Java 将Html转为PDF(二)
- 格式:docx
- 大小:15.22 KB
- 文档页数:2

在Java中将链接转换为PDF文件,通常需要使用一些第三方库,如Jsoup 用于抓取网页内容,然后使用iText或PDFBox等库将HTML内容转换为PDF 格式。
以下是一个基本的步骤示例:
1. 添加依赖项:
对于Jsoup:在你的Maven或Gradle构建文件中添加Jsoup依赖。
对于iText或PDFBox:添加相应的PDF生成库依赖。
2. 使用Jsoup抓取网页内容:
java代码:
3. 将HTML内容转换为PDF:
如果使用iText:
java代码:
如果使用PDFBox:
java代码:
注意:上述PDFBox示例中并没有直接将HTML转换为PDF,因为PDFBox 本身并不直接支持HTML到PDF的转换。
你可能需要结合使用Flying Saucer 或Apache FOP等其他库来实现这一功能。
请根据你的具体需求和环境选择合适的库和方法进行链接转PDF的操作。
同时,由于网络抓取和PDF生成可能会涉及到版权和许可问题,确保你在进行此类操作时遵守相关法律法规和网站的使用条款。

html转pdf的几种方法
有几种方法可以将HTML文件转换为PDF文件。
以下是其中一些常见的方法:
1.使用在线转换工具:有很多在线工具可以将HTML文件转换为
PDF格式,例如pdfcrowd、HTML to PDF等。
你只需上传HTML
文件,选择转换选项,然后等待转换完成并下载生成的PDF文
件。
2.使用浏览器打印功能:现代的Web浏览器(如Google Chrome
和Mozilla Firefox)通常都内置了“打印”功能,并提供将网页内
容保存为PDF文件的选项。
只需打开HTML文件,点击浏览器
菜单中的“打印”选项,然后选择“保存为PDF”或类似选项即可。
3.使用第三方库或工具:有一些专门的库和工具可以在编程环境
中将HTML转换为PDF。
例如,使用Python可以使用库如pdfkit、
WeasyPrint、PyPDF2等。
这些库允许你以编程方式加载HTML
文件并将其转换为PDF。
4.使用专业的PDF转换软件:还有一些专业的PDF转换软件,可
以将HTML文件转换为PDF。
这些软件通常提供更多的自定义
选项和功能,例如调整页面布局、添加水印等。
每种方法都有其优缺点,选择最适合你的方法取决于你的需求和偏好。
如果只是偶尔需要将HTML转换为PDF,那么在线工具或浏览器打印功能可能是最简单的选择。
如果需要在程序中自动化转换,那么使用相关的库或工具会更合适。

(C#)中使用pdf2htmlEX实现pdf向html的格式转换器1 背景目前,网络阅读平台在线阅读pdf文档的较为流行的解决方案是将pdf 文档转换成swf格式,然后使用flash播放器进行播放。
该解决方案的缺点较多:一,对于没有安装flash播放器的用户,pdf文档内容可能不能正常显示;二,使用flash在线播放容易导致清晰度降低,影响阅读;三,用户无法复制其中的内容;四,对屏幕尺寸各异的移动设备缺乏自适应能力。
将pdf转换成html文档则可以解决上述问题。
网络上和文献中分享的该领域的技术大部分是通过Java语言实现的。
笔者通过查阅文献和相关技术资料,结合本人的开发实践,提供了(C#)中基于pdf2htmlEX开源工具的格式转换器的实现技术。
2 使用pdf2htmlEX在(C#)中实现pdf向html的转换2.1 pdf2htmlEX介绍pdf 转换为html(下文部分地方简称为pdf2html)的技术思路是将pdf文档中的文字、图片、字体等信息提取出来,然后按照html的语法写入html文档中[1]。
pdf2htmlEX是免费使用的可高保真地对pdf至html 转换的工具,作者为王璐,在网上能找到较多的版本,笔者所使用的版本的下载地址是:http://download.csdn/detail/zhouyifan2009/8552783。
pdf2htmlEX的主要特点有以下四个:首先,它能准确提取字体,保证最大限度地原样输出;第二,保证渲染准确性,针对Web进行优化,如对文件进行必要的压缩等;第三,其他内容用背景图片的形式显示;第四,单文件输出,即转换结果是生成一个html文件,图片等信息不存放在单独的文件中。
[2]2.2 实现步骤pdf2htmlEX工具是控制台程序,没有自己的用户界面(点击pdf2htmlEX.exe文件时,程序窗口一闪而过,用户不能直接使用),必须由操作系统自带的cmd.exe调用或者其他第三方程序调用来实现它的功能。

poihtml转pdf 带表格传统的办公转换文件工具仍然是非常重要的。
POIHtml转PDF带表格是其中一种。
本篇文章将为读者介绍如何使用POIHtml转换器,将HTML文件带表格的内容转为PDF格式。
第一步:下载并安装POIHtml转换器工具POIHtml转换器是一个Java开发工具,任何具有Java环境的计算机都可以运行。
在网上搜索并下载POIHtml转换器程序包,将其解压并创建一个文件夹。
在文件夹中将包含POIHtml转换器的“jar”文件和一个例子HTML文件。
第二步:准备HTML文件和表格在POIHtml转换器工具的文件夹中,打开“example.html”文件并使用HTML标记创建一个包含表格的文件。
这个表格可以有一个或多个行和列。
第三步:编写Java代码在一个文本编辑器中打开一个新文件,输入以下代码:```javaimport java.io.*;import com.lowagie.text.*;import com.lowagie.text.pdf.*;import org.xhtmlrenderer.pdf.ITextRenderer;public class HtmlToPDF {public static void main(String[] args) throws DocumentException, IOException {OutputStream os = new FileOutputStream("example.pdf"); //创建PDF文件ITextRenderer renderer = new ITextRenderer();renderer.setDocument(new File("example.html"));yout();renderer.createPDF(os);}}```将“example.html”中的内容转换为PDF,将其保存为“example.pdf”。

