Java 转PDF为Word、图片、html、XPS、SVG、PDFA
- 格式:docx
- 大小:17.48 KB
- 文档页数:3

在Java中将链接转换为PDF文件,通常需要使用一些第三方库,如Jsoup 用于抓取网页内容,然后使用iText或PDFBox等库将HTML内容转换为PDF 格式。
以下是一个基本的步骤示例:
1. 添加依赖项:
对于Jsoup:在你的Maven或Gradle构建文件中添加Jsoup依赖。
对于iText或PDFBox:添加相应的PDF生成库依赖。
2. 使用Jsoup抓取网页内容:
java代码:
3. 将HTML内容转换为PDF:
如果使用iText:
java代码:
如果使用PDFBox:
java代码:
注意:上述PDFBox示例中并没有直接将HTML转换为PDF,因为PDFBox 本身并不直接支持HTML到PDF的转换。
你可能需要结合使用Flying Saucer 或Apache FOP等其他库来实现这一功能。
请根据你的具体需求和环境选择合适的库和方法进行链接转PDF的操作。
同时,由于网络抓取和PDF生成可能会涉及到版权和许可问题,确保你在进行此类操作时遵守相关法律法规和网站的使用条款。

使用模板引擎生成pdf的几种方法
使用模板引擎生成PDF有以下几种方法:
1. 使用Java生成PDF:利用Freemarker模板引擎生成HTML,然后使用iText包进行转换,转换过程需要解决中文显示问题,需要在Freemarker模板文件中设置<body style="font-family:SimSun;">以解决该问题。
2. 使用Spring Boot和FreeMarker:通过在applicationproperties 中配置后缀、设置模板文件路径和覆盖默认属性值,可在SpringBoot 中使用FreeMarker生成Web应用。
3. 使用wkhtmltopdf:这是一种高性能的工具,可以将HTML转换为PDF,可以生成美观且实用的界面。
4. 使用SwingUI和JFreePDF:利用SwingUI生成用户界面,再使用JFreePDF将生成的HTML转换为PDF。
虽然这种方法可以生成PDF,但界面样式难看且不兼容太新的js语言。
5. 使用art-template:这是一种新的高性能JavaScript模板引擎,可以将数据与HTML模板更加友好地结合起来,支持服务器端和浏览器端使用,并使用标准语法进行渲染。
需要注意的是,不同的方法可能适用于不同的需求和场景,具体选择哪一种方法需要根据实际情况进行权衡和评估。

JAVA中pdf转图⽚的⼏种⽅法 JAVA中实现pdf转图⽚可以通过第三⽅提供的架包,这⾥介绍⼏种常⽤的,可以根据⾃⾝需求选择使⽤。
⼀、icepdf。
有收费版和开源版,⼏种⽅法⾥最推荐的。
转换的效果⽐较好,能识别我⼿头⽂件中的中⽂,就是转换后可能字体的关系部分字间距有点宽。
因为,字体⽀持是要收费的,所以转换的图⽚会带有官⽅的⽔印。
去⽔印的⽅法可以查看另⼀篇⽂章:1、下载icepdf的架包,并导⼊项⽬中,这⾥⽤到4个,如下:2、附上代码例⼦:1 String filePath = "c:/test.pdf";2 Document document = new Document();3 document.setFile(filePath);4 float scale = 2.5f;//缩放⽐例5 float rotation = 0f;//旋转⾓度67 for (int i = 0; i < document.getNumberOfPages(); i++) {8 BufferedImage image = (BufferedImage)9 document.getPageImage(i, GraphicsRenderingHints.SCREEN, org.icepdf.core.pobjects.Page.BOUNDARY_CROPBOX, rotation, scale);10 RenderedImage rendImage = image;11 try {12 File file = new File("c:/iecPDF_" + i + ".png");13 ImageIO.write(rendImage, "png", file);14 } catch (IOException e) {15 e.printStackTrace();16 }17 image.flush();18 }19 document.dispose(); 例⼦中是pdf转png格式的,也可以将12、13⾏改成jpg,转出jpg格式的,但是从转换效果来看png的清晰度会相对较⾼。

java根据模板⽣成word⽂档,兼容富⽂本、图⽚Java⾃动⽣成带图⽚、富⽂本、表格等的word⽂档使⽤技术 freemark+jsoup ⽣成mht格式的伪word⽂档,已经应⽤项⽬中,确实是可⾏的,⽆论是富⽂本中是图⽚还是表格,都能在word中展现出来使⽤jsoup解析富⽂本框,将其中的图⽚进⾏Base64位转码,使⽤freemark替换模板的占位符,将变量以及图⽚资源放⼊模板中在输出⽂件maven地址<!--freemarker--><!--<dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.23</version></dependency><!--JavaHTMLParser--><!--<dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.2</version></dependency>制作word的freemark模板1. 先将wrod的格式内容定义好,如果需要插⼊参数的地⽅以${xxx}为表⽰,例:${product}模板例⼦: 2. 将模板另存为mht格式的⽂件,打开该⽂件检查每个变量(${product})是否完整,有可能在${}中出现其他代码,需要删除。
3. 将mht⽂件变更⽂件类型,改成ftl为结尾的⽂件,引⼊到项⽬中 4. 修改ftl模板⽂件,在⽂件中加上图⽚资源占位符${imagesBase64String},${imagesXmlHrefString}具体位置如下图所⽰: 5. ftl⽂件中由⼏个关键配置需要引⼊到代码中:docSrcParent = word.filesdocSrcLocationPrex =nextPartId = 01D2C8DD.BC13AF60上⾯三个参数,在模板⽂件中可以找到,需要进⾏配置,如果配置错误,图⽚⽂件将不会显⽰下⾯这三个参数固定,切换模板也不会改变shapeidPrex = _x56fe__x7247__x0020typeid = #_x0000_t75spidPrex = _x0000_i 6. 模板引⼊之后进⾏代码编辑源码地址为:下载源码后需要进⾏调整下内容:1. 录⼊步骤5中的6个参数2. 修改freemark获取模板⽅式下⾯这种⽅式能获取模板,但是在项⽬打包之后⽆法获取jar包内的⽂件Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));Template template=configuration.getTemplate("xxx.ftl");通过流的形式直接创建模板对象Configuration configuration=newConfiguration(Configuration.getVersion());configuration.setDefaultEncoding(StandardCharsets.UTF_8.toString());configuration.setDirectoryForTemplateLoading(newFile(templatePath));InputStream inputStream=newFileInputStream(newFile(templatePath+"/"+templateName)); InputStreamReader inputStreamReader=newInputStreamReader(inputStream,StandardCharsets.UTF_8); Template template=newTemplate(templateName,inputStreamReader,configuration);。

