非线性回归19种模型
- 格式:pptx
- 大小:72.18 KB
- 文档页数:2

回归分析的基本思想及其初步应用1.回归分析回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法,回归分析的基本步骤是画出两个变量的散点图,求回归直线方程,并用回归直线方程进行预报. 2.线性回归模型(1)在线性回归直线方程y ^=a ^+b ^x 中,b ^=∑ni =1 (x i -x )(y i -y )∑ni =1(x i -x )2,a ^=y --b ^x -,其中x -=1n ∑ni =1x i ,y -=1n∑ni =1y i ,(x ,y )称为样本点的中心,回归直线过样本点的中心. (2)线性回归模型y =bx +a +e ,其中e 称为随机误差,自变量x 称为解释变量,因变量y 称为预报变量.[注意] (1)非确定性关系:线性回归模型y =bx +a +e 与确定性函数y =a +bx 相比,它表示y 与x 之间是统计相关关系(非确定性关系),其中的随机误差e 提供了选择模型的准则以及在模型合理的情况下探求最佳估计值a ,b 的工具.(2)线性回归方程y ^=b ^x +a ^中a ^,b ^的意义是:以a ^为基数,x 每增加1个单位,y 相应地平均增加b ^个单位.3.刻画回归效果的方式方式方法计算公式 刻画效果R 2R 2=1-∑ni =1(y i -y ^i )2∑n i =1(y i -y )2R 2越接近于1,表示回归的效果越好残差图e ^i 称为相应于点(x i ,y i )的残差,e ^i =y i -y ^i残差点比较均匀地落在水平的带状区域中,说明选用的模型比较合适,其中这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高残差平方和∑ni =1(y i -y ^i )2 残差平方和越小,模型的拟合效果越好判断正误(正确的打“√”,错误的打“×”) (1)求线性回归方程前可以不进行相关性检验.( )(2)在残差图中,纵坐标为残差,横坐标可以选为样本编号.( )(3)利用线性回归方程求出的值是准确值.( ) 答案:(1)× (2)√ (3)×变量x 与y 之间的回归方程表示( )A .x 与y 之间的函数关系B .x 与y 之间的不确定性关系C .x 与y 之间的真实关系形式D .x 与y 之间的真实关系达到最大限度的吻合 答案:D在两个变量y 与x 的回归模型中,分别选择了4个不同的模型,它们的相关指数R 2如下,其中拟合效果最好的模型是( )A .模型1的相关指数R 2为0.98 B .模型2的相关指数R 2为0.80 C .模型3的相关指数R 2为0.50 D .模型4的相关指数R 2为0.25 答案:A已知线性回归方程y ^=0.75x +0.7,则x =11时,y 的估计值为________. 答案:8.95探究点1 线性回归方程在某种产品表面进行腐蚀刻线试验,得到腐蚀深度y 与腐蚀时间x 之间的一组观察值如下表.x (s) 5 10 15 20 30 40 50 60 70 90 120 y (μm)610101316171923252946(1)画出散点图;(2)求y 对x 的线性回归方程;(3)利用线性回归方程预测时间为100 s 时腐蚀深度为多少. 【解】 (1)散点图如图所示.(2)从散点图中,我们可以看出y 对x 的样本点分布在一条直线附近,因而求回归直线方程有意义.x =111(5+10+15+ (120)=51011,y =111(6+10+10+…+46)=21411,a ^=y -b ^x ≈21411-0.304×51011= 5.36. 故腐蚀深度对腐蚀时间的线性回归方程为y =0.304x + 5.36.(3)根据(2)求得的线性回归方程,当腐蚀时间为100 s 时,y ^=5.36+0.304×100=35.76(μm),即腐蚀时间为100 s 时腐蚀深度大约为35.76 μm.求线性回归方程的三个步骤(1)画散点图:由样本点是否呈条状分布来判断两个量是否具有线性相关关系. (2)求回归系数:若存在线性相关关系,则求回归系数.(3)写方程:写出线性回归方程,并利用线性回归方程进行预测说明.炼钢是一个氧化降碳的过程,钢水含碳量的多少直接影响冶炼时间的长短,必须掌握钢水含碳量和冶炼时间的关系.