
结构体重命名数组名[数组⼤⼩]四、结构体指针只要是存储在内存中的变量或者数组或函数编译器都会为他们分配⼀个地址,我们可以通过指针变量指向这个地址来访问地址⾥⾯的数,只要把指针变量定义成同数据类型就可以指向了,⽐如说要指向字符型变量就定义字符型指针变量,所以我们也可以定义结构体类型指针来指向它。
1、直接⽤struct声明⼀个结构体,然后在定义结构体指针,struct 结构体名称 *结构体指针变量名2、⽤typedef struct声明⼀个结构体,并且为结构体重命名,通过别名的⽅式定义结构体指针。
结构体别名 *结构体指针变量名结构体指针访问成员⽅法结构体指针变量名->成员名五、包含结构体的结构体学⽣信息包含姓名,学号,性别,出⼊⽇期等数据,⽽出⽣⽇期⼜包含年⽉⽇这3个成员,所以把出⽣⽇期单独声明⼀个结构体,那么学⽣这个结构体就包含出⽣⽇期这个结构体,这种就是包含结构体的结构体。


【6.1简略版】在main函数中输入一个学生的学号、姓名、性别、出生日期和3门课程的成绩,在另一函数print中输出这个学生的信息,采用结构体变函数参数。
void print( student );void main ( ){student John;// 定义一个结构体变量cin>> John.ID>> >> John.gender;cin>> John.birthday.year>> John.score[2];print(John);// 调用函数完成输出}void print( student s)// 输出参数s成员的值{cout<<"学号: " << setw(5) << s.ID<< endl;cout<< setw(5) << s.birthday.month<< endl;}使用结构体变量作函数参数效率较低,why? 可采用指向结构体变量的指针或引用作参数,例如:student *ps;student John;并且如下赋值:ps= &John;则:<=> ps->name <=> (*ps).name思考:如何将程序【例6.1】中的函数print改为传指针。
【例6.2】假设一个班级有5个学生,从键盘输入5个学生的学号、姓名、性别、出生日期和三门功课的成绩,编程输出个人平均分小于全班总均分的那些学生的信息。
struct date{int year, month, day;};struct student{int ID;char name[20];char gender;date birthday;double score[3];};void input( student*, int);double average( student *, int n); //求总的平均分void print( student*,int);const int studentNumber=5;int main ( ){student stud[5];input(stud,studentNumber);print(stud,studentNumber);return 0;}void input( student *ps, int n)// 输入函数{cout<<"请输入如下学生信息" << endl;for(int i=0;i<n; i++){cin>> ps->ID;cin>> ps->name;cin>> ps->gender;cin>> ps->birthday.year>> ps->birthday.month>> ps->birthday.day;cin>> ps->score[0] >> ps->score[1]>> ps->score[2];ps++;}}void print( student *ps, int n){ student *pStart;double averAll, averPerson;averAll=average(ps,n);cout<< "总均分: "<< averAll<<endl;for(pStart=ps;pStart<ps+n;pStart++){averPerson= (pStart->score[0]+pStart->score[1]+pStart->score[2])/3 ;if( averPerson< averAll){cout<<"\n个人均分:"<< averPerson<<endl;cout<<"学号: " << setw(5) << pStart->ID;cout<<“出生年: " << pStart->birthday.year;cout<<" 成绩: " << setw(4) << pStart->score[0];}}}double average( student stud[], int n) // 求总均分{double aver=0;for(int i=0; i<n; i++)for(int j=0;j<3;j++)aver += stud[i].score[j];aver /= n*3;return aver;}NODE *create( ) // 创建无序链表{ NODE *p1, *p2, *head;int a;cout<< "Creating a list...