模糊聚类分析步骤
- 格式:docx
- 大小:318.91 KB
- 文档页数:13

模糊聚类分析是一种数学方法,它使用模糊数学语言根据某些要求对事物进行描述和分类。
模糊聚类分析通常是指根据研究对象的属性构造模糊矩阵,并在此基础上根据一定隶属度确定聚类关系,即样本之间的模糊关系由样本的数量来确定。
模糊数学方法,以客观,准确地聚类。
聚类是将数据集划分为多个类或群集,以便每个类之间的数据差异应尽可能大,并且该类内的数据差异应尽可能小基本覆盖当涉及事物之间的模糊边界时,模糊聚类分析是一种根据某些要求对事物进行分类的数学方法。
聚类分析是数学统计中的一种多元分析方法是利用数学方法定量确定样品之间的关系,从而客观地分类类型。
事物之间的某些界限是精确的,而其他界限则是模糊的。
人群中人脸的相似度之间的界限是模糊的,多云和晴天之间的界限也是模糊的。
当聚类涉及事物之间的模糊界限时,应使用模糊聚类分析方法。
模糊聚类分析广泛应用于气象预报,地质,农业,林业等领域。
通常,聚类的事物称为样本,一组事物称为样本集。
模糊聚类分析有两种基本方法:系统聚类和逐步聚类。
基本方法基本流程(1)通过计算样本或变量之间的相似系数,建立模糊相似矩阵;(2)通过对模糊矩阵进行一系列综合变换,生成模糊等效矩阵。
(3)最后,根据不同的截获水平λ对模糊等效矩阵进行分类系统聚类方法系统聚类方法是一种基于模糊等价关系的模糊聚类分析方法。
在经典聚类分析方法中,经典等价关系可用于对样本集X进行聚类。
令R为X上的经典等价关系。
对于X中的两个元素x和Y,如果XRY或(x,y)∈R ,然后x和y,否则X和y不属于同一类。
[3]使用这种方法,分类的结果与α的值有关。
α的值越大,划分的类别越多。
当α小于某个值时,X中的所有样本将被归为一类。
该方法的优点是可以根据实际需要选择α值,以获得正确的分类。
系统聚类的步骤如下:①用数字描述样品的特性。
设要聚类的样本为x = {x1,xn}。
每个样本具有p个特征,记录为Xi =(Xi1,xip);i = 1,2,…,N;XIP是描述样本Xi的第p个特征的编号。


模糊聚类分析方法聚类分析是将事物根据一定的特征,并按某种特定要求或规律分类的方法。
由于聚类分析的对象必定是尚未分类的群体,而且现实的分类问题往往带有模糊性,对带有模糊特征的事物进行聚类分析,分类过程中不是仅仅考虑事物之间有无关系,而是考虑事物之间关系的深浅程度,显然用模糊数学的方法处理更为自然,因此称为模糊聚类分析。
一、模糊聚类分析的一般步骤1、第一步:数据标准化[9](1) 数据矩阵设论域12{,,,}n U x x x = 为被分类对象,每个对象又有m 个指标表示其性状,即12{,,,}i i i im x x x x = (1,2,,i n = , 于是,得到原始数据矩阵为111212122212m m n n nm x x xx x x x x x ⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭。
其中nm x 表示第n 个分类对象的第m 个指标的原始数据。
(2) 数据标准化在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行比较,通常需要对数据做适当的变换。
但是,即使这样,得到的数据也不一定在区间[0,1]上。
因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据压缩到区间[0,1]上。
通常有以下几种变换: ① 平移·标准差变换i k kikk x x x s -'= (1,2,,;1,2,i n k m ==其中 11nk i k i x x n==∑,k s =经过变换后,每个变量的均值为0,标准差为1,且消除了量纲的影响。