如果已测得炉料熔化完毕时钢水的含碳量x 与冶炼时间y (从炼料熔化完毕到出钢的时间)的数据(x i ,y i )(i =1,2,…,10)并已计算出=1589,i =110y i =1 720,故冶炼时间y 对钢水的含碳量x 的回归直线方程为y ^=1.267x -30.47. 探究点2 线性回归分析假定小麦基本苗数x 与成熟期有效穗y 之间存在相关关系,今测得5组数据如下:(1)以x 为解释变量,y 为预报变量,作出散点图;(2)求y 与x 之间的回归方程,对于基本苗数56.7预报有效穗; (3)计算各组残差,并计算残差平方和;(4)求相关指数R 2,并说明残差变量对有效穗的影响占百分之几? 【解】 (1)散点图如下.(2)由图看出,样本点呈条状分布,有比较好的线性相关关系,因此可以用回归方程刻画它们之间的关系.设回归方程为y ^=b ^x +a ^,x -=30.36,y -=43.5,(1)该类题属于线性回归问题,解答本题应先通过散点图来分析两变量间的关系是否线性相关,然后再利用求回归方程的公式求解回归方程,并利用残差图或相关指数R 2来分析函数模x 15.0 25.8 30.0 36.6 44.4 y39.442.942.943.149.2型的拟合效果,在此基础上,借助回归方程对实际问题进行分析. (2)刻画回归效果的三种方法①残差图法:残差点比较均匀地落在水平的带状区域内说明选用的模型比较合适; ②残差平方和法:残差平方和 i =1n(y i -y ^i )2越小,模型的拟合效果越好;关于x 与y 有如下数据:x 2 4 5 6 8 y3040605070由(2)可得y i -y ^i 与y i -y -的关系如下表:y i -y ^i -1 -5 8 -9 -3 y i -y --20-101020由于R 21=0.845,R 22=0.82,0.845>0.82, 所以R 21>R 22.所以(1)的拟合效果好于(2)的拟合效果. 探究点3 非线性回归分析某地今年上半年患某种传染病的人数y (人)与月份x (月)之间满足函数关系,模型为y =a e bx ,确定这个函数解析式.月份x /月 1 2 3 4 5 6 人数y /人526168747883【解】 设u =ln y ,c =ln a , 得u ^=c ^+b ^x ,则u 与x 的数据关系如下表:x12 3 4 56u =ln y 3.95 4.114.224.3044.356 7 4.418 8非线性回归方程的步骤(1)确定变量,作出散点图.(2)根据散点图,选择恰当的拟合函数.(3)变量置换,通过变量置换把非线性回归问题转化为线性回归问题,并求出线性回归方程. (4)分析拟合效果:通过计算相关指数或画残差图来判断拟合效果. (5)根据相应的变换,写出非线性回归方程.某种书每册的成本费y (元)与印刷册数x (千册)有关,经统计得到数据如下:x(千册)1 2 3 5 10 20 30 50 100 200 y (元)10.155.524.082.852.111.621.411.301.211.15检验每册书的成本费y (元)与印刷册数的倒数1x之间是否具有线性相关关系,如有,求出y 对x 的回归方程,并画出其图形.解:首先作变量置换u =1x,题目中所给的数据变成如下表所示的10对数据.u i 1 0.5 0.33 0.2 0.1 0.05 0.03 0.02 0.01 0.005 y i10.155.524.082.852.111.621.411.301.211.15然后作相关性检测.经计算得r ≈0.999 8>0.75,从而认为u 与y 之间具有线性相关关系,由公式得a ^≈1.125,b ^≈8.973,所以y ^=1.125+8.973u ,最后回代u =1x ,可得y ^=1.125+8.973x.这就是题目要求的y 对x 的回归方程.回归方程的图形如图所示,它是经过平移的反比例函数图象的一个分支.1.关于回归分析,下列说法错误的是( ) A .回归分析是研究两个具有相关关系的变量的方法 B .散点图中,解释变量在x 轴,预报变量在y 轴C .回归模型中一定存在随机误差D .散点图能明确反映变量间的关系解析:选D.用散点图反映两个变量间的关系时,存在误差. 2.