1、IText实现html2pdf,速度快,纠错能力差,支持中文(要求HTML使用unicode编码),但中支持一种中文字体,开源。
2、Flying Sauser实现html2pdf,纠错能力差,支持多种中文字体(部分样式不能识别),开源。
3、PD4ML实现html2pdf,速度快,纠错能力强,支持多种中文字体,商业。
(一)IText官网:/测试案例:TestIText.java依赖jar包:iText-2.0.8.jar、iTextAsian.jar(支持中文)下面只是一个小的测试案例,如果项目中使用到了该组件可以参考API完成项目组中相应的功能![c-sharp]view plaincopyprint?1.import java.io.FileOutputStream;2.import java.io.FileReader;3.import java.util.ArrayList;4.import com.lowagie.text.Document;5.import com.lowagie.text.Element;6.import com.lowagie.text.Font;7.import com.lowagie.text.PageSize;8.import com.lowagie.text.Paragraph;9.import com.lowagie.text.html.simpleparser.HTMLWorker;10.importcom.lowagie.text.html.simpleparser.StyleSheet;11.import com.lowagie.text.pdf.BaseFont;12.import com.lowagie.text.pdf.PdfWriter;13.public class TestIText{14.public static void main(String[] args) {15.TestIText ih = new TestIText();16.ih.htmlCodeComeFromFile("D://Test//iText.html","D://Test//iText_1.pdf");17.ih.htmlCodeComeString("Hello中文","D://Test//iText_2.pdf");18.}19.20.public void htmlCodeComeFromFile(String filePath,String pdfPath) {21.Document document = new Document();22.try {23.StyleSheet st = new StyleSheet();24.st.loadTagStyle("body", "leading", "16,0");25.PdfWriter.getInstance(document, newFileOutputStream(pdfPath));26.document.open();27.ArrayList p = HTMLWorker.parseToList(newFileReader(filePath), st);28.for(int k = 0; k < p.size(); ++k) {29.document.add((Element)p.get(k));30.}31.document.close();32.System.out.println("文档创建成功");33.}catch(Exception e) {34. e.printStackTrace();35.}36.}37.38.public void htmlCodeComeString(String htmlCode,String pdfPath) {39.Document doc = new Document(PageSize.A4);40.try {41.PdfWriter.getInstance(doc, newFileOutputStream(pdfPath));42.doc.open();43.// 解决中文问题44.BaseFont bfChinese = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);45.Font FontChinese = new Font(bfChinese, 12,Font.NORMAL);46.Paragraph t = new Paragraph(htmlCode, FontChinese);47.doc.add(t);48.doc.close();49.System.out.println("文档创建成功");50.}catch(Exception e) {51. e.printStackTrace();52.}53.}54.}1.import java.io.File;2.import java.io.FileOutputStream;3.import java.io.OutputStream;4.5.import org.xhtmlrenderer.pdf.ITextFontResolver;6.import org.xhtmlrenderer.pdf.ITextRenderer;7.8.import com.lowagie.text.pdf.BaseFont;9.10.public class TestFlyingSauser {11.public static void main(String[] args) throwsException {12.demo_1();13.demo_2();14.}15.16.// 不支持中文17.public static void demo_1() throws Exception {18.String inputFile = "D:/Test/flying.html";19.String url = newFile(inputFile).toURI().toURL().toString();20.String outputFile = "D:/Test/flying.pdf";21.OutputStream os = new FileOutputStream(outputFile);22.ITextRenderer renderer = new ITextRenderer();23.renderer.setDocument(url);yout();25.renderer.createPDF(os);26.os.close();27.}28.29.// 支持中文30.public static void demo_2() throws Exception {31.String outputFile = "D:/Test/demo_3.pdf";32.OutputStream os = new FileOutputStream(outputFile);33.ITextRenderer renderer = new ITextRenderer();34.ITextFontResolver fontResolver =renderer.getFontResolver();35.fontResolver.addFont("C:/Windows/fonts/simsun.ttc",BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);36.StringBuffer html = new StringBuffer();37.// DOCTYPE 必需写否则类似于这样的字符解析会出现错误38.html.append("<!DOCTYPE html PUBLIC /"-//W3C//DTDXHTML 1.0 Transitional//EN/"/"/TR/xhtml1/DTD/xhtml1-transitional.dtd/">");39.html.append("<htmlxmlns=/"/1999/xhtml/">").append("<head>")40..append("<meta http-equiv=/"Content-Type/"content=/"text/html; charset=UTF-8/" />")41..append("<mce:style type=/"text/css/"><!--42.body {font-family: SimSun;}43.--></mce:style><style type=/"text/css/"mce_bogus="1">body {font-family: SimSun;}</style>")44..append("</head>")45..append("<body>");46.html.append("<div>支持中文!</div>");47.html.append("</body></html>");48.renderer.setDocumentFromString(html.toString());49.// 解决图片的相对路径问题50.//renderer.getSharedContext().setBaseURL("file:/F:/teste /html/");yout();52.renderer.createPDF(os);53.os.close();54.}55.}/sns/space.php?uid=4&do=blog&id=582关于Flying Sauser的一篇非常不错的文章:/pub/a/today/2007/06/26/generating-pdfs-with-flying-saucer-and-itext.html(三)PD4ML官网下载:/downloads.htm依赖jar包:pd4ml_demo.jar、pd4ml__css2.jar、fonts.jar下面只是一个小的测试案例,如果项目中使用到了该组件可以参考API完成项目组中相应的功能![java]view plaincopyprint?1.import java.awt.Insets;2.import java.io.File;3.import java.io.FileOutputStream;4.import java.io.StringReader;5.6.import org.zefer.pd4ml.PD4Constants;7.import org.zefer.pd4ml.PD4ML;8.9.public class Converter {10.public static void main(String[] args) throwsException {11.Converter converter = new Converter();12.converter.generatePDF_2(newFile("D:/Test/demo_ch_pd4ml_a.pdf"), "D:/Test/a.htm");13.File pdfFile = newFile("D:/Test/demo_ch_pd4ml.pdf");14.StringBuffer html = new StringBuffer();15.html.append("<html>")16..append("<head>")17..append("<meta http-equiv=/"Content-Type/"content=/"text/html; charset=UTF-8/" />")18..append("</head>")19..append("<body>")20..append("<font face=/"KaiTi_GB2312/">")21..append("<font color='red' size=22>显示中文</font>")22..append("</font>")23..append("</body></html>");24.StringReader strReader = newStringReader(html.toString());25.converter.generatePDF_1(pdfFile, strReader);26.}27.// 手动构造HTML代码28.public void generatePDF_1(File outputPDFFile,StringReader strReader) throws Exception {29.FileOutputStream fos = newFileOutputStream(outputPDFFile);30.PD4ML pd4ml = new PD4ML();31.pd4ml.setPageInsets(new Insets(20, 10, 10, 10));32.pd4ml.setHtmlWidth(950);33.pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));eTTF("java:fonts", true);35.pd4ml.setDefaultTTFs("KaiTi_GB2312", "KaiTi_GB2312","KaiTi_GB2312");36.pd4ml.enableDebugInfo();37.pd4ml.render(strReader, fos);38.}39.40.// HTML代码来自于HTML文件41.public void generatePDF_2(File outputPDFFile,String inputHTMLFileName) throws Exception {42.FileOutputStream fos = newFileOutputStream(outputPDFFile);43.PD4ML pd4ml = new PD4ML();44.pd4ml.setPageInsets(new Insets(20, 10, 10, 10));45.pd4ml.setHtmlWidth(950);46.pd4ml.setPageSize(pd4ml.changePageOrientation(PD4Constants.A4));eTTF("java:fonts", true);48.pd4ml.setDefaultTTFs("KaiTi_GB2312", "KaiTi_GB2312","KaiTi_GB2312");49.pd4ml.enableDebugInfo();50.pd4ml.render("file:" + inputHTMLFileName, fos);51.}52.}。