但是,再用得到的ikx '还不一定在区间[0,1]上。
② 平移·极差变换111m i n {}m a x {}m i n {}i k i ki nikikiki ni nx x x x x ≤≤≤≤≤≤''-''=''-,(1,2,,)k m =显然有01ikx ''≤≤,而且也消除了量纲的影响。
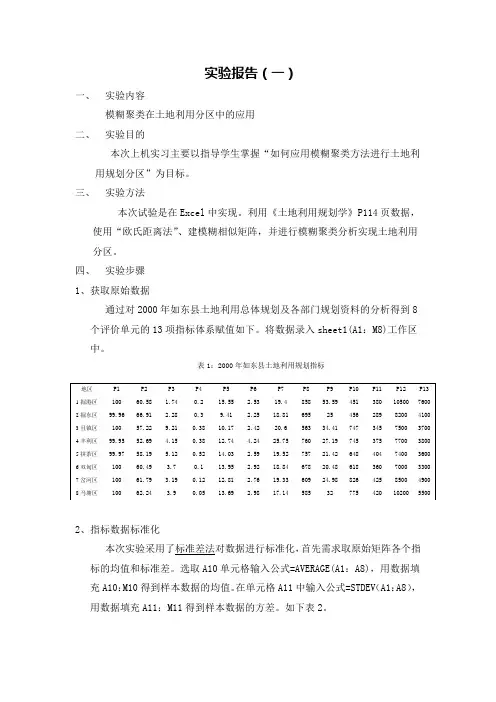
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。

模糊聚类分析壹、何谓聚类分析聚类分析是研究事物分类的一种多元分析方法。
在日常生活中,我们时常要把所接触到的事物(样本),按其性质、用途等进行分类,这种分类过程我们称为聚类分析。
(阙颂廉,民83)贰、聚类分析的应用模糊聚类分析是当前在模糊数学中应用最多的几个方法之一,可以将研究的样本进行合理的分类,如产品的分类就常常用聚类分析来进行,另聚类分析也可用来进行判别分析和预测(林杰斌等。
民76)。
所以,也被广泛地应用于天气预报、地震预测、地质探勘、运动员心理素质分类、河川水质污染程度等方面。
参、普通的等价关系在谈聚类分析之前,应先介绍相似关系和等价关系:一.自反性对任意Uu∈,都有Ru,u(∈,即集合中任一个元素u都)与自身有某相同性质的关系,则称R是自反关系,相对应的矩阵称为自反矩阵。
另数学表示意义为:A中的元素关于R具有”自反性”,即。
例:若U 为同一种族的集合,而集合中每一个人u ,皆与自身有同一种族之关系,这种性质则称为自反性。
二. 对称性如果ji ,R )u ,u (,R )u ,u(i j j i≠∈∈必有。
即u i 与u j 有存在某种关系,若将两个元素之位置对调,则即u j 与u i 也必有符合这层关系,则称R 有对称关系,相对应的矩阵为对称矩阵。
另数学表示意义为:A 中的元素关于R 具有”对称性”,即yRx xRy ,A y ,x 且若∈∀。
例:若甲和乙是同学关系,则乙和甲必也是同学关系,这种关系则称为对称性。
三. 传递性如果能由R)w u (R )w v (R )v u (∈∈∈,,推導出,及,。
即u与v 有存在某一关系,而v 与w 也有这同一种关系存在,则即u 与w 也必有符合这层关系存在,则称R 有传递关系,相对应的矩阵为传递矩阵。
另数学表示意义为:A 中的元素关于R 具有”传递性”,即。
例:若甲和乙是同一种族关系,而乙和丙也是同一种族关系,则甲和丙必有同一种族关系,这种则称为具有传递性关系。


模糊聚类分析定义:根据具体的标准和性质对事物进行分类的方法称为聚类分析 根据模糊标准对事物进行分类的方法称为模糊聚类分析基本思想:根据分类对象之间的模糊相似程度来衡量相互的异同程度,进而实现模糊分类。
传统聚类分析VS 模糊聚类分析1. 传统聚类分析: 设有n 个对象12,,...nx x x,每个对象有m 种特性12,,...my y y。
1>首先对每个对象的特性进行数量化:用ijz代表第i 个对象的第j 个性质的数值。
则对象ix 的性质形成的一个向量()12,,...i i im z zz2>考察对象之间相近的程度:引入“欧式距离”和“夹角余弦”。
1欧式距离:设对象()()1212,,...,,,....i i im j j jm ijy x z zz z zz ==则欧式距离为:ijyx -=这与我们所熟知的向量的欧式距离是一样的!2夹角余弦:设α是对象ix和jy之间的夹角,0180α≤≤,则夹角余弦为:(),cos ijijy x yx α=其中:()11,...i j im jm ijy x z zz z =++ix=iy=有了这些基础认识之后,下面我们通过一个例子来说明传统聚类分析 设有5个对象125,,...x x x,不妨设每个对象只有一个性质,数量化后分别为1,2,4.5,6,8.现使用传统聚类法进行聚类。
