Matlab学习系列.灰色关联分析
- 格式:docx
- 大小:91.77 KB
- 文档页数:8
灰色关联度分析法为了适应瞬息万变的市场需求, 企业不断调整自己的核心能力, 在产品的开发设计中更重视供应商的作用。
作为供应链合作关系运行的基础, 供应商的评价选择是一个至关重要的问题, 供应商的业绩对企业的影响越来越大,影响着企业的生存与发展。
因此, 进行科学全面的供应商评价就显得十分必要。
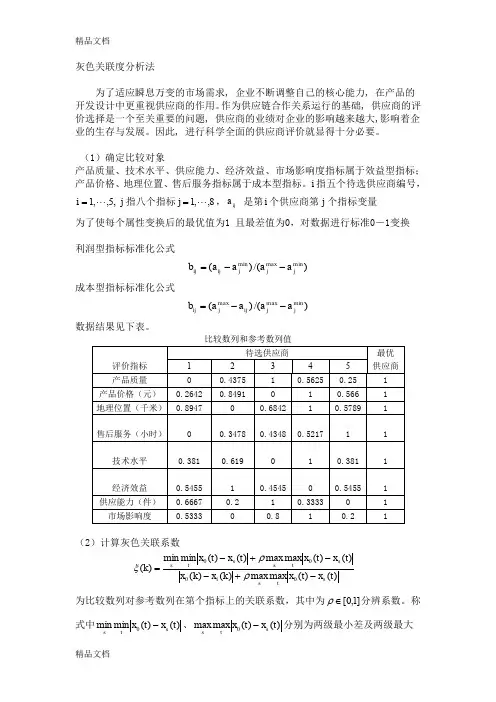
(1)确定比较对象产品质量、技术水平、供应能力、经济效益、市场影响度指标属于效益型指标;产品价格、地理位置、售后服务指标属于成本型指标。
i 指五个待选供应商编号,,5,,1 =i j 指八个指标8,,1j =,ij a 是第i 个供应商第j 个指标变量为了使每个属性变换后的最优值为1 且最差值为0,对数据进行标准0-1变换利润型指标标准化公式)/()(min maxmin j j j ij ij a a a a b --=成本型指标标准化公式)/()(min max max j j ij j ij a a a a b --=数据结果见下表。
(2)计算灰色关联系数)()(max max )()()()(max max )()(min min )(0000t x t x k x k x t x t x t x t x k s tsi s ts s ts -+--+-=ρρξ为比较数列对参考数列在第个指标上的关联系数,其中为]1,0[∈ρ分辨系数。
称式中)()(min min 0t x t x s ts-、)()(max max 0t x t x s ts-分别为两级最小差及两级最大差。
一般来讲,分辨系数ρ越大,分辨率越大;ρ越小,分辨率越小。
在这里ρ取0.5。
(3)计算灰色加权关联度 灰色加权关联度的计算公式为∑==nk i i k w r 1)(ξ这里i r 为第i 个评价对象对理想对象的灰色加权关联度。
关联系数和关联度值(4)评价分析根据灰色加权关联度的大小,对各评价对象进行排序,可建立评价对象的关联序,关联度越大其评价结果越好。

(完整版)五种灰色关联度分析matlab代码灰色邓氏关联度分析% P12 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_deng(x)s = size(x);len = s(2);num = s(1);ro = 0.5;for i = 1: numx(i,:) = x(i,:)./x(i,1);enddx(num,len) = 0;for i = 2 : numfor k = 1 : lendx(i,k) = abs(x(1,k) - x(i,k));endendmax_dx = max(max(dx));min_dx = min(min(dx));r(1,1:len-1) = 1;for i = 2 : numfor k = 1 : lenr(i,k) = (min_dx + ro*max_dx)/(dx(i,k) + ro*max_dx);endendr1 = sum(r(2:num,:),2)/(len);改进灰色绝对关联度分析% P11 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_gjjd(x)s = size(x);len = s(2);num = s(1);for i = 1: numx(i,:) = x(i,:)./x(i,1);enddx(num,len-1) = 0;for i = 1 : numfor j = 1 : len - 1dx(i,j) = x(i,j+1) - x(i,j);endendc = 1;beta(1,1:len-1) = 0;w(1,1:len-1) = 0;for i = 2 : numtemp = sum(abs(x(i,:) - x(1,:)),2);for k = 1 : len - 1beta(i,k) = atan((dx(i,k) - dx(1,k))/(1 + dx(i,k)*dx(1,k)));if beta(i,k) < 0beta(i,k) = pi + beta(i,k);endw(i,k) = 1 - abs(x(i,k) - x(1,k))/temp;endendr = c./(c + tan(beta./2));wr = w.*r;r1 = sum(wr(2:num,:),2)/(len - 1);灰色绝对关联度分析% P18 -- The Study on the Grey Relational Degree and ItsApplication function r1 = gld_jd(x)s = size(x);len = s(2);num = s(1);for i = 1: numx(i,:) = x(i,:)./x(i,1);enddx(num,len-1) = 0;for i = 1 : numfor j = 1 : len - 1dx(i,j) = x(i,j+1) - x(i,j);endendr(1,1:len-1) = 1;for i = 2 : numfor k = 1 : len - 1r(i,k) = 1/(1 + abs(dx(1,k) - dx(i,k)));endendr1 = sum(r(2:num,:),2)/(len - 1);灰色T型关联度分析% P19 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_t(x)s = size(x);len = s(2);num = s(1);dx(num,len-1) = 0;for i = 1 : numfor j = 1 : len - 1dx(i,j) = abs(x(i,j+1) - x(i,j));d_x = sum(dx(i,:),2)/(len - 1);x(i,:) = x(i,:)./d_x;enddx(num,len-1) = 0;for i = 1 : numfor j = 1 : len - 1dx(i,j) = x(i,j+1) - x(i,j);endendr(1,1:len-1) = 1;for i = 2 : numfor k = 1 : len - 1if dx(1,k)*dx(i,k) == 0r(i,k) = sign(dx(1,k)*dx(i,k));elser(i,k) = sign(dx(1,k)*dx(i,k))*min(abs(dx(1,k)),abs(dx(i,k))) / max(abs(dx(1,k)),abs(dx(i,k)));endendendr1 = sum(r(2:num,:),2)/(len - 1);灰色斜率关联度分析% P20 -- The Study on the Grey Relational Degree and Its Application function r1 = gld_xl(x)s = size(x);len = s(2);num = s(1);for i = 1: numx(i,:) = x(i,:)./x(i,1);dx(num,len-1) = 0;for i = 1 : numfor j = 1 : len - 1dx(i,j) = x(i,j+1) - x(i,j);endendr(1,1:len-1) = 1;for i = 2 : numfor k = 1 : len - 1r(i,k) = 1/(1 + abs(dx(1,k)/x(1,k+1) - dx(i,k)/x(i,k+1))); endendr1 = sum(r(2:num,:),2)/(len - 1);。

灰色关联分析法灰色关联分析法是一种用于研究多个指标之间相关性的统计方法。
它通过计算不同指标之间的关联度来确定它们之间的关系强度。
本文将介绍灰色关联分析法的原理、应用领域以及优点和局限性。
灰色关联分析法最早由中国科学家陈进才于1981年提出,并广泛应用于工程和管理学科领域。
它的核心思想是通过将不同的指标序列转化为灰色级数形式,然后计算各指标之间的关联系数,以揭示它们之间的关系。
灰色关联分析法的基本步骤包括:首先,将各指标序列归一化,使得数据位于相同的量纲范围内;其次,构建灰色级数模型,将指标序列转化为灰色级数;然后,计算各指标之间的关联系数,确定关联度;最后,利用关联度进行综合评价,得出最终的结论。
灰色关联分析法在许多领域具有广泛的应用。
在经济管理领域,它可以用于评估企业绩效、判断市场趋势、研究产业发展等。
在工程领域,它可以用于分析工艺参数对产品质量的影响、评估设备可靠性等。
在环境科学领域,它可以用于评估生态环境质量、分析污染物传输和扩散等。
灰色关联分析法具有一些优点。
首先,它可以对多指标间的关联进行定量分析,较为客观地反映指标之间的关系。
其次,它适用于小样本数据的分析,不依赖于大样本假设。
此外,它对序列变化的敏感性较高,能够较好地发现序列间的规律性或趋势。
然而,灰色关联分析法也存在一些局限性。
首先,它对数据的要求较高,需要有较为完整的时间序列数据。
其次,它假设指标之间的关系是线性的,对非线性关系的分析有一定局限性。
此外,灰色关联分析法对指标权重的确定也有一定的主观性,可能引入一定的误差。
综上所述,灰色关联分析法作为一种多指标关联分析方法,在多个领域得到了广泛应用。
它通过计算不同指标之间的关联程度,为决策提供了科学的依据。
然而,使用灰色关联分析法时需要充分考虑相关因素,避免误导决策。
未来,随着数据技术的不断发展,灰色关联分析方法也将继续完善和应用于更多的领域中。


灰色关联分析灰色关联分析是一种常用于研究和预测多个影响因素之间关联程度的方法。
该分析方法可以通过对各个因素的数值进行比较,得出它们之间的关联强度,从而为决策提供依据。
下面将详细介绍灰色关联分析的原理、应用以及优势。
灰色关联分析的原理基于灰色系统理论,该理论是中国科学家陈纳德于1982年提出的一种对部分已知和部分未知信息进行分析的数学方法。
灰色关联分析将各个影响因素的数据进行标准化处理,然后计算各个因素之间的关联度。
通过对关联度进行排序,即可得出影响因素之间的关联程度大小。
灰色关联分析在各个领域都有广泛的应用,比如经济学、管理学、环境科学等。
在经济学领域,可以使用灰色关联分析来研究不同经济指标之间的关联程度,从而预测未来的经济趋势。
在管理学中,可以利用灰色关联分析来研究不同管理指标之间的关联程度,进而指导管理决策。
在环境科学领域,可以运用灰色关联分析来分析各个环境因素对生态系统的影响程度,以及控制污染等。
灰色关联分析相对于其他分析方法有一些独特的优势。
首先,它不要求数据分布满足正态分布等数学假设,可以对数据进行较好的处理。
其次,灰色关联分析可以处理样本量较小的情况,对于样本量不足的数据分析也有较好的适用性。
此外,由于灰色关联分析能够捕捉到数据之间的内在联系,因此对于某些非线性关系的分析,其结果可能更加准确。
然而,灰色关联分析也存在一些限制和不足之处。
首先,该分析方法依赖于数据的稳定性,对于非稳态的数据可能会导致分析结果不准确。
其次,灰色关联分析无法处理存在时间滞后效应的数据。
此外,该方法对数据的标准化要求较高,如果数据质量较差或者存在异常值,也会影响分析结果。
