
(1)建立spss数据文件,如下图所示:
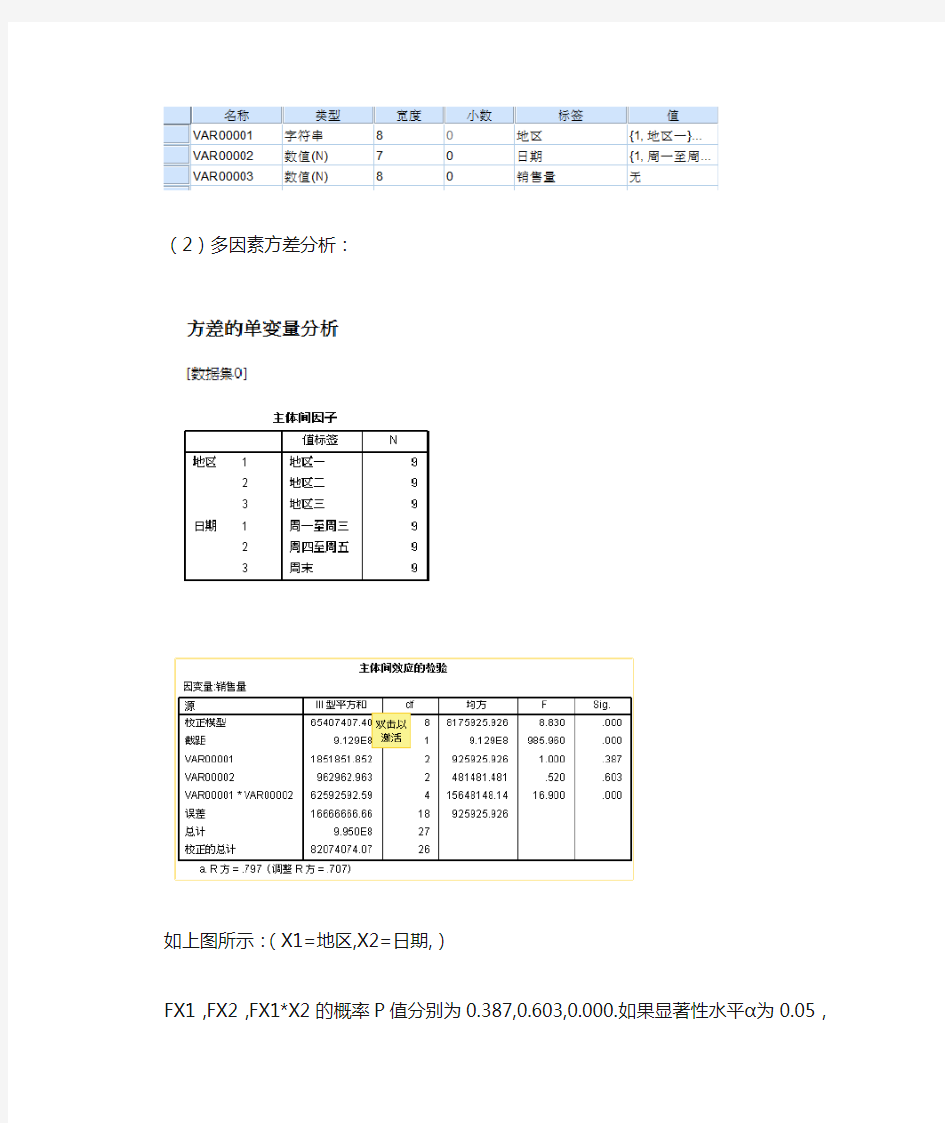
(2)多因素方差分析:
如上图所示:(X1=地区,X2=日期,)
FX1,FX2,FX1*X2的概率P值分别为0.387,0.603,0.000.如果显著性水平α为0.05,由于FX1<0.05,小于显著性水平,所以拒绝原假设,可以认为不同地区的销售量存在显著性差异。FX2>0.05,不应拒绝原假设,可以认为日期没有对销售量产生显著作用。
(3)FX1*X2=0,小于0.05,拒绝原假设。各自不同地区、日期交互没有显著性影响。
非饱和模型
复习参考题 一、选择题 1.应用统计学原理进行试验设计,其最终目的是(C) A.选择该病暴露因素 B.使论文具有可续性 C.达到齐同对比、均衡化抽样 D.观察指标稳定可靠 E.使研究内容达到先进性、创新性 2.专业设计主要包括(E) A.选择观察对象 B.需组织多少观察病例 C.观察结果可重复性 D.减少或排除抽样误差 E.确立研究目的和建立假设 3.实验设计的主要目的(ABCDE) A.解决试验结果可重复性 B.提高试验效率 C.保证样本代表性 D.样本间可比性 E.观察结果精确性 4.临床研究设计中的主要困难是(ABDE) A.不能在人身上复制疾病模板 B.样本一致性较差 C.只能应用整体水平进行研究 D.观察条件不易控制 E.观察结果离散度大 5.专业设计中建立假设是(BDE) A.对某一问题的学说设定 B.一种科学预见 C.主观推测 D.对提出问题的释疑 E.推理指导下安排试验与调查 6.实验设计中的处理因素是指(D) A.随机化 B.盲法 C.观察对象代表性 D.分组因素及其水平 E.指标的客观性、稳定性 7.实验设计中必须贯彻的基本原则是(ADE) A.随机化与盲法 B.观察对象金标准 C.制定明确的纳入与排除标准 D.设立对照组
E.达到有统计意义的最低样本含量 8.随机误差(抽样误差)的数据特点是(ADE) A.个体反应差异 B.数据差异具有方向性 C.数据常不呈正态分布 D.数据趋向于接近均值水平 E.可通过统计学处理缩小或排除 9.产生偏倚的原因和控制是(CE) A.数据无规律,随机变化 B.个体反应差异所产生变化 C.不能用统计方法控制 D.数据服从正态分布 E.实验设计不周所产生的数据变化 10.选择性偏倚产生的主要原因是(BCDE) A.个体反应差异 B.测量上具有主观倾向性 C.选择病例未应用金标准 D.分组时有关特征构成的差异显著 E.抽样及分组时未采用随机盲法 11.样本代表性与下列哪些因素有关(ABCDE) A.诊断金标准 B.贯彻随机化原则 C.是否排除了偏倚产生 D.确定达到统计要求的最低样本含量 E.样本抽取与分组要有选择 12.数据资料能进行统计学处理的必须是哪一类资料(AE) A.抽样误差产生数据 B.诊断性偏倚产生数据 C.分组偏倚产生数据 D.入院率偏倚产生数据 E.具有组间可比性、随机盲法分组产生的数据 13.求样本大小设定的统计学范围是(BCE) A.设定总体标准差 B.设定检验水准 C.设定检验效能 D.设定样本均数与总体均数差值 E.设定把握度 14.那些实验设计应用正交设计(DE) A.单个处理因素、两个样本均数比较 B.单个处理因素、两个样含量不等的均数比较 C.两个处理因素、且每个因素又有两个水平的实验设计
《统计分析软件》试(题)卷 班级xxx班xxx 学号xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel 数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。
华中师范大学网络教育学院 《SPSS统计软件》练习题库及答案(本科) 一、选择题(选择类) (A)1、在数据中插入变量的操作要用到的菜单是: A Insert Variable; B Insert Case; C Go to Case; D Weight Cases (C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是: A Sort Cases; B Select Cases; C Compute; D Categorize Variables — (C)3、Transpose菜单的功能是: A 对数据进行分类汇总; B 对数据进行加权处理; C 对数据进行行列转置; D 按某变量分割数据 (A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=,说明: A. 按照显著性水平,拒绝H0,说明三种城市的平均身高有差别; B. 三种城市身高没有差别的可能性是; C. 三种城市身高有差别的可能性是; 、 D. 