\n";p2 = head = initlist( );cout<< "Please input a number(if(-1) stop): ";cin>> a; // 输入第1个数据while( a != -1 ) // 循环输入数据,建立链表{ p1 = (NODE *) malloc(sizeof(NODE));p1->data = a;p2->next = p1;p2 = p1;cout<< "Please input a number(if(-1) stop): ";cin>> a; // 输入下一个数据}p2->next=NULL;return(head); // 返回创建链表的首指针}// 输出链表各结点值,也称为对链表的遍历void print( NODE *head ){NODE *p;让p指向第一个数据结点p=head->next; //if( p!=NULL ){cout<< "Output list: ";while( p!=NULL ){cout<< setw(5) << p->data;p=p->next;}cout<< "\n";}}// 查询结点数据为x的结点,返回指向该结点指针NODE * search( NODE *head, int x ){ NODE *p;p=head->next;while( p!=NULL ){if(p->data == x)return p; // 返回该结点指针p = p->next;}return NULL; // 找不到返回空指针}// 删除链表中值为num的结点,返回值: 链表的首指针NODE * delete_one_node( NODE *head, int num ) {NODE *p, *temp;p=head;while(p->next !=NULL && p->next->data != num) p=p->next;temp=p->next;if(p->next!=NULL){p->next=temp->next;free(temp);cout<< "Delete successfully";}else cout<< "Not found!";return head;}// 释放链表void free_list( NODE *head ) {NODE *p;while(head){p=head;head=head->next;free(p);}}// 插入结点,将s指向的结点插入链表,结果链表保持有序NODE * insert(NODE*head, NODE *s){NODE *p;p=head;while(p->next!=NULL && p->next->data < s->data) p=p->next;s->next=p->next;p->next=s;return head;}// 创建有序链表。


数据结构—链表链表⽬录⼀、概述1.链表是什么链表数⼀种线性数据结构。
它是动态地进⾏储存分配的⼀种结构。
什么是线性结构,什么是⾮线性结构?线性结构是⼀个有序数据元素的集合。
常⽤的线性结构有:线性表,栈,队列,双队列,数组,串。
⾮线性结构,是⼀个结点元素可能有多个直接前趋和多个直接后继。
常见的⾮线性结构有:⼆维数组,多维数组,⼴义表,树(⼆叉树等)。
2.链表的基本结构链表由⼀系列节点组成的集合,节点(Node)由数据域(date)和指针域(next)组成。
date负责储存数据,next储存其直接后续的地址3.链表的分类单链表(特点:连接⽅向都是单向的,对链表的访问要通过顺序读取从头部开始)双链表循环链表单向循环链表双向循环链表4.链表和数组的⽐较数组:优点:查询快(地址是连续的)缺点:1.增删慢,消耗CPU内存链表就是⼀种可以⽤多少空间就申请多少空间,并且提⾼增删速度的线性数据结构,但是它地址不是连续的查询慢。
⼆、单链表[1. 认识单链表](#1. 认识单链表)1. 认识单链表(1)头结点:第0 个节点(虚拟出来的)称为头结点(head),它没有数据,存放着第⼀个节点的⾸地址(2)⾸节点:第⼀个节点称为⾸节点,它存放着第⼀个有效的数据(3)中间节点:⾸节点和接下来的每⼀个节点都是同⼀种结构类型:由数据域(date)和指针域(next)组成数据域(date)存放着实际的数据,如学号(id)、姓名(name)、性别(sex)、年龄(age)、成绩(score)等指针域(next)存放着下⼀个节点的⾸地址(4)尾节点:最后⼀个节点称为尾节点,它存放着最后⼀个有效的数据(5)头指针:指向头结点的指针(6)尾指针:指向尾节点的指针(7)单链表节点的定义public static class Node {//Object类对象可以接收⼀切数据类型解决了数据统⼀问题public Object date; //每个节点的数据Node next; //每个节点指向下⼀结点的连接public Node(Object date) {this.date = date;}}2.引⼈头结点的作⽤1. 概念头结点:虚拟出来的⼀个节点,不保存数据。

数据结构与C语言的关系引言数据结构是计算机科学中一个重要的概念,它用于组织和存储数据以便于访问和操作。
而C语言是一种通用的编程语言,常用于开发系统软件和应用程序。
本文将详细探讨数据结构与C语言之间的关系,包括C语言中实现常用数据结构的方法和数据结构对C语言程序性能的影响。
数据结构在C语言中的实现在C语言中,数据结构可以通过自定义数据类型来实现。
C语言提供了一些基本的数据类型,如整型、浮点型和字符型等,但对于复杂的数据结构,我们需要自己定义。
