模糊聚类分析报告例子
- 格式:doc
- 大小:455.00 KB
- 文档页数:17

模糊聚类分析1.1 模糊聚类分析法的基本原理模糊聚类分析是根据事物间的不同特征、亲疏程度和相似性等关系,通过建立模糊相似关系对客观事物进行分类的一种数学方法。
用模糊聚类分析方法处理带有模糊性的聚类问题更为客观、灵活、直观,计算也更加简捷。
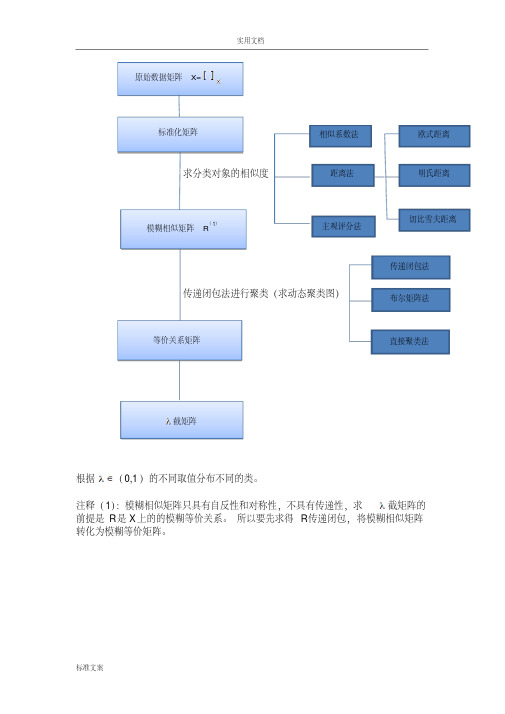
1.2 模糊聚类分析的简要流程1.3 模糊聚类分析的一般步骤Step1:数据标准化(1) 获取数据设论域12{,,,}n X x x x =为被分类对象,每个对象又有m 个指标表示其性状,即:12{,,,}(1,2,,)i i i im x x x x i n ==。
于是,得到原始数据矩阵为:111212122212()m m ij n m n n nm x x x x x x A x x x x ⨯⎛⎫ ⎪ ⎪== ⎪ ⎪⎝⎭ 其中,nm x 表示第n 个分类对象的第m 个指标的原始数据。
(2)数据的标准化处理在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行比较,通常需要对数据做适当的变换。
但是,即使这样,得到的数据也不一定在区间[0,1]上。
因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据压缩到区间[0,1]上。
通常有以下几种变换:标准差变换与极差变换,本文采用极差变换对原始数据标准化处理,其数学模型模型为:'111min{}max{}min{}ik ik i n ik ik ik i ni n x x x x x ≤≤≤≤≤≤-=-,(1,2,,)k m =显然有01ikx ''≤≤,且消除了量纲的影响,从而可以得到模糊矩阵: ''()ij n m R x ⨯=Step2:建立模糊相似矩阵设论域12{,,,}n X x x x =,12{,,(1,2,..,,)}.i i i im x x x x i n ==,即数据矩阵()ij n m A x ⨯=。
如果i x 与j x 的相似程度(,)ij i j r R x x =,则称之为相似系数。

实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。

专业:信息与计算科学 姓名: 学号:实验一 模糊聚类分析实验目的:掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件MATLAB 进行模糊矩阵的有关运算实验学时:4学时实验内容:⑴ 根据已知数据进行数据标准化.⑵ 根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵.⑶ (可选做)根据模糊等价矩阵绘制动态聚类图.⑷ (可选做)根据原始数据或标准化后的数据和⑶的结果确定最佳分类. 实验日期:20017年12月02日实验步骤:1 问题描述:设有8种产品,它们的指标如下:x 1 = (37,38,12,16,13,12)x 2 = (69,73,74,22,64,17)x 3 = (73,86,49,27,68,39)x 4 = (57,58,64,84,63,28)x 5 = (38,56,65,85,62,27)x 6 = (65,55,64,15,26,48)x 7 = (65,56,15,42,65,35)x 8 = (66,45,65,55,34,32)建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:2.1 建立原始数据矩阵设论域},,{21n x x x X 为被分类对象,每个对象又有m 个指标表示其性状, im i i i x x x x ,,,21 ,n i ,,2,1 由此可得原始数据矩阵。
于是,得到原始数据矩阵为323455654566356542155665482615645565276285655638286384645857396827498673176422747369121316123837X 其中nm x 表示第n 个分类对象的第m 个指标的原始数据,其中m = 6,n = 8。
2.2 样本数据标准化2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。
(1)平移极差变换:111min{}max{}min{}ik ik i n ik ik ik i n i n x x x x x ,(1,2,,)k m L显然有01ikx ,而且也消除了量纲的影响。

23. 模糊聚类分析原理及实现聚类分析,就是用数学方法研究和处理所给定对象,按照事物间的相似性进行区分和分类的过程。
传统的聚类分析是一种硬划分,它把每个待识别的对象严格地划分到某个类中,具有非此即彼的性质,这种分类的类别界限是分明的。
随着模糊理论的建立,人们开始用模糊的方法来处理聚类问题,称为模糊聚类分析。
由于模糊聚类得到了样本数与各个类别的不确定性程度,表达了样本类属的中介性,即建立起了样本对于类别的不确定性的描述,能更客观地反映现实世界。
本篇先介绍传统的两种(适合数据量较小情形,及理解模糊聚类原理):基于择近原则、模糊等价关系的模糊聚类方法。