下列关于统计的说法:①将一组数据中的每个数据都加上或减去同一个常数,方差恒不变; ②回归方程y ^=b ^x +a ^必经过点(x ,y ); ③线性回归模型中,随机误差e =y i -y ^i ;④设回归方程为y ^=-5x +3,若变量x 增加1个单位,则y 平均增加5个单位. 其中正确的为________(写出全部正确说法的序号).解析:①正确;②正确;③线性回归模型中,随机误差的估计值应为e ^i =y i -y ^i ,故错误;④若变量x 增加1个单位,则y 平均减少5个单位,故错误. 答案:①②3.某商场经营一批进价是30元/台的小商品,在市场试销中发现,此商品的销售单价x (x 取整数)(元)与日销售量y (台)之间有如下关系:x 35 40 45 50 y56412811(1)画出散点图,并判断y 与x 是否具有线性相关关系;(2)求日销售量y 对销售单价x 的线性回归方程(方程的斜率保留一个有效数字); (3)设经营此商品的日销售利润为P 元,根据(2)写出P 关于x 的函数关系式,并预测当销售单价x 为多少元时,才能获得最大日销售利润.解:(1)散点图如图所示,从图中可以看出这些点大致分布在一条直线附近,因此两个变量具有线性相关关系.(2)因为x -=14×(35+40+45+50)=42.5,(3)依题意有P =(161.5-3x )(x -30) =-3x 2+251.5x -4 845=-3⎝⎛⎭⎪⎫x -251.562+251.5212-4 845. 所以当x =251.56≈42时,P 有最大值,约为426元.故预测当销售单价为42元时,能获得最大日销售利润.知识结构深化拓展线性回归模型的模拟效果(1)残差图法:观察残差图,如果残差点比较均匀地落在水平的带状区域中,说明选用的模型比较合适,这样的带状区域的宽度越窄,说明模型拟合精度越高,回归方程的预报精度越高.(2)残差的平方和法:一般情况下,比较两个模型的残差比较困难(某些样本点上一个模型的残差的绝对值比另一个模型的小,而另一些样本点的情况则相反),故通过比较两个模型的残差的平方和的大小来判断模型的拟合效果.残差平方和越小的模型,拟合的效果越好.(3)R 2法:R 2的值越大,说明残差平方和越小,也就是说模型拟合的效果越好.[注意] r 的绝对值越大说明变量间的相关性越强,通常认为r 的绝对值大于等于0.75时就是有较强的相关性,同样R 2也是如此,R 2越大拟合效果越好.[A 基础达标]1.废品率x %和每吨生铁成本y (元)之间的回归直线方程为y ^=256+3x ,表明( ) A .废品率每增加1%,生铁成本增加259元 B .废品率每增加1%,生铁成本增加3元 C .废品率每增加1%,生铁成本平均每吨增加3元 D .废品率不变,生铁成本为256元解析:选C.回归方程的系数b ^表示x 每增加一个单位,y ^平均增加b ^,当x 为1时,废品率应为1%,故当废品率增加1%时,生铁成本平均每吨增加3元.2.已知某产品连续4个月的广告费用为x i (i =1,2,3,4)千元,销售额为y i (i =1,2,3,4)万元,经过对这些数据的处理,得到如下数据信息:①x 1+x 2+x 3+x 4=18,y 1+y 2+y 3+y 4=14;②广告费用x 和销售额y 之间具有较强的线性相关关系;③回归直线方程y ^=b ^x +a ^中,b ^=0.8(用最小二乘法求得),那么当广告费用为6千元时,可预测销售额约为( )A .3.5万元B .4.7万元C .4.9万元D .6.5万元解析:选B.依题意得x =4.5,y =3.5,由回归直线必过样本点中心得a ^=3.5-0.8×4.5=-0.1,所以回归直线方程为y ^=0.8x -0.1.当x =6时,y ^=0.8×6-0.1=4.7.3.某化工厂为预测某产品的回收率y ,需要研究它和原料有效成分含量之间的相关关系,现取了8对观测值,计算得的线性回归方程是( )A.y ^=11.47+2.62xB.y ^=-11.47+2.62x C.y ^=2.62+11.47x D.y ^=11.47-2.62x 解析:选A.由题中数据得x =6.5,y =28.5,a ^=y -b ^x =28.5-2.62×6.5=11.47,所以y 与x 的线性回归方程是y ^=2.62x +11.47.故选A.4.