Introduction to XML
- 格式:pdf
- 大小:811.18 KB
- 文档页数:63

学科基础课程:高级语言程序设计、高等数学(B)、管理信息系统、数据库原理与应用、管理学原理。
专业主干课程:信息管理学基础、经济学原理、管理学原理、高级语言程序设计、计算机原理、数据结构、信息分析与预测、数据库原理与应用、计算机网络、信息组织、信息检索、信息服务与用户、信息计量学、信息系统分析与设计、管理信息系统、网站设计与开发、操作系统原理、信息需求分析、市场营销、运筹学、标准化与质量管理、智能信息系统、信息经济学等。
信息管理与信息系统专业人才培养方案Undergraduate Program for Information Management &Information System Major学科门类:管理学代码:11Discipline Type: Administration Code: 11类别:管理科学与工程类代码:1101Type:Management Science and Engineering Code: 1101专业名称:信息管理与信息系统代码:110102Title of the Major: Information Management &Information System Code: 110102一、学制与学位Length of Schooling and Degree学制:四年Duration:4 years学位:管理学学士学位Degree:Bachelor of Administration二、培养目标Educational Objectives本专业培养具有扎实的管理学理论基础、熟练掌握计算机技术知识,有较强的计算机和网络应用能力、有较强的信息系统分析和设计方法以及信息管理等方面的知识和能力的高级管理人才。
能在电力系统、企事业单位、金融机构、科研院所和国家各级管理部门从事信息系统分析、设计、开发、实施、维护和评价等方面的工作。
To satisfy the society requirement, the aim of the major is to educate the students to be the advanced administrators who have the base of administration theory, knowledge of computer technology, the capability of computer and network application. The graduates will have the knowledge of the information management and have the capability of information system analysis and design. The graduates will be competent for the information system analysis, design, development, maintence applying and evaluation in power system, enterprises, government, finance organization and academy.三、专业培养基本要求Skills Profile本专业学生主要学习和掌握信息管理和信息系统方面的基本理论、基本知识、方法和技能。


javaweb英文参考文献以下是关于JavaWeb的英文参考文献的相关参考内容:1. Deepak Vohra. Pro XML Development with Java Technology. Apress, 2006.This book provides a comprehensive guide to XML development with Java technology. It covers topics such as XML basics, XML parsing using Java, XML validation, DOM and SAX APIs, XSLT transformation, XML schema, and SOAP-based web services. The book also includes numerous code examples and case studies to illustrate the concepts.2. Robert J. Brunner. JavaServer Faces: Introduction by Example. Prentice Hall, 2004.This book introduces the JavaServer Faces (JSF) framework, which is a part of the Java EE platform for building web applications. It provides a step-by-step guide to building JSF applications using various components and features such as user interface components, data validation, navigation handling, and backing beans. The book also covers advanced topics such as internationalization and security.3. Brett McLaughlin. Head First Servlets and JSP: Passing the Sun Certified Web Component Developer Exam. O'Reilly Media, 2008. This book is a comprehensive guide to the development of Java web applications using Servlets and JavaServer Pages (JSP). It covers topics such as HTTP protocol, Servlet lifecycle, request andresponse handling, session management, JSP syntax and directives, JSTL and EL expressions, deployment descriptors, and web application security. The book also includes mock exam questions to help readers prepare for the Sun Certified Web Component Developer exam.4. Hans Bergsten. JavaServer Pages, 3rd Edition. O'Reilly Media, 2011.This book provides an in-depth guide to JavaServer Pages (JSP) technology, which is used for creating dynamic web content. It covers topics such as JSP syntax, scriptlets and expressions, JSP standard actions, JSP custom tag libraries, error handling, JSP with databases, JSP and XML, and internationalization. The book also includes examples and best practices for using JSP effectively.5. Marty Hall, Larry Brown. Core Servlets and JavaServer Pages, 2nd Edition. Prentice Hall, 2003.This book is a comprehensive guide to building Java web applications using Servlets and JavaServer Pages (JSP). It covers topics such as Servlet API, HTTP protocol, session management, request and response handling, JSP syntax and directives, JSP custom tag libraries, database connectivity, and security. The book also includes numerous code examples and case studies to demonstrate the concepts.6. Michael Ernest. Java Web Services in a Nutshell. O'Reilly Media, 2003.This book provides a comprehensive reference to Java-based web services technology. It covers topics such as SOAP, WSDL, UDDI, and XML-RPC protocols, as well as Java API for XML-based web services (JAX-WS) and Java API for RESTful web services (JAX-RS). The book also includes examples and best practices for developing and deploying web services using Java technology. Please note that the above references are just a selection of some of the available books on the topic of JavaWeb. There are numerous other resources available that can provide more detailed information on specific aspects of JavaWeb development.。

GIS to CIM Data Translation Template Reference GuideContentsIntroduction (3)What is the CIM? (3)How a CIM Translation Template Can Help (4)How the Sample Template Works (5)Approach A: Walk-through for Setting up using a Spatial ETL Tool with the ArcGIS Data Interoperability Extension (5)Approach B: Walk-through for Setting up using FME (12)Resources (16)© Esri 2013IntroductionThe purpose of this document is to provide information about a sample Common Information Model (CIM) XML data translation template which Esri has developed with Safe Software in order to provide a basic approach to translating data from an Esri geodatabase to the CIM XML format, where it can potentially then be shared between other enterprise systems.Information provided will include a brief overview of CIM, an introduction to the data translation template and how it can be used within a GIS enterprise scenario, and a basic walk-through to guide a user through a simple test of its use.What is the CIM?CIM stands for the “Common Information Model” which for the electric power transmission and distribution industry, represents a set of open standards developed by the Electric Power Research Institute (EPRI) and the electric power industry, and which has been officially adopted by the International Electrotechnical Commission (IEC). One of t he CIM’s key objectives is to provide a way for application software to exchange information about the configuration and status of an electrical network.The CIM is maintained as a Unified Modeling Language (UML) model, and defines a common set of electric data objects. Through the use of UML software such as Sparx Systems’ Enterprise Architect, the CIM UML can be used to create design artifacts, such as XML / RDF schema which can then be used as a template for the exchange of data between integrated software applications and systems.There are a number of IEC standards related to CIM, including:∙IEC 61970-301: Defines a core set of packages for the CIM, with focus on the needs of electricity transmission, where related applications include energy management system, SCADA, planning and optimization.∙IEC 61970-501 and 61970-452: Define an XML format for network model exchanges using RDF.∙IEC 61968: Defines a series of standards to extend the CIM to meet the needs of electrical distribution, where related applications include distribution managementsystem, outage management system, planning, metering, work management, geographic information system, asset management, customer information systems and enterpriseresource planning.From the perspective of users of GIS (geographic information systems), the CIM provides a useful data exchange schema for electrical objects, and is of primary importance for electric utilities who have an enterprise GIS system which needs to interface with other applications / systems as part of their overall enterprise implementation, and also potentially those who may need to share their electrical network data between companies / agencies.Enterprise GIS capabilities provide broad access to geospatial data and applications throughout the organization. The advantages to deploying an enterprise GIS include:∙Using a common infrastructure for building and deploying GIS solutions∙Extending geospatial capabilities to an enterprise community∙Improving capabilities of other enterprise systems by leveraging the value of geographic information∙Increasing overall operating efficiency using GIS across your organizationGeospatial information can also be integrated with other enterprise applications to enable distribution analysis and support key decision-support systems. The CIM model as a mechanism for enterprise system integration, can be of use in this process. Some key areas of data exchange would occur between GIS, DMS, SCADA, OMS, CIS, WMS and AMI.How a CIM Translation Template Can HelpThe CIM is extensive and complex, and the CIM RDF XML structure can likewise be very challenging to navigate. There are CIM standards websites online with different types of resources, and there can be a fairly significant learning curve associated with the materials. EPRI provides some very good resources such as their CIM Primer which walks through some of the main aspects which will be of concern for GIS users such as navigating CIM UML and the CIM RDF XML structure, generating XML schema, messaging and extending the CIM. Some resource links are found at the end of this document.Given the complexities around CIM, Esri has worked with Safe Software to develop a proof of concept template for demonstrating the process of migrating GIS data to the CIM RDF XML structure. The demonstration is intended to provide users the ability to see how CIM XML for enterprise system integration purposes can be created. The CIM translation template process which this document will outline is just one way of performing translation to CIM XML. As using both the ArcGIS Data Interoperability extension and Safe’s FME product are popular ways to move spatial data in and out of a geodatabase, it was identified as a good starting point for Esri GIS users to begin a review of CIM and some of the data translation considerations around it. The CIM translation template consists of both an FME workspace and a Data Interoperability ETL (Extract, Transform, Load) tool, along with a sample dataset which has been referenced in the configuration so that the user can quickly test how the translation process works. The user can also further review the template’s configuration and copy and modify it and/or build a new configuration which references another dataset. The template provides a framework by which the user can begin to envision how their own data can be tailored, configured and translated to the CIM.How the Sample Template WorksIn order to use the template, the user will require the following software:o ArcGIS Desktop 10.1 SP1 (or higher) and the Esri Data Interoperability extension 10.1 SP1 (or higher)Or:o FME (Feature Manipulation Engine) Desktop 2012 SP1 (or higher) from Safe SoftwareAs for the skillset involved, experience with the above software is of course recommended, although a high level of proficiency is not seen as necessary to simply run the template with the accompanying sample data and get the sample template to run and export CIM XML from a test geodatabase.Proficiency will be required in order to perform actual configuration work based on the template, and will require expertise with the Data Workbench component which comes with FME and the Data Interoperability extension. Again, this is needed if the user is looking to customize the workspace template to their own data.As referenced in the Resources section at the end of this document, some basic training is available for the ArcGIS Data Interoperability extensi on through Esri’s Training site, as well as FME through Safe’s FME site.Approach A: Walk-through for Setting up using a Spatial ETL Tool with the ArcGIS Data Interoperability ExtensionThe following are basic steps to follow when using the template with ArcGIS Desktop 10.1 SP1 (or higher) and the Esri Data Interoperability extension 10.1 SP1 (or higher).Extract the Template Zipfile Package:In order to maintain paths as currently defined in documents, files should be extracted to the following folder: C:\temp\GDB_to_CIM_Template\. To do this, place the accompanying zipfile, “GDB_to_CIM_Template.zip”, in the C:\temp directory, and extract it at its location to a folder with the same name as the zipfile. This is usually the default option as seen in the following:Once extracted you will find four items in the C:\temp\GDB_to_CIM_Template\ folder as seen in the following:These four items include:∙Electric_Source_Sample.gdb– A sample file geodatabase containing electric distribution feature classes with features that can be converted to CIM XML with the tools provided in the template. The classes include:o Circuit Breakero Fuseo Meterso Transformerso Primary Overheado Primary Undergroundo Secondary Overhead∙ArcMap Document – CIM Template.mxd– An ArcMap document file containing the features from the above sample file geodatabase and a reference to Spatial ETL tool in a file-based toolbox. Note: This file is used if the user has ArcGIS Desktop and the DataInteroperability extension.∙Data Interoperability – CIM Template.tbx– A file-based toolbox containing a Spatial ETL tool with the CIM Template configuration for data translation of the above sample geodatabase to CIM XML. Note: This file is used if the user has ArcGIS Desktop and the Data Interoperability extension.