1 欧式距离:5个对象,共有25c个欧式距离。
计算可得121x x-=133.5x x-= 145x x-= 157x x-= 232.5x x-= 244x x -= 256x x-=341.5x x-=35 3.5x x-=452x x-=根据聚类的思想,差异最小的对象属于一类 从而1x 和2x为一类,并记为1G2 将1G 看成新的对象,其特征值为1x 和2x 的平均值1.5。
此时对象为1345,,,G x x x 。
再次计算欧式距离。
可知34,x x之间的距离最小。

模糊聚类流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by the editor. I hope that after you download them, they can help yousolve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, our shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts,other materials and so on, want to know different data formats and writing methods, please pay attention!模糊聚类流程是一种用于处理具有模糊性质的数据的聚类方法,它能够有效地识别出不同数据之间的模糊关系,从而实现数据的分组和分类。

模糊聚类分析方法
分类伴随着模糊性,将模糊数学中的有关概念与方法引进聚类分析,通过建立模糊相似关系,进而对客观事物进行分类。
(1)原始数据标准化
要构造模糊关系矩阵,必须对样本进行数据进行预处理,使样本数据压缩到[0,1]闭区间内,首先求出n个样本的第j个指标的平均值和标准差。
原始数据标准化值为
运用极值标准化公式,将标准化数据压缩到[0,1]闭区间内
其中与分别表示中最小值和最大值。
(2)相似系数法——标定
为了建立模糊相似矩阵,引入相似系数
这里表示两个样本与之间相似程度的变量,当接近于1,表明这两个样本越接近。
的确定方法:
相关系数法:
归一化互信息
表示样本的表达数据在个不同表达水平的发生率(概率)
距离法:欧氏距离
C选取适当的正数,使在[0,1]区间内
(3)模糊相似矩阵——聚类
通过上述标定,得到模糊相似矩阵,反映了样本间的相似关系,但它只具有自反性和对
称性,不具有传递性,此时,可以通过平方法得到的传递闭包,而就是论域上
的一个模糊等价矩阵,选择不同的值,得到不同的水平截集,得到动态聚类结果,生成动态聚类树。

模糊聚类方法模糊聚类是一种基于模糊集合理论的聚类算法,它在数据分析和模式识别中得到广泛应用。
与传统的硬聚类方法相比,模糊聚类能够更好地处理数据中的不确定性和模糊性,能够给出每个数据点属于不同聚类的概率,从而更全面地描述数据的特征。
一、模糊聚类的基本原理模糊聚类的基本原理是根据数据点之间的相似性将它们分成不同的聚类。
与传统的硬聚类方法不同,模糊聚类允许数据点属于多个聚类,且给出每个数据点属于不同聚类的权重。
通过引入隶属度函数,模糊聚类能够更好地处理数据的模糊性,给出更丰富的聚类结果。
二、模糊聚类的算法步骤模糊聚类的算法步骤一般包括以下几个方面:1. 初始化隶属度矩阵:隶属度矩阵用于描述每个数据点属于每个聚类的概率,一般通过随机初始化或者根据先验信息进行初始化。
2. 计算聚类中心:根据隶属度矩阵计算每个聚类的中心点,一般采用加权平均的方式计算。
3. 更新隶属度矩阵:根据当前的聚类中心,更新隶属度矩阵,使得每个数据点更准确地属于不同聚类。
4. 判断停止条件:根据一定的准则(如隶属度矩阵的变化程度或者目标函数的收敛性)判断是否达到停止条件,如果未达到,则返回第2步继续迭代。