(一)预备知识一、模糊等价矩阵定义1 设R=(r ij )n ×n 为模糊矩阵,I 为n 阶单位矩阵,若R 满足 i) 自反性:I ≤R (等价于r ii =1); ii) 对称性:R T =R;则称R 为模糊相似矩阵,若再满足iii) 传递性:R 2≤R (等价于1()nik kj ij k r r r =∨∧≤)则称R 为模糊等价矩阵。
定理1 设R 为n 阶模糊相似矩阵,则存在一个最小的自然数k(k <n ), 使得R k 为模糊等价矩阵,且对一切大于k 的自然数l ,恒有R l =R k . R k 称为R 的传递闭包矩阵,记为t(R). 二、模糊矩阵的λ-截矩阵定义2 设A =(a ij )n ×m 为模糊矩阵,对任意的λ∈[0,1], 作矩阵()()ij n mA a λλ⨯=其中,()1, 0, ij ijij a aa λλλ≥⎧=⎨<⎩称为模糊矩阵A 的λ-截矩阵。
显然,A λ为布尔矩阵,且其等价性与与A 一致。
意义:将模糊等价矩阵转化为等价的布尔矩阵,可以得到有限论域上的普通等价关系,而等价关系是可以分类的。
因此,当λ在[0,1]上变动时,由A λ得到不同的分类。
若λ1<λ2, 则A λ1≥A λ2, 从而由A λ2确定的分类是由A λ1确定的分类的加细。

专业:信息与计算科学姓名:学号:实验一模糊聚类分析实验目的:掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件 MATLAB 进行模糊矩阵的有关运算实验学时: 4 学时实验内容:⑴根据已知数据进行数据标准化.⑵根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵.⑶ (可选做 )根据模糊等价矩阵绘制动态聚类图.⑷ (可选做 )根据原始数据或标准化后的数据和⑶的结果确定最佳分类.实验日期: 20017 年 12 月 02 日实验步骤:1问题描述:设有 8 种产品,它们的指标如下:x1 = (37,38,12,16,13,12)x2 = (69,73,74,22,64,17)x3 = (73,86,49,27,68,39)x4 = (57,58,64,84,63,28)x5 = (38,56,65,85,62,27)x6 = (65,55,64,15,26,48)x7 = (65,56,15,42,65,35)x8 = (66,45,65,55,34,32)建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:2.1 建立原始数据矩阵设论域 X{ x1, x2 ,x n } 为被分类对象,每个对象又有 m 个指标表示其性状,x i x i1, x i 2 ,, x imi1,2, , n由此可得原始数据矩阵。
,于是,得到原始数据矩阵为37 38 12 16 13 12 69 73 74 22 64 17 73 86 49 27 68 39 57 58 64 84 63 28 X56 65 85 62 27 38 65 55 64 15 26 48 65 56 15 42 65 35 66 45 65 55 34 32其中 x nm 表示第 n 个分类对象的第 m 个指标的原始数据,其中 m = 6,n = 8。
2.2 样本数据标准化2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。

(二).模型实例分析例:设某地区设置有11个雨量站,其分布图见图1,10年来各雨量站所测得的年降雨量列入表1中。
现因经费问题,希望撤销几个雨量站,问撤销那些雨量站,而不会太多的减少降雨信息?图1表1应该撤销那些雨量站,涉及雨量站的分布,地形,地貌,人员,设备等众多因素。
我们仅考虑尽可能地减少降雨信息问题。
一个自然的想法是就10年来各雨量站所获得的降雨信息之间的相似性,对全部雨量站进行分类,撤去“同类”(所获降雨信息十分相似)的雨量站中“多余”的站。
问题求解 假设为使问题简化,特作如下假设 (1) 每个观测站具有同等规模及仪器设备; (2) 每个观测站的经费开支均等; 具有相同的被裁可能性。
分析:对上述撤销观测站的问题用基于模糊等价矩阵的模糊聚类方法进行分析,原始数据如上。
求解步骤:1.利用相关系数法,构造模糊相似关系矩阵1111)(⨯αβr ,其中ij r =2111221])()([|)(||)(|∑∑∑=-=-⋅---n k nk j jk i ik nk j jk i ikx x x x x x x x其中i x =∑=101101k ik x ,i =1,2, (11)j x =∑=nk jk x n 11,j =1,2, (11)用C 语言编程计算出模糊相似关系矩阵1111)(⨯αβr ,具体程序如下 #include<stdio.h> #include<math.h>double r[11][11]; double x[11]; void main(){ int i,j,k; double fenzi=0,fenmu1=0,fenmu2=0,fenmu=0;int year[10][11]={276,324,159,413, 292 ,258,311,303,175,243,320, 251 ,287,349,344,310,454,285,451,402,307,470, 192 ,433,290,563,479,502,221,220,320,411,232,246 ,232,243,281,267,310,273,315,285,327,352,291,311,502,388 ,330,410,352,267,603,290,292,466 ,158,224,178,164,203,502,320,240,278,350,258,327,432 ,401,361,381,301,413,402,199,421,453,365,357 ,452,384,420,482,228,360,316,252,158 ,271,410,308,283,410,201,179,430,342,185,324,406,235,520 ,442,520,358,343,251,282,371};for(i=0;i<11;i++){ for(k=0;k<10;k++){ x[i]=x[i]+year[k][i];}x[i]=x[i]/10;}for(i=0;i<11;i++){for(j=0;j<11;j++){ for(k=0;k<10;k++){ fenzi=fenzi+fabs((year[k][i]-x[i])*(year[k][j]-x[j]));fenmu1=fenmu1+(year[k][i]-x[i])*(year[k][i]-x[i]);fenmu2=fenmu2+(year[k][j]-x[j])*(year[k][j]-x[j]); fenmu=sqrt(fenmu1)*sqrt(fenmu2);r[i][j]=fenzi/fenmu;}fenmu=fenmu1=fenmu2=fenzi=0;}}for(i=0;i<11;i++){ for(j=0;j<11;j++){printf("%6.3f",r[i][j]);}printf("\n");} getchar(); }得到模糊相似矩阵R1.000 0.839 0.528 0.844 0.828 0.702 0.995 0.671 0.431 0.573 0.712 0.839 1.000 0.542 0.996 0.989 0.899 0.855 0.510 0.475 0.617 0.572 0.528 0.542 1.000 0.562 0.585 0.697 0.571 0.551 0.962 0.642 0.568 0.844 0.996 0.562 1.000 0.992 0.908 0.861 0.542 0.499 0.639 0.607 0.828 0.989 0.585 0.992 1.000 0.922 0.843 0.526 0.512 0.686 0.584 0.702 0.899 0.697 0.908 0.922 1.000 0.726 0.455 0.667 0.596 0.511 0.995 0.855 0.571 0.861 0.843 0.726 1.000 0.676 0.489 0.587 0.719 0.671 0.510 0.551 0.542 0.526 0.455 0.676 1.000 0.467 0.678 0.994 0.431 0.475 0.962 0.499 0.512 0.667 0.489 0.467 1.000 0.487 0.485 0.573 0.617 0.642 0.639 0.686 0.596 0.587 0.678 0.487 1.000 0.688 0.712 0.572 0.568 0.607 0.584 0.511 0.719 0.994 0.485 0.688 1.000对这个模糊相似矩阵用平方法作传递闭包运算,求442:R R R −→−即t (R )=4R =*R注:R 是对称矩阵,故只写出它的下三角矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1688.0697.0688.0719.0719.0719.0719.0697.0719.0719.01697.0688.0688.0688.0688.0688.0688.0688.0688.01676.0697.0697.0697.0697.0962.0697.0697.01719.0719.0719.0719.0697.0719.0719.01861.0861.0861.0697.0861.0994.01922.0922.0697.0995.0861.01992.0697.0996.0861.01697.0996.0861.01697.0697.01861.0000.1*R取λ=0.996,则996.0R =⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡111111*********故第二行(列),第四行(列)完全一致,故42,x x 同属一类,所以此时可以将观测站分为9类{42,x x ,5x },{1x },{3x },{6x },{7x },{8x },{9x },{10x },{11x } 这表明,若只裁减一个观测站,可以裁42,x x 中的一个。

模糊聚类实现鸢尾花(iris)分类实验报告实验报告:模糊聚类实现鸢尾花(iris)分类一、实验目的本实验旨在通过模糊聚类算法对鸢尾花(iris)数据集进行分类,并比较其分类效果与传统的硬聚类算法。
二、实验原理模糊聚类是一种基于模糊集合理论的聚类分析方法。
与传统的硬聚类算法不同,模糊聚类能够为每个样本赋予一个隶属度,表示该样本属于某个簇的程度。
常用的模糊聚类算法包括模糊C-均值聚类(FCM)和概率模糊C-均值聚类(PFCM)。
三、实验步骤1. 数据准备:加载鸢尾花数据集,将数据分为特征和标签两部分。