JAVA实现PPT转图⽚、PDF和SVGJava:PPT(X)转图⽚、PDF和SVG⼯作中,PowerPoint⽂档有时需要被转换为PDF/图像⽂件来存档。
下⾯介绍如何在Java 中将PowerPoint⽂档转为图⽚或PDF。
所需⼯具:●Free Spire.Presentation for Java 2.2.3(免费版)●Intellij IDEA导⼊Jar⽂件包:⾸先,在官⽹获取Jar包。
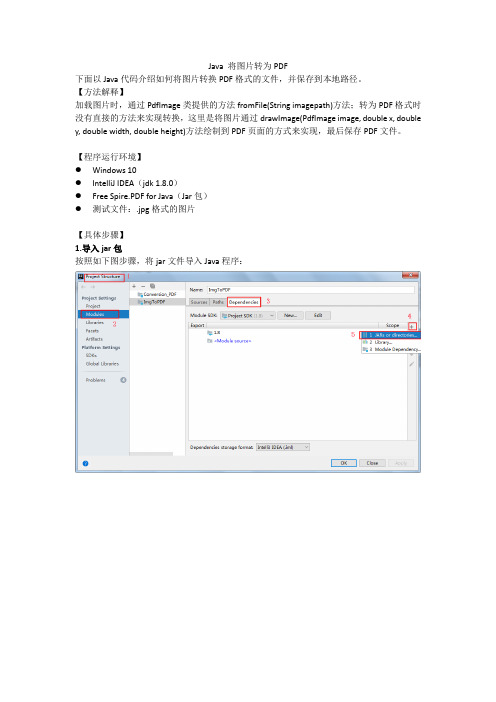
Step 1:下载控件包后解压,进⼊“Project Structure” 界⾯。
(以下是三种在IDEA中快速打开Project Structure界⾯的⽅式,可任意选择⼀种⽅式)Step 2:按以下操作步骤进⾏导⼊。
①选择“Modules”—“Dependencies”,添加外置jar包;②进⼊"Attach File or Directories"界⾯选择jar⽂件路径,然后点击“OK”;③勾选jar路径选项,点击”OK”/”Apply”;④导⼊完成。
如下图:下⾯是PowerPoint源⽂档的截图:JAVA代码⽰例1)PPT(X) 转图⽚定义outputFile⽤于存放⽣成⽂档的⽂件。
使⽤saveAsImage()⽅法将每张幻灯⽚保存为BufferdImage对象,然后将图像数据写⼊⽂件,并保存为PNG格式。
//系统中ppt⽂件位置String inputFile ="C:\\Users\\Administrator\\Desktop\\Presentation.pptx";//输出⽂件的⽂件夹String outputFile="output";//创建⼀个ppt实例Presentation ppt = new Presentation();//加载ppt⽂件ppt.loadFromFile(inputFile);//保存ppt⽂件为图像⽂件for (int i = 0; i < ppt.getSlides().getCount(); i++) {BufferedImage image = ppt.getSlides().get(i).saveAsImage();String fileName = outputFile + "/" + String.format("ToImage-%1$s.png", i);ImageIO.write(image, "PNG",new File(fileName));}转换结果:2 )PPT(X) 转PDF:创建⼀个Presentation类对象来保存要转换的PowerPoint⽂件,然后调⽤相同对象的saveToFile()⽅法将⽂档保存为PDF⽂件。
Java 将图片转为PDF下面以Java代码介绍如何将图片转换PDF格式的文件,并保存到本地路径。
【方法解释】加载图片时,通过PdfImage类提供的方法fromFile(String imagepath)方法;转为PDF格式时没有直接的方法来实现转换,这里是将图片通过drawImage(PdfImage image, double x, double y, double width, double height)方法绘制到PDF页面的方式来实现,最后保存PDF文件。
【程序运行环境】●Windows 10●IntelliJ IDEA(jdk 1.8.0)●Free Spire.PDF for Java(Jar包)●测试文件:.jpg格式的图片【具体步骤】1.导入jar包按照如下图步骤,将jar文件导入Java程序:完成导入后,如下效果:2. Java 代码import com.spire.pdf.*;import com.spire.pdf.graphics.PdfImage;public class ImgToPDF {public static void main(String[] args) {//新建Pdf 文档PdfDocument pdf = new PdfDocument();//添加一页PdfPageBase page = pdf.getPages().add();//加载图片PdfImage image = PdfImage.fromFile("logo.jpg");double widthFitRate = image.getPhysicalDimension().getWidth() / page.getCanvas().getClientSize().getWidth();double heightFitRate = image.getPhysicalDimension().getHeight() / page.getCanvas().getClientSize().getHeight();double fitRate = Math.max(widthFitRate, heightFitRate);//图片大小double fitWidth = image.getPhysicalDimension().getWidth() / fitRate;double fitHeight = image.getPhysicalDimension().getHeight() / fitRate;//绘制图片到PDFpage.getCanvas().drawImage(image, 0, 30, fitWidth, fitHeight);//保存文档pdf.saveToFile("ImgToPDF.pdf");pdf.dispose();}}注:代码中的文件路径为IDEA程序项目文件夹路径,如:F:\IDEAProject\Conversion_PDF\logo.jpg ,文件路径也可以自定义。

java生成word的几种方案1、Jacob是Java-COM Bridge的缩写,它在Java与微软的COM组件之间构建一座桥梁。
使用Jacob自带的DLL动态链接库,并通过JNI的方式实现了在Java平台上对COM程序的调用。
DLL动态链接库的生成需要windows平台的支持。
2、Apache POI包括一系列的API,它们可以操作基于MicroSoft OLE 2 CompoundDocument Format的各种格式文件,可以通过这些API在Java中读写Excel、Word 等文件。
他的excel处理很强大,对于word还局限于读取,目前只能实现一些简单文件的操作,不能设置样式。
3、Java2word是一个在java程序中调用MS Office Word 文档的组件(类库)。
该组件提供了一组简单的接口,以便java程序调用他的服务操作Word 文档。
这些服务包括:打开文档、新建文档、查找文字、替换文字,插入文字、插入图片、插入表格,在书签处插入文字、插入图片、插入表格等。
填充数据到表格中读取表格数据,1.1版增强的功能:指定文本样式,指定表格样式。
如此,则可动态排版word 文档。
4、iText操作Excel还行。
对于复杂的大量的word也是噩梦。
用法很简单, 但是功能很少, 不能设置打印方向等问题。
5、JSP输出样式基本不达标,而且要打印出来就更是惨不忍睹。
6、用XML做就很简单了。
Word从2003开始支持XML格式,大致的思路是先用office2003或者2007编辑好word的样式,然后另存为xml,将xml翻译为FreeMarker模板,最后用java来解析FreeMarker模板并输出Doc。
经测试这样方式生成的word文档完全符合office标准,样式、内容控制非常便利,打印也不会变形,生成的文档和office中编辑文档完全一样。
java生成pdf方案总结1. Jasper Report生成pdf:设计思路是先生成模板,然后得到数据,最后将两者整合得到结果。