5. 输出聚类结果:根据最终的隶属度矩阵,确定每个数据点最可能属于的聚类,输出聚类结果。
三、模糊聚类的优势相比传统的硬聚类方法,模糊聚类具有以下优势:1. 能够更好地处理数据的模糊性和不确定性。
在现实世界的数据中,往往存在一些边界模糊或者属于多个类别的情况,传统的硬聚类无法很好地处理这种情况,而模糊聚类能够给出每个数据点属于不同聚类的概率。
2. 能够更全面地描述数据的特征。
传统的硬聚类方法只能将数据点划分为一个聚类,而模糊聚类能够给出每个数据点属于不同聚类的权重,从而更全面地描述数据的特征。
3. 能够适应不同的聚类形状和大小。
传统的硬聚类方法通常假设聚类的形状是凸的,并且假设聚类的大小相等,但在实际应用中,聚类的形状和大小往往是不确定的,而模糊聚类能够更好地适应不同的聚类形状和大小。

模糊c均值聚类算法
模糊c均值聚类算法(Fuzzy C-Means Algorithm,简称FCM)是一种基于模糊集理论的聚类分析算法,它是由Dubes 和Jain于1973年提出的,也是用于聚类数据最常用的算法之
一。
fcm算法假设数据点属于某个聚类的程度是一个模糊
的值而不是一个确定的值。
模糊C均值聚类算法的基本原理是:将数据划分为k个
类别,每个类别有c个聚类中心,每个类别的聚类中心的模糊程度由模糊矩阵描述。
模糊矩阵是每个样本点与每个聚类中心的距离的倒数,它描述了每个样本点属于每个聚类中心的程度。
模糊C均值聚类算法的步骤如下:
1、初始化模糊矩阵U,其中每一行表示一个样本点,每
一列表示一个聚类中心,每一行的每一列的值表示该样本点属于该聚类中心的程度,U的每一行的和为
1.
2、计算聚类中心。
对每一个聚类中心,根据模糊矩阵U
计算它的坐标,即每一维特征值的均值。
3、更新模糊矩阵U。
根据每一个样本点与该聚类中心的距离,计算每一行的每一列的值,其中值越大,说明该样本点属于该聚类中心的程度就越大。
4、重复步骤2和步骤
3,直到模糊矩阵U不再变化,即收敛为最优解。
模糊C均值聚类算法的优点在于它可以在每一个样本点属于每一类的程度上,提供详细的信息,并且能够处理噪声数据,因此在聚类分析中应用十分广泛。
然而,其缺点在于计算量较大,而且它对初始聚类中心的选取非常敏感。
模糊数学方法及其应用论文题目:模糊聚类方法案例分析小组成员:王季光宋申辉兰洁陈倩芸肖仑杨洋吴云峰2013年10 月27 日模糊聚类分析方法1.1距离和相似系数为了将样品(或指标)进行分类,就需要研究样品之间关系。
目前用得最多的方法有两个:一种方法是用相似系数,性质越接近的样品,它们的相似系数的绝对值越接近1,而彼此无关的样品,它们的相似系数的绝对值越接近于零。
比较相似的样品归为一类,不怎么相似的样品归为不同的类。
另一种方法是将一个样品看作P 维空间的一个点,并在空间定义距离,距离越近的点归为一类,距离较远的点归为不同的类。
但相似系数和距离有各种各样的定义,而这些定义与变量的类型关系极大,因此先介绍变量的类型。
由于实际问题中,遇到的指标有的是定量的(如长度、重量等),有的是定性的(如性别、职业等),因此将变量(指标)的类型按以下三种尺度划分: 间隔尺度:变量是用连续的量来表示的,如长度、重量、压力、速度等等。
在间隔尺度中,如果存在绝对零点,又称比例尺度,本书并不严格区分比例尺度和间隔尺度。
有序尺度:变量度量时没有明确的数量表示,而是划分一些等级,等级之间有次序关系,如某产品分上、中、下三等,此三等有次序关系,但没有数量表示。
名义尺度:变量度量时、既没有数量表示,也没有次序关系,如某物体有红、黄、白三种颜色,又如医学化验中的阴性与阳性,市场供求中的“产”和“销”等。
不同类型的变量,在定义距离和相似系数时,其方法有很大差异,使用时必须注意。
研究比较多的是间隔尺度,因此本章主要给出间隔尺度的距离和相似系数的定义。