2. 数据预处理:对特征数据进行归一化处理,使其满足模糊聚类的要求。
3. 构建模糊矩阵:根据给定的模糊参数,构建模糊矩阵。
4. 执行模糊聚类:使用模糊聚类算法对数据进行聚类,得到每个样本的隶属度矩阵。
5. 分类结果输出:根据隶属度矩阵和阈值,将样本分为不同的类别。
6. 评估分类效果:计算分类准确率、召回率等指标,评估分类效果。
四、实验结果以下是使用模糊C-均值聚类算法对鸢尾花数据集进行分类的结果:样本实际类别预测类别隶属度1 setosa setosa2 versicolor versicolor3 virginica virginica... ... ... ...150 setosa setosa151 versicolor versicolor152 virginica virginica通过观察上表,我们可以发现大多数样本被正确地分类到了所属的类别,且具有较高的隶属度。
具体分类准确率如下:setosa: 97%,versicolor: 94%,virginica: 95%。
可以看出,模糊聚类算法在鸢尾花数据集上取得了较好的分类效果。
五、实验总结本实验通过模糊聚类算法对鸢尾花数据集进行了分类,并得到了较好的分类效果。
与传统硬聚类算法相比,模糊聚类能够为每个样本赋予一个隶属度,更准确地描述样本属于各个簇的程度。

专业:信息与计算科学 姓名: 学号:实验一 模糊聚类分析实验目的:掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件MATLAB 进行模糊矩阵的有关运算实验学时:4学时实验内容:⑴ 根据已知数据进行数据标准化.⑵ 根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵. ⑶ (可选做)根据模糊等价矩阵绘制动态聚类图.⑷ (可选做)根据原始数据或标准化后的数据和⑶的结果确定最佳分类. 实验日期:20017年12月02日实验步骤: 1 问题描述:设有8种产品,它们的指标如下:x 1 = (37,38,12,16,13,12) x 2 = (69,73,74,22,64,17) x 3 = (73,86,49,27,68,39) x 4 = (57,58,64,84,63,28) x 5 = (38,56,65,85,62,27) x 6 = (65,55,64,15,26,48) x 7 = (65,56,15,42,65,35) x 8 = (66,45,65,55,34,32)建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:2.1 建立原始数据矩阵设论域},,{21n x x x X =为被分类对象,每个对象又有m 个指标表示其性状,{}im i i i x x x x ,,,21 =,ni ,,2,1 = 由此可得原始数据矩阵。
于是,得到原始数据矩阵为⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛=323455654566356542155665482615645565276285655638286384645857396827498673176422747369121316123837X 其中nm x 表示第n 个分类对象的第m 个指标的原始数据,其中m = 6,n = 8。
2.2 样本数据标准化2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。
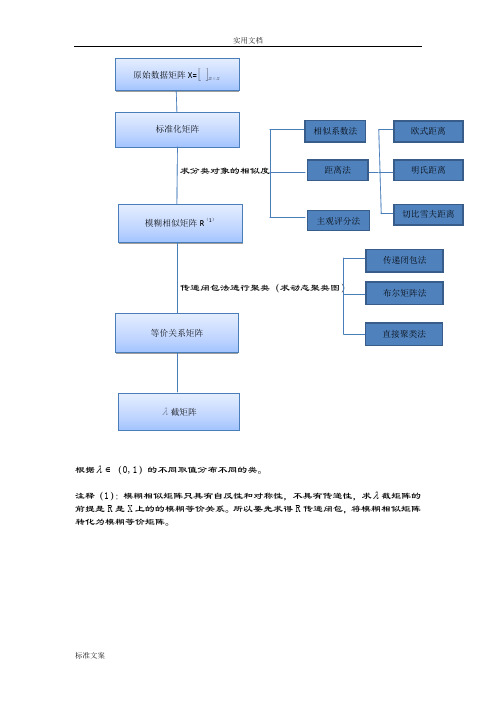
根据λ∈(0,1)的不同取值分布不同的类。
注释(1):模糊相似矩阵只具有自反性和对称性,不具有传递性,求λ截矩阵的前提是R是X上的的模糊等价关系。
所以要先求得R传递闭包,将模糊相似矩阵转化为模糊等价矩阵。
雨量站问题原始数据矩阵:(重要定理:设 R∈F ( X ⨯ X ) 是相似关系 ( 即 R 是自反、对称模糊关系 ) ,则e(R) = t(R) ,即模糊相似关系的传递闭包就是它的等价闭包。
)Y的传递闭包(即Y的等价矩阵):求λ截矩阵,在程序中我用的k代替了λ。
K=1时,x1,x2,x3,…x11,各成一类,将11个雨量站分成11类。
K=0.9095时,将11个雨量站分为10类,X8, X11为一类,其余各自一类。
分8类,将x2 ,x5,x8,x11分一类,其余各自一类分6类,x2 x3,x5,x8,x9x11为一类,其余各自一类。
分4类,x1,x2,x3,x5,x7,x8,x9x11为一类,其余各自一类。
分4类,x1, x3x2x7x8x9x11为一类,x2x4x5为一类,x6一类,x10一类。
分3类,x2 x4x5x6为一类,x1x3x7x8x9x11一类,x10一类。
分2类,x2 x4x5x6x10一类,x1x3x7x8x9x11一类分2类,x1x2x4x5x6x10一类,x3x8x9x11一类.分1类。