∙FME Workspace – CIM Template.fmw – An FME Workspace file containing the same ETL configuration as the above toolbox, for data translation of the above sample geodatabaseto CIM XML. Note: This file is used if the user wants to use FME in place of ArcGIS Desktop and the Data Interoperability extension.Launch ArcMap and Load MXD:Once the above files are extracted at the “C:\temp\GDB_to_CIM_Template” folder location, launch ArcMap and open the ArcMap document file named “ArcMap Document – CIM Template.mxd”. This will load the data in the sample file geodatabase, and make the ArcToolbox visible.Add CIM Template Toolbox:In ArcToolbox, add the Spatial ETL toolbox, navigating to the extraction folder as seen in the following:Once added, you will see the following new toolbox available –“Data Interoperability CIM Template” and once expanded you will find the Spatial ETL tool labeled “GDB to CIM XML Template”:Run the ToolAt this point, you can open the tool like any standard geoprocessing tool by double-clicking or right-clicking and selecting “Open”. The following shows the template tool dialog with the default locations set for both the input source file geodatabase and the output CIM XML file, which defaults to the main extraction folder. Press “OK” to accept the defaults.The tool will run for about 1 – 2 minutes depending on your machine and will show the following at the bottom of the ArcToolbox / ArcMap when completed:Review ResultsAfter the tool runs, you can then click on the completion message box above to quickly move to the Results log in ArcToolbox:By scrolling to the bottom, you can see if the tool completed successfully. You should see the following messages if it did:Next, c heck the extraction folder to see if the file “CIMRDFXML--Output CIM XML File.xml” was created as seen here:This default name for the file was configured in the ETL tool. You can now review the content of the XML file which was produced. Open, view or edit the created file in your XML tool of choice to examine the content produced by the tool:Review the Template Tool ConfigurationTo review the ETL tool configuration, right-click the tool in the toolbox and select “Edit”:This brings up the Data Interoperability Workbench:You can now explore the template’s configuration, copy the tool and make modifications as desired based on the sample, or begin working with your own data.This concludes the walk-through of the template based on the ArcGIS Data Interoperability extension.Approach B: Walk-through for Setting up using FMEThe following are basic steps to follow when using the template with FME (Feature Manipulation Engine) 2012 SP1 (or higher). Most of these steps are covered in Approach A for the ArcGIS Data Interoperability extension, although are repeated here so the user has a full procedure for use with FME in one section.Extract the Template Zipfile Package:In order to maintain paths as currently defined in documents, files should be extracted to the following folder: C:\temp\GDB_to_CIM_Template\. To do this, place the accompanying zipfile, “GDB_to_CIM_Template.zip”, in the C:\temp directory, and extract it at its location to a folder with the same name as the zipfile. This is usually the default option as seen in the following:Once extracted you will find four items in the C:\temp\GDB_to_CIM_Template\ folder as seen in the following:These four items include:Electric_Source_Sample.gdb– A sample file geodatabase containing electric distribution feature classes with features that can be converted to CIM XML with the tools provided in the template. The classes include:o Circuit Breakero Fuseo Meterso Transformerso Primary Overheado Primary Undergroundo Secondary Overhead∙ArcMap Document – CIM Template.mxd– An ArcMap document file containing the features from the above sample file geodatabase and a reference to Spatial ETL tool in a file-based toolbox. Note: This file is used if the user has ArcGIS Desktop and the DataInteroperability extension.∙Data Interoperability – CIM Template.tbx– A file-based toolbox containing a Spatial ETL tool with the CIM Template configuration for data translation of the above samplegeodatabase to CIM XML. Note: This file is used if the user has ArcGIS Desktop and the Data Interoperability extension.∙FME Workspace – CIM Template.fmw – An FME Workspace file containing the same ETL configuration as the above toolbox, for data translation of the above sample geodatabase to CIM XML. Note: This file is used if the user wants to use FME in place of ArcGISDesktop and the Data Interoperability extension.Launch FME and Load FME Workspace:Once the above files are extracted at the “C:\temp\GDB_to_CIM_Template” fold er location, launch FME and open the FME Workspace file named “FME Workspace - CIM Template.fmw”. You will then see the FME workbench and the CIM Template configuration:Run the TranslationAt this point, you can run the translation as-is with all of the default values, as long as the files were extracted extracted to the “C:\temp\GDB_to_CIM_Template” folder location. To run the translation, press the first green “Run Translation” button on the FME toolbar:As the translation starts, the log window will appear and provide updates on progress. The tool will run for about 1 – 2 minutes depending on your machine and will show notes on the completion of the translation at the bottom of the log window.Review ResultsAt the bottom of the log window, you will be able to determine if the translation completed successfully and an XML file was written, such as in the following:Next, check the extraction folder to see if the file “CIMRDFXML--Output CIM XML File - FME.xml” was created as seen here:This default name for the file was configured in the ETL tool. You can now review the content of the XML file which was produced. Open, view or edit the created file in your XML tool of choice to examine the content produced by the tool:You can now explore the template’s configuration, make a copy of the FME workspace and make modifications as desired based on the sample, or begin working with your own data. This concludes the walk-through of the CIM template based on FME.Resources∙CIM Links and Documents:o International Electrotechnical Commission (IEC) Smart Grid Standards▪http://www.iec.ch/smartgrid/standards/o CIM Users Group▪/default.aspxo Electric Power Research Institute (EPRI) CIM documents▪IntelliGrid Common Information Model Primer: Second Edition:/abstracts/Pages/ProductAbstract.aspx?ProductId=000000003002001040▪CIM – MultiSpeak Harmonization:/abstracts/Pages/ProductAbstract.aspx?ProductId=000000000001026585∙Esri Data Interoperability Extensiono Main site: /software/arcgis/extensions/datainteroperabilityo Training courses:▪Go to Esri Training Site:/gateway/index.cfm and type “data interoperability”into the “Find Training” s earch box.▪Free, sample course: “ArcGIS Data Interoperability Basics”/gateway/index.cfm?fa=catalog.webCourseDetail&courseid=1720∙Safe Software FMEo Safe’s FME Technology: /fme/∙CIMToolo A free open source tool that supports the Common Information Model (CIM) standards: /index.htmlDisclaimer/Notice: This CIM XML data translation template and the information, documentation and materials related thereto are provided “AS IS” on a no-fee basis without warranty of any kind, express or implied, including, but not limited to, the warranties of merchantability or fitness for a particular purpose and non-infringement of intellectual property rights. The user bears all risk as to the quality and performance of the template and i n no event will Esri be liable to the user for direct, indirect, special, incidental, or consequential damages related to the use or the results generated by the CMI template, even if Esri has been advised of the possibility of such damage. The user understands that: (1) the tool may not accommodate the user’s specific data, (2) that the results generated may not comply with any industry standard or produce a complete, valid or accurate output, and (3) Esri is not obligated to develop or provide updates, support or maintenance for this CIM template.© Esri 2013。

常见数据集文件格式常见数据集文件格式有多种,下面我将为您介绍几种常见的数据集文件格式和它们的相关参考内容。
1. CSV (Comma Separated Values)CSV是一种常见的以逗号作为分隔符的数据集文件格式。
它是一种非常简单的文本文件格式,可以用任何文本编辑器打开和编辑。
CSV文件可以用于存储包含表格结构的数据,每行代表一条记录,每个字段用逗号分隔。
例如:```Name, Age, GenderJohn, 25, MaleEmily, 28, Female```参考内容:- "Understanding CSV Files" - 该文章详细介绍了CSV文件的格式规范和常见用途。
- "Working with CSV Files in Python" - 这篇教程介绍了在Python中如何读取和处理CSV文件。
2. JSON (JavaScript Object Notation)JSON是一种常用的轻量级数据交换格式。
它是基于键值对的方式来表示结构化的数据。
JSON文件使用文本格式,易于阅读和编写,也易于解析和生成。
例如:```{"name": "John","age": 25,"gender": "Male"}```参考内容:- "JSON: What It Is, How It Works, & How to Use It" - 该文章介绍了JSON的基本概念、语法和常见应用。
- "Working with JSON Data in Python" - 这篇教程介绍了如何在Python中读取、解析和处理JSON数据。
3. XML (eXtensible Markup Language)XML是一种使用标记来描述数据的通用文件格式。

IBM教育课程介绍技能级别说明:1-基本知识,入门;2-初级知识;3-中级知识;4-高级知识关于详细课程介绍,请参阅:/services/learning/us关于详细IBM全球认证考试,请参阅:/certify1 信息管理类课程1-1 数据库基础、数据库系统原理(初级)♦内容:关系数据库概述、SQL、DB2 UDB产品概述、数据库操纵、数据模型与数据库设计等。
♦教材:高校通用数据库原理教材、《CF03 - DB2 UDB Fundamentals》♦课时:12♦实验环境要求:WIN 2000或WIN XP操作系统,内存512M以上,硬盘10G以上,局域网连接。
♦预备知识:关系型数据库原理,SQL初级♦技能级别: 2♦认证:“IBM Certified Database Associate – DB2 UDB Fundamentals( Test 700)”♦关联课程:《数据库系统管理》、《数据库系统设计》、《数据库应用开发》1-2 数据库系统管理、数据库系统设计(中级)♦内容:DB2 GUI、安装与配置、数据库对象、数据放置与移动、备份与恢复、并发性控制、安全机制、应用程序性能控制、CLP。
♦教材:《CF23 – DB2 UDB Administration Workshop for Windows》♦课时:36♦实验环境要求:WIN 2000或WIN XP操作系统,内存512M以上,硬盘10G以上,局域网连接。
♦预备知识:SQL用法,DB2 UDB基础♦技能级别: 3♦认证:“IBM Certified Database Administrator – DB2 UDB V8(Test 701)”♦前导课程:《数据库基础》♦关联课程:《数据库系统管理》《商业智能基础》《分布式数据库》1-3 数据库应用开发(中级)♦内容:DB2编程模式、JDBC、SQLJ、存储过程、DB2 XML Extender、性能考虑。



黄聪:最简单Excel的XML格式With the soon-to-be released next version of Microsoft® Office (currently code-named "Office 12"), there will be new default file formats for Microsoft Word, PowerPoint®, and Excel®. These new formats, called the Microsoft Office Open XML Formats, will open up a whole new world to Office developers. By default, Office documents will be open and accessible, as they will use standard ZIP and XML technologies with full documentation made available under a royalty-free license. These technologies are an improvement on the existing XML formats that shipped with Microsoft Office 2003 Editions, but those existing Office 2003 XML Reference Schemas can be used today to implement solutions that work with the document data and they provide a great way to gain an understanding of what developing with the new default formats will entail.The SpreadsheetML format in Microsoft Excel is fairly easy to work with, as it was designed especially to be human readable and editable. But many of you probably haven’t had a chance to take a look at the XML support in Excel. Once you get a handle on how it works, though, you’ll realize you have plenty of uses for the XML features, from converting data between databases and Web pages to sharing files among disparate applications.To get you started, I’ll build a sample in XML that will illustrate how it all works. As you follow along, you can use Office XP or Office 2003 for this example since both support SpreadsheetML in their versions of Excel. Using a text editor, I’m going to create a very simple table that looks like Figure 1, outlining seven steps to create an XML file that represents an Excel worksheet.Figure 1 The Table ExampleFirst Name Last Name Phone NumberNancy Davolio(206) 555-9857Andrew Fuller(206) 555-9482Janet Leverling(206) 555-3412Margaret Peacock(206) 555-8122Steven Buchanan(71) 555-48481. Create the XML FileTo begin, create a new file in Notepad, and call it test.xml. Then follow the steps outlined here. First type the following:<?xml version="1.0"?>This declares that the file is an XML document adhering to the 1.0 version of the XML spec. It should always be found at the top of all your XML files. Next add the root element for the document. XML files always have one and only one root element that contains the rest of the document. For SpreadsheetML, the root element is <Workbook>. After the XML declaration, add that element so that your file now looks like this:<?xml version="1.0"?><Workbook></Workbook>2. Declare the NamespaceNow you’ll declare the namespace and add a prefix to the root element. Most XML documents have a namespace associated with them. Declaring the namespace of an XML file makes it a lot easier for users parsing your XML to know what type of XML they are dealing with. Even in Office there are a number of different uses for XML. One way to know when you are parsing a Word XML file as opposed to an Excel XML file, for example, is to look at the namespace. With Office XP, when the product group created the SpreadsheetML schema, we were still using namespaces in the form "urn:schemas-microsoft-com:office". Going forward, we’ll use URL namespaces, as we did with WordML in Office 2003 (///office, for example). By adding the namespace declaration to the spreadsheet, your file should look like this:<?xml version="1.0"?><Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet"></Workbook>The last thing you’ll do for the namespace is use a prefix, rather than the default. Since the attributes are qualified for the SpreadsheetML schema, you need to do this if you are going to use any attributes. Let’s use "ss" (for spreadsheet) as the prefix. You’ll add "ss:" in front of all of your elements, and you’ll update your namespace declaration to say that the namespace applies to everything with an "ss:" in front of it, instead of just applying to the default XML elements, as shown here:<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"></ss:Workbook>Notice that the namespace declaration says xmlns:ss= instead of just xmlns=. This means that anything with an "ss:" in front of it applies to the spreadsheet namespace.3. Add a WorksheetNext you’ll add a worksheet. Since you have an empty workbook, you need to declare the spreadsheet grid within the workbook. As you may know, workbooks can have multiple worksheets, but here you’ll just declare one. In addition, let’s declare a table inside the worksheet. The table is where all the grid data will go, and the file will now look like this:<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"><ss:Worksheet ss:Name="Sheet1"><ss:Table></ss:Table></ss:Worksheet></ss:Workbook>4. Add the Header RowThe first row in the table you want to generate has "First Name", "Last Name", and "Phone Number" in the three columns. Let’s add a<Row> tag as well as three <Cell> tags. The actual content of the cell is contained within a <Data> tag, so let’s add that as well. The file now looks like Figure 2.Figure 2 XML Worksheet Takes Form<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"><ss:Worksheet ss:Name="Sheet1"><ss:Table><ss:Row><ss:Cell><ss:Data ss:Type="String">First Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Last Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Phone Number</ss:Data></ss:Cell></ss:Row></ss:Table></ss:Worksheet></ss:Workbook>You now have a template for the table that you can open directly in Excel. It will look like Figure 3. Not too exciting, but it’s a start. Figure 3 Rudimentary Worksheet5. Adjust the Column WidthsNotice that the widths of the columns are too narrow for the content. Let’s add some XML to the file to specify the width you want for the columns. The resulting code is shown in Figure 4.Figure 4 Resizing the Columns<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"><ss:Worksheet ss:Name="Sheet1"><ss:Table><ss:Row><ss:Cell><ss:Data ss:Type="String">First Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Last Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Phone Number</ss:Data></ss:Cell></ss:Row></ss:Table></ss:Worksheet></ss:Workbook>Now open the file again in Excel. Notice that the columns are wider and that the text now fits (see Figure 5). There is another attribute you can set on the column element that tells it to use autofit for the widths. This only works for numbers and dates though. Since your cells are strings, you need to explicitly set the width.Figure 5 Resized Cells6. Add the Remaining DataNow add those additional rows of data. This should be pretty easy. Just select that first "row" element and copy it. Then paste it five more times so you have six total rows. Now go through and update the values of the rows. If you are familiar with Extensible Stylesheet Language Transform (XSLT), you’ll see how you could easily generate an XSLT that could be applied to a DataSet to transform it into SpreadsheetML. Just repeat the Row tag for each row in your DataSet and add the values in each cell’s Data tag. After applying all the data, your XML should look like Figure 6, which has been abbreviated for space. Figure 7 shows the full table in Excel.Figure 6 XML Table with all Data<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"><ss:Worksheet ss:Name="Sheet1"><ss:Table><ss:Column ss:Width="80"/><ss:Column ss:Width="80"/><ss:Column ss:Width="80"/><ss:Row><ss:Cell><ss:Data ss:Type="String">First Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Last Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Phone Number</ss:Data></ss:Cell></ss:Row><ss:Row><ss:Cell><ss:Data ss:Type="String">Nancy</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Davolio</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">(206)555 9857</ss:Data></ss:Cell></ss:Row><ss:Row>...