说明城市不是身高的一个影响因素 (B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异; B 服用某种药物前后病情的改变情况; C 服用药物和没有服用药物的病人身体状况的差异; D性别和年龄对雇员薪水的影响 二、填空题(填空类) 6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。 7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。 % 8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。 三、名词解释(问答类) 9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。 10、Chi-Square test:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。 四、简答题(问答类) 11、用SPSS对数据进行分析的基本流程是什么 答:(1)、将数据输入SPSS,并保存; { (2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法; (3)、按题目要求进行统计分析; (4)、保存和导出分析结果。 12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么 答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。 13、简述SPSS打开其它格式数据的几种方法 答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮; (2)、使用数据库查询打开:选择菜单File==>Open Database==>New Query,根据向导打开数据; (3)、使用文本向导读入文本文件:选择菜单File==>Read Text Data ) 14、指定数据按某个变量进行排序需要用到哪个菜单
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
SPSS统计练习题及答案 一、选择题(选择类) (A)1、在数据中插入变量的操作要用到的菜单是: A Insert Variable; B Insert Case; C Go to Case; D Weight Cases (C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是: A Sort Cases; B Select Cases; C Compute; D Categorize Variables (C)3、Transpose菜单的功能是: A 对数据进行分类汇总; B 对数据进行加权处理; C 对数据进行行列转置; D 按某变量分割数据 (A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明: A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别; B. 三种城市身高没有差别的可能性是0.043; C. 三种城市身高有差别的可能性是0.043; D. 说明城市不是身高的一个影响因素 (B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异; B 服用某种药物前后病情的改变情况; C 服用药物和没有服用药物的病人身体状况的差异; D性别和年龄对雇员薪水的影响 二、填空题(填空类) 6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。 7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。 8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。 三、名词解释(问答类) 9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。 10、Chi-Square test:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。 四、简答题(问答类) 11、用SPSS对数据进行分析的基本流程是什么? 答:(1)、将数据输入SPSS,并保存; (2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法; (3)、按题目要求进行统计分析; (4)、保存和导出分析结果。 12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么? 答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。 13、简述SPSS打开其它格式数据的几种方法? 答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮; (2)、使用数据库查询打开:选择菜单File==>Open Database==>New Query,根据向导打开数据; (3)、使用文本向导读入文本文件:选择菜单File==>Read Text Data 14、指定数据按某个变量进行排序需要用到哪个菜单?