程序一:标准化矩阵:function Y=bzh1(X)[a,b]=size(X);C=max(X);D=min(X);Y=zeros(a,b);for i=1:afor j=1:bY(i,j)=(X(i,j)-D(j))/(C(j)-D(j)); %平移极差变化进行数据标准化endendfprintf('标准化矩阵如下:Y=\n');disp(Y)end程序二:求模糊相似矩阵:function R=biaod2(Y,c)[a,b]=size(Y);Z=zeros(a);R=zeros(a);for i=1:afor j=1:afor k=1:bZ(i,j)=abs(Y(i,k)-Y(j,k))+Z(i,j);R(i,j)=1-c*Z(i,j);%绝对值减数法--欧氏距离求模糊相似矩阵 endendendfprintf('模糊相似矩阵如下:R=\n');disp(R)end程序三:计算传递闭包:function B=cd3(R)a=size(R);B=zeros(a);flag=0;while flag==0for i= 1: afor j= 1: afor k=1:aB( i , j ) = max(min( R( i , k) , R( k, j) ) , B( i , j ) ) ;%R 与R内积,先取小再取大endendendif B==Rflag=1;elseR=B;%循环计算R传递闭包endend程序四:求 截矩阵:function [D k] =jjz4(B)L=unique(B)';a=size(B);D=zeros(a);for m=length(L):-1:1k=L(m);for i=1:afor j=1:aif B(i,j)>=kD(i,j)=1;实用文档else D(i,j)=0;%求?截距阵,当bij≥? 时,bij(?) =1;当bij<? 时,bij(?) =0endendendfprintf('当分类系数k=:\n');disp(L(m));fprintf('所得截距阵为:\n');disp(D);end标准文案。
数学实验报告
实验序号:模糊数学日期:2013年10 月06 日
实验过程记录(含:基本步骤、主要程序清单及异常情况记录等):
1.求解相似矩阵:
相似矩阵为R2;其中c=256.8561。
n表示的是数据的个数,这里,我们选取的是50个数据,n 可以根据你选取的数据的多少进行调整。
可以根据你的数据的存储位置进行相应的改变,但必须是文本文档形式。
2.求相似矩阵的传递闭包矩阵:
传递闭包矩阵为R。
3.进行聚类分析与聚类图:
对截集的确定
d是的个数,lamd是所有组成的行矩阵。
结果如下页:
聚类的程序如下:
聚类结果如下:
聚类图:
要画出聚类图,先要将50种白酒进行顺序排列,程序如下:
排序的结果在C中,结果如下页:
聚类图的程序如下:
聚类图如下所示:。

模糊数学方法及其应用论文题目:模糊聚类方法案例分析小组成员:王季光宋申辉兰洁陈倩芸肖仑杨洋吴云峰2013年10 月27 日模糊聚类分析方法1.1距离和相似系数为了将样品(或指标)进行分类,就需要研究样品之间关系。
目前用得最多的方法有两个:一种方法是用相似系数,性质越接近的样品,它们的相似系数的绝对值越接近1,而彼此无关的样品,它们的相似系数的绝对值越接近于零。
比较相似的样品归为一类,不怎么相似的样品归为不同的类。
另一种方法是将一个样品看作P 维空间的一个点,并在空间定义距离,距离越近的点归为一类,距离较远的点归为不同的类。
但相似系数和距离有各种各样的定义,而这些定义与变量的类型关系极大,因此先介绍变量的类型。
由于实际问题中,遇到的指标有的是定量的(如长度、重量等),有的是定性的(如性别、职业等),因此将变量(指标)的类型按以下三种尺度划分: 间隔尺度:变量是用连续的量来表示的,如长度、重量、压力、速度等等。
在间隔尺度中,如果存在绝对零点,又称比例尺度,本书并不严格区分比例尺度和间隔尺度。
有序尺度:变量度量时没有明确的数量表示,而是划分一些等级,等级之间有次序关系,如某产品分上、中、下三等,此三等有次序关系,但没有数量表示。
名义尺度:变量度量时、既没有数量表示,也没有次序关系,如某物体有红、黄、白三种颜色,又如医学化验中的阴性与阳性,市场供求中的“产”和“销”等。
不同类型的变量,在定义距离和相似系数时,其方法有很大差异,使用时必须注意。
研究比较多的是间隔尺度,因此本章主要给出间隔尺度的距离和相似系数的定义。
设有n 个样品,每个样品测得p 项指标(变量),原始资料阵为px x x np n n p p nx x x x x x x x x X X X X 2122221112112121 ⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=其中(1,,;1,,)ij x i n j p ==为第i 个样品的第j 个指标的观测数据。

一、实验背景随着大数据时代的到来,数据挖掘技术在各个领域得到了广泛的应用。
聚类分析作为数据挖掘的一种基本方法,通过对数据进行无监督学习,将相似的数据点归为一类,从而揭示数据中的潜在结构和规律。
传统的聚类算法如K-means算法在处理复杂数据时往往存在局限性,而模糊聚类算法能够更好地处理模糊性和不确定性,因此在实际应用中具有更广泛的前景。
二、实验目的1. 理解模糊聚类算法的基本原理和实现方法;2. 掌握模糊C均值(FCM)算法的应用;3. 分析不同参数对聚类结果的影响;4. 对比模糊聚类算法与传统聚类算法的性能。
三、实验内容1. 数据准备选取UCI机器学习库中的鸢尾花(Iris)数据集作为实验数据。
该数据集包含150个样本,每个样本有4个特征,属于3个类别。
2. 模糊C均值算法实现(1)初始化聚类中心:随机选取3个样本作为初始聚类中心。
(2)计算隶属度:根据每个样本与聚类中心的距离,计算其属于各个聚类的隶属度。
