贾俊平《统计学》(第5版)课后习题-第4章 数据的概括性度量【圣才出品】
- 格式:pdf
- 大小:854.93 KB
- 文档页数:20


统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1。
3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。


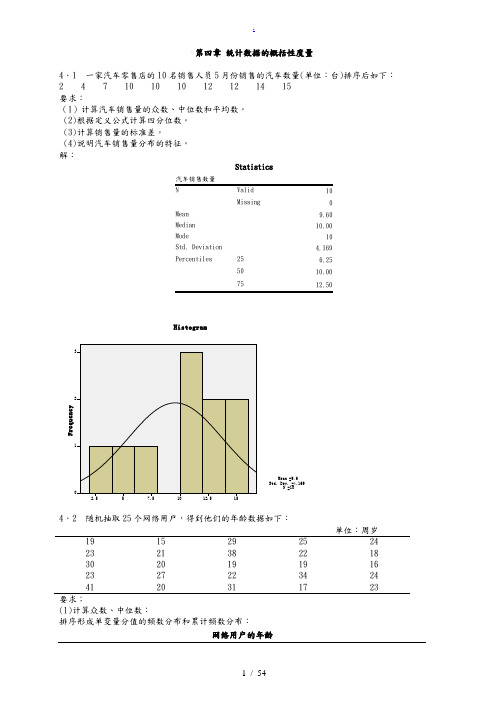
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:StatisticsMissing0Mean9.60Median10.00Mode10Std. Deviation 4.169Percentiles25 6.255010.007512.504.2下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 最小值)÷ 组数=(4115)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)4.3 某银行为缩短顾客到银行办理业务等待的时间。

【关键字】单位《统计学》分章习题及答案(贾俊平,第五版)主编:杨群目录习题部分第1章导论一、单项选择题1.指出下面的数据哪一个属于分类数据()A.年龄B.工资C.汽车产量D.购买商品的支付方式(现金、信用卡、支票)2.指出下面的数据哪一个属于顺序数据()A.年龄B.工资C.汽车产量D.员工对企业某项制度改革措施的态度(赞成、中立、反对)3.某研究部门准备在全市200万个家庭中抽取2000个家庭,据此推断该城市所有职工家庭的年人均收入,这项研究的统计量是()A.2000个家庭B.200万个家庭C.2000个家庭的人均收入D.200万个家庭的人均收入4.了解居民的消费支出情况,则()A.居民的消费支出情况是总体B.所有居民是总体C.居民的消费支出情况是总体单位D.所有居民是总体单位5.统计学研究的基本特点是()A.从数量上认识总体单位的特征和规律B.从数量上认识总体的特征和规律C.从性质上认识总体单位的特征和规律D.从性质上认识总体的特征和规律6.一家研究机构从IT从业者中随机抽取500人作为样本进行调查,其中60%的人回答他们的月收入在5000元以上,50%的回答他们的消费支付方式是使用信用卡。
这里的“月收入”是()A.分类变量B.顺序变量C.数值型变量D.离散变量7.要反映我国工业企业的整体业绩水平,总体单位是()A.我国每一家工业企业B.我国所有工业企业C.我国工业企业总数D.我国工业企业的利润总额8.一项调查表明,在所抽取的1000个消费者中,他们每月在网上购物的平均消费是200元,他们选择在网上购物的主要原因是“价格便宜”。
这里的参数是()A.1000个消费者B.所有在网上购物的消费者C.所有在网上购物的消费者的平均消费额D.1000个消费者的平均消费额9.一名统计学专业的学生为了完成其统计作业,在《统计年鉴》中找到的2006年城镇家庭的人均收入数据属于()A.分类数据B.顺序数据C.截面数据D.时间序列数据10.一家公司的人力资源部主管需要研究公司雇员的饮食习惯,改善公司餐厅的现状。
第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。

第四章统计数据的概括性度量欧阳歌谷(2021.02.01)4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.00754.2 随机抽取单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。

第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:StatisticsMissing0Mean9.60Median10.00Mode10Std. Deviation 4.169Percentiles25 6.255010.007512.504.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 最小值)÷ 组数=(4115)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。