Java JODConverter是一个开源的Java库,可以将各种类型的文档转换为PDF格式。
在将Excel 文件转换为PDF时,可以设置一些参数来自定义转换过程。
以下是一些常见的参数:转换模式:JODConverter支持多种转换模式,包括直接转换和模板转换。
直接转换是将原始Excel文件直接转换为PDF,而模板转换则是使用预定义的模板来生成PDF。
页面设置:可以指定PDF文件的页面大小、方向和边距等设置。
字体和样式:可以指定要使用的字体和样式,以及是否要在PDF中保留原始Excel中的格式。
水印和背景:可以添加水印和背景图像到PDF文件中。
安全性:可以设置PDF文件的安全性选项,例如是否允许打印、复制和修改等操作。
输出路径:指定转换后的PDF文件的输出路径。
以下是一个示例代码片段,演示如何使用JODConverter将Excel文件转换为PDF,并设置一些参数:javaimport java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import ermodel.Workbook;import ermodel.XSSFWorkbook;import org.jodconverter.core.document.DocumentStyle;import org.jodconverter.core.document.DocumentStyleSheet;import org.jodconverter.core.document.DocumentTemplate;import org.jodconverter.core.document.DefaultDocumentStyleSheet;import org.jodconverter.core.document.DefaultDocumentTemplate;import org.jodconverter.core.office.OfficeService;import org.jodconverter.core.office.SimpleOfficeService;public class ExcelToPDFConverter {public static void main(String[] args) throws IOException {// Load Excel fileFileInputStream inputStream = new FileInputStream(new File("input.xlsx"));Workbook workbook = new XSSFWorkbook(inputStream);// Create PDF output fileFileOutputStream outputStream = new FileOutputStream(new File("output.pdf"));// Create office service and document style sheetOfficeService officeService = SimpleOfficeService.getInstance();DocumentStyleSheet styleSheet = new DefaultDocumentStyleSheet();// Create document template with custom style and template contentDocumentTemplate template = new DefaultDocumentTemplate(styleSheet);template.addContent("Hello World!"); // Add content to the template// Convert Excel to PDF with custom parametersofficeService.convert(workbook, outputStream, template, null, null); // Set custom parameters here// Close streams and exitoutputStream.close();inputStream.close();}}。

Java:PPT(X)转图片、PDF和SVG工作中,PowerPoint文档有时需要被转换为PDF/图像文件来存档。
下面介绍如何在Java 中将PowerPoint文档转为图片或PDF。
所需工具:●Free Spire.Presentation for Java 2.2.3(免费版)●Intellij IDEA导入Jar文件包:首先,在官网获取Jar包。
Step 1:下载控件包后解压,进入“Project Structure” 界面。
(以下是三种在IDEA中快速打开Project Structure界面的方式,可任意选择一种方式)Step 2:按以下操作步骤进行导入。
①选择“Modules”—“Dependencies”,添加外置jar包;②进入"Attach File or Directories"界面选择jar文件路径,然后点击“OK”;③勾选jar路径选项,点击”OK”/”Apply”;④导入完成。
如下图:下面是PowerPoint源文档的截图:JAVA代码示例1)PPT(X) 转图片定义outputFile用于存放生成文档的文件。
使用saveAsImage()方法将每张幻灯片保存为BufferdImage对象,然后将图像数据写入文件,并保存为PNG格式。
//系统中ppt文件位置String inputFile ="C:\\Users\\Administrator\\Desktop\\Presentation.pptx";//输出文件的文件夹String outputFile="output";//创建一个ppt实例Presentation ppt = new Presentation();//加载ppt文件ppt.loadFromFile(inputFile);//保存ppt文件为图像文件for (int i = 0; i < ppt.getSlides().getCount(); i++) {BufferedImage image = ppt.getSlides().get(i).saveAsImage();String fileName = outputFile + "/" + String.format("ToImage-%1$s.png", i);ImageIO.write(image, "PNG",new File(fileName));}转换结果:2 )PPT(X) 转PDF:创建一个Presentation类对象来保存要转换的PowerPoint文件,然后调用相同对象的saveToFile()方法将文档保存为PDF文件。

JAVA使⽤aspose实现word⽂档转pdf⽂件引⼊jar包下载地址:然后打开下载的⽬录打开cmd执⾏mvn install:install-file -Dfile=aspose-words-15.8.0-jdk16.jar -DgroupId=com.aspose -DartifactId=aspose-words -Dversion=15.8.0 -Dpackaging=jar这是把jar包安装到本地仓库中这样在pom⽂件⾥引⼊<dependency><groupId>com.aspose</groupId><artifactId>aspose-words</artifactId><version>15.8.0</version></dependency>当然也可以直接使⽤jar包然后在项⽬根⽬录中创建⼀个⽂件(SpringBoot项⽬直接在resources下)license.xml<License><Data><Products><Product>Aspose.Total for Java</Product><Product>Aspose.Words for Java</Product></Products><EditionType>Enterprise</EditionType><SubscriptionExpiry>20991231</SubscriptionExpiry><LicenseExpiry>20991231</LicenseExpiry><SerialNumber>8bfe198c-7f0c-4ef8-8ff0-acc3237bf0d7</SerialNumber></Data><Signature>sNLLKGMUdF0r8O1kKilWAGdgfs2BvJb/2Xp8p5iuDVfZXmhppo+d0Ran1P9TKdjV4ABwAgKXxJ3jcQTqE/2IRfqwnPf8itN8aFZlV3TJPYeD3yWE7IT55Gz6EijUpC7aKeoohTb4w2fpox58wWoF3SNp6sK6jDfiAUGEHYJ9pjU= </Signature></License>使⽤⼯具类AsposeUtil.javaimport com.aspose.words.Document;import com.aspose.words.License;import com.aspose.words.SaveFormat;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.InputStream;/*** @author yvioo。