html2pdf是一个JavaScript库,可以将HTML文档转换为PDF文件。
以下是使用html2pdf方法的步骤:1. 引入html2pdf库文件```html<script src="/ajax/libs/html2pdf.js/0.9.3/html2pdf.bundle.min.js"></script>```2. 创建一个HTML元素,将要转换的内容放入其中```html<div id="content"><h1>Hello World</h1><p>This is a sample HTML content that will be converted to PDF.</p></div>```3. 在JavaScript代码中调用html2pdf方法,将HTML元素转换为PDF并下载```javascriptfunction downloadPDF() {var element = document.getElementById('content'); // 获取要转换的HTML元素var opt = {margin: 1,filename: 'sample.pdf',image: { type: 'jpeg', quality: 0.98 },html2canvas: { scale: 2 },jsPDF: { unit: 'in', format: 'letter', orientation: 'portrait' }};html2pdf().set(opt).from(element).save(); // 调用html2pdf方法,将HTML元素转换为PDF 并下载}```在上面的代码中,我们首先获取了要转换的HTML元素,然后定义了一些选项,如页面边距、文件名、图片质量等。

Java将Html转为PDF(⼆)前⾯介绍了如何,该⽅法需要使⽤Spire.PDF for Java 3.6.6或者之后的新版本,可根据⾃⼰的系统选择不同插件来实现转换。
本⽂提供另外⼀种转换⽅法,需要使⽤Spire.Doc for Java 3.9.4或者之后的新版本。
关于Jar包下载及导⼊⽅法1:。
解压,找到lib⽂件夹的Spire.Doc.jar⽂件,并在Java程序中导⼊jar⽂件⽅法2:在Maven程序中配置Pom.xml⽂件,如下(需要指定Maven仓库路径以及Spire.Doc的依赖):<repositories><repository><id>com.e-iceblue</id><url>/repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId> e-iceblue </groupId><artifactId>spire.doc</artifactId><version>3.9.4</version></dependency></dependencies>完成配置后,导⼊jar。
详细步骤可参考官⽅⽂档。
Html转PDF⽅法转换时可以将Html String或者Html file转为PDF,参见以下代码⽅法:1. 将Html String转为PDF创建Word⽂档,将Html String添加到Word段落,通过saveToFile()保存为PDF⽂档。
import com.spire.doc.*;import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;public class HtmlToPDF1 {public static void main(String[] args) throws IOException{String inputHtml = "InputHtml.txt";//新建Document对象Document doc = new Document();//添加sectionSection sec = doc.addSection();String htmlText = readTextFromFile(inputHtml);//添加段落并写⼊HTML⽂本sec.addParagraph().appendHTML(htmlText);//将⽂档另存为PDFdoc.saveToFile("HTMLstringToPDF.pdf", FileFormat.PDF);doc.dispose();}public static String readTextFromFile(String fileName) throws IOException {StringBuffer sb = new StringBuffer();BufferedReader br = new BufferedReader(new FileReader(fileName));String content;while ((content = br.readLine()) != null) {sb.append(content);}return sb.toString();}}2. 将Html file转为PDF加载Html⽂件,通过saveToFile()⽅法直接保存为PDF。
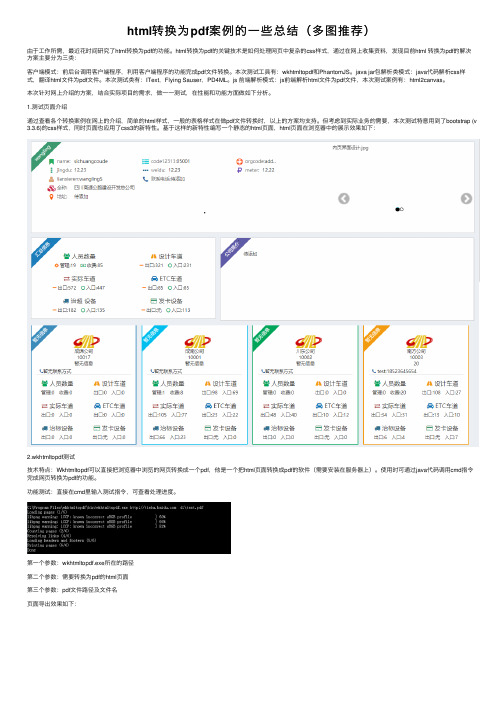
html转换为pdf案例的⼀些总结(多图推荐)由于⼯作所需,最近花时间研究了html转换为pdf的功能。
html转换为pdf的关键技术是如何处理⽹页中复杂的css样式,通过在⽹上收集资料,发现⽬前html 转换为pdf的解决⽅案主要分为三类:客户端模式:前后台调⽤客户端程序,利⽤客户端程序的功能完成pdf⽂件转换。
本次测试⼯具有:wkhtmltopdf和PhantomJS。
java jar包解析类模式:java代码解析css样式,翻译html⽂件为pdf⽂件。
本次测试类有:IText,Flying Sauser,PD4ML。
js 前端解析模式:js前端解析html⽂件为pdf⽂件,本次测试案例有:html2canvas。
本次针对⽹上介绍的⽅案,结合实际项⽬的需求,做⼀⼀测试,在性能和功能⽅⾯做如下分析。
1.测试页⾯介绍通过查看各个转换案例在⽹上的介绍,简单的html样式,⼀般的表格样式在做pdf⽂件转换时,以上的⽅案均⽀持。
但考虑到实际业务的需要,本次测试特意⽤到了bootstrap (v 3.3.6)的css样式,同时页⾯也应⽤了css3的新特性。
基于这样的新特性编写⼀个静态的html页⾯,html页⾯在浏览器中的展⽰效果如下:2.wkhtmltopdf测试技术特点:Wkhtmltopdf可以直接把浏览器中浏览的⽹页转换成⼀个pdf,他是⼀个把html页⾯转换成pdf的软件(需要安装在服务器上)。
使⽤时可通过java代码调⽤cmd指令完成⽹页转换为pdf的功能。
功能测试:直接在cmd⾥输⼊测试指令,可查看处理进度。
第⼀个参数:wkhtmltopdf.exe所在的路径第⼆个参数:需要转换为pdf的html页⾯第三个参数:pdf⽂件路径及⽂件名页⾯导出效果如下:测试说明:通过测试发现,wkhtmltopdf对bootstap的CSS样式整体⽀持较好。
对css3的新特性如圆形图⽚样式⽀持⾏不好。
部分页⾯样式会失效。

