多元统计分析习题
- 格式:doc
- 大小:187.50 KB
- 文档页数:7

1. 在多元统计分析中,主成分分析的主要目的是:A. 减少变量数量B. 增加变量数量C. 提高模型复杂度D. 降低模型复杂度2. 下列哪种方法不属于多元回归分析?A. 逐步回归B. 岭回归C. 主成分回归D. 判别分析3. 在因子分析中,公因子的数量通常是如何确定的?A. 根据经验B. 根据数据特征C. 根据特征值大于1的原则D. 根据样本数量4. 多元统计分析中的聚类分析主要用于:A. 数据降维B. 数据分类C. 数据预测D. 数据可视化5. 在判别分析中,Fisher判别法的主要思想是:A. 最大化类间距离B. 最小化类内距离C. 最大化类内距离D. 最小化类间距离6. 下列哪种统计方法适用于处理非正态分布数据?A. 多元回归分析B. 主成分分析C. 因子分析D. 非参数统计方法7. 在多元统计分析中,协方差矩阵的作用是:A. 描述变量间的线性关系B. 描述变量间的非线性关系C. 描述变量间的独立关系D. 描述变量间的随机关系8. 下列哪种方法可以用于处理多重共线性问题?A. 逐步回归B. 岭回归C. 主成分回归D. 以上都是9. 在多元统计分析中,偏相关系数的定义是:A. 控制其他变量后,两个变量间的相关性B. 控制其他变量后,两个变量间的独立性C. 控制其他变量后,两个变量间的依赖性D. 控制其他变量后,两个变量间的随机性10. 下列哪种方法不属于时间序列分析?A. 移动平均法B. 指数平滑法C. 主成分分析D. 自回归模型11. 在多元统计分析中,典型相关分析的主要目的是:A. 分析两个变量集之间的相关性B. 分析两个变量集之间的独立性C. 分析两个变量集之间的依赖性D. 分析两个变量集之间的随机性12. 下列哪种方法可以用于处理缺失数据?A. 删除含有缺失数据的样本B. 使用均值填充C. 使用回归模型预测缺失值D. 以上都是13. 在多元统计分析中,马氏距离的定义是:A. 基于协方差矩阵的距离度量B. 基于相关矩阵的距离度量C. 基于方差矩阵的距离度量D. 基于标准差矩阵的距离度量14. 下列哪种方法不属于非线性降维方法?A. 主成分分析B. 核主成分分析C. 局部线性嵌入D. 等距映射15. 在多元统计分析中,偏最小二乘回归的主要优点是:A. 处理多重共线性问题B. 处理非正态分布数据C. 处理缺失数据D. 处理高维数据16. 下列哪种方法可以用于处理高维数据?A. 主成分分析B. 因子分析C. 偏最小二乘回归D. 以上都是17. 在多元统计分析中,核方法的主要思想是:A. 将数据映射到高维空间B. 将数据映射到低维空间C. 将数据映射到同维空间D. 将数据映射到随机空间18. 下列哪种方法不属于分类方法?A. 判别分析B. 逻辑回归C. 支持向量机D. 主成分分析19. 在多元统计分析中,支持向量机的主要优点是:A. 处理线性可分问题B. 处理线性不可分问题C. 处理非线性可分问题D. 处理非线性不可分问题20. 下列哪种方法可以用于处理不平衡数据集?A. 过采样B. 欠采样C. 合成少数类过采样技术D. 以上都是21. 在多元统计分析中,随机森林的主要优点是:A. 处理高维数据B. 处理缺失数据C. 处理不平衡数据集D. 以上都是22. 下列哪种方法不属于集成学习方法?A. 随机森林B. 梯度提升机C. 自适应提升D. 主成分分析23. 在多元统计分析中,梯度提升机的主要思想是:A. 逐步构建模型B. 逐步优化模型C. 逐步简化模型D. 逐步复杂化模型24. 下列哪种方法可以用于处理时间序列数据?A. 移动平均法B. 指数平滑法C. 自回归模型D. 以上都是25. 在多元统计分析中,时间序列分析的主要目的是:A. 预测未来值B. 分析历史值C. 分析周期性D. 以上都是26. 下列哪种方法不属于时间序列预测方法?A. 移动平均法B. 指数平滑法C. 自回归模型D. 主成分分析27. 在多元统计分析中,移动平均法的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据D. 处理随机性数据28. 下列哪种方法可以用于处理季节性数据?A. 移动平均法B. 指数平滑法C. 季节性分解D. 以上都是29. 在多元统计分析中,指数平滑法的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据D. 处理随机性数据30. 下列哪种方法可以用于处理周期性数据?A. 移动平均法B. 指数平滑法C. 季节性分解D. 以上都是31. 在多元统计分析中,季节性分解的主要目的是:A. 分析趋势B. 分析季节性C. 分析周期性D. 分析随机性32. 下列哪种方法不属于时间序列分解方法?A. 移动平均法B. 指数平滑法C. 季节性分解D. 主成分分析答案部分(1-32题)1. A2. D3. C4. B5. A6. D7. A8. D9. A10. C11. A12. D13. A14. A15. A16. D17. A18. D19. D20. D21. D22. D23. B24. D25. D26. D27. A28. D29. A30. D31. B32. D以下是后32题:选择题部分(33-64题)33. 在多元统计分析中,自回归模型的主要目的是:A. 预测未来值B. 分析历史值C. 分析周期性D. 以上都是34. 下列哪种方法不属于自回归模型?A. ARIMAB. SARIMAC. VARD. 主成分分析35. 在多元统计分析中,ARIMA模型的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据D. 处理随机性数据36. 下列哪种方法可以用于处理多变量时间序列数据?A. ARIMAB. SARIMAC. VARD. 以上都是37. 在多元统计分析中,VAR模型的主要目的是:A. 