java将html转为word导出(富⽂本内容导出word)业务:将富⽂本内容取出⽣成本地word⽂件参考百度的⽅法word本⾝是可以识别html标签,所以通过poi写⼊html内容即可import com.util.WordUtil;import org.springframework.web.bind.annotation.PostMapping;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;public class SysAnnouncementController {@PostMapping(value = "/exportAccidentExampleWord")public void exportAccidentExampleWord(HttpServletRequest request, HttpServletResponse response) throws Exception {String s = "<p><strong>第⼀⾏要加粗</strong></p>\n" +"<p><em><strong>第⼆⾏要倾斜</strong></em></p>\n" +"<p style=\"text-align: center;\"><em><strong>第三⾏要居中</strong></em></p>";StringBuffer sbf = new StringBuffer();sbf.append("<html " +"xmlns:v=\"urn:schemas-microsoft-com:vml\" xmlns:o=\"urn:schemas-microsoft-com:office:office\" xmlns:w=\"urn:schemas-microsoft-com:office:word\" xmlns:m=\"/office/2004/12/omml\" xmlns=\"http://w ">");//缺失的⾸标签sbf.append("<head>" +"<!--[if gte mso 9]><xml><w:WordDocument><w:View>Print</w:View><w:TrackMoves>false</w:TrackMoves><w:TrackFormatting/><w:ValidateAgainstSchemas/><w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid><w:IgnoreMixedCo "</head>");//将版式从web版式改成页⾯试图sbf.append("<body>");//缺失的⾸标签sbf.append(s);//富⽂本内容sbf.append("</body></html>");//缺失的尾标签try{WordUtil.exportWord(request,response,sbf.toString(),"wordName");}catch (Exception e){System.out.println(e.getMessage());}}}⼯具类import javax.servlet.ServletOutputStream;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import java.io.ByteArrayInputStream;import java.io.OutputStream;public class WordUtil {public static void exportWord(HttpServletRequest request, HttpServletResponse response, String content, String fileName) throws Exception {byte[] b = content.getBytes("GBK"); //这⾥是必须要设置编码的,不然导出中⽂就会乱码。
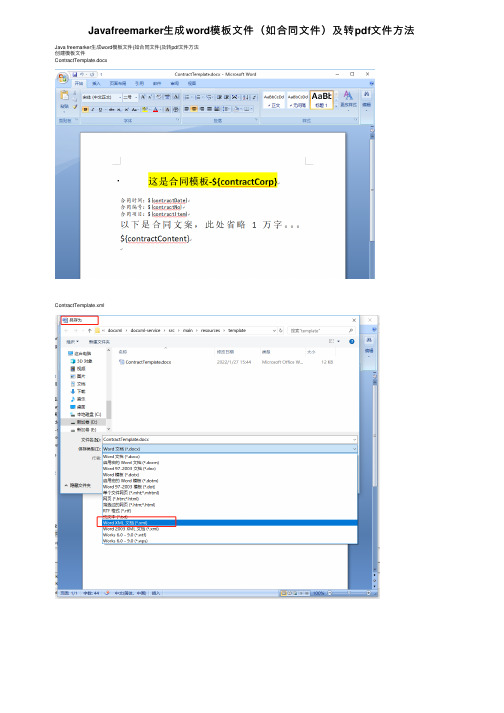
Javafreemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法Java freemarker⽣成word模板⽂件(如合同⽂件)及转pdf⽂件⽅法创建模板⽂件ContractTemplate.docxContractTemplate.xml导⼊的Jar包compile("junit:junit")compile("org.springframework:spring-test")compile("org.springframework.boot:spring-boot-test")testCompile 'org.springframework.boot:spring-boot-starter-test'compile 'org.freemarker:freemarker:2.3.28'compile 'fakepath:aspose-words:19.5jdk'compile 'fakepath:aspose-cells:8.5.2'Java⼯具类 xml⽂档转换 Word XmlToDocx.javapackage com.test.docxml.utils;import java.io.File;import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.InputStream;import java.util.Enumeration;import java.util.zip.ZipEntry;import java.util.zip.ZipFile;import java.util.zip.ZipOutputStream;/*** xml⽂档转换 Word*/public class XmlToDocx {/**** @param documentFile 动态⽣成数据的docunment.xml⽂件* @param docxTemplate docx的模板* @param toFilePath 需要导出的⽂件路径* @throws Exception*/public static void outDocx(File documentFile, String docxTemplate, String toFilePath,String key) throws Exception { try {File docxFile = new File(docxTemplate);ZipFile zipFile = new ZipFile(docxFile);Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();FileOutputStream fileOutputStream = new FileOutputStream(toFilePath);ZipOutputStream zipout = new ZipOutputStream(fileOutputStream);int len = -1;byte[] buffer = new byte[1024];while (zipEntrys.hasMoreElements()) {ZipEntry next = zipEntrys.nextElement();InputStream is = zipFile.getInputStream(next);// 把输⼊流的⽂件传到输出流中如果是word/document.xml由我们输⼊zipout.putNextEntry(new ZipEntry(next.toString()));if ("word/document.xml".equals(next.toString())) {InputStream in = new FileInputStream(documentFile);while ((len = in.read(buffer)) != -1) {zipout.write(buffer, 0, len);}in.close();} else {while ((len = is.read(buffer)) != -1) {zipout.write(buffer, 0, len);}is.close();}}zipout.close();} catch (Exception e) {e.printStackTrace();}}}Java⼯具类 word⽂档转换 PDF WordToPdf.javapackage com.test.docxml.utils;import com.aspose.cells.*;import com.aspose.cells.License;import com.aspose.words.*;import java.io.ByteArrayInputStream;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;/*** word⽂档转换 PDF*/public class WordToPdf {/*** 获取license许可凭证* @return*/private static boolean getLicense() {boolean result = false;try {String licenseStr = "<License>\n"+ " <Data>\n"+ " <Products>\n"+ " <Product>Aspose.Total for Java</Product>\n"+ " <Product>Aspose.Words for Java</Product>\n"+ " </Products>\n"+ " <EditionType>Enterprise</EditionType>\n"+ " <SubscriptionExpiry>20991231</SubscriptionExpiry>\n"+ " <LicenseExpiry>20991231</LicenseExpiry>\n"+ " <SerialNumber>23dcc79f-44ec-4a23-be3a-03c1632404e9</SerialNumber>\n"+ " </Data>\n"+ " <Signature>0nRuwNEddXwLfXB7pw66G71MS93gW8mNzJ7vuh3Sf4VAEOBfpxtHLCotymv1PoeukxYe31K441Ivq0Pkvx1yZZG4O1KCv3Omdbs7uqzUB4xXHlOub4VsTODzDJ5MWHqlRCB1HHcGjlyT2sVGiovLt0Grvqw5+QXBuin + "</License>";InputStream license = new ByteArrayInputStream(licenseStr.getBytes("UTF-8"));License asposeLic = new License();asposeLic.setLicense(license);result = true;} catch (Exception e) {e.printStackTrace();}return result;}/*** word⽂档转换为 PDF* @param inPath 源⽂件* @param outPath ⽬标⽂件*/public static File doc2pdf(String inPath, String outPath) {//验证License,获取许可凭证if (!getLicense()) {return null;}//新建⼀个PDF⽂档File file = new File(outPath);try {//新建⼀个IO输出流FileOutputStream os = new FileOutputStream(file);//获取将要被转化的word⽂档Document doc = new Document(inPath);// 全⾯⽀持DOC, DOCX,OOXML, RTF HTML,OpenDocument,PDF, EPUB, XPS,SWF 相互转换doc.save(os, com.aspose.words.SaveFormat.PDF);os.close();} catch (Exception e) {e.printStackTrace();}return file;}public static void main(String[] args) {doc2pdf("D:/1.doc", "D:/1.pdf");}}Java单元测试类 XmlDocTest.javapackage com.test.docxml;import com.test.docxml.utils.WordToPdf;import com.test.docxml.utils.XmlToDocx;import freemarker.template.Configuration;import freemarker.template.Template;import org.junit.Test;import org.junit.runner.RunWith;import org.springframework.boot.test.context.SpringBootTest;import org.springframework.core.io.ClassPathResource;import org.springframework.core.io.Resource;import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;import org.springframework.test.context.web.WebAppConfiguration;import java.io.File;import java.io.PrintWriter;import java.io.Writer;import java.nio.charset.Charset;import java.util.HashMap;import java.util.Locale;import java.util.Map;/*** 本地单元测试*/@RunWith(SpringJUnit4ClassRunner.class)//@RunWith(SpringRunner.class)@SpringBootTest(classes= TemplateApplication.class)@WebAppConfigurationpublic class XmlDocTest {//短租@Testpublic void testContract() throws Exception{String contractNo = "1255445544";String contractCorp = "银河宇宙⽆敌测试soft";String contractDate = "2022-01-27";String contractItem = "房地产交易中⼼";String contractContent = "稳定发展中的⽂案1万字";//doc xml模板⽂件String docXml = "ContractTemplate.xml"; //使⽤替换内容//xml中间临时⽂件String xmlTemp = "tmp-ContractTemplate.xml";//⽣成⽂件的doc⽂件String toFilePath = contractNo + ".docx";//模板⽂档String docx = "ContractTemplate.docx";//⽣成pdf⽂件String toPdfFilePath = contractNo + ".pdf";;String CONTRACT_ROOT_URL = "/template";Resource contractNormalPath = new ClassPathResource(CONTRACT_ROOT_URL + File.separator + docXml);String docTemplate = contractNormalPath.getURI().getPath().replace(docXml, docx);//设置⽂件编码(注意点1)Writer writer = new PrintWriter(new File(xmlTemp),"UTF-8");Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);configuration.setEncoding(Locale.CHINESE, Charset.forName("UTF-8").name());//设置配置(注意点3)configuration.setDefaultEncoding("UTF-8");String filenametest = contractNormalPath.getURI().getPath().replace(docXml, "");System.out.println("filenametest=" + filenametest);configuration.setDirectoryForTemplateLoading(new File(filenametest));// Template template = configuration.getTemplate(ContractConstants.CONTRACT_NORMAL_URL+orderType+type+".xml"); //设置模板编码(注意点2)Template template = configuration.getTemplate(docXml,"UTF-8"); //绝对地址Map paramsMap = new HashMap();paramsMap.put("contractCorp",contractCorp);paramsMap.put("contractDate",contractDate);paramsMap.put("contractNo",contractNo);paramsMap.put("contractItem",contractItem);paramsMap.put("contractContent",contractContent);template.process(paramsMap, writer);XmlToDocx.outDocx(new File(xmlTemp), docTemplate, toFilePath, null);System.out.println("do finish");//转成pdfWordToPdf.doc2pdf(toFilePath,toPdfFilePath);}}创建成功之后的⽂件如下:。