Java 将PDF 转为Word、图片、SVG、XPS、Html、PDF/A本文将介绍通过Java编程来实现PDF文档转换的方法。
包括:PDF转为WordPDF转为图片PDF转为HtmlPDF转为SVG将PDF每一页转为单个的SVG将一个包含多页的PDF文档转为一个SVGPDF转为XPSPDF转为PDF/A使用工具:Free Spire.PDF for Java(免费版)Jar文件获取及导入:方法1:通过官网下载jar文件包。
下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入Java程序。
方法2:可通过maven仓库安装导入。
参考导入方法。
Java代码示例【示例1】PDF 转WordPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToWord.docx",FileFormat.DOCX);【示例2】PDF转图片支持的图片格式包括Jpeg, Jpg, Png, Bmp, Tiff, Gif, EMF等。
这里以保存为Png格式为例。
import com.spire.pdf.*;import javax.imageio.ImageIO;import java.awt.image.BufferedImage;import java.io.File;import java.io.IOException;public class PDFtoimage {public static void main(String[] args) throws IOException {PdfDocument pdf = new PdfDocument("test.pdf");BufferedImage image;for(int i = 0; i< pdf.getPages().getCount();i++){image = pdf.saveAsImage(i);File file = new File( String.format("ToImage-img-%d.png", i)); ImageIO.write(image, "PNG", file);}pdf.close();}}【示例3】PDF转HtmlPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToHTML.html", FileFormat.HTML);【示例4】PDF转SVG1.转为单个svgPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToSVG.svg", FileFormat.SVG);2.多页pdf转为一个svgPdfDocument pdf = new PdfDocument("sampe.pdf");pdf.getConvertOptions().setOutputToOneSvg(true);pdf.saveToFile("ToOneSvg.svg",FileFormat.SVG);【示例5】PDF 转XPSPdfDocument pdf = new PdfDocument("test.pdf");pdf.saveToFile("ToXPS.xps", FileFormat.XPS);【示例6】PDF转PDF/Aimport com.spire.pdf.*;import com.spire.pdf.graphics.PdfMargins;import java.awt.geom.Dimension2D;public class PDFtoPDFA {public static void main(String[]args){//加载测试文档PdfDocument pdf = new PdfDocument();pdf.loadFromFile("test.pdf");//转换为Pdf_A_1_B格式PdfNewDocument newDoc = new PdfNewDocument();newDoc.setConformance(PdfConformanceLevel.Pdf_A_1_B);PdfPageBase page;for ( int i=0;i< pdf.getPages().getCount();i++) {page = pdf.getPages().get(i);Dimension2D size = page.getSize();PdfPageBase p = newDoc.getPages().add(size, new PdfMargins(0)); page.createTemplate().draw(p, 0, 0);}//保存结果文件newDoc.save("ToPDFA.pdf");newDoc.close();}}(本文完)。

java html转pdf方案在 Java 中,可以使用第三方库来实现将 HTML 转换为 PDF。
以下是一个使用Flying Saucer 和 iText 库的示例:1. 首先,需要在项目中添加 Flying Saucer 和 iText 的依赖:```java<dependency><groupId>org.xhtmlrenderer</groupId><artifactId>flying-saucer-pdf</artifactId><version>9.1.22</version></dependency><dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.13.2</version></dependency>```2. 创建一个 HTML 文件,例如 `example.html`,并保存到本地文件系统中。
3. 使用以下代码将 HTML 文件转换为 PDF 文件:```javaimport java.io.File;import java.io.FileOutputStream;import java.io.OutputStream;import org.xhtmlrenderer.pdf.ITextRenderer;public class HtmlToPdfConverter {public static void main(String[] args) throws Exception {// 输入 HTML 文件路径和输出 PDF 文件路径String inputPath = "example.html";String outputPath = "example.pdf";// 创建 ITextRenderer 对象并设置 PDF 输出流ITextRenderer renderer = new ITextRenderer();OutputStream outputStream = new FileOutputStream(new File(outputPath));renderer.setDocument(new File(inputPath));renderer.setOutputStream(outputStream);// 渲染 PDF 并关闭输出流yout();renderer.close();outputStream.close();}}```在上述代码中,我们创建了一个 `ITextRenderer` 对象,并将其配置为从输入HTML 文件渲染 PDF 文件,并将输出流设置为一个文件输出流。