分析多变量时间序列数据B. 预测多变量时间序列数据C. 分析多变量时间序列数据的周期性D. 以上都是38. 下列哪种方法不属于时间序列模型?A. ARIMAB. SARIMAC. VARD. 主成分分析39. 在多元统计分析中,SARIMA模型的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据D. 处理随机性数据40. 下列哪种方法可以用于处理非线性时间序列数据?A. ARIMAB. SARIMAC. VARD. 非线性自回归模型41. 在多元统计分析中,非线性自回归模型的主要目的是:A. 预测未来值B. 分析历史值C. 分析周期性D. 以上都是42. 下列哪种方法不属于非线性时间序列模型?A. 非线性自回归模型B. 神经网络模型C. 支持向量机模型D. 主成分分析43. 在多元统计分析中,神经网络模型的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据D. 处理随机性数据44. 下列哪种方法可以用于处理复杂时间序列数据?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 以上都是45. 在多元统计分析中,支持向量机模型的主要目的是:A. 预测未来值B. 分析历史值C. 分析周期性D. 以上都是46. 下列哪种方法不属于复杂时间序列模型?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 主成分分析47. 在多元统计分析中,随机森林模型的主要优点是:A. 处理趋势数据B. 处理季节性数据C. 处理周期性数据48. 下列哪种方法可以用于处理高维时间序列数据?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 以上都是49. 在多元统计分析中,高维时间序列数据的主要特点是:A. 数据量大B. 数据维度高C. 数据复杂度高D. 以上都是50. 下列哪种方法不属于高维时间序列数据处理方法?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 主成分分析51. 在多元统计分析中,主成分分析在高维时间序列数据处理中的主要作用是:A. 数据降维B. 数据分类C. 数据预测D. 数据可视化52. 下列哪种方法可以用于处理高维时间序列数据的缺失值?A. 删除含有缺失数据的样本B. 使用均值填充C. 使用回归模型预测缺失值D. 以上都是53. 在多元统计分析中,高维时间序列数据的缺失值处理的主要目的是:A. 提高数据完整性B. 提高数据准确性C. 提高数据可靠性D. 以上都是54. 下列哪种方法不属于高维时间序列数据的缺失值处理方法?A. 删除含有缺失数据的样本B. 使用均值填充C. 使用回归模型预测缺失值D. 主成分分析55. 在多元统计分析中,高维时间序列数据的可视化主要目的是:B. 提高数据分析性C. 提高数据预测性D. 以上都是56. 下列哪种方法可以用于高维时间序列数据的可视化?A. 散点图B. 热力图C. 平行坐标图D. 以上都是57. 在多元统计分析中,高维时间序列数据的可视化方法的主要优点是:A. 提高数据理解性B. 提高数据分析性C. 提高数据预测性D. 以上都是58. 下列哪种方法不属于高维时间序列数据的可视化方法?A. 散点图B. 热力图C. 平行坐标图D. 主成分分析59. 在多元统计分析中,高维时间序列数据的预测主要目的是:A. 提高数据理解性B. 提高数据分析性C. 提高数据预测性D. 以上都是60. 下列哪种方法可以用于高维时间序列数据的预测?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 以上都是61. 在多元统计分析中,高维时间序列数据的预测方法的主要优点是:A. 提高数据理解性B. 提高数据分析性C. 提高数据预测性D. 以上都是62. 下列哪种方法不属于高维时间序列数据的预测方法?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 主成分分析63. 在多元统计分析中,高维时间序列数据的分类主要目的是:A. 提高数据理解性B. 提高数据分析性C. 提高数据预测性D. 以上都是64. 下列哪种方法可以用于高维时间序列数据的分类?A. 神经网络模型B. 支持向量机模型C. 随机森林模型D. 以上都是答案部分(33-64题)33. D34. D35. A36. D37. D38. D39. B40. D41. D42. D43. D44. D45. D46. D47. D48. D49. D50. D51. A52. D53. D54. D55. D56. D57. D58. D59. C60. D61. C62. D63. D64. D。

22121212121~(,),(,),(,),,1X N X x x x x x x ρμμμμσρ⎛⎫∑==∑=⎪⎝⎭+-1、设其中则Cov(,)=____.10312~(,),1,,10,()()_________i i i i X N i W X X μμμ='∑=--∑、设则=服从。
()1234433,492,3216___________________X x x x R -⎛⎫ ⎪'==-- ⎪⎪-⎝⎭=∑、设随机向量且协方差矩阵则它的相关矩阵4、__________, __________,________________。
215,1,,16(,),(,)15[4()][4()]~___________i p p X i N X A N T X A X μμμμ-=∑∑'=--、设是来自多元正态总体和分别为正态总体的样本均值和样本离差矩阵,则。
