多基因病的分子遗传学
- 格式:ppt
- 大小:388.00 KB
- 文档页数:64



多基因病名词解释医学遗传学
多基因病名词解释:
多基因病(Multifactorial Disease):也称复发性疾病,是一类慢性、隐性遗传性疾病,是指由多个遗传因素和外部环境因素相互作用所致,如高血压、糖尿病、冠心病、肥胖等。
在诊断和治疗过程中,医生需要考虑多个因素的作用,以保证治疗的有效性。
多基因病包括了有关细胞信号转导或代谢的遗传失常,通常这类疾病具有复发性、先天性和遗传传递性的特点。
遗传学(Genetics):也称遗传学,是生物学的一门分支学科,是研究遗传物质(DNA)、遗传变化和遗传规律的科学。
它与其它科学相关,如分子生物学、发育生物学、变异学、细胞生物学、工程生物学,以及其它复杂系统和机制的研究。
遗传学研究的目的是确定生命的基本原理,揭示生命的发展历程,预测未来发展趋势,发现和分析遗传变异的本质,以及探讨遗传病的起源和致病机制,以及通过基因治疗等方法治疗遗传病。


分子遗传学与人类疾病研究分子遗传学是研究基因和遗传物质在分子层面上的运作和相互作用的学科。
它不仅涉及基因的遗传机制,更是研究基因和环境之间的相互作用以及基因突变在遗传疾病中的作用。
随着科技的不断发展,分子遗传学在疾病的预防、诊断和治疗方面正发挥着越来越重要的作用。
一、分子遗传学概述分子遗传学是遗传学研究中的重要分支之一,它涉及到DNA的结构和功能,基因表达和基因调控,以及细胞周期和遗传多态性等多个方面的内容。
在人类疾病研究方面,分子遗传学主要应用于遗传疾病的研究,包括单基因遗传疾病以及多基因遗传疾病。
二、单基因遗传疾病研究单基因遗传疾病是由单一基因突变所引起的遗传疾病。
这样的疾病是由一个基因突变所引发的,因此研究起来非常方便。
现如今,对于大部分单基因疾病,已经可以准确地诊断出相关的基因缺陷,并且进行基因诊断,预防和治疗这些疾病。
举个例子,囊性纤维化是一种常见的单基因疾病,它是由CFTR基因突变所引起的,而CFTR基因编码蛋白在身体内的功能是控制细胞膜上的离子通道,调节体内的钠、氯离子平衡和分泌物的形成。
通过对CFTR基因进行研究,可以了解该基因的遗传机制和突变对疾病的影响,进一步为囊性纤维化的应对提供重要的科学依据。
三、多基因遗传疾病研究与单基因遗传疾病不同,多基因遗传疾病是由多个基因一起作用所形成的。
在这种情况下,可能会涉及到基因的相互作用,基因多态性等内容。
例如,糖尿病、心血管疾病、癌症等都是多基因遗传的疾病,它们的发病机制复杂,难以准确识别。
在这种情况下,分子遗传学研究需要结合大量数据信息和统计分析手段,以研究基因之间的相互作用和基因之间的关联。
为了更好地理解这个问题,让我们以糖尿病为例。
糖尿病是一种影响全球成年人口的高度流行病,近年来越来越多的人群受到了其侵害。
分子遗传学在糖尿病中的应用已经取得了重要的进展。
通过对大量谱系样本的基因分析,已经确定了许多与糖尿病相关的基因,例如PPARG、TCF7L2、CDKAL1等等。