SPSS统计分析案例 一、我国城镇居民现状 近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。 二、我国居民消费结构的横向分析 第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。随着收入的增加,衣着支出比重呈现先上升后下降的走势。事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。可以看出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。 三、我国居民消费结构的纵向分析 进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费
《统计分析与SPSS的应用(第五版)》(薛薇) 课后练习答案 第7章SPSS的非参数检验 1、 满意程度年龄段 青年中年老年 很不满意126 297 156 不满意306 498 349 满意88 61 75 很满意27 17 44 请选择恰当的非参数检验方法,以恰当形式组织上述数据,分析不同年龄段人群对该商品满意程度的分布状况是否一致。 卡方检验 步骤:(1)数据→加权个案→对“人数”加权→确定 (2)分析→描述统计→交叉表格→行:满意度;列:年龄→Statistics→如图选择→确定
满意程度 * 年龄交叉表 计数 年龄 总计 青年中年老年 满意程度很不满意126 297 156 579 不满意306 498 349 1153 满意88 61 75 224 很满意27 17 44 88 总计547 873 624 2044 卡方检验 值自由度渐近显著性(双 向) 皮尔逊卡方66.990a 6 .000 似然比(L) 68.150 6 .000 线性关联.008 1 .930 McNemar-Bowker 检验. . .b 有效个案数2044 a. 0 个单元格 (0.0%) 具有的预期计数少于 5。最小预期计数为 23.55。 b. 仅为 PxP 表格计算(其中 P 必须大于 1)。 因概率P值小于显著性水平(0.05),拒绝原假设,不同年龄度对该商品满意程度不一致。 2、利用第2章第7题数据,选择恰当的非参数检验方法,分析本次存款金额的总体分布与正态分布是否存在显著差异。
分析→非参数检验→旧对话框→1-样本-K—S…→选择相关项:本次存款金额[A5] →确定 结果如下: 单样本 Kolmogorov-Smirnov 检验 本次存款金额 数字282 正态参数a,b平均值4738.09 标准偏差10945.569 最极端差分绝对.333 正.292 负-.333 检验统计.333 渐近显著性(双尾).000c a. 检验分布是正态分布。 b. 根据数据计算。 c. Lilliefors 显著性校正。 因概率P值小于显著性水平(0.05),拒绝原假设,与正态分布存在显著差异。 2、为对某条工业生产线的工作稳定性进行监测,测量了该生产线连续加工的20个成品的 直径(单位:英寸),数据如下: 12.27,9.92,10.81,11.79,11.87,10.90,11.22,10.80,10.33,9.30 9.81,8.85,9.32,8.67,9.32,9.53,9.58,8.94,7.89,10.77 选择恰当的非参数检验方法,分析成品尺寸变化是由随机因素造成的,还是由生产线工作不稳定导致的。
实验三SPSS基本统计分析 一.实验目的和要求 1.掌握频数分析; 2.掌握计算基本描述统计量; 3.掌握交叉分组下的频数分析和各种相关性检验; 4.掌握多选项分析; 5.掌握比率分析。 二.实验的基本方法和内容 1. 频数分析 操作步骤:参阅教材第63、64、65页。 2. 基本描述统计量 操作步骤:参阅教材第68、69、70、71页。 3. 交叉分组下的频数分析 操作步骤:参阅教材第73、74、75、76、77、78、79、80、81、82、83、84、85页。 4. 多选项分析 操作步骤:参阅教材第85、86、87、88、89、90页。 5. 比率分析 操作步骤:参阅教材第91、92页。 6. 实验内容: (一)验证性实验 (1)教材第65页“商品房购买意向的调查数据分析” (2)教材第71“商品房购买意向的调查数据分析” (3)教材第79“商品房购买意向的调查数据分析” (4)教材第90“商品房购买意向的调查数据分析” (5)教材第92“保险业务的保费收入占全部业务保费收入的比例情况” (二)实践性实验 (1)对“文科成绩”的数据文件作如下统计整理: 1.利用频数分析功能,分别对“文科成绩7”中“及格次数”变量和“文科成绩9”中的“value