12332313116421(,,)~(,),(1,0,2),441,2142X x x x N x x x x x μμ-⎛⎫⎪'=∑=-∑=-- ⎪ ⎪-⎝⎭-⎛⎫+ ⎪⎝⎭、设其中试判断与是否独立?(),123设X=x x x 的相关系数矩阵通过因子分析分解为211X h =的共性方差111X σ=的方差21X g =1公因子f 对的贡献121330.93400.1280.9340.4170.8351100.4170.8940.02700.8940.44730.8350.4470.1032013R ⎛⎫- ⎪⎛⎫⎛⎫⎪-⎛⎫ ⎪ ⎪⎪=-=-+ ⎪ ⎪ ⎪ ⎪⎝⎭ ⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪⎪⎝⎭11262(90,58,16),82.0 4.310714.62108.946460.2,(5)( 115.6924)14.6210 3.17237.14.5X S μ--'=-⎛⎫ ⎪==-- ⎪ ⎪⎝⎭0、对某地区农村的名周岁男婴的身高、胸围、上半臂围进行测量,得相关数据如下,根据以往资料,该地区城市2周岁男婴的这三个指标的均值现欲在多元正态性的假定下检验该地区农村男婴是否与城市男婴有相同的均值。

多元统计分析练习题一、主成分练习题填空题1.主成分分析是通过适当的变量替换,使新变量成为原变量的___________,并寻求_________的一种方法。
2.主成分分析的基本思想是______________。
3.主成分的协方差矩阵为_________矩阵。
4.主成分表达式的系数向量是_______________的特征向量。
5.原始变量协方差矩阵的特征根的统计含义是________________。
6.原始数据经过标准化处理,转化为均值为____,方差为____的标准值,且其________矩阵与相关系数矩阵相等。
7.因子载荷量的统计含义是_____________________________。
8.样本主成分的总方差等于_____________。
9.变量按相关程度为,在__________程度下,主成分分析的效果较好。
10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为________________。
11.SPSS 中主成分分析采用______________命令过程。
计算题1.设三个变量(x1,x2,x3)的样本协方差矩阵为:2121002222222<<−⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡r s rs r s s r s r s s 试求主成分及每个主成分的方差贡献率。
2.在一项研究中,测量了376只鸡的骨骼,并利用相关系数矩阵进行主成分分析,见下表: Y1 Y2 Y3 Y4 Y5 Y6 头长x1 头宽x2 肱骨x3 尺骨x4 股骨x5 胫骨x6 0.35 0.33 0.44 0.44 0.43 0.44 0.53 0.70 0.19 0.25 0.28 0.22 0.76 -0.64 -0.05 -0.02 -0.06 -0.05 -0.05 0.00 0.53 0.48 0.51 0.48 -0.04 0.00 0.19 0.15 0.67 0.70 0.00 0.04 0.59 0.63 0.48 0.15 特征值4.570.710.410.170.080.06解释6个主成分的实际意义。

实用多元统计分析相关习题练习题一、填空题1.人们通过各种实践,发现变量之间的相互关系可以分成(相关)和(不相关)两种类型。
多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。
2.总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。
3.回归方程显著性检验时通常采用的统计量是(S R/p)/[S E/(n-p-1)]。
4.偏相关系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的)的相关系数。
5.Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。
6.主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求(降维)的一种方法。
7.主成分分析的基本思想是(设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来替代原来的指标)。
8.主成分表达式的系数向量是(相关系数矩阵)的特征向量。
9.样本主成分的总方差等于(1)。
10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。
主成分的协方差矩阵为(对称)矩阵。
主成分表达式的系数向量是(相关矩阵特征值)的特征向量。
11.SPSS中主成分分析采用(analyze—data reduction—facyor)命令过程。
12.因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部分为(特殊因子)。
13.变量共同度是指因子载荷矩阵中(第i行元素的平方和)。
14.公共因子方差与特殊因子方差之和为(1)。
15.聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏程度)进行科学的分类。
16.Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。
17.Q型聚类统计量是(距离),而R型聚类统计量通常采用(相关系数)。

《多元统计分析》试卷1、若 且相互独立,则样本均值向量服从的分布为。