Html转pdf(JAVA)html转pdf⼯具类/*** HTML转PDF的⼯具类*/SystemPath(获取路径,需要⾃⼰处理下)public class ConverterHTMLToPDF {private static Logger logger = Logger.getLogger(ConverterHTMLToPDF.class.getName());public void converterHTMLToPDF(String content, String myRandom){String toPdfExeHome = "";ponent.config.ConfigXMLReader reader=new ponent.config.ConfigXMLReader();toPdfExeHome = reader.getAttribute("topdftools", "topdfhome");String osName = System.getProperties().getProperty("").toUpperCase();String htmlFile_temp_path = SystemPath.getRootFilePath()+File.separator+"platform"+File.separator+"custom"+File.separator+"custom_form"+File.separator+"run"+File.separator+"export2html_temp.html"; htmlFile_temp_path=SystemPath.getRootFilePath()+File.separator+"platform"+File.separator+"custom"+File.separator+"custom_form"+File.separator+"run"+File.separator+"export2html_govtemp.html"; logger.debug("临时HTML⽂件"+htmlFile_temp_path);String fileContent = "";try {fileContent = mons.io.FileUtils.readFileToString(new File(htmlFile_temp_path), "UTF-8");} catch (IOException e) {e.printStackTrace();}fileContent=fileContent.replace("[htmlcontent]",content);String temppath=SystemPath.getRootFilePath()+File.separator+"upload"+File.separator+"tempfile";String htmlName=myRandom+".html";String pdfName=myRandom+".pdf";//pdfName="export2pdf_temp.pdf";String htmlFile_path=temppath+File.separator+"temphtml"+File.separator+htmlName;String pdfFile_path=temppath+File.separator+"temppdf"+File.separator+pdfName;logger.debug("HTML的路径:"+htmlFile_path+",PDF⽂件路径"+pdfFile_path);try {mons.io.FileUtils.writeStringToFile(new File(htmlFile_path), fileContent, "UTF-8");} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}Runtime r = Runtime.getRuntime();try {Process pro = null;if (osName.startsWith("WIN")){pro = r.exec( toPdfExeHome+"\\wkhtmltopdf.exe "+htmlFile_path+" "+pdfFile_path);}else{logger.debug("linux tttt:"+toPdfExeHome+File.separator+"wkhtmltopdf "+htmlFile_path+" "+pdfFile_path);pro = r.exec( toPdfExeHome+File.separator+"wkhtmltopdf "+htmlFile_path+" "+pdfFile_path);}new DoOutput(pro.getInputStream()).start();new DoOutput(pro.getErrorStream()).start();try {pro.waitFor();} catch (InterruptedException e) {e.printStackTrace();}} catch (IOException eee) {eee.printStackTrace();}}/*** 把⾃定义流程的html转换成pdf* @param htmlFile html⽂件* @param pdfFile pdf⽂件*/public void converterArchivesFileHTMLToPDF(File htmlFile,File pdfFile){String toPdfExeHome = "";ponent.config.ConfigXMLReader reader=new ponent.config.ConfigXMLReader();toPdfExeHome = reader.getAttribute("topdftools", "topdfhome");String osName = System.getProperties().getProperty("").toUpperCase();String htmlFile_path= htmlFile.getAbsolutePath();String pdfFile_path= pdfFile.getAbsolutePath();logger.debug("HTML的路径:"+htmlFile_path+",PDF⽂件路径"+pdfFile_path);Runtime r = Runtime.getRuntime();try {Process pro = null;if (osName.startsWith("WIN")){pro = r.exec( toPdfExeHome+"\\wkhtmltopdf.exe "+htmlFile_path+" "+pdfFile_path);}else{logger.debug("linux tttt:"+toPdfExeHome+File.separator+"wkhtmltopdf "+htmlFile_path+" "+pdfFile_path);pro = r.exec( toPdfExeHome+File.separator+"wkhtmltopdf "+htmlFile_path+" "+pdfFile_path);}new DoOutput(pro.getInputStream()).start();new DoOutput(pro.getErrorStream()).start();try {pro.waitFor();} catch (InterruptedException e) { e.printStackTrace();}} catch (IOException eee) {eee.printStackTrace();}}。

java将html转为word导出(富⽂本内容导出word)业务:将富⽂本内容取出⽣成本地word⽂件参考百度的⽅法word本⾝是可以识别html标签,所以通过poi写⼊html内容即可import com.util.WordUtil;import org.springframework.web.bind.annotation.PostMapping;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;public class SysAnnouncementController {@PostMapping(value = "/exportAccidentExampleWord")public void exportAccidentExampleWord(HttpServletRequest request, HttpServletResponse response) throws Exception {String s = "<p><strong>第⼀⾏要加粗</strong></p>\n" +"<p><em><strong>第⼆⾏要倾斜</strong></em></p>\n" +"<p style=\"text-align: center;\"><em><strong>第三⾏要居中</strong></em></p>";StringBuffer sbf = new StringBuffer();sbf.append("<html " +"xmlns:v=\"urn:schemas-microsoft-com:vml\" xmlns:o=\"urn:schemas-microsoft-com:office:office\" xmlns:w=\"urn:schemas-microsoft-com:office:word\" xmlns:m=\"/office/2004/12/omml\" xmlns=\"http://w ">");//缺失的⾸标签sbf.append("<head>" +"<!--[if gte mso 9]><xml><w:WordDocument><w:View>Print</w:View><w:TrackMoves>false</w:TrackMoves><w:TrackFormatting/><w:ValidateAgainstSchemas/><w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid><w:IgnoreMixedCo "</head>");//将版式从web版式改成页⾯试图sbf.append("<body>");//缺失的⾸标签sbf.append(s);//富⽂本内容sbf.append("</body></html>");//缺失的尾标签try{WordUtil.exportWord(request,response,sbf.toString(),"wordName");}catch (Exception e){System.out.println(e.getMessage());}}}⼯具类import javax.servlet.ServletOutputStream;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.ByteArrayInputStream;import java.io.OutputStream;public class WordUtil {public static void exportWord(HttpServletRequest request, HttpServletResponse response, String content, String fileName) throws Exception {byte[] b = content.getBytes("GBK"); //这⾥是必须要设置编码的,不然导出中⽂就会乱码。

Java实现HTML页⾯转PDF解决⽅案(转)public boolean convertHtmlToPdf(String inputFile, String outputFile)throws Exception {OutputStream os = new FileOutputStream(outputFile);ITextRenderer renderer = new ITextRenderer();String url = new File(inputFile).toURI().toURL().toString();renderer.setDocument(url);// 解决中⽂⽀持问题ITextFontResolver fontResolver = renderer.getFontResolver();fontResolver.addFont("C:/Windows/Fonts/SIMSUN.TTC", BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);//解决图⽚的相对路径问题renderer.getSharedContext().setBaseURL("file:/D:/");yout();renderer.createPDF(os);os.flush();os.close();return true;}上⾯这段代码是这样的,输⼊⼀个HTML地址URL = inputFile,输⼊⼀个要输出的地址,就可以在输出的PDF地址中⽣成这个PDF。
注意事项:1.输⼊的HTML页⾯必须是标准的XHTML页⾯。
页⾯的顶上必须是这样的格式:<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="/1999/xhtml">并且HTML页⾯的语法必须是⾮常严谨的,所有标签都必须闭合等等(由于flying-Saucer做了XML解析的⼯作,不严谨会报错的。