javaword转pdf的⼏种⽅法最近公司需要以word为模版,填充数据,然后转成pdf。
做了⼀点点研究1.使⽤xdocreport进⾏转(优点效率⾼,缺点对word格式要求较⼤,适合对⽣成pdf要求不⾼的情况)/*** 将word⽂档,转换成pdf* 宋体:STSong-Light** @param fontParam1 可以字体的路径,也可以是itextasian-1.5.2.jar提供的字体,⽐如宋体"STSong-Light"* @param fontParam2 和fontParam2对应,fontParam1为路径时,fontParam2=BaseFont.IDENTITY_H,为itextasian-1.5.2.jar提供的字体时,fontParam2="UniGB-UCS2-H"* @param tmp 源为word⽂档,必须为docx⽂档* @param target ⽬标输出* @throws Exception*/public void wordConverterToPdf(String tmp, String target, String fontParam1, String fontParam2) {InputStream sourceStream = null;OutputStream targetStream = null;XWPFDocument doc = null;try {sourceStream = new FileInputStream(tmp);targetStream = new FileOutputStream(target);doc = new XWPFDocument(sourceStream);PdfOptions options = PdfOptions.create();//中⽂字体处理options.fontProvider(new IFontProvider() {public Font getFont(String familyName, String encoding, float size, int style, Color color) {try {BaseFont bfChinese = BaseFont.createFont(fontParam1, fontParam2, BaseFont.NOT_EMBEDDED);Font fontChinese = new Font(bfChinese, size, style, color);if (familyName != null)fontChinese.setFamily(familyName);return fontChinese;} catch (Exception e) {e.printStackTrace();return null;}}});PdfConverter.getInstance().convert(doc, targetStream, options);File file = new File(tmp);file.delete(); //刪除word⽂件} catch (IOException e) {e.printStackTrace();} finally {IOUtils.closeQuietly(doc);IOUtils.closeQuietly(targetStream);IOUtils.closeQuietly(sourceStream);}}2.使⽤dom4j进⾏转换,试了下效率较低,⽽且转换质量还不如xdoreport,故没有继续。

