清华大学2001年计算机组成原理试题
- 格式:doc
- 大小:25.00 KB
- 文档页数:3

计算机组成原理试题及答案全套第一部分:选择题1.下列关于计算机内存的说法,错误的是:A.内存是计算机的主要存储器件之一B.内存是临时存储器件,供程序运行时使用C.内存容量越大,计算机的性能越强D.内存分为主存和辅存,主存速度较快,但容量相对较小答案:C2.下列关于CPU的说法,错误的是:A.CPU是计算机的核心部件,负责执行指令和控制计算机的运行B.CPU由运算器、控制器和寄存器组成C.CPU的速度越快,计算机的运行速度越快D.CPU的主频越高,计算机的运行速度越慢答案:D3.下列关于指令周期的说法,错误的是:A.指令周期是CPU执行一条指令所需的时间B.指令周期包括取指令、译码、执行、访存四个阶段C.指令周期的长度取决于CPU的主频D.指令周期越短,CPU的执行效率越高答案:D4.下列关于存储器层次结构的说法,错误的是:A.存储器层次结构分为寄存器、高速缓存、主存和辅存B.存储器层次结构越高,存取速度越快,容量越小C.高速缓存是位于CPU和主存之间的高速存储器D.存储器层次结构的设计目标是在速度、容量和成本之间取得平衡答案:B5.下列哪项措施可以提高计算机系统的安全性?A.设置强密码B.定期更新操作系统和应用程序补丁C.安装杀毒软件和防火墙D.以上都是答案:D6.下列关于计算机硬盘的说法,错误的是:A.硬盘是一种磁存储设备,用于长期存储数据B.硬盘的读写速度相对较慢,但容量较大C.硬盘的存储介质是固态闪存芯片D.硬盘采用磁道、扇区和柱面的方式来寻址数据答案:C第二部分:填空题1.计算机系统由________、软件和人员三部分组成。
答案:硬件2.CPU的两个主要功能是执行________和控制计算机的运行。
答案:指令3.存储器层次结构的设计目标是在速度、________和成本之间取得平衡。
答案:容量4.计算机的存储器分为________和辅存两部分。
答案:主存5.操作系统的主要功能包括________管理、文件管理和用户接口等。

《计算机组成原理》习题参考答案习题一一、判断题⒈(√)⒉(√)⒊(√)⒋(×)⒌(×)⒍(×)⒎(√)⒏(×)⒐(√)⒑(√)二、单选题⒈⑴C ⑵B ⒉ C ⒊D 4. B 5. D6. C7. B8. C9. A 10. B三、填空题⒈⑴进行数据变换和算术、逻辑运算⑵为计算机的工作提供统一的时钟,按照程序,不断的取指令、分析指令,把指令中的操作码译码成相应的操作命令,并进行时序分配,变成相应的控制信号,驱动计算机的各部件按照节拍有序地完成程序规定的操作内容⒉⑴系统软件⑵应用软件⑶系统软件⑷控制和管理计算机的所有资源⒊⑴数字⑵模拟⑶处理的是数字量⑷处理的是模拟量⒋⑴字长⑵长⒌⑴计算机的地址总线的根数⑵=2地址总线根数⒍⑴内存储器⑵外存储器⒎计算机系统的运算速度指标,即每秒钟执行多少百万条指令⒏⑴曙光4000A ⑵10万⑶美国、日本)⒐⑴CPU ⑵CPU ⑶主机)⒑⑴机器语言⑵翻译程序)⒒计算机的运算速度与下列因素决定:⑴、⑵、⑶和⑷。
⒓某微处理器的地址总线有16条,则该微处理器所能直接访问的存储空间为⑴字节;若该存储空间的起始地址是0000H,那么最高地址应为⑵。
习题二一、判断题⒈(×)⒉(√)⒊(√)⒋(√)⒌(×)⒍(×)⒎(×)⒏(×)⒐(√)⒑(√)二、单选题⒈D ⒉C ⒊(1) D (2) A (3) C (4)B (5) B (6) A⒋ B ⒌ (1) A (2) D ⒍ (1) C (2) F (3) B (4) C (5) A⒎在计算机中,由于受有限字长的限制,用机器代码表示数时会产生误差,该误差称为(1) ;若取圆周率π=3.…的近似值为π*=3.1416,则它有 (2) 有效数字。
(1) A.相对误差 B.绝对误差 C.截断误差 D.测量误差(2) A.2位 B.3位 C.4位 D.5位⒏ (1) B (2) A (3) D (4)C (5) B⒐ (1) (2) ; (3) (4) (5) 。

计算机组成原理考试题及答案
1.计算机组成原理
计算机组成原理是计算机科学中的基础,它是用来理解、设计与构建
计算机硬件、软件系统及应用软件的基础知识。
它涉及到了计算机的
各个方面,包括硬件系统、操作系统、应用软件、网络系统等,一般
的计算机组成原理涵盖微机系统结构、存储技术、总线结构、指令设
计等内容。
2.计算机组成原理的应用
1)指令集设计:计算机组成原理涉及到指令集的设计,即构建一套机
器指令结构,用来支持某个特定的硬件系统。
这里涉及到了众多的原
理和技术,从MIPS指令语言到RISC,以及如何利用指令实现特定业
务逻辑、改变指令结构而不改变逻辑功能,等等。
2)流水线系统设计:流水线是一种改善机器执行能力的技术,它将指
令流中的每条指令都划分成几个阶段,每个阶段完成指令的单一功能,在流水线中,每个指令的各个部分在相隔的延迟之后不断的输出。
计
算机组成原理包括了流水线的设计技术,以及对流水线受阻的解决方案,如分支指令的处理,缓冲技术的应用,以及如何确定受阻指令的
顺序。
3)存储技术:存储技术也是计算机组成原理的重要组成部分,主要涉及到物理存储设备、逻辑存储布局、缓存技术以及虚拟内存管理等内容,它为数据存储和访问提供了统一的框架,使得计算机的性能有所提高。
3.计算机组成原理的考试题及答案
1)流水线系统中,当受阻指令产生后,采用什么技术进行处理?