遗传性疾病分子诊断技术的研究遗传性疾病是由遗传因素引起的一类疾病,其中大部分疾病是由单个基因突变引起的,称为单基因遗传性疾病。
其余的疾病则称为多基因遗传性疾病。
在这些疾病中,基因的突变会导致蛋白质的功能异常或缺失,从而引起相关的疾病,如肌萎缩侧索硬化症,囊性纤维化等。
可以通过遗传检测技术,早期诊断这些疾病。
分子遗传学是研究个体遗传物质的结构、功能、变异和遗传性疾病发病机制的学科。
在分子遗传学中,分子诊断技术是一项关键的技术,包括PCR、Sanger测序、检测突变基因和类似的技术。
PCR技术是常用的核酸扩增技术之一。
它是以DNA聚合酶为媒介,通过引物二倍体沿模板DNA进行扩增,最终得到目的片段。
这种技术使用广泛,可以用于检测基因型和突变,如囊性纤维病突变检测。
Sanger测序是测定DNA序列的金标准技术。
这种技术的原理是,将DNA片段代入测序装置中的扩增过程中,通过加入不同特定的荧光含量的dNTPs(脱氧核苷三磷酸),以测序。
Sanger序列技术在研究遗传疾病的基因突变时也经常使用。
检测突变基因是单基因遗传病诊断的核心问题。
对于一些常见的单基因遗传病,部分疾病的基因定位和突变规律已被明确。
胰岛素样生长因子1受体(IGF-1R)等基因是有关巨细胞增生症(Gigantism)的遗传突变基因,其突变可以导致疾病发生。
研究发现,通过删除IGF-1R基因可以预防Gigantism的发生。
这种技术为控制疾病发生提供了一种新方法。
除此之外,还有其他分子遗传学技术广泛应用于遗传性疾病的诊断和预测,诸如荧光原位杂交、单细胞测序、功能分析和转录组分析等。
通过这些技术,不仅可以预测单个疾病发病的可能性,还可以填补遗传和保健之间的空白。
虽然分子遗传学技术已经具备了足够的实用性和安全性,但是在使用过程中仍然会存在一些问题和挑战,比如样本提取的困难、误差率高等问题。
这也需要逐步解决。
综上,分子遗传学技术在遗传性疾病的早期诊断、疾病治疗和疾病预防方面发挥着越来越重要的作用。




第六章多基因遗传病多基因遗传病:某些病(高血压、糖尿病、唇腭裂等)患病率超过1%,发病有遗传基础(家族倾向),也是一种“全或无”性状,但遗传方式不简单的孟德尔遗传,即系谱分析不符合AD、AR、XD、XR的遗传方式,这种疾病的发生不决定于一对等位基因,而是由两对或两对以上基因决定,称为多基因病(polygenic disorders),这类疾病的形成还受到环境因子的影响,称多因子病(multifactorial disorders)。
第一节数量性状的多基因遗传一、数量性状与质量性状1.数量性状:受2对甚至更多对等位基因控制的性状称多基因性状。
2.微效基因:控制数量性状的多对等位基因之间没有显、隐区分,是共显性的,这些基因对该遗传性状的形成作用微小,也称微效基因(minor gene)。
微效基因的作用累加起来可形成明显的表型效应,即累积效应(additive effect)。
3.多基因遗传(polygenic inheritance):性状或疾病受多对微效基因控制,同时还受环境影响,其遗传方式称多基因遗传或多因子遗传。
4.质量性状(quantiative character):单基因遗传的性状称质量性状。
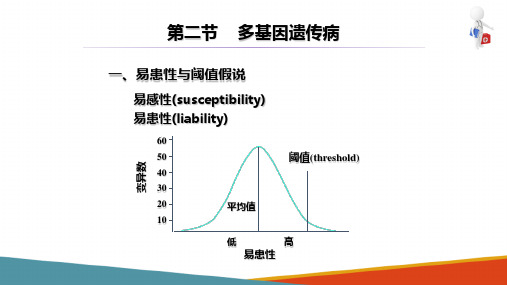
数量性状在一个群体中的变异分布是连续的,呈正态分布曲线,大多数人群性状变异近于平均值,极端性状占少数。
如人的身高。
质量性状的变异呈“全或无”的不连续分布。
如白化病。
二、数量性状的多基因遗传数量性状的遗传机制1.由多对微效基因控制。
如人的身高是数量性状,假设有3对基因控制,其表示为AA’、BB’、CC’,则ABC控制人体增高,而A’B’C’则控制人体减低,若在平均身高(165cm)的基础上增高或减低5cm,则具AABBCC基因型的个体身高可达196cm,而AA’BB’CC’的个体则身高只有135cm。
2.微效基因之间遵循分离律和自由组合律。
如一个中等身材个体的基因型是AA’BB’CC’,其形成的配子有ABC、AB’C、AB’C’、A’B C、A’B’C、A’BC’、ABC’、A’B’C’。