</ss:Row></ss:Table></ss:Worksheet></ss:Workbook>Figure 7 Worksheet with Data7. Add Header FormattingAs you can see, the first row does not look like a column header, so let’s format it with bold text so that it’s clearly the header. All you need to do is generate a style that has bold text, and then reference that style with the first row. First, add the following XML in front of the Worksheet tag:<ss:Styles><ss:Style ss:ID="1"><ss:Font ss:Bold="1"/></ss:Style></ss:Styles>This creates a style whose ID is "1" and has bold applied to it. Next, update the first row element to reference StyleID 1. The row code should now look like this:<ss:Row ss:SyleID="1">Your XML should now look like Figure 8, and Figure 9 shows how it looks in Excel.Figure 8 Bolding the Header Row<?xml version="1.0"?><ss:Workbook xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"><ss:Styles><ss:Style ss:ID="1"><ss:Font ss:Bold="1"/></ss:Style></ss:Styles><ss:Worksheet ss:Name="Sheet1"><ss:Table><ss:Column ss:Width="80"/><ss:Column ss:Width="80"/><ss:Column ss:Width="80"/><ss:Row ss:StyleID="1"><ss:Cell><ss:Data ss:Type="String">First Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Last Name</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Phone Number</ss:Data></ss:Cell></ss:Row><ss:Row><ss:Cell><ss:Data ss:Type="String">Nancy</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">Davolio</ss:Data></ss:Cell><ss:Cell><ss:Data ss:Type="String">(206)555-9857</ss:Data></ss:Cell></ss:Row>...</ss:Row></ss:Table></ss:Worksheet></ss:Workbook>Figure 9 The Completed WorksheetWrap-UpThat was a pretty simple example, but it’s a good introduction if you’re new to Office XML (or even new to XML in general). The new XML formats for future versions of Excel will look different than what I’ve shown you with SpreadsheetML, but there will also be some similarities. It’s good to become familiar with the existing schemas, and I’ll start posting a lot more about the new schemas on my blog at .。

IBM:SVG(可伸缩向量图形)基础教程简介•我应该学习这个教程吗?本教程辅助开发人员理解可伸缩向量图形(SVG)背后的概念以将它们作为静态文档或动态生成的内容创建。
XML 经验不是必需的,但熟悉至少一种标记语言(如 HTML)是有用的。
有关基本的 XML 信息,请参阅教程 Introduction to XML 。
在本教程的结束部分的单个脚本编制示例中用到了 JavaScript,不过相当简单。
•本教程的内容可伸缩向量图形(SVG)使得用文本指定出现在页面上的图像成为可能。
例如,传统图形需要指定矩形的每一个像素,而 SVG 只要说明矩形存在,并指出它的大小、位置和其它属性即可。
它的好处有很多,包括轻松地从数据库信息生成图形(如图或图表)的能力,以及向图形添加动画和交互性的能力。
本教程演示了构建 SVG 文档必需的概念,如基本形状、路径、文本和绘制模型,还有动画和脚本编制。
•关于作者Nicholas Chase 曾参与了 Lucent Technologies、Sun Microsystems、Oracle 和 Tampa Bay Buccaneers 等公司的网站开发。
Nick 曾经当过高中物理教师、低级放射性废物设施经理、在线科幻杂志编辑、多媒体工程师以及 Oracle 讲师。
最近,他担任过位于美国佛罗里达州 Clearwater 的 Site Dynamics Interactive Communications 的首席技术官,他还写了三本有关 Web 开发的书,包括 Java and XML From Scratch(Que)。
他喜欢倾听读者的意见,可以通过 This email address is being protected from spam bots, you need Javascript enabled to view it 与他联系。
-----------------------------------------SVG是什么?•向量图形与光栅图形的比较在万维网历史的大部分时间里,浏览器显示的图形都是光栅格式的。

More informationIntroduction to Information Retrieval Introduction to Information Retrieval is thefirst textbook with a coherent treat-ment of classical and web information retrieval,including web search andthe related areas of text classification and text clustering.Written from acomputer science perspective,it gives an up-to-date treatment of all aspectsof the design and implementation of systems for gathering,indexing,andsearching documents and of methods for evaluating systems,along with anintroduction to the use of machine learning methods on text collections.Designed as the primary text for a graduate or advanced undergraduatecourse in information retrieval,the book will also interest researchers andprofessionals.A complete set of lecture slides and exercises that accompanythe book are available on the web.Christopher D.Manning is Associate Professor of Computer Science and Lin-guistics at Stanford University.Prabhakar Raghavan is Head of Yahoo!Research and a Consulting Professorof Computer Science at Stanford University.Hinrich Sch¨utze is Chair of Theoretical Computational Linguistics at the In-stitute for Natural Language Processing,University of Stuttgart.IntroductiontoInformation RetrievalChristopher D.ManningStanford UniversityPrabhakar RaghavanYahoo!ResearchHinrich Sch ¨utzeUniversity ofStuttgartMore informationMore informationcambridge university pressCambridge,New York,Melbourne,Madrid,Cape Town,Singapore,S˜a o Paulo,DelhiCambridge University Press32Avenue of the Americas,New York,NY10013-2473,USAInformation on this title:/9780521865715C Cambridge University Press2008This publication is in copyright.Subject to statutory exceptionand to the provisions of relevant collective licensing agreements,no reproduction of any part may take place withoutthe written permission of Cambridge University Press.First published2008Printed in the United States of AmericaA catalog record for this publication is available from the British Library.Library of Congress Cataloging in Publication dataManning,Christopher D.Introduction to information retrieval/Christopher D.Manning,PrabhakarRaghavan,Hinrich Sch¨utze.p.cm.Includes bibliographical references and index.ISBN978-0-521-86571-5(hardback)1.Text processing(Computer science)rmation retrieval.3.Documentclustering. 4.Semantic Web.I.Raghavan,Prabhakar.II.Sch¨utze,Hinrich.III.Title.QA76.9.T48M262008025.04–dc222008001257ISBN978-0-521-86571-5hardbackCambridge University Press has no responsibility forthe persistence or accuracy of URLs for external orthird-party Internet Web sites referred to in this publicationand does not guarantee that any content on suchWeb sites is,or will remain,accurate or appropriate.More informationContentsTable of Notation page xiPreface xv1Boolean retrieval11.1An example information retrieval problem31.2Afirst take at building an inverted index61.3Processing Boolean queries91.4The extended Boolean model versus ranked retrieval131.5References and further reading162The term vocabulary and postings lists182.1Document delineation and character sequence decoding182.2Determining the vocabulary of terms212.3Faster postings list intersection via skip pointers332.4Positional postings and phrase queries362.5References and further reading433Dictionaries and tolerant retrieval453.1Search structures for dictionaries453.2Wildcard queries483.3Spelling correction523.4Phonetic correction583.5References and further reading594Index construction614.1Hardware basics624.2Blocked sort-based indexing634.3Single-pass in-memory indexing664.4Distributed indexing684.5Dynamic indexing71vMore informationvi Contents4.6Other types of indexes734.7References and further reading765Index compression785.1Statistical properties of terms in information retrieval795.2Dictionary compression825.3Postingsfile compression875.4References and further reading976Scoring,term weighting,and the vector space model1006.1Parametric and zone indexes1016.2Term frequency and weighting1076.3The vector space model for scoring1106.4Variant tf–idf functions1166.5References and further reading1227Computing scores in a complete search system1247.1Efficient scoring and ranking1247.2Components of an information retrieval system1327.3Vector space scoring and query operator interaction1367.4References and further reading1378Evaluation in information retrieval1398.1Information retrieval system evaluation1408.2Standard test collections1418.3Evaluation of unranked retrieval sets1428.4Evaluation of ranked retrieval results1458.5Assessing relevance1518.6A broader perspective:System quality and userutility1548.7Results snippets1578.8References and further reading1599Relevance feedback and query expansion1629.1Relevance feedback and pseudo relevancefeedback1639.2Global methods for query reformulation1739.3References and further reading17710XML retrieval17810.1Basic XML concepts18010.2Challenges in XML retrieval18310.3A vector space model for XML retrieval18810.4Evaluation of XML retrieval192More informationContents vii10.5Text-centric versus data-centric XML retrieval19610.6References and further reading19811Probabilistic information retrieval20111.1Review of basic probability theory20211.2The probability ranking principle20311.3The binary independence model20411.4An appraisal and some extensions21211.5References and further reading21612Language models for information retrieval21812.1Language models21812.2The query likelihood model22312.3Language modeling versus other approachesin information retrieval22912.4Extended language modeling approaches23012.5References and further reading23213Text classification and Naive Bayes23413.1The text classification problem23713.2Naive Bayes text classification23813.3The Bernoulli model24313.4Properties of Naive Bayes24513.5Feature selection25113.6Evaluation of text classification25813.7References and further reading26414Vector space classification26614.1Document representations and measures of relatednessin vector spaces26714.2Rocchio classification26914.3k nearest neighbor27314.4Linear versus nonlinear classifiers27714.5Classification with more than two classes28114.6The bias–variance tradeoff28414.7References and further reading29115Support vector machines and machine learning on documents29315.1Support vector machines:The linearly separable case29415.2Extensions to the support vector machine model30015.3Issues in the classification of text documents30715.4Machine-learning methods in ad hoc information retrieval31415.5References and further reading318More informationviii Contents16Flat clustering32116.1Clustering in information retrieval32216.2Problem statement32616.3Evaluation of clustering32716.4K-means33116.5Model-based clustering33816.6References and further reading34317Hierarchical clustering34617.1Hierarchical agglomerative clustering34717.2Single-link and complete-link clustering35017.3Group-average agglomerative clustering35617.4Centroid clustering35817.5Optimality of hierarchical agglomerativeclustering36017.6Divisive clustering36217.7Cluster labeling36317.8Implementation notes36517.9References and further reading36718Matrix decompositions and latent semantic indexing36918.1Linear algebra review36918.2Term–document matrices and singular valuedecompositions37318.3Low-rank approximations37618.4Latent semantic indexing37818.5References and further reading38319Web search basics38519.1Background and history38519.2Web characteristics38719.3Advertising as the economic model39219.4The search user experience39519.5Index size and estimation39619.6Near-duplicates and shingling40019.7References and further reading40420Web crawling and indexes40520.1Overview40520.2Crawling40620.3Distributing indexes41520.4Connectivity servers41620.5References and further reading419More informationContents ix21Link analysis42121.1The Web as a graph42221.2PageRank42421.3Hubs and authorities43321.4References and further reading439Bibliography441Index469More informationTable of NotationSymbol Page Meaningγ90γcodeγ237Classification or clustering function:γ(d)is d’s classor cluster237Supervised learning method in Chapters13and14:(D)is the classification functionγlearned fromtraining set Dλ370Eigenvalueµ(.)269Centroid of a class(in Rocchio classification)or acluster(in K-means and centroid clustering)105Training exampleσ374Singular value(·)10A tight bound on the complexity of an algorithmω,ωk328Cluster in clustering328Clustering or set of clusters{ω1,...,ωK}arg maxf(x)164The value of x for which f reaches its maximumxarg minf(x)164The value of x for which f reaches its minimumxc,c j237Class or category in classificationcf t82The collection frequency of term t(the total numberof times the term appears in the document collection) C237Set{c1,...,c J}of all classesC248A random variable that takes as values members ofCC369Term–document matrixd4Index of the d th document in the collection Dd65A documentd, q163Document vector,query vectorD326Set{d1,...,d N}of all documentsD c269Set of documents that is in class cD237Set{ d1,c1 ,..., d N,c N }of all labeled documents inChapters13–15xiMore informationxii Table of Notationdf t108The document frequency of term t(the total numberof documents in the collection the term appears in) H91EntropyH M93M th harmonic numberI(X;Y)252Mutual information of random variables X and Yidf t108Inverse document frequency of term tJ237Number of classesk267Top k items from a set,e.g.,k nearest neighbors inkNN,top k retrieved documents,top k selected fea-tures from the vocabulary Vk50Sequence of k charactersK326Number of clustersL d214Length of document d(in tokens)L a242Length of the test document(or application docu-ment)in tokensL ave64Average length of a document(in tokens)M4Size of the vocabulary(|V|)M a242Size of the vocabulary of the test document(or appli-cation document)M ave71Average size of the vocabulary in a document in thecollectionM d218Language model for document dN4Number of documents in the retrieval or training col-lectionN c240Number of documents in class cN(ω)275Number of times the eventωoccurredO(·)10A bound on the complexity of an algorithmO(·)203The odds of an eventP142PrecisionP(·)202ProbabilityP425Transition probability matrixq55A queryR143Recalls i53A strings i103Boolean values for zone scoringsim(d1,d2)111Similarity score for documents d1,d2T40Total number of tokens in the document collectionT ct240Number of occurrences of word t in documents ofclass ct4Index of the t th term in the vocabulary Vt56A term in the vocabularytf t,d107The term frequency of term t in document d(the totalnumber of occurrences of t in d)More informationTable of Notation xiiiU t246Random variable taking values0(term t is present)and1(t is not present)V190Vocabulary of terms{t1,...,t M}in a collection(a.k.a.the lexicon)v(d)111Length-normalized document vectorV(d)110Vector of document d,not length normalizedwf t,d115Weight of term t in document dw103A weight,for example,for zones or termsw T x=b269Hyperplane; w is the normal vector of the hyperplaneand w i component i of wx204Term incidence vector x=(x1,...,x M);more gener-ally:document feature representationX246Random variable taking values in V,the vocabulary(e.g.,at a given position k in a document)X237Document space in text classification|A|56Set cardinality:the number of members of set A|S|370Determinant of the square matrix S|s i|53Length in characters of string s i| x|128Length of vector x| x− y|121Euclidean distance of x and y(which is the length of( x− y))More informationPrefaceAs recently as the1990s,studies