A.流水线重排
B.缓冲技术
C.虚拟内存管理
D.分支指令处理
答案:D。


2001年数据结构与程序设计试题内容:一、试给出下列有关并查集(mfsets)的操作序列的运算结果:union(1,2) , union(3,4) , union(3,5) , union(1,7) , union(3,6) , union(8,9) , union(1,8) , union(3,10) , union(3,11) , union(3,12) , union(3,13) , union(14,15) , union(16,0) , u nion(14,16) , union(1,3) , union(1,14)。
(union是合并运算,在以前的书中命名为merge)要求(1) 对于union(i,j),以i作为j的双亲;(5分)(2) 按i和j为根的树的高度实现union(i,j),高度大者为高度小者的双亲;(5分)(3) 按i和j为根的树的结点个数实现union(i,j),结点个数大者为结点个数小者的双亲;(5分)二、设在4地(A,B,C,D)之间架设有6座桥,如图所示:要求从某一地出发,经过每座桥恰巧一次,最后仍回到原地(1) 试就以上图形说明:此问题有解的条件是什么? (5分)(2) 设图中的顶点数为n,试用C或Pascal描述与求解此问题有关的数据结构并编写一个算法,找出满足要求的一条回路. (10分)三、针对以下情况确定非递归的归并排序的运行时间(数据比较次数与移动次数):(1) 输入的n个数据全部有序; (5分)(2) 输入的n个数据全部逆向有序; (5分)(3) 随机地输入n个数据. (5分)四、简单回答有关AVL树的问题.(1) 在有N个结点的AVL树中,为结点增加一个存放结点高度的数据成员,那么每一个结点需要增加多少个字位(bit)? (5分)(2) 若每一个结点中的高度计数器有8bit,那么这样的AVL树可以有多少层?最少有多少个关键码? (5分)五、设一个散列表包含hashSize=13个表项,.其下标从0到12,采用线性探查法解决冲突. 请按以下要求,将下列关键码散列到表中.10 100 32 45 58 126 3 29 200 400 0(1) 散列函数采用除留余数法,用%hashSize(取余运算)将各关键码映像到表中. 请指出每一个产生冲突的关键码可能产生多少次冲突. (7分)(2) 散列函数采用先将关键码各位数字折叠相加, 再用%hashSize将相加的结果映像到表中的办法. 请指出每一个产生冲突的关键码可能产生多少次冲突. (8分)六、设一棵二叉树的结点定义为struct BinTreeNode{ElemType data;BinTreeNode *leftChild, *rightChild;}现采用输入广义表表示建立二叉树. 具体规定如下:(1) 树的根结点作为由子树构成的表的表名放在表的最前面;(2) 每个结点的左子树和右子树用逗号隔开. 若仅有右子树没有左子树, 逗号不能省略.(3) 在整个广义表表示输入的结尾加上一个特殊的符号(例如”#”)表示输入结果.例如,对于如右图所示的二叉树, 其广义表表示为A(B(D,E(G,)),C(,F))A/ \B C/ \ \D E F/G此算法的基本思路是:依次从保存广义表的字符串ls中输入每个字符. 若遇到的是字母(假定以字母作为结点的值), 则表示是结点的值, 应为它建立一个新的结点, 并把该结点作为左子女(当k=1)或有子女(当k= 2)链接到其双亲结点上. 若遇到的是左括号”(“, 则表明子表的开始,将k置为1;若遇到的是右括号”)”,则表明子表结果. 若遇到的是逗号”,”, 则表示以左子女为根的子树处理完毕,应接着处理以右子女为根的子树, 将k置为2.在算法中使用了一个栈s, 在进入子表之前,将根结点指针进栈, 以便括号内的子女链接之用. 在子表处理结束时退栈. 相关的栈操作如下:MakeEmpty(s) 置空栈Push(s,p) 元素p进栈Pop(s) 进栈Top(s) 存取栈顶元素的函数下面给出了建立二叉树的算法, 其中有5个语句缺失. 请阅读此算法并把缺失的语句补上. (每空3分)Void CreateBinTree(BinTreeNode *&BT, char ls){Stack<BinTreeNode*>s; MakeEmpty(s);BT=NULL; //置二叉树BinTreeNode *p;int k;istream ins(ls); //把串ls定义为输入字符串流对象insChar ch;ins>>ch; //从ins顺序读入一个字符While(ch!=”#”){ //逐个字符处理,直到遇到'#'为止Switch(ch){case’(‘: _______(1)_______k=1;break;case’)’: pop(s);break;case’,‘: _______(2)_______break;default: p=new BinTreeNode;_______(3)_______p->leftChild=NULL;p->rightChild=NULL;if(BT==NULL)_______(4)_______else if (k==1) top(s)->leftChild=p;else top(s)->rightChild=p;}_______(5)_______}}七、下面是一个用C编写的快速排序算法. 