第四章统计数据的概括性度量4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量Missing0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()l g 25l g () 1.398111 5.64l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。

第4章数据的概括性度量一、单项选择题1.某企业男性职工占80%,月平均工资为450元,女性职工占20%,月平均工资为400元,该企业全部职工的平均工资为()。
[中央财经大学2015研] A.425元B.430元C.435元D.440元【答案】D【解析】企业全部职工的平均工资=男性职工比例×男性月平均工资+女性职工比例×女性月平均工资=80%×450+20%×400=440(元)。
2.15位同学的某门课程考试成绩中,70分出现3次,80分出现4次,85分出现6次,90分出现2次,则他们成绩的众数为()。
[华中农业大学2015研] A.80B.85C.81.3D.90【答案】B【解析】众数是一组数据中出现次数最多的变量值。
题中,85分出现次数最多,故成绩的众数为85分。
3.一组样本的变异系数(CV)等于10,样本均值为5,则样本方差为()。
[厦门大学2014研]A.2B.4C.0.5D.2500【答案】D【解析】变异系数是一组数据的标准差与其相应的平均数之比,因而样本标准差=样本均值×变异系数=5×10=50,样本方差=50×50=2500。
4.现抽取了10个同学,每个同学的月生活费数据排序后为:660,750,780,850,960,1080,1250,1500,1630,2000。
则中位数的位置为()。
[重庆大学2013研]A.5.5B.5C.4D.6【答案】A【解析】中位数是将样本排序后处于中间位置的数据,总共有10个样本,因此1 5.5102+==中位数的位次5.哪种频数分布状态下平均数、众数和中位数是相等的?( )[东北财经大学2011研]A .对称的钟形分布B .左偏的钟形分布C .右偏的钟形分布D .U 形分布【答案】A【解析】在频数对称且单峰分布的状态下,平均数、众数、中位数相等。
6.统计学期中考试非常简单,为了评估简单程度,教师记录了9名学生交上考试试卷的时间如下(分钟)[东北财经大学2012研]33,29,45,60,42,19,52,38,36(1)这些数据的极差为( )。
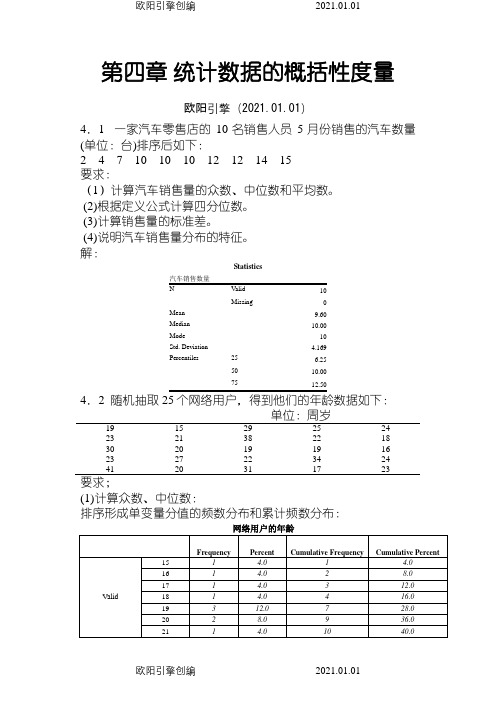
第四章统计数据的概括性度量欧阳引擎(2021.01.01)4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.00754.2 随机抽取单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线: 分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。

统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

统计学(第五版)贾俊平课后思考题和练习题答案(最终完整版)第一部分思考题第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。