(3)更新聚类中心:根据隶属度,计算每个聚类中心的新位置。
(4)重复步骤(2)和(3),直到满足迭代终止条件。
3. 参数设置与调整(1)模糊系数m:m值越大,聚类结果越模糊,m值越小,聚类结果越精确。
实验中分别取m=1.5、m=2.5和m=3.5。
(2)最大迭代次数:设置最大迭代次数为100次。
4. 聚类结果分析(1)对比不同m值下的聚类结果:通过可视化工具展示不同m值下的聚类结果,分析m值对聚类结果的影响。
(2)对比模糊聚类算法与传统K-means算法的性能:通过计算聚类结果的轮廓系数,对比两种算法的性能。
四、实验结果与分析1. 不同m值下的聚类结果当m=1.5时,聚类结果较为模糊,部分样本同时属于多个类别;当m=2.5时,聚类结果较为精确,但仍存在一些样本同时属于多个类别;当m=3.5时,聚类结果最为精确,但部分样本的类别归属存在争议。
2. 模糊聚类算法与传统K-means算法的性能对比通过计算轮廓系数,模糊聚类算法的平均轮廓系数为0.76,而K-means算法的平均轮廓系数为0.54。

模糊聚类分析模糊聚类分析是根据客观事物间的特征、亲疏程度、相似性,通过建立模糊相似关系对客观事物进行聚类的分析方法。
介绍涉及事物之间的模糊界限时按一定要求对事物进行分类的数学方法。
聚类分析是数理统计中的一种多元分析方法,它是用数学方法定量地确定样本的亲疏关系,从而客观地划分类型。
事物之间的界限,有些是确切的,有些则是模糊的。
例人群中的面貌相像程度之间的界限是模糊的,天气阴、晴之间的界限也是模糊的。
当聚类涉及事物之间的模糊界限时,需运用模糊聚类分析方法。
模糊聚类分析广泛应用在气象预报、地质、农业、林业等方面。
通常把被聚类的事物称为样本,将被聚类的一组事物称为样本集。
模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
2常用分类综述数据分类中,常用的分类方法有多元统计中的系统聚类法、模糊聚类分析等.在模糊聚类分析中,首先要计算模糊相似矩阵,而不同的模糊相似矩阵会产生不同的分类结果;即使采用相同的模糊相似矩阵,不同的阈值也会产生不同的分类结果.“如何确定这些分类的有效性”便成为模糊聚类的要点。
识别研究中的一个重要问题.文献,把有效性不满意的原因归结于数据集几何结构的不理想.但笔者认为,不同的几何结构是对实际需要的反映,我们不能排除实际需要而追求所谓的“理想几何结构”,不理想的分类不应归因于数据集的几何结构.针对同一模糊相似矩阵,文献建立了确定模糊聚类有效性的方法.用固定的显著性水平,在不同分类的F一统计量和F检验临界值的差中选最大者,即为有效分类.但是,当显著性水平变化时,此方法的结果也会变化.文献引进了一种模糊划分嫡来评价模糊聚类的有效性,并人为规定当两类的嫡大于一数时,此两类可合并,通过逐次合并,最终得到有效分类.此方法人为干预较多,当这个规定数不同时,也会得到不同的结果.另外这两种方法也未比较不同模糊相似矩阵的分类结果.系统聚类法系统聚类法是基于模糊等价关系的模糊聚类分析法。
在经典的聚类分析方法中可用经典等价关系对样本集进行聚类。

1. 模糊聚类分析模型环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。
设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。
解 :由题设知特性指标矩阵为: *80106250164906464057310124X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦数据规格化:最大规格化'ij ijjx x M =其中: 12max(,,...,)j j j nj M x x x =00.8910.860.330.560.10.860.6710.60.5710.440.510.50.110.10.290.67X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ⨯=,10.540.620.630.240.5410.550.700.530.620.5510.560.370.630.700.5610.380.240.530.370.381R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦利用平方自合成方法求传递闭包t (R )依次计算248,,R R R , 由于84R R =,所以4()t R R =210.630.620.630.530.6310.560.700.530.620.5610.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,410.630.620.630.530.6310.620.700.530.620.6210.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦=8R选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。

1. 模糊聚类分析模型环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。
设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。