2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。
4、型聚类是指对_样品_进行聚类,型聚类是指对_指标(变量)_进行聚类。
5、设样品,总体,对样品进行分类常用的距离有:明氏距离,马氏距离,兰氏距离。
6、因子分析中因子载荷系数的统计意义是_第i 个变量与第j 个公因子的相关系数。
7、一元回归的数学模型是:,多元回归的数学模型是:。
8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
1、设三维随机向量,其中,问与是否独立?和是否独立?为什么?解: 因为,所以与不独立。
把协差矩阵写成分块矩阵,的协差矩阵为因为,而,所以和是不相关的,而正态分布不相关与相互独立是等价的,所以和是独立的.2、设抽了五个样品,每个样品只测了一个指标,它们分别是1 ,2 ,4。
5 ,6 ,8。
若样本间采用明氏距离,试用最长距离法对其进行分类,要求给出聚类图. 解:样品与样品之间的明氏距离为:样品最短距离是1,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵 类与类的最短距离是1。
5,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵类与类的最短距离是3。
5,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵分类与聚类图(略)(请你们自己做)3、设变量的相关阵为的特征值和单位化特征向量分别为一、填空题(每空2分,共40分)二、计算题(每小题10分,共40分)(1) 取公共因子个数为2,求因子载荷阵。
(2) 计算变量共同度及公共因子的方差贡献,并说明其统计意义。
解:因子载荷阵变量共同度: ===公共因子的方差贡献:统计意义(省略)(学生自己做)4、设三元总体的协方差阵为,从出发,求总体主成分,并求前两个主成分的累积贡献率。


多元统计分析多元统计分析习题集(⼀)⼀、填空题1.若()(,),(1,2,,)p X N n αµα∑= 且相互独⽴,则样本均值向量X 服从的分布是____________________。
2.变量的类型按尺度划分为___________、____________、_____________。
3.判别分析是判别样品_____________的⼀种⽅法,常⽤的判别⽅法有_____________、_____________、_____________、_____________。
4.Q 型聚类是指对_____________进⾏聚类,R 型聚类指对_____________进⾏聚类。
5.设样品12(,,,),(1,2,,)i i i ip X X X X i n '== ,总体(,)p X N µ∑ ,对样品进⾏分类常⽤的距离有____________________、____________________、____________________。
6.因⼦分析中因⼦载荷系数ij a 的统计意义是_________________________________。
7.主成分分析中的因⼦负荷ij a 的统计意义是________________________________。
8.对应分析是将__________________和__________________结合起来进⾏的统计分析⽅法。
9.典型相关分析是研究__________________________的⼀种多元统计分析⽅法。
⼆、计算题 1.设3(,)X N µ∑ ,其中410130002?? ?∑= ? ??,问1X 与2X 是否独⽴?12(,)X X '与3X 是否独⽴?为什么?2.设抽了5个样品,每个样品只测了⼀个指标,它们分别是1,2,4.5,6,8。
若样品间采⽤绝对值距离,试⽤最长距离法对其进⾏分类,要求给出聚类图。
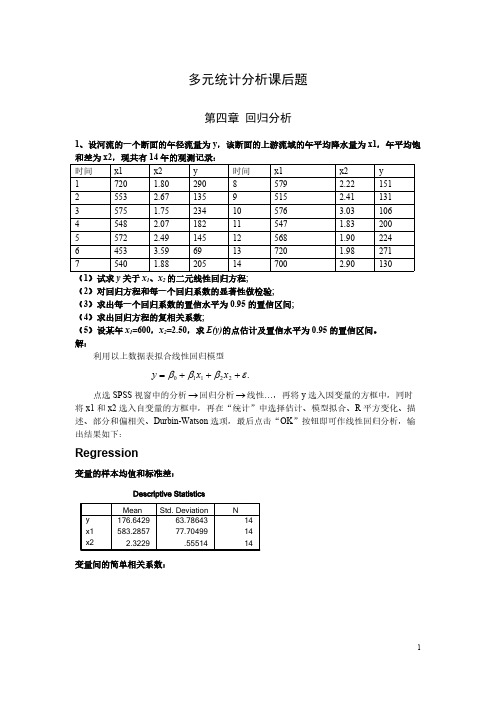
多元统计分析课后题第四章 回归分析1、设河流的一个断面的年径流量为y ,该断面的上游流域的年平均降水量为x1,年平均饱和差为x2,现共有14年的观测记录:时间x1x2y 时间x1x2y17201.8029085792.221512553 2.6713595152.411313575 1.75234105763.031064548 2.07182115471.832005572 2.49145125681.902246453 3.5969137201.982717540 1.88205147002.90130(1)试求y 关于x 1、x 2的二元线性回归方程;(2)对回归方程和每一个回归系数的显著性做检验;(3)求出每一个回归系数的置信水平为0.95的置信区间;(4)求出回归方程的复相关系数;(5)设某年x 1=600,x 2=2.50,求E(y)的点估计及置信水平为0.95的置信区间。
解:利用以上数据表拟合线性回归模型.22110εβββ+++=x x y 点选SPSS 视窗中的分析回归分析线性…,再将y 选入因变量的方框中,同时→→将x1和x2选入自变量的方框中,再在“统计”中选择估计、模型拟合、R 平方变化、描述、部分和偏相关、Durbin-Watson 选项,最后点击“OK ”按钮即可作线性回归分析,输出结果如下:Regression变量的样本均值和标准差:变量间的简单相关系数:这里给出了回归方程的样本决定系数和P值以及DW值:下面的框图是方差分析表,从中可以看出,y关于x1和x2的线性回归方程通过了显著性检验,均方残差为554.963,F统计量值为42.155,P值为0.000,回归方程在0.000的统计意义上是显著的。
上面的框图给出了非标准化和标准化的回归方程,以及回归系数的t 统计量检验结果。
从中我们可以看出,非标准化的回归方程为:(1)21x 647.87292.0875.209-+=x y(2)回归系数、均通过了显著性检验。