综上所述,灰色关联分析是一种研究和预测多个影响因素之间关联程度的有效方法。
它的原理基于灰色系统理论,可以在各个领域中广泛应用。
灰色关联分析相对于其他分析方法有一些独特的优势,但也存在一定限制。
在实际应用中,我们应该结合具体情况,合理选择分析方法,并充分考虑其适用性和局限性,以提高分析和决策的准确性。

灰色关联度公式灰色关联度分析方法是一种多因素间的关联度分析方法,适用于各种多因素间的关联度分析问题。
该方法在解决多因素间的关联度分析问题时,不需要事先建立准确的模型,也不需要事先明确各因素之间的关系,只需要给出各因素对应的历史数据序列即可。
灰色关联度公式是灰色关联度分析方法的核心,它通过比较多个因素的发展规律,评估它们之间的关联程度。
灰色关联度公式如下:$$\rho_ij = \frac{{min|y_{0i} - y_{0j}| + \Delta }}{{max|y_{0i} - y_{0j}| + \Delta }}$$其中,$\rho_ij$表示第$i$个因素和第$j$个因素的关联度,$y_{0i}$和$y_{0j}$分别表示第$i$个因素和第$j$个因素的数据序列,$\Delta$是关联度分析中的常数,用于处理零值和负值。
通过计算灰色关联度公式,可以得到各个因素间的关联度,从而进行比较和排序。
关联度越高,说明因素间的关联程度越大,反之,关联度越低,说明因素间的关联程度越小。
在实际应用中,灰色关联度分析方法常用于评估各种指标的综合质量,分析影响因素的重要性,确定影响因素的权重等。
下面是一些常见的应用场景和参考内容:1. 经济分析:可以使用灰色关联度分析方法分析影响经济增长的各个因素之间的关联程度,如GDP、消费水平、投资等因素间的关联度。
2. 产业分析:可以使用灰色关联度分析方法分析不同产业之间的关联程度,评估各个产业在整体产业结构中的重要性。
3. 市场营销:可以使用灰色关联度分析方法分析市场营销活动中各个因素的关联度,评估不同市场营销策略的效果。
4. 环境评价:可以使用灰色关联度分析方法评估环境影响因素之间的关联程度,确定主要的环境影响因素和其权重。
5. 工程管理:可以使用灰色关联度分析方法分析工程进度、质量、成本等因素之间的关联度,确定影响工程管理的主要因素和其权重。
总之,灰色关联度分析方法通过灰色关联度公式,可以帮助我们评估多个因素间的关联程度,并为决策提供依据。

灰色关联分析灰色关联分析(Grey Relational Analysis, GRA)什么是灰色关联分析灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度[1]。
灰色系统理论是由著名学者邓聚龙教授首创的一种系统科学理论(Grey Theory),其中的灰色关联分析是根据各因素变化曲线几何形状的相似程度,来判断因素之间关联程度的方法。
此方法通过对动态过程发展态势的量化分析,完成对系统内时间序列有关统计数据几何关系的比较,求出参考数列与各比较数列之间的灰色关联度。
与参考数列关联度越大的比较数列,其发展方向和速率与参考数列越接近,与参考数列的关系越紧密。
灰色关联分析方法要求样本容量可以少到4个,对数据无规律同样适用,不会出现量化结果与定性分析结果不符的情况。
其基本思想是将评价指标原始观测数进行无量纲化处理,计算关联系数、关联度以及根据关联度的大小对待评指标进行排序。
灰色关联度的应用涉及社会科学和自然科学的各个领域,尤其在社会经济领域,如国民经济各部门投资收益、区域经济优势分析、产业结构调整等方面,都取得较好的应用效果。
[2]关联度有绝对关联度和相对关联度之分,绝对关联度采用初始点零化法进行初值化处理,当分析的因素差异较大时,由于变量间的量纲不一致,往往影响分析,难以得出合理的结果。
而相对关联度用相对量进行分析,计算结果仅与序列相对于初始点的变化速率有关,与各观测数据大小无关,这在一定程度上弥补了绝对关联度的缺陷。
[2]灰色关联分析的步骤[2]灰色关联分析的具体计算步骤如下:第一步:确定分析数列。
确定反映系统行为特征的参考数列和影响系统行为的比较数列。
反映系统行为特征的数据序列,称为参考数列。
影响系统行为的因素组成的数据序列,称比较数列。
设参考数列(又称母序列)为Y={Y(k) | k = 1,2,Λ,n};比较数列(又称子序列)X i={X i(k)| k = 1,2,Λ,n},i = 1,2,Λ,m。

灰色关联分析灰色关联分析是指对一个系统发展变化态势的定量描述和比较的方法,其基本思想是通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度[1]。
灰色系统理论是由著名学者邓聚龙教授首创的一种系统科学理论(Grey Theory),其中的灰色关联分析是根据各因素变化曲线几何形状的相似程度,来判断因素之间关联程度的方法。
此方法通过对动态过程发展态势的量化分析,完成对系统内时间序列有关统计数据几何关系的比较,求出参考数列与各比较数列之间的灰色关联度。
与参考数列关联度越大的比较数列,其发展方向和速率与参考数列越接近,与参考数列的关系越紧密。
灰色关联分析方法要求样本容量可以少到4个,对数据无规律同样适用,不会出现量化结果与定性分析结果不符的情况。
其基本思想是将评价指标原始观测数进行无量纲化处理,计算关联系数、关联度以及根据关联度的大小对待评指标进行排序。
灰色关联度的应用涉及社会科学和自然科学的各个领域,尤其在社会经济领域,如国民经济各部门投资收益、区域经济优势分析、产业结构调整等方面,都取得较好的应用效果。
[2]关联度有绝对关联度和相对关联度之分,绝对关联度采用初始点零化法进行初值化处理,当分析的因素差异较大时,由于变量间的量纲不一致,往往影响分析,难以得出合理的结果。