为了避免最坏情况,取基准记录pivot采用从left,right和mi d=[(left+right)/2]中取中间值, 并交换到right位置的办法. 数组a存放待排序的一组记录, 数据类型为Type, left和right是呆排序子区间的最左端点和最右端点.Void quicksort(Type a&#;,int left,int right){Type temp;If(left<right){Type pivot=median3(a,left,right);Int I=left, j=right-1;For( ; ; ){While(i<j && a[i]<pivot) i++;While(i<j && pivot<a[j]) j--;if(i<j){temp=a[i]; a[j]=a[i]; a[i]=temp;I++; j--;}else break;}if(a[i]>pivot){temp=a[i]: a[i]=a[right]; a[right]=temp;}quicksort(a,left,i-1); //递归排序左子区间quicksort(a,i+1,right); //递归排序右子区间}}(1) 用C 或Pascal 实现三者取中子程序 median3(a,left,right); (5分)(2) 改写 quicksort 算法, 不用栈消去第二个递归调用 quicksort(a,i+1,right); (5分)(3) 继续改写 quicksort 算法, 用栈消去剩下的递归调用. (5分)编译原理及操作系统试题内容:编译原理部分1.(5%) 给出下述NFA M 的五元组表示, 并将其确定化2 (5%) 构造一个不具有ε-转移的NFA M ’ , 使得L(M ’)=L(M)3 (10%) 证明文法G[A]是LR(1)文法.G[A]: A->BA|εB->aB|b4 (5%) 证明合并不存在冲突(移进/归约、归约/归约)的LR(1)项目集的同心集不会产生新的移进/归约冲突.5.(5%) 对目标代码运行时的存储空间采用基于过程活动记录的栈式分配方案, 举例说明象PASCAL 这样的语言如何实现对非局部变量的访问.6(15%) 文法G[R]: R->R+R | R ·R | R*| (R) | a | b | ε(1)证明文法G[R] 生成字母表Σ={a, b} 上的所有正规表达式(用+代替”|”, 连接符·没有省略)(2)证明此文法是二义的(3)根据正规式的三个运算符(+,·, *) (或, 连接, 闭包) 的优先性和结合性约定重新构造一个等价的LL(1) 文法7(5%) 找出下列流图中的回边和回边组成的循环.编译中利用流图完成什么工作?操作系统部分一、名次解释(10分)多道程序、多重处理、进程、线程、虚存二、画出NT操作系统的线程状态转移图(10分)三、UNIX系统与Linux系统等中都提供pipe文件功能,简述pipe() 的工作原理。

习题和解析第一部分《计算机原理组成》中各章习题的解析及补充题的解析。
第1章计算机系统概论1.1习题解析一、选择题1.在下列四句话中,最能准确反映计算机主要功能的是。
A.计算机可以存储大量信息B.计算机能代替人的脑力劳动C.计算机是一种信息处理机D.计算机可实现高速运算解:答案为C。
2.1946年2月,在美国诞生了世界上第一台电子数字计算机,它的名字叫(1),1949年研制成功的世界上第一台存储程序式的计算机称为(2)。
(1)A.EDV AC B.EDSAC C.ENIAC D.UNIVAC-Ⅰ(2)A.EDV AC B.EDSAC C.ENIAC D.UNIVAC-Ⅰ解:答案为⑴ C,⑵A。
3.计算机硬件能直接执行的只能是。
A.符号语言 B.机器语言C.汇编语言 D.机器语言和汇编语言解:答案为B。
4.运算器的核心部件是。
A.数据总线 B.数据选择器 C.累加寄存器 D.算术逻辑运算部件解:答案为D。
5.存储器主要用来。
A.存放程序 B.存放数据 C.存放微程序 D.存放程序和数据解:答案为D。
6.目前我们所说的个人台式商用机属于。
A.巨型机 B.中型机C.小型机 D.微型机解:答案为D。
7.至今为止,计算机中所含所有信息仍以二进制方式表示,其原因是。
A.节约元件 B.运算速度快C.物理器件性能决定 D.信息处理方便解:答案为C。
8.对计算机软、硬件资源进行管理,是的功能。
A.操作系统 B.数据库管理系统C.语言处理程序 D.用户程序解:答案为A。
9.企事业单位用计算机计算、管理职工工资,这属于计算机的应用领域。
A.科学计算 B.数据处理C.过程控制 D.辅助设计解:答案为B。
10.微型计算机的发展以技术为标志。
A.操作系统 B.微处理器C.硬盘 D.软件解:答案为B。
二、填空题1.操作系统是一种(1),用于(2),是(3)的接口。
(1)A.系统程序 B.应用程序 C.用户程序 D.中间件(2)A.编码转换 B.操作计算机 C.管理和控制计算机的资源D.把高级语言程序翻译成机器语言程序(3)A.软件与硬件 B.主机与外设 C.用户与计算机 D.高级语言与机器语言机解:答案为⑴A⑵ C ⑶ C。

一.选择题(每空1分,共20分)1.将有关数据加以分类、统计、分析,以取得有利用价值的信息,我们称其为_____。
A. 数值计算B. 辅助设计C. 数据处理D. 实时控制2.目前的计算机,从原理上讲______。