若某地财政收入x 与支出y 满足线性回归方程y =bx +a +e (单位:亿元),其中b =0.8,a =2,|e |≤0.5.如果今年该地区财政收入10亿元,则年支出预计不会超过( )A .10亿元B .9亿元C .10.5亿元D .9.5 亿元解析:选C.代入数据y =10+e ,因为|e |≤0.5, 所以9.5≤y ≤10.5,故不会超过10.5亿元.5.某种产品的广告费支出x 与销售额y (单位:万元)之间的关系如下表:y 与x 的线性回归方程为y =6.5x +17.5,当广告支出5万元时,随机误差的效应(残差)为________.解析:因为y 与x 的线性回归方程为y ^=6.5x +17.5,当x =5时,y ^=50,当广告支出5万元时,由表格得:y =60,故随机误差的效应(残差)为60-50=10. 答案:106.若一组观测值(x 1,y 1),(x 2,y 2),…,(x n ,y n )之间满足y i =bx i +a +e i (i =1,2,…,n ),且e i 恒为0,则R 2为________.解析:由e i 恒为0,知y i =y ^i ,即y i -y ^i =0, 故R 2=1-∑ni =1 (y i -y ^i )2∑n i =1 (y i -y )2=1-0=1.答案:17.某个服装店经营某种服装,在某周内获纯利y (元)与该周每天销售这种服装件数x 之间的一组数据关系见表:已知∑7i =1x 2i =280,∑7i =1x i y i =3 487. (1)求x ,y ;(2)已知纯利y 与每天销售件数x 线性相关,试求出其回归方程. 解:(1)x =3+4+5+6+7+8+97=6,y =66+69+73+81+89+90+917=5597.(2)因为y 与x 有线性相关关系,所以b ^=∑7i =1x i y i-7x y ∑7i =1x 2i -7x 2=3 487-7×6×5597280-7×36=4.75,a ^=5597-6×4.75=71914≈51.36.故回归方程为y ^=4.75 x +51.36.8.已知某校5个学生的数学和物理成绩如下表:(1)假设在对这5名学生成绩进行统计时,把这5名学生的物理成绩搞乱了,数学成绩没出现问题,问:恰有2名学生的物理成绩是自己的实际分数的概率是多少?(2)通过大量事实证明发现,一个学生的数学成绩和物理成绩具有很强的线性相关关系,在上述表格是正确的前提下,用x 表示数学成绩,用y 表示物理成绩,求y 与x 的回归方程; (3)利用残差分析回归方程的拟合效果,若残差和在(-0.1,0.1)范围内,则称回归方程为“优拟方程”,问:该回归方程是否为“优拟方程”?参考数据和公式:y ^=b ^x +a ^,其中.解:(1)记事件A 为“恰有2名学生的物理成绩是自己的实际成绩”, 则P (A )=2C 25A 55=16.(2)因为x =80+75+70+65+605=70,y =70+66+68+64+625=66,学生的编号i 1 2 3 4 5 数学x i 80 75 70 65 60 物理y i7066686462[B 能力提升]9.假设关于某设备的使用年限x和所支出的维修费用y(万元)有如表的统计资料:使用年限x 2 3 4 5 6 维修费用y 2.2 3.8 5.5 6.5 7.010.(选做题)某地区不同身高的未成年男性的体重平均值如表所示:身高x(cm)60708090100110体重y(kg) 6.137.909.9912.1515.0217.50身高x(cm)120130140150160170体重y(kg)20.9226.8631.1138.8547.2555.05 (1)(2)如果体重超过相同身高男性体重平均值的1.2倍为偏胖,低于0.8倍为偏瘦,那么这个地区一名身高175 cm 、体重82 kg 的在校男生体重是否正常? 解:(1)根据题表中的数据画出散点图如图所示.由图可看出,样本点分布在某条指数函数曲线y =c 1e c 2x的周围, 于是令z =ln y ,得下表:x 60 70 80 90 100 110 z 1.81 2.07 2.30 2.50 2.71 2.86 x 120 130 140 150 160 170 z3.043.293.443.663.864.01作出散点图如图所示:由表中数据可得z 与x 之间的回归直线方程为 z ^=0.662 5+0.020x ,则有y ^=e 0.662 5+0.020x .(2)当x =175时,预报平均体重为y ^=e 0.662 5+0.020×175≈64.23, 因为64.23×1.2≈77.08<82,所以这个男生偏胖.。