设有n 个样品,每个样品测得p 项指标(变量),原始资料阵为px x x np n n p p nx x x x x x x x x X X X X 2122221112112121 ⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎣⎡=其中(1,,;1,,)ij x i n j p ==为第i 个样品的第j 个指标的观测数据。
如何在Matlab中进行模糊聚类分析在数据分析领域,模糊聚类分析是一种常用的技术,它可以应用于各种领域的数据处理和模式识别问题。
而Matlab作为一种功能强大的数据分析工具,也提供了丰富的函数和工具箱,以支持模糊聚类分析的实施。
1. 引言模糊聚类分析是一种基于模糊集理论的聚类方法,与传统的硬聚类方法不同,它允许样本属于多个聚类中心。
这种方法的优势在于可以更好地应对数据中的不确定性和复杂性,对于某些模糊或模糊边界问题具有更好的解释能力。
2. 模糊聚类算法概述Matlab提供了多种模糊聚类算法的实现,其中最常用的是基于模糊C均值(Fuzzy C-Means,FCM)算法。
FCM算法的基本思想是通过最小化聚类后的模糊划分矩阵与原始数据之间的距离来确定每个样本所属的聚类中心。
3. 数据预处理与特征提取在进行模糊聚类分析之前,需要对原始数据进行预处理和特征提取。
预处理包括数据清洗、缺失值处理和异常值处理等;特征提取则是从原始数据中抽取出具有代表性和区分性的特征,用于模糊聚类分析。
4. 模糊聚类分析步骤在Matlab中,进行模糊聚类分析通常包括以下步骤:(1) 初始化聚类中心:通过随机选择或基于某种准则的方法初始化聚类中心。
(2) 计算模糊划分矩阵:根据当前的聚类中心,计算每个样本属于各个聚类中心的隶属度。
(3) 更新聚类中心:根据当前的模糊划分矩阵,更新聚类中心的位置。
(4) 判断终止条件:通过设置一定的终止条件,判断是否达到停止迭代的条件。
(5) 输出最终结果:得到最终的聚类结果和每个样本所属的隶属度。
5. 模糊聚类结果评估在进行模糊聚类分析后,需要对聚类结果进行评估以验证其有效性和可解释性。
常用的评估指标包括模糊划分矩阵的聚类有效性指标、外部指标和内部指标等。
通过这些指标的比较和分析,可以选择合适的模糊聚类算法和参数设置。
6. 模糊聚类的应用模糊聚类分析在诸多领域中都有广泛的应用。
例如,在图像处理中,可以利用模糊聚类方法对图像进行分割和识别;在生物信息学中,可以应用于基因表达数据的分类和模式识别等。
模糊聚类分析及matlab 程序实现采用模糊数学语言对按一定的要求进行描述和分类的数学方法称为模糊聚类分析。
聚类分析主要经过标定和聚类两步骤。
【1】 1 标定(建立模糊相似矩阵)城市居民食品零售价格,第t 时刻第i 种食品的零售价记为),(t i x 。
相似矩阵R 的构建方法:NTV 法设时间序列),(j i A 表示食品i 在时间t 的价格,其中i=1,2…42;t=1,2…39。
∑∑==--=mk jk ik m k jk ik x xx x j i R 11),max (1),((其中i,j,k=1,2…42,m=39) 42*42),(j i R R = 2 聚类2.1 计算R 的传递闭包:对模糊相似矩阵R,依次用平方法计算,2R ,4R ,…,t2R ,…,当第一次出现k k k R R R =*时,则称k R 为传递闭包。
【1】2.2 开始聚类:【2】 (1)令T={1,2,3…42},取)1(xi T ∈ ,令X 、Q 为空集;(2)令0=j ;(3)若λ>=),(j xi R 且X x j ∉,则令}{j X X ⋃=,}{j Q Q ⋃=;(4)1+=j j ;(5)若n j <,返回(1);(6)若Q 为空集,怎输出聚类x,X -T T =;(7))1(xi Q =,}{xi Q Q -=,返回(2)。