showed that most people preferred gettinginformation from other people rather than from information retrieval(IR)systems.Of course,in that time period,most people also used human travelagents to book their travel.However,during the last decade,relentless opti-mization of information retrieval effectiveness has driven web search enginesto new quality levels at which most people are satisfied most of the time,andweb search has become a standard and often preferred source of informationfinding.For example,the2004Pew Internet Survey(Fallows2004)foundthat“92%of Internet users say the Internet is a good place to go for gettingeveryday information.”To the surprise of many,thefield of information re-trieval has moved from being a primarily academic discipline to being thebasis underlying most people’s preferred means of information access.Thisbook presents the scientific underpinnings of thisfield,at a level accessibleto graduate students as well as advanced undergraduates.Information retrieval did not begin with the Web.In response to variouschallenges of providing information access,thefield of IR evolved to giveprincipled approaches to searching various forms of content.Thefield be-gan with scientific publications and library records but soon spread to otherforms of content,particularly those of information professionals,such asjournalists,lawyers,and doctors.Much of the scientific research on IR hasoccurred in these contexts,and much of the continued practice of IR dealswith providing access to unstructured information in various corporate andgovernmental domains,and this work forms much of the foundation of ourbook.Nevertheless,in recent years,a principal driver of innovation has been theWorld Wide Web,unleashing publication at the scale of tens of millions ofcontent creators.This explosion of published information would be moot ifthe information could not be found,annotated,and analyzed so that eachuser can quicklyfind information that is both relevant and comprehensivefor their needs.By the late1990s,many people felt that continuing to in-dex the whole Web would rapidly become impossible,due to the Web’sxvMore informationxvi Prefaceexponential growth in size.But major scientific innovations,superb engi-neering,the rapidly declining price of computer hardware,and the rise ofa commercial underpinning for web search have all conspired to power to-day’s major search engines,which are able to provide high-quality resultswithin subsecond response times for hundreds of millions of searches a dayover billions of web pages.Book organization and course developmentThis book is the result of a series of courses we have taught at Stanford Uni-versity and at the University of Stuttgart,in a range of durations includinga single quarter,one semester,and two quarters.These courses were aimedat early stage graduate students in computer science,but we have also hadenrollment from upper-class computer science undergraduates,as well asstudents from law,medical informatics,statistics,linguistics,and various en-gineering disciplines.The key design principle for this book,therefore,wasto cover what we believe to be important in a one-term graduate course onIR.An additional principle is to build each chapter around material that webelieve can be covered in a single lecture of75to90minutes.Thefirst eight chapters of the book are devoted to the basics of informationretrieval and in particular the heart of search engines;we consider this ma-terial to be core to any course on information retrieval.Chapter1introducesinverted indexes and shows how simple Boolean queries can be processedusing such indexes.Chapter2builds on this introduction by detailing themanner in which documents are preprocessed before indexing and by dis-cussing how inverted indexes are augmented in various ways for function-ality and speed.Chapter3discusses search structures for dictionaries andhow to process queries that have spelling errors and other imprecise matchesto the vocabulary in the document collection being searched.Chapter4de-scribes a number of algorithms for constructing the inverted index from atext collection with particular attention to highly scalable and distributed al-gorithms that can be applied to very large collections.Chapter5covers tech-niques for compressing dictionaries and inverted indexes.These techniquesare critical for achieving subsecond response times to user queries in largesearch engines.The indexes and queries considered in Chapters1through5only deal with Boolean retrieval,in which a document either matches a queryor does not.A desire to measure the extent to which a document matches aquery,or the score of a document for a query,motivates the development ofterm weighting and the computation of scores in Chapters6and7,leadingto the idea of a list of documents that are rank-ordered for a query.Chapter8focuses on the evaluation of an information retrieval system based on therelevance of the documents it retrieves,allowing us to compare the relativeMore informationPreface xviiperformances of different systems on benchmark document collections andqueries.Chapters9through21build on the foundation of thefirst eight chaptersto cover a variety of more advanced topics.Chapter9discusses methods bywhich retrieval can be enhanced through the use of techniques like relevancefeedback and query expansion,which aim at increasing the likelihood of re-trieving relevant documents.Chapter10considers IR from documents thatare structured with markup languages like XML and HTML.We treat struc-tured retrieval by reducing it to the vector space scoring methods developedin Chapter6.Chapters11and12invoke probability theory to compute scoresfor documents on queries.Chapter11develops traditional probabilistic IR,which provides a framework for computing the probability of relevance ofa document,given a set of query terms.This probability may then be usedas a score in ranking.Chapter12illustrates an alternative,wherein,for eachdocument in a collection,we build a language model from which one canestimate a probability that the language model generates a given query.Thisprobability is another quantity with which we can rank-order documents.Chapters13through18give a treatment of various forms of machine learn-ing and numerical methods in information retrieval.Chapters13through15treat the problem of classifying documents into a set of known categories,given a set of documents along with the classes they belong to.Chapter13motivates statistical classification as one of the key technologies needed fora successful search engine;introduces Naive Bayes,a conceptually simpleand efficient text classification method;and outlines the standard method-ology for evaluating text classifiers.Chapter14employs the vector spacemodel from Chapter6and introduces two classification methods,Rocchioand k nearest neighbor(kNN),that operate on document vectors.It alsopresents the bias-variance tradeoff as an important characterization of learn-ing problems that provides criteria for selecting an appropriate method for atext classification problem.Chapter15introduces support vector machines,which many researchers currently view as the most effective text classifica-tion method.We also develop connections in this chapter between the prob-lem of classification and seemingly disparate topics such as the induction ofscoring functions from a set of training examples.Chapters16,17,and18consider the problem of inducing clusters of relateddocuments from a collection.In Chapter16,wefirst give an overview of anumber of important applications of clustering in IR.We then describe twoflat clustering algorithms:the K-means algorithm,an efficient and widelyused document clustering method,and the expectation-maximization al-gorithm,which is computationally more expensive,but also moreflexible.Chapter17motivates the need for hierarchically structured clusterings(in-stead offlat clusterings)in many applications in IR and introduces a numberof clustering algorithms that produce a hierarchy of clusters.The chapterMore informationxviii Prefacealso addresses the difficult problem of automatically computing labels forclusters.Chapter18develops methods from linear algebra that constitutean extension of clustering and also offer intriguing prospects for algebraicmethods in IR,which have been pursued in the approach of latent semanticindexing.Chapters19through21treat the problem of web search.We give in Chap-ter19a summary of the basic challenges in web search,together with a setof techniques that are pervasive in web information retrieval.Next,Chap-ter20describes the architecture and requirements of a basic web crawler.Finally,Chapter21considers the power of link analysis in web search,usingin the process several methods from linear algebra and advanced probabilitytheory.This book is not comprehensive in covering all topics related to IR.Wehave put aside a number of topics,which we deemed outside the scope ofwhat we wished to cover in an introduction to IR class.Nevertheless,forpeople interested in these topics,we provide the following pointers to mainlytextbook coverage:Cross-language IR Grossman and Frieder2004,ch.4,and Oard andDorr1996.Image and multimedia IR Grossman and Frieder2004,ch.4;Baeza-Yates and Ribeiro-Neto1999,ch.6;Baeza-Yates and Ribeiro-Neto1999,ch.11;Baeza-Yates and Ribeiro-Neto1999,ch.12;del Bimbo1999;Lew2001;and Smeulders et al.2000.Speech retrieval Coden et al.2002.Music retrieval Downie2006and /.User interfaces for IR Baeza-Yates and Ribeiro-Neto1999,ch.10.Parallel and peer-to-peer IR Grossman and Frieder2004,ch.7;Baeza-Yates and Ribeiro-Neto1999,ch.9;and Aberer2001.Digital libraries Baeza-Yates and Ribeiro-Neto1999,ch.15,and Lesk2004.Information science perspective Korfhage1997;Meadow et al.1999;and Ingwersen and J¨a rvelin2005.Logic-based approaches to IR van Rijsbergen1989.Natural language processing techniques Manning and Sch¨utze1999;Jurafsky and Martin2008;and Lewis and Jones1996.PrerequisitesIntroductory courses in data structures and algorithms,in linear algebra,andin probability theory suffice as prerequisites for all twenty-one chapters.Wenow give more detail for the benefit of readers and instructors who wish totailor their reading to some of the chapters.More informationPreface xixChapters1through5assume as prerequisite a basic course in algorithmsand data structures.Chapters6and7require,in addition,a knowledge ofbasic linear algebra,including vectors and dot products.No additional pre-requisites are assumed until Chapter11,for which a basic course in prob-ability theory is required;Section11.1gives a quick review of the conceptsnecessary in Chapters11,12,and13.Chapter15assumes that the readeris familiar with the notion of nonlinear optimization,although the chaptermay be read without detailed knowledge of algorithms for nonlinear op-timization.Chapter18demands afirst course in linear algebra,includingfamiliarity with the notions of matrix rank and eigenvectors;a brief reviewis given in Section18.1.The knowledge of eigenvalues and eigenvectors isalso necessary in Chapter21.Book layout✎Worked examples in the text appear with a pencil sign next to them in theleft margin.Advanced or difficult material appears in sections or subsections ✄with a question mark.The level of difficulty of exercises is indicated as easy indicated with scissors in the margin.Exercises are marked in the margin?[ ],medium[ ],or difficult[ ].AcknowledgmentsThe authors thank Cambridge University Press for allowing us to make thedraft book available online,which facilitated much of the feedback we havereceived while writing the book.We also thank Lauren Cowles,who has beenan outstanding editor,providing several rounds of comments on each chap-ter;on matters of style,organization,and coverage;as well as detailed com-ments on the subject matter of the book.To the extent that we have achievedour goals in writing this book,she deserves an important part of the credit.We are very grateful to the many people who have given us comments,suggestions,and corrections based on draft versions of this book.We thankfor providing various corrections and comments:Cheryl Aasheim,Josh At-tenberg,Luc B´e langer,Tom Breuel,Daniel Burckhardt,Georg Buscher,Fa-zli Can,Dinquan Chen,Ernest Davis,Pedro Domingos,Rodrigo PanchiniakFernandes,Paolo Ferragina,Norbert Fuhr,Vignesh Ganapathy,Elmer Gar-duno,Xiubo Geng,David Gondek,Sergio Govoni,Corinna Habets,BenHandy,Donna Harman,Benjamin Haskell,Thomas H¨uhn,Deepak Jain,Ralf Jankowitsch,Dinakar Jayarajan,Vinay Kakade,Mei Kobayashi,Wes-sel Kraaij,Rick Lafleur,Florian Laws,Hang Li,David Mann,Ennio Masi,Frank McCown,Paul McNamee,Sven Meyer zu Eissen,Alexander Murzaku,Gonzalo Navarro,Scott Olsson,Daniel Paiva,Tao Qin,Megha Raghavan,More informationxx PrefaceGhulam Raza,Michal Rosen-Zvi,Klaus Rothenh¨a usler,Kenyu L.Run-ner,Alexander Salamanca,Grigory Sapunov,Tobias Scheffer,Nico Schlae-fer,Evgeny Shadchnev,Ian Soboroff,Benno Stein,Marcin Sydow,AndrewTurner,Jason Utt,Huey Vo,Travis Wade,Mike Walsh,Changliang Wang,Renjing Wang,and Thomas Zeume.Many people gave us detailed feedback on individual chapters,eitherat our request or through their own initiative.For this,we’re particularlygrateful to James Allan,Omar Alonso,Ismail Sengor Altingovde,Vo NgocAnh,Roi Blanco,Eric Breck,Eric Brown,Mark Carman,Carlos Castillo,Junghoo Cho,Aron Culotta,Doug Cutting,Meghana Deodhar,Susan Du-mais,Johannes F¨urnkranz,Andreas Heß,Djoerd Hiemstra,David Hull,Thorsten Joachims,Siddharth Jonathan J.B.,Jaap Kamps,Mounia Lal-mas,Amy Langville,Nicholas Lester,Dave Lewis,Stephen Liu,DanielLowd,Yosi Mass,Jeff Michels,Alessandro Moschitti,Amir Najmi,MarcNajork,Giorgio Maria Di Nunzio,Paul Ogilvie,Priyank Patel,Jan Peder-sen,Kathryn Pedings,Vassilis Plachouras,Daniel Ramage,Stefan Riezler,Michael Schiehlen,Helmut Schmid,Falk Nicolas Scholer,Sabine Schulteim Walde,Fabrizio Sebastiani,Sarabjeet Singh,Alexander Strehl,John Tait,Shivakumar Vaithyanathan,Ellen Voorhees,Gerhard Weikum,Dawid Weiss,Yiming Yang,Yisong Yue,Jian Zhang,and Justin Zobel.Andfinally there were a few reviewers who absolutely stood out in termsof the quality and quantity of comments that they provided.We thank themfor their significant impact on the content and structure of the book.We ex-press our gratitude to Pavel Berkhin,Stefan B¨uttcher,Jamie Callan,ByronDom,Torsten Suel,and Andrew Trotman.Parts of the initial drafts of Chapters13,14,and15were based on slidesthat were generously provided by Ray Mooney.Although the material hasgone through extensive revisions,we gratefully acknowledge Ray’s contri-bution to the three chapters in general and to the description of the timecomplexities of text classification algorithms in particular.The above is unfortunately an incomplete list;we are still in the process ofincorporating feedback we have received.And,like all opinionated authors,we did not always heed the advice that was so freely given.The publishedversions of the chapters remain solely the responsibility of the authors.The authors thank Stanford University and the University of Stuttgart forproviding a stimulating academic environment for discussing ideas and theopportunity to teach courses from which this book arose and in which itscontents were refined.CM thanks his family for the many hours they’ve lethim spend working on this book and hopes he’ll have a bit more free time onweekends next year.PR thanks his family for their patient support throughthe writing of this book and is also grateful to Yahoo!Inc.for providing afertile environment in which to work on this book.HS would like to thankhis parents,family,and friends for their support while writing this book.。