而相对关联度用相对量进行分析,计算结果仅与序列相对于初始点的变化速率有关,与各观测数据大小无关,这在一定程度上弥补了绝对关联度的缺陷。
[2]灰色关联分析的步骤[2]灰色关联分析的具体计算步骤如下:第一步:确定分析数列。
确定反映系统行为特征的参考数列和影响系统行为的比较数列。
反映系统行为特征的数据序列,称为参考数列。
影响系统行为的因素组成的数据序列,称比较数列。
设参考数列(又称母序列)为Y={Y(k) | k= 1,2,Λ,n};比较数列(又称子序列)X i={X i(k) | k= 1,2,Λ,n},i= 1,2,Λ,m。


灰色关联分析简介灰色关联分析是一种用于评估多个因素之间相关性的统计分析方法。
它可以帮助我们理解一组因素对于某个指标的影响程度,并且可以用来预测未来的趋势。
原理灰色关联分析基于灰色理论,其核心思想是将样本数据转化为灰色数列,然后通过计算灰色相关度来评估因素之间的关联性。
在灰色关联分析中,我们首先需要确定一个参考数列和一个比较数列,然后根据数列的发展趋势和规律性对它们进行排序。
最后,通过计算两个数列之间的关联度来评估它们之间的关联程度。
灰色关联度的计算方法灰色关联度可以通过以下公式计算:$$ \\rho(i,j) = \\frac{{\\min(\\Delta^*+(k-1)\\Delta^*,\\Delta^*+\\delta^*+(k-1)\\Delta^*,\\Delta^*-\\delta^*+(k-1)\\Delta^*)}}{{\\max(\\Delta^*+(k-1)\\Delta^*,\\Delta^*+\\delta^*+(k-1)\\Delta^*,\\Delta^*-\\delta^*+(k-1)\\Delta^*)}} $$其中,$\\Delta^*$表示相邻数据的差值绝对值的最大值,$\\delta^*$表示数列中数据的最大值与最小值之差。
灰色关联分析步骤1.数据预处理:将原始数据进行标准化处理,使其具有可比性。
2.建立关联矩阵:根据参考数列和比较数列计算灰色关联度,并构建关联矩阵。
3.确定权重:根据关联矩阵的行列和大小确定各因素的权重,权重越大表示因素对目标的影响越大。
4.计算综合关联度:将灰色关联度与权重相乘并求和,得到各个因素的综合关联度。
5.分析结果:根据综合关联度的大小对因素进行排序和评估,得出各因素对目标的贡献程度。
适用领域灰色关联分析在许多领域都有广泛的应用,包括经济、环境、工程等。
它可以用于评估多个因素对某个现象的影响程度,帮助决策者制定合理的决策和策略。
优势与局限灰色关联分析具有以下优势:•可以在样本数据不完整或不完全的情况下进行分析。

灰色关联分析法对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。
在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。
因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
应用于综合评价(灰色综合评价)步骤:(1) 确定比较对象(评价对象)和参考数列(评价标准)。
设评价对象有m 个,评价指标有n 个,参考数列为{}00()|1,2,,x x k k n ==⋅⋅⋅,比较数列为{}()|1,2,,,1,2,,i i x x k k n i m ==⋅⋅⋅=⋅⋅⋅。
(2) 对参考数列和比较数列进行无量纲化处理由于系统中各因素的物理意义不同,导致数据的量纲也不一定相同,不便于比较,或在比较时难以得到正确的结论。
因此在进行灰色关联度分析时,一般都要进行无量纲化的数据处理。
设无量纲化后参考数列为{}00()|1,2,,x x k k n ''==⋅⋅⋅,无量纲化后比较数列为{}()|1,2,,,i i x x k k n ''==⋅⋅⋅1,2,,i m =⋅⋅⋅。
(3) 确定各指标值对应的权重。
可用层次分析法等确定各指标对应的权重[]12,,,n w w w w =⋅⋅⋅,其中(1,2,,)k w k n =⋅⋅⋅为第k 个评价指标对应的权重。
(4) 计算灰色关联系数:0000min min ()()max max ()()()()()max max ()()s s s t s t i i s s tx t x t x t x t k x k x k x t x t ρξρ''''-+-=''''-+- 为比较数列i x 对参考数列0x 在第k 个指标上的关联系数,其中[]0,1ρ∈为分辨系数,称0min min ()()s s t x t x t ''-、0max max ()()s s tx t x t ''-分别为两级最小差及两级最大差。
灰色关联度matlab源程序最近几天一直在写算法,其实网上可以下到这些算法的源程序的,但是为了搞懂,搞清楚,还是自己一个一个的看了,写了,作为自身的积累,而且自己的的矩阵计算类库也迅速得到补充,以后关于算法方面,基本的矩阵运算不用再重复写了,挺好的,是种积累,下面把灰关联的matlab程序与大家分享。
灰色关联度分析法是将研究对象及影响因素的因子值视为一条线上的点,与待识别对象及影响因素的因子值所绘制的曲线进行比较,比较它们之间的贴近度,并分别量化,计算出研究对象与待识别对象各影响因素之间的贴近程度的关联度,通过比较各关联度的大小来判断待识别对象对研究对象的影响程度。
关联度计算的预处理,一般初值化或者均值化,根据我的实际需要,本程序中使用的是比较序列与参考序列组成的矩阵除以参考序列的列均值等到的,当然也可以是其他方法。