结构体C语言中的结构体是一种用户自定义的数据类型,它可以将不同类型的数据组合在一起形成一个整体。
结构体可以表示现实世界中的实体,如学生、员工等。
通过结构体,我们可以定义一个具有多个属性的变量。
下面是一个示例代码,展示了如何在C语言中定义和使用结构体:#include <stdio.h>struct student {char name[50];int age;float score;};int main() {struct student s;strcpy(, "Tom");s.age = 20;s.score = 90.5;printf("Name: %s\n", );printf("Age: %d\n", s.age);printf("Score: %.2f\n", s.score);return 0;}链表链表是一种常见的数据结构,它由多个节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
通过指针的连接,多个节点形成了一个链式结构。
在C语言中,链表可以通过使用结构体和指针来实现。
我们可以定义一个结构体来表示节点,然后使用指针将多个节点连接起来。
以下是一个简单的链表示例代码:#include <stdio.h>#include <stdlib.h>struct node {int data;struct node* next;};void printList(struct node* n) {while (n != NULL) {printf("%d ", n->data);n = n->next;}}int main() {struct node* head = NULL;struct node* second = NULL;struct node* third = NULL;head = (struct node*)malloc(sizeof(struct node));second = (struct node*)malloc(sizeof(struct node));third = (struct node*)malloc(sizeof(struct node));head->data = 1;head->next = second;second->data = 2;second->next = third;third->data = 3;third->next = NULL;printList(head);return 0;}栈和队列栈和队列是常见的数据结构,它们都可以通过数组或链表来实现。

简述二叉链表的类型定义二叉链表是一种常见的数据结构,它是由节点组成的树形结构,每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉链表的类型定义包括节点结构体和二叉链表结构体两部分。
节点结构体定义节点结构体是二叉链表中最基本的数据单元,它包含三个成员变量:数据域、左子节点指针和右子节点指针。
其中,数据域用于存储节点的数据,左子节点指针和右子节点指针分别指向节点的左子节点和右子节点。
节点结构体的类型定义如下:```typedef struct BiTNode {int data; // 数据域struct BiTNode *lchild; // 左子节点指针struct BiTNode *rchild; // 右子节点指针} BiTNode, *BiTree;```在上面的代码中,BiTNode是节点结构体的别名,BiTree是指向节点结构体的指针类型。
节点结构体中的成员变量lchild和rchild都是指向节点结构体的指针类型,它们分别指向节点的左子节点和右子节点。
二叉链表结构体定义二叉链表结构体是由节点组成的树形结构,它包含一个指向根节点的指针。
二叉链表结构体的类型定义如下:```typedef struct {BiTree root; // 指向根节点的指针} BiTreeStruct;```在上面的代码中,BiTreeStruct是二叉链表结构体的别名,它包含一个指向根节点的指针root。
root指针指向节点结构体,表示二叉链表的根节点。
二叉链表的操作二叉链表是一种常见的数据结构,它支持多种操作,包括创建二叉链表、遍历二叉链表、插入节点、删除节点等。
下面我们将介绍二叉链表的常见操作。
1. 创建二叉链表创建二叉链表的过程就是构建二叉树的过程。
我们可以通过递归的方式来创建二叉链表。
具体步骤如下:1. 如果当前节点为空,则返回NULL。
2. 创建一个新节点,并将数据存储到新节点的数据域中。

c语言遍历结构体摘要:1.结构体的概念与用途2.结构体在C语言中的遍历方法a.使用for循环遍历结构体b.使用指针遍历结构体c.使用链表遍历结构体3.遍历结构体的实际应用案例4.总结与展望正文:结构体(structure)是C语言中一种复合数据类型,它允许我们将不同类型的数据组合在一起,形成一个整体。
结构体在实际编程中有广泛的应用,如存储记录、表示图形、处理日期等。
遍历结构体是指对结构体中的成员变量进行访问或操作。
在C语言中,有多种方法可以遍历结构体。
以下将介绍三种常用的方法:1.使用for循环遍历结构体我们可以使用for循环,结合结构体成员变量的地址,逐一访问结构体中的成员变量。