目 录第1章 导 论1.1 复习笔记1.2 课后习题详解1.3 典型习题详解第2章 数据的搜集2.1 复习笔记2.2 课后习题详解2.3 典型习题详解第3章 数据的图表展示3.1 复习笔记3.2 课后习题详解3.3 典型习题详解第4章 数据的概括性度量4.1 复习笔记4.2 课后习题详解4.3 典型习题详解第5章 概率与概率分布5.1 复习笔记5.2 课后习题详解5.3 典型习题详解第6章 统计量及其抽样分布6.1 复习笔记6.2 课后习题详解6.3 典型习题详解第7章 参数估计7.1 复习笔记7.2 课后习题详解7.3 典型习题详解第8章 假设检验8.1 复习笔记8.2 课后习题详解8.3 典型习题详解第9章 分类数据分析9.1 复习笔记9.2 课后习题详解9.3 典型习题详解第10章 方差分析10.1 复习笔记10.2 课后习题详解10.3 典型习题详解第11章 一元线性回归11.1 复习笔记11.2 课后习题详解11.3 典型习题详解第12章 多元线性回归12.1 复习笔记12.2 课后习题详解12.3 典型习题详解第13章 时间序列分析和预测13.1 复习笔记13.2 课后习题详解13.3 典型习题详解第14章 指 数14.1 复习笔记14.2 课后习题详解14.3 典型习题详解第1章 导 论1.1 复习笔记一、统计学1统计学统计学是收集、处理、分析、解释数据并从数据中得出结论的科学。
数据收集也就是取得统计数据;数据处理是将数据用图表等形式展示出来;数据分析则是选择适当的统计方法研究数据,并从数据中提取有用信息进而得出结论。
2.数据分析所用的方法(1)描述统计:研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法;(2)推断统计:研究如何利用样本数据来推断总体特征的统计方法。
二、统计数据的类型1分类数据、顺序数据、数值型数据(按计量尺度不同分类)(1)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,是用文字来表述的;(2)顺序数据:只能归于某一有序类别的非数字型数据。