Java HTML直接导出PDFJava HTML直接导出PDF对于java中如何从html中直接导出pdf,有很多的开源代码,这里个人用itext转。
首先需要的包有:core-renderer-1.0.jarcore-renderer-R8pre1.jarcore-renderer.jariText-2.0.8.jarjtidy-4aug2000r7-dev.jarTidy.jariTextAsian.jarjava代码的话就比较简单了。
具体是先用Tidy将html转换为xhtml,将xhtml转换为其它各种格式的。
虽然在转化到pdf时也是用的iText。
代码如下:Java代码//struts1.x中Java代码elseif("Html2Pdf".equalsIgnoreCase(action)){ exportPdfF ile("http://localhost:8080/jsp/test.jsp"); return null; } // 导出pdf add by huangt 2012.6.1 public File exportPdfFile(String urlStr) throws BaseException{ // String outputFile = this.fileRoot + "/" +// ServiceConstants.DIR_PUBINFO_EXPORT + "/" + getFileName() + ".pdf"; String outputFile = "d:/test3.pdf"; OutputStream os; try { os = new FileOutputStream(outputFile); ITextRenderer renderer = new ITextRenderer();String str = getHtmlFile(urlStr);renderer.setDocumentFromString(str); ITextFontResolver fontResolver =renderer.getFontResolver();fontResolver.addFont("C:/WINDOWS/Fonts/SimSun.ttc",B aseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);// 宋体字fontResolver.addFont("C:/WINDOWS/Fonts/Arial.ttf",Base Font.IDENTITY_H, BaseFont.NOT_EMBEDDED);// 宋体字yout();renderer.createPDF(os);System.out.println("转换成功!"); os.flush(); os.close(); return newFile(outputFile); } catch (FileNotFoundException e) { // logger.error("不存在文件!" +e.getMessage()); throw new BaseException(e); } catch (DocumentExceptione) { // logger.error("生成pdf时出错了!" + e.getMessage()); throw new BaseException(e); } catch (IOException e){ // logger.error("pdf出错了!" +e.getMessage()); throw new BaseException(e); } } // 读取页面内容add by huangt 2012.6.1 public String getHtmlFile(String urlStr) throws BaseException{ URL url; try { if (urlStr.indexOf("?") != -1) { urlStr = urlStr + "&locale=" + LocaleContextHolder.getLocale().toString();} else { urlStr = urlStr + "?locale="+LocaleContextHolder.getLocale().toString();} url = new URL(urlStr); URLConnection uc = url.openConnection();InputStream is = uc.getInputStream();Tidy tidy = new Tidy(); OutputStream os2 = new ByteArrayOutputStream();tidy.setXHTML(true); // 设定输出为xhtml(还可以输出为xml)tidy.setCharEncoding(Configuration.UTF8); // 设定编码以正常转换中文tidy.setTidyMark(false); // 不设置它会在输出的文件中给加条meta信息tidy.setXmlPi(true); // 让它加上<?xml version="1.0"?> tidy.setIndentContent(true); // 缩进,可以省略,只是让格式看起来漂亮一些tidy.parse(is, os2);is.close(); // 解决乱码--将转换后的输出流重新读取改变编码String temp; StringBuffer sb = new StringBuffer();BufferedReader in = new BufferedReader(new InputStreamReader( new ByteArrayInputStream( (( ByteArrayOutputStream) os2).toByteArray()),"utf-8")); while ((temp = in.readLine()) != null){ sb.append(temp); } return sb.toString(); } catch (IOException e) { // logger.error("读取客户端网页文本信息时出错了" + e.getMessage()); throw new BaseException(e); } }为了解决包的问题,加上Maven <!-- pdf导出-->Xml代码<dependency><groupId>com.lowagie</groupId><artifactId>itext</artifactId><version>2.1.7</version> </dependency> <dependency><groupId>org.xhtmlrenderer.flyingsaucer</groupId& gt; <artifactId>pdf-renderer</artifactId><version>1.0</version> </dependency> <dependency><groupId>jtidy</groupId><artifactId>jtidy</artifactId><version>4aug2000r7-dev</version><type>jar</type><scope>compile</scope> </dependency> <dependency><groupId>net.sf.barcode4j</groupId><artifactId>barcode4j-light</artifactId><version>2.0</version> </dependency> <dependency><groupId>avalon-framework</groupId><artifactId>avalon-framework-impl</artifactId> <version>4.2.0</version> </dependency><!-- pdf -->另外附上稍微复杂的PDFUtils.java文件,由于没时间就不做整理解释了!见下载附件!。

针对生成pdf文件二中的方法一、前言在企业的信息系统中,报表处理一直占比较重要的作用,本文将介绍一种生成PDF报表的Java组件--iText。
通过在服务器端使用Jsp或JavaBean生成PDF报表,客户端采用超级连接显示或下载得到生成的报表,这样就很好的解决了B/S系统的报表处理问题。
二、iText简介iText是著名的开放源码的站点sourceforge一个项目,是用于生成PDF文档的一个java 类库。
通过iText不仅可以生成PDF或rtf的文档,而且可以将XML、Html文件转化为PDF 文件。
iText的安装非常方便,在/iText/download.html - download 网站上下载iText.jar文件后,只需要在系统的CLASSPATH中加入iText.jar的路径,在程序中就可以使用iText类库了。
三、建立第一个PDF文档用iText生成PDF文档需要5个步骤:①建立com.lowagie.text.Document对象的实例。
Document document = new Document();②建立一个书写器(Writer)与document对象关联,通过书写器(Writer)可以将文档写入到磁盘中。
PDFWriter.getInstance(document, new FileOutputStream("Helloworld.PDF"));③打开文档。
document.open();④向文档中添加内容。
document.add(new Paragraph("Hello World"));⑤关闭文档。
document.close();通过上面的5个步骤,就能产生一个Helloworld.PDF的文件,文件内容为"Hello World"。
建立com.lowagie.text.Document对象的实例com.lowagie.text.Document对象的构建函数有三个,分别是:public Document();public Document(Rectangle pageSize);public Document(Rectangle pageSize,int marginLeft,int marginRight,int marginTop,int marginBottom);构建函数的参数pageSize是文档页面的大小,对于第一个构建函数,页面的大小为A4,同Document(PageSize.A4)的效果一样;对于第三个构建函数,参数marginLeft、marginRight、marginTop、marginBottom分别为左、右、上、下的页边距。