range ”变量,要求绘制频数分布表和频数分布图,其中频数分布表中的内容按变量值的升序输出,频数分布图前者采用饼状图,后者采用带有分布曲线的直方图,二者均输出百分比数据。最后将输出结果保存为“文科成绩7-1”和“文科成绩9-1”。 2. 对“文科成绩5.1”的spss 文件,利用描述统计功能,统计第一、第二及第三次考试成 绩的最大值,最小值,区间范围,平均值,标准差,方差,峰度,偏度等统计量的数值, 要求三个变量的输出内容按均值升值的顺序排列。最后将输出结果保存为“文科成绩5.1-1”。并配文字对数据做出以适当的分析。 3. 如何在同一个输出结果中同时输出不同学院的“第三次考试成绩”的各种基本 描述统计量,并对不同学院的学生考试成绩情况进行深入比较。 (2)调查100名健康大学生的血清总蛋白含量(g%)如下表: 1.利用描述统计功能从集中趋势、分散程度、偏斜程度、有无异常值等方面分析血清蛋白含量这个变量的分布状况。 2.原始数据进行算术处理:已知最小值为6.430,最大值为8.430,全距为2.000,故可要求分成5组,试作分组后的频数分析,并给出带有正态曲线的直方图。 7.43 7.88 6.88 7.80 7.04 8.05 6.97 7.12 7.35 8.05 7.95 7.56 7.50 7.88 7.20 7.20 7.20 7.43 7.12 7.20 7.50 7.35 7.88 7.43 7.58 6.50 7.43 7.12 6.97 6.80 7.35 7.50 7.20 6.43 7.58 8.03 6.97 7.43 7.35 7.35 7.58 7.58 6.88 7.65 7.04 7.12 8.12 7.50 7.04 6.80 7.04 7.20 7.65 7.43 7.65 7.76 6.73 7.20 7.50 7.43 7.35 7.95 7.35 7.47 6.50 7.65 8.16 7.54 7.27 7.27 6.72 7.65 7.27 7.04 7.72 6.88 6.73 6.73 6.73 7.27 7.58 7.35 7.50 7.27 7.35 7.35 7.27 8.16 7.03 7.43 7.35 7.95 7.04 7.65 7.27 7.72 8.43 7.50 7.65 7.04 (3)对某城市家庭的社会经济调查中,美国某调查公司想确定家庭的家庭拥有量与汽车拥有量是否独立。该公司对10000户家庭组成的简单随机样本进行调查,获得如下资料。 现问: 1汽车用有量与量与电话拥有量是否独立?(01.0=α) 2请根据列联表特征,选择卡方统计量以外的检验方法分析行列变量之间的关联强度和关联方向。
满意程度青年中年老年合计比率 很不满意126 297 156 579 0.283268 不满意306 498 349 1153 0.56409 满意88 61 75 224 0.109589 很满意27 17 44 88 0.043053 合计547 873 624 2044 1 要分析不同年龄段人群对该商品满意程度的分布状况是否一致? 在全部2044个样本中,对该商品满意程度的分布状况:很不满意的个案有579个,占总数的28.3268%;不满意的个案有1153个,占总数的56.409%;满意的个案有224个,占总数的10.96%;很满意的个案有88个,占总数的4.305%。 从逻辑上讲,如果各种不同年龄段人群对该商品满意程度的分布状况是一致的话,那么,不论青年、中年、老年不同年龄段人群对该商品满意程度的分布都应是很不满意占 28.3268%;不满意占56.409%;满意的占10.96%;很满意的占4.305%。 一、原假设Ho:青年人群对该商品满意程度的分布是很不满意占28.3268%;不满意占56.409%;满意的占10.96%;很满意的占4.305%。 如果显著性水平 =0.05,由于概率P值小于0.05,故拒绝原假设Ho。 二、原假设Ho:中年人群对该商品满意程度的分布是很不满意占28.3268%;不满意占56.409%;满意的占10.96%;很满意的占4.305%。
如果显著性水平α=0.05,由于概率P值小于0.05,故拒绝原假设Ho。 三、原假设Ho:老年人群对该商品满意程度的分布是很不满意占28.3268%;不满意占56.409%;满意的占10.96%;很满意的占4.305%。 如果显著性水平α=0.05,由于概率P值小于0.05,故拒绝原假设Ho。 不同年龄段人群对该商品满意程度的分布状况是不一致