35种原点回归模式详解在数据分析与机器学习的领域中,回归分析是一种重要的统计方法,用于研究因变量与自变量之间的关系。
以下是35种常见的回归分析方法,包括线性回归、多项式回归、逻辑回归等。
1.线性回归(Linear Regression):最简单且最常用的回归分析方法,适用于因变量与自变量之间存在线性关系的情况。
2.多项式回归(Polynomial Regression):通过引入多项式函数来扩展线性回归模型,以适应非线性关系。
3.逻辑回归(Logistic Regression):用于二元分类问题的回归分析方法,其因变量是二元的逻辑函数。
4.岭回归(Ridge Regression):通过增加一个正则化项来防止过拟合,有助于提高模型的泛化能力。
5.主成分回归(Principal Component Regression):利用主成分分析降维后进行线性回归,减少数据的复杂性。
6.套索回归(Lasso Regression):通过引入L1正则化,强制某些系数为零,从而实现特征选择。
7.弹性网回归(ElasticNet Regression):结合了L1和L2正则化,以同时实现特征选择和防止过拟合。
8.多任务学习回归(Multi-task Learning Regression):将多个任务共享部分特征,以提高预测性能和泛化能力。
9.时间序列回归(Time Series Regression):专门针对时间序列数据设计的回归模型,考虑了时间依赖性和滞后效应。
10.支持向量回归(Support Vector Regression):利用支持向量机技术构建的回归模型,适用于小样本数据集。
11.K均值聚类回归(K-means Clustering Regression):将聚类算法与回归分析相结合,通过对数据进行聚类后再进行回归预测。
12.高斯过程回归(Gaussian Process Regression):基于高斯过程的非参数贝叶斯方法,适用于解决非线性回归问题。


多项式回归、非线性回归模型关键词:回归方程的统计检验、拟合优度检验、回归方程的显著性检验、F 检验、回归系数的显著性检验、残差分析、一元多项式回归模型、一元非线性回归模型一、回归方程的统计检验 1. 拟合优度检验1. 概念介绍SST 总离差平方和total SSR 回归平方和regression SSE 剩余平方和error∑∑∑∑====--=---=ni i ini i ini i ini i iy yy y y yyy R 121212122)()ˆ()()ˆ(12. 例题1存在四点(-2,-3)、(-1,-1)、(1,2)、(4,3)求拟合直线与决定系数。
2. 回归方程的显著性检验)2/()2/()ˆ()ˆ(1212-=---=∑∑==n SSE SSAn yyy yF ni i i ni i i例6(F 检验)在合金钢强度的例1中,我们已求出了回归方程,这里考虑关于回归方程的显著性检验,经计算有:表5 X 射线照射次数与残留细菌数的方差分析表这里值很小,因此,在显著性水平0.01下回归方程是显著的。
3. 回归系数的显著性检验 4. 残差分析二、一元多项式回归模型模型如以下形式的称为一元多项式回归模型:0111a x a x a x a y n n n n ++++=--例1(多项式回归模型)为了分析X 射线的杀菌作用,用200千伏的X 射线来照射细菌,每次照射6分钟,用平板计数法估计尚存活的细菌数。
照射次数记为t ,照射后的细菌数为y 见表1。
试求:(1)给出y 与t 的二次回归模型。
(2)在同一坐标系内作出原始数据与拟合结果的散点图。
(3)预测16=t 时残留的细菌数。