A.指令以二进制形式存放,数据以十进制形式存放B.指令以十进制形式存放,数据以二进制形式存放C.指令和数据都以二进制形式存放D.指令和数据都以十进制形式存放3.根据国标规定,每个汉字在计算机内占用______存储。
A.一个字节B.二个字节C.三个字节D.四个字节4.下列数中最小的数为______。
A.(101001)2B.(52)8C.(2B)16D.(44)105.存储器是计算机系统的记忆设备,主要用于______。
A.存放程序B.存放软件C.存放微程序D.存放程序和数据6.设X= —0.1011,则[X]补为______。
A.1.1011B.1.0100C.1.0101D.1.10017. 下列数中最大的数是______。
A.(10010101)2B.(227)8C.(96)16D.(143)108.计算机问世至今,新型机器不断推陈出新,不管怎样更新,依然保有“存储程序”的概念,最早提出这种概念的是______。
A.巴贝奇B.冯. 诺依曼C.帕斯卡D.贝尔9.在CPU中,跟踪后继指令地指的寄存器是______。
A.指令寄存器B.程序计数器C.地址寄存器D.状态条件寄存器10. Pentium-3是一种__A____。
A.64位处理器B.16位处理器C.准16位处理器D.32位处理器11. 三种集中式总线控制中,_A_____方式对电路故障最敏感。
A.链式查询B.计数器定时查询C.独立请求12. 外存储器与内存储器相比,外存储器____B__。
A.速度快,容量大,成本高B.速度慢,容量大,成本低C.速度快,容量小,成本高D.速度慢,容量大,成本高13. 一个256KB的存储器,其地址线和数据线总和为__C____。
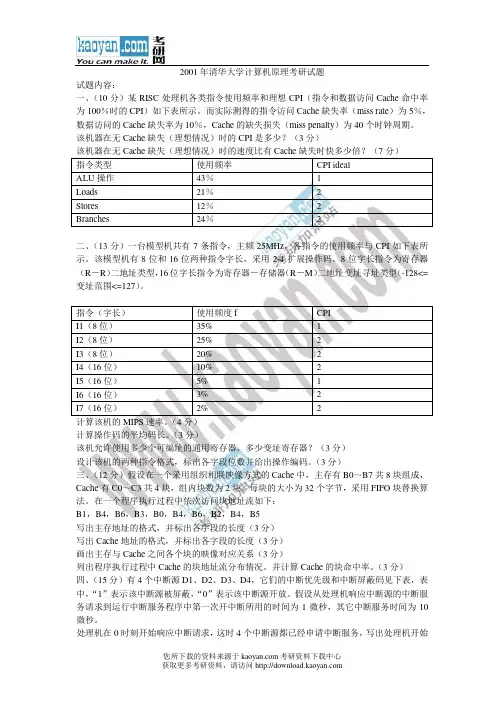
2001年清华大学计算机原理考研试题试题内容:一、(10分)某RISC处理机各类指令使用频率和理想CPI(指令和数据访问Cache命中率为100%时的CPI)如下表所示。
而实际测得的指令访问Cache缺失率(miss rate)为5%,数据访问的Cache缺失率为10%,Cache的缺失损失(miss penalty)为40个时钟周期。
该机器在无Cache缺失(理想情况)时的CPI是多少?(3分)该机器在无Cache缺失(理想情况)时的速度比有Cache缺失时快多少倍?(7分)指令类型使用频率CPI idealALU操作43% 1Loads 21% 2Stores 12% 2Branches 24% 2二、(13分)一台模型机共有7条指令,主频25MHz,各指令的使用频率与CPI如下表所示。
该模型机有8位和16位两种指令字长,采用2-4扩展操作码。
8位字长指令为寄存器(R-R)二地址类型,16位字长指令为寄存器-存储器(R-M)二地址变址寻址类型(-128<=变址范围<=127)。
指令(字长)使用频度f CPII1(8位)35% 1I2(8位)25% 2I3(8位)20% 2I4(16位)10% 2I5(16位)5% 1I6(16位)3% 2I7(16位)2% 2计算该机的MIPS速率。
(4分)计算操作码的平均码长。
(3分)该机允许使用多少个可编址的通用寄存器,多少变址寄存器?(3分)设计该机的两种指令格式,标出各字段位数并给出操作编码。
(3分)三、(12分)假设在一个采用组织相联映像方式的Cache中,主存有B0~B7共8块组成,Cache有C0~C3共4块,组内块数为2块。
每块的大小为32个字节,采用FIFO块替换算法。
在一个程序执行过程中依次访问块地址流如下:B1,B4,B6,B3,B0,B4,B6,B2,B4,B5写出主存地址的格式,并标出各字段的长度(3分)写出Cache地址的格式,并标出各字段的长度(3分)画出主存与Cache之间各个块的映像对应关系(3分)列出程序执行过程中Cache的块地址流分布情况。

计算机组成原理试题及答案一、填空(12分)1.某浮点数基值为2,阶符1位,阶码3位,数符1位,尾数7位,阶码和尾数均用补码表示,尾数采用规格化形式,用十进制数写出它所能表示的最大正数,非0最小正数,最大负数,最小负数。
2.变址寻址和基址寻址的区别是:在基址寻址中,基址寄存器提供,指令提供;而在变址寻址中,变址寄存器提供,指令提供。
3.影响流水线性能的因素主要反映在和两个方面。
4.设机器数字长为16位(含1位符号位)。
若1次移位需10ns,一次加法需10ns,则补码除法需时间,补码BOOTH算法最多需要时间。
5.CPU从主存取出一条指令并执行该指令的时间叫,它通常包含若干个,而后者又包含若干个。
组成多级时序系统。
二、名词解释(8分)1.微程序控制2.存储器带宽3.RISC4.中断隐指令及功能三、简答(18分)1. 完整的总线传输周期包括哪几个阶段?简要叙述每个阶段的工作。
2. 设主存容量为1MB,Cache容量为16KB,每字块有16个字,每字32位。
(1)若Cache采用直接相联映像,求出主存地址字段中各段的位数。
(2)若Cache采用四路组相联映像,求出主存地址字段中各段的位数。
3. 某机有五个中断源,按中断响应的优先顺序由高到低为L0,L1,L2,L3,L4,现要求优先顺序改为L3,L2,L4,L0,L1,写出各中断源的屏蔽字。
4. 某机主存容量为4M ×16位,且存储字长等于指令字长,若该机的指令系统具备120种操作。
操作码位数固定,且具有直接、间接、立即、相对四种寻址方式。
(1)画出一地址指令格式并指出各字段的作用; (2)该指令直接寻址的最大范围; (3)一次间址的寻址范围; (4)相对寻址的寻址范围。