下面是一个示例代码:```c#include <stdio.h>typedef struct {int id;char name[20];float score;} Student;int main() {Student s1 = {1, "张三", 95.5};Student s2;for (int i = 0; i < sizeof(s1) / sizeof(int); i++) { s2.id = s1.id;[i] = [i];s2.score = s1.score;}printf("ID: %d", s2.id);printf("Name: %s", );printf("Score: %.1f", s2.score);return 0;}```2.使用指针遍历结构体我们可以使用指针操作结构体成员变量。
这种方法更简洁,尤其是在处理结构体数组时。
下面是一个示例代码:```c#include <stdio.h>typedef struct {int id;char name[20];float score;} Student;int main() {Student s1[] = {{1, "张三", 95.5},{2, "李四", 85.0},{3, "王五", 75.5}};for (int i = 0; i < sizeof(s1) / sizeof(Student); i++) {printf("ID: %d", s1[i].id);printf("Name: %s", s1[i].name);printf("Score: %.1f", s1[i].score);}return 0;}```3.使用链表遍历结构体在某些情况下,结构体会作为链表的节点。

c语言链表定义链表是一种非常基础的数据结构,它的定义可以用多种编程语言来实现,其中最为常见的就是C语言。
本文将着重介绍C语言的链表定义。
第一步:首先,我们需要定义一个链表节点的结构体,用来存储链表中每个节点的数据信息以及指向下一个节点的指针。
具体代码如下所示:```struct ListNode {int val;struct ListNode *next;};```在这个结构体中,我们定义了两个成员变量,一个是表示节点值的val,一个是表示指向下一个节点的指针next。
其中,节点值可以是任意类型的数据,而指针next则是一个指向结构体类型的指针。
第二步:我们需要定义链表的头节点,通常会将头节点的指针定义为一个全局变量,方便在程序的不同部分中都能够访问。
这个头节点的作用是指向链表的第一个节点,同时也充当了哨兵节点的作用,使得链表的操作更加方便。
具体代码如下所示:```struct ListNode *list_head = NULL;```在这个全局变量中,我们定义了一个指向链表头节点的指针list_head,并将它初始化为NULL,表示目前链表为空。
第三步:链表的基本操作主要包括创建、插入、删除和遍历等。
我们将逐一介绍它们的定义方法。
1. 创建链表创建链表时,我们需要动态地分配内存,以保证每个节点的空间都是连续的而不会被覆盖。
具体代码如下所示:```struct ListNode *create_list(int arr[], int n) {struct ListNode *head = NULL, *tail = NULL;for (int i = 0; i < n; i++) {struct ListNode *node = (struct ListNode*)malloc(sizeof(struct ListNode));node->val = arr[i];node->next = NULL;if (head == NULL) {head = node;tail = node;} else {tail->next = node;tail = node;}}return head;}```在这个代码中,我们首先定义了链表的头节点head和尾节点tail,并将它们初始化为空。
第九章结构体与链表9.1结构体类型的定义❑程序设计者自己定义的数据类型❑包含若干成员,各成员可有不同的数据类型(与数组的区别)❑结构体类型定义struct 结构体名{ 类型标识符成员名1;类型标识符成员名2;…………….类型标识符成员名n;};大括号内为成员说明列表❑如,处理学生成绩数据,每个学生有三门课程的成绩、总成绩等变量。
struct student{long num; /*学号*/char name[10]; /* 姓名*/int score1; /* 成绩*/int score2;int score3;int total; /*总成绩*/};这样,student就是一个新的结构数据类型,可用它定义变量struct student a1, a2; 注意:struct不能省略结构体就是一个专有名词,代表一类事物,如:学生,教师,汽车等,是泛指结构体成员是描述该类事物的指标,如:学生的学号,名字,成绩等结构体变量是该类事物的一个具体事例,每个事例都具有全部成员,如每个学生都有学号,名字,成绩等9.2 结构体类型变量的定义1 先定义结构体类型,再定义变量如:struct student{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/};struct student a1, a2;注意:struct不能省略2 定义类型的同时定义变量struct student{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/} a1, a2;3 直接定义结构体类型变量struct{ long num; /* 学号*/char name[10];/* 姓名*/int score1;/* 成绩*/int score2;int score3;int total; /* 总成绩*/} a1, a2;每个结构体变量都拥有结构体的全部成员9.2.2 结构变量的引用❑结构变量的引用是通过引用其成员(分量)的形式来实现的,格式为: 结构变量名.