%注意:由于需要,均值化方法采用各组值除以样本的各列平均值clear;clc;yangben=[47.924375 25.168125 827.4105438 330.08875 1045.164375 261.37437516.3372 6.62 940.2824 709.2752 962.1284 84.87455.69666667 30.80333333 885.21 275.8066667 1052.42 435.81]; %样本数据fangzhen=[36.27 14.59 836.15 420.41 1011.83 189.5464.73 35.63 755.45 331.32 978.5 257.8742.44 23.07 846 348.05 1025.4 296.6959.34 39.7 794.31 334.63 1016.4 317.2752.91 17.14 821.79 306.92 1141.94 122.044.21 4.86 1815.52 2584.68 963.61 0.006.01 2.43 1791.61 2338.17 1278.08 30.873.01 1.58 1220.54 956.14 1244.75 3.9125.65 7.42 790.17 328.88 1026.01 92.82115.80 27 926.5 350.93 1079.49 544.3812.63 8.75 1055.50 1379.00 875.10 1.65]; %待判数据[rows,cols]=size(fangzhen);p=0.5; %分辨系数[m,n]=size(yangben);R=[];for irow=1:rowsyy=fangzhen(irow,:);data=[yy;yangben];data_gyh1=mean(yangben)for i=1:m+1for j=1:ndata_gyh(i,j)=data(i,j)/data_gyh1(j);endendfor i=2:m+1for j=1:nDij(i-1,j)=abs(data_gyh(1,j)-data_gyh(i,j));endendDijmax=max(max(Dij));Dijmin=min(min(Dij));for i=1:mfor j=1:nLij(i,j)=(Dijmin+p*Dijmax)/(Dij(i,j)+p*Dijmax);endendLijRowSum=sum(Lij');for i=1:mRij(i)=LijRowSum(i)/n;endR=[R;Rij];endRmatlab求灰色关联度矩阵源代码2010-12-11 22:57function greyrelationaldegree(X,c)%GRAYRELATIONALDEGREE this function is used for calculating the gery%relation between squence%rememeber that the first column of the input matrix is the desicion%attribution squences.what we want to calculate is the grey ralational degree between%it and other attributions%X is the squence matrix, c is the parameter used in the function%in most of the time, the value of c is 0.5firstrow = X(1,:);reci_firstrow = 1./firstrow;reci_convert = diag(reci_firstrow);initialMIRROR = X*reci_convert;% find the initial value mirror of the sequce matrix A = initialMIRROR'[nrow,ncolumn] = size(A);for (i=2:nrow)C = A(i,:)-A(1,:)D=abs(C);eval(['B' num2str(i) '=D']);amax = max(eval(['B' num2str(i)]))amin = min(eval(['B' num2str(i)]))maxarray(i-1)=amaxminarray(i-1)=aminend %find the difference squence and the max value and min value of each squencemaxmax = max(maxarray)minmin = min(minarray)for(i=2:nrow)for(j=1:ncolumn)eval(['greyrelationdegree' num2str(i) '(j)=(minmin+c*maxmax)/(B' num2str(i) '(j)+c*maxmax)'])endend % calculate the greyralational degree of each datafor(i=2:nrow)eval(['greyrelatioanaldegree_value' num2str(i) '= mean (greyrelationdegree'num2str(i) ')' ])end基于matlab灰色关联度计算的实现2006年07月28日星期五上午 11:06function r=incident_degree(x0,x1)%compute the incident degree for grey model.