四、(6分)设阶码取3位,尾数取6位(均不包括符号位),按浮点补码运算规则计算 [25169⨯] + [24)1611(-⨯]五、画出DMA 方式接口电路的基本组成框图,并说明其工作过程(以输入设备为例)。

题号一二三四共计分数阅卷人一、单项选择题(每题 2分,共 30分)1 冯. 诺依曼计算机构造的核心思想是:_____ 。
A 二进制运算B有储存信息的功能 C 运算速度快 D 储存程序控制2 计算机硬件能够直接履行的只有_____。
A机器语言B汇编语言 C 机器语言和汇编语言 D 各样高级语言3 零的原码能够用哪个代码来表示:_____ 。
A 11111111B 10000000C 01111111D 11000004 某数在计算机顶用 8421码表示为0111 1000 1001,其真值为_____。
A 789B 789HC 19295当前在小型和微型计算机里最广泛采纳的字符编码是_____。
A BCD 码B 十六进制代码C AS CⅠⅠ码D海明码6当 -1 < x<0时,【x】原= :______。
A 1-xB xC2+xD(2-2 -n ) - ︱x ︳7 履行一条一地点的加法指令需要接见主存______次。
A1 B 2 C 3D48 在寄存器间接寻址中,操作数应在______中。
A 寄存器B 货仓栈顶C 累加器D 主存单元9 在串行进位的并行加法器中,影响加法器运算速度的重点要素是:______。
A 门电路的级延缓B 元器件速度C 进位传达延缓D 各位加法器速度的不同10 运算器虽由很多零件构成,但核心零件是______。
A 算术逻辑运算单元B 多路开关C 数据总线D 累加寄存器11 在浮点数编码表示中______在机器中不出现,是隐含的。
A.阶码B.符号C尾数D基数12 以下对于 RISC的表达中,错误的选项是:______。
A RISC 广泛采纳微程序控制器B RISC 大部分指令在一个时钟周期内达成C RISC 的内部通用寄存器数目相对CISC少D RISC 的指令数、寻址方式和指令格式种类相对CISC少13计算机主频的周期是指______。
A 指令周期B时钟周期 C CPU 周期 D 存取周期14 冯. 诺依曼计算机中指令和数据均以二进制形式寄存在储存器中,CPU 划分它们的依照是______。

清华大学2001年计算机组成原理试题试题内容:一、(10分)某RISC处理机各类指令使用频率和理想CPI(指令和数据访问Cache命中率为100%时的CPI)如下表所示。
而实际测得的指令访问Cache缺失率(miss rate)为5%,数据访问的Cache缺失率为10%,Cache的缺失损失(miss penalty)为40个时钟周期。
(1)该机器在无Cache缺失(理想情况)时的CPI是多少?(3分)(2)该机器在无Cache缺失(理想情况)时的速度比有Cache缺失时快多少倍?(7分)指令类型使用频率 CPI idealALU操作 43% 1Loads 21% 2Stores 12% 2Branches 24% 2二、(13分)一台模型机共有7条指令,主频25MHz,各指令的使用频率与CPI如下表所示。
该模型机有8位和16位两种指令字长,采用2-4扩展操作码。
8位字长指令为寄存器(R-R)二地址类型,16位字长指令为寄存器-存储器(R-M)二地址变址寻址类型(-128<=变址范围<=127)。
指令(字长)使用频度f CPII1(8位) 35% 1I2(8位) 25% 2I3(8位) 20% 2I4(16位) 10% 2I5(16位) 5% 1I6(16位) 3% 2I7(16位) 2% 2(1)计算该机的MIPS速率。
(4分)(2)计算操作码的平均码长。
(3分)(3)该机允许使用多少个可编址的通用寄存器,多少变址寄存器?(3分)(4)设计该机的两种指令格式,标出各字段位数并给出操作编码。
(3分)三、(12分)假设在一个采用组织相联映像方式的Cache中,主存有B0~B7共8块组成,Cache有C0~C3共4块,组内块数为2块。
每块的大小为32个字节,采用FIFO块替换算法。
在一个程序执行过程中依次访问块地址流如下:B1,B4,B6,B3,B0,B4,B6,B2,B4,B5(1)写出主存地址的格式,并标出各字段的长度(3分)(2)写出Cache地址的格式,并标出各字段的长度(3分)(3)画出主存与Cache之间各个块的映像对应关系(3分)(4)列出程序执行过程中Cache的块地址流分布情况。
计算机组成原理试题及答案优选【五】篇(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如工作计划、工作总结、规章制度、策划方案、演讲致辞、合同协议、条据书信、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays for everyone, such as work plans, work summaries, rules and regulations, planning plans, speeches, contract agreements, document letters, teaching materials, complete essays, and other sample essays. If you want to learn about different sample formats and writing methods, please pay attention!计算机组成原理试题及答案优选【五】篇计算机组成原理试题及答案 1(共18分)1.比较程序XX方式、程序中断方式、直接存储器访问方式,在完成输入/输出操作时的优缺点。