1 、设 X ~ N2 ( ,), 其中 X( x1 , x 2 ),( 1 ,212 ),,1则 Cov( x1x 2 , x1x 2 )=____.102、设X i ~N 3 (,), i 1, L,10,则 W =( X i)( X i)i 1服从_________。
4433、设随机向量X x1x2x3, 且协方差矩阵 4 9 2 ,3 2 16则它的相关矩阵R___________________4、设 X= x1x2x3,的相关系数矩阵通过因子分析分解为112330.93400.1280.4171R100.4170.9340.83530.8940.8940.027 0.83500.4472010.4470.10332__________,__________,X1的共性方差 h1X1的方差11公因子 f 1对 X的贡献 g12________________。
5、设 X i , i 1,L ,16 是来自多元正态总体N p (, ), X 和 A分别为正态总体N p ( ,)的样本均值和样本离差矩阵 , 则T 215[4( X)] A 1[4( X)] ~ ___________。
1642、设( x1 , x2 , x3) ~ N3(, ),其中(1,0, 2) ,44 1 ,1X214试判断 x12 x3与x2x3是否独立?x12、对某地区农村的 6 名 2 周岁男婴的身高、胸围、上半臂围进行测量,得相关数据如下 , 根据以往资料 , 该地区城市 2周岁男婴的这三个指标的均值0(90,58,16), 现欲在多元正态性的假定下检验该地区农村男婴是否与城市男婴有相同的均值。
82.0 4.310714.62108.9464其中 X60.2 ,(5 S ) 1( 115.6924)114.6210 3.17237. 376014.58.946437.376035.5936 (0.01,F 0.01 (3, 2)99.2, F 0.01 (3,3)29.5,F0.01 (3, 4)16.7)、设已知有两正态总体G与 G,且12,24,1211,3126219而其先验概率分别为q1q20.5,误判的代价C (2 1)4;e ,C(1 2)e试用判别法确定样本X 3属于哪一个总体?Bayes514、设X( X1 , X2 , X3 , X4 )T,协方差阵1~ N (0, ),0111(1)试从Σ出发求 X 的第一总体主成分;(2)试问当取多大时才能使第一主成分的贡献率达95%以上。

1. 在多元统计分析中,主成分分析的主要目的是什么?A. 减少变量数量B. 增加变量数量C. 提高模型复杂度D. 降低模型复杂度2. 下列哪项不是多元回归分析的假设条件?A. 线性关系B. 正态性C. 独立性D. 等方差性3. 在因子分析中,公因子的数量通常如何确定?A. 主观选择B. 根据特征值大于1的原则C. 随机选择D. 根据样本大小4. 聚类分析中,Ward's方法属于哪一类?A. 层次聚类B. 非层次聚类C. 密度聚类D. 网格聚类5. 在判别分析中,Fisher判别法的主要思想是什么?A. 最大化类间差异B. 最小化类内差异C. 最大化类内差异D. 最小化类间差异6. 多元方差分析(MANOVA)与单因素方差分析(ANOVA)的主要区别是什么?A. 处理单个因变量B. 处理多个因变量C. 处理单个自变量D. 处理多个自变量7. 在结构方程模型(SEM)中,路径分析的主要目的是什么?A. 描述变量间的因果关系B. 描述变量间的相关关系C. 描述变量间的线性关系D. 描述变量间的非线性关系8. 在多维尺度分析(MDS)中,常用的距离度量是什么?A. 欧几里得距离B. 曼哈顿距离C. 切比雪夫距离D. 马氏距离9. 在对应分析中,主要用于分析什么类型的数据?A. 连续数据B. 分类数据C. 时间序列数据D. 混合数据10. 在多元统计分析中,偏最小二乘回归(PLS)主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系11. 在多元统计分析中,典型相关分析(CCA)主要用于分析什么关系?A. 两个变量组之间的关系B. 单个变量组内部的关系C. 多个变量组之间的关系D. 单个变量与多个变量组之间的关系12. 在多元统计分析中,岭回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系13. 在多元统计分析中,LASSO回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 变量选择14. 在多元统计分析中,支持向量机(SVM)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析15. 在多元统计分析中,随机森林主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析16. 在多元统计分析中,神经网络主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析17. 在多元统计分析中,决策树主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析18. 在多元统计分析中,关联规则挖掘主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析19. 在多元统计分析中,时间序列分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 预测问题20. 在多元统计分析中,生存分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 时间至事件的分析21. 