应用练习题spss社会统计学与 2011—2012学年第二学期 《社会统计学与SPSS应用》练习题 一、单项选择题 1.只能把研究对象分类,即只能决定研究对象是同类或是不同类的,具有=与≠的数学属性,例如:性别,民族等变量,该类变量是(A) A.定类变量 B.定序变量 C.定距变量 D.定比变量 2.根据上题内容,在操作SPSS软件时,在Measure选项中选择正确的是(B)A.
B. C.
D. 左50%3.针对出生婴儿性别状况的多年调查发现,新生婴儿男女性别比一直在右摆动,但是对于某个家庭而言,是生男孩还是生女孩却具有偶然性。这说明新生婴儿性别状况属于(D)。随机现象 D. A.非统计现象 B.统计现象 C.非随机现象左新生婴儿男女性别比一直在针对出生婴儿性别状况的多年调查发现,50%4.右摆动,但是对于某个家庭而言,是生男孩还是生女孩却具有偶然性。这体现)。新生婴儿性别状况具有(D必然性 D.随机性 A.确定性 B.因果
性 C..为调查不同年龄段群体对某商品的偏好程度,把年龄划分为:婴幼儿、青少5 年、成年、中年、老年,那么,年龄划分违背了变量取值的原则。(B)差异D.整体C.互斥B.完备A. C)6.下列哪类变量能用折线图表示其分布状况?(虚拟变量定类变量 B.定序变量 C.定距变量 D.A. 。7.下列某变量取值状况的累积图,其中正确的表现形式是(B) .B A. .CD. 2相同,图1较之图2的密度曲线向左8.下两图是正态分布密度曲线,两图的σ移了一些,这说明(C)。
图图≥ D.μμ< C.μμ =μB.μμ>A.μ22112 112 2 1 )C(如下所示首先应该操作步骤的是对于多选项分析而言,软件中,SPSS 在.9. A. B.Freque
§1.2 数据的编辑与整理 当录入数据之后,就可以对原始数据进行整理和分析,关于数据的整理和分析都是在数据窗口完成的。下面将介绍SPSS统计分析软件在数据窗口的主要操作方式和菜单相应的功能。 §1.2.1 数据窗口菜单栏功能操作 数据编辑窗口的主菜单如图1.4所示,主菜单中的具体功能包括: 图1.4 SPSS主菜单 1.File:文件操作。 2.Edit:文件编辑。 3.View:视图编辑。 4.Data:数据操作。 5.Transform:数据转换。 6.Analyze:统计分析方法。 7.Graphs:图形编辑。 8.Utilities:实用程序。 9.Windows:窗口控制。 10.Help:帮助。 在统计分析过程中常用的功能主要集中在数据操作、数据转换、数据分析、统计图形的建立与编辑等操作。 §1.2.2 Date数据功能 数据编辑窗口的Data菜单为用户创建和定义数据提供了方便的功能,如图1.5
所示。这个菜单是SPSS 统计软件数据整理的特有功能菜单。它的功能包括:对变量、观测量的编辑处理;对变量数据的变换;对观察量数据整理。 这些功能为各种统计分析要求提供极其灵活了数据整理功能,用户可以根据不同统计分析对数据的要求对数据进行整理。 一、定义和编辑变量、观测量的命令 Define Variable Properties 用于定义变量属性; Copy Data Properties 由外部文件和工作文件拷贝数据变量和属性; Define Dates 定义或编辑日期变量格式; Insert Variable 在数据编辑窗口插入一个变量; Insert Case 在数据编辑窗口插入一个观测量; Goto Case 光标跳转到某一指定观测量。 二、变量数据变换的命令 Sort Cases 对观测量进行排序; Transpose 对观测量进行转置; Restructure 对现有的观测量进行重新构造,形成新格式的数据文件; Merge File 把外部文件数据合并到工作文件中; Aggregate 对数据进行分类或不分类汇总,产生新文件或代替工作文件。 Identify Duplicate Cases 标识重复观测量; Orthogonal Design 进行正交设计。 三、观察量数据整理的命令 图1.5 Data 菜单项示意图
第2章习题 2、1 指出下列哪些是不合法的变量名?为什么? a、Educl2yr b、&ab345 c、fund_$ d、my_ e、With-1 f、Student's g、My age h、论文数量i、grade02 2、2 为下列变量指定其类型、测度水平,并为适合定义值标签的变量定义相应的值标签 a、公交公司年载客量h、每天上网的小时数 c、某市的行政区划 d、某地每日的平均气温 e、对待电视节目中武打片的态度 f、10~11时内到汽车站候车人数 g、血液中白细胞数量h、库存物资种类 l、某市日啤酒消耗量i、运动会比赛项目 2、3 搜集数据,建立一个数据文件记录你所在班级学生下列情况:学号、姓名、年龄、籍贯、民族、家庭电话号码、出生年月日、评定成绩等级(优、良、中、可、差)等,给出正确的变量名、变量类型、标签及值标签、测度水平。 2、4 试对一个数据文件的部分变量和全部变量作转置练习,指出: (1)在转置后的文件中,系统产生的新变量有何特征? (2)文件转置后原来文件中的变量的哪些信息将会丢失? 2、5 下面的表,分别为某企业1991年~1995年5年中各季度计划完成和实际完成的产量 划产量和实际完成的产量、平均产量。 2、6 某地区农科所为了研究该地区种植的两个小麦品种“中麦9号”、“豫展1号”产量的差异,从该地区的两个村庄各选5块田地,分别种植两个品种小麦,使用相同的田间管 g)进行分类汇总,试定义有关变量,并建立数据文件,完成分类汇总工作。