%Designed by NIXIUHUI,Dalian Fisher University.%17 August,2004,Last modified by NXH at 21 August,2004%数据初值化处理x0_initial=x0./x0(1);temp=size(x1);b=repmat(x1(:,1),[1 temp(2)]);x1_initial=x1./b;%分辨系数选择K=0.1;disp('The grey interconnect degree is: ');x0_ext=repmat(x0_initial,[temp(1) 1]);contrast_mat=abs(x0_ext-x1_initial);delta_min=min(min(contrast_mat));%delta_min在数据初值化后实际为零delta_max=max(max(contrast_mat));a=delta_min+K*delta_max;incidence_coefficient=a./(contrast_mat+K*delta_max);%得到关联系数r=(sum(incidence_coefficient'))'/temp(2); %得到邓氏面积关联度我们根据图1的步骤和图2的数据进行编程实现,程序如下:%清除内存空间等clear;close all;clc;%载入源数据%其实这里可以载入execl表格的n=15; %参与评价的人数m=4; %参与评价的指标个数X_0=zeros(n,m); % 数据矩阵X_2=zeros(n,m); %偏差结果的求取矩阵X_3=zeros(n,m); % 相关系数计算矩阵a1_0=[13 18 17 18 17 17 18 17 13 17 18 13 18 13 18];a2_0=[18 18 17 17 18 13 17 13 18 13 17 13 13 17 17];a3_0=[48.67 43.33 43.56 41.89 39.47 43.44 37.97 41.14 39.67 39.83 34.11 40.58 34.19 30.75 21.22];a4_0=[10 10.7 3 5.4 5.4 0.7 4.2 0.5 9.3 0.85 2.9 5.45 4.2 2.7 6]; %指标数X_1=[a1_0',a2_0',a3_0',a4_0']; %最后使用到的数据矩阵%1 寻找参考列x0=[max(a1_0),max(a2_0),max(a3_0),max(a4_0)]; %取每列的最大值(指标的最大值)%2 计算偏差结果i=1;while(i~=m+1) %为什么这个地方会出问题呢for j=1:1:nX_2(j,i)=abs(X_1(j,i)-x0(i));i=i+1;end%3 确定偏差的最值error_min=min(min(X_2));error_max=max(max(X_2));%4 计算相关系数i=1;p=0.5;while(i~=m+1)for j=1:1:nX_3(j,i)=(error_min+p*error_max)/(X_2(j,i)+p*error_max);end;i=i+1;end%X_3 %可以在此观察关联矩阵%5 计算各个学生的关连序a=zeros(1,n);for j=1:1:nfor i=1:1:ma(j)=a(j)+X_3(j,i); %%%%其实可以直接用suma(j)=a(j)/m; %%%%%%%%%可以改进%%%%%%%%%%1 2 3 下一页%end%a %在此可以观测各个学生的序%改进:如果各个指标的所占权重不一样的话,可以添加相应的权系数%6 排序b=a';[c,s]=sort(b);for i=1:1:nd(i)=i;endd=d';result=[d b c s]%7 将结果显示出来figure(1);plot(a);figure(2)bar(a); %柱状图最后所得到的结果如图3到图5所示。
灰色关联度分析法引言灰色关联度分析法是一种用于揭示变量之间关联程度的方法。
它可以在缺乏足够数据的情况下,通过对变量之间的相关性进行评估,帮助分析人员做出决策。
在本文中,我们将介绍灰色关联度分析法的原理和应用,并探讨其在实际问题中的价值和局限性。
一、灰色关联度分析法的原理灰色关联度分析法是在灰色系统理论基础上发展起来的一种关联性分析方法。
灰色关联度分析法的核心思想是通过模糊度量的方法,将样本数据的数量化描述量和次序特征结合起来,通过计算变量间的关联度,得出它们之间的相关性。
具体而言,灰色关联度分析法的步骤主要包括以下几个方面:1. 数据标准化:将原始数据进行归一化处理,以消除变量之间的量纲差异,使其具有可比性。
2. 确定参考序列:在给定的多个序列中,根据研究目标和实际需求,选择一个作为参考序列,其他序列将与之进行比较。
3. 计算关联度指数:通过计算每个序列与参考序列之间的关联度指数,来评估它们之间的关联程度。
关联度指数的计算通常有多种方法,如灰色关联度、相对系数法等。
4. 判别等级:根据关联度指数的大小,将序列划分为几个等级,以便更直观地评估变量之间的关联程度。
二、灰色关联度分析法的应用灰色关联度分析法在许多领域和问题中都有广泛的应用。
下面将介绍一些典型的应用情况:1. 经济领域:灰色关联度分析法可以用于评估经济指标之间的关联性,识别影响经济发展的主要因素,帮助政府和企业做出相应的调整和决策。
2. 工业制造业:在工业制造领域,灰色关联度分析法可以用于优化生产工艺,提高产品质量,降低成本。