在多元统计分析中,贝叶斯网络主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理22. 在多元统计分析中,马尔可夫链蒙特卡罗(MCMC)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理23. 在多元统计分析中,高斯过程回归主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率推理24. 在多元统计分析中,核密度估计主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 概率密度估计25. 在多元统计分析中,EM算法主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 参数估计26. 在多元统计分析中,K均值聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析27. 在多元统计分析中,层次聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析28. 在多元统计分析中,DBSCAN聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析29. 在多元统计分析中,谱聚类主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析30. 在多元统计分析中,自组织映射(SOM)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 数据可视化31. 在多元统计分析中,主成分回归主要用于解决什么问题?A. 多重共线性B. 异方差性C. 自相关D. 非线性关系32. 在多元统计分析中,偏最小二乘判别分析(PLS-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析33. 在多元统计分析中,典型相关分析(CCA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析34. 在多元统计分析中,岭判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析35. 在多元统计分析中,LASSO判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析36. 在多元统计分析中,支持向量机判别分析(SVM-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析37. 在多元统计分析中,随机森林判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析38. 在多元统计分析中,神经网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析39. 在多元统计分析中,决策树判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析40. 在多元统计分析中,关联规则挖掘判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析41. 在多元统计分析中,时间序列判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析42. 在多元统计分析中,生存判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析43. 在多元统计分析中,贝叶斯网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析44. 在多元统计分析中,马尔可夫链蒙特卡罗判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析45. 在多元统计分析中,高斯过程回归判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析46. 在多元统计分析中,核密度估计判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析47. 在多元统计分析中,EM算法判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析48. 在多元统计分析中,K均值聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析49. 在多元统计分析中,层次聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析50. 在多元统计分析中,DBSCAN聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析51. 在多元统计分析中,谱聚类判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析52. 在多元统计分析中,自组织映射判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析53. 在多元统计分析中,主成分回归判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析54. 在多元统计分析中,偏最小二乘判别分析(PLS-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析55. 