Java使⽤IText(VM模版)导出PDF,IText导出word(⼆)===============action===========================//退款导出wordpublic void exportWordTk() throws IOException{Long userId=(Long)ServletActionContext.getContext().getSession().get(Constant.SESSION_USER_ID);//获取⽣成Pdf需要的⼀些路径String tmPath=ServletActionContext.getServletContext().getRealPath("download/template");//vm 模板路径String wordPath=ServletActionContext.getServletContext().getRealPath("download/file");//⽣成word路径//wordPath+"/"+userId+"_"+fk+".doc"//数据Map map=new HashMap();//velocity模板中的变量map.put("date1",this.fk);map.put("date",new SimpleDateFormat("yyyy-MM-dd HH:mm").format(new Date()));String newFile=wordPath+"/tk_word_"+userId+".doc";File file=new File(newFile);if(!file.exists()){//设置字体,⽀持中⽂显⽰new PdfUtil().addFontAbsolutePath(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun.ttf"));//这个字体需要⾃⼰去下载PdfUtil.createByVelocityPdf(tmPath,"tk_word.vm", wordPath+"/tk_word_"+userId+".pdf", map);//导出PDFPdfUtil.createByVelocityDoc(tmPath,"tk_word.vm",newFile, map);//导出word}sendMsgAjax("dzz/download/file/tk_word_"+userId+".doc");}=================vm ⽂件模板(tk_word.vm)=====================<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><title></title><style type="text/css">body, button, input, select, textarea {color: color:rgb(0,0,0);font: 14px/1.5 tahoma,arial,宋体,sans-serif;}p{margin:0;padding:0;}.title{border-bottom:1px solid rgb(0,0,0);margin:0;padding:0;width:85%;height:25px;}li{list-style:none;}.li_left li{text-align:left;line-height:47px;font-size:14pt;}.li_left{width:610px;}.fnt-21{font-size:16pt;}table{width:90%;/*argin-left:25px;*/}div_cls{width:100%;text-align:center;}</style></head><body style="font-family: songti;width:100%;text-align:center;"><div style="text-align:center;"><b class="fnt-21"> 本组评审结果清单</b> </div> <table border="1" cellpadding="0" cellspacing="0" style="width:90%;margin-left:25px;"> <tr><td style="width:20%" align="center">申报单位</td><td style="width:10%" align="center">申报经费(万元)</td></tr></table><br/><div><ul style="float:right;margin-right:40px;"><li>$date</li><!--获取后天封装的数据--></ul></div></body></html>====================⼯具类======================package com.qgc.dzz.util;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.io.PrintWriter;import .URL;import java.util.ArrayList;import java.util.List;import java.util.Map;import java.util.UUID;import org.apache.struts2.ServletActionContext;import org.apache.velocity.Template;import org.apache.velocity.VelocityContext;import org.apache.velocity.app.VelocityEngine;import org.xhtmlrenderer.pdf.ITextFontResolver;import org.xhtmlrenderer.pdf.ITextRenderer;import com.lowagie.text.Document;import com.lowagie.text.DocumentException;import com.lowagie.text.Font;import com.lowagie.text.Image;import com.lowagie.text.Rectangle;import com.lowagie.text.pdf.BaseFont;import com.lowagie.text.pdf.PdfImportedPage;import com.lowagie.text.pdf.PdfReader;import com.lowagie.text.pdf.PdfWriter;public class PdfUtil {private static List<String> fonts = new ArrayList();//字体路径/*** 使⽤vm导出word* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param docPath ⽣成⽂件的路径,包含⽂件如:d://temp.doc* @param map 参数,传递到vm* @return*/public static boolean createByVelocityDoc(String localPath, String templateFileName, String docPath, Map<String, Object> map) {try{createFile(localPath,templateFileName,docPath, map);return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 导出pdf* @param localPath VM 模板路径* @param templateFileName vm 模板名称* @param pdfPath ⽣成⽂件的路径,包含⽂件如:d://temp.pdf* @param map 参数,传递到vm* @return*/public static boolean createByVelocityPdf(String localPath, String templateFileName, String pdfPath, Map<String, Object> map) {try{String htmlPath = pdfPath + UUID.randomUUID().toString() + ".html";createFile(localPath, templateFileName, htmlPath, map);//⽣成html 临时⽂件HTML2OPDF(htmlPath, pdfPath, fonts);//html转成pdfFile file = new File(htmlPath);file.delete();return true;} catch (Exception e) {e.printStackTrace();}return false;}/*** 合并PDF* @param writer* @param document* @param reader* @throws DocumentException*/public void addToPdfUtil(PdfWriter writer, Document document,PdfReader reader) throws DocumentException {int n = reader.getNumberOfPages();Rectangle pageSize = document.getPageSize();float docHeight = pageSize.getHeight();float docWidth = pageSize.getWidth();for (int i = 1; i <= n; i++) {document.newPage();PdfImportedPage page = writer.getImportedPage(reader, i);Image image = Image.getInstance(page);float imgHeight = image.getPlainHeight();float imgWidth = image.getPlainWidth();if (imgHeight < imgWidth) {float temp = imgHeight;imgHeight = imgWidth;imgWidth = temp;image.setRotationDegrees(90.0F);}if ((imgHeight > docHeight) || (imgWidth > docWidth)) {float hc = imgHeight / docHeight;float wc = imgWidth / docHeight;float suoScale = 0.0F;if (hc > wc)suoScale = 1.0F / hc * 100.0F;else {suoScale = 1.0F / wc * 100.0F;}image.scalePercent(suoScale);}image.setAbsolutePosition(0.0F, 0.0F);document.add(image);}}/*** html 转成 pdf ⽅法* @param htmlPath html路径* @param pdfPath pdf路径* @param fontPaths 字体路径* @throws Exception*/public static void HTML2OPDF(String htmlPath, String pdfPath,List<String> fontPaths)throws Exception{String url = new File(htmlPath).toURI().toURL().toString();//获取⽣成html的路径OutputStream os = new FileOutputStream(pdfPath);//创建输出流ITextRenderer renderer = new ITextRenderer();//itext 对象ITextFontResolver fontResolver = renderer.getFontResolver();//字体// //⽀持中⽂显⽰字体// fontResolver.addFont(ServletActionContext.getServletContext().getRealPath("dzz/pdfFont/simsun_0.ttf"), // BaseFont.IDENTITY_H, BaseFont.NOT_EMBEDDED);if ((fontPaths != null) && (!fontPaths.isEmpty())) {URL classPath = PdfUtil.class.getResource("/");for (String font : fontPaths) {if (font.contains(":"))fontResolver.addFont(font, "Identity-H", false);else {fontResolver.addFont(classPath + "/" + font, "Identity-H",false);}}}renderer.setDocument(url);//设置html路径yout();renderer.createPDF(os);//html转换成pdfSystem.gc();os.close();System.gc();}public static boolean createFile(String localPath, String templateFileName,String newFilePath, Map<String, Object> map){try{VelocityEngine engine = new VelocityEngine();engine.setProperty("file.resource.loader.path", localPath);//指定vm路径Template template = engine.getTemplate(templateFileName, "UTF-8");//指定vm模板VelocityContext context = new VelocityContext();//创建上下⽂对象if (map != null){Object[] keys = map.keySet().toArray();for (Object key : keys) {String keyStr = key.toString();context.put(keyStr, map.get(keyStr));//传递参数到上下⽂对象}}PrintWriter writer = new PrintWriter(newFilePath, "UTF-8");//写⼊参数到vm template.merge(context, writer);writer.flush();writer.close();return true;} catch (Exception e) {e.printStackTrace();}return false;}public static Font FONT = getChineseFont();public static BaseFont BSAE_FONT = getBaseFont();/*** ⽀持显⽰中⽂* @return*/public static Font getChineseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}Font fontChinese = new Font(bfChinese);return fontChinese;}public static BaseFont getBaseFont() {BaseFont bfChinese = null;try {bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", false);} catch (DocumentException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}return bfChinese;}public void addFontAbsolutePath(String path) {this.fonts.add(path);}public void addFontClassPath(String path) {this.fonts.add(path);}public List<String> getFonts() {return this.fonts;}public void setFonts(List<String> fonts) {this.fonts = fonts;}}。