html转pdf 分页原理HTML转PDF时的分页原理涉及到模拟浏览器渲染和布局的过程,然后根据纸张大小、页面边距等因素将内容切割并分配到不同的PDF页面上。
在JavaScript库中如html2canvas和jspdf实现这一功能时,主要步骤如下:html2canvas:1.html2canvas用于将HTML元素转化为图片(通常为PNG格式)。
它通过遍历DOM树,计算每个元素的位置、样式和其他属性,并使用Canvas API来绘制页面内容。
2.分页处理不是html2canvas的核心功能,但它会尽可能地捕捉整个可见视口的内容。
jspdf:1.jspdf是一个纯JavaScript编写的PDF生成库,它可以创建、修改PDF文档。
2.当需要进行分页时,首先利用html2canvas抓取的网页截图或直接处理HTML内容后,将其分割成适合单个PDF页面的部分。
3.在将图片或渲染后的文本添加到PDF时,jspdf会检查当前页面是否已满(基于指定的页面尺寸和内容高度),如果满则自动创建新的一页,并继续添加内容。
具体的分页算法可能包括以下步骤:•初始化PDF页面设置,包括页面大小、边距等。
•使用html2canvas逐部分或整体捕获HTML内容并转换为位图或可直接写入PDF的数据结构。
•将捕获的内容按照从上至下的顺序,按需插入到PDF页面中。
•当内容的高度接近或超过一页的可用空间时,计算出合适的断点并将剩余内容移动到下一页。
•循环这个过程直到所有内容都被正确分页并添加到PDF文件中。
需要注意的是,由于不同浏览器对CSS样式的解释可能会有细微差别,以及PDF本身的局限性,在复杂布局下实现精确的分页效果可能较为复杂,需要针对具体情况进行调整优化。

介绍一个PDF的生成方案/topic/509417在Java世界,要想生成PDF,方案不少。
最近一直在和这个东西打交道,所以简单做一个小结吧。
在此之前,先来勾画一下我心中比较理想的一个解决方案。
在企业应用中,碰到的比较多的PDF的需求,可能是针对某个比较典型的具备文档特性的内容,导出成为PDF进行存档。
由于我们现在往往使用一些开源框架,诸如ssh来构建我们的应用,所以我们相对熟悉的方案是针对具体的业务逻辑设计实体,使用开源框架来实现我们的业务逻辑。
而PDF的导出,最好不要破坏现有的程序框架,甚至能复用我们业务逻辑层的代码。
因为如果把PDF作为一种特殊的表现形式的话,实际上它有点类似模板。
最佳的情况,是我们能够通过编写某种模板,把PDF的大概样子确定下来,然后把数据和模板做一次整合,得到最后的结果带着这个目标,开始在网上搜索解决方案。
也找到了一些方案,下面简单小结一下:Jasper Report看到的市面上采用的最多的方案,是Jasper Report。
相关的文档也很多,不过很杂,需要完全掌握,我认为还是有些坡度和时间的。
这个时间和坡度我认为主要来自于对iReport这个IDE的反复尝试,对里面的每个属性的摸索。
Jasper Report的设计思路,本身是不违反我上面所说的初衷的。
因为我们的努力方向是先生成模板,然后得到数据,最后将两者整合得到结果。
但是Jasper Report的问题在于,其生成模板的方式过于复杂,即使有IDE的帮助,我们还是需要对其中的众多规则有所了解才行,否则就会给调试带来极大的麻烦。
所以,我认为Jasper Report是一个半调子方案,这种强依赖于IDE进行可视化编辑的方式令我很不爽。
同时,由此带来的诸多的限制,相信也让很多使用者颇为头疼。
在经历了一番痛苦的挣扎后,决定放弃使用这种方案。
iText其实Jasper Report是基于iText的。
于是有的人会说,那么直接使用iText不是一种倒退么?的确,直接使用iText似乎就需要直接使用原生的API进行编程了。

java使⽤POI实现html和word相互转换项⽬后端使⽤了springboot,maven,前端使⽤了ckeditor富⽂本编辑器。
⽬前从html转换的word为doc格式,⽽图⽚处理⽀持的是docx格式,所以需要⼿动把doc另存为docx,然后才可以进⾏图⽚替换。
⼀.添加maven依赖主要使⽤了以下和poi相关的依赖,为了便于获取html的图⽚元素,还使⽤了jsoup:<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.14</version></dependency><dependency><groupId>fr.opensagres.xdocreport</groupId><artifactId>xdocreport</artifactId><version>1.0.6</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>3.14</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>ooxml-schemas</artifactId><version>1.3</version></dependency><dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.11.3</version></dependency>⼆.word转换为html在springboot项⽬的resources⽬录下新建static⽂件夹,将需要转换的word⽂件temp.docx粘贴进去,由于static是springboot的默认资源⽂件,所以不需要在配置⽂件⾥⾯另⾏配置了,如果改成其他名字,需要在application.yml进⾏相应配置。