在多元统计分析中,典型相关分析(CCA)判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析56. 在多元统计分析中,岭判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析57. 在多元统计分析中,LASSO判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析58. 在多元统计分析中,支持向量机判别分析(SVM-DA)主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析59. 在多元统计分析中,随机森林判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析60. 在多元统计分析中,神经网络判别分析主要用于解决什么问题?A. 分类问题B. 回归问题C. 聚类问题D. 关联分析1. A2. C3. B4. A5. A6. B7. A8. A9. B10. A11. A12. A13. D14. A15. A16. A17. A18. D19. D20. D21. D22. D23. B24. D25. D26. C27. C28. C29. C30. D31. A32. A33. A34. A35. A36. A37. A38. A39. A40. A41. A42. A43. A44. A45. A46. A47. A48. A49. A51. A52. A53. A54. A55. A56. A57. A58. A59. A60. A。

多元统计复习题答案一、单项选择题1. 多元统计分析中,用于描述多个变量之间关系的统计方法是()。
A. 相关分析B. 聚类分析C. 因子分析D. 主成分分析答案:C2. 以下哪个不是多元统计分析中常用的降维方法?()A. 主成分分析B. 因子分析C. 聚类分析D. 典型相关分析答案:C3. 在多元统计分析中,用于识别数据集中的异常值或离群点的统计方法是()。
A. 马氏距离B. 箱线图C. 相关系数D. 卡方检验答案:B二、多项选择题1. 多元统计分析中,以下哪些方法可以用来进行变量选择?()A. 逐步回归B. 岭回归C. 偏最小二乘回归D. 主成分分析答案:A|B|C2. 多元统计分析中,以下哪些方法可以用来进行数据的分类?()A. 判别分析B. 聚类分析C. 因子分析D. 典型相关分析答案:A|B三、判断题1. 多元统计分析中的因子分析可以用于变量的降维。
(对)2. 多元统计分析中的主成分分析和因子分析是完全相同的方法。
(错)3. 多元统计分析中的聚类分析可以用于识别数据集中的异常值。
(错)四、简答题1. 简述多元统计分析中主成分分析(PCA)的主要步骤。
答:主成分分析的主要步骤包括:数据标准化、计算协方差矩阵、求解特征值和特征向量、选择主成分、构造主成分得分。
2. 描述多元统计分析中判别分析的应用场景。
答:判别分析在多元统计分析中主要应用于根据已有的分类变量来预测新样本的分类,例如在医学诊断、市场细分、信用评分等领域。
五、计算题1. 给定一组数据,计算其主成分得分。
答:首先需要对数据进行标准化处理,然后计算协方差矩阵,接着求解特征值和特征向量,最后根据特征值的大小选择前几个主成分,并计算对应的得分。
2. 利用判别分析对一组数据进行分类,并给出分类结果。
答:首先需要确定分类的依据,然后计算各类别的判别函数,接着对新样本进行判别分析,最后根据判别得分将样本分类到相应的类别中。

第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。

1.已知n=4,p=3的一个样本数据阵143X =626,X S 833534ρ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦计算,,v,2.已知23514241130010322X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,用最短、最长、中间距离法聚类,并画出聚类树形图3.已知52=22⎡⎤∑⎢⎥⎣⎦,要求: ①求特征根12λλ, ②求特征向量12μμ,③构造主成分12,F F④计算1F 的方差Var(F 1)和2F 的方差Var(F 2)⑤计算()()()()11122122,,,,;;;F X F X F X F X ρρρρ4.设有12,G G 两个总体,从中分别抽取容量为3的样品如下:要求:(1)样本的均值向量()()12,XX 及离差阵12,S S(2)假定()()12==∑∑∑,用12,S S 联合估计∑(3)已知待判样品(27)X T=,分别用距离判别法、Fisher 判别法、Bayes 判别法判定X 的归属。
5.设111=n 个和122=n 个的观测值分别取自两个随机变量1X 和2X 。
假定这两个变量服从二元正态分布,且有相同的协方差阵。
样本均值向量和联合协方差阵为:⎥⎦⎤⎢⎣⎡--=111X ,⎥⎦⎤⎢⎣⎡=122X ,⎥⎦⎤⎢⎣⎡--=∑8.41.11.13.7。
新样品⎥⎦⎤⎢⎣⎡=21X ,要求用Bayes 法和Fisher 进行判别分析。
6.已知2变量协方差阵⎥⎦⎤⎢⎣⎡=∑3224,要求:(1)求∑的特征根及其对应的单位特征向量;(2)组建主成分1F 、2F ;(3)验证j j F Var λ=)(;(4)计算11x F ρ、21x F ρ。
7、试分析某海运学院100名新生的性别与来自的区域有无相关关系。
(20.05(1) 3.84χ=)8、已知4个样品3个数据的数据如下:44068644363X ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦,试求均值向量X 、协方差阵∑、相关阵R 。