计算机组成原理试题及答案计算机组成原理试题及答案一、选择题(共20分,每题1分)1.零地址运算指令在指令格式中不给出操作数地址,它的操作数来自______。
A.立即数和栈顶; B.暂存器; C.栈顶和次栈顶; D.累加器。
2.______可区分存储单元中存放的是指令还是数据。
A.存储器;B.运算器;C.控制器;D.用户。
3.所谓三总线结构的计算机是指______。
A.地址线、数据线和控制线三组传输线。
B.I/O总线、主存总统和DMA总线三组传输线;C.I/O总线、主存总线和系统总线三组传输线;D.设备总线、主存总线和控制总线三组传输线。
4.某计算机字长是32位,它的存储容量是256KB,按字编址,它的寻址范围是______。
A.128K;B.64K;C.64KB;D.128KB。
5.主机与设备传送数据时,采用______,主机与设备是串行工作的。
A.程序查询方式;B.中断方式;C.DMA方式;D.通道。
6.在整数定点机中,下述第______种说法是正确的。
A.原码和反码不能表示-1,补码可以表示-1;B.三种机器数均可表示;C.三种机器数均可表示-1,且三种机器数的表示范围相同;D.三种机器数均不可表示。
7.变址寻址方式中,操作数的有效地址是______。
A.基址寄存器内容加上形式地址(位移量); B.程序计数器内容加上形式地址; C.变址寄存器内容加上形式地址; D.以上都不对。
8.向量中断是______。
A.外设提出中断;B.由硬件形成中断服务程序入口地址;C.由硬件形成向量地址,再由向量地址找到中断服务程序入口地址D.以上都不对。
9.一个节拍信号的宽度是指______。
A.指令周期;B.机器周期;C.时钟周期;D.存储周期。
10.将微程序存储在EPROM中的控制器是______控制器。
A.静态微程序;B.毫微程序;C.动态微程序;D.微程序。
11.隐指令是指______。
A.操作数隐含在操作码中的指令;B.在一个机器周期里完成全部操作的指令;C.指令系统中已有的指令;D.指令系统中没有的指令。
2001年《计算机组成原理》考题答案 一、 单项选择题(从每小题的4个备选答案中选出一个正确答案,填入题干的括号内。
每小题2分,共20分) 1、隐地址是指(②)。
①隐指令的地址②不出现在指令中的地址③间接地址 ④主存单元的地址2、在微程序控制方式中,一段微程序解释执行(④)。
①一个微操作②一步操作③一条微指令 ④一条机器指令3、在规格化浮点运算中,若某浮点数为25×1.00101,其中尾数为补码表示,则该数( ① )。
①不需规格化 ②需右移规格化 ③需将尾数左移一位规格化 ④需将尾数左移两位规格化 4、将0.101101变补后,正确的结果是( ③ )。
①1.101101 ②0.010011 ③1.010011 ④0.101101 5、在同步控制方式中,各操作( ④ )。
①由CPU统一控制 ②按实际需要分配时间 ③用异步应答方式实现衔接 ④由统一的时序信号控制 6、静态存储器的特点是( ② )。
①靠重写保持信息不变 ②靠电源电流保持信息不变 ③靠只读不写保持信息不变 ④靠电容电荷保持信息不变 7、CPU在中断响应周期中( ① )。
①关中断 ②设置屏蔽字 ③传送数据 ④执行中断服务程序 8、在字符显示方式下,字符编码存放在( ③ )。
①字符发生器中 ②主存中 ③显示缓冲存储器中 ④显示器控制器中 9、在DMA方式中,数据传送由( ② )。
①总线控制器控制 ②DMA控制器控制 ③CPU控制 ④接口控制 10、串行总线适用于( ③ )。
①CPU内总线 ②系统总线 ③外总线 ④任何总线 二、判断题(下列说法有的正确,有的错误,请作出正/误判断,并将判断结果填在题后的括号内。
每小题2分,共10分) 1、在补码除法中,够减商1,不够减商0。
( 误 ) 2、微指令周期是指从主存中读取并执行一条微指令所用的时间。
( 误 ) 3、压栈操作是将有关信息写入堆栈指针SP所指示的存储单元。
( 正 ) 4、DMA请求的优先级高于中断请求的优先级。
计算机组成原理试题及答案一、选择题1. 在计算机中,下列哪个部件是负责执行算术和逻辑运算的?A. 控制器B. 内存C. CPUD. 输入输出设备答案:C2. 冯·诺依曼体系结构中,程序指令和数据都存储在哪个部分?A. 寄存器B. 缓存C. 内存D. 硬盘答案:C3. 下列哪种类型的半导体材料通常用于制造集成电路?A. 硅B. 锗C. 石墨D. 金刚石答案:A4. 在计算机系统中,总线的作用是什么?A. 连接CPU和内存B. 连接显示器和键盘C. 连接所有外部设备D. 传输数据、地址和控制信号答案:D5. 下列哪个术语描述的是计算机处理的信息的最小单位?A. 位B. 字节C. 字D. 千字节答案:A二、填空题1. 一个标准的ASCII码使用__位来表示一个字符。
答案:72. 在计算机中,CPU通过__与内存进行通信。
答案:总线3. 一个32位的系统可以寻址的内存空间最大为__GB。
答案:44. 在计算机组成中,__是指计算机中用于存储指令和数据的半导体存储器。
答案:内存5. 一个计算机系统的性能很大程度上取决于其__的速度。