JavaScript+Java实现HTML页⾯转为PDF⽂件保存的⽅法需求是⼀个导出pdf的功能,多⽅奔⾛终于实现了,⾛了不少弯路,⽽且怀疑现在这个⽅法仍是弯的。
有个jsPDF 插件可以在前端直接⽣成pdf,很简便,但不⽀持IE。
前端:⾸先引⼊ html2canvas.jshtml2canvas(document.body, { //截图对象//此处可配置详细参数onrendered: function(canvas) { //渲染完成回调canvascanvas.id = "mycanvas";// ⽣成base64图⽚数据var dataUrl = canvas.toDataURL('image/png'); //指定格式,也可不带参数var formData = new FormData(); //模拟表单对象formData.append("imgData",convertBase64UrlToBlob(dataUrl)); //写⼊数据var xhr = new XMLHttpRequest(); //数据传输⽅法xhr.open("POST", "../bulletin/exportPdf"); //配置传输⽅式及地址xhr.send(formData);xhr.onreadystatechange = function(){ //回调函数if(xhr.readyState == 4){if (xhr.status == 200) {var back = JSON.parse(xhr.responseText);if(back.success == true){alertBox({content: 'Pdf导出成功!',lock: true,drag: false,ok: true});}else{alertBox({content: 'Pdf导出失败!',lock: true,drag: false,ok: true});}}}};}});//将以base64的图⽚url数据转换为Blobfunction convertBase64UrlToBlob(urlData){//去掉url的头,并转换为bytevar bytes=window.atob(urlData.split(',')[1]);//处理异常,将ascii码⼩于0的转换为⼤于0var ab = new ArrayBuffer(bytes.length);var ia = new Uint8Array(ab);for (var i = 0; i < bytes.length; i++) {ia[i] = bytes.charCodeAt(i);}return new Blob( [ab] , {type : 'image/png'});}兼容性:Firefox 3.5+, Chrome, Opera, IE10+不⽀持:iframe,浏览器插件,Flash跨域图⽚需要在跨域服务器header加上允许跨域请求access-control-allow-origin: * access-control-allow-credentials: truesvg图⽚不能直接⽀持,已经有补丁包了,不过我没有试过。
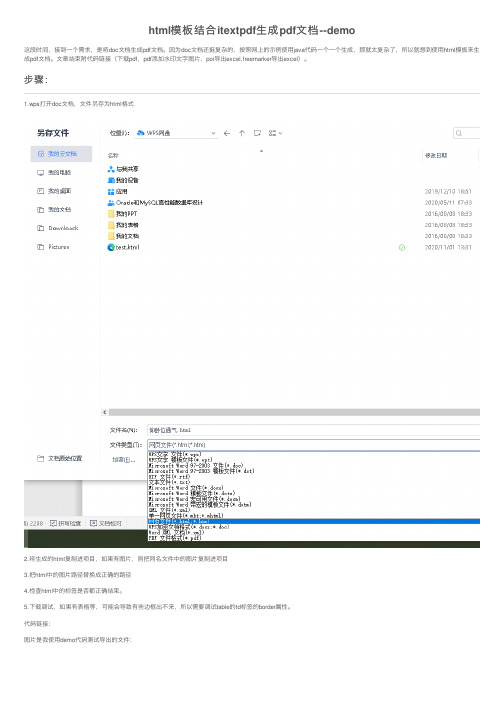
html模板结合itextpdf⽣成pdf⽂档--demo这段时间,接到⼀个需求,是将doc⽂档⽣成pdf⽂档。
因为doc⽂档还挺复杂的,按照⽹上的⽰例使⽤java代码⼀个⼀个⽣成,那就太复杂了,所以就想到使⽤html模板来⽣成pdf⽂档。
⽂章结束附代码链接(下载pdf,pdf添加⽔印⽂字图⽚,poi导出excel,freemarker导出excel)。
步骤:1.wps打开doc⽂档,⽂件另存为html格式2.将⽣成的html复制进项⽬,如果有图⽚,则把同名⽂件中的图⽚复制进项⽬3.把html中的图⽚路径替换成正确的路径4.检查html中的标签是否都正确结束。
5.下载调试,如果有表格等,可能会导致有些边框出不来,所以需要调试table的td标签的border属性。
代码链接:图⽚是我使⽤demo代码测试导出的⽂件:⽣成的⽔印⽂字,⽀持多页⽣成:可能遇到的坑:⼀、报错信息: The document has no pages.原因1:在⽣成PDF时,需要⽣成PDF的内容,标签有误,在使⽤itextpdf下载pdf的时候,⼀定要保证标签有开始,有结束才⾏。
⽐如⽣成的html⽂件中的meta标签,img标签;解决:<meta http-equiv=Content-Type content="text/html; charset=UTF-8"/><meta name=ProgId content=Word.Document/><meta name=Generator content="Microsoft Word 14"/><meta name=Originator content="Microsoft Word 14"/><img src=""/>原因2:使⽤新版的wps⽣成的html⽂档中含有itextPdf不识别的内容,我这次就因为这个搞了我⼏天。
Java 将Html转为PDF(二)
前面介绍了如何通过插件的方式将Html文件转为PDF,需要使用Spire.PDF for Java 3.6.6或者之后的新版本,可根据自己的系统选择不同插件来实现转换。
本文提供另外一种转换方法,需要使用Spire.Doc for Java 3.9.4或者之后的新版本。
关于Jar包下载及导入
方法1:下载jar包。
解压,找到lib文件夹的Spire.Doc.jar文件,并在Java程序中导入jar 文件
方法2:在Maven程序中配置Pom.xml文件,如下(需要指定Maven仓库路径以及Spire.Doc 的依赖):
<repositories>
<repository>
<id>com.e-iceblue</id>
<url>/repository/maven-public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId> e-iceblue </groupId>
<artifactId>spire.doc</artifactId>
<version>3.9.4</version>
</dependency>
</dependencies>
完成配置后,导入jar。
详细步骤可参考官方教程文档。
Html转PDF方法
转换时可以将Html String或者Html file转为PDF,参见以下代码方法:
1. 将Html String转为PDF
创建Word文档,将Html String添加到Word段落,通过saveToFile()保存为PDF文档。
import com.spire.doc.*;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class HtmlToPDF1 {
public static void main(String[] args) throws IOException{
String inputHtml = "InputHtml.txt";
//新建Document对象
Document doc = new Document();
//添加section
Section sec = doc.addSection();
String htmlText = readTextFromFile(inputHtml);
//添加段落并写入HTML文本
sec.addParagraph().appendHTML(htmlText);
//将文档另存为PDF
doc.saveToFile("HTMLstringToPDF.pdf", FileFormat.PDF);
doc.dispose();
}
public static String readTextFromFile(String fileName) throws IOException {
StringBuffer sb = new StringBuffer();
BufferedReader br = new BufferedReader(new FileReader(fileName));
String content;
while ((content = br.readLine()) != null) {
sb.append(content);
}
return sb.toString();
}
}
2. 将Html file转为PDF
加载Html文件,通过saveToFile()方法直接保存为PDF。
import com.spire.doc.*;
import com.spire.doc.documents.XHTMLValidationType;
public class HtmlToPDF2 {
public static void main(String[] args) {
//加载HTML文档
Document doc = new Document();
doc.loadFromFile("sample.html", FileFormat.Html, XHTMLValidationType.None);
//文档另存为PDF
doc.saveToFile("HTMLToPDF.pdf",FileFormat.PDF);
doc.dispose();
}
}。