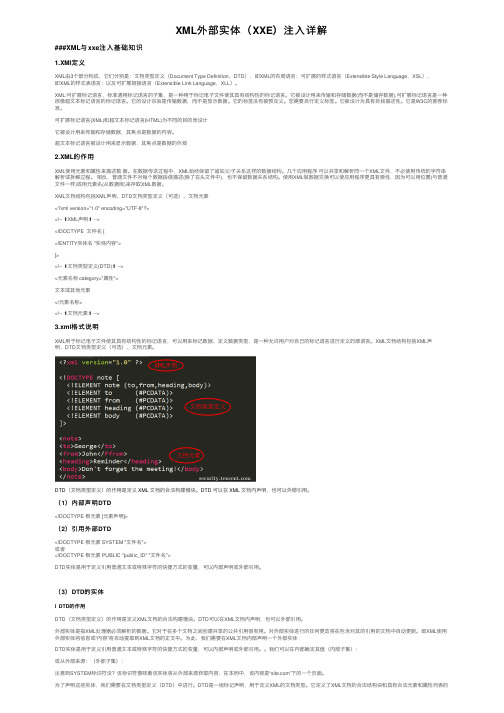
XML外部实体(XXE)注⼊详解###XML与xxe注⼊基础知识1.XMl定义XML由3个部分构成,它们分别是:⽂档类型定义(Document Type Definition,DTD),即XML的布局语⾔;可扩展的样式语⾔(Extensible Style Language,XSL),即XML的样式表语⾔;以及可扩展链接语⾔(Extensible Link Language,XLL)。
XML:可扩展标记语⾔,标准通⽤标记语⾔的⼦集,是⼀种⽤于标记电⼦⽂件使其具有结构性的标记语⾔。
它被设计⽤来传输和存储数据(⽽不是储存数据),可扩展标记语⾔是⼀种很像超⽂本标记语⾔的标记语⾔。
它的设计宗旨是传输数据,⽽不是显⽰数据。
它的标签没有被预定义。
您需要⾃⾏定义标签。
它被设计为具有⾃我描述性。
它是W3C的推荐标准。
可扩展标记语⾔(XML)和超⽂本标记语⾔(HTML)为不同的⽬的⽽设计它被设计⽤来传输和存储数据,其焦点是数据的内容。
超⽂本标记语⾔被设计⽤来显⽰数据,其焦点是数据的外观2.XML的作⽤XML使⽤元素和属性来描述数据。
在数据传送过程中,XML始终保留了诸如⽗/⼦关系这样的数据结构。
⼏个应⽤程序可以共享和解析同⼀个XML⽂件,不必使⽤传统的字符串解析或拆解过程。
相反,普通⽂件不对每个数据段做描述(除了在头⽂件中),也不保留数据关系结构。
使⽤XML做数据交换可以使应⽤程序更具有弹性,因为可以⽤位置(与普通⽂件⼀样)或⽤元素名(从数据库)来存取XML数据。
XML⽂档结构包括XML声明、DTD⽂档类型定义(可选)、⽂档元素<?xml version="1.0" encoding="UTF-8"?><!-- ⬆XML声明⬆ --><!DOCTYPE ⽂件名 [<!ENTITY实体名 "实体内容">]><!-- ⬆⽂档类型定义(DTD)⬆ --><元素名称 category="属性">⽂本或其他元素</元素名称><!-- ⬆⽂档元素⬆ -->3.xml格式说明XML⽤于标记电⼦⽂件使其具有结构性的标记语⾔,可以⽤来标记数据、定义数据类型,是⼀种允许⽤户对⾃⼰的标记语⾔进⾏定义的源语⾔。

ES123735Advanced Anxiety-Free Isometric Configuration in AutoCAD Plant 3DKenneth Fauver Autodesk, IncDescriptionThis class will cover the proper methods for customizing AutoCAD Plant 3D 2018 isometric styles using the user interface within Project Setup, supplemented with XML file editing.Attendees will learn when to use the user interface, as well as gain insight into the advanced customization available by directly editing the IsoConfig.xml file for the style. Topics covered will include understanding how filters are used in the isometric configuration. We’ll learn the difference between themes, schemes, memes—and how to manipulate annotations and dimensions to get the desired isometric deliverable.SpeakerKen Fauver has been employed by Autodesk for the past 6 years. He is part of the CS WW Project Delivery AMER as a Plant 3D and P&ID Implementation Consultant. Previously part of the ENI & TS-AMER Technical Sales Specialist Team. Concentrating on activities related to Plant 3D. Ken supports the North American AEC Named Accounts working with Owner /Operators and other Key Accounts. Has over 25 years’ experience in the Oil and Gas industry as a Piping Designer, Drafter, and CAD Administrator. Prior to joining Autodesk, Ken worked for several companies in the Petro/Chemical markets including Wink Engineering, ACPlant dbaFlow Logic International and Jacobs Engineering. My work-related interests include pipe design, software support and training. Also, worked as a System Administrator, AutoCAD Programmer, Trainer and CAD Coordinator with several software applications during his pre-Autodesk career.Learning ObjectivesLearn how to customize an isometric style using Project Setup in AutoCAD Plant 3D Learn how to do specific advanced customization directly in the IsoConfig.xml file Understand the different parts and syntax of the IsoConfig.xml fileLearn how to create an isometric style template for future useTable of ContentsIntroduction (4)Isometric Drawing Setup (5)Symbols and Reference (5)Edit Isometric Symbols (6)Isometric Symbols (SKEY) (6)Isosymbolstyles.dwg (6)Isokeyacadblockmap.xml (6)Iso Style Setup (7)Content paths (7)Production iso output directory: (7)Quick iso output directory: (8)Iso Style Default Settings (8)Annotations (10)Iso sheet continuation (to) (11)Iso sheet continuation (from) (11)Other connected pipe lines (12)Connected equipment nozzles (12)Drain Annotation (13)Vent Annotation (13)Open pipe ends (14)Closed pipe ends (14)Connection text: (15)Dimensions (17)Themes (18)Default Theme (18)Fitting To Fitting Theme (19)Small Bore Piping Theme (20)Vent/Drain Piping Theme (21)Offline Instrument Connection Theme (22)Existing Piping Theme (23)Continuation/Connection Piping Theme (24)Sloped and Offset Piping (25)Title Block and Display (26)Table Setup (28)Iso Themes (30)Title Block Attributes (32)IsoConfig.xml (36)Autodesk Iso Style Editor Public Beta (36)What is the isoconfig.xml (37)Modifying the IsoConfig XML (38)Themes (38)Split (41)Filters (41)Miscellaneous Annotation Changes (42)Appendix (47)References: (49)Previous AU Classes (49)IntroductionThis class will focus on an isometric style that I configured for a customer in the Petro/Chem industry. These setting are common to most industries and will serve as a starting place for those of you that are new to configuring Plant 3D isometric.Isometric Drawing SetupThis section describes the settings used to setup the AU_Final_ANSI-C Isometric Style. Note: This isometric style can be used for future projects by updating the isometric title block for each customer.Symbols and ReferenceThis section will allow you to modify SKEY and Annotation symbols.Figure 1Changes made in the Symbols and Reference dialog will get written to the IsoSymbolStyles .dwg and Plant3dIsoSymbols.dwg drawing files.Visit the ? help documentation.Edit Isometric SymbolsCreated these new isometric symbol blocks.Isometric Symbols make use of AutoCAD Blocks along with the use of Dynamic Block parameter.For AutoCAD Isometric to recognize this new symbol we need to new SKEY definitions in the IsoSkeyAcadBlockMap.xml file as shown below.Isometric Symbols (SKEY)Isosymbolstyles.dwgInserted ExtBodyGateValve block.Isokeyacadblockmap.xmlAdded line item to Valves section<!-- Begin: Valves --><SkeyMap SKEY = "V3??" AcadBlock ="3WayValve"/><SkeyMap SKEY = "V4??" AcadBlock ="4WayValve"/><SkeyMap SKEY = "AR??" AcadBlock ="ValveAngle"/>………<SkeyMap SKEY = "VE??" AcadBlock ="ExtBodyGateValve"/> <!-- End: Valves -->Iso Style SetupFigure 2The Iso Style that was modified for this class is called AU_Final_ANSI-C. Except for Content paths all other settings in this dialog are set to their default values.Content pathsThe AU_Final_ANSI-C isometric style resides under the following folder:“C:\Plant 3D 2017 Projects\2017 Projects\AU 2017 Project\Isometric”Production iso output directory:Location where the Production Isometrics are created.“C:\Plant 3D 2017 Projects\2017 Projects\AU 2017Project\Isometric\AU_Final_ANSI-C\ProdIsos\”Quick iso output directory:Location where the Quick Isometrics are created.“C:\Plant 3D 2017 Projects\2017 Projects\AU 2017Project\Isometric\AU_Final_ANSI-C\QuickIsos\”View the ? help documentation.Iso Style Default SettingsWhen creating isometrics, you have option to change some settings at run time by selecting the Advanced… button.Figure 3View the ? help documentation.Or set these values as default through the Iso Style Defaults Settings in Project Setup.Figure 4The only setting that were changed are as follows:Turn on Overwrite existing filesLevel of congestion to split isometric at: Set to MoreTurn off Export data tablesVisit the ? help documentation.AnnotationsFigure 5In the Annotations dialog the following settings have been changed: Spool, Welds, and Cut pieces annotation has been turned off. Enclosure height and text have been set to 0.09375.Iso sheet continuation (to)Removed (#) from the connection prefix.Figure 6 Iso sheet continuation (from)Removed (#) from the connection prefix.Figure 7Other connected pipe linesAdded (DWG) to the connection prefix.Figure 8 Connected equipment nozzlesNo change to Connected equipment nozzles. .Figure 9Drain AnnotationDisable the display of coordinates for drain annotation.Figure 10Vent AnnotationDisable the display of coordinates for vent annotation.Figure 11Open pipe endsNo change.Figure 12Closed pipe endsDisabled the display of closed pipe annotation and coordinates.Figure 13Connection text:The Connection text box allows you to change the information shown on the isometric continuation.For Example:Out-of-the-box the continuation for a pipeline connected to equipment with look like thisUnder the Connection and continuations > Connected equipment nozzle > Connection text: add the following:<Equipment.Tag>, <Nozzle.Tag>, <Nozzle.Size>-<Nozzle.PressureClass>LB$<Equipment.PartSizeLongDesc>Note: The “$” in the text represents typing the “Enter” key to start a new text line.Results:Visit the ? help documentation.DimensionsSets the format for dimensions placed in isometric drawings.Figure 14 Changed the following settings:Dimension text height: 0.0830Do not over constrain string dimensions is checked. Visit the ? help documentation.ThemesSpecifies dimension, annotation, and isometric symbol scale for piping and override themes.Default ThemeThe default theme specifies isometric options for normal piping.Figure 15Fitting To Fitting ThemeThe Fitting to Fitting theme specifies isometric options for fittings that are connected. Overrides the Default Theme.Figure 16Small Bore Piping ThemeThe Small-Bore Piping theme specifies isometric options for small borefittings and pipe as defined in the Dimension section above. Overrides the Default Theme.Figure 17In this case all pipe and fitting 2” and below are considered Small Bore Piping.Vent/Drain Piping ThemeThe Vent/Drain Piping theme specifies isometric options for Vent andDrain piping. Overrides the Default Theme.The may be some additional configuration changes in the IsoConfig.xml to get exactly what you want he. Usually must do with modifying orcreating filters. We will discuss this later in this document.Figure 18Offline Instrument Connection ThemeThe Offline Instrument Connection theme specifies isometric options for offline instruments. Overrides the Default Theme. Currently set to not dimension instruments.Figure 19Existing Piping ThemeThe Existing Piping theme specifies isometric options for existing pipe and fittings. Overrides the Default Theme. Currently set to not to show dimensions or annotations.Figure 20Continuation/Connection Piping ThemeThe Continuation/Connection Piping theme specifies isometric options forcontinuations and/or connections. Overrides the Default Theme. Currently set to not to show annotations only.Figure 21Visit the ? help documentation.Sloped and Offset PipingSpecifies formatting for sloped lines, including falls, 2D offsets, and 3D offsets.Figure 22Visit the ? help documentation.Title Block and DisplaySets up the title block for isometric drawings.Figure 23Selecting the Setup Title Block… button will allow you to modify the isometric title block you would like to use for your project.Title Block InsertionTo change out the title block with your custom title block, follow these steps:1. Insert your title block drawing into the isometric template.2. Erase the existing Title Block reference.3. Purge the Title Block block definition.4. Use the RENAME command to change your company title block name to “TitleBlock”.Here we eliminate the tables for Cut Pieces and Welds.Figure 24 Visit the ? help documentation.Table SetupBOM Table LayoutThis dialog configures the columns and column layout to be used for the Bill of Material (BOM). Use default values.Figure 25Visit the ? help documentation.BOM Table SettingsSpecifies the bill of materials settings. Use default values.Figure 26Visit the ? help documentation.Iso ThemesIso Themes are used to control which Dimension Style, Multileader Style, Table Style, Text Style, and Layer Setup.Default ThemeFigure 27Override ThemesYou can override the default layers for each them. No changes here.Visit the ? help documentation.Figure 28No changes were made to the Override Themes.Visit the ? help documentation.Title Block AttributesAutomatically fill out the title block from a data source.Map Title Block AttributesThe isometric configuration allows for two ways to map data to the title block attributes. You can either map directly to the database properties or you use an external spreadsheet referred to a Line Designation Table (LDT).Selecting the Map attributes… button will take you to the dialog that allows you to map directly to the database properties.For the AU_Final_ANSI-C Iso Style my customer opted for the Line DesignationTable method. Clicking on the LDT Setup tab in the dialog starts thisconfiguration.LDT file (XLS): <drive>\<project root>\Isometric\AU_Final_ANSI-C\Line List for Isos.xlsWorksheet name: LNLIST (Tab inside the XLS to be used)Header row: 1 (Row number that in considered the header. The spreadsheet can only have one header row.)Line number column: Line# (Name of column containing the Line Number)View LDT… (Is everything is correct, this button will show a preview of the spreadsheet data)Figure 29Map Title Block Attributes (Cont’d)Selecting the View LDT… button will show the columns of data in thespreadsheet.Figure 30The columns will now be accessible in the attribute map dialog. Set them as shown. Notice I have utilized a combination of database properties and LDT columns.Figure 31Finished title block with all attributes assigned.Figure 32 Visit the ? help documentation.IsoConfig.xmlSome isometric configuration requires modification of the IsoConfig.xml file. Meaning there was not a setting in the user interface to change or I needed to tweak the setting further to get the results needed.I will outline those changes in this section.Autodesk Iso Style Editor Public BetaHello Plant 3D Beta forum participants,I'm pleased to announce that we have just made available the Autodesk Iso Style Editor Public Beta to you for testing!We know how difficult it is having to navigate and work with the Iso Config XML file when tweaking the finer details of Iso Styles, so the team has put together the Iso Style Editor to try and simplify things for you.You can work with a Properties table UI, and still have access to the XML when you need it! Go to the DOWNLOADS page to watch our getting started video, check out the PDF guide, and download the Iso Style Editor!Next, let us know your thoughts! The FORUM for the Iso Style Editor is here.Have a friend that isn't part of the forum yet? Send them this invite link:https://goo.gl/AoSxBGWhat is the isoconfig.xmlXml stands for eXtensible Markup Language. Although called, a language, it’s better to think of xml as a way of organizing information for developers. Xml is closer to customizable database format than a programming language. For further information on using XML please read: /xml/xml_whatis.aspInformation within xml is grouped within tags by including sub-tags, and/or attributes. The contents and types of tags are completely definable by the developer. The xml follows a loose structure dictated here: /xml/xml_tree.asp.In short, xml is organized in a tree hierarchy with elements indicated by brackets. Applying the structure to the isoconfig.xml, our root element is the element IsoconfigDefinition.Xml definitions:<Tag> – a value surrounded in brackets. Same for Parent and Child elements.