结构成员名❑若定义了struct student a1, a2; 就可以使用其成员a1.num=00001;a2.num=00002;strcpy(, “John”);strcpy(, “Andrew”);a1.total=a1.score1+a1.score2+a1.score3;❑每个结构成员都可当做一个变量来使用,类型为在定义结构时所指定的数据类型❑结构变量的成员使用方法与普通内存变量没有区别。
链表的初始化c语言链表是一种常见的数据结构,它由一系列的结点组成,每个结点包含数据和指向下一个结点的指针。
链表的初始化是指在程序中创建一个空链表,并为链表中的每个结点分配内存空间。
在C语言中,可以通过以下步骤来初始化链表:1.定义一个结构体来表示链表的每个结点,例如:struct Node {int data;struct Node* next;};其中,data表示结点中存储的数据,next表示指向下一个结点的指针。
2.定义一个指向链表头结点的指针,初始值设为NULL:struct Node* head = NULL;3.创建并初始化第一个结点,将其地址赋值给head指针:head = (struct Node*)malloc(sizeof(struct Node));head->data = 1;head->next = NULL;4.创建并初始化其他结点,将它们插入链表中。
例如,以下代码创建一个有3个结点的链表:struct Node* second = NULL;struct Node* third = NULL;second = (struct Node*)malloc(sizeof(struct Node));second->data = 2;second->next = NULL;head->next = second;third = (struct Node*)malloc(sizeof(struct Node));third->data = 3;third->next = NULL;second->next = third;注意,创建新的结点时需要使用malloc函数分配内存空间,并将分配的地址赋值给结点的指针。
同时,需要确保最后一个结点的next指针指向NULL,表示链表的结束。
5.最后,通过遍历链表来检查初始化是否正确。
例如,以下代码遍历链表并输出每个结点的数据:struct Node* ptr = head;while (ptr != NULL) {printf('%d ', ptr->data);ptr = ptr->next;}输出结果为:1 2 3,表示链表中的每个结点都被正确地初始化了。
链表基本操作链表作为一种重要的数据结构,在计算机程序设计中被广泛应用。
链表是一种元素之间通过指针相连接的线性结构,每个元素包含数据和指向下一个元素的指针。
链表能够灵活地增加和删除元素,适用于许多需要频繁插入和删除数据的场景。
在本文中,我们将介绍链表的基本操作,并按照类别进行介绍。
创建链表链表的创建是链表操作的第一步。
首先需要声明链表节点类型的结构体,并定义链表头指针。
然后通过动态内存分配函数malloc为链表节点动态分配内存,建立链表节点之间的关系,直到最后一个节点。
struct Node{int data;Node* next;};Node* createLinkedList(int n){Node* head = NULL;Node* tail = NULL;for(int i = 0; i < n; i++){Node* node = (Node*)malloc(sizeof(Node));node->data = 0;node->next = NULL;if(head == NULL){head = node;}else{tail->next = node;}tail = node;}return head;}插入数据链表的插入操作包括在链表头插入和在链表尾插入两种情况。
在链表头插入时,新节点的指针指向链表头,链表头指针指向新节点。
在链表尾插入时,先找到链表尾节点,然后将新节点插入在尾节点后面。
void insertAtFront(Node** head, int data){Node* node = (Node*)malloc(sizeof(Node));node->data = data;node->next = *head;*head = node;}void insertAtEnd(Node** head, int data){Node* node = (Node*)malloc(sizeof(Node)); node->data = data;node->next = NULL;if(*head == NULL){*head = node;}else{Node* tail = *head;while(tail->next != NULL){tail = tail->next;}tail->next = node;}}删除数据链表的删除操作包括在链表头删除和在链表尾删除两种情况。