答案:CPU三、简答题1. 请简述冯·诺依曼体系结构的基本原理。
答:冯·诺依曼体系结构的基本原理是将程序指令和数据统一存储在内存中,并通过一个中央处理单元(CPU)来执行这些指令和处理数据。
该体系结构采用二进制表示数据,并通过一个控制单元来解释内存中的指令并控制数据流。
2. 什么是缓存,它是如何提高计算机性能的?答:缓存是一种高速存储器,用于暂时存储频繁访问的数据和指令。
它可以减少CPU访问慢速内存的次数,从而加快数据处理速度和提高整体系统性能。
3. 描述计算机中总线的基本功能。
答:总线在计算机中起到连接各个部件并传输数据、地址和控制信号的作用。
它允许CPU、内存和其他外围设备之间进行通信,确保数据能够高效地在系统内部流动。
四、论述题1. 论述计算机组成中的输入输出系统的重要性及其工作原理。
计算机组成原理习题(附参考答案)一、单选题(共90题,每题1分,共90分)1、在统一编址方式下,下面的说法( )是正确的。
A、一个具体地址只能对应内存单元B、一个具体地址既可对应输入/输出设备,又可对应内存单元C、一个具体地址只能对应输入/输出设备D、只对应输入/输出设备或者只对应内存单元正确答案:D2、堆栈指针SP的内容是()。
A、栈顶地址B、栈顶内容C、栈底内容D、栈底地址正确答案:A3、下列不属于程序控制指令的是()。
A、循环指令B、无条件转移指令C、条件转移指令D、中断隐指令正确答案:D4、计算机的存储系统是指()。
A、cache,主存储器和外存储器B、主存储器C、ROMD、RAM正确答案:A5、指令是指()。
A、计算机中一个部件B、发给计算机的一个操作命令C、完成操作功能的硬件D、通常用于构成主存的集成电路正确答案:B6、相对于微程序控制器,组合逻辑控制器的特点是()。
A、指令执行速度慢,指令功能的修改和扩展容易B、指令执行速度慢,指令功能的修改和扩展难C、指令执行速度快,指令功能的修改和扩展容易D、指令执行速度快,指令功能的修改和扩展难正确答案:D7、中断向量可提供()。
A、主程序的断点地址B、传送数据的起始地址C、被选中设备的地址D、中断服务程序入口地址正确答案:D8、迄今为止,计算机中的所有信息仍以二进制方式表示的理由是()。
A、信息处理方便B、物理器件性能所致C、运算速度快D、节约元件正确答案:B9、相联存储器是按()进行寻址的存储器。
A、内容指定方式B、地址指定与堆栈存取方式结合C、堆栈存取方式D、地址指定方式正确答案:A10、若SRAM芯片的容量是2M×8位,则该芯片引脚中地址线和数据线的数目之和是()。
A、29B、21C、18D、不可估计正确答案:A11、若x=103,y=-25,则下列表达式采用8位定点补码运算实现时,会发生溢出的是()。
A、x+yB、-x+yC、-x-yD、x-y正确答案:D12、系统总线是指()。
计算机组成原理试题班号:学号:姓名:(所有答案均写在答题纸上)一.填空(20分)1.(4分)给出十进制数-254的IEEE754标准单精度浮点数表示。
(-254)= ⑴。
2.(3分)某计算机字长16位,整数用补码表示,按字编址。
某C语言定义了i, j, k共3个short型变量,其中有程序段如下:{ i = 105; j = -12767; k = i + j; }。
编译器将i, j, k三个变量分配到地址分别为100、101和102三个内存单元中。
则上述程序段执行完成后,地址100内容为⑵,地址101的内容为⑶,地址102的内容为⑷。
(均用16进制表示)。
3.(3分)TEC2008使用THCO MIPS指令系统,指令BEQZ rx, imm的功能为当rx的值为0时跳转,指令操作码为00100。
在内存地址为0109H处有一条机器指令,二进制形式为(0010000011111100),该指令执行前寄存器r0的值为0。
则该指令成功执行后,PC值为⑸。
(用16进制表示)。
4.(5分)常见的指令寻址方式:⑹、⑺、⑻、⑼、⑽。
5.(5分)中断处理过程包括关中断、⑾、⑿、开中断、⒀、关中断、⒁、开中断、⒂等步骤。
二.单项选择(20分,每题2分)1.下列选项中,能缩短程序执行时间的是。
I.提高CPU时钟频率 II.优化数据通路结构 III.对程序进行编译优化A.仅I和II B.仅I和III C.仅II和III D.I,II,III2.某一编码系统中,数据为8位。
为提高系统的可靠性,希望能发现2位出错,并能在仅有1位出错时进行纠正,则需要增加的校验位的位数至少是。
A.3位 B.4位 C.5位 D.6位3.下列寄存器中,汇编程序员可见的是。
A.存储器地址寄存器(MAR)B.程序计数器(PC)C.存储器数据寄存器(MDR)D.指令寄存器(IR)4.微程序存放的位置是。
A.CPU B.高速缓冲存储器 C.主存储器 D.磁盘存储器5.下面关于多周期CPU的描述,正确的是。
清华大学2001年计算机组成原理试题
试题内容:
一、(10分)某RISC处理机各类指令使用频率和理想CPI(指令和数据访问Cache命中率为100%时的CPI)如下表所示。
而实际测得的指令访问Cache缺失率(miss rate)为5%,数据访问的Cache缺失率为10%,Cache的缺失损失(miss penalty)为40个时钟周期。
(1)该机器在无Cache缺失(理想情况)时的CPI是多少?(3分)
(2)该机器在无Cache缺失(理想情况)时的速度比有Cache缺失时快多少倍?(7分)指令类型使用频率 CPI ideal