通过分析不同因素对产品质量的影响程度,可以找出关键因素,并制定相应的改进措施。
3. 市场调研:在市场调研中,灰色关联度分析法可以用于分析消费者行为和市场趋势,预测产品的需求量和销售额。
通过对多个变量之间的关联性进行评估,可以为企业的市场营销决策提供有价值的参考和支持。
4. 环境管理:在环境管理领域,灰色关联度分析法可以用于评估各种环境因素对生态系统的影响程度,为环境保护和可持续发展提供科学依据。
灰色关联度分析法
灰色关联度分析法(Grey Relational Analysis,GRA)是一种多属性
决策分析的统计方法,是一个在变量未知情况下实现系统模型和控制
不确定性的有用工具。
灰色关联度分析法主要用于研究和分析影响多
维度多属性数据测量结果的各种因素之间的相关关系。
它对模糊数据
进行综合处理,可以把多维评价分解成基本的准则来实现。
灰色关联度分析法的原理是利用灰色关联度的基本定义来衡量某种系
统的相关程度,灰色关联度通过确定系统的相似度和差异度来计算相
关程度,以此作为最终判断结果。
首先,将所有系统样本的信息表示
成一维度序列,并计算各时间点的灰色关联度。
其次,将灰色关联度
转化成定量指标,以此确定每一种系统的相关程度。
最后,根据定量
指标的值,把每一种系统分成几个类,以便于进一步分析和研究。
灰色关联度分析法可以应用于多种领域,例如工程设计、产品设计、
资源调配等。
例如,当进行工程设计时,可以利用灰色关联度分析法,通过灰色关联度来考虑多种参数和因素,以便最大限度地满足工程项
目的要求。
总之,灰色关联度分析法是一种有效的多属性决策分析方法,在许多
领域得到了广泛的应用,对于多维度和多属性问题具有显著优势。
有
效地利用灰色关联度分析法,能够更好地实现系统模型和控制不确定性,有助于优化效率和提高决策水平。
matlab灰色关联度计算
灰色关联度计算是一种用于分析变量之间关联程度的方法,常用于数据挖掘和预测分析中。
在MATLAB中,可以通过以下步骤进行灰色关联度计算:
1. 数据准备,首先,准备好需要分析的数据,确保数据的准确性和完整性。
2. 数据预处理,对数据进行预处理,包括数据清洗、归一化等操作,以便进行后续的灰色关联度计算。
3. 灰色关联度计算函数,MATLAB提供了灰色关联度计算的相关函数,例如graycoprops和graycomatrix等。
你可以使用这些函数来计算数据之间的灰色关联度。
4. 灰色关联度分析,利用灰色关联度计算函数,对数据进行灰色关联度分析,得到变量之间的关联度值。
5. 结果展示,最后,可以将灰色关联度分析的结果进行可视化展示,例如绘制关联度矩阵图或者相关性曲线图,以便更直观地理
解变量之间的关联程度。
需要注意的是,灰色关联度计算涉及到一些数学和统计知识,因此在进行计算时需要对数据和算法有一定的理解和把握。
希望这些步骤能够帮助你在MATLAB中进行灰色关联度计算。
28. 灰色关联分析
一、灰色系统理论简介
若系统的内部信息是完全已知的,称为白色系统;若系统的内部信息是一无所知(一团漆黑),只能从它同外部的联系来观测研究,这种系统便是黑色系统;灰色系统介于二者之间,灰色系统的一部分信息是已知的,一部分是未知的。
灰色系统理论以“部分信息已知、部分信息未知”的“小样本”、“贫信息”不确定型系统为研究对象,其特点是:
(1)认为不确定量是灰数,用灰色数学来处理不确定量,使之量化,灰色系统理论只需要很少量的数据序列;
(2)观测到的数据序列看作随时间变化的灰色量或灰色过程,通过鉴别系统因素之间发展趋势的相似或相异程度,即进行关联度分析;
(3)通过累加生成和累减生成逐步使灰色量白化,从而建立相应于微分方程解的模型,从而预测事物未来的发展趋势和未来状态。
二、灰色关联度分析
1. 要定量地研究两个事物间的关联程度,可以用相关系数和相似系数等,但这需要足够多的样本数或者要求数据服从一定概率分布。
在客观世界中,有许多因素之间的关系是灰色的,分不清哪些因素之间关系密切,哪些不密切,这样就难以找到主要矛盾和主要特性。
灰因素关联分析,目的是定量地表征诸因素之间的关联程度,从而揭示灰色系统的主要特性。
关联分析是灰色系统分析和预测的基础。
关联分析源于几何直观,实质上是一种曲线间几何形状的分析比较,即几何形状越接近,则发展变化趋势越接近,关联程度越大。
如下图所示:
x
t
曲线A 与B 比较平行,则认为A 与B 的关联程度大;曲线C 与A 随时间变化的方向很不一致,则认为A 与C 的关联程度较小;曲线A 与D 相差最大,则认为两者的关联程度最小。
2. 关联度分析是分析系统中各因素关联程度的方法
步骤:
(1) 计算关联系数
设参考序列为
0000{(1),(2),...,()}X x x x n =
比较序列为
{(1),(2),...,()}, 1,,i i i i X x x x n i m ==
比较序列X i 对参考序列X 0在k 时刻的关联系数定义为:
0000min min ()() max max ()()()()() max max ()()s s s t s t
i i s s t
x t x t x t x t k x k x k x t x t ρηρ-+-=-+- 其中,0min min ()()s s t
x t x t -和0max max ()()s s t x t x t -分别称为两级最小差、两级最大差,[0,1]ρ∈称为分辨系数,ρ越大分辨率越大,一般采用0.5ρ=
对单位不一,初值不同的序列,在计算关联系数之前应首先进行初值化,即将该序列的所有数据分别除以第一数据,将变量化为无单位的相对数值。
注1:若数据是负向数据(越小越好),初值化时要取倒数,即用第一数据除以该所有数据;