(4)根据问题的实际意义,你认为选择多项式函数是否合适?表1 X 射线照射次数与残留细菌数程序1 t=1:15;y=[352 211 197 160 142 106 104 60 56 38 36 32 21 19 15]; p=polyfit(t,y,2)%作二次多项式回归 y1=polyval(p,t);%模型估计与作图plot(t,y,'-*',t,y1,'-o');%在同一坐标系中做出两个图形 legend('原始数据','二次函数') xlabel('t(照射次数)')%横坐标名 ylabel('y(残留细菌数)')%纵坐标名 t0=16;yc1=polyconf(p,t0)%预测t0=16时残留的细菌数,方法1 yc2=polyval(p,t0)%预测t0=16时残留的细菌数,方法2 即二次回归模型为:8967.3471394.519897.121+-=t t y图1 原始数据与拟合效果的散点图原始数据与拟合结果的散点图如图所示,从图形可知拟合效果较好。



⾃回归(Autoregressive ,AR )模型⾮⾃回归(Non-autoregressi 。
前⾔回归分析(regression analysis )是确定两种或两种以上变数间相互依赖的定量关系的⼀种统计分析⽅法,运⽤⼗分⼴泛。
回归分析按照涉及的⾃变量的多少,可分为⼀元回归分析和多元回归分析;按照⾃变量和因变量之间的关系类型,可分为线性回归分析和⾮线性回归分析。
回归(regression):Y 变量为连续数值型(continuous numerical variable)。
应⽤现状⽬前主流的神经机器翻译模型为⾃回归模型,每⼀步的译⽂单词的⽣成都依赖于之前的翻译结果,因此模型只能逐词⽣成译⽂,翻译速度较慢。
Gu 等⼈提出的⾮⾃回归神经机器翻译模型(NAT)对⽬标词的⽣成进⾏独⽴的建模,因此能够并⾏解码出整句译⽂,显著地提升了模型的翻译速度。
然⽽,⾮⾃回归模型在翻译质量上与⾃回归模型有较⼤差距,主要表现为模型在长句上的翻译效果较差,译⽂中包含较多的重复词和漏译错误等。
⾮⾃回归(Non-autoregressive ,NAR)模型并⾏⽣成序列的所有标记,与⾃回归(AR)模型相⽐,⽣成速度更快,但代价是准确性较低。
在神经机器翻译(neural machine translation ,NMT)、⾃动语⾳识别(automatic speech recognition ,ASR)和语⾳合成(TTS)等不同的任务中,⼈们提出了包括知识提取和源-⽬标对齐在内的不同技术来弥补AR 和NAR 模型之间的差距。
在这些技术的帮助下,NAR 模型可以在某些任务中赶上AR 模型的准确性,但在其他任务中则不能。
ARAR 模型,即⾃回归(AutoRegressive, AR )模型⼜称为时间序列模型,数学表达式为:y (t )=n∑i =1a i y (t −i )+e (t )此处的n 表⽰n 阶⾃回归。
AR 模型是⼀种线性预测,利⽤前期若⼲时刻的随机变量的线性组合来描述以后某时刻随机变量的线性回归模型。

非线性回归非线性模型非线性函数非线性表达式SPSSAU非线性回归模型如果数学模型为非线性关系,比如人口学增长模型Logistic(S模型),其模式公式为:y = b1 / (1 + exp(b2 + b3 * x)),其中y为人口数量,x为年份(实际数据为第n年,数字从0年起,依次顺序增加),b1,b2和b3分别为三个估计参数,exp为自然指数的意思。
此数学表达式并非线性表达式,因此不能使用SPSSAU的线性回归进行拟合。
诸如此类非线性关系(即不是直接关系)的非线性模型,可使用非线性回归进行研究。
SPSSAU当前提供约50类非线性函数表达式,涵盖绝大多数非线性函数表达式。
如下图:备注:图中出现的b1,b2,b3等代表待估计参数;exp表示自然指数,ln表示自然对数,cos表示余弦函数;“**”表示指数的意思。
进行非线性回归模型构建时,通常分为三步。
第一步:首先需要结合专业知识选择正确的构建模型,比如人口增长预测时使用logistic模型,经济学研究的抛物线二次曲线模型等。
第二步:设置参数初始值;与线性回归不同,非线性回归模型数学原理上使用迭代思想计算参数估计值,因而对初始值的不同设置,很可能会导致不同的结果,因而初始值设置较为重要,其可使用模型求解更为精确,并且有助于模型快速迭代收敛。
关于初始值的设置在案例中有更详细说明。
第三步:模型预测。
在得到参数拟合值后,并且拟合效果在认可范围内时,那么可使用模型进行预测数据,输入X的数据信息,对应得到Y的预测值。
特别提示:关于初始值。