ALU操作 43% 1
Loads 21% 2
Stores 12% 2
Branches 24% 2
二、(13分)一台模型机共有7条指令,主频25MHz,各指令的使用频率与CPI如下表所示。
该模型机有8位和16位两种指令字长,采用2-4扩展操作码。
8位字长指令为寄存器(R-R)二地址类型,16位字长指令为寄存器-存储器(R-M)二地址变址寻址类型(-128<=变址范围<=127)。
指令(字长)使用频度f CPI
I1(8位) 35% 1
I2(8位) 25% 2
I3(8位) 20% 2
I4(16位) 10% 2
I5(16位) 5% 1
I6(16位) 3% 2
I7(16位) 2% 2
(1)计算该机的MIPS速率。
(4分)
(2)计算操作码的平均码长。
(3分)
(3)该机允许使用多少个可编址的通用寄存器,多少变址寄存器?(3分)
(4)设计该机的两种指令格式,标出各字段位数并给出操作编码。
(3分)
三、(12分)假设在一个采用组织相联映像方式的Cache中,主存有B0~B7共8块组成,Cache有C0~C3共4块,组内块数为2块。
每块的大小为32个字节,采用FIFO块替换算法。
在一个程序执行过程中依次访问块地址流如下:
B1,B4,B6,B3,B0,B4,B6,B2,B4,B5
(1)写出主存地址的格式,并标出各字段的长度(3分)
(2)写出Cache地址的格式,并标出各字段的长度(3分)
(3)画出主存与Cache之间各个块的映像对应关系(3分)
(4)列出程序执行过程中Cache的块地址流分布情况。
并计算Cache的块命中率。
(3分)四、(15分)有4个中断源D1、D2、D3、D4,它们的中断优先级和中断屏蔽码见下表,表中,"1"表示该中断源被屏蔽,"0"表示该中断源开放。
假设从处理机响应中断源的中断服务请求到运行中断服务程序中第一次开中断所用的时间为1微秒,其它中断服务时间为10微秒。
(1)处理机在0时刻开始响应中断请求,这时4个中断源都已经申请中断服务,写出处理机开始响应各中断源的中断请求和处理机为各中断源完成中断服务的时刻。
(7分)
(2)处理机在0时刻开始响应中断请求,这时中断源D3和D4已经申请中断服务,在6
微秒时中断源D1和D2同时申请中断服务,写出处理机开始响应各中断源的中断请求和处理机为各中断源完成中断服务的时刻。
(8分)
中断源中断优先级中断屏蔽码D1 D2 D3 D4
D1 1(最高) 1 1 0 0
D2 2(第二) 0 1 0 1
D3 3(第三) 1 0 1 0
D4 4(最低) 1 0 1 1
五、(10分)假定我们将某一执行部件性能改进后速度提高10倍。
改进后被改进部件执行时间占系统总运行时间的50%。
则改进后获得的加速比Sp是多少?
六、(10分)在下列单级互连网络中,将信息从一个PE播送给所有其它PE要用多少步(N =2n个PE)?
(1)混洗交换网络,每步只能做一次混洗或一次交换。
(5分)
(2)超立方体网络,每步i(0≤i≤n-1)可实现寻径函数Ci。
(5分)
七、(15分)在一台单流水线处理机上执行下面的程序。
每条指令都要经过"取指令"、"译码"、"执行"和"写结果"4个流水段,每个流水段的延迟时间都是5ns。
在"执行"流水段,L S部件完成LOAD和STORE操作,其他操作都在ALU部件中完成,两个操作部件的输出端有直接数据通路与任意一个操作部件的输入端相连接,ALU部件产生的条件码也能够直接送入控制器。
1: SUB R0, R0 :R0←0
2: LOAD R1, #8 :R1←向量长度8
3:LOOP: LOAD R2, A(R1) :R2←A向量的一个元素
4: MUL R2, R1 :R2←(R2)×(R1)
5: ADD R0, R2 :R0←(R0)+(R2)
6: DNE R1, LOOP :R1←(R1)-1,若(R1)≠0 转向LOOP
7: STORE R0, S :保存结果
(1)采用静态分支预测技术,每次都预测转移不成功。
画出指令流水线的时空图(中间部分可以省略,图中可用指令序号表示),计算流水线的吞吐率和加速比,并分别计算译码部件和ALU部件的使用效率。
(8分)
(2)采用静态分支预测技术,每次都预测转移成功。
计算指令流水线的吞吐率和加速比,并分别计算译码部件和ALU部件的使用效率。
(7分)
八、(15分)分别在下面三种计算机系统上用最短的时间来计算表达式。
假设加法和乘法分别需要2个和4个单位时间,从存储器取指令、取数据、译码的时间忽略不计,所有的指令和数据已装入有关的PE或处理机中。
PE或处理机中有一个加法器和一个乘法器,同一时刻只有其中一个可以使用。
试确定下列每种情况的最小计算时间。
(1)一台串行计算机,这种单处理机系统不需要数据寻径操作。
(3分)
(2)一台有8个PE(PE0,PE1,···,PE7)的SIMD计算机,8个PE连成单向环结构。
每个PE用一个单位时间可以把数据直接送给它的相邻PE。
操作数Ai和Bi最初存放在PEi mod 8 中,其中i=0,2,···,35。
(6分)
(3)分布存储器的MIMD多处理机,8个CPU用立方体网连接。
在相邻CPU之间传送一个数据需要一个单位时间。
操作数Ai和Bi最初存放在CPU i mod 8中,其中i=0,1,···,
35。
最终结果s可以放在任意CPU的寄存器中。
(6分)总共用时=35+1次乘法=39单位时间。