多基因遗传病是一类病因复杂、发病率高的常见病,多发病。
多基因遗传的疾病或性状受控于多对等位基因,也可以说受多个微效基因控制,微效基因没有显性与隐性之分,是共显性的,有累加效应,并受到环境因素的影响。
分析和研究多基因遗传病病因、发病机制、再发风险估计,要考虑遗传因素和环境因素的双重作用。
急性淋巴性白血病(ALL)是在儿童中最为常见的一种恶性肿瘤,在正常情况下应分化为免疫系统细胞(B细胞和T淋巴细胞)的未成熟白细胞停止分化,并快速异常增值,使得血液中机体赖以生存的正常血细胞的数目急剧减少。
在控制一个性状的所有QTL中,通常都存在一个或数个效应较大的QTL,它们能单独解释表型总变异的10~50%甚至更多,当其中一个位置明确的基因座效应达到一定阈值时,即可将该位置处的基因称为主基因。
第二节数量性状遗传的多基因假说在孟德尔遗传规律被重新发现后的二十世纪初,形成了以Bateson W.和Devries H.为首的Mendel学派以及以Pearson K.和WeldonW.F.R.为首的Galton学派,也称为生物统计学派(Biometricians)。
在遗传和进化问题上,Mendel学派认为不连续性变异是重要因素,孟德尔原理可以普遍用于遗传变异的研究,而连续性变异之所以不符合这些规律是因为它是不能遗传的;而Galton 学派则认为连续性变异是可遗传的,是进化的重要因素,在研究上必须采用统计学的方法,而Mendel法则对于连续性变异不适用。
这场争论直到1909年才结束。
该年约翰逊(Johannsen W.L.)发表了“纯系学说(Pure line theory)”,尼尔逊.埃尔(Nilsson-Ehle H.)提出“多基因假说(polygene hypothesis o rmultiple-factor hypothesis)”;这两个理论的建立,标志着数量遗传学的诞生。
Johannsen W.L.从十九个菜豆(Phaseolus Vulgaris)为材料,研究呈连续性变异的种子重量这性状的遗传。


多基因疾病的遗传特点多基因疾病是一类遗传性疾病,它们的发生与多个基因的作用关系密切。
研究多基因疾病的遗传特点,可以为预防和治疗该类疾病提供重要的理论基础。
1. 多基因疾病的遗传模式与单基因遗传疾病不同,多基因疾病通常不具有明显的遗传模式,而是与环境因素相互作用导致的结果。
但是,在一些多基因疾病中,仍存在一些遗传特征。
比如,亲属间发病率较高,且患病者的同时发病风险也较高。
2. 多基因疾病的遗传异质性多基因疾病的遗传异质性指的是,同一疾病不同患者之间基因表达的差异。
这种差异可能是由于不同基因型的影响,也可能是由于环境因素、生理状态等方面的影响。
了解多基因疾病的遗传异质性,可以为个性化治疗和预防提供依据。
3. 多基因疾病的遗传风险评估多基因疾病的遗传风险评估涉及到多个方面的因素,包括家族史、个人基因型、环境因素等。
现在,有一些基因组学检测技术可以帮助人们了解自己的基因风险,但是这些技术仍面临着许多技术和伦理上的困难。
4. 多基因疾病的遗传控制遗传控制是指采取措施减少或消除多基因疾病的遗传风险。
在现代医学中,已经开发出了一些基因编辑技术,可以在某种程度上减少或消除一些基因突变导致的遗传疾病。
但是,这些技术仍需要进一步的研究和完善,以确保其安全性和有效性。
5. 多基因疾病的治疗目前,多数多基因疾病的治疗仍是以控制症状、预防发作为主。
但是,随着基因组学和精准医学的发展,越来越多的个性化治疗方法将应用到多基因疾病的治疗中。
比如,可以根据病人的基因型选择适合的治疗药物或疗法,以最大限度地减轻患者的疼痛和痛苦。
总之,多基因疾病的遗传特点是复杂而多样的,它与单个基因突变不同,需要更加系统、全面的研究和解答。
未来,基于更深入的遗传学研究和技术进步,预防和治疗多基因疾病的方法将得到更加完善和精准的实现。