解 :由题设知特性指标矩阵为: *80106250164906464057310124X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦数据规格化:最大规格化'ij ijjx x M =其中: 12max(,,...,)j j j nj M x x x =00.8910.860.330.560.10.860.6710.60.5710.440.510.50.110.10.290.67X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ⨯=,10.540.620.630.240.5410.550.700.530.620.5510.560.370.630.700.5610.380.240.530.370.381R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦利用平方自合成方法求传递闭包t (R )依次计算248,,R R R , 由于84R R =,所以4()t R R =210.630.620.630.530.6310.560.700.530.620.5610.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,410.630.620.630.530.6310.620.700.530.620.6210.620.530.630.700.6210.530.530.530.530.531R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦=8R选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。
把()t R 中的元素从大到小的顺序编排如下: 1>0.70>0.63>062>053. 依次取λ=1, 0.70, 0.63, 062, 053,得11000001000()0010*******0001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为5类:{1x },{2x },{3x },{4x },{5x }0.71000001010()001000101000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为4类:{1x },{2x ,4x },{3x },{5x }0.631101011010()001001101000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为3类:{1x ,2x ,4x },{3x },{5x }0.621111011110()111101111000001t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为2类:{1x ,2x ,4x ,3x },{5x }0.531111111111()111111*********t R ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎣⎦,此时X 被分为1类:{12345,,,,x x x x x }Matlab 程序如下: %数据规格化MATLAB 程序a=[80 10 6 2 50 1 6 4 90 6 4 6 40 5 7 3 10 1 2 4]; mu=max(a) for i=1:5 for j=1:4r(i,j)=a(i,j)/mu(j); end end r%采用最大最小法构造相似矩阵r=[0.8889 1.0000 0.8571 0.3333 0.5556 0.1000 0.8571 0.6667 1.0000 0.6000 0.5714 1.0000 0.4444 0.5000 1.0000 0.5000 0.1111 0.1000 0.2857 0.6667]; b=r'; for i=1:5 for j=1:5R(i,j)=sum(min([r(i,:);b(:,j)']))/sum(max([r(i,:);b(:,j)'])); end end R%利用平方自合成方法求传递闭包t (R ) 矩阵合成的MATLAB 函数function rhat=hech(r); n=length(r); for i=1:n for j=1:nrhat(i,j)=max(min([r(i,:);r(:,j)'])); end end求模糊等价矩阵和聚类的程序R=[ 1.0000 0.5409 0.6206 0.6299 0.2432 0.5409 1.0000 0.5478 0.6985 0.5339 0.6206 0.5478 1.0000 0.5599 0.3669 0.6299 0.6985 0.5599 1.0000 0.3818 0.2432 0.5339 0.3669 0.3818 1.0000]; R1=hech (R) R2=hech (R1) R3=hech (R2) bh=zeros(5); bh(find(R2>0.7))=12. 模糊综合评判模型某烟草公司对某部门员工进行的年终评定,关于考核的具体操作过程,以对一名员工的考核为例。
如下表所示,根据该部门工作人员的工作性质,将18个指标分成工作绩效(1U )、工作态度(2U )、工作能力(3U )和学习成长(4U )这4各子因素集。