初始值是由研究人员输入的一个‘大概’值,即参数的大概估计值,大概预期的值,与此同时,也可设置参数的范围,即上下界,但通常情况下不设置上下界值,除非认为有必要,通常不需要设置上下界值。
关于初始值的设置方法。
通常包括两种,一是结合专业知识进行判断,二是利用模型公式时的特殊点(比如X=0时,Y=?)去求解得到。
专业知识判断上,某参数的实际意义为数据的最大值,那么就设定该参数为最大值即可。

19种回归分析你知道几种?展开全文只要学习过数据分析,或者对数据分析有一些简单的了解,使用过spssau、spss、stata这些统计分析软件,都知道有回归分析。
按照数学上的定义来看,回归分析指研究一组随机变量(Y1 ,Y2 ,…,Yi)和另一组(X1,X2,…,Xk)变量之间关系的统计分析方法,又称多重回归分析。
通常Y1,Y2,…,Yi是因变量,X1、X2,…,Xk是自变量。
其实说简单点就是研究X对于Y的影响关系,这就是回归分析。
但是,这并不够呢,看下图,总共19种回归(其实还有不单独列出),这如何区分,到底应该使用哪一种回归呢,这19种回归分析有啥区别呢。
为什么会这如此多的回归分析呢?一、首先回答下:为什么会有如此多的回归分析方法?在研究X对于Y的影响时,会区分出很多种情况,比如Y有的是定类数据,Y有的是定量数据(如果不懂,可阅读基础概念),也有可能Y有多个或者1个,同时每种回归分析还有很多前提条件,如果不满足则有对应的其它回归方法进行解决。
这也就解决了为什么会有如此多的回归分析方法。
接下来会逐一说明这19种回归分析方法。
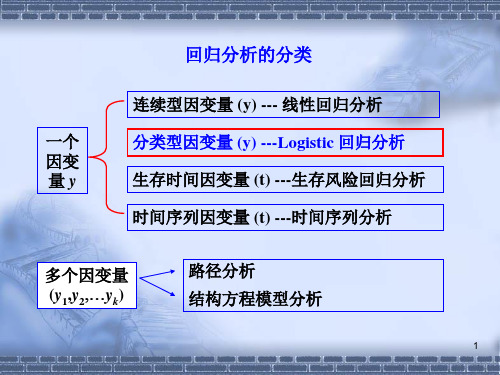
二、回归分析按数据类型分类首先将回归分析中的Y(因变量)进行数据类型区分,如果是定量且1个(比如身高),通常我们会使用线性回归,如果Y为定类且1个(比如是否愿意购买苹果手机),此时叫logistic回归,如果Y为定量且多个,此时应该使用PLS回归(即偏最小二乘回归)。
线性回归再细分:如果回归模型中X仅为1个,此时就称为简单线性回归或者一元线性回归;如果X有多个,此时称为多元线性回归。
Logistic回归再细分:如果Y为两类比如0和1(比如1为愿意和0为不愿意,1为购买和0为不购买),此时就叫二元logistic回归;如果Y为多类比如1,2,3(比如DELL, Thinkpad,Mac),此时就会多分类logistic回归;如果Y为多类且有序比如1,2,3(比如1为不愿意,2为中立,3为愿意),此时可以使用有序logistic回归。





回归模型的演变史回归模型是统计学中的一种重要方法,用于研究变量之间的关系。
它的演变史可以追溯到19世纪初,当时的统计学家们开始尝试用数学方法来描述变量之间的关系。
最早的回归模型是线性回归模型,它最早由法国数学家勒让德提出。
他发现,一些自然现象的变化可以用一条直线来描述,这就是线性回归模型的基本思想。
线性回归模型的公式为y = a + bx,其中y是因变量,x是自变量,a和b是常数。
这个模型可以用来预测因变量y的值,只需要知道自变量x的值即可。
随着统计学的发展,人们发现线性回归模型并不能完全描述变量之间的关系。
于是,他们开始尝试用非线性模型来描述这些关系。
这就是非线性回归模型的诞生。
非线性回归模型的公式为y = f(x),其中f(x)是一个非线性函数。
这个模型可以用来描述因变量y和自变量x之间的复杂关系。
在20世纪60年代,统计学家们开始尝试用多元回归模型来描述多个自变量和一个因变量之间的关系。
多元回归模型的公式为y = a + b1x1 + b2x2 + ... + bnxn,其中x1、x2、...、xn是自变量,b1、b2、...、bn是常数。
这个模型可以用来预测因变量y的值,只需要知道自变量x1、x2、...、xn的值即可。
随着计算机技术的发展,人们开始尝试用机器学习算法来构建回归模型。
这就是机器学习回归模型的诞生。
机器学习回归模型可以自动学习变量之间的关系,从而预测因变量的值。
它可以处理大量的数据,并且可以自动调整模型参数,以提高预测精度。
回归模型是统计学中的一种重要方法,它可以用来描述变量之间的关系,并且可以用来预测因变量的值。
随着时间的推移,回归模型不断演变,从线性回归模型到非线性回归模型,再到多元回归模型和机器学习回归模型。
这些模型的出现,为我们研究变量之间的关系提供了更多的选择。