注2:也可以数据均值化,所有数据都除以均值;也可以数据百分比化,所有数据都除以最大值;也可以数据归一化。
(2) 计算关联度
关联系数只表示了各个时刻参考序列和比较序列之间的关联程度,为了从总体上了解序列之间的关联程度,必须求出它们的时间平均值,即关联度:
1
1()n
i i k r k n η==∑ 注:若各指标有不同的权重,可以对i η进行加权平均,得到灰色
加权关联度。
例1对某健将级女子铅球运动员的跟踪调查,获得其1982 年至1986 年每年最好成绩及16项专项素质和身体素质的时间序列资料:
做灰色关联度分析,看哪些指标与铅球成绩关联度更高?从而进行更加有针对性的训练。
代码:
data=xlsread('data28_1.xlsx');
x=data(:,2:18);
%初始化数据
for i=1:15
x(:,i)=x(:,i)/x(1,i);
end
for i=16:17
x(:,i)=x(1,i)./x(:,i);
end
n=size(x,1); %序列元素个数
ck=x(:,1); %提取参考序列
bj=x(:,2:end); %提取比较序列
m=size(bj,2);
for j=1:m %每个比较序列与参考序列作差
t(:,j)=bj(:,j)-ck;
end
min2=min(min(abs(t))); %求两级最小差
max2=max(max(abs(t))); %求两级最大差
rho=0.5; %分辨系数
eta=(min2+rho*max2)./(abs(t)+rho*max2); %求关联系数
r=mean(eta) %求关联度
[rs,rind]=sort(r,'descend') %对关联度从大到小排序
运行结果:
r = 0.5881 0.6627 0.8536 0.7763 0.8549 0.5022 0.6592 0.5820 0.6831 0.6958 0.8955 0.7047 0.9334 0.8467 0.7454 0.7261
rs = 0.9334 0.8955 0.8549 0.8536 0.8467 0.7763 0.7454 0.7261 0.7047 0.6958 0.6831 0.6627 0.6592 0.5881 0.5820 0.5022
rind =
13 11 5 3 14 4 15 16 12 10 9 2 7 1 8 6
结果表明,影响铅球专项成绩的前8项主要因素依次为:全蹲x13,3kg滑步x11,高翻x5,4kg原地x3,挺举x14,立定跳远x4,
30米起跑x15,100米x16.
三、优势分析
当参考序列不止一个,比较序列也不止一个时,需要进行优势分析。
设有m个参考序列(母因素),记为y1, …, y m
有l个比较序列(子因素),记为x1, …, x l
则这l个比较序列对每一个参考序列都有l个关联度,记r ij表示比较序列x j对参考序列y i的关联度,可得到关联度矩阵R=(r ij)m×l 根据矩阵R的各元素的大小,可分析判断出哪些因素起主要影响(优势因素),哪些因素起次要影响;进一步,当某一列元素大于其他列元素时,称此列对应的因素为优势子因素;若某一行元均大于其他行元素时,称此行所对应的母因素为优势母因素。
若矩阵R的某个元素达到最大,则该行对应的母因素被认为是所有母因素中影响最大的。
注:为了便于分析,常将较小的元素近似为0.
例2某地区有5个子因素,6个母因素:
x1:固定资产投资y1:国民收入
x2:工业投资y2:工业收入
x3:农业投资y3:农业收入
x4:科技投资y4:商业收入
x5:交通投资y5:交通收入
y6:建筑业收入
其数据见下表:
代码:
data=xlsread('data28_2.xlsx');
x=data(:,2:end);
[m,n]=size(x); %m为观测时刻数; n为所有因素的个数
%初值化数据
for i=1:n
x(:,i)=x(:,i)/x(1,i);
end
s1=6; %母因素个数
s2=5; %子因素个数ý
mu=x(:,s2+1:end); %提取母因素
zi=x(:,1:s2); %提取子因素
for i=1:s1
%对每个母因素, 分别计算子因素关于它的关联度, 作为关联度矩阵的1行for j=1:s2
t(:,j)=zi(:,j)-mu(:,i);
end
min2=min(min(abs(t)));
max2=max(max(abs(t)));
rho=0.5;
eta=(min2+rho*max2)./(abs(t)+rho*max2);
R(i,:)=mean(eta);
end
R
运行结果:
R = 0.8017 0.7611 0.5567 0.8096 0.9349
0.6887 0.6658 0.5287 0.8854 0.8004
0.8910 0.8581 0.5786 0.5773 0.6749
0.6776 0.6634 0.5675 0.7800 0.7307
0.8113 0.7742 0.5648 0.8038 0.9205
0.7432 0.7663 0.5616 0.6065 0.6319
结果说明:从关联度矩阵R可以看出,
(1) 第4行元素都比较小,表明各种投资对商业收入影响不大,即商业是一个不太需要依赖外部投资而能自行发展的行业。
从消耗投资上看,这是劣势,但从少投资多收入的效益观点看,商业是优势;
(2) 各行最大值反应了哪个子因素对该行对应的母因素影响最大,例如,r15=0.9349最大,表明交通投资(x5)对国民收入(y1)的影响最大;
(3) 第一行和第五行除了第3个元素外都较大,说明国民收入、交通收入是较综合性的行业,受除农业投资外其他投资的影响都较大。