java获取数据并转换为pdf的方法Java中可以使用第三方库iText来生成PDF文件。
下面是一个简单的示例代码,演示如何使用iText生成PDF文件并将数据写入其中:javaimport java.io.FileOutputStream;import com.itextpdf.text.Document;import com.itextpdf.text.Element;import com.itextpdf.text.Paragraph;import com.itextpdf.text.pdf.PdfWriter;public class PDFGenerator {public static void main(String[] args) throws Exception {// 创建PDF文档Document document = new Document();PdfWriter.getInstance(document, new FileOutputStream("example.pdf"));// 打开文档document.open();// 写入数据Paragraph paragraph = new Paragraph("Hello World!");document.add(paragraph);// 关闭文档document.close();}}在上面的代码中,我们首先创建了一个PDF文档对象,然后使用PdfWriter类将其写入到文件中。
接下来,我们打开文档,创建一个包含文本"Hello World!"的段落,并将其添加到文档中。
最后,我们关闭文档。
执行该程序后,将生成一个名为"example.pdf"的PDF文件,其中包含文本"Hello World!"。
需要注意的是,iText库需要单独下载并添加到Java项目中。

在Java中,有几种方法可以将Excel文件转换为PDF文件。
下面我将介绍两种常用的方法:方法一:使用Apache POI和iText库1. 首先,确保你的项目中已经导入了Apache POI和iText库的相关依赖。
2. 使用Apache POI库读取Excel文件的内容,将其转换为PDF需要的数据。
```java// 导入必要的类import ermodel.*;import ermodel.XSSFWorkbook;// 读取Excel文件Workbook workbook = new XSSFWorkbook(new FileInputStream("path/to/excel.xlsx"));// 获取第一个工作表Sheet sheet = workbook.getSheetAt(0);// 使用StringBuilder保存PDF文件内容StringBuilder pdfContent = new StringBuilder();// 遍历每一行for (Row row : sheet) {// 遍历每一列for (Cell cell : row) {// 获取单元格的值String cellValue = cell.getStringCellValue();// 将值添加到PDF内容中pdfContent.append(cellValue).append(" ");}// 换行pdfContent.append("\n");}// 关闭工作簿workbook.close();```3. 使用iText库将PDF内容写入PDF文件。
```java// 导入必要的类import com.itextpdf.kernel.pdf.PdfDocument;import com.itextpdf.kernel.pdf.PdfWriter;// 创建PDF文档对象PdfWriter writer = new PdfWriter(new FileOutputStream("path/to/pdf.pdf")); PdfDocument pdfDocument = new PdfDocument(writer);// 添加内容到PDFpdfDocument.addNewPage();pdfDocument.getDefaultPageSize().applyMargins(36, 36, 36, 36, false); pdfDocument.add(new Paragraph(pdfContent.toString()));// 关闭PDF文档pdfDocument.close();```方法二:使用第三方库jOfficeConvertjOfficeConvert是一个Java库,可以将多种文件格式转换为PDF,包括Excel文件。

openoffice java 转pdf将OpenOffice与Java结合使用以将文档转换为PDF的过程可以分为几个步骤。
以下是一个基本的指南:1.安装OpenOffice:确保已安装OpenOffice。
可以从OpenOffice官网下载最新版本。
2.配置OpenOffice服务:OpenOffice需要作为一个服务运行,以便从Java程序中访问它。
可以通过命令行启动OpenOffice服务,如下所示:3.bash复制代码path/to/openoffice/program/soffice -headless-accept="socket,host=127.0.0.1,port=8100;urp;"这将启动OpenOffice作为服务,并监听端口8100。
3. 使用Java代码连接OpenOffice:接下来,您需要使用Java代码连接到OpenOffice服务。
这可以通过Socket连接完成。
以下是一个示例代码片段:java复制代码import java.io.File;import java.io.IOException;import .Socket;import java.util.logging.Logger;public class OpenOfficeConnection {private static final Logger LOGGER =Logger.getLogger(OpenOfficeConnection.class.getName());private static final String HOST = "127.0.0.1";private static final int PORT = 8100;private Socket connection;private StringBuilder response = new StringBuilder();public OpenOfficeConnection() throws IOException {connection = new Socket(HOST, PORT);}public void executeCommand(String command) {// Send command to OpenOffice and read response}}4.执行转换命令:一旦连接到OpenOffice服务,就可以发送命令来执行文档转换。