文小编收集文档之第四章统计数据的概括性度量'4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.00754.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
1、确定组数: ()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)验:一种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
第4章 数据的概括性度量
一、思考题
1.一组数据的分布特征可以从哪几个方面进行测度?
答:数据分布的特征可以从三个方面进行测度和描述:
(1)分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;
(2)分布的离散程度,反映各数据远离其中心值的趋势;
(3)分布的形状,反映数据分布的偏态和峰态。
2.怎样理解平均数在统计学中的地位?
答:平均数也称为均值,它是一组数据相加后除以数据的个数得到的结果。
平均数在统计学中具有重要的地位,是集中趋势的最主要测度值,它主要适用于数值型数据,而不适用于分类数据和顺序数据。
3.简述四分位数的计算方法。
答:首先对数据进行排序,然后确定四分位数所在的位置,该位置上的数值就是四分位数。
四分位数的位置确定方法如下:设下四分位数为L Q ,上四分位数为U Q ,根据四分位数的定义有:
14
L n Q +=位置()
314
U n Q +=位置如果位置是整数,四分位数就是该位置对应的值;如果是在0.5的位置上,则取该位
置两侧值的平均数;如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按比例分摊位置两侧数值的差值。
4.对于比率数据的平均为什么采用几何平均?
答:几何平均数是指n 个变量值乘积的n
次方根,称为几何平均数。
其计算公式为:
G ==比率数据属于相对数,它不能如绝对数那样对其进行累加,而只能对其进行连乘,比如工厂年产量去年比前年的年增长率为10%,今年比去年的增长率为20%,那么今年对前年的相对增长率为(1+10%)×(1+20%)—1。
而不能用(1+10%)+(1+20%)—1来计算,这样累加的结果是没有实际意义的,因此对于比率数据,在对其计算平均数的时候,就不能像计算一般的平均数那样计算,而要用几何平均数的计算公式计算。
实际上,几何平均数也可以看做是均值的一种变形。
只要对其计算公式两边取对数,则其公式的形式变为算术平均数的公式形式。
5.简述众数、中位数和平均数的特点和应用场合。
答:(1)众数的特点如下:①其优点是不受极端值的影响;②其缺点是具有不惟一性。
一组数据可能有一个众数,也可能有两个或多个众数,也可能没有众数。
众数只有在数据量较多时才有意义,当数据量较少时,不宜使用众数。
众数主要适合作为分类数据的集中趋势测度值。
(2)中位数是一组数据中间位置上的代表值,不受数据极端值的影响。
当一组数据的分布偏斜程度较大时,使用中位数也许是一个好的选择。
中位数主要适合作为顺序数据的集中趋势测度值。
(3)平均数是对数值型数据计算的,而且利用了全部数据信息,它是实际中应用最广泛的集中趋势测度值。
当数据呈对称分布或接近对称分布时,3个代表值相等或接近相等,这时则应选择平均数作为集中趋势的代表值。
平均数的主要缺点是易受数据极端值的影响,对于偏态分布的数据,平均数的代表性较差。
因此当数据为偏态分布,特别是当偏斜程度较大时,可以考虑选择中位数或众数,这时它们的代表性要比平均数好。
6.简述异众比率、四分位差、方差或标准差的应用场合。
答:(1)异众比率主要用于衡量众数对一组数据的代表程度。
异众比率越大,说明非众数组的频数占总频数的比重越大,众数的代表性就越差;异众比率越小,说明非众数组的频数占总频数的比重越小,众数的代表性越好。
异众比率主要适合测度分类数据的离散程度,当然,对于顺序数据以及数值型数据也可以计算异众比率。
(2)四分位差主要用于测度顺序数据的离散程度。
对于数值型数据也可以计算四分位差,但不适合分类数据。
(3)方差或标准差能较好地反映出数据的离散程度,是实际中应用最广泛的离散程度测度值。
方差开方后即得到标准差。
与方差不同的是,标准差是具有量纲的,它与变量值的计量单位相同,其实际意义要比方差清楚。
因此,在对实际问题进行分析时更多地使用标准差。
7.标准分数有哪些用途?
答:变量值与其平均数的离差除以标准差后的值称为标准分数。
也称标准化值或z分
数。
设标准分数为z 。
则有
i i x x
z s -=标准分数给出了一组数据中各数值的相对位置。
在对多个具有不同量纲的变量进行处理时,常常需要对各变量进行标准化处理。
标准分数具有平均数为0、标准差为1的特性。
实际上,z 分数只是将原始数据进行了线性变换,它并没有改变一个数据在该组数据中的位置,也没有改变该组数据分布的形状,而只是将该组数据变为平均数为0,标准差为1。
8.为什么要计算离散系数?
答:方差和标准差是反映数据分散程度的绝对值,其数值的大小一方面受原变量值本身水平高低的影响,也就是与变量的平均数大小有关,变量值绝对水平高的,离散程度的测度值自然也就大,绝对水平小的离散程度的测度值自然也就小;另一方面,它们与原变量值的计量单位相同。
采用不同计量单位计量的变量值,其离散程度的测度值也就不同。
因此,对于平均水平不同或计量单位不同的不同组别的变量值,是不能用标准差直接比较其离散程度的。
为消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。
9.测度数据分布形状的统计量有哪些?
答:测度数据分布形状的统计量有以下两种:
(1)偏态,如果一组数据的分布是对称的,则偏态系数等于0;如果偏态系数明显不等于0,表明分布是非对称的。
若偏态系数大于1或小于-1,被称为高度偏态分布;若偏
态系数在0.5~1或-1~-0.5之间,被认为是中等偏态分布;偏态系数越接近0,偏斜程度就越低。
(2)峰态,通常是与标准正态分布相比较而言的。
如果一组数据服从标准正态分布,则峰态系数的值等于0;若峰态系数的值明显不等于0,则表明分布比正态分布更平或更尖,通常称为平峰分布或尖峰分布。
二、练习题
1.一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:
2 4 7 10 10 10 12 12 14 15
要求:
(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:(1)10名销售人员5月份销售的汽车数量中,销售10台汽车的人数最多,为3人,因此众数M 0=10。
中位数位置=
1101 5.522n ++==,所以1010102e M +==(台)。
平均数12415969.61010
n i
i x x n =+++====∑L (台)(2)由题中数据可得:
10 2.544
L n Q ===位置即L Q 在第2个数值(4)和第3个数值(7)之间0.5的位置上。
因此
47 5.52
L Q +==(台)由于33107.544
U n Q ⨯===位置,即U Q 在第7个数值(12)和第8个数值(12)之间0.5的位置上,因此
1212122U Q +=
=(台)(3)由平均数9.6x =
可得:
4.2s =
=
==
(4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
2.随机抽取25个网络用户,得到他们的年龄数据如表4-1所示。
表4-1 网络用户的年龄数据
单位:周
岁
19
1529252423
213822183020191916。