结构体声明和定义结构体是一种自定义的数据类型,它可以包含多个不同类型的变量。
在C语言中,结构体是一种非常常见的数据类型,它可以用来表示复杂的数据结构,如图形、文本、音频等。
本文将介绍C语言中结构体的声明和定义。
一、结构体的声明结构体的声明通常包括两个部分:结构体的类型定义和结构体变量的定义。
1. 结构体类型定义结构体类型定义可以理解为一个模板,它定义了一个结构体的数据类型,包括结构体的名称和成员变量的类型和名称。
语法格式如下:struct 结构体名称 {成员变量类型1 成员变量名称1;成员变量类型2 成员变量名称2;…成员变量类型n 成员变量名称n;};例如,定义一个表示学生信息的结构体类型如下:struct Student {char name[20];int age;float score;};这个结构体类型包含了三个成员变量:姓名、年龄和分数,它们的数据类型分别为char、int和float。
2. 结构体变量定义结构体变量定义就是用结构体类型定义变量,它定义了一个实际的结构体变量,并为其分配了内存空间。
语法格式如下:struct 结构体名称结构体变量名称;例如,定义一个表示某个学生具体信息的结构体变量如下:struct Student stu1;这个结构体变量的名称为stu1,类型为Student。
二、结构体的定义结构体的定义通常包括两个部分:结构体的初始化和结构体的使用。
1. 结构体的初始化结构体的初始化就是为结构体变量的各个成员变量赋初值,可以通过以下两种方式进行初始化:(1)直接为每个成员变量赋值例如,为上面的结构体变量stu1赋初值如下: = 'Tom';stu1.age = 18;stu1.score = 90.5;(2)使用结构体初始化器结构体初始化器是一种简化的初始化方式,它可以在定义结构体变量时直接为其成员变量赋初值。
语法格式如下:struct 结构体名称结构体变量名称 = { 成员变量1的初值, 成员变量2的初值, …, 成员变量n的初值 };例如,为上面的结构体变量stu1使用初始化器赋初值如下:struct Student stu1 = { 'Tom', 18, 90.5 };2. 结构体的使用结构体的使用就是访问结构体变量的各个成员变量,可以使用点操作符(.)来访问结构体变量的成员变量。
结构体与链表11.1 结构体类型的定义结构体是由C语言中的基本数据类型构成的、并用一个标识符来命名的各种变量的组合,其中可以使用不同的数据类型。
1.结构体类型的定义Struct结构体名{ 类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;};Struct结构体名——结构体类型名2.关于结构体类型的说明:(1)“struct 结构体名”是一个类型名,它和int、float等作用一样可以用来定义变量。
(2)结构体名是结构体的标识符不是变量名,也不是类型名。
(3)构成结构体的每一个类型变量称为结构体成员,它像数组的元素一样,单数组中元素以下标来访问,而结构体是按结构体变量名来访问成员的。
(4)结构体中的各成员既可以属于不同的类型,也可以属于相同的类型。
(5)成员也可以是一个结构体类型,如:Struct date{Int month;Int day;Int year;};Struct person{Float num;Char name[20];Char sex;Int age;Struct date birthday;Char address[10];};11.2 结构体类型变量11.2.1 结构体类型变量的定义1.先定义结构体类型,再定义结构体变量形式:Struct 结构体名{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;};Struct 结构体名变量名表;例如:Struct student{char name[20];Char sex;Int age;Float score;};Struct student stu1,stu2;2.在定义结构体类型的同时定义变量形式:Struct 结构体名{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;}变量名表;例如:Struct student{Char name[20];Char sex;Int age;Float score;}stu1,stu2;3.用匿名形式直接定义结构体类型变量形式:Struct{类型标识符1 成员名1;类型标识符2 成员名2;……类型标识符n 成员名n;}变量名表;例如:StructChar naem[20];Char sex;Int age;Float score;}stu1,stu2;11.2.2 结构体变量的使用结构体是一种新的数据类型,因此结构体变量也可以像其它类型的变量一样赋值、运算,不同的是结构体变量以成员作为基本变量。