员工考核指标体系及考核表技能提高 0.1 0.4 0.3 0.1 0.1 培训参与 0.2 0.3 0.4 0.1 0 工作提供0.40.30.20.1请专家设定指标权重,一级指标权重为:()0.4,0.3,0.2,0.1A =二级指标权重为:()10.2,0.3,0.3,0.2A =()20.3,0.2,0.1,0.2,0.2A = ()30.1,0.2,0.3,0.2,0.2A = ()40.3,0.2,0.2,0.3A = 对各个子因素集进行一级模糊综合评判得到:()1110.39,0.39,0.26,0.04,0.01B A R == ()2220.21,0.37,0.235,0.125,0.06B A R == ()3330.15,0.32,0.355,0.125,0.06B A R == ()4440.27,0.35,0.24,0.1,0.02B A R ==这样,二级综合评判为:()0.390.390.260.040.010.210.370.2350.1250.060.4,0.3,0.2,0.10.150.320.3550.1250.060.270.350.240.10.2B A R ⎡⎤⎢⎥⎢⎥==⎢⎥⎢⎥⎣⎦()0.28,0.37,0.27,0.09,0.04= 根据最大隶属度原则,认为该员工的评价为良好。
同理可对该部门其他员工进行考核。
3. 层次分析模型你已经去过几家主要的摩托车商店,基本确定将从三种车型中选购一种,你选择的标准主要有:价格、耗油量大小、舒适程度和外观美观情况。
经反复思考比较,构造了它们之间的成对比较判断矩阵。
A=1378115531113751111853⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦三种车型(记为a,b,c )关于价格、耗油量、舒适程度和外表美观情况的成对比较判断矩阵为价格 a b c 耗油量 a b c1231/2121/31/21a b c ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦ 11/51/251721/71a b c ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦舒适程度 a b c 外表 a b c1351/3141/51/41a b c ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦ 11/535171/31/71a b c ⎡⎤⎢⎥⎢⎥⎢⎥⎣⎦根据上述矩阵可以看出四项标准在你心目中的比重是不同的,请按由重到轻顺序将它们排出。
解:用matlab 求解 层次总排序的结果如下表Matlab程序如下:clc,clearn1=4;n2=3;a=[1 3 7 81/3 1 5 51/7 1/5 1 31/8 1/5 1/3 1];b1=[1 2 31/2 1 21/3 1/2 1 ];b2=[1 1/5 1/25 1 72 1/7 1 ];b3=[1 3 51/3 1 41/5 1/4 1 ];b4=[1 1/5 35 1 71/3 1/7 1];ri=[0,0,0.58,0.90,1.12,1.24,1.32,1.41,1.45]; % 一致性指标RI[x,y]=eig(a); %x为特征向量,y为特征值lamda=max(diag(y));num=find(diag(y)==lamda);w0=x(:,num)/sum(x(:,num));w0 %准则层特征向量CR0=(lamda-n1)/(n1-1)/ri(n1) %准则层一致性比例for i=1:n1[x,y]=eig(eval(char(['b',int2str(i)])));lamda=max(diag(y));num=find(diag(y)==lamda);w1(:,i)=x(:,num)/sum(x(:,num)); %方案层的特征向量CR1(i)=(lamda-n2)/(n2-1)/ri(n2); %方案层的一致性比例endw1CR1, ts=w1*w0, CR=CR1*w0 %ts为总排序的权值,CR为层次总排序的随机一致性比例% 当CR小于0.1时,认为总层次排序结果具有较满意的一致性并接受该结果,否则对判断矩阵适当修改4. 灰色预测GM(1,1)模型某地区年平均降雨量数据如表 某地区年平均降雨量数据规定hz=320,并认为(0)()x i <=hz 为旱灾。
预测下一次旱灾发生的时间 解:初始序列如下(0)x =(390.6,412,320,559.2,380.8,542.4,553,310,561,300,632,540,406.2,313.8,576,587.6,318.5)由于满足(0)()x i <=320的(0)()x i 为异常值,易得下限灾变数列为hzx = (320,310,300,313.8,318.5) 其对应的时刻数列为t = (3,8,10,14,17)建立GM (1,1)模型(1) 对原始数据t 做一次累加,即t(1) = (3,11,21,35,52) (2) 构造数据矩阵及数据向量 (3) 计算a ,ba=-0.2536,b=6.2585 (4) 建立模型y=-24.6774+27.6774*exp(.253610*t) (5) 模型检验(6) 通过计算可以预测到第六个数据是22.0340由于 22.034 与17 相差5.034,这表明下一次旱灾将发生在五年以后。