<Tag/>– an element (tag) is closed with a slash “/”. Same for Parent and Child elements. Attributes – A property of a tag residing within its brackets, i.e. <Tag IsLinear=”true”/>. The IsLinear value is an attribute that has a true or false value.Comments – Comments are surrounded with <!-- and closed with !-->.Modifying the IsoConfig XMLThemesA theme is a named configuration for Dimensions, Annotations, Bend, Elbow,Symbols, and Insulation.Default ThemeDefault dimension format cutoff. All dimension 12” and above are shownas feet and inches instead of 24 and above.Formatting of the line number annotation. This example changes the format to <Line#>-<Size>-<Spec>Fitting To Fitting ThemeFitting to fitting dimension format cutoff. All dimension 12” and above areshown as feet and inches instead of 24 and above.Small Bore Piping ThemeTo turn off the dimensioning of plugs for small bore piping “Overall”.To turn off the dimensioning of plugs for small bore piping “String”.SplitThe split section controls how the isometric engine will break up the model into drawingsTo change the number of components shown as dashed for the continuation. Also includes flanges.FiltersAdded new filters for changes made to Small Bore Piping Theme above.Eliminate insulation break symbol at iso message.Miscellaneous Annotation ChangesPrevent the valve text from being grouped with other annotations and have the leader stop at center of BOM tag.Default Theme > Annotations > AnnotationSchemesSeparate the annotation from the BOM tag.Default Theme > Annotations > AnnotationSchemesResolve the issue of valves with different descriptions being grouped into one row in the BOM.Resolve the issue of pipe supports with different descriptions being grouped into one row in the BOM.Resolves the issue of pipe being separated into two rows with identical descriptions and sizes in the BOM.Resolves the issue of valves with different descriptions being grouped into one row in the BOM.To enable inline instruments to be listed in Iso BOM add the following.The SizeDelimiter can be made lower case.Also, within the Data section, the Index on an AggregatedList may include a character attribute which includes characters that are allowed as the index.AppendixVariable Filter Values (including but not limited to the following):Type– all components. Example: "Type = 'Bend'"DIRECTION– for valve operators. Example: “DIRECTION='E'"UNDIMENSIONED – Boolean property of an isometric messageEND1, END2– end conditions. Example: FL, BW, SC, SW, CP, etc.SHORTRADIUS – short radius elbow flag. Valid value: SRService – service property for a componentCategory – shop or field items. Valid values: ERECTION-ITEM, FABRICATION-ITEM, OFFSHORE-ITEMSymbolName – connector symbol. Example: FieldWeldLength – Pipe lengthFieldItem– flag for field itemsExisting – flag for existing itemsITEM-CODE – ITEM-CODE property from the piping spec or catalogConnectionSize – size of a component end connection in decimal unitsSpoolNumber – spool number property for a component[FLAT-DIRECTION]– for eccentric reducers[TRACING-SPEC]– tracing spec property for a component[REFERENCE-TO] for continuations[REFERENCE-FROM] – for continuations[ANGLE-CDEG] – cutback elbow degreesTEXT– for messagesMPVLEVEL– for multiport valvesMaxPipeLength– for fixed length pipeSKEY – Isometric symbol SKEYValid Operators:LIKE– contains a string and is usually used with a wildcard. Example: "Type LIKE 'TEE*'"=- exactly matches. Example: "Type='Support'"NOT - inverts the operation. Example: "NOT [ITEM-CODE] IS NULL" means that when the value for ITEM-CODE is not NULL (blank).OR– one condition or another. Best if enclosed with parentheses. Example: "Type='FLANGE-BLIND' OR Type='CAP'"AND– one condition as well as another. Best if enclosed with parentheses. Example: "Type LIKE '*Weld' AND Category='FABRICATION-ITEM'"()– for grouping logical conditions. Example: "Type = 'olet' AND (SKEY='LASC' ORSKEY='LASW' OR SKEY='LABW')"‘– for enclosing literal text. Example: "Type = 'END-CONNECTION-PIPELINE'"* - wildcard. Example: "Type LIKE '*Weld'”<- less than “<” symbol. Example: (ConnectionSize > 0 AND ConnectionSize <= 2) means “ConnectionSize is greater than 0 but less than 2”.>– greater than “>” symbol. Example usage: “<>” is the same as “not equal to”References:Autodesk Knowledge NetworkAutoCAD Plant 3D 2018 HelpDe-Mystifying AutoCAD Plant 3D Isometrics Configuration ReferenceMicrosoft Developer NetworkPrevious AU Classes(AU2015) ES10519-L: Customize Your AutoCAD Plant 3D Isometric Configuration - Mike Musgrave(AU2014) PD6442-L: Configuring AutoCAD Plant 3D Isometrics - Bernd Gerstenberger (AU 2013) PD1392: Setting up Isometrics in AutoCAD Plant 3D - Carsten Beinecke。

OBC results processing - reference Contents1.Prerequisites2.Processing results from BBO2.1.Locate the event2.2.Download the results and hands from BBO2.3.Handling Robots2.4.Convert the csv file to an xml file2.4.1.Master points2.4.2.Neuberg scoring2.4.3.Upload the names file and generate the xml files2.4.4.Check results and, if necessary, identify and fix any name issues2.5.Upload results3.Processing results from RealBridge3.1.Introduction3.2.Normal Procedure3.3.Procedure when the director asks for changes to be made when sending you the results.4.Procedures common to BBO and RealBridge4.1.Upload results to Bridgewebs4.2.Save results on the G-Drive4.3.Upload results to Pianola4.4.To edit the results after they have been published to Pianola1.PrerequisitesTo complete the whole process you will needi.Access to https:///drive/folders/1U5MD7FvdZ8HVODWjmKQtNW6yujDwKRWFii. A Chrome web browser with the BBO Extractor extension(see /bboextractor/) iii.Access to the BBO to XML webpage at https:///bbotoxml(documentation at /bboextractor/index.php?section=7)iv.Scorer password to Bridgewebs results administration areav.Your personal login access to Pianola with privilege to upload scoring files2.Processing results from BBO2.1.Locate the eventOur identifier as a virtual club on BBO is vEBU201048.This step involves finding the page for the session that BBO Extractor wants to work on.Go to /v2/tarchive.php?m=h&h=vEBU201048&d=vEBU201048Which brings up a page where each line is one of the virtual club event events that has been played in the last 7 days.Click the event link for the particular event of interest(normally the top one) which will open the results in a new tab. See the example below. If you are doing this immediately after the event there will be a line which reads: Note:“Results shown are provisional - adjustments possible within 20 minutes”Processing further must wait until this line disappears.There is a mandatory 20 minute correction period after the final board is played. In busy times it may take a little longer than that before BBO removes the “provisional”message. It will go eventually. Periodically refresh the page until the message goes away.Sometimes you will get an error. In which case wait a few minutes and try again.Eventually the final results will appear. This URL of the form/v2/tview.php?t=2058-1588687199is persistent. However the details required by the process described here may not be.2.2.Download the results and hands from BBONow the BBO Extractor process can be started by clicking on the BBX extension button indicated by the red arrow in the illustration below. The BBX button turns yellow and the process starts immediately. It takes a while with the displayed page changing frequently and will be interrupted by any attempt to use your web browser even in another window.So just wait patiently.It will display a box telling you that the results will be in your downloads folder. This is quite unusual behaviour as you are not given any option - it just happens.Click on OK and It then goes on to generate the PBN file and reports:At this stage the BBX button loses its yellow colour and you will find two files in the browser’s download directory with names such as:2058_Pairs_Oxford_Bridge_Club_Matchpoint_Pairs_2020-05-05.csv2058_Pairs_Oxford_Bridge_Club_Matchpoint_Pairs_2020-05-05.pbn2.3.Handling RobotsBBO permits a set of results to contain multiple Robots all called “Robot”. In this case you will need to edit the downloaded CSV file before subsequent processing will be successful. You might know that robots were in use, or you may find them reported when the XML files generated from the CSV file are checked as described below.When you edit this file please use a simple text editor and avoid word processing or spreadsheet software.Here is an example: First an extract from the original CSV with (in this case) 4 robots - highlighted in red.#Tournament1357-1591621370https:///v2/tview.php?t=1357-1591621370#Date08/06/2020Date:2020-06-08#ScoringType MATCH_POINTS#Ranking Section 1 N/S1NS #Rank Name Score pair1Robot+lesant461.9812rocklizart+stevej6657.523...#Ranking Section 1 E/W1EW#Rank Name Score pair1Robot+Robot64.32122AdrianS111+cris djone58.09133Ianient+sueient55.99144Robot+thefilth53.6115Edit the file such that each robot has a unique name formed by appending a one character suffix starting A, then B, then C etc. To give a file such as the one below where the robots are now called RobotA to RobotD.#Tournament1357-1591621370https:///v2/tview.php?t=1357-1591621370#Date08/06/2020Date:2020-06-08#ScoringType MATCH_POINTS#Ranking Section 1 N/S1NS#Rank Name Score pair ID1ID21RobotA+lesant461.9812rocklizart+stevej6657.523...#Ranking Section 1 E/W1EW#Rank Name Score pair ID1ID21RobotB+RobotC64.32122AdrianS111+cris djone58.09133Ianient+sueient55.99144RobotD+thefilth53.6115The BBONames.txt file will contain entries for Robots up to the maximum number that have been experienced up to that time. RobotA and Robot B are currently in the BBONames.txt file as:RobotA,Advanced BBO,Bot A,9000002RobotB,Advanced BBO,Bot B,9000003The two robots above have special EBU numbers and are very young so that no UMS charge will be made.For the third robot and others you may need to add an entry in the BBONames.txt file (after checking that it is not already there but this time using 88888888 as the EBU number so that they will be processed as guests)in the form RobotC,Advanced BBO,Bot C,88888888RobotD,Advanced BBO,Bot D,88888888Then go back and upload the modified BBONames.txt file, regenerate the xml files and check them once again.If you know that robots were included in the results then it would be sensible to edit the .csv file as described here2.4.Convert the csv file to an xml fileThis process requires the current BBONames.txt file which defines a mapping from a BBOName to a forename, surname and ebu number. It is maintained by Matt Wilkinson.Download it from withinhttps:///drive/folders/1U38QMSgYTWin9o7TtmAzYTbZsCNZl_BfBring up the BBO to XML Converter https:///bbotoxml/bbotoxml.htmIt remembers the settings you used last time. It is enhanced on a regular basis but currently looks like:As necessary set:Club Name: Oxford Bridge ClubClub ID Number: 201048Contact Name: Your initials or abbreviated nameUMS Charge rate:10 - Normal club session04 - L&P11 - Saturday afternoonFor master points select the club scale (as shown above) except for L&P when it should be manual.Select enhanced scoring (Neuberg)2.4.1.Master pointsWhen the master points are set to the manual scale then no master points will be awarded (unless you enter numbers in the boxes above - which you shouldn’t).With the club scale, after you have generated the XML files the allocated master points will be displayed in the two boxes above.2.4.2.Neuberg scoringThis applies a formula to correct the match points awarded for each board that has not been played as much as other boards and is to allow for the fact that if it had been played by more people then what would have been a top is no longer 100% and what would have been a bottom is not0% and so makes sure that all boards carry the same weight.2.4.3.Upload the names file and generate the xml filesNow click on the large “Load Names” button at the top right. It will ask that you identify the current BBONames.txt file which should be in your downloads directory.It will display the number of names downloaded to the right of the “Load Names” button.Now click on the “Create XML file button” at the bottom right and select as input file the csv file that was produced by the BBO Extractor and which should be in your downloads directory. This will then report:After clicking OK then you will see (in the case of a regular club session with master points):which now shows information about the event and the master points awarded.2.4.4.Check results and, if necessary, identify and fix any name issuesGo https:///obc/noebu, press the“Choose Files” button, select the xml file from your downloads directory and press the “Check the XML” button. This will check that ebu numbers have been allocated.A good result looks like:If there is something wrong you might see:which was generated when two substitutes were playing.In such a case, if the name that is shown is “Robot”,then please see the section above on Handling Robots. Otherwise the BBONames.txt file must be edited, uploaded into BBOtoXML and the two xml files regenerated and checked again. The BBONames.txt file looks like:#names,,,ameenaahd,Ameena,Ahmad,472163sarajalden,Sara,Alden,418151dplay,Linda,Allen,487536JulieAA,Julie,Anderson,420923briii,Brian,Andrews,510871When editing it add lines after the first line and be sure not to have any spaces before or after the commas. In some cases you will have to consult the director to find out what happened.If a human is playing but is not in the BBONames.txt file then if their name and EBU number are known then add an entry:<bboname>,<firstname>,<surname>,<EBUnumber>otherwise add entries:<bboname>,BBOA,Substitute,88888888<bboname>,BBOB,Substitute,88888888where <bboname> should be the actual bboname value.The eight eights number is a special one recognised by Pianola as a guest.In each case the names file must be edited and the results re-processed.To preserve the integrity of the Pianola Database please be especially careful that this is done correctly. Even those with full admin rights cannot remove an incorrect entry once it has been established.When using the file checker, if you modify the input files then you should refresh the web page, otherwise it does not notice that the files have changed and will just report the same error.If you add people to the BBONames.txt file then please tell Matt Wilkinson.2.5.Upload resultsFinally:●upload the results to Bridgewebs (see4.1. Upload results to Bridgewebs)●check that the results appear as expected●upload the results to Pianola (see4.2. Upload results to Pianola)3.Processing results from RealBridge3.1.IntroductionFor RealBridge if you are not directing yourself then you will be emailed an xml file conforming to the USEBIO 2.1 DTD and described fully at /documentation/usebio-1.2.pdf.This format is accepted