设置不同的置信水平λ值,就可以得到不同的分类。
Matlab 程序实现:A=data;[N M] = size(A);for i = 1:Nfor j = 1:NR(i,j)=abs(1-sum(abs(A(i,:)-A(j,:)))/sum(max([A(i,:);A(j,:)])));endendfor j=1:42for i=1:42y(i,j)=0;for k=1:42mn(k)=min(R(i,k),R(k,j));endy(i,j)=max(mn);endendnumda=[1 0.9 0.95 0.85 0.8 0.75 0.55 0.7 0.655 0.65 0.6 0.55 0.5 0.45 0.454 0.4 0.45 0.3 0.35 0.255 0.25 0.2 0.15 0.1];for i=1:42TT(i)=i;endfor i=1:length(numda)disp ('当分类系数是');disp(numda(i));a=numda(i);T=TT;disp ('分类为');while 1if ~isempty(T)xi=T(1);endX=[];Q=[];while 1for j=1:42if (y(xi,j)>=a)&isempty(intersect(X,j))X=union(X,j);Q(length(Q)+1)=j;endendif isempty(Q)disp(X);breakelsexi=Q(1);Q(1)=[];endendT=setdiff(T,X); if isempty(T) breakendendend。
模糊聚类的分析模糊聚类是一种新兴的数据挖掘技术,它既可以结合经典聚类方法,又可以采用模糊逻辑理论。
模糊聚类把数据聚类的过程分解为两个阶段:测量和模糊聚类。
它的优点在于可以处理不确定的数据,并且对大量的数据有明显的优势。
模糊聚类是以模糊逻辑理论为基础的一种聚类方法。
与常规的聚类方法不同,模糊聚类的目的是把数据点归类到具有不同程度相似度的聚类中。
模糊聚类可以使用模糊逻辑,捕捉数据点之间不显著的相关性,而绕开实际相关矩阵中的障碍。
模糊聚类的核心过程主要有两种:测量和模糊聚类。
测量过程是模糊聚类中最重要的步骤,其目的是识别数据点之间的相似度。
模糊聚类过程的核心是构建模糊关联矩阵,它可以把数据点归类到不同的相似度类别中。
通常,模糊聚类的测量过程主要采用距离度量和角度度量来完成。
距离度量主要是指以欧氏距离、曼哈顿距离和切比雪夫距离为代表,能够直接测量数据点之间的距离;角度度量则是以余弦相似度为代表,能够衡量数据点之间的角度大小。
模糊聚类的聚类过程是把数据点归类到不同的聚类中。
这一步骤是根据距离或角度度量值来实现的,它把数据点归类到按照相似度排列的聚类中。
通常,模糊聚类的聚类过程主要由两个步骤组成:构建模糊关联矩阵(FCM)和求解模糊关联矩阵(FCM)。
模糊聚类有着很多优点:首先,它可以处理不确定性数据,它可以综合考虑模糊逻辑中不确定性的因素;其次,它对大数据有明显的优势,它可以对大规模的数据进行有效的聚类处理。
在聚类分析的实际应用中,模糊聚类的作用也正在发挥出来,它可以用于汽车维修、航空航行反演分析、银行信用风险分析、智能多媒体表达等多个领域中。
同时,模糊聚类也把聚类自身的边界变得更加模糊,让聚类结果更加灵活,同时也提高了聚类结果的可解释性。
综上所述,模糊聚类是一种新型的数据挖掘方法,它在聚类分析领域有着重要的意义,它的应用可以帮助我们把数据点归类到不同的相似度类别中,使得分析过程更加针对性和高效。
模糊聚类分析步骤
————————————————————————————————作者:————————————————————————————————日期:
求分类对象的相似度
传递闭包法进行聚类(求动态聚类图)