(1)调用Sort Cases命令分别对年产值、职工人数和年工资总额进行排序。许多SPSS文件中都定义一个表示观测量序号的id变量,按照自己的体会指出这个id变量的作用。 (2)调用Aggregate命令分别按部门和所有制类型作分类汇总。 (3)首先调用Sort Cases命令分别按部门:按所有制类型;按部门和所有制类型进行排序。再执行Analyze →Descriptives Statistics →Descriptives,对年产值、职工人数和年工资总额进行描述。 (4)首先调用Split File命令分别按部门和所有制类型将文件分组,再重复(3)的操作,比较二者的差异。 2、8 针对一个数据文件(如对习题2、6建立的数据文件)作选择观测量练习,并回答下列问题: (1)选择随机抽样方法,抽取约30%的观测量作为样本,将此执行两次,所得到的样本是否相同? (2)将随机选择的部分观测量能否作为样本加以保存?下一次打开这个文件要使用上次选择的随机样本作统计分析,应执行何种操作? 2、9 下表列出3个民族的血型分布数据,为了统计各个民族和各种血型的人数,选择合适的结构将此组输入到SPSS数据窗口建立数据文件。(提示:定义人数为权变量)
SPSS 专业技术词汇、短语的中英文对照索引% of cases 各类别所占百分比 1-tailed单尾的 1Independent Samples 两个独立样本的检验 2 Related Samples 两个相关样本检验 2-tailed双尾的 3-D (=dimensional) 三维-->三维散点图 A Above 高于 Absolute 绝对的-->绝对值 Add 加,添加 Add Cases 合并个案 Add cases from...从……加个案 Add Variables 合并变量 Add variables from... 从……加变量 Adj.(=adjusted)standardized 调整后的标准化残差 Aggregate 汇总-->分类汇总 Aggregate Data 对数据进行分类汇总 Aggregate Function 汇总函数 Aggregate Variable需要分类汇总的变量 Agreement协议 Align 对齐-->对齐方式 Alignment 对齐-->对齐方式 All 全部,所有的 All cases所有个案 All categories equal 所有类别相等 All other values所有其他值 All requested variables entered 所要求变量全部引入 Alphabetic 按字母顺序的-->按字母顺序列表 Alternative 另外的,备选的 Analysis by groups is off 分组分析未开启 Analyze 分析-->统计分析 Analyze all cases, do not create groups 分析全部个案,不建立分组 Annotation 注释 ANOVA Table ANOVA表 ANOVA table and eta (对分组变量)进行单因素方差分析并计算其η值 Apply 应用 Apply Data Dictionary 应用数据字典 Apply Dictionary 应用数据字典 Approximately 大约 Approximately X% of all cases从所有个案中随机选择约X%的个案
SPSS复习题 一、简答题: 1.SPSS的运行方式有几种分别是什么各自的特点是什么 答:SPSS的运行方式有三种,分别是完全窗口菜单运行方式、程序运行方式、混合运行方式。完全窗口菜单运行方式的特点:所有分析操作过程都是通过菜单和按钮及对话框方式进行的.是经常使用的一种运行方式,适用于一般分析和SPSS的初学者。程序运行方式的特点:手工编写SPSS命令程序;一次性提交计算机运行;适用于大规模的分析工作和熟练的SPSS 程序员。混合运行方式的特点:在使用菜单的同时编辑SPSS程序,是完全窗口菜单方式和程序运行方式的综合。 