java生成复杂pdf的方法摘要:1.Java 生成复杂PDF 的方法1.1.Java 的优势1.2.生成复杂PDF 的方法1.2.1.使用iText 库1.2.2.使用Apache PDFBox 库1.2.3.使用Java 内置的PDF 支持1.3.选择合适的库1.4.总结正文:Java 作为一种广泛应用的编程语言,具有跨平台、可移植性强等优势。
在生成复杂PDF 方面,Java 同样具有很好的表现。
本文将介绍几种Java 生成复杂PDF 的方法。
首先,Java 的优势在于其跨平台性,这意味着在编写代码时,可以忽略底层操作系统和硬件的差异,从而更专注于业务逻辑。
此外,Java 有着丰富的开源库,可以帮助开发者轻松实现各种功能。
在生成复杂PDF 方面,Java 有多种方法可供选择。
其中,使用iText 库、Apache PDFBox 库以及Java 内置的PDF 支持是最常见的几种方式。
iText 库是一个功能强大的Java PDF 库,可以轻松地创建、编辑和处理PDF 文件。
它提供了丰富的API,支持各种PDF 对象的创建和操作。
使用iText 库,可以方便地实现复杂PDF 的生成,例如添加图片、表格、超链接等。
同时,iText 库还支持将PDF 文件转换为其他格式,如HTML、XML 等。
Apache PDFBox 库是另一个常用的Java PDF 库,它提供了一组工具,用于处理PDF 文档。
与iText 库相比,PDFBox 库更注重底层操作,可以实现对PDF 文件的无缝解析。
通过PDFBox 库,可以提取PDF 文件中的文本、图片等元素,并对其进行操作。
这使得Apache PDFBox 库在处理复杂PDF 时具有较高的灵活性。
此外,Java 内置的PDF 支持也是一个值得关注的领域。
随着Java 7 的发布,Java 引入了PDF 支持,使得开发者可以直接在Java 代码中处理PDF 文件。

java libreoffice转pdf对于很多工作者和学生而言,在日常学习、工作和生活中都需要经常使用到PDF格式文件,并且很多时候我们需要将一些文档、博客文章等内容转换为PDF格式方便管理和浏览。
而对于比较熟悉Java编程的开发者,那么使用Java进行LibreOffice转PDF是一个非常不错的选择。
下面就来一步步讲解下如何使用Java转换LibreOffice转换PDF。
第一步,请确保你已经在电脑上安装好了LibreOffice,如果没有安装的话可以在官方网站上去下载并安装,安装好后在终端窗口中输入以下命令运行LibreOffice进程:libreoffice --headless --writer, 运行成功会显示一个特殊的端口号。
第二步,在Java程序中使用jodConverter进行相关转换操作。
jodconverter是轻量级库,它具有与LibreOffice交互并生成PDFs的能力。
第三步,定义一些输出的参数,比如输出文件存储的路径、名称等,然后将这些参数传递给jodConverter并绑定到指定的转换操作中,这样jodConverter就会根据传递的参数进行LibreOffice转换PDF操作。
代码如下:```File inputFile = new File("document.doc");File outputFile = new File("document.pdf");// Create OfficeDocumentConverter object and set its propertiesLocalOfficeManager officeManager =LocalOfficeManager.builder().officeHome("/opt/libreoffice5.2").portNumber(8100).build();officeManager.start();OfficeDocumentConverter converter = new OfficeDocumentConverter(officeManager);// Perform conversionconverter.convert(inputFile, outputFile);```代码中的``/opt/libreoffice5.2``是LibreOffice的安装路径,而``8100``是LibreOffice的进程端口号。
Java 将PDF 转为Word、图片、SVG、XPS、Html、PDF/A
本文将介绍通过Java编程来实现PDF文档转换的方法。
包括:
PDF转为Word
PDF转为图片
PDF转为Html
PDF转为SVG
将PDF每一页转为单个的SVG
将一个包含多页的PDF文档转为一个SVG
PDF转为XPS
PDF转为PDF/A
使用工具:Free Spire.PDF for Java(免费版)
Jar文件获取及导入:
方法1:通过官网下载jar文件包。
下载后,解压文件,并将lib文件夹下的Spire.Pdf.jar文件导入Java程序。
方法2:可通过maven仓库安装导入。
参考导入方法。
Java代码示例
【示例1】PDF 转Word
PdfDocument pdf = new PdfDocument("test.pdf");
pdf.saveToFile("ToWord.docx",FileFormat.DOCX);
【示例2】PDF转图片
支持的图片格式包括Jpeg, Jpg, Png, Bmp, Tiff, Gif, EMF等。
这里以保存为Png格式为例。
import com.spire.pdf.*;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
public class PDFtoimage {
public static void main(String[] args) throws IOException {
PdfDocument pdf = new PdfDocument("test.pdf");
BufferedImage image;
for(int i = 0; i< pdf.getPages().getCount();i++){
image = pdf.saveAsImage(i);
File file = new File( String.format("ToImage-img-%d.png", i)); ImageIO.write(image, "PNG", file);
}
pdf.close();
}
}
【示例3】PDF转Html
PdfDocument pdf = new PdfDocument("test.pdf");
pdf.saveToFile("ToHTML.html", FileFormat.HTML);
【示例4】PDF转SVG
1.转为单个svg
PdfDocument pdf = new PdfDocument("test.pdf");
pdf.saveToFile("ToSVG.svg", FileFormat.SVG);
2.多页pdf转为一个svg
PdfDocument pdf = new PdfDocument("sampe.pdf");
pdf.getConvertOptions().setOutputToOneSvg(true);
pdf.saveToFile("ToOneSvg.svg",FileFormat.SVG);
【示例5】PDF 转XPS
PdfDocument pdf = new PdfDocument("test.pdf");
pdf.saveToFile("ToXPS.xps", FileFormat.XPS);
【示例6】PDF转PDF/A
import com.spire.pdf.*;
import com.spire.pdf.graphics.PdfMargins;
import java.awt.geom.Dimension2D;
public class PDFtoPDFA {
public static void main(String[]args){
//加载测试文档
PdfDocument pdf = new PdfDocument();
pdf.loadFromFile("test.pdf");
//转换为Pdf_A_1_B格式
PdfNewDocument newDoc = new PdfNewDocument();
newDoc.setConformance(PdfConformanceLevel.Pdf_A_1_B);
PdfPageBase page;
for ( int i=0;i< pdf.getPages().getCount();i++) {
page = pdf.getPages().get(i);
Dimension2D size = page.getSize();
PdfPageBase p = newDoc.getPages().add(size, new PdfMargins(0)); page.createTemplate().draw(p, 0, 0);
}
//保存结果文件
newDoc.save("ToPDFA.pdf");
newDoc.close();
}
}
(本文完)。