根据λ∈(0,1)的不同取值分布不同的类。
注释(1):模糊相似矩阵只具有自反性和对称性,不具有传递性,求λ截矩阵的前提是R 是X 上的的模糊等价关系。
所以要先求得R 传递闭包,将模糊相似矩阵转化为模糊等价矩阵。
原始数据矩阵
标准化矩阵
模糊相似矩阵R
(1)
相似距离
主观
欧式距明氏距切比雪
等价关系矩阵
传递闭布尔矩
直接聚
截矩阵
雨量站问题
原始数据矩阵:
(重要定理:设R∈F ( X ⨯X ) 是相似关系( 即R 是自反、对称模糊关系) ,则e(R) = t(R) ,即模糊相似关系的传递闭包就是它的等价闭包。
)
Y的传递闭包(即Y的等价矩阵):
求λ截矩阵,在程序中我用的k代替了λ。
K=1时,x1,x2,x3,…x11,各成一类,将11个雨量站分成11类。
K=0.9095时,将11个雨量站分为10类,X8, X11为一类,其余各自一类。
分8类,将x2 ,x5, x8, x11分一类,其余各自一类
分6类,x2 x3,x5, x8, x9 x11为一类,其余各自一类。
分4类,x1
,x2 ,x3,x5, x7,x8, x9 x11为一类,其余各自一类。
分4类,x1, x3 x2 x7 x8 x9 x11为一类,x2 x4 x5为一类,x6一类,x10一类。
分3类,x2 x4 x5 x6为一类,x1 x3 x7 x8 x9 x11一类,x10一类。
分2类,x2 x4 x5 x6 x10一类,x1 x3 x7 x8 x9 x11一类
分2类,x1x2 x4 x5 x6 x10一类,x3 x8 x9 x11一类.
分1类。
程序一:标准化矩阵:
function Y=bzh1(X)
[a,b]=size(X);
C=max(X);
D=min(X);
Y=zeros(a,b);
for i=1:a
for j=1:b
Y(i,j)=(X(i,j)-D(j))/(C(j)-D(j)); %平移极差变化进行数据标准化end
end
fprintf('标准化矩阵如下:Y=\n');
disp(Y)
end
程序二:求模糊相似矩阵:
function R=biaod2(Y,c)
[a,b]=size(Y);
Z=zeros(a);
R=zeros(a);
for i=1:a
for j=1:a
for k=1:b
Z(i,j)=abs(Y(i,k)-Y(j,k))+Z(i,j);
R(i,j)=1-c*Z(i,j);%绝对值减数法--欧氏距离求模糊相似矩阵
end
end
end
fprintf('模糊相似矩阵如下:R=\n');
disp(R)
end
程序三:计算传递闭包:
function B=cd3(R)
a=size(R);
B=zeros(a);
flag=0;
while flag==0
for i= 1: a
for j= 1: a
for k=1:a
B( i , j ) = max(min( R( i , k) , R( k, j) ) , B( i , j ) ) ;%R与R内积,先取小再取大
end
end
end
if B==R
flag=1;
else
R=B;%循环计算R传递闭包
end
end
程序四:求 截矩阵:
function [D k] =jjz4(B)
L=unique(B)';
a=size(B);
D=zeros(a);
for m=length(L):-1:1
k=L(m);
for i=1:a
for j=1:a
if B(i,j)>=k
D(i,j)=1;
else D(i,j)=0;%求?截距阵,当bij≥? 时,bij(?) =1;当bij<? 时,bij(?) =0
end
end
end
fprintf('当分类系数k=:\n'); disp(L(m));
fprintf('所得截距阵为:\n'); disp(D);
end。