遗传性疾病的分子遗传学与诊断遗传性疾病是指由遗传变异引起的疾病。
在人类基因组计划完成后,人类已识别了许多遗传性疾病的基因。
然而,基因的发现并不意味着疾病的治愈,因为疾病的遗传机制十分复杂。
为了更好地了解遗传性疾病的分子遗传学和诊断方法,本文对此进行了讨论。
一、分子遗传学的基础知识分子遗传学是研究基因及其表达的分子机制的学科。
最基本的分子遗传学概念是基因,基因是生物遗传信息的基本单位。
基因通常由DNA序列编码。
分子遗传学的研究对象包括基因的表达、转录、翻译和调控等方面。
近年来,随着生物技术的发展,分子遗传学越来越广泛地应用于遗传性疾病的诊断治疗。
二、遗传性疾病的分类遗传性疾病可分为单基因遗传疾病和多基因遗传疾病。
1. 单基因遗传疾病是由单个基因所引起的遗传性疾病。
例如,囊性纤维化、酚酞蓝尿症等。
2. 多基因遗传疾病是由多个基因和环境因素共同作用所引起的遗传性疾病。
如糖尿病、癌症等。
三、遗传性疾病的诊断1. 染色体分析诊断染色体分析诊断是利用细胞学技术对人体染色体进行分析,以检测染色体结构和数量上的异常,是目前诊断某些遗传性疾病的主要手段之一。
2. 分子生物学诊断分子生物学诊断主要针对单基因遗传疾病,通过基因测序技术检测特定基因中的突变或缺失,以及疾病基因的扩增等。
例如,红细胞病的检测就是基于分子生物学诊断技术。
3. 产前诊断产前诊断包括羊膜穿刺、脐带穿刺、绒毛活检和羊水穿刺等。
其主要目的是检测出胎儿的染色体异常、单基因突变和母体血型异常等,以尽早采取措施预防或治疗。
四、结论与展望随着分子遗传学的发展,遗传性疾病的诊断方法也在不断改善。
分子遗传学技术的广泛应用,已经使人们对很多遗传性疾病有了更深入的了解,且已经获得了许多有益的成果。
未来,随着更多遗传性疾病基因的发现和治疗方法的改善,遗传性疾病的治愈将会越来越有希望。


简述多基因遗传病的遗传特征多基因遗传病是指一种由多个基因和环境因素共同决定,表现为遗传性疾病特征的疾病。
它可以是由一个或多个基因缺陷引起的遗传性疾病,也可以是由几个基因的复合缺陷引起的疾病。
因此,多基因遗传病的遗传特征比单基因遗传病更为复杂。
一、多基因遗传病的遗传模式多基因遗传病一般有两种遗传模式,即多种形式的显性遗传和多种形式的隐性遗传。
1、显性遗传显性遗传是指由单个缺陷基因决定的遗传病,其遗传模型是显性单基因遗传。
在显性多基因遗传病中,患者所携带的疾病状态受到两个状态的缺陷基因的共同影响,即当一个缺陷基因不足时,病的特征就不会出现,而当携带两个缺陷基因时,患者就会出现相应的症状。
2、隐性遗传隐性遗传是指由两个健康基因决定的遗传病,其遗传模型是隐性多基因遗传。
在隐性多基因遗传病中,患者所携带的疾病状态受到两个健康基因的影响,即当两个健康基因中只有一个有缺陷时,病的特征就不会出现,而当两个健康基因都有缺陷时,患者就会出现相应的症状。
二、多基因遗传病的遗传结果在多基因遗传病中,一个病人可能会携带几种不同类型的基因缺陷,因此,基因缺陷的组合可以产生不同的多基因遗传病的遗传结果。
其中,最著名的就是全部纯合型,半纯合型和杂合型三种型式,其中纯合型携带两个相同的基因缺陷,半纯合型携带一个可能活跃和另一个失活的基因缺陷,而杂合型则携带一个活跃基因和另一个失活基因的基因缺陷。
三、多基因遗传病的发病多基因遗传病的发病可能是由于遗传因素或环境因素引起的,一般可以分为多种发病机制:1、基因效应由于基因效应,多基因遗传病可以在遗传上转移,从而引起病变和症状出现。
2、环境因素多基因遗传病可能还受到环境和其他因素的影响,从而实现特定症状的出现和发展。
四、多基因遗传病的诊断多基因遗传病的诊断通常是结合临床表现、家族史、遗传学检查等方法,以确定病因和诊断结果。
其中,最常用的是遗传学检查,可以检测携带疾病基因的概率和病人是否携带相应病症特征。