9、已知随机向量X=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡321x x x ,具有均值向量826X ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦和协方差阵,⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--=∑411161113。
1.已知n=4,p=3的一个样本数据阵
143X =626,X S 833534ρ
⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥
⎢⎥⎣⎦
计算,,v,
2.已知2
035142
411
300103
2
2X ⎡⎤
⎢⎥⎢⎥⎢⎥=⎢
⎥
⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦
,用最短、最长、中间距离法聚类,并画出聚类树形图
3.已知
5
2=2
2⎡⎤
∑⎢⎥⎣⎦,要求: ①求特征根1
2λλ, ②求特征向量12μμ,
③构造主成分
12
,F F
④计算1F 的方差Var(F 1)和2F 的方差Var(F 2)
⑤计算()()()()111221
22,,,,;;;F X F X F X F X ρρρρ
4.设有12,G G 两个总体,从中分别抽取容量为3的样品如下:
要求:(1)样本的均值向量()
()12
,X
X 及离差阵12,S S
(2)假定()()12==∑∑∑,用12,S S 联合估计∑
(3)已知待判样品(27)
X
T
=,分别用距离判别法、Fisher 判别
法、Bayes 判别法判定X 的归属。
5.设111=n 个和122=n 个的观测值分别取自两个随机变量1X 和
2X 。
假定这两个变量服从二元正态分布,且有相同的协方差阵。
样本均值向量和联合协方差阵为:
⎥⎦⎤
⎢⎣⎡--=111X ,⎥⎦⎤⎢⎣⎡=122X ,⎥⎦⎤⎢⎣⎡--=∑8.41.11.13.7。
新样品⎥⎦
⎤⎢⎣⎡=21X ,
要求用Bayes 法和Fisher 进行判别分析。
6.已知2变量协方差阵⎥⎦
⎤
⎢
⎣⎡=∑3224
,要求:(1)求∑的特征根及其对应的单位特征向量;(2)组建主成分1F 、2F ;(3)验证
j j F Var λ=)(;(4)计算11x F ρ、21x F ρ。
7、试分析某海运学院100名新生的性别与来自的区域有无相关关系。
(2
0.05(1) 3.84χ=)
8、已知4个样品3个数据的数据如下:
4
406
864
436
3X ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦
,试求均值向量X 、协方差阵∑
、相关阵R 。
9、已知随机向量X=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡32
1x x x ,具有均值向量826X ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦
和协方差阵,
⎥⎥⎥⎦
⎤⎢⎢⎢⎣⎡--=∑411161113。
设A=⎥⎦
⎤
⎢⎣⎡131
023,试求: (1)2
1x x ρ (2)E (AX ) (3)
)(AX Cov 10.已知4个样品3个数据的数据如下:
⎥⎥⎥
⎥⎦
⎤⎢⎢⎢
⎢⎣⎡=31
6325
536123
X ,试求均值向量X 、离差阵S 、协方差阵∑、相关阵R 。
11.已知随机向量X=⎥⎥⎥⎦
⎤
⎢⎢⎢⎣⎡321x x x ,具有均值向量
⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=314X 和协方差阵 ⎥⎥⎥⎦
⎤⎢⎢⎢⎣⎡--=∑411152123。
设A=⎥⎦⎤
⎢⎣⎡131
024,试求:
(1)E (AX ) (2)2
1x x ρ (3))(AX Cov
12.已知初始距离阵
44010()11205340ij D d ⨯⎡⎤⎢⎥
⎢
⎥==⎢⎥⎢⎥⎣⎦
,要求用最长距离法和最短距离法进行聚类,并画出聚类树形图。
12.已知初始距离阵
⎥⎥⎥⎥⎥⎥⎦
⎤
⎢⎢⎢⎢⎢⎢⎣⎡==⨯0821011
09560
74090)(5
5ij d D ,要求用最短距
离法和最长距离法进行聚类,并画出聚类树形图。
13.设112n =个和213n =个的观测值分别取自两个随机变量1X 和2X 。
假定这两个变量服从二元正态分布,且有相同的协方差阵。
样本均值向量和联合协方差阵为:
123X ⎡⎤=⎢⎥⎣⎦,234X ⎡⎤=⎢⎥⎣⎦,7114⎡⎤∑=⎢⎥⎣⎦。
新样品⎥⎦
⎤⎢⎣⎡=21X ,要求:
(1)构造Fisher 判别函数,判别新样品的归属; (2)用Bayes 法进行判别分析。
14.已知2变量协方差阵
⎥⎦
⎤
⎢⎣⎡=∑32
24
,要求: (1)求∑的特征根及其对应的单位特征向量;
(2)组建主成分1F 、2F ; (3)验证j j F Var λ=)(; (4)计算1
1x F ρ、2
1x F ρ。
15.为了研究吸烟是否与患肺癌有关,对126位肺癌患者及86位非
肺癌患者进行了调查,得如下表:
试利用2χ统计量检验吸烟与患肺癌是否存在相关关系。
[2
05
.0χ(1)=3.84]
16.相关阵R 的特征根和特征向量分别为:
96.11=λ,[]T 507
.0593.0625.01=μ
68.02=λ, []T 843
.0491
.0219
.02--=μ
36.03=λ,
[]T 177
.0638
.0749
.03--=μ
要求:(1)构建因子载荷阵A ;
(2)分别写出指标变量1X 与1F 、2X 与2F 、3X 与2F 的相关系数; (3)计算指标变量共同度21h 、22h 、 23h 。