中数据视图所对应的表格与一般的电子处理软件有什么区别 答:与一般电子表格处理软件相比,SPSS的“Data View”窗口还有以下一些特性: (1)一个列对应一个变量,即每一列代表一个变量(Variable)或一个被观测量的特征;(2)行是观测,即每一行代表一个个体、一个观测、一个样品,在SPSS中称为事件(Case);(3)单元包含值,即每个单元包括一个观测中的单个变量值; (4)数据文件是一张长方形的二维表。 3.SPSS有哪两个主要窗口它们的功能和特点各是什么 答:数据编辑窗口,功能:定义SPSS数据的结构、数据文件的录入、编辑、管理等基本操作的窗口;特点:SPSS运行过程中自动打开;SPSS中各统计分析功能都是针对该窗口中的数据进行的;窗口中的数据文件以.sav存于磁盘上;两个视图:数据视图和变量视图。 输出窗口,功能:SPSS统计分析报表及图形的输出的窗口;特点:在进行第一次分析时自动打开,也可手工打开;输出窗口可以关闭,窗口内容以.spv存于磁盘上;两个视图:目录视图和内容视图。 4.SPSS的数据加工和管理功能主要集中在哪些菜单中统计绘图和分析功能主要集中在哪些菜单中 答案:SPSS的数据加工和管理功能主要集中在编辑菜单、数据菜单、转换菜单。统计绘图和分析功能主要集中在统计绘图和分析功能主要集中在分析菜单和图形菜单。 5.利用SPSS进行数据分析的一般步骤是什么 答案:主要集中在以下4个阶段: (1)SPSS数据的准备阶段 在该阶段应按照SPSS的要求,建立SPSS数据文件。其中包括在数据编辑窗口中定义SPSS
内蒙古师范大学全日制硕士研究生 2008—2009 学年第2学期 SPSS 统计分析基础试题(B 卷) 考试时间:90分钟 考试说明: (1) 在E 盘中建立考生文件夹,要求以考生学号加姓名为文件夹命名。 (2) 登陆ftp:// 219.225.189.8,下载与试卷相关文件放入所建立文件夹 中(B 卷所需下载文件在B 卷文件夹中)。 (3) 启动SPSS ,请使用菜单项Edit →Options ,将Viewer 选项卡中的 Display command in the …复选框选中,保证每一步操作都有相应程序被输出到结果窗口中,我们将以此判断您是否按照要求进行了正确的操作。 (4) 考试结束后将考生文件夹上传ftp:// 219.225.189.8上的相应的文 件夹中,然后将试卷交给监考教师。 一、下面是城市居民生活情况调查问卷, 请根据问卷建立相应的名为WJ .sav 数据文件(将此文件保存到自己的文件夹中),数据的变量名用括号中给出的名称,多选 题中的多个变量名请在给出的变量名后加数字区分,如Q1、Q2、Q3等。完成后将数据文件保存在考生文件夹中,并对输出窗口中的信息进行保存,文件命名为WJ1.SPO ,最后关闭输出文件。
二、某高校对部分考生采取单独出题提前录取的招生 模式,现有20名来自国内不同的省市的考生报考该 校,具体数据见文件compute.sav。该校制定了如下录取规则:文化课成绩由数学、语文、英语和综合4门组成,文化课成绩制定最低录取分数线:350分;个人档案中若有“不良记录”,不予录取(即“不良记录”的编码为1的记录不予录取);对西部考生和少数民族考生,给予加分照顾,少数民族考生加30分,西部考生加20分;对参加过省以上竞赛并取得三等奖以上名次的考生,每项加10分(数据文件中“奖项”为考生取得的省以上竞赛并且是三等奖以上项目的次数)。首先算出每人的“文化课成绩”,然后根据以上规则算出有资格被录取的考生的“录取成绩”(“录取成绩”为文化课成绩和加分总和构成的成绩),按“录取成绩”进行降序排序,并将前5名考生的相应信息写在下列表格当中。
第三章 1、利用习题二第6题数据,采用SPSS数据筛选功能将数据分成两份文件。其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。 第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。 第二份文件:选取数据数据——选择个案——随机个案样本——输入70。 2、利用习题二第6题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。 排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。 3、利用习题二第4题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。 计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。 4、利用习题二第4题的完整数据,计算每个学生课程的平均分以及标准差。同时,计算男生和女生各科成绩的平均分。 方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定 5、利用习题二第6题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。 根据存款金额排序,观察其最大值与最小值,算出组数和组距。转换——重新编码为其他变量——将存款金额作为输出变量——定义输出变量的名称及标签——设定旧值和新值. 6、在习题二第6题数据中,如果认为调查中“今年的收入比去年增加”且“预计未来一两年收入仍会增加”的人是对自己收入比较满意和乐观的人,请利用SPSS的计数和数据筛选功能找到这些人。 转换——对个案的值计数——设定目标变量及标签——将“今年的收入比去年增加”和“预计未来一两年收入仍会增加”两个变量选中——定义值。 7、对习题二第5题数据,选择恰当的加权变量进行加权处理进而还原为原始数据为后续分析做准备。 数据——加权个案——点击加权个案——将人数作为频率变量——确定。 第四章
An Introduction to SPSS Or PASW The two laboratory sessions created for this course introduce students to the use of SPSS software. Section One To Should be completed by all students Section Three Section Four Further statistical analysis for you to try It is expected that students should complete the exercises up to and including Section Three within class time, if this is not achieved students should complete the exercises in their own time. Introduction to SPSS Section One
Introduction Section One introduces the various screens and displays as well as explaining how to input your survey and your data. SPSS is one of the most popular statistical analysis packages in use today and has been around for well over 20 years. The latest version with the w indow?s interface is particularly easy to use. The windows environment also facilitates the import and export of data, for example importing data from a spreadsheet and exporting results to a word document. The University holds a license that allows students to have a copy of SPSS on their own computers. The CD for installing the latest version of SPSS can be borrowed from the Library. Starting SPSS PASW Version 18 is the latest version. It can be found from Start(Bottom left hand corner), Programmes, SPSS Inc, PASW 18. The opening display asks you to select one of a number of options. At the moment click on the Red Cross to close the box. The Opening Display The window displayed is called the Data Editor; this is used for entering, editing and selecting data. The Data Editor has two views: the Variable View and the Data View you can flip from one view to the other by using the tab at the bottom of the page. SPSS has a number of other windows including Output, Help and Tutorial.