both by BridgeWebs and by Pianola so often it will be very straightforward to process.If you look at the file you will see that it starts with general information about the session, then a block on the pairs (that is displayed as “Rankings” on the club website and finally the play for every board. If you convert to csv format (using BBOtoXML) you will see that the file contains just the same information mostly in the same order.RealBridge also produces a .pbn file however it does not contain information on possible and optimum contracts. Instead bring up BBOtoXML and click on Import/Edit CSV/XML and select the xml file from RealBridge.Click on “Create PBN” and the pbn file will appear in your downloads folder.There are a couple of mistakes that the director may have made and each player may have made a mistake with either his name, EBU number or both. RealBridge remembers these from one session to the next so once a user has got it right then it should stay right.It is well worth checking the xml file before uploading to Pianola. So go to https:///obc/xmlchk and specify the xml file and the BBONames.txt file. It will display some basic information about the session- the name, the date and the UMS code. If anybody has not entered an EBU number their name will be output. For anybody who has entered one then their name will be looked up in the BBONames.txt file and the names compared and any problems highlighted. If the surname does not match the EBU number it will fail to load into Pianola so should be fixed if possible. These are shown in red. There are also some cases where the name does not completely match that stored in the BBONames files which is derived from Pianola. This does not prevent the results being uploaded but it is worth liaising between Matt Wilkinson and the player to have them identical. To fix the errors in red,then edit the.xml file with a text editor to get the EBU numbers correct and recheck.3.2.Normal Procedure1.Receive the XML and the PBN files for the session from the director.2.Run https:///obc/xmlchk and fix problems reported in red by editing the .xml file with atext editor. If a player is not found in the BBONames.txt file then please inform Matt Wilkinson. if you have sufficient Pianola privileges you may be able to discover their EBU number otherwise continue to process the results.The output of xmlchk may look like:Attempt to fix all the issues marked in red before continuing. The black ones do not prevent the results being processed but can look a bit untidy on the website.The problem with Marianne O’Connor is the character used as an apostrophe which does not match that stored in Pianola.The pair entry for the Whittingtons looks like:use a simple text editor to set the correct EBU number between the <NATIONAL_ID_NUMBER> and</NATIONAL_ID_NUMBER>.After editing the .xml file you will need to refresh the webpage https:///obc/xmlchk and reload the files.3.If the director did not send you a PBN file then use BBOtoXML and click on Import/Edit/Merge CSV/XML andselect the xml file from RealBridge. Click on “Create PBN” and the pbn file will appear in your downloadsfolder.4.Upload the results to Bridgewebs (see4.1. Upload results to Bridgewebs)5.Check that the results appear as expected6.Store the xml file on the G-Drive (see4.2 Save results on the G-Drive)7.Upload the results to Pianola (see4.3. Upload results to Pianola)3.3.Procedure when the director asks for changes to be made when sending you the results.Most changes can (and should) be made by the director before sending you the results however if they need to be edited then:1.Run https:///obc/xmlchk and fix problems reported in red by editing the .xml file with atext editor. If a player is not recognised inform Matt Wilkinson.2.BBOtoXML and click on Import/Edit CSV/XML and select the xml file from RealBridge. Click on “Create PBN”and “Save as CSV” and files will appear in your downloads folder. This file has at line 5 the board count -if you wish to remove a round this number will need to be adjusted. From around line 13 onwards the pairs are listed. The rest of the file - which is most of it- is the list of traveller lines. For each board played at a table the first number is the board number followed by the names of N,S,E and W.3.Edit the .csv file to remove any boards which should have been marked as not played. They will all appear atthe end of the list of traveller lines and update the board count.4.Edit the .csv file to remove any pair that left during the session and should not appear in the scores - makesure that all their hands have also been removed from the list of travellers.5.Import the file back into BBOtoXML and check that it looks sensible with nothing in red. Go back and nowgenerate a new .xml file using BBOtoXML and read in the .csv file. Do not load a names file.6.Upload the new .xml and .pbn files to BridgeWebs7.Store the xml file on the G-Drive8.Upload the .xml and .pbn files to Pianola4.Procedures common to BBO and RealBridge4.1.Upload results to BridgewebsTwo files are required for the upload to Bridgewebs:xml file and the pbn file . Go tohttps:///cgi-bin/bwon/bw.cgi?pid=upload_results&club=obc and enter the password to get to:Select the results file using the first “Choose file”button and use the file without UMS at the end of the file name. Then select the deal file using the third “Choose file” BUTTON to select the pbn file for the session.fileClick on the “Upload” button. You may be asked to confirm the calendar event to which these results should be attached.Now check and make sure that there are no obvious errors4.2.Save results on the G-DriveThe main reason for this is to provide a reliable backup. Only the final .xml file is needed.Go to https:///drive/u/1/folders/1U31YD5OAunlAPyyrsAvTuDJ72rJSOj8k and enter the directory corresponding to the generic session name and upload the .xml file to that directory.4.3.Upload results to PianolaThis is the last chance to make corrections without needing to ask a chief scorer to help you out.Login to Pianola and click on Results. Locate the session or choose Ad Hoc session. Now identify the XML file for UMS and also the PBN file and then click upload results.In general try to avoid using Ad Hoc sessions as they spoil the statistics which are available from Pianola.If this goes smoothly then the job is done. However if Pianola reports problems then please contact one of the Chief Scorers (***************************).4.4.To edit the results after they have been published to Pianola1.Mail***************************to ask to have the results deleted2.Go to the Bridgewebs upload area(https:///cgi-bin/bwon/bw.cgi?pid=upload_results&club=obc), login and select the “Recover” tab. Find the session and download the xml and pbn files.3.Rename the .xml file to old.xmle BBOtoXML and click on Import/Edit CSV/XML and select the old.xml file.5.Click on Edit Scores6.Find the board by using the controls at the top left.7.Click on the field you want to change - typically the number of tricks - update it and click elsewhere.8.Click on “Save as CSV” and the file appears in the downloads directory with the correct name.9.Click Go Back once (or twice) to get back to the normal screen10.Make sure the UMS charge rate and master point settings are correct.11.Don’t load a names file but generate the .xml file from the new .csv file.12.Check the new .xml file with https:///obc/xmlchk13.Upload the new .xml and the .pbn to BridgeWebs again(it should overwrite the old results) and check14.Upload the new results to Pianola once the old ones have been deletedFor problems with this document please contact*********************************Last modified: 06/05/2021。


XACML简介(beegee译稿)研究权限管理和访问控制实现原理的朋友都应该知道RBAC(Role Based Access Control),而OASIS(Organization for the Advancement of Structured Information Standards)是推动RBAC相关标准的积极组织之一。
OASIS的XACML(eXtensible Access Control Markup Language),即可扩展的访问控制高标记语言是其中重要的标准。
了解,并理解其中设计的机理对我们很有意义。
本文是对OASIS“A Brief Introduction to XACML”一文翻译的草稿。
写于此,希望可以帮助别人。
A Brief Introduction to XACML一个XACML的简介最近一次更新: March 14, 2003摘要:本文对XACML进行一个简要的介绍。
如需对XACML作更多的了解,请访问OASIS的XACML 技术委员会网站。
简要的说,XACML是一个通用的访问控制策略定义语言。
XACML提供一套语法(使用XML 定义)来管理对系统资源的访问。
A Brief Introduction to XACMLXACML简介XACML是一个OASIS标准。
该标准是一个描述(访问控制)策略语言,同时也是一个描述访问控制判断请求/应答(request/response)的语言。
当然,都是使用XML。
策略描述语言用于定义通用的访问控制需求,包括若干标准扩展点来定义新的功能、数据类型、组合逻辑等。
(访问控制判断)请求/应答描述语言使得你可以构成一个问询(query)来判断是否一个动作(action)被允许执行,并对结果进行解释。
访问请求通常包括关于请求是否被允许的问题,这个问题中包括四个参数:Permit,Deny,Indeterminate(错误发生或需要的参数值不可用,无法进行判断)和Not Applicable(该请求无法被该服务器回应)典型的机制是这样:当有人试图执行一项资源上的动作时。

Vol. 1 No. 2 September, 2006, pp. 115-121以XML為基礎的心電圖管理系統XML-based ECG Management System曾文慶中華大學生物資訊學系ttzeng@.tw蔣家正交通大學電控所博士班財團法人國泰綜合醫院新竹分院m9102045@.tw鄭涵菁中華大學生物資訊學系財團法人為恭紀念醫院急診部m09402031@.tw莊文南中華大學資訊工程學系m09302057@.tw陳朝慶中華大學資訊工程學系m9202059@.tw摘要心電圖(Electrocardiogram, ECG),是醫生用來診斷心臟疾病的最普遍方式。
心電儀輸出的方式一般分為兩種,一為紙本ECG,另一為電腦化的數位檔案。
紙本ECG將心電儀量測所得的心電訊號及相關資訊,列印在一張A4大小規格的紙上。
這是目前最普遍的輸出與存取方式,但不利於資訊交換、資料存取及數據之研究分析。
由於醫療資訊電腦化之需求,大部分的心電儀本身也具有數位化輸出的功能,但是因為商用心電儀一般採用專屬的資料格式,須有專用商業軟體才可使用,這不但增加操作成本,且不同的機型間也無法進行資料交換。
基於上述理由,本研究將商用心電儀產生的數位資料轉換成XML-ECG格式以利於資訊的交換與分析。
本研究與地區醫院合作,收集心電儀的SCP-ECG資料,解碼取得內含資訊及心臟各導程原始電位數據後,轉為符合HL7與FDA標準之XML格式,並開發XML-ECG之資料庫管理系統。
至於ECG波形閱覽及數據分析,本研究以SVG技術開發互動式SVG-ECG,一方面提供臨床醫師熟悉的傳統ECG圖形介面;另一方面,藉由SVG的互動性,提供ECG數據比對與分析之功能。
關鍵字 : 心電圖、心電圖管理系統、SCP-ECG、XML、資料庫Wen-Ching TzengDepartment of Bioinformatics, Chung Hua Universityttzeng@.twChia-Cheng ChiangDepartment of Electrical and Control Engineering, National Chiao Tung UniversityDepartment of Emergency, Cathay General Hospital, Hsinchu Branchm9102045@.twHan-Chin ChengDepartment of Bioinformatics, Chung Hua UniversityEmergency Department, Wei-Gong Memorial Hospital, Maio-Li Countym09402031@.twWen-Nan JuangDepartment of Computer Science and Information Engineering, Chung Hua Universitym09302057@.twChau-Ching ChenDepartment of Computer Science and Information Engineering, Chung Hua Universitym9202059@.twAbstractElectrocardiogram (ECG) is the most commonly used tool for diagnosis of heart-related diseases. In general, there are two types of output forms from commercial electrocardiographs: paper ECG and computerized digital format. In paper ECG, the measured electrocardiac signal and related information are printed on a sheet of A4-size paper. Paper ECG has been widely adopted as the standard output for most of commercial electrocardiographs. However, it is unfavorable for information exchange, information management, and signal analysis. To meet the requirement of hospital information system, most of modern electrocardiographs can also output digital electronic files (e-files). Nevertheless, e-files so generated are encoded in various proprietary formats. This not only increases operation cost, but hinders information exchange among different models.Due to the reasons mentioned above, this study transformed digital data obtained form commercial electrocardiographs into the XML-ECG format so that information in ECG can be conveniently exchanging and analyzed. In this study, we worked with a regional hospital, collected SCP-ECG data from electrocardiographs, and decoded SCP-ECG file to acquire raw data of 12-lead electrocardiac signal and related annotative information. The content of decoded SCP-ECG files was then transformed into the XML format based on HL7 and FDA standards. In addition, a database system for managing the XML-ECG files was developed in this study. As for browsing and analysis of ECG waveform, SVG was used to develop interactive SVG-ECG, not only providing a graphic ECG representation which is widely accepted by clinical physicians, but offering comparison and analysis of ECG data through interactivity of SVG.Keyword:ECG、ECG management system、SCP-ECG、XML、SVG、database1.Introduction自從1924年發明了心電儀,到現今數十年來,由於心電儀非侵入性且快速的特性,所以一直是心臟醫學最重要且常用的診斷工具之一[1]。

Table of ContentsAbout1 Chapter 1: Getting started with openxml2 Remarks2 Examples2 Installation of OpenXML SDK and productivity tool on your computer2 Create a new Spreadsheet with OpenXML2 Using Open XML SDK 2.5 Productivity Tool4 Chapter 2: Create New Word Document with Open XML7 Introduction7 Examples7 Hello World7 Chapter 3: How to add an image to a Word Document.10 Introduction10 Remarks10 Examples10 Add the image to the OpenXml structure10 Refer to the image in the Word Document10 Chapter 4: Insert image into an inline "inline shape" in word documents13 Introduction13 Examples13 Add the following OpenXML namespaces to your class13 Open the document and add imagePart object to reference the picture you want to insert int13 Get a reference of a Blip object13 Adding reference of the image the shapes in the template document.14 With a collection reference of all the shapes, loop through the collection.14 Credits16AboutYou can share this PDF with anyone you feel could benefit from it, downloaded the latest version from: openxmlIt is an unofficial and free openxml ebook created for educational purposes. All the content is extracted from Stack Overflow Documentation, which is written by many hardworking individuals at Stack Overflow. It is neither affiliated with Stack Overflow nor official openxml.The content is released under Creative Commons BY-SA, and the list of contributors to each chapter are provided in the credits section at the end of this book. Images may be copyright of their respective owners unless otherwise specified. All trademarks and registered trademarks are the property of their respective company owners.Use the content presented in this book at your own risk; it is not guaranteed to be correct nor accurate, please send your feedback and corrections to ********************Chapter 1: Getting started with openxml RemarksThis section provides an overview of what openxml is, and why a developer might want to use it. It should also mention any large subjects within openxml, and link out to the related topics. Sincethe Documentation for openxml is new, you may need to create initial versions of those relatedtopics.ExamplesInstallation of OpenXML SDK and productivity tool on your computerGo to the Microsoft link for the OpenXML SDK download. Click the red download button. On the next screen click the box next to OpenXMLSDKToolV25.msi and click next to begin the download. Once the download is complete, launch the OpenXMLSDKToolV25.msi and follow the instructions on the screen.The installer places the files in the following default directory:"C:\Program Files (x86)\Open XML SDK\V2.5"In this directory is a readme that explains how to use the SDK and a readme for the productivity tool.Create a new Spreadsheet with OpenXMLThis method will create a new Excel Spreadsheet. Pass in the fileName which is a full file path name.using DocumentFormat.OpenXml;using DocumentFormat.OpenXml.Packaging;using DocumentFormat.OpenXml.Spreadsheet;using System;....void Create(string fileName){using (SpreadsheetDocument document = SpreadsheetDocument.Create(fileName, SpreadsheetDocumentType.Workbook)){var relationshipId = "rId1";//build Workbook Partvar workbookPart = document.AddWorkbookPart();var workbook = new Workbook();var sheets = new Sheets();var sheet1 = new Sheet() { Name = "First Sheet", SheetId = 1, Id = relationshipId};sheets.Append(sheet1);workbook.Append(sheets);workbookPart.Workbook = workbook;//build Worksheet Partvar workSheetPart = workbookPart.AddNewPart<WorksheetPart>(relationshipId);var workSheet = new Worksheet();workSheet.Append(new SheetData());workSheetPart.Worksheet = workSheet;//add document propertiesdocument.PackageProperties.Creator = "Your Name";document.PackageProperties.Created = DateTime.UtcNow;}For this project, make sure you include the reference to DocumentFormat.OpenXml. This is located in the path specified in the Installing OpenXML Example.The spreadsheet will be created with Your Name as the Author and the first Worksheet named First Sheet.Using Open XML SDK 2.5 Productivity ToolReading the specification for the document formats in OpenXML can be a time consuming process. Sometimes you just want to see how to produce a certain feature in a word-document. The Open XML SDK 2.5 Productivity Tool for Microsoft Office (OpenXmlSdkTool.exe) does just that. Its main features are:•See the structure of a file - which xml-parts does it contain•Navigate the xml in each of these parts•Generate c#-code for producing the selected part of the document•Link to the file format specification describing more details•Document OpenXML ValidationFor a simple 'Hello world.docx' it looks like this:The pane on the left show the document-structure. The top-right pane displays the xml corresponding to the selection in the tree, and finally the bottom-right pane show some generated code for producing the xml displayed above it.This enables a very hands on way to investigate a certain feature:•Produce an example-document (fx a word-document)•Open the document in Productivity Tool•Use 'Reflect Code' to generate codeThe SDK can be downloaded from https:///en-us/download/details.aspx?id=30425 - download and install both of the msi packages. After installation use OpenXMLSdkTool.exe installed in "C:\Program Files (x86)\Open XMLSDK\V2.5\tool".Read Getting started with openxml online: https:///openxml/topic/6967/getting-started-with-openxmlChapter 2: Create New Word Document with Open XMLIntroductionThe OpenXML document markup standard is an XML based format which enables solutions on many software platforms and operating systems.ExamplesHello WorldFirst, create a new console project using Visual Studio and add the following .dlls to your project:DocumentFormat.OpenXmlWindowsBaseNext, compile and execute the following code:static void Main(string[] args){// Create a Wordprocessing document.using ( WordprocessingDocument package = WordprocessingDocument.Create("HelloWorld.docx", WordprocessingDocumentType.Document)){// Add a new main document part.package.AddMainDocumentPart();// Create the Document DOM.package.MainDocumentPart.Document =new Document(new Body(new Paragraph(new Run(new Text("Hello World!")))));// Save changes to the main document part.package.MainDocumentPart.Document.Save();}}Under your \bin\Debug folder you should have your first WordprocessingML document:The text that we added in the above example is stored under the main document part. Inside the main document part there is the document element which allows a child element body to store the text which makes our document. There are two main groups of content for the document body, block level (paragraphs and tables) and inline content (runs and text). The block level content provides the main structure and contains inline content. To understand the example above, we first need to understand the text hierarchy in WordprocessingML. A paragraph is split into different runs. A run is the lowest level element to which formatting can be applied. The run is split up again into various text elements.Read Create New Word Document with Open XML online:https:///openxml/topic/9833/create-new-word-document-with-open-xmlChapter 3: How to add an image to a Word Document.IntroductionInserting an image in a word document using OpenXml require two actions: add the image inside the openxml and refer to the image in your DocumentRemarksif you only add the image to the openxml structure without refering it in the Word Document, the next time you "open / save" your document, the image file will be deleted.Word delete all orphan references. So make sure to add the image in the Word Document otherwise you will need to redo all the steps.ExamplesAdd the image to the OpenXml structureprivate string AddGraph(WordprocessingDocument wpd, string filepath){ImagePart ip = wpd.MainDocumentPart.AddImagePart(ImagePartType.Jpeg);using (FileStream fs = new FileStream(filepath, FileMode.Open)){if (fs.Length == 0) return string.Empty;ip.FeedData(fs);}return wpd.MainDocumentPart.GetIdOfPart(ip);}In this case we use a FileStream to retrieve the image, but feedData(Stream) is waiting for any kind of Stream.Refer to the image in the Word Documentprivate void InsertImage(WordprocessingDocument wpd, OpenXmlElement parent, string filepath) {string relationId = AddGraph(wpd, filepath);if (!string.IsNullOrEmpty(relationId)){Size size = new Size(800, 600);Int64Value width = size.Width * 9525;Int64Value height = size.Height * 9525;var draw = new Drawing(new DW.Inline(new DW.Extent() { Cx = width, Cy = height },new DW.EffectExtent(){LeftEdge = 0L,TopEdge = 0L,RightEdge = 0L,BottomEdge = 0L},new DW.DocProperties(){Id = (UInt32Value)1U,Name = "my image name"},new DW.NonVisualGraphicFrameDrawingProperties(new A.GraphicFrameLocks() { NoChangeAspect = true }),new A.Graphic(new A.GraphicData(new PIC.Picture(new PIC.NonVisualPictureProperties(new PIC.NonVisualDrawingProperties(){Id = (UInt32Value)0U,Name = relationId},new PIC.NonVisualPictureDrawingProperties()),new PIC.BlipFill(new A.Blip(new A.BlipExtensionList(new A.BlipExtension() { Uri = "{28A0092B-C50C-407E-A947-70E740481C1C}" })){Embed = relationId,CompressionState =A.BlipCompressionValues.Print},new A.Stretch(new A.FillRectangle())),new PIC.ShapeProperties(new A.Transform2D(new A.Offset() { X = 0L, Y = 0L },new A.Extents() { Cx = width, Cy = height }),new A.PresetGeometry(newA.AdjustValueList()) { Preset = A.ShapeTypeValues.Rectangle }))) { Uri ="/drawingml/2006/picture" })){DistanceFromTop = (UInt32Value)0U,DistanceFromBottom = (UInt32Value)0U,DistanceFromLeft = (UInt32Value)0U,DistanceFromRight = (UInt32Value)0U,EditId = "50D07946"});parent.Append(draw);}}In this example I set a static size of 800*600 but you can set any size you need Read How to add an image to a Word Document. online:https:///openxml/topic/9397/how-to-add-an-image-to-a-word-document-Chapter 4: Insert image into an inline "inline shape" in word documentsIntroductionInsert an image into an MS Word document shapes such as Rectangles and ovals.This documentation assumes you know how to insert an image into a word document, open and close a word document using OpenXMLExamplesAdd the following OpenXML namespaces to your classusing System;using System.Collections.Generic;using System.Linq;using DocumentFormat.OpenXml;using A = DocumentFormat.OpenXml.Drawing;using DW = DocumentFormat.OpenXml.Drawing.Wordprocessing;using PIC = DocumentFormat.OpenXml.Drawing.Pictures;using DocumentFormat.OpenXml.Drawing.Wordprocessing;using Wps = DocumentFormat.OpenXml.Office2010.Word.DrawingShape;Open the document and add imagePart object to reference the picture you want to insert into the shapeNow open the document using OpenXML, you must add an imagePart that references the picture object to the MainDocumentPart object by using a file stream, and get the ID of the imagestring temp;MainDocumentPart mainPart = document.MainDocumentPart;ImagePart imagePart = mainPart.AddImagePart(ImagePartType.Bmp);using (FileStream stream = new FileStream(barcodepath,FileMode.Open)){imagePart.FeedData(stream);}temp = mainPart.GetIdOfPart(imagePart);Get a reference of a Blip objectIn office OpenXML, a picture that is inserted into a word document is considered a "Blip" Object or element. The class is derived from the DocumentFormat.OpenXml.Drawing the Blip must have an Embed value that is an imagePart ID. The Blip object then goes inside a BlipFill Object/element,and that also goes inside a graphicData Object/element and that in turn goes into a graphic object element. I'm pretty sure by now you've realized everything works like an XML tree. Sample OpenXML tree below.<a:graphic xmlns:a="/drawingml/2006/main"><a:graphicDatauri="/office/word/2010/wordprocessingShape"><wps:wsp><wps:cNvSpPr><a:spLocks noChangeArrowheads="1" /></wps:cNvSpPr><wps:spPr bwMode="auto"><a:xfrm><a:off x="0" y="0" /><a:ext cx="1234440" cy="1234440" /></a:xfrm><a:prstGeom prst="roundRect"><a:avLst><a:gd name="adj" fmla="val 16667" /></a:avLst></a:prstGeom><a:blipFill dpi="0" rotWithShape="1"><a:blip r:embed="Raade88ffea8d4c1b" /><a:stretch><a:fillRect l="10000" t="10000" r="10000" b="10000" /></a:stretch></a:blipFill></wps:spPr><wps:bodyPr rot="0" vert="horz" wrap="square" lIns="91440"tIns="45720" rIns="91440" bIns="45720" anchor="t" anchorCtr="0" upright="1"><a:noAutofit /></wps:bodyPr></wps:wsp></a:graphicData></a:graphic>Adding reference of the image the shapes in the template document.Now you have a reference of the image. Insert the image into the shapes in the templatedocument. To do this, you will have to use some LINQ to iterate through the document and get a reference to all the shapes in the document. The wps:spPr element you see in the above XMLcode is the xml element for the shapes in a document. The equivalent C# class is WordprocessingShapeIEnumerable<DocumentFormat.OpenXml.Office2010.Word.DrawingShape.WordprocessingShape> shapes2 = document.MainDocumentPart.document.Body.Descendants<DocumentFormat.OpenXml.Office2010.Word.DrawingShapeWith a collection reference of all the shapes, loop through the collection.Now that you have a collection of all the shape references in the document. Loop through thecollection with a foreach, and through each iteration create a Blip object. Set the Blip object embedvalue to the picture ID reference you captured earlier from the image part. Also create a Stretchobject, and FillRectangle object(these are not really necessary, they are just used them for properalignment of the image). And append each to its parent object like the XML tree equivalent.foreach (DocumentFormat.OpenXml.Office2010.Word.DrawingShape.WordprocessingShape sp in shapes2){//Wps.ShapeProperties shapeProperties1 =A.BlipFill blipFill1 = new A.BlipFill() { Dpi =(UInt32Value)0U, RotateWithShape = true };A.Blip blip1 = new A.Blip() { Embed = temp };A.Stretch stretch1 = new A.Stretch();A.FillRectangle fillRectangle1 = new A.FillRectangle() { Left = 10000, Top = 10000, Right = 10000, Bottom = 10000 };Wps.WordprocessingShape wordprocessingShape1 = newWps.WordprocessingShape();stretch1.Append(fillRectangle1);blipFill1.Append(blip1);blipFill1.Append(stretch1);Wps.ShapeProperties shapeProperties1 =sp.Descendants<Wps.ShapeProperties>().First();shapeProperties1.Append(blipFill1);}Read Insert image into an inline "inline shape" in word documents online:https:///openxml/topic/9660/insert-image-into-an-inline--inline--shape--in-word-documentsCredits。

winsw xml参数说明Title: Explanation of XML Parameters in WinSWIntroduction:WinSW is a wrapper executable for running Windows services. It provides an XML-based configuration file that allows users to customize and configure various aspects of the service. This article aims to explain the different parameters available in the WinSW XML configuration file and their functionalities.1. Service ID:The service ID parameter is used to uniquely identify the service. It is a user-defined string value that should be unique among all services running on the same system. This parameter is important when managing multiple services or when performing operations specific to a particular service.2. Service Name:The service name parameter specifies the display name of the service. It is the name that is visible to users in service management tools. This parameter should be set to a descriptive and meaningful name that accurately represents the purpose of the service.3. Service Description:The service description parameter allows users to provide a detailed description of the service. This description is displayed alongside the service name in service management tools and can be helpful in providing additional information about the service to users.4. Executable:The executable parameter specifies the path to the executable file that should be executed as the service. It should be set to the location of the main application or script that the service will run. Ensure that the path is correct and the file is accessible.5. Working Directory:The working directory parameter sets the current working directory for the service. It determines the location from which relative paths are resolved. It is recommended to set this parameter to the directory where the executable is located to avoid any path-related issues.6. Log Path:The log path parameter defines the location where theservice logs will be stored. It is important to set this parameter to a directory that has sufficient write permissions and enough disk space to accommodate the log files generated by the service.7. Start Mode:The start mode parameter specifies how the service should start. It can be set to "Automatic" to start the service automatically when the system starts, "Manual" to start the service only when requested, or "Disabled" to prevent the service from starting altogether.8. Dependencies:The dependencies parameter allows users to specify other services that the current service depends on. This ensures that the dependent services are started before the current service is started. It is important to provide the correct service names separated by commas.9. Service Parameters:The service parameters parameter allows users to pass additional command-line arguments to the service executable. These arguments can be used to customize the behavior of the service or provide configuration options. Ensure thatthe arguments are specified correctly and adhere to the expected format.10. Environment Variables:The environment variables parameter allows users to define custom environment variables that will be available to the service during runtime. This can be useful for providing configuration values or specifying paths needed by the service. Ensure that the variable names and values are correctly defined.Conclusion:Understanding the various XML parameters available in the WinSW configuration file is essential for customizing and configuring Windows services. By correctly setting these parameters, users can tailor the behavior and functionality of the service to meet their specific requirements. It is important to ensure that the parameters are accurately